少量通道脑电信号的实时情绪分类模型
2024-02-27张冰雪李文楷
张冰雪,李文楷
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
情绪是结合了思想、感情和行为的一种复杂状态,是人们对来自内部或外部的刺激作出的一种心理生理反应[1],在人们的决策、感知和沟通中起着至关重要的作用.积极的情绪带来积极的人际交互体验,增进个人的主观幸福感,而消极的情绪可能会影响身心健康[2].情绪识别的研究方向主要有两种.一种是使用面部表情、语音、行为、文本等非生理信号对情绪进行分类,采用非侵入方式收集数据.如果人们通过控制行为反应来隐藏真实感受,这种方式就很难获得准确的情绪,可靠性无法保证.另一种方式是使用心率、皮肤电导率、体温、脑电图等生理信号.这些生理信号被人体中枢神经系统和自主神经系统响应,大多数情况是非自愿激活的,不容易受到人的主观意识控制,更接近人的真实情绪.在这类生理信号中,脑电信号直接来自大脑,有良好的时间分辨率,可以提供直接和高精度的数据.因此,脑电信号被广泛应用于情绪识别.
脑电图采集设备类型多样.研究人员常使用大通道昂贵的医疗设备采集数据,例如32通道的DEAP数据[3]集,62通道SEED数据集[4].Rahman等人[5]统计了脑电情绪数据集的使用情况,大多数使用完整的32或62通道数据,以及少部分14通道数据集.大通道的脑电设备价格昂贵,实验前期准备时间较长且佩戴不舒适.Didar等人[6]评估了流行的消费级脑电设备,并回顾了这些低成本设备用于情绪识别可靠性的相关研究.目前存在新一代脑电图设备,即脑电头带,如Emotiv Insight,Muse InteraXon和Neurosky Mindwave,通常这些设备的电极数量较少佩戴舒适且价格便宜.例如5个通道的Emotive INSIGHT设备是32通道的Emotive EPOC FLEX设备价格的六分之一,是14通道的Emotive EPOC X 设备的价格三分之一.与传统的脑电设备相比,脑电头带设备不需要准备导电膏或盐水,能直接和移动设备进行交互,使用简单方便佩戴舒适.
早期脑电信号情绪识别主要采用手动提取脑电信号中的时域、频域或时频域特征信息,然后利用机器学习算法进行分类.常使用功率谱密度、微分熵、微分不对称、共空间模式等特征[2].但这种方法通常需要复杂的人工特征工程,降低了脑电分类技术的灵活性和泛化能力.有时也需要选择多种特征,使用特征融合方式的方式提高特征质量,在脑电情绪分类中也取得了较好的效果,但是特征质量还是限制了算法的能力.
随着深度学习在各个领域的发展,深度神经网络也用于提取脑电特征,可以自动过滤数据,提取数据的高维特征[7],相比于传统手动提取特征有好的表征能力、更强的泛化能力和更灵活的应用.深度学习模型中分层的特性意味着可以在原始数据或最低限度的预处理数据上学习特征,从而减少对特定于域的处理和特征提取的需求[8].现阶段深度学习模型主要采用卷积神经网络(CNN)和递归神经网络(RNN)提取脑电特征.CNN算法利用滑动窗口在脑电信号中选择候选区域,提取候选区域的信号特征,通过深层网络进一步获取信号的高级特征,最后使用回归等方法对窗口中的脑电信号进行分类.CNN模型更关注局部特征,能提取出相邻通道之间的特征信息,但是对信号时序特征关注较弱,对于脑电一类时序较长的信号,难以分析信号前后的变化.RNN模型能通过序列化输入来提取时序部分的特征,强调先后顺序,能处理任意的输入长度.通常这些模型采用两步训练过程,包括特征学习和训练分类器.一种方式是将手动提取的特征组合为特征矩阵,使用深度学习模型在这些特征中再进行特征的筛选和提炼,另一种方式是使用深度学习模型同时训练特征提取和分类器,实现端到端的特征提取和分类.
针对上述的问题,本文提出一种脑电信号的实时情绪分类模型.首先使用一维卷积神经网络提取特征并且降低数据时序的长度,使用BiLSTM进一步提取特征然后送入到分类器分类,实现端到端的特征提取和分类.为了进一步提高模型性能,在BiLSTM层使用多头注意力机制挖掘更多有效特征.在32通道和选出的5个通道的DEAP数据上,使用不同时间窗口对数据进行分段,每个分段都进行分类检测.结果表明本文提出的模型在5通道数据中,具有更好实时识别脑电情绪的能力.
1 相关工作
在人机交互领域,伴随着人工智能和深度学习的发展,脑电情绪识别又成为研究热点.目前,脑电情绪识别研究主要在数据预处理、特征提取和分类三方面.其中特征提取是最关键的一步.如何准确挖掘出脑电信号中的情绪表征并提取出关键的信息是研究的难点.常用频域、时域或时频域等分析方法特征提取.例如Mashail等人[9]使用频域分析中的功率谱密度(PSD)作为特征,使用支持向量机(SVM)分类器分类,取得了较好的效果.Li等人[10]使用时频域的离散小波变换(DWT)特征作为K-最近邻分类算法的输入特征.上述模型都是使用一种特征进行分类,研究员通常也会将多个域的不同特征进行组合,获得更有效的特征.特征提取算法通常需要复杂特征计算和选择,虽然在脑电情绪分类中已经取得了一定的成果,但是特征质量还是限制了算法的能力.随着深度学习的性能快速提升在多个研究方向超过机器学习,深度学习算法在情绪识别方向也被广泛使用.一方面,深度学习方法可以在手动提取的特征之后提取更高维度的特征.例如,Yang等人[11]提出了脑电图的3D表示,组合不同频段的信号特征组成3D图,然后使用卷积神经网络提取特征和分类,也证实了多个波段的特征组合能进一步提高识别精度.另一方面,摆脱手工设计特征的方式,使用端对端的深度学习方式提取特征和分类.例如,Xing等人[12]使用堆栈自动编码器构建脑电混合模型提取特征,使用基于长短期记忆循环神经网络(LSTM)进行分类,在多通道脑电的情绪识别中表现出比传统方法更好的性能.其中LSTM是RNN的变体,能解决RNN存在的梯度消失和梯度爆炸问题.然而LSTM只能处理从前往后的信息,而脑电信号一个时刻的信息可能和这个时刻的前后时间段都是有关联的,BiLSTM在LSTM的基础上增加了一个向后的LSTM,从而能从两个方向获取脑电信号特征.基于上述分析,本文使用BiLSTM提取脑电信号在时序方面的特征.
注意力机制是深度学习领域发展的突破之一,它不仅使模型的准确率有了一定程度的提高,也让模型有了一定的可解释性.在计算能力有限的情况下,注意力机制可以将计算资源用于处理更重要的信息[13].注意力机制最开始被应用在计算机视觉领域,取得不错的效果.现在,注意力机制已经被广泛的应用在神经网络模型中.研究人员对注意力机制进行不同的修改和改进,以便更好地适应特定的任务.Zhang等人[14]提出结合注意力机制的LSTM网络来学习脑电图时间序列信息,用于脑电信号的肢体运动分类.Tao等人[15]提出一种基于注意力的卷积递归神经网络,从脑电信号中提取出更多鉴别特征,分别使用了两种注意力机制,一种是通道注意力机制关注不同脑电通道的权重信息,一种是自注意力机制专注于输入序列之间的注意力.随着对注意力机制的进一步研究,Vaswani等人[16]提出一种多头注意力方案,让模型关注到不同子空间的信息.Ma等人[17]研究结合脑电图和眼球运动等多模态残差 LSTM 网络在不同睡眠质量下的情绪分析,证明使用多头注意力机制改进的模型能更好的从生理信号中提取关键特征.在本文的研究中使用多头注意力机制来提升对脑电信号的情绪特征挖掘.
早期的实时系统由传统特征提取和机器学习分类算法构成,使用滑动窗口进行特征计算.例如David等人[18]提出的一种实时脑电情绪识别算法,将结合统计的维度特征和高阶交叉特征相结合,使用支持向量机算法进行分类.实验使用4个通道对2种情绪进行分类,获得87.02%的平均准确度.Liu等人[19]构建了一个包含16个中文电影片段的标准化数据库,使用带有滑动窗口的短时傅里叶变换进行基于时频分析的特征提取和归一化,在七种基本离散情绪中获得较好的分类结果.随着人工智能应用的日渐普及,一些脑电情绪计算使用了浅层模型或深度学习模型,与传统分类方式相比获得了更好的结果.Yang等人[20]使用一种改进的CNN模型,使用边缘计算,每个样本的训练时间成本极大降低,2分类的结果正确率达到88.34%.Liu等人[21]提出一种将CNN、稀疏自动编码器和深度神经网络结合在一起的新型深度神经网络,在8秒和12秒的时间窗口分段中获得比传统CNN方法更好的分类精度.实时系统能在较短时间中获取情绪分类结果,有利于研究情感的变化和分析影响情绪的因素.同时受到设备价格、佩戴舒适性以及模型计算复杂度等方面的影响,脑电情绪分类模型对脑电设备的通道数量以及实时性的要求进一步提高.
2 模 型
本文提出的脑电情绪分类模型整体框架如图1所示,模型主要由一维卷积、BiLSTM、多头注意力机制模块和分类器4部分组成.输入的数据先经过一维卷积层降低输入序列长度和特征提取,然后 BiLSTM层进一步提取特征信息.多头注意力机制层将对特征进行权重分析,得到最终的注意力值.经过两层的BiLSTM层和注意力机制的特征计算后,使用全连接层将输出值传递给sigmoad分类器得到最终的结果.
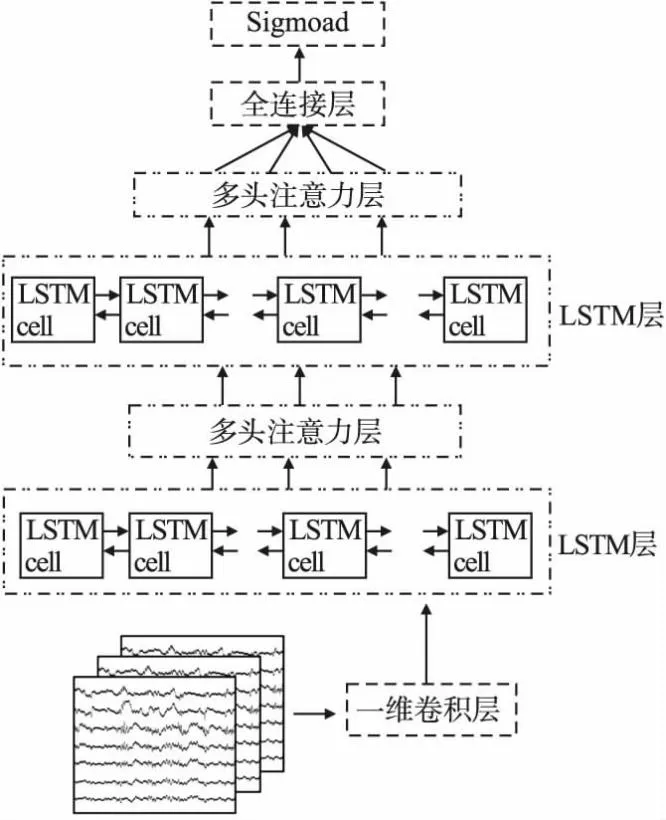
图1 模型整体结构Fig.1 Overall structure of the model
2.1 一维卷积
由于EEG设备的采样率较大,分段后数据的时间序列长度依然很长,而BiLSTM能处理的数据量级是有限的,所以需要使用一维卷积控制输入序列的长度.一维卷积的卷积核只在一个方向上移动,在脑电信号中,脑电信号是M行N列的矩阵平面,其中M表示通道的数量,N表示时序的长度,卷积核在时序方向上移动.使用一维卷积能有效的降低数据时序长度,并从原始时序数据中提取时序特征,卷积核的权重随时间共享并且对时间延迟不敏感[22].
2.2 BiLSTM模块
BiLSTM模块是由众多LSTM单元组成的,这些单元具有共同的单元状态,沿整个LSTM单元链保持长期依赖关系.其中信息流是由输入门和遗忘门控制,从而让网络能决定忘记之前的状态还是使用最新信息更新当前状态.每个单元的输出由输出门控制,根据更新的单元状态计算其输出.LSTM单元结构如图2所示.
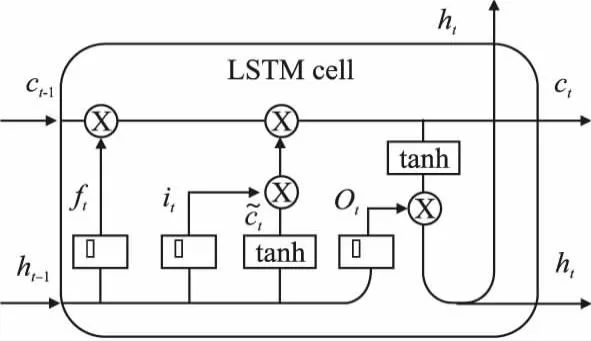
图2 LSTM单元结构Fig.2 Structure of the LSTM cell
遗忘门的计算公式如公式(1)所示:
ft=σ(Wf·[ht-1,Xt]+bf)
(1)
输入门的计算公式如公式(2)所示:
it=σ(Wi·[ht-1,Xt]+bi
(2)
输出门的计算公式如公式(3)所示:
Ot=σ(Wo·[ht-1,Xt]+bo
(3)
记忆单元的更新公式如公式(4)到公式(6)所示:
(4)
(5)
ht=Ot*tanhh(ct)
(6)
由于LSTM只能从前向后处理数据,但是一段脑电信号特征不仅与它时序之前的特征有关,可能也和时序之后的特征有关,因此在LSTM的基础上,增加一个后向的LSTM模块构成BiLSTM,从而提升整个模型提取特征的性能.BiLSTM的计算表达式如公式(7)~公式(9)所示:
(7)
(8)
(9)

2.3 多头注意力机制
自注意力机制可以帮助模型关注到脑电特征序列中的重要特征部分,其中多头注意力机制注重关注序列数据中不同位置元素之间的依赖关系.多头注意力机制由若干相同的层组成,每层都是一个自注意力机制,通过缩放点积注意力来实现.注意力机制是由多个query和key-Value键值对组成.计算query和每一个key的相似度,从而得到与query值相应的key的权重系数.通过加权权重系数对Value进行加权求和得到注意力值.单头注意力计算表达式如公式(10)所示:
(10)
其中K、Q、V分别表示query,key和value.
使用多头注意力机制计算流程,在不共享参数的情况下对卷积模块输出Q,K,V做线性变换,然后进行m次放缩点积注意力计算,将每层的输出的结果进行拼接.选择上次时间步长输出的原因是它包含所有时间步长中最冗余的信息.表达式如公式(11)~公式(13)所示:
(11)
(12)
(13)
其中oall表示所有时间的输出,olast表示上次输出,B表示批量的大小,T表示时间步长,Z表示特征维度.N表示注意力头的数量,b是偏差.
多头注意力分数和上下文向量的计算方法如公式(14)~公式(16)所示:
(14)
(15)
CV=Concat([context1,…,contextn]),CV∈RB,1,Z
(16)
其中si表示多头时间维度注意力得分,contexti表示来自每个子空间的上下文向量.
2.4 全连接层和输出层
将注意力机制层的所有结点的输出结果进行连接,计算公式如公式(17)所示:
Fc=σ(WfP+bf)
(17)
其中Wf为全连接层的权重,bf为偏置,σ为激活函数,最后通过sigmoid函数进行分类如公式(18)所示:
(18)
3 实 验
3.1 数据集
DEAP数据集是由Koelstra等人[3]开发的多模态情绪脑电信号数据集.由32名健康志愿者观看40段长达一分钟的情绪音乐视频,每次实验记录40个电极的信号,包括32个脑电信号和8个外围生理信号.所有的电极位置遵循国际标准10~20系统.志愿者需要对每个视频从1~9打分,用来评估唤醒、效价、喜好、支配性和熟悉度5个方面的水平.每个实验数据包括3s的基线数据部分和60s的实验数据部分.本文只使用与脑电相关的32通道数据.数据集预处理部分,将数据从512Hz下采样到128Hz,去除眼电伪影,使用4~45Hz的带通滤波器进行滤波.效价描述了与刺激相关的愉悦程度,唤醒度表示对刺激的清醒程度.根据评价量表,将每个评价都分为两类,高于7分表示为高,低于3分表示低.
为了提高识别准确度,使用Yang等人[23]提出的将实验数据中的基线信号去除办法.将3秒的基线信号平均为了3段1秒的片段,3个片段求平均得到一段1秒的基线信号.将60秒的实验数据分为60个长度为1秒的不重叠片段,60个片段数据分别减去1秒的基线信号,将得到去除极限信号的片段连接起来,得到去除基线信号的60秒实验数据.脑电信号将被划分为较短的数据片段用于实时分类,分别用1秒、3秒、5秒和7秒的时间窗口对数据进行分段.为了增加训练的样本和平衡不同标签的样本数量,对不同标签的数据使用不同的移动窗口扩充数据.针对高低效价和高低唤醒度标签不平衡问题,对高低标签的数据使用不同移动窗口,使最终不同标签的数据数量基本相同.
3.2 通道选择
许多研究表明,与情绪相关的脑电通道主要位于额叶、中央叶和顶叶.其中脑电信号的beta波段在大脑皮层呈现兴奋状态时更加显著[23].而beta活性在额叶和中央叶区域明显.大多数的研究使用DEAP数据集或SEED数据集的所有脑电通道数据,这些研究模型在实际应用往往需要高端的设备来采集数据,实验需要的前期准备时间长,设备也不够舒适,后期的计算量大不适合移动设备的使用.研究人员尝试使用少量通道数据进行情感分类,例如Liu等人[18]使用非重叠滑动窗口进行FD特征计算,计算所有受试者的每个通道的平均FDR分数,得到每个通道的排名,选择前4个通道FC5,F4,F7和AF3作为具有足够精确度的情绪识别最佳选择.Zhang等人从Beta波活跃的额叶和中央区域的F3,F4,C3,C4通道中,通过两个通道之间的Pearson相关系数,选择出F3和F4通道进行研究.Yang等人[20]使用八通道的情绪识别系统,通道的位置大多位于额叶区域.上述文章通道的选择大多是通过算法计算不同通道的特征,然后进行相关性分析,排序得到所选的通道.特征类型的选择和计算方式影响最终的通道选择结果.上述不同论文选择的通道有所不同,后续要将这些模型进行测试和商业使用时,没有对应的EEG设备可以使用.可以使用只安装特定电极的设备进行实验,缺点是商用成本依然较大,佩戴舒适性基本没有提升.针对上述的问题,本文从现有的商用消费级设备中进行选择,将Emotiv insight EEG设备所对应的5个脑电电极位置作为本文实验通道位置.该设备和DEAP使用的设备同样符合10-20系统,脑电通道分别是AF3,T7,Pz,AF4和T8,分布在额叶、中央叶和顶叶,符合与情绪相关通道所在的位置.
3.3 实验参数
一维卷积的卷积核设置为100,窗口长度设置为30,这样能减少计算的复杂度,步长设置为5.深度学习模型采用Adam优化器加快网络的收敛速度.学习率设置为0.001.每次训练的样本数量为64.为了降低BiLSTM层出现过拟合的情况,引入L2正则化项和Dropout机制,随机失活率设置为0.3,正则系数为0.001.全连接层采用ReLU激活功能,增加非线性度,同样使用Dropout层防止过拟合.模型训练使用均方差损失函数来度量模型的结果.
3.4 对比实验与结果分析
本文选取LSTM模型作为基准,使用3种改进的LSTM模型在DEAP数据集上进行实验.这些模型是:1)BiLSTM,标准的双向长短期记忆网络网络;2)BiLSTM-attention,基于自注意力机制的双向长短期记忆网络;3)BiLSTM+nH,基于多头注意力机制的BiLSTM的网络模型,n表示多头.所有的模型都是端对端实时深度学习网络模型,使用相同数据预处理,在不同时间片分段上进行实验,使用效价和唤醒度两个维度进行分析.
表1显示了5个网络模型在32通道和5通道的DEAP数据集上的效价分类的实验结果.在32通道的实验结果中,3秒数据分段在2头注意力机制的BiLSTM网络中取得93.69%的最佳实验结果.自注意力机制BiLSTM模型比BiLSTM模型,在所有时间分段中正确率都有提升.多头注意力机制模型比自注意力机制模型实验正确率提升更多,在3秒分段中正确率的提升了4.78%,证明使用多头注意力能发掘到数据中更有效的信息.对比几个多头注意力模型,发现随着头部的增加,模型正确率在减少,原因是头部数量的增加并不能总能提升模型的性能.对比不同的时间分段,1秒~7秒正确率是先增加后减少的过程,证明多头注意力模型能提取信息的能力与信息的长度有关,较短和太长的时序数据都不利于特征的提取.整体结果表明,在32通道实验中使用多头注意力机制比使用自注意力机制的BiLSTM模型和BiLSTM模型性能更好.

表1 效价实验结果Table 1 Value experiment result
在5通道的实验中,实验结论与32通道结论基本相同,使用多头注意力机制比使用自注意力机制的效果更好.使用BiLSTM+2H模型比LSTM模型在5秒分段中提升了9.57%的正确率,1秒分段中提升了4.21%的正确率.多头注意力模型在5通道的数据中提升的效果明显,取得93.34%的正确率.说明多头注意力机制在数量量少的情况下,更能提取出特征之间的相互关系,从而提升模型的整体性能.
对比32通道和5通道的数据,在LSTM模型中5通道比32通道的数据正确率平均减少了7.08%,说明在通道数量减少之后,LSTM模型提取特征的性能有明显下降.从32减少到5通道,在LSTM+attention模型中,正确率平均减少了6.80%,而在BiLSTM+2H模型中,正确率平均只减少了2.56%,使用多头注意力之后,模型能从有限的通道数据中提取有效特征,提升模型正确率.在5秒分段的数据中,BiLSTM+2H模型的在5通道的实验正确率为93.34%,比使用32通道数据的正确率要提高0.92%,说明使用较少的通道某种程度上能减少无关通道特征的影响,从而提升一定到正确率.多头注意力机制的头数增加并不一定能有效的提升模型的性能,从2头~8头,两种通道的实验结果都呈现下降趋势,说明过多的头数不适合实验使用的数据.时间分段从1秒到7秒的过程中,32通道和5通道模型的正确率都呈现升高到降低的过程,其中7秒分段的数据性能下降严重,说明模型适合3秒和5秒的分段数据,其中5通道模型更适合5秒分段的数据.
表2是模型在唤醒度分类上的结果.32通道模型中,5秒分段的数据取得94.42%的最佳结果.多头注意力模型的平均正确率高于基础的BiLSTM模型和使用自注意力的BiLSTM模型,其中使用4头和8头注意力机制的模型结果差别不大.在使用5通道数据的模型中,2头注意力机制模型同样在5秒数据分段中取得最佳结果为91.76%,32通道模型结果降低了2.66%,对比BiLSTM模型从32通道到5通道降低了5.14的正确率有较大的提升.
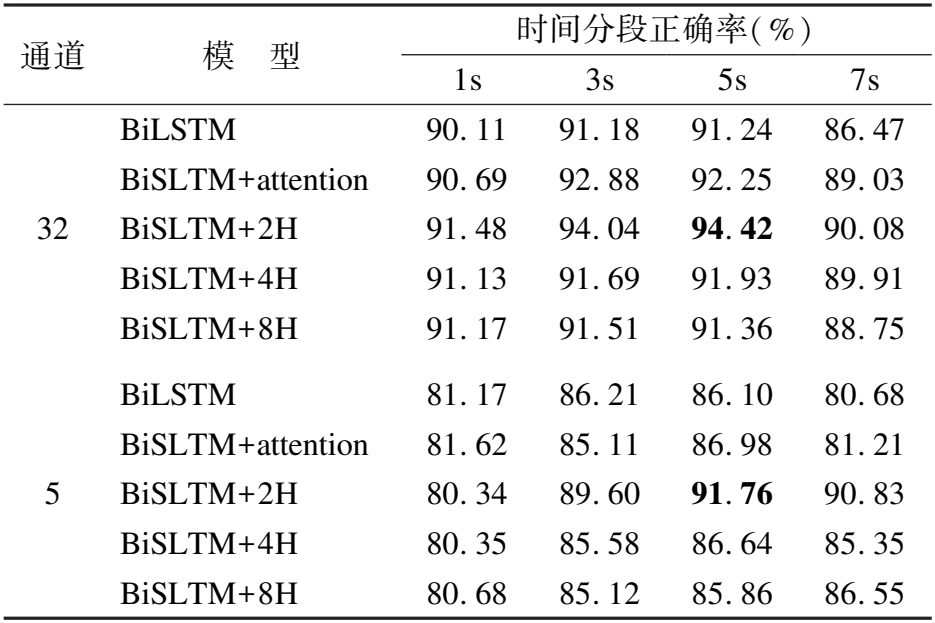
表2 唤醒度实验结果Table 2 Arousal experiment result
比较表1和表2的结果,32通道和5通道的最佳正确率都是使用2头注意力机制的BiLSTM模型其中,说明多头注意力机制比较基础BiLSTM模型和使用自注意力机制的BiLSTM模型有更好的性能.此外,多头的数量对模型的结果也有影响,并不是头数越多模型的性能越强,本文的模型中2头取得的实验效果最好.时间分段的长度对实验也有较大的影响,较短或较长的分段都会导致模型的性能下降,说明使用BiLSTM的模型对时间序列长度有一定的要求,5通道模型在效价和唤醒度上都适合5秒分段的数据.
3.5 训练时间和测试时间
实验使用的操作系统环境是Ubuntu 18.04.6 LTS,使用Tensorflow、Keras和Python编程实现.硬件采用Intel(R) Xeon(R) CPU @ 2.30GHz的处理器和12.68GB内存的NVIDIA T4 GPU显卡.
以3秒分段的效价数据记录训练时间和测试时间为例,训练集数量29710,测试集数量8729,预测集数量8725.所有模型都是在NVIDIA GPU上进行训练,考虑到项目部署过程中可能没有GPU环境,预测时间在CPU环境中获得,测试时间为所有预测数据集的总时间.
表3展示了在3秒效价分段的数据上,各模型在32通道和5通道的数据上的模型参数量、模型在GPU上的训练时间以及在CPU上的测试时间.从表中可以看到BiLSTM模型的参数量和通道的数量是正相关的,从5通道到32通道模型参数扩大了5.5倍,通道数量为6.4倍,而模型的训练时间略微增加,说明使用GPU训练时,数据的并行效率高,极大的减少了训练时间.模型使用多头注意力时,模型每增加两个头参数量增长基本相同,32通道模型从2头到4头模型参数量增加15674,5通道模型对应增加了15294参数量.多头注意力从4头到8头的参数增长量也在一个数量级.所有模型从32通道到5通道参数量是有明显的降低,训练时间也有一定程度的降低.在预测时间上,模型的参数量对预测时间有一定的影响,参数量越多预测计算的时间就越长.8725个数据集的预测时间都少于25秒,则每个数据的预测时间少于2.8毫秒,即在实时系统中每3秒到数据能快速完成分类,满足了模型部署预测时对实时性的要求.

表3 3秒分段数据的训练时间和预测时间Table 3 Training time and test time on 3-second segmented data
3.6 与其他模型比较
表4显示与其他使用DEAP数据集构建实时情绪分类模型的比较.Liu等人[19]使用4个通道4秒滑动窗口数据计算统计特征、HOC特征和FD特征,使用SVM分类器训练和测试样本,获得83.73%的分类精度.Dandi等人[24]使用的小波变换获取特征,使用数据流的形式进行实时情绪分类.在使用手动制作特征的方式的非深度学习方法中,实现了高精度.Hector等人[25]使用功率谱密度PSD特征组成14个通道的特征矩阵,使用一种基于FPGA的CNN模型提出BioCNN模型进一步提取特征,和硬件结合的方式提高模型的计算能力,低内存占用和资源重用.Asghar等人[26]提出多个网络多个功能的大型特征向量表中选择的iMEMD模型,简化的特征向量在使用SVM和k-NN分类器时性能出色,在8通道的数据上获得83.12%的效价准确率和76.78%的唤醒度准确率.以上方式都是首先使用手动方式特征提取,然后用机器学习算法分类,或者是使用深度学习的方式进一步提取特征然后再进行分类.Yang等人[20]提出一种使用长期卷积递归卷积网络模型LRCN,实现低功耗和实时监控.使用数据流的形式进行训练,使用8个通道10秒的时间窗口中获得二分类的平均正确率为88.34%,优于iMEMD模型.Liu等人[21]提出一种结合CNN、SAE和DNN将脑电时间序列转化为而为图像的新型网络模型,根据频率、时间和位置信息提取2D特征,使用8秒窗口分别获得了89.49%的效价正确率和92.86%的唤醒度正确率,在12秒窗口中获得82.16%和85.47%的正确率,表明深度学习算法在特征提取方面已经超过了传统的手工特征提取算法.本文的模型使用CNN、LSTM和注意力机制模块提取特征,使用5通道5秒时间分段的数据,在效价和唤醒度上分别取得了93.34%和91.76%的正确率.在通道数量和时间窗口的选择上相较于其他算法有明显优势,模型结果比其他算法也更有优势.

表4 与其他模型对比Table 4 Comparison with other models
随着针对消费级的脑电情绪分类模型的发展,除了追求较高的准确率,还有计算复杂度的降低,通道数量较少,设备佩戴的舒适性好,预测所需的数据时序更短等方面.综上所述,本文提出的模型使用5个通道的脑电数据,在训练准确率和训练时间上都有较好的表现,相比于传统机器学习方法,也不需要手动提取特征和进行特征组合,实现了端对端的脑电信号的情绪识别,简化了脑电识别的流程.从现有的消费级脑电头带设备中选出实验通道,方便进一步的研究.
4 结束语
本文提出了一种基于CNN、BiLSTM和多头注意力机制的深度网络模型对脑电信号进行分类,使用端到端的方式进行特征提取和分类,使用较短的时间分段数据进行训练和预测,达到实时情绪分类模型要求.在提出的模型中,CNN和BiLSTM被训练用于特征提取,通过结合多头注意力机制,更有效的提取特征提高分类精度.在DEAP数据集上,分别使用32通道和5通道的脑电生理信号进行实验,结果表明所提出的网络模型比其他基于LSTM模型有更好的性能.模型在32通道和5通道之间效价和唤醒度的平均最佳精度只减少了1.51%,表明使用5通道的数据来进行脑电情绪分类是可行的.不同的时间片长度也会影响到模型的性能,在5通道模型中5秒的数据能达效价和唤醒度的最佳实验效果.在未来的工作中,可以使用不同数据集对模型进行检验,也可以在消费级的脑电设备上采集数据,验证模型实际使用中的性能.
