联合异质图卷积网络和注意力机制的假新闻检测
2024-02-27韩晓鸿赵梦凡张钰涛
韩晓鸿,赵梦凡,2,张钰涛,2
1(河北工程大学 信息与电气工程学院,河北 邯郸 056038)
2(天津大学 智能与计算学部,天津 300350)
0 引 言
随着互联网技术的飞速发展,人们更容易在社交网络上表达观点,转发和评论各种信息,社交媒体平台的隐蔽性促进了假新闻的产生和传播,微观层面来说,短时间内一条假新闻可以在社交平台快速发酵,给新闻当事人带来困扰,此外,宏观角度来说,假新闻的泛滥在经济、政治和公共卫生等领域对社会造成了更大的负面影响,在2016年美国总统大选期间,恶意捏造的党派新闻导致公众对总统候选人产生了偏见和误解[1].经济学中,假新闻的传播可以操纵股价,如美联社的Twitter账号被黑客攻击,发布“白宫爆炸,导致奥巴马受伤”的假新闻,造成了1390亿美元的股价亏损.新冠肺炎疫情爆发以来,出现了各种关于新冠肺炎的起源、预防、诊断、治疗等错误信息和阴谋论,如声称“漂白剂可以预防新冠病毒”的假新闻导致印度多人死亡.假新闻在社交媒体平台传播的时间越久,就越难辟谣,对大众造成的影响也越深远,这迫切需要有效的方法进行假新闻检测,尽可能减少假新闻造成的危害.
近年来,社交媒体上传播的假新闻成为一个严峻的问题,研究人员在假新闻检测领域投入了大量的精力,以前的大多数方法主要基于对新闻内容的分析,例如挖掘词汇特征[2]、句法特征[3]、修辞结构[4]和写作风格[2,5],然而,“深假技术”的出现,使得仅依靠新闻内容很难有效识别高度仿造的假新闻.最近的假新闻检测方法集中在利用新闻网站的社交信息上,这些方法增加了额外的社会背景特征,包括用户资料数据、用户社交信息[6]、社交网络结构和传播结构[7],这些方法为假新闻检测提供了新的思路,然而现有方法主要根据单条新闻的特征来判断新闻真实性,由于单条新闻提供的特征有限,并且可能与事实有所偏差,因此检测效果不佳.
近年来,受深度神经网络在许多自然语言处理任务中特征探索的成功启发,如机器翻译、情感分析、文本分类等,Ma等人[8]首先引入深度神经网络来捕获谣言源推文传播的时间表示,利用循环神经网络RNN(Recurrent Neural Network)来捕获每条源推文及其转发推文的语义变化,并根据语义变化进行预测.Ma等人[9]探索了一种基于树的递归神经网络来捕获源推文传播的语义信息和传播线索,以进行谣言检测.Yuan等人[10]构建了一个全局-局部注意力网络来捕获源推文传播的局部语义关系和全局结构信息,用于谣言检测.对于这些方法,一个主要限制是它们忽略了文本内容的全局语义关系,而文本的全局语义关系是十分重要的[11].
图神经网络GNN(Graph Neural Networks)得益于非欧式的数据空间,能够捕获文本全局语义关系,因此在自然语言处理领域的应用取得了良好的效果.Hu等人[12]引入外部知识图,通过为每条新闻构建一个有向图进行假新闻检测.Koloski等人[13]提取新闻中主谓宾三元组,证明了基于知识图谱进行假新闻检测的有效性.Xu等人[14]将新闻和证据建模为图结构,并通过邻域传播捕获分散的相关片段之间的长距离语义依赖性.事实上,社会心理学家认为,当情况不明显或存在潜在威胁,并且当人们需要安全感时,谣言就会出现.因此,假新闻的文本内容往往会包含更多的含糊和恐吓性词语,以促进假新闻的传播[15].然而,以往的这些检测方法大多构建同质图进行假新闻检测,图中只包含一种类型的节点,没有充分利用新闻全部的特征,并且重点关注于新闻内容的局部语义关系,忽略了不同新闻之间的全局语义关系.最近的研究中,Huang等人[15]提出异质图假新闻检测模型,但是对于不同类型的节点,如推文节点和用户节点,忽略了异质节点特征提取的全面性和有效性.
为了弥补以上缺陷,本文提出了一种异质图卷积注意力网络模型HGCAN(Heterogeneous Graph Convolutional Attention Network),通过构建推文-词-用户异质图捕获新闻内容的文本信息和传播结构信息,然后基于元路径将异质图分解为推文-词、推文-用户两个子图,设计推文-用户对图卷积神经网络GCN(Graph Convolutional Neural Network)提取新闻-用户子图的节点特征,并对两个子图应用子图内注意力机制学习节点的特征表示,最后,引入子图间注意力机制学习两个子图的权重,聚合两个子图学习到的节点特征表示.
本文的主要贡献有以下几点:
1)针对目前已有研究中构建的图网络中存在的问题,即涵盖的信息片面,不能很好的提取新闻特征,且未区分不同图节点的重要程度,结合新闻内容和用户信息构建推文-词-用户异质图,增强新闻信息表示能力,其中包括推文、词、用户3种类型的节点,构建的异质图如图1所示;
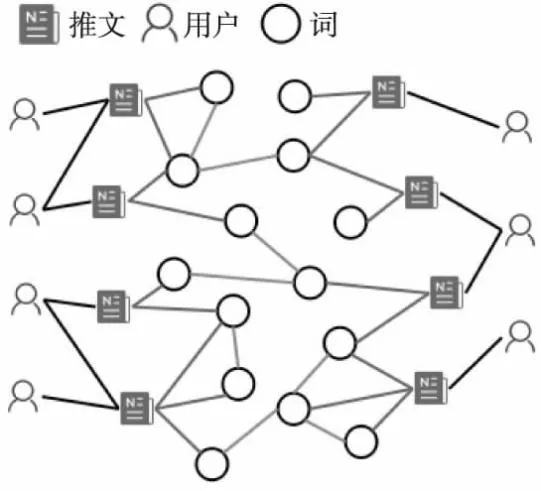
图1 推文-词-用户异质图Fig.1 Tweet-word-user heterogeneous graph
2)针对于推文节点和用户节点类型不一致的问题,设计推文-用户节点对图卷积网络,首先将不同类型的节点投影到同一特征空间,再进行节点特征提取;
3)为了探索不同节点的重要性,引入注意力机制节点权重,利用基于元路径的异质图注意力网络捕捉新闻内容的全局语义关系和新闻传播的全局结构信息;
4)在两个公开数据集上进行的大量实验证明了本文方法的有效性.
1 相关工作
传统的基于机器学习方法中,新闻的文本内容是通过使用一组手动选择的特征来表示的,这些特征可以从新闻的语法、语义、词汇等角度进行提取.机器学习方法还可以通过检测新闻的类型来进行基于风格的假新闻检测,如依赖于支持向量机SVM[16]、随机森林RF[17]等.还有一些方法结合了不同类型的特征进行假新闻检测,Castillo等人[18]提出了基于消息、用户、主题和传播的谣言检测模型,Ma等人[19]探索了一种谣言生命周期的时间序列来捕捉社会背景信息的新方法.此外,越来越多的研究融入新闻传播特征,Ma等人[20]提出了一种具有树的核函数SVM分类器,通过计算传播拓扑数相似性识别谣言.然而,从新闻文本内容、用户信息、和传播模式中手动提取特征既费时又费力,并且这些特征严重依赖于数据集.
深度学习已经成功应用于许多现实世界的任务,如图节点分类、机器翻译、图像识别等,一些学者开始研究用于假新闻检测的深度学习模型.Yang等人[21]利用新闻之间的相似性关系,通过图神经网络进行假新闻检测,Yuan等人[10]提出了一个全局-局部注意力网络来捕获源推文传播拓扑树的全局结构特征,用于谣言检测.Ran等人[22]提出了一个端到端的多通道图注意力网络,通过并行构建3个子图学习新闻传播结构的语义信息,从而进行谣言检测.然而,这些方法没有将新闻全局语义关系信息和传播结构信息进行有效的整合,丢失了很多重要特征信息.图注意力网络的发展为假新闻检测领域提供了新的方向和思路,在本文中,根据假新闻文本内容和传播信息构造了异质图,并设计节点对之间的图卷积网络架构,以有效提取新闻节点的高阶信息表示,利用图注意力机制对提取的特征及子图进行有效的融合.
2 异质图的构建
本文提出的异质图卷积注意力模型HGCAN包括3个重要部分,分别是异质图构建、子图卷积注意力网络、子图间注意力网络.在本节中,将详细介绍异质图的构建过程,并定义异质图上的假新闻检测问题.
2.1 推文-词-用户异质图
将数据集中的信息构建为推文-词-用户异质图,其中包括新闻的文本内容和源推文传播所涉及的信息,如转发用户、时间信息等,构建的异质图如图1所示.对于构建的推文-词-用户异质图G=(V,E),V和E分别表示图中的节点集和边集,节点集V包含一组源推文T和用户集U,其中源推文T包含一组词W.边集E包含3种类型的边:推文-词边Etw,词-词边Eww和推文-用户边Etu,其中Etw描述了推文与其包含的单词之间的关系,Eww表示词之间的语义关系,Etu代表推文和用户之间的交互关系.
构建边时,利用推文和词的包含关系构建推文-词边Etw,即如果一个单词出现在某条推文中,则该条推文和词之间产生一条边;利用词共现信息构建词-词边Eww,即当某些词同时出现在特定大小的滑动窗口中,则为这些词之间构建一条边;利用推文和用户之间的回复或者转发关系构建推文-用户边Etu.对于边Etw的权重,根据词频-逆文档频率(TF-IDF)生成其权重,其中词频TF是词在源推文中出现的次数,逆文档频率IDF是源推文总数量与包含该词的推文数量之比,其主要思想就是包含词wi的推文越少,IDF值越大,说明该词具有很好的类别区分能力;为了利用词的全局共现信息,捕捉新闻的全局语义关系,在数据集中的所有源推文上设置固定大小的滑动窗口,以收集词共现统计信息,利用单词关联度量PMI(Pointwise Mutual Information)[23]计算边Eww的权重;边Etu的权重通过用户转发或回复推文的时间的倒数计算.节点i和j之间边的权重计算如下:
(1)
其中t表示用户j转发或回复推文i后经过的时间,词对i和j之间的PMI值[24]计算如下:
(2)
其中W(i,j)*表示同时包含词i和j的滑动窗口的数量,W*表示滑动窗口的总数量,W(i)*表示包含词i的滑动窗口的数量,W(j)*表示包含词j的滑动窗口的数量.TF-IDF倾向于过滤掉常见词,保留重要的词,某条新闻内的高频率词语,以及在整个数据集中属于低频词,则会产生权重较高的TF-IDF值,推文t和词i的TF-IDF值计算如下:
(3)
其中nij表示词i在推文t中出现的次数,|T|表示推文的总数,|{k:wi∈tk}|表示包含词i的推文数,加1是防止包含词i的推文数为0,从而导致运算出错的现象发生.
2.2 推文-词和推文-用户异质子图
为了捕获文本内容的全局语义关系和源推文传播的结构信息,基于元路径将推文-词-用户异质图分解为推文-词子图和推文-用户子图.
推文-词子图:推文-词子图中的节点是推文-词-用户异质图中的推文节点、词节点,边由异质图中推文节点和词节点之间的边构成.
推文-用户子图:推文-用户子图中的节点是推文-词-用户异质图中的推文节点、用户节点,边与异质图中推文节点和用户节点之间的边一致.
2.3 假新闻检测问题定义
给定一个构建的异质图G=(V,E),其中V=(T,W,U),E={Etw,Eww,Etu},分别表示图中的节点和边,T={t1,t2,t3,…,tn}表示一组源推文,n为源推文的数量,W={w1,w2,w3,…,wW}表示源推文中包含的词,U={u1,u2,u3,…,uU}表示社交媒体中发布或者转发新闻的用户.Etw、Eww、Etu分别表示推文-词、词-词、推文-用户之间的边.
目标是学习一个函数p(l|ti,G;θ)来确定推文ti的标签概率,其中l和θ分别表示要学习的标签和模型的参数.
3 基于异质图卷积注意力的假新闻检测
本文提出异质图卷积注意力模型解决社交媒体上的假新闻检测问题,如图2所示,该框架包括子图卷积层、子图注意力网络和子图间注意力网络,子图卷积层通过图卷积神经网络[25]提取节点的高阶表示特征,子图注意力网络[26]利用图注意力网络的注意力机制捕获节点的全局关系信息,子图间注意力网络通过引入注意力机制学习不同子图的权重,并融合两个子图中的新闻表示以进行假新闻检测.本节将详细介绍子图卷积层、两个子图注意力网络以及两者之间的交互.

图2 HGCAN模型架构图Fig.2 Overall framework of the model HGCAN
3.1 子图卷积层
在构建的推文-词-用户异质图中,推文节点和用户节点属于不同类型的节点,为了更好地提取节点的高阶表示特征,设计推文-用户节点对图卷积层,该图卷积层通过在相邻节点之间传递和聚合消息来学习节点表示,通过逐层传播,很方便的处理高阶邻居关系.具体来说,给定图G以及特征矩阵X={XT,XU},一个通用的多层图卷积模型f(G,A)可以定义为:
(4)
(5)
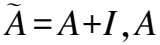
3.2 子图注意力网络
对于特定的节点来说,子图中每个节点的邻居对于学习节点特征嵌入具有不同的重要性,受到注意力网络[26]的启发,本文将注意力机制引入图节点学习过程中,在子图注意力网络中,利用注意力机制学习每个节点的邻居节点的重要性,并合并所有邻居节点的表示,得到每个节点的特征表示.
在构建的推文-词-用户异质图中,词集W的特征表示为XW={xw1,xw2,xw3,…,xwW},xwi∈RN,其中xwi是词wi的词嵌入向量,N是词嵌入向量的维度.推文集T的特征表示为XT={xt1,xt2,xt3,…,xtT},xti∈RN,其中每条推文ti的表示xti由包含的单词表示的平均值计算得到,即xti=1/|ti|∑wj∈tixwj.用户集U的特征表示为XU={xu1,xu2,xu3,…,xuU},xui∈RD,其中每个用户ui的表示xui可以从用户行为数据中提取得到,D为用户特征向量的维度.在推文-用户异质子图中,推文节点和用户节点是两种不同类型的节点,其所在的特征空间也不同,为了将其投影到相同的特征空间,设计变换矩阵Mφt和Mφu将推文节点和用户节点的特征表示投影到同一个向量空间中,投影过程如下所示:
(6)
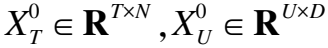
在推文-词子图中,推文节点和词节点特征类型空间一致,无需进行线性变换.因此其节点表示为Xtw={xt1,xt2,…,xtT,xw1,xw2,…,xwW},其中xti∈XT,xwi∈XW.然后利用自注意力机制[27]学习两个子图中节点之间的权重,给定子图中的节点对(i,j),自注意力机制f可以学习注意力系数eij,表示节点j对节点i的重要性.其中节点j是节点i的邻居节点,即j∈Ni(包括节点i自身).节点对之间的注意力系数eij计算如下:
ei,j=f(Wxi,Wxj),其中xi,xj∈Xtw(tu)
(7)
其中f由单层前馈神经网络实现,该网络由向量a参数化,并应用LeakyRelu[28]作为激活函数,W表示线性变换的共享权重矩阵.得到表示节点之间重要性的注意力系数之后,利用softmax函数将其进行归一化得到系数αi,j:
(8)
其中σ(·)表示LeakyRelu激活函数,a表示权重向量,T表示转置操作,表示连接操作.然后,将子图中节点i的邻居节点表示与其相应的系数进行聚合,以更新节点i的嵌入,如下所示:
(9)
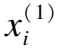
为了学习到更稳定的嵌入表示,将自注意力机制扩展到多头注意力机制[1].具体来说,对式(7)执行K次变换,并连接其学习表示,得到最终的输出表示:
(10)
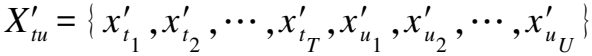
3.3 子图间注意力网络
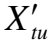
(11)
其中attentionsub表示计算子图间注意力的前馈神经网络,进一步的,将子图中所有节点的重要性进行平均,作为子图的重要性,具体计算如下:
(12)
其中Wsub表示权重矩阵,a为子图级的注意力向量,由两个子图所共享.在获得子图的重要性之后,利用softmax函数对子图的重要性进行归一化,两个子图的权重分别记为βtw和βtu:
(13)
最后,利用学习到的子图权重系数,融合子图中推文节点的表示,得到源推文的表示XT,如下所示:
XT={x1,x2,x3,…,xT}
(14)
(15)
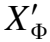
3.4 假新闻检测
现在已经得到了节点的表示和子图的重要性,将源推文的表示XT输入具有softmax归一化的单层前馈神经网络(FNN),从而通过以下公式预测源推文的类别概率分布:
p(l|ti,G;θ)=softmax(FNN(xi)),xi∈XR
(16)
为了训练模型的参数,使用交叉熵损失和正则化项作为模型的目标优化函数:
(17)
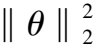
4 实 验
4.1 数据集
本文使用两个公开的数据集来评估模型的性能,即Twitter15和Twitter16[20],分别包含1490条和818条新闻.数据集中的每条新闻都被标记为非谣言(Non-Rumor,NR)、假谣言(False-Rumor,FR)、真谣言(True-Rumor,TR)和未经证实的谣言(Unverified-Rumor,UR).随机选择10%的数据作为验证集,其余数据按照3:1的比例划分为训练集和测试集.由于原始数据集中不包含用户个人资料信息,因此调用Twitter API接口爬取与新闻相关的所有用户的个人资料信息.两个数据集的详细数据信息如表1所示.

表1 数据集统计信息Table 1 Statistics information of the datasets
4.2 对比模型
实验将本文的基于异质图卷积注意力网络的假新闻检测模型与多种具有代表性的方法进行了比较,相关模型具体介绍如下:
DTR[29]:Zhao等人[29]提出一种基于决策树的排名模型,通过正则表达式搜索查询短语,根据从新闻中提取的集群进行排名来识别谣言.
DTC[18]:一种基于决策树的模型,利用特征工程提取推文的特征.
RFC[30]:一个随机森林分类器,利用谣言的时间、结构和语言信息特征进行谣言检测.
SVM-TS[19]:一种线性支持向量机(Support Vector Machines,SVM)分类器,应用时间序列信息整合社会背景信息.
SVM-HK[31]:基于图内核的混合SVM分类器,捕获新闻主题、情感等语义特征和高阶传播模式.
SVM-TK[20]:一种SVM分类器,通过传播树对微博帖子的传播进行建模,利用基于树的内核来计算传播树结构相似性以识别谣言.
SVM-RBF[32]:一种基于SVM的模型,具有基于传播的特征(Propagation-based features,RBF)内核,由各种新闻特征训练.
GRU-RNN[8]:基于带有门控递归单元GRU(Gate Recurrent Unit)的RNN对相关推文的顺序结构进行建模,通过学习新闻隐藏的特征表示,以捕获相关帖子的上下文信息随时间的变化.
BU-RvNN and TD-RvNN[9]:基于传播树进行自底向上和自顶向下遍历方向的递归神经网络,用于捕获新闻的传播线索和内容语义信息.
PPC[33]:将社交媒体上新闻的传播路径建模为多变量时间序列,通过循环神经网络RNN和卷积神经网络CNN组合的传播路径分类器来检测假新闻.
Bi-GCN[34]:基于新闻内容构建同质图,并利用双向图卷积网络模型来探索谣言自上而下的传播特征和自下而上的扩散特征.
PLAN[35]:一种基于帖子级的结构感知分层自注意力模型,通过学习带有传播结构的谣言嵌入向量,进行谣言检测.
PPA-WAE[36]:一种用于谣言嵌入和分类的轻量级传播路径聚合(PPA)神经网络,通过捕获谣言的语义信息,学习带有传播结构的谣言嵌入向量.
HGATRD[15]:基于源推文内容以及用户构建异质图注意力网络进行谣言检测.
4.3 实验结果
表2和表3分别是在Twitter15和Twitter16数据集上的实验结果,可以观察到本文所提模型HGCAN优于其他模型.具体来说,在两个数据集上,本文模型分别达到了92.6%和91.3%的准确率,和最佳对比模型相比,准确率分别提高了2.1%和2.6%,这表明本文所提模型能够捕捉假新闻的全局语义关系信息及传播结构信息,这将有助于进行假新闻检测.

表2 Twitter 15数据集实验结果Table 2 Experimental results of Twitter 15 dataset

表3 Twitter 16数据集实验结果Table 3 Experimental results of Twitter 16 dataset
传统的机器学习方法,即DTR、DTC、RFC、SVM-TS、SVM-HK、SVM-TK、SVM-RBF表现不佳,在这些方法中,SVM-TK效果最好,这是因为该模型利用了额外的时间特征和谣言的传播结构信息.
对于深度学习方法,普遍都比传统的机器学习方法效果好,这表明深度学习模型更能捕捉新闻的有效特征,这些模型中,在Twitter 15数据集上HGATRD模型效果最好,这也表明异质图提取信息的强大能力.在Twitter 16数据集上HGATRD和PPA-WAE模型效果相似,这是因为它们都捕获了源推文传播的语义关系和全局结构信息,而其他模型只捕获了该信息的一部分.
4.4 消融实验
为了进一步验证模型中各个子模块的贡献,本文设计了3个用于消融实验的对比模型,分别为HGCAN-GCN、HGCAN-tut_GAT、HGCAN-twt_GAT,其中:
HGCAN-GCN:去掉推文-用户子图中的GCN层;
HGCAN-tut_GAT:去掉推文-用户子图中的GAT层;
HGCAN-twt_GAT:去掉推文-词子图中的GAT层.
从表4和表5的实验结果中可以观察到,推文-词子图中的注意力层发挥的作用最大,去掉GAT之后,Twitter 15和Twitter 16数据集检测准确率分别下降了28.0%和27.2%;去掉推文-用户中的注意力层检测准确率分别下降了9.6%和9.8%;去掉GCN层之后准确率分别下降了3.3%和1.6%,这证明3个模块都对模型有促进作用,这也表明假新闻的文本内容对于检测假新闻是最重要的.

表4 Twitter 15数据集消融实验结果Table 4 Ablation experimental results of Twitter 15 dataset

表5 Twitter 16数据集消融实验结果Table 5 Ablation experimental results of Twitter 16 dataset
对于非谣言类(NR),在Twitter 15数据集中,推文-用户子图贡献比推文-词子图大,在F1值上,去掉推文-用户GAT层和去掉推文-词GAT层准确率分别下降了20.7%和8.0%,这表明非谣言,即真实新闻更可能与可信度高的用户进行交互.
4.5 参数分析
本文模型使用Adam[37]算法更新参数,学习率初始化为0.005,训练期间批大小为64,训练轮数为30.为了探究衰减率dropout和注意力机制头数heads对模型性能的影响,进行了参数实验并进行分析,图3为模型准确率Accuracy随dropout不同而变化情况,图4为模型准确率Accuracy随注意力头数变化的影响.可以看到在Twitter15数据集中,dropout值为0.3,注意力头数为7时准确率达到最优,在Twitter16数据集中,dropout值为0.6,注意力头数为2时准确率达到最优.
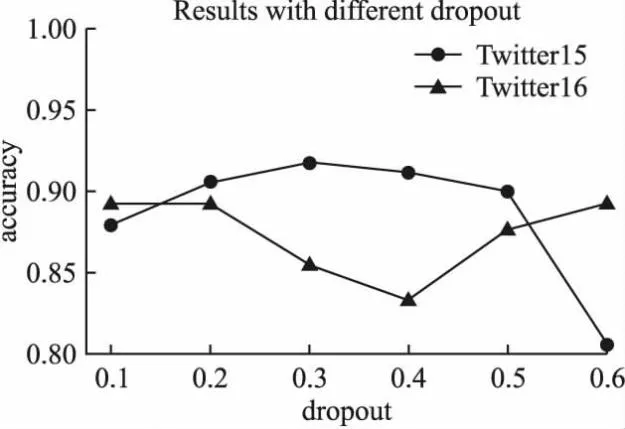
图3 参数dropout对准确率的影响Fig.3 Influence of parameter dropout on accuracy

图4 注意力头数对准确率的影响Fig.4 Influence of the number of attention heads on the accuracy
5 结束语
大多数现有假新闻检测方法都没有兼顾新闻文本内容的全局语义关系信息和传播结构信息,为了弥补这一研究缺陷,本文提出了基于异质图卷积注意力机制的假新闻检测模型HGCAN,该模型对新闻中的推文、词、用户构建异质图,并基于元路径分解为两个子图,从推文-词异质图中可以提取新闻文本内容的全局语义信息,推文-用户异质图中包含新闻传播的全局结构信息,所提模型在两个真实数据集上的实验证明了该模型在假新闻检测领域的有效性.
在未来的研究工作中,考虑将用户复杂的社交关系和用户可信度、兴趣爱好等属性信息融入到模型中,实现假新闻的早期检测,并将其应用于更复杂的假新闻检测任务,如进一步融入图片、视频等多模态新闻数据,构建多模态假新闻检测模型,以及细粒度假新闻检测分类任务.
