融合多模态生成和情景训练的环境无关手势识别
2024-02-27张子若张宏旺王佳昊
程 宇,周 瑞,张子若,罗 悦,张宏旺,王佳昊
(电子科技大学 信息与软件工程学院,成都 610054)
0 引 言
随着WiFi的广泛普及,基于WiFi的智能感知研究日益增加,给人们的日常生活带来便捷与舒适.例如,通过手势识别进行家电控制,可以实现智能家居等.使用无线信号进行室内感知,主要通过捕捉人体对室内空间无线信号的扰动,结合感知算法来判断人体的运动规律和轨迹,以达到在不侵犯隐私的情况下感知人体的行为.WiFi感知最常用的信号量是信道状态信息(Channel State Information,CSI).在环境不变的情况下,可以达到很高的识别准确率.但是当环境发生变化时,现有感知模型将无法泛化到新环境中.其原因主要是环境变化对无线信号传播影响较大,使得测试数据和训练数据有较大差别,从而导致原有基于学习方法建立的模型无法在新环境下正常识别.为了解决这个问题,现有方法主要包括两大类.一类从信号分析出发,通过布置多对收发器,利用信号处理技术提取环境无关手势特征[1-3],成本较高;另一类通过迁移学习实现跨域手势识别[4-6],大多采用半监督或无监督域适应(Domain Adaptation,DA),需要采集新环境数据参与模型训练.但在实际应用中,无法预先获得新环境中的数据.因此,需要一种无需新环境数据,即可自动泛化到新环境的方法.
为了实现环境无关手势识别,本文提出了一种基于样本生成和情景训练的域泛化(Domain Generalization,DG)方法,只需一对收发器进行数据采集,能够使现有模型在只有源域数据的情况下,很好地适应到新环境中.该方法采用幅值、相位和多普勒频谱3种模态数据,结合虚拟数据生成扩充数据量,通过情景训练[7]使模型从时间和空间维度提取环境无关手势特征,从而达到域泛化的效果.
本文主要贡献如下:
1)实现了环境无关手势识别.能够将手势识别模型泛化到新环境中,而无需目标域任何数据参与训练.
2)提出一种基于变分自编码器(Variational auto-encoder,VAE)并能够同时生成多模态虚拟数据的方法.该方法以幅值为基础,同时生成虚拟的幅值数据、相位数据和多普勒频谱数据.既能缓解数据量不足的问题,也能保证3种虚拟数据模态的一致性.
3)采用情景训练方式,通过主特征提取器、主分类器、域特征提取器、域分类器的交叉训练,使得主特征提取器获得提取域无关特征的能力,最后通过主分类器进行域无关手势识别.
4)采用时间空间双神经网络作为特征提取器.幅值数据输入时间特征提取器,相位数据和多普勒频谱数据输入空间特征提取器.时间特征提取器采用Conv1D结构,空间特征提取器采用ResNet[8]结构,分类器采用多层神经网络.
1 相关工作
解决环境无关无线感知,可以基于信号处理进行域无关特征提取.文献[1]通过分析WiFi信号中的多普勒频移,量化信号频率与动作的位置、方向和速度之间的关系.在此基础上,设计了一套位置无关手势识别系统.文献[2]提出了一种位置无关感知策略,其基本思想是将观测从传统的收发器视角转移到面向手的视角,提取与位置无关的特征.根据该策略,设计了一种位置无关特征,称为运动导航原语,并以此为基础构建手势识别系统.文献[3]提出了一种基于WiFi的零成本跨域手势识别系统Widar3.0,从无线信号中提取域无关手势特征.只需一次训练,就可以适应不同的环境.这类方法通常需要布置多对收发器.
解决环境无关无线感知,也可以基于域适应方法.域适应属于迁移学习,旨在利用源域数据解决具有相同任务的目标域学习问题.文献[4]提出的WiAG通过生成目标域虚拟样本来实现应对位置、朝向和环境动态变化的手势识别.文献[5]通过源域数据训练好一个模型,再利用少量目标域带标签数据对模型进行微调以达到跨域效果.文献[6]利用幅值,通过一个包含特征提取器、类别分类器和域判别器的对抗网络来实现环境无关活动识别.这些方法均需要目标域数据参与训练.
域泛化主要研究如何从若干个具有不同分布的源域数据集中学习一个泛化模型,使其在未知的目标域上取得较好的效果[9].目前对域泛化的研究多集中在图像识别领域.文献[7]通过情景训练,提升训练模型的领域鲁棒性.文献[10]利用元学习并结合Wasserstein自编码器生成大量虚拟数据来实现泛化.文献[11]利用对抗自编码器,学习一个泛化的隐空间特征表示,并利用最大均值差异(Max mean discrepancy,MMD)对不同域的特征分布进行对齐,以提取域无关特征.
本文采用域泛化方法解决基于WiFi的跨域手势识别问题.和上述方法的不同在于,相比于基于信号处理的方法,本方法只需要一对收发器;相比于基于域适应的方法,本方法不需要目标域数据.本方法先通过虚拟数据生成器,以源域幅值数据作为基础生成大量带标签多模态虚拟样本,再通过域无关特征提取网络和情景训练提取环境无关的手势特征,已获得对目标域数据的较高的识别精度.
2 环境无关手势识别方法
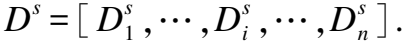
本方法的整体框架如图1所示,包含数据采集与预处理、多模态虚拟数据生成、域无关特征提取与分类识别3大部分.方法的输入包含幅值、相位和多普勒频谱3个模态,以获得从时间和空间维度描述的关于手势的完整信息.为增加数据量,同时使得数据尽可能包含不同环境信息,采用数据生成器生成虚拟数据.将幅值作为基础数据,在训练阶段学习同一动作的相位和多普勒频谱与幅值的对应关系,在生成阶段通过向中间特征添加同分布噪声,解码生成多模态虚拟样本.由单一幅值数据生成多模态数据是为了保证生成的多模态数据之间的一致性.特征提取与分类识别由主网络和域网络组成,通过情景训练提取域无关特征.主网络只有一个,包含主特征提取器和主分类器.每个源域有一个域网络,各包含一个域特征提取器和一个域分类器.特征提取器从时间和空间维度对三模态输入数据进行特征提取,通过主网络和域网络的情景训练,使得主网络获得域无关特征提取能力.在新环境中测试时,将新环境作为目标域,将其数据输入到主网络即可实现手势识别.
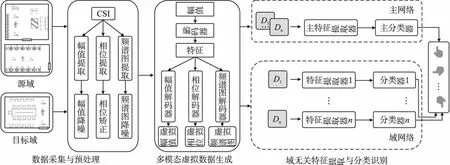
图1 总体框架图Fig.1 Framework of the proposed method
2.1 数据采集与预处理
通过无线设备采集的CSI数据可以表示为:
H=[H1,H2,…,Hi,…,HN]T,i∈[1,N]
(1)
N代表子载波数量.对于每一条子载波,其数据可以表示为:
Hi=|Hi|e(j∠Hi)
(2)
其中,|Hi|表示第i条子载波的幅值,∠Hi表示其相位.无线感知通过捕捉人体对无线信号的扰动,结合算法分析达到感知目的.从CSI的数据形式看,扰动通过幅值和相位的变化体现.此外,手势动作对信号的扰动,会影响接收信号的频率,产生多普勒效应,因此借助多普勒频谱也可以区分不同手势动作.本文结合幅值、相位和多普勒频谱进行手势识别.
2.2 多模态虚拟数据生成
只有当训练数据足够多且足够多样时,神经网络才能提取到环境无关的手势特征,从而提高模型在新环境的泛化能力.因此,为增加训练数据的多样性,进行虚拟数据生成.本文基于变分自编码器构造虚拟数据生成器,如图2所示,包含一个编码器和3个解码器,编码器由二维卷积和全连接神经网络构成,解码器为二维反卷积结构.在训练虚拟数据生成器的过程中,使编码器的输出特征服从正态分布,从而在数据生成时,向特征层添加同分布噪声不会改变特征分布,解码器才可以正常解码出对应的数据.
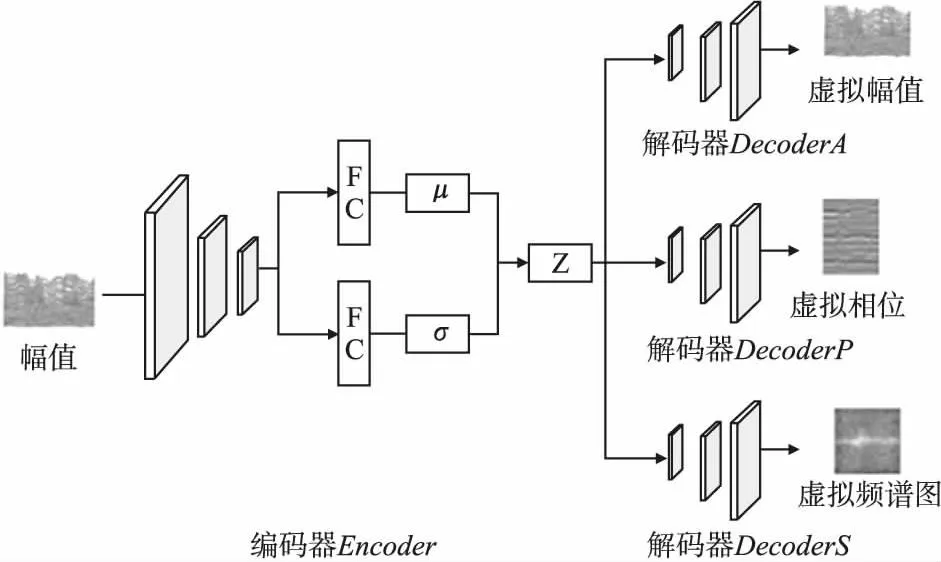
图2 虚拟数据生成器结构Fig.2 Structure of virtual data generator

Z=μ+σ⊙
(3)
其中μ为编码器输出的均值,σ为编码器输出的标准差,~N(0,I)为随机产生的正态分布数.将手势特征Z输入到3个解码器中分别获得幅值重构数据相位重构数据和频谱重构数据将重构数据分别与真实数据进行对比计算重构损失,以确保网络输出的重构数据不断接近真实数据.训练中,虚拟数据生成器的总损失函数定义为:
(4)
KLD=λ·KL[N(μ,σ),N(0,I)]
其中LA为幅值重构损失;LP为相位重构损失;LS为多普勒频谱重构损失;KLD为KL散度(Kullback-Leibler Divergence),确保中间特征Z不断接近目标正态分布.
选取幅值作为基础数据,是由于其包含丰富的手势动作引起的信号波动信息.在虚拟数据生成器中,编码器从幅值中提取准确的手势信息.3个解码器则基于编码器输出的手势信息,分别重构出对应的幅值、相位和多普勒频谱.通过反向传播优化网络,确保编码器和3个解码器协同工作.
(5)
本文方法需要生成带标签的虚拟数据.如果采用生成对抗网络(Generative Adversarial Networks,GAN)生成带标签的虚拟数据,则需要对每种手势类别训练一个GAN网络,这样会导致训练样本不足,同时难以区分虚拟数据的域.如果采用Cycle-GAN进行虚拟数据生成,则需要目标域数据,而本文方法在训练阶段没有任何目标域数据.因此本文基于变分自编码器进行虚拟数据生成.
2.3 域无关特征提取与手势分类识别
2.3.1 基本网络结构
手势识别模型的基本结构如图3所示,包括由时间空间双神经网络构成的特征提取器和由全连接神经网络构成的分类器.时间特征提取器是由4层卷积层构成的一维卷积神经网络,用于幅值数据的特征提取.空间特征提取器则是由ResNet 18[8]构成的二维卷积神经网络,用于相位数据和频谱数据的特征提取.分类器采用3层全连接神经网络,用于对手势特征进行分类.由于手势动作具有连贯性,手势动作对信号的连续扰动通过幅值的连续波动呈现,因此将幅值作为时序数据进行特征提取.相位图反映出的时序性较弱,采用二维卷积神经网络进行局部特征提取,并通过多个卷积层的多次卷积得到全局特征.频谱图反应出的是手势对信号频率的影响,在图中会出现不同位置的高亮区域,因此也通过二维卷积神经网络提取特征.手势识别时,幅值输入时间特征提取器,相位和频谱数据输入空间特征提取器,再将三者的特征进行融合,将融合特征输入到分类器进行手势识别.

图3 基本网络结构图Fig.3 Basic network structure
2.3.2 情景训练
为了能够提取域无关手势特征,采用情景训练方式[7].首先构建主网络和域网络,情景训练时,将域网络特征提取器提取到的特征输入到主网络分类器进行识别,将主网络特征提取器提取到的特征输入到域网络分类器识别.通过训练过程提升主网络的泛化性.整个训练过程分为两步:训练域网络和训练主网络.
1)训练域网络
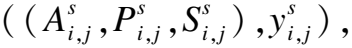
(6)
将相位和频谱分别输入到空间特征提取器,得到对应输出:
(7)
(8)
其中TExt_i和SExt_i分别代表第i个域网络的时间特征提取器和空间特征提取器.获取到3个模态的特征后,对它们进行融合,得到融合特征:
(9)
将融合特征输入到对应域网络分类器得到分类结果:
(10)
域网络的目标函数定义为:
(11)
其中CR(·)代表交叉熵损失函数.循环遍历全部源域,依次对每个域网络进行训练.
2)训练主网络

(12)

图4 主网络训练过程Fig.4 Main network training process
再将源域数据输入到对应的域网络特征提取器进行特征提取,将该特征输入到主网络分类器进行分类,计算损失:
(13)
以及将主网络特征提取器提取的特征输入到对应的域网络分类器进行分类,并计算损失:
(14)
在主网络训练中,域网络的参数已固定,反向传播优化网络参数时,只优化主网络参数.主网络训练的目标函数为:
(15)
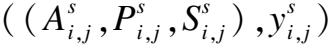
本文方法融合多模态虚拟数据生成和域无关特征提取实现域泛化.方法中使用到的情景训练为元学习的一种[9],其学习策略的目的是增加模型的域鲁棒性.其它元学习策略,如小样本学习,基于学习任务,在每个训练批次选取部分源域作为模拟目标域进行学习,经过不断迭代提升模型学习能力,让模型学会学习.本文解决的问题为域泛化问题,如何利用现有源域数据训练出具备鲁棒性的网络模型尤为重要,因此情景训练更为合适.
3 实验验证
3.1 实验设置
为了评估本文方法,将两台装有Intel WiFi Link 5300网卡的笔记本电脑分别作为发射器和接收器,采样频率设置为1000Hz,接收器和发射器均包含3根天线,共9条数据链路,每条数据链路包含30维数据,采集到的数据为270维CSI数据.由于每个手势的持续时间不一样,需要将手势数据进行统一,得到的幅值和相位数据维度均为(200,270),多普勒频谱的数据维度为(200,200).手势识别实验在4个房间进行,如图5所示.房间1大小为5米×5米,发射器和接收器的距离为1.6米;房间2大小为6米×8米,发射器和接收器的距离为2米;房间3大小为11.4米×6.8米,发射器和接收器的距离为2米;房间4大小为7.6米×5.8米,发射器和接收器的距离为2米.每个场景中6人参与实验,手势包括6个字母:L、O、V、S、W、Z,每个手势重复20次.
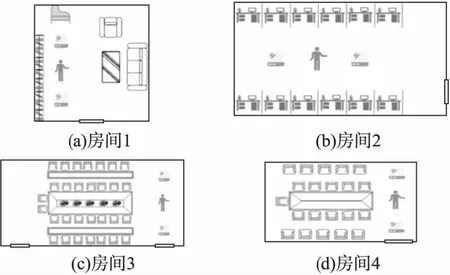
图5 实验场景Fig.5 Experimental scenes
3.2 实验结果
3.2.1 用户无关手势识别
分别在4个房间进行了两组实验.第1组用5人数据作为源域,另外1人作为新用户.依次将每人作为新用户进行测试,实验结果如图6(a)所示.以房间进行分组,在每个房间内进行新用户手势识别,每组里面的6根柱子为依次将每人作为新用户的识别准确率.平均识别精度达到83.3%.第2组实验选择4人的数据作为源域,另外2人作为新用户.实验中选取3组新用户组合进行测试,分别为P1-P2、P3-P4和P5-P6,实验结果如图6(b)所示.以房间进行分组,每组里面的3根柱子为依次选取P1-P2,P3-P4和P5-P6作为新用户的识别准确率.平均识别精度达到80.6%.实验中,新用户数据完全没有参与训练,仅仅作为测试使用.
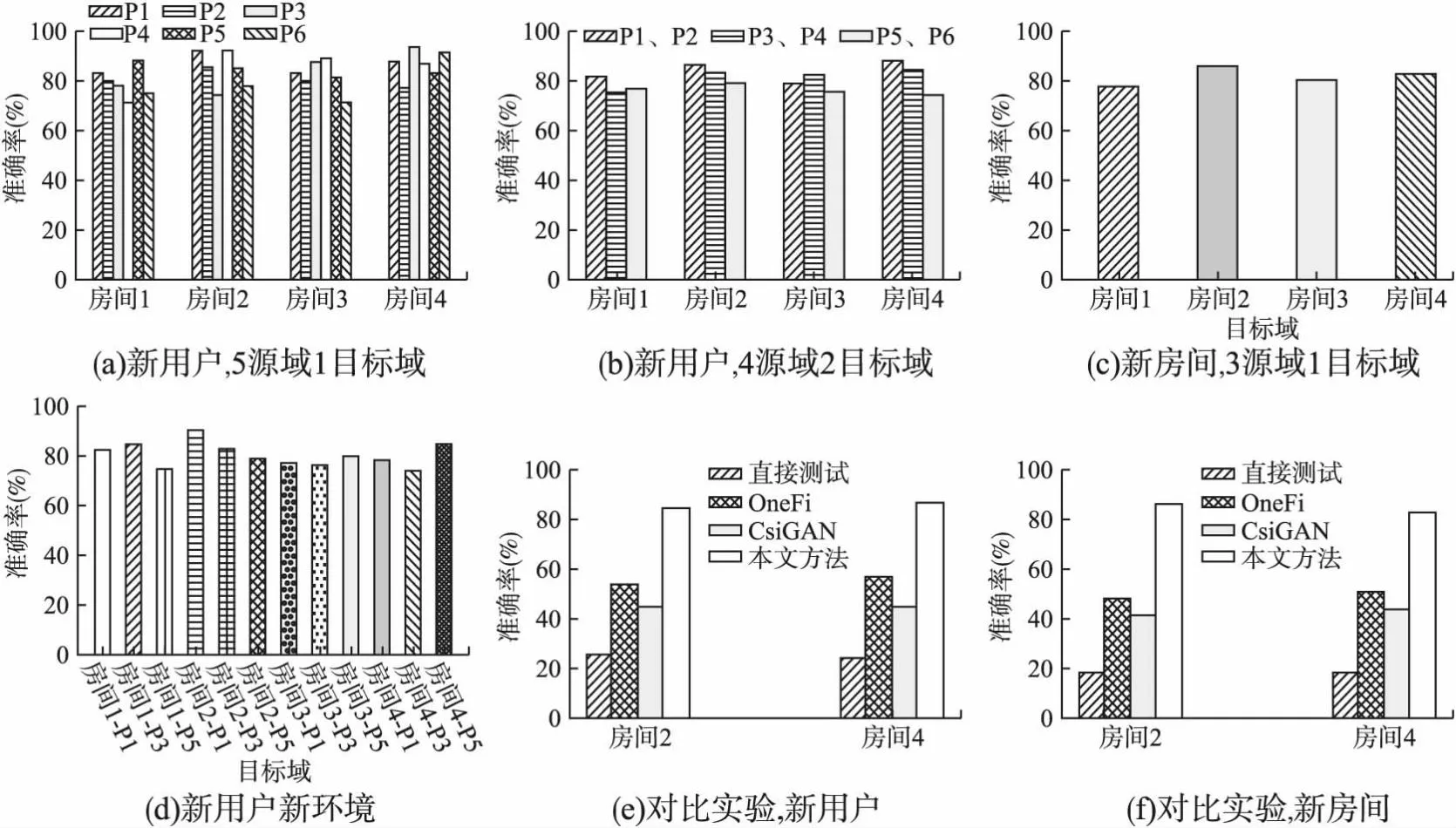
图6 手势识别结果Fig.6 Gesture recognition result set
3.2.2 房间无关手势识别
选取4个房间中的3个作为源域,另外 1个房间作为新环境.每个房间均包含6个人的完整手势数据.依次选取每个房间作为新环境,得到4组识别结果,平均达到81.7%的识别准确率,如图6(c)所示,每根柱子表示以当前房间作为新环境,其他房间作为源域的手势识别准确率.
3.2.3 用户房间均无关手势识别
选取3个房间和5人作为源域,另外1个房间和另外1人作为目标域.实验分别抽取P1、P3、P5和房间1、房间2、房间3、房间4进行组合作为目标域,平均识别精度为80.6%,如图6(d)所示,第一根柱子表示用户1在房间1作为目标域,用户2-6在房间2-4作为源域的精度,以此类推.
3.3 与业界方法对比
为证明本文方法的有效性,进行3组对比实验.对比方法分别为直接测试、CsiGAN和OneFi.CsiGAN[12]使用半监督生成对抗网络进行手势识别,通过目标域少量带标签数据和部分无标签数据生成大量虚拟数据,训练出鲁棒的分类网络.OneFi[13]基于多普勒频谱,结合虚拟数据生成提出一个one-shot识别框架.由于本文方法不需要目标域数据,因此在其他方法对比实验中,均没有使用目标域数据.图6(e)为选取房间2和房间4,进行新用户手势识别对比分析.每组结果里,每根柱子为不同方法依次选取用户1到用户6作为新用户的识别准确率的均值.图6(f)为选取房间2和房间4,进行新房间手势识别的对比分析,每根柱子表示不同方法选取当前房间作为新环境,其他3个房间作为源域的识别准确率.
本文识别准确率高于CsiGAN和OneFi的原因在于:本文方法是基于多模态的域泛化方法,而CsiGAN和OneFi提出的则是域适应方法,需要目标域数据参与模型训练,在不提供目标域数据的情况下,很难泛化到新域上.
3.4 方法分析
3.4.1 源域数量
为验证源域数量对实验结果的影响,本文在房间2进行用户无关实验.依次选取5、4、3、2、1个人的数据作为源域,其余1、2、3、4、5个人作为新用户.5组实验的识别准确率分别为84.6%、83%、79%、68%、41.75%,其中每个结果均为多次实验结果的平均值.实验结果表明,源域数量越多,新用户的识别结果越好,但训练代价越大.
3.4.2 基于幅值的多模态虚拟数据生成
为验证基于幅值生成多模态虚拟数据的方法,本文对比了基于各个模态分别生成虚拟数据的方法.将幅值、相位和多普勒频谱分别进行虚拟数据生成,在房间2和房间4的新用户手势识别准确率分别为73.8%和76.5%,明显低于基于幅值的多模态虚拟生成器.如果不进行虚拟数据生成,仅使用域无关特征提取与分类识别,在房间2的新用户手势识别准确率为77.6%,低于采用虚拟数据生成的识别精度.
3.4.3 网络结构分析
本文时间特征提取器采用Conv1D.为验证其有效性,将其替换为LSTM和BLSTM进行对比实验.采用LSTM作为时间特征提取器,在房间4的新用户手势识别准确率为86.1%,略低于Conv1D的86.9%.采用BLSTM作为时间特征提取器,在房间2的新用户手势识别准确率为84.48%,略低于Conv1D的84.6%.因此本文选择Conv1D.本文空间特征提取器采用ResNet18.为验证其有效性,将其替换为CNN进行对比实验.采用CNN作为空间特征提取器,在房间2的新用户手势识别准确率为81.2%,训练时间19分钟,测试时间0.16秒.采用ResNet18作为空间特征提取器,准确率为84.6%,训练时间40分钟,测试时间0.19秒.ResNet为预训练模型,具备更强的参数学习能力,因此泛化效果更优.本文算法运行在服务器上,采用ResNet的较长训练时间对于实际应用没有负担,而测试时间与CNN基本一致,因此在保证精度和测试实时性的情况下,采用ResNet结构.
4 结 论
为解决基于WiFi的手势识别对用户和环境的依赖,本文采用包含幅值、相位和多普勒频谱的多模态数据,通过多模态虚拟数据生成扩充数据集,通过情景训练提取出域无关手势特征,从而实现环境无关手势识别.为了使现有数据集尽可能包含不同环境和用户的信息,本文提出以幅值作为基础数据,基于变分自编码器生成虚拟幅值、虚拟相位和虚拟频谱,以保持生成数据的一致性,并扩充数据集.采用双神经网络特征提取器从时间和空间两个维度提取手势特征,通过构建主网络和域网络进行情景训练,使得主网络能够提取出域无关特征,实现在目标域无数据的情况下,主网络仍能精确识别出手势,即能够泛化到新用户和新环境中.实验表明,本方法对新用户的平均手势识别准确率达到83.3%,对新房间的平均手势识别准确率达到81.7%,对新房间新用户的平均手势识别准确率达到80.6%.,超过业界现有水平.
