密集行人检测方法研究
2024-02-24张忠民
吴 泽,张忠民
(哈尔滨工程大学 信息与通信工程学院, 哈尔滨 150010)
近年来,随着人工智能技术的飞速发展,行人检测技术被广泛应用于安全监控,自动驾驶,人群计数以及智能交通等诸多领域[1].目前,通用场景下的行人检测已经取得较好的检测效果,但在密集行人检测中,行人严重遮挡、小尺度行人检测难等问题还有较大的提升空间.
行人检测主要分为传统的行人检测算法和基于深度学习行人检测算法两个阶段.传统的行人检测算法首先通过人工进行特征提取,然后再设计和训练分类器对其进行分类.Papageorgiou等人[2]在2000年提出Harr特征并结合支持向量机(Support Vector Machine, SVM)实现了行人检测;Dalal等人[3]在2005年提出梯度方向直方图(Histogram of Oriented Gradient, HOG)特征描述算子提取行人特征;Felzenszwalb等人[4]在2010年提出可形变部件模型(deformable part model, DPM)改善卷积核大小加强行人信息特征提取.但是传统的行人检测算法特征提取能力有限且鲁棒性和泛化能力较差,存在精度低和漏检率高的问题,已基本不再使用.
目前,随着深度学习技术的飞速发展,基于深度学习的行人检测算法成为主流.Lei等人[5]在2018年提出基于行人区域信息设计多流区域提案网络模型,充分利用未遮挡信息进行特征提取,通过两级网络实现可见部分特征信息的提取和确定,最后使增强森林算法对所提取候选区域进行分类和预测;Liu等人[6]在2019年设计CSP检测模型,该模型放弃滑动窗口检测的方式,通过全卷积结构对行人中心坐标和尺度进行预测;冯婷婷等人[7]在2021年提出通过加入滤波器响应归一化 (Filter Response Normalization, FRN)和加强候选框聚类的方法对SSD[8]进行了改进,通过强化预处理的方式提高了网络特征提取的能力.然而上述行人检测模型仍存在一定的局限性:1)行人尺度大小不统一,在同一检测场景下大尺度行人检测效果良好,小尺度行人漏检严重; 2)行人相互遮挡严重导致损失函数优化性能较差,候选框尺寸回归不准确; 3)行人检测模型后处理算法未充分考虑行人重叠遮挡问题严重,丢弃机制过于严格.
为了解决上述问题, 以YOLOv5为基础模型进行改进,主要改进如下:1)网络特征融合阶段采用改进双向加权特征金字塔网络(Bidirectional Feature Pyramid Network,BIFPN)[9]结构替换原有的路径聚合网络(Path Aggregation Network,PANet)[10]结构; 2)采用EIOULoss[11]替换原回归损失函数CIOULoss[12];3)提出模型后处理算法两阈值非极大值抑制算法(Two threshold non-maximum suppression algorithm,T-NMS)替换原NMS[13]算法.改进后的Improved-YOLOv5算法在不同程度遮挡下都取得了较好的检测效果,极大降低了行人检测中的漏检率.
1 YOLOv5算法原理
YOLOv5是Ultralytics团队在2020年提出来的单阶段(One-stage)目标检测模型,该模型识别精度高,推理速度快,避免了两级序列中候选区域的重新计算.根据网络深度和宽度不同,分为V5-X、V5-L、V5-M、V5-S、共4个不同模型,其复杂度依次降低,用户可以根据不同的需求选择所需的网络结构来满足不同的检测任务.YOLOv5的网络结构主要由输入端input、特征提取层Backbone、特征融合层Neck和检测层Head共4部分构成,其中YOLOv5网络结构见图1.

图1 YOLOv5网络结构Figure 1 YOLOv5 network structure
输入端input首先对图像进行预处理和数据增强,将处理好的图像输入到特征提取骨干网络Backbone中,经过Conv和C3模块多次进行下采样以及SPPF的池化操作,实现网络的特征提取.特征融合层Neck采用PANet网络,相比于特征金字塔网络(Feature Pyramid Net,FPN)[14],充分利用了高层语义信息和底层定位信息,实现了特征信息的充分融合.检测层Head通过20×20、40×40、80×80三组不同尺寸的预测框对目标进行预测和分类,最后再通过NMS消除多余预测框,生成最终预测结果.
2 改进算法
2.1 特征融合网络改进
FPN是目前主流的特征融合网络,见图2(A).FPN结构仅仅融合了高层语义特征信息,没有充分利用低层的位置信息,只关注了全局而没有注意到局部.图2(B)PANet不仅拥有从上到下的融合路径,还添加了一条从下到上低层位置信息融合,使得网络具有更好的特征信息利用能力,但采用此种连接方式以后,网络开销较大,面对多尺度目标场景,小目标较多时,模型对小尺度目标关注度不够,带来检测效果的下降.基于这些问题,谷歌在2020推出的一种特征融合网络BiFPN,见图2(C),与PANet不同的是,BiFPN采用的双向特征融合不是简单的相加,引入了权重,不再平等地对待不同尺度的特征,可以更好平衡不同特征尺度的特征信息.在简单双向融合基础上,删除了只有一条输入边的节点,添加了输入特征层到输出特征层的残差连接,减少参数的情况下实现了更好的特征融合.

图2 各种特征金字塔结构Figure 2 Pyramid structure of various features
BiFPN采用快速归一化融合策略加权特征融合方式为每个特征添加一个额外的权重.快速归一化融合策略实现权重训练稳定,使权重大小保持在(0,1),充分发挥GPU的高速特性,如式(1)所示.
(1)
其中:i,j是输入的特征层数;Ii是输入的特征层矩阵;wi是网络学习权重;ε是一个很小的常数,防止分母为0.
基于BIFPN思想对原特征融合网络PANet进行改进,引入权重学习部分,考虑到网络本身对于大中目标检测效果较好,仅仅在原特征金字塔底层加入残差连接,见图3.增强对小目标的检测效果,减少网络开销.

图3 改进BIFPN模型Figure 3 Improved BIFPN model
2.2 损失函数改进
损失函数(Loss)衡量模型预测值与真实值差距,是神经网络模型训练的重要依据.一个合适的Loss,有利于提高模型的精度.一般来讲,Loss值越小则模型精度越高,鲁棒性也越好.YOLOv5使用CIoULoss计算边界框的回归损失,如式(2)所示.
(2)
其中:IoU(intersection over union)为预测框与真实框的交并比;b和bgt分别为预测框和真实框;ρ2(b,bgt)为预测框和真实框对角线中心的欧氏距离的平方;c2为预测框与真实框的最小包围框对角线距离的平方;wgt与w分别为真实框和预测框的宽;hgt与h分别为真实框和预测框的高;v为真实框和预测框的长宽比例一致性的参数;α为权重参数.
CIoULoss仅将预测框和真实框的宽高比例系数作为影响因子,没有考虑到宽和高的真实值,当预测框宽和高的比值等于真实框宽和高的比值时,会出现v=0的情况,出现预测框回归与真实框不符的情况.为了解决此问题,本文采用EIoULoss替代原有CIoULoss,EIoULoss提出采用预测框和真实框的宽高实际值来定义损失函数,其计算公式如式(3)所示.
(3)
2.3 后处理算法改进
在目标检测中,通常采用NMS算法和Soft NMS[15]算法对网络模型进行后处理和预测框的抑制,如式(4)、(5)所示.
(4)
(5)
其中:si为置信度分数;Nt为人工设定的阈值;M为遍历所有预测框后置信度分数最高的候选框;bi为除M以外的候选框;iou(M,bi)为最大置信度候选框与其他候选框IoU大小的.
NMS算法在通用行人场景下能够取得不错的检测效果,但在复杂场景下,往往因为行人之间距离过小导致出现很严重的漏检问题.Soft NMS算法处理对于IoU较高预测框没有选择直接丢弃,而是采用了一种柔性降低置信度的方法,降低了网络漏检的问题,但过多的候选框带来了运算资源几何级的数量增长,往往导致同一个目标被重复检测,在候选框过多的场景下检测效果往往不尽人意.基于此问题,对两种后处理算法进行改进,提出一种两阈值T-NMS算法,如式(6)所示.
(6)
其中:Nt1为抑制候选框的阈值;Nt2为丢弃候选框的阈值.经多次实验,Nt1选取0.4,Nt2选取0.85,该算法效果达到最佳.
相比于NMS算法和Soft NMS算法,T-NMS算法既能够减少Soft NMS大量运算资源的开销,又能降低由于NMS算法暴力丢弃带来的漏检情况,降低了网络在密集行人检测下的漏检率.
3 实验结果与分析
3.1 实验平台及数据集
本文实验平台为: Intel( R) Core( TM) i5-11600 kf CPU,16 G 内存;显卡 RTX 3060;Windows 10,64 位 操作系统;学习框架为pytorch 1.10.1;Cuda 11.3.
数据集为Citypersons[16],其中2 975张图片用于训练,500张和1 575张图片用于验证和测试,像素大小为2 048×1 024.由于作者并未公开验证集标注,本文选取500张验证集作为测试集,将训练集2 975按照0.85和0.15的比例划分训练集和验证集.根据行人之间相互遮挡后可见区域比例,将行人划分为几乎无遮挡Bare子集、通用Reasonble子集、部分遮挡Partial子集和严重遮挡Heavy子集,考察检测器在面对不同遮挡比例的性能,其划分参数指标见表1.

表1 CityPersons数据集可见度状况划分Table 1 Visibility status division of CityPersons data set
3.2 评价指标
为了更好地评价检测器的性能,本文采用目前行人检测算法主流的评价指标:漏检率的对数平均值(Log-average Missing Rate,MR-2).MR-2指的是采用每幅图误检数(False Positive Per Image,FPPI)为横坐标,漏检率(Missing Rate,MR)为纵坐标的曲线中,均匀选取[10-2,100]范围内的9个FPPI, 得到他们对应的9个logMR值,并对这几个纵坐标值进行平均计算,最后将其化成百分数的形式就得到MR-2.MR-2数值越低,则证明漏检率越低,检测器的性能越好,MR和MR-2的计算公式分别如式(7)、(8)所示.
(7)
(8)
其中:TP(True Positive)代表的是预测框中预测为真实际也是真的例子;FN(False Positive) 代表的是预测框预测为假实际为真的例子.
3.3 实验设置
本文采用SGD作为模型的优化器训练200个epoch;batch size设置为16;初始学习率设置为0.02,采用余弦退火算法,经过100个epoch后达到0.002;动量(momentum) 为0.937.
3.4 对比实验
为了验证改进各个模块对原始YOLOv5模型提升有效性,在CityPersons数据集上设置了1组消融实验.消融实验包括三个改进模块的对比:1)采用改进后的BIFPN替换原PANet;2)将原有CIoULoss替换为EIoULoss;3)对原有后处理算法进行改进.消融结果如表2所示,其中:BIFPN为采用改进BIFPN替换原有特征融合网络;EIoU为替换原有CIOULoss;T-NMS为对替换原NMS算法.

表2 消融实验结果/%Table 2 Ablation results/%
由表2可知,与原有YOLOv5算法相比,改进各个模块后,在不同子集下MR-2均有下降,尤其是遮挡最严重可见比例最小的Heavy部分,MR-2下降了4.2%,体现了改进模型在遮挡场景下的有效性,其检测效果对比见图4.

图4 检测效果对比图Figure 4 Comparison of detection results
为了验证本文所提出的Improved-YOLOv5效果和性能,设置了1组对比试验,将算法与其他主流的目标检测算法进行比较,其结果见表3.
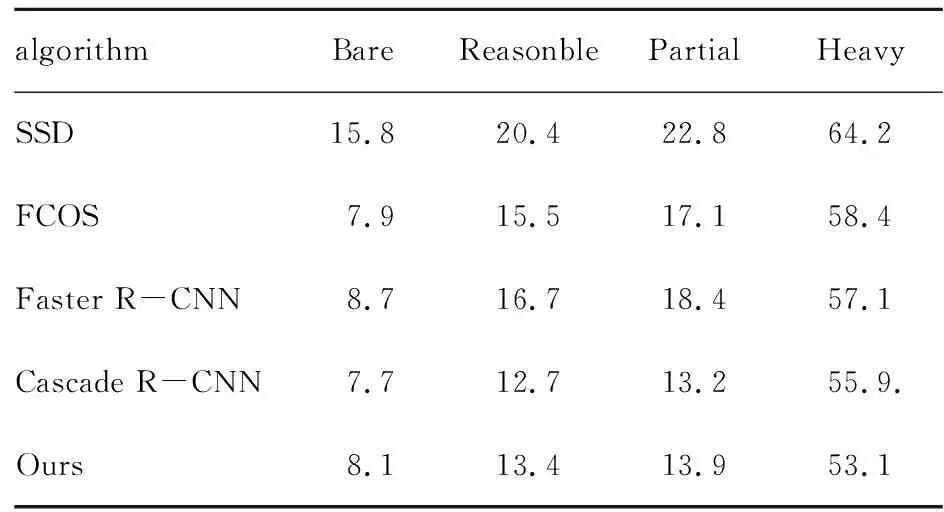
表3 对比实验结果MR-2/% Table 3 Comparative experimental results
由表3可知,改进算法在Heavy子集部分取得MR-2为53.1%最优效果,在Reasonble和Partial取得了次优效果,表明算法在遮挡严重场景下性能较好,确实具有较好性能.
4 结 语
本文提出一种新的密集行人检测算法Improved -YOLOv5,使用改进BIFPN替换原PANet网络;采用回归精度更优的EIOULoss替换原有CIOULoss;最后对后处理算法进行了双阈值的改进.经实验证明,在面对不同程度遮挡子集情况下,漏检率均有显著下降,尤其是Heavy子集部分降低了4.2%,达到了53.1%,证明了所改进模型的有效性.此外,研究发现,检测器出现头肩部与身体不适配的误检问题,对于行人可见部分的特征信息利用率还有待提高.未来将对行人可见信息和全身信息的利用方面进一步进行研究,继续降低漏检率和误检率.
