异构犹豫模糊偏好关系及其在群决策中的应用
2024-02-13冯雪耿生玲









摘 要:偏好关系在处理群决策问题时,能够充分发挥决策者的主观能动性,将不确定信息量化为数字等级或者语言等级,从而降低了主观臆断造成的决策误差。考虑犹豫偏好关系更能全面地表征决策者的偏好信息,本文研究了基于自信度的异构犹豫模糊偏好关系,并应用于群决策问题中。首先,分别定义了三种犹豫偏好关系的一致性,并建立三个优化模型以获得备选方案的权重向量。其次,构建群共识达成过程,并通过反馈机制为决策者提供调整方向,通过逐步调整偏好关系,达到满意的决策结果和群共识水平,建立群决策模型。最后,通过具体实例和对比分析验证了文中所建立的模型在复杂决策环境中的有效性和可行性。
关键词:异构犹豫偏好关系;自信水平;一致性;共识水平;群体决策
DOI:10.15938/j.jhust.2024.05.017
中图分类号: O159
文献标志码: A
文章编号: 1007-2683(2024)05-0149-10
Heterogeneous Hesitant Fuzzy Preference Relation and Its Application in Group Decision-making
FENG Xue1,2,3, GENG Shengling2,3
(1.College of Mathematics and Statics, Qinghai Minzu University, Xining 810007, China;
2.College of Computer Science and Technology, Qinghai Normal University, Xining 810016, China;
3.The State Key Laboratory of Tibetan Intelligent Information Processing and Application, Xining 810008, China)
Abstract:When dealing with group decision making problems, preference relations can give full play to the subjective initiative of decision makers and quantify uncertain information into numerical or linguistic levels, thus reducing the decision-making error caused by subjective assumptions. Considering that the hesitant preference relationship can more comprehensively represent the preference information of decision makers, we study the heterogeneous hesitant fuzzy preference relationship of confidence and apply it to group decision-making problems. Firstly, the consistency of three hesitant preference relationships is defined, and three optimization models are established to obtain the weight vector of alternatives. Secondly, the process of building group consensus is established, and feedback mechanisms are used to provide decision-makers with adjustment directions. By gradually adjusting preference relationships, satisfactory decision results and group consensus levels are achieved, and a group decision-making model is established. Finally, the effectiveness and feasibility of the model established in the article in complex decision-making environments were verified through specific examples and comparative analysis.
Keywords:heterogeneous hesitant preference relations; self-confidence levels; consistency ; consensus reaching process; group decision-making
0 引 言
决策是现代管理科学研究的重要问题[1-2]。 随着决策环境越来越复杂, 决策涉及更广泛的信息和更多的影响因素, 仅凭一人很难能实现科学决策。 因此, 群决策研究引起了广泛的关注。 群决策有利于汇集不同领域专家的集体智慧, 来提高决策结果的全面性和科学性[3]。
在群决策过程中,用偏好关系[4]表达决策者对备选方案的偏好非常有用。 目前, 已经提出了多种利用偏好关系解决群决策问题的方法[5-9]。 随着决策过程中不确定信息的增加, 相继提出模糊偏好关系[10]、区间模糊偏好关系[11]以及直觉模糊偏好关系[12]等。 2010年, Torra[13] 提出了犹豫模糊集的概念, 决策者可以利用犹豫模糊数来来表达评估中有可能的几个值,从而解决了决策过程中存在犹豫的情况。 在此基础上, Rodriguez等[14] 提出了犹豫模糊术语集, 丰富了语言表达。 随后, Xia等[15]提出犹豫模糊偏好关系和犹豫乘法偏好关系; Zhu等[16]提出了犹豫模糊语言偏好关系, 犹豫模糊环境下的决策问题得到了充分研究。 众所周知, 群决策问题中最重要的两个研究是偏好关系的一致性和群共识水平。 缺乏一致性将导致决策结果的不合理, 而共识水平越高, 群决策结果越有说服力[17-20]。 在以上研究中, 只允许决策者使用一种形式的偏好关系, 且未考虑专家所给偏好信息的自信水平。 然而, 在实际的群决策问题中, 由于决策者具有不同的教育背景、专业知识和实践经验, 不同的决策者使用自己擅长的偏好结构来表示偏好信息, 所得到的决策结果更准确合理[21]。 Liu等[22-23]研究了异构背景下的自信偏好关系, 提出了基于自信的乘法、加法和语言偏好关系, 并应用于群决策研究中。 2022年, Song等[24]提出了一种针对异质犹豫偏好关系群决策中交互式共识达成模型。 显然, 异质犹豫偏好关系为处理不确定偏好信息、提高决策质量提供了有效的工具。 然而, 现有的研究方法并未考虑偏好信息的自信水平, 同时应用范围有一定的局限性。
本文基于自信水平, 定义了自信异质犹豫偏好关系, 建立了三个优化模型, 调整偏好关系的一致性,并得到备选方案的权重向量。 同时, 考虑群共识水平, 建立了一个群决策模型。 基于备选方案的权重向量和个决策者的一致性水平, 构建群共识达成过程, 并通过反馈机制为决策者提供调整方向, 通过逐步调整偏好关系, 达到满意的决策结果和群共识水平。 最后,利用该模型解决了三江源自然保护区保护治理方案的选择问题, 进一步验证了文中所建模型在复杂决策环境中的适用性。
1 预备知识
1.1 2-元组语言表达式模型
设S={S1,S2,…,Sg}是一个具有奇数粒度的语言术语集,g+1是语言集S的粒度。2000年,Herrera和Martinez[25]提出了2-元组的语言表达模型(si,αi)。
定义1[25] 设β∈[0,g]是语言术语集S={S1,S2,…,Sg}上的符号聚合运算的结果。 那么, 在2-元组中与β的等效信息可通过以下函数获得:
Δ∶[0,g]→S×[-0.5,0.5)
Δ(β)=(si,α),(1)
其中i=round(β),α=β-i,此处round(·)为四舍五入算子。
定义2[25] 设S={S1,S2,…,Sg}是语言术语集,(si,αi)是2-元组, 那么存在函数Δ-1函定义如下:
Δ-1∶S×[-0.5,0.5)→[0,g]
Δ-1(si,α)=i+α(2)
此外, 根据定义1和定义2,S中的元素可以通过添加0作为符号转变, 将其转变为2-元语言表示, 即Δ(Si)=(Si,0)。
2-元语言集的排序和否算子定义如下:
1)设(sk,α)和(sl,γ)是两个2-元组则
(ⅰ)若klt;l,那么(sk,α)小于(sl,γ);
(ⅱ)若k=l则
(a)若α=γ,(sk,α)和(sl,γ)代表相同的信息;
(b)若αlt;γ,那么(sk,α)小于(sl,γ)。
2)2-元组否算子
Neg(si,α)=Δ(g-Δ-1(si,α))(3)
在实际问题中,常常出现S(h1)=S(h2)的情况, 通过得分函数无法判断出h1和h2的优劣, 为了进一步区分,Chen等[13]给出了偏差度的概念。
定义3[17] 给定犹豫模糊元h(x),称
σ-(h(x))=1l(hA(x))∑r∈hA(x)(ri-rj)212
为h(x)的偏差度。
对于两个犹豫模糊元的大小比较,Liao等[14]给出如下法则:
1)如果S(h1)gt;S(h2),则h1gt;h2;
2)如果S(h1)=S(h2), 则当σ-(h1)gt;σ-(h2)时,有h1lt;h2;当σ-(h1)=σ-(h2), 有h1~h2。
1.2 犹豫模糊偏好关系
定义4[15] 设X={X1,X2,…,Xn}为备选项集, 则H=(hij)n×n为犹豫模糊偏好关系(HFPRs), 其中hij={rσ(l)ij|l=1,2,…,#hij}是犹豫模糊元(#hij表示hij中元素的数量);rσ(l)ij表示hij中的第l个元素; hij表示备选项Xi对Xj的可能偏好程度, 且满足:
rσ(l)ijlt;rσ(l+1)ij,l=1,2,…,#hij-1
rσ(l)ij+rσ(hij-l+1)ji=1,l=1,2,…,#hij
#hij=#hji
rii=0.5(4)
定义5[15] 设X={X1,X2,…,Xn}是备选项集, 则H=(hij)n×n为犹豫乘性偏好关系(HMPRs),其中hij={rσ(l)ij|l=1,2,…,#hij}是犹豫模糊元(#hij表示hij中元素的数量); rσ(l)ij表示hij中的第l个元素; hij表示备选项Xi对Xj的可能偏好程度, 且满足:
rσ(l)ij=19,9,l=1,2,…,#hij-1
rσ(l)ij·rσ(hij-l+1)ji=1,l=1,2,…,#hij
#hij=#hji
rii=1(5)
1.3 自信水平
为了让决策者能够用语言方式描述自信水平, 我们使用语言自信术语集SSL={l0,l1,…,lg}, 例如:
SSL={l0=极度差,l1=非常差,l2=差,l3=略差,l4=中度,l5=稍好,l6=好,l7=非常好,l8=极度好}
决策者可使用简单的术语li∈SSL来描述自信水平偏好值。
定义6[26] 设X={X1,X2,…,Xn}是备选项集,则X上基于自信的乘法偏好关系定义为A*=((aij,Sij))n×n, 其元素有两个分量, 第1个元素aij∈19,9表示备选项Xi对Xj的偏好程度, 第2个元素表示Sij∈SSL与第1个分量相关的自信水平, 且满足以下条件:
aijaji=1,aii=1,Sij=Sji,Sii=lg(6)
2 基于自信的偏好关系及其一致性
定义7 设有限备选项集X上基于自信的犹豫模糊偏好关系H*=((hij,Sij))n×n,其中(hij,Sij)={(h(s)ij,S(s)ij)|s=1,2,…,#hij}是自信犹豫模糊元(#hij表示(hij,Sij)中元素的数量);(s)表示(hij,Sij)中的第s个元素, 它有两个分量, 第1个元素hij表示备选项Xi对Xj的可能偏好程度, 第2个元素Sij∈SSL表示与第一个分量相关的自信水平, 且满足:
h(s)ij+h(#hij-s+1)ji=1,s=1,2,…,#hij-1
hij∈[0,1],hii=0.5,i,j=1,2,…,n
Sij=Sji,Sii=lg
#hij=#hji(7)
定义8 设有限备选项集X上基于自信的犹豫乘法偏好关系P*=((pij,Sij))n×n,其中(pij,Sij)={(p(s)ij,S(s)ij)|s=1,2,…,#pij}是自信犹豫模糊元(#pij表示(pij,Sij)中元素的数量);(s)表示(pij,Sij)中的第s个元素, 它有两个分量, 第1个元素pij表示备选项Xi对Xj的可能偏好程度, 第2个元素Sij∈SSL表示与第一个分量相关的自信水平, 且满足:
p(s)ij·p(#pij-s+1)ji=1,s=1,2,…,#pij-1
pij∈19,9,pii=1,i,j=1,2,…,n
Sij=Sji,Sii=lg
#pij=#pji(8)
定义9 设有限备选项集X上基于自信的犹豫模糊语言偏好关系R*=((rij,Sij))n×n, 其中(rij,Sij)={(r(s)ij,S(s)ij)|s=1,2,…,#rij}是自信犹豫模糊元(#rij表示(rij,Sij)中元素的数量),它有两个分量, 第1个元素rij表示备选项Xi对Xj的可能偏好程度, 第2个元素Sij∈SSL表示与第1个分量相关的自信水平, 且满足:
Δ-1(Δ(r(s)ij)+Δ(r(s)ji))=g,s=1,2,…,#rij-1
r(s)ijlt;r(s+1)ij,S(s+1)jilt;S(s)ji,i,j=1,2,…,n
Sij=Sji,Sii=lg
#rij=#rji(9)
其中:(s)表示(rij,Sij)中的第s个元素; r(s)ij∈SSL={l0,l1,…,lg}。
下面, 我们讨论上述三种偏好关系的一致性。
定义10 设H*=((hij,Sij))n×n是具有自信水平的犹豫模糊偏好关系,
则在自信水平Sij∈SSL上,若
0.5(ωi-ωj)+0.5=h(1)ij或h(2)ij或…或h(#hij)ij(10)
则H*是加性一致的基于自信的犹豫模糊偏好关系, 其中ω=(ω1,ω2,…,ωn)T表示H*的优先权重向量, ∑ni=1ωi=1,ωi≥0,i,j=1,2,…,n。
定义11 设P*=((pij,Sij))n×n是具有自信水平的犹豫乘法偏好关系, 则在自信水平Sij∈SSL上,若ωiωj=p(1)ij或p(2)ij或…或p(#pij)ij(11)
则P*是乘性一致的基于自信的犹豫乘法偏好关系,其中ω=(ω1,ω2,…,ωn)T表示P*的优先权重向量,∑ni=1ωi=1,ωi≥0,i,j=1,2,…,n。
定义12 设R*=((rij,Sij))n×n是具有自信水平的犹豫模糊语言偏好关系, 则在自信水平Sij∈SSL上,若
gn2(ωi-ωj)+g2=Δ-1(r(1)ij)或…或Δ-1(r(#rij)ij)(12)
则R*是加性一致的基于自信的犹豫模糊语言偏好关系, 其中ω=(ω1,ω2,…,ωn)T表示R*的优先权重向量,∑ni=1ωi=1,ωi≥0,i,j=1,2,…,n。
3 异构犹豫模糊偏好关系群决策问题
设X={X1,X2,…,Xn}是n个备选方案的有限集, E={e1,e2,…,em}是由m个专家构成的有限决策者集合。 由于每个决策者都有自己的想法、态度、动机和个性, 所以很自然地, 不同的决策者会以不同形式的偏好关系表达他们对备选方案的偏好, 因此, 决策者可以使用犹豫模糊偏好关系、犹豫乘法偏好关系和犹豫模糊语言偏好关系来表达他们对备选项的偏好信息。
不失一般性,设EH*={e1,e2,…,em1},EP*={em1+1,em1+2,…,em2},ER*={em2+1,em2+2,…,em}是决策者集E={e1,e2,…,em}的3个子集, 分别表示决策者的偏好信息表示为基于自信水平的犹豫模糊偏好关系, 基于自信水平的犹豫乘法偏好关系, 基于自信水平的犹豫模糊语言偏好关系。 此外,ωc=(ωc1,ωc2,…,ωcn)T表示备选项X={X1,X2,…,Xn}的优先权重向量。 群决策问题研究将经历两个阶段: 选择阶段和共识达成过程。
3.1 选择阶段
在此阶段中, 我们首先通过建立3个模型, 得到个体优先权重向量, 再通过IOWA算子得到群优先权重向量。
3.1.1 获得个体优先权重向量
根据异构犹豫偏好关系的一致性, 建立了3个偏差最小的优化模型, 得到在异构犹豫偏好关系条件下的个体优先权重向量。 下面, 我们将讨论以下3个情况。
1)ek∈EH*(k=1,2,...,m1)
对于基于自信的犹豫模糊偏好关系H*=((hij,Sij))n×n,设δ(h(s)ij)=h(1)ij或h(2)ij或…或h(#hij)ij, 则式(10)可以写成
0.5(ωi-ωj)+0.5-δ(h(s)ij)=0(13)
为了得到最优权重向量, 我们设总偏差值为εkij, 使得εkij=|0.5(ωi-ωj)+0.5-δ(h(s)ij)|最小, 建立下面模型:
minεkij
s.t.
∑nt=1ωkt=1,0≤ωki,ωkj≤1,i,j=1,2,…,n(14)
当偏差εkij处于Skij(Skij∈SSL)的自信水平时, 可以引入下面信息偏差。
Zkij=|Δ-1(Skij)|εkij,k=1,2,…,m;i,j=1,2,…,n(15)
在等式(15)中, 自信Skij的水平确定误差εkij的放大倍数, 其值越大, 放大率越大, εkij的误差越大。
又因为
|0.5(ωj-ωi)+0.5-δ(h(s)ji)|=|0.5(ωi-ωj)+0.5-δ(h(s)ij)|,因此, 模型(14)可以转化为
minZkij
s.t.
∑nt=1ωkt=1,0≤ωki,ωkj≤1
Zkij-Δ-1(Skij)εkij≥0
Zkij+Δ-1(Skij)εkij≥0
i,j=1,2,…,n,jgt;i(16)
此外,因为δ(h(s)ij)=h(1)ij或h(2)ij或…或h(#hij)ij,设t(s)ij,k=0或1, 且∑#hij,ks=1t(s)ij,k=1, 则δ(h(s)ij)=∑#hij,ks=1t(s)ij,kh(s)ij,k.模型(16)可以转化为
minZkij
s.t.
0.5(ωki-ωkj)+0.5-∑#hij,ks=1t(s)ij,kh(s)ij,k-εkij=0
∑ni=1ωki=1,i=1,2,…,n
ωki≥0,i=1,2,…,n
∑#h(s)ijs=1t(s)ij,k=1,i,j=1,2,…,n,jgt;i,k=1,2,…,m1
t(s)ij,k=0或1,i,j=1,2,…,n,jgt;i,k=1,2,…,m1
Zkij-Δ-1(Skij)εkij≥0,i,j=1,2,…,n,jgt;i,k=1,2,…,m1(17)
基于偏差值|εkij|, 决策者ek的一致性指标Cl(ek)定义如下:
Cl(ek)=1-2∑n-1i=1∑ni=2,jgt;iZkijn(n-1)(18)
2)ek∈EP*(k=m1+1,m1+2,…,m2)
设δ(p(s)ij)=p(1)ij或p(2)ij或…或p(#pij)ij, 那么
ωiωj=p(1)ij或p(2)ij或…或p(#pij)ij, 可得ωiωj=δ(p(s)ij), 即ωi-ωj·δ(p(s)ij)=0。为了使εij=|ωi-ωj·δ(p(s)ij)|的总偏差最小化, 建立下面模型:
minZkij
s.t.
ωki-(∑#pij,ks=1t(s)ij,kp(s)ij,k)ωkj-εkij=0
∑ni=1ωki=1,ωki≥0,i=1,2,…,n
∑#h(s)ijs=1t(s)ij,k=1
i,j=1,2,…,n,jgt;i,k=m1+1,m1+2,…,m2
tkij=0或1
i,j=1,2,…,n,jgt;i,k=m1+1,m1+2,…,m2
Zkij-Δ-1(Skij)εkij≥0
i,j=1,2,…,n,jgt;i,k=m1+1,m1+2,…,m2(19)
基于偏差值|εkij|, 决策者ek的一致性指数Cl(ek)如下:
Cl(ek)=1-2∑n-1i=1∑ni=2,jgt;iZkijn(n-1)(20)
3)ek∈ER*(k=m2+1,m2+2,…,m)
设δ(Δ-1(r(s)ij))=Δ-1(r(1)ij)或Δ-1(r(s)ij)或…或Δ-1(r(#rij)ij),那么gn2(ωi-ωj)+g2=δ(Δ-1(r(s)ij)),即
gn2(ωi-ωj)+g2-δ(Δ-1(r(s)ij))=0。 为了使总偏差最小化, 设εij=|gn2(ωi-ωj)+g2-δ(Δ-1(r(s)ij))|, 建立以下模型:
minZkij
s.t.
gn2(ωki-ωkj)+g2-∑#rij,ks=1t(s)ij,kΔ-1(r(s)ij,k)-εkij=0
∑ni=1ωki=1,ωki≥0,i=1,2,…,n
∑#h(s)ijs=1t(s)ij,k=1
i,j=1,2,…,n,jgt;i,k=m2+1,m2+2,…,m
tkij=0或1
i,j=1,2,…,n,jgt;i,k=m2+1,m2+2,…,m
Zkij-Δ-1(Skij)εkij≥0
i,j=1,2,…,n,jgt;i,k=m2+1,m2+2,…,m(21)
基于偏差值|εkij|,决策者ek的一致性指数Cl(ek)如下:
Cl(ek)=1-2∑n-1i=1∑ni=2,jgt;iZkijgn(n-1)(22)
3.1.2 群优先权重向量
根据IOWA算子[27] ,结合一致性指数, 通过聚合个体优先权重向量ω(k)=(ω(k)1,ω(k)2,…,ω(k)n)T(k=1,2,…,m)可以得到群优先权重向量ω(c)=(ω(c)1,ω(c)2,…,ω(c)n)T。 其中
ω(c)i=IOWAQc(ω(1)i,ω(2)i,…,ω(m)i)=
Φω(〈cl1,ω(1)i〉,〈cl2,ω(2)i〉,…,〈clm,ω(m)i〉)=
∑mτ=1λτω(τ)i(23)
clσ(τ-1)≥clσ(τ),λτ=Q(∑τk=1clσ(τ)T)-Q(∑τ-1k=1clσ(τ)T)
其中T=∑mk=1clσ(k), clσ(k)表示{cl1,cl2,…,clm}中从小到大排列后第k个值。
3.2 共识达成过程
3.2.1 群共识度
一般地, 异构群决策中的群共识度是度量个体优先权重向量与群优先权重向量之间的距离。基于此, 我们定义群共识度(GCD)如下:
定义13 设ω(k)表示个体优先权重向量,ω(c)表示群优先权重向量, 决策者ek的群共识度定义为
GCD(ek)=1-1n∑ni=1(ω(k)i-ω(c)i)2(24)
由上述定义可知, 所有决策者的群共识度为
GCD(e1,e2,…,em)=1m∑mk=1GCD(ek)(25)
显然,若GCD(ek)=1, 则GCD(e1,e2,…,em)=1, 可知个体决策与群体决策相一致; 否则, GCD(e1,e2,…,em)越大, 群共识度越高。
3.2.2 群共识度调整
本部分给出群共识度调整的方法, 主要是基于上述群共识度, 若个体决策与群体决策结果偏差较大, 则向决策者提供调整建议, 以调整其偏好, 最终提高群共识水平。
一般地, 给定阈值δ0, 若GCD(e1,e2,…,em)≥δ0,则群共识度可接受一致。 若GCD(e1,e2,…,em)lt;δ0,则需要调整的偏好GCD(ek)lt;δ0, 使其满足GCD(ek)≥δ0。
基于不同的偏好结构, 给出下面三种调整方法。
1)ek∈EH*(k=1,2,…,m1)
设H-*=((h-ij,S-ij))n×n, 其中
(h-ij,S-ij)={(h-(s)ij,S-(s)ij)|s=1,2,…,#hij}, 则
(h-(s)ij,S-(s)ij)=
(hij,c,lg)|Δ-1(Sij)|εijgt;0.1,
(h(s)ij,S(s)ij)|Δ-1(Sij)|εij≤0.1,
(0.5,lg)i=j,
(1-h-(s)ji,S-(s)ij)igt;j(26)
其中hij,c=0.5(ωci-ωcj)+0.5,
εij=|0.5(ωi-ωj)+0.5-δ(h(s)ij)|, i,j=1,2,…,n
2)ek∈EP*(k=m1+1,m1+2,…,m2)
设P-*=((p-ij,S-ij))n×n, 其中
(p-ij,S-ij)={(p-(s)ij,S-(s)ij)|s=1,2,…,#pij}, 则
(p-(s)ij,S-(s)ij)=
(pij,c,lg)|Δ-1(Sij)|εijgt;0.1,
(p(s)ij,S(s)ij)|Δ-1(Sij)|εij≤0.1,
(0.5,lg)i=j,
(1-p-(s)ji,S-(s)ij)igt;j(27)
其中, pij,c=ωciωcj, εij=|ωi-ωj·δ(p(s)ij)|, i,j=1,2,…,n
3)ek∈ER*(k=m2+1,m2+2,…,m)
设R-*=((r-ij,S-ij))n×n, 其中
(r-ij,S-ij)={(r-(s)ij,S-(s)ij)|s=1,2,…,#rij}, 则
(p-(s)ij,S-(s)ij)=
(rij,c,lg)|Δ-1(Sij)|εijgt;0.1,
(r(s)ij,S(s)ij)|Δ-1(Sij)|εij≤0.1,
(Sg2,lg)i=j,
(1-Δ-1(r-(s)ji),S-(s)ij)igt;j(28)
其中rij,c=gn2(ωci-ωcj)+g2,
εij=gn2(ωi-ωj)+g2-δ(Δ-1(r(s)ij)), i,j=1,2,…,n
基于以上分析, 建立下面基于自信的异构犹豫偏好关系群共识达成算法。
算法1 基于自信的异构犹豫偏好关系共识达成过程。
输入 初始异构犹豫偏好关系H*k,P*k,R*k,GCD阈值δ0。
输出 调整后的异构犹豫偏好关系H-*k,P-*k,R-*k;最终的群优先级权重向量ω*。
步骤1 令θ=0,H*(θ)k=((h(θ)ij,k,S(θ)ij,k))n×n(k=1,2,…,m1),
P*(θ)k=((p(θ)ij,k,S(θ)ij,k))n×n(k=m1+1,m1+2,…,m2),
R*(θ)k=((r(θ)ij,k,S(θ)ij,k))n×n(k=m2+1,m2+2,…,m), 设置δ0的值。
步骤2 由模型(17)~(19)计算个体优先权重向量
ω(θ)k=(ω(θ)1,k,ω(θ)2,k,…,ω(θ)n,k)T(k=1,2,…,m)由(18)~(22)
式计算个体一致性水平cl(θ)k(k=1,2,…,m)。
步骤3 根据式(23), 由IOWA算子等到群优先权重向量ω(θ)c=(ω(θ)1,c,ω(θ)2,c,…,ω(θ)n,c)T。
步骤4 由式(25)计算可得GCD(e1,e2,…,em), 若GCD(e1,e2,…,em)≥δ0, 进入步骤6;否则, 进入下一步。
步骤5 根据式(26)~(28), 调整决策者所给偏好。 令θ=θ+1, 返回步骤2。
步骤6 设H-*k=H*(θ)k(k=1,2,…,m1),
P-*k=P*(θ)k(k=m1+1,m1+2,…,m2),
R-*k=R*(θ)k(k=m2+1,m2+2,…,m), 和ω*=ω*c
4 应用实例
三江源自然保护区是世界上海拔最高、面积最大、生物多样性最集中的高原湿地, 是我国最重要的水源涵养地。 近年来, 由于全球气温变暖, 冰川逐年萎缩, 导致湖泊湿地面积逐渐缩小甚至干涸。 同时, 疏于管理而引发的过度放牧, 乱采滥挖等不合理的人类活动, 也导致了水土流失加剧, 草地沙漠化严重, 虫鼠猖獗野生动物锐减, 三江源地区生态环境加速恶化。 考虑到三江源自然保护区的重要生态环境效益,从退耕还草(林), 全面禁猎, 禁采砂金, 休牧育草, 实施天然林和天然牧场保护工程等方面, 给出了4个保护治理方案。 现邀请相关专家多角度考虑, 从所给4个方案中选择最优方案, 开展三江源自然保护区的保护治理工作。
由于专家组在做决策时, 受到时间限制、专业知识的局限等影响, 会存在有一定的犹豫性, 因此,使用异构犹豫偏好关系更符合实际情况。 此外, 为方便专家更准确地表达自己的偏好信息, 允许每个专家使用自己熟悉的表征方式来评价四种备选方案。假设专家e1采用基于自信的犹豫模糊偏好关系, 专家e2采用基于自信的犹豫乘法偏好关系, 专家e3采用基于自信的犹豫模糊语言偏好关系。 通过比较每一种备选方案, 3位专家给出了以下偏好关系。
H*=(0.5,l8)(0.4,l4)(0.6,l3)(0.8,l6)(0.9,l2)(0.5,l0)(0.7,l3)(0.8,l5)
(0.4,l3)(0.6,l4)(0.5,l8)(0.7,l2)(0.8,l6)(0.5,l7)
(0.1,l2)(0.2,l6)(0.2,l6)(0.3,l2)(0.5,l8)(0.4,l1)(0.7,l4)
(0.2,l5)(0.3,l3)(0.5,l0)(0.5,l7)(0.3,l4)(0.6,l1)(0.5,l8)
P*=(1,l8)(2,l4)(4,l3)(17,l0)(15,l1)(12,l7)(7,l2)(9,l1)
(14,l5)(12,l3)(1,l8)(6,l8)(14,l7)(13,l1)
(2,l7)(5,l1)(7,l0)(16,l8)(1,l8)(5,l5)(7,l2)
(19,l1)(17,l2)(3,l1)(4,l7)(17,l2)(15,l5)(1,l8)
R*=(S4,l8)(S1,l4)(S4,l4)(S4,l5)(S6,l2)(S6,l2)(S7,l1)
(S4,l4)(S7,l4)(S4,l8)(S6,l5)(S7,l3)(S2,l2)(S6,l3)(S8,l3)
(S2,l2)(S4,l5)(S1,l3)(S2,l5)(S4,l8)(S6,l8)
(S1,l1)(S2,l2)(S0,l3)(S2,l3)(S6,l2)(S2,l8)(S4,l8)
1)获得个体优先权重向量
根据模型(17)~(21), 建立相应的优化模型, 可计算个体优先权重向量如下:
ω(0)1=(0.1537,0.3613,0.3660,0.1190)T,
ω(0)2=(0.3915,0.3308,0.1712,0.1065)T,
ω(0)3=(0.2660,0.3191,0.2436,0.1713)T
再由(15)~(17)式, 计算3个专家ek(k=1,2,3)的一致性水平如下:
cl(0)(e1)=0.9537,cl(0)(e2)=0.9167, cl(0)(e3)=0.9096
2)获得群优先权重向量
在本文中, 利用Q函数Q(x)=x0.9实现IOWA算子。 由cl(0)(e1)=0.9537, cl(0)(e2)=0.9167, cl(0)(e3)=0.9096可得σ(1)=1,σ(2)=2,σ(3)=3。 然后, 根据Q(x)=x0.9得到3个决策者的权值如下:λ1=0.3764,λ2=0.3138,λ3=0.3098。
基于3个决策者的权重, 利用IOWA算子聚合得到群优先权重向量如下:
ω(c)=(0.2612,0.3181,0.2904,0.1303)T
3)共识达成过程
共识达成过程有以下两步:①群共识度量; ②反馈调整。 根据式(24), 可以计算得到3个决策者的共识水平如下:
GCD(e1)=0.9305,GCD(e2)=0.9106,GCD(e3)=0.9688
根据式(25), 3位专家的群共识水平为:
GCD(e1,e2,e3)=0.9366lt;δ0=0.95
调整决策者所给的偏好, 由模型(17)和(21)计算可得:
ω(1)1=(0.2057,0.3216,0.3274,0.1453)T,
ω(1)2=(0.3016,0.3008,0.2766,0.1210)T.
再由式(18)、(20)计算ek(k=1,2)的一致性水平: cl(1)(e1)=0.9252, cl(1)(e2)=0.9114。则σ(1)=1,σ(2)=2,σ(3)=3,得到3个决策者的权值如下:
λ1=0.3756,λ2=0.3027,λ3=0.3037
计算得到群优先权重向量:
ω(c)(1)=(0.2548,0.3142,0.2857,0.1454)T
3个决策者的共识水平:
GCD(e1)=0.9692,GCD(e2)=0.9726,GCD(e3)=0.9745
3位专家的群共识水平:
GCD(e1,e2,e3)=0.9721gt;δ0
经过调整后, 满足群共识要求, 最终群优先权重向量为:
ω*=ω(c)(1)=(0.2548,0.3142,0.2857,0.1454)T
可得备选项方案的优劣顺序为X2>X3>X1>X4。因此, X2是最佳方案。
5 分析比较
5.1 聚合算子比较
聚合算子是群决策问题中的常用工具, 它是聚合方法的形式化表示。1988年, Yager[27]提出了有序加权平均算子(OWA), 由于OWA算子具有许多良好的性质, 可以根据决策者对聚合参数的不同偏好来赋予权重, 被广泛应用于决策理论中。 1999年, Yager 和Filev[28] 进一步提出诱导有序加权平均算子(IOWA), 随后研究了IOWA算子的相关性质, 并将其应用于决策理论等领域中。
下面, 我们考虑有序加权平均(OWA)算子和诱导有序加权平均(IOWA)算子来聚合个体优先权重向量ω1,ω2,ω3, 并与我们的方法进行比较, 所得结果见表1和图1。 显然, 我们的方法和以上两种算子聚合后所得到的排序结果相同, 但3种方法所得到的群优先权重向量不同, 基于聚合算子方法所得到的优先权重向量更接近一些。 本文的方法, 考虑了群共识达成过程, 该模型更加科学合理。
5.2 与其他方法的比较
本节中, 我们将本文的方法与文[26]、[29]的相关研究比较分析。 具体的比较结果见表2。可以看出, 文[3]未考虑犹豫模糊环境下的决策问题, 文[7]只能处理基于数值类型的HHPRs的群决策问题, 而不能处理基于语言的偏好关系。 本文所提出的模型, 不仅可以处理模糊犹豫环境下含有语言的异构偏好关系, 同时考虑了群共识达成过程, 使决策结果更为大多数决策者所接受。 在共识达成过程中, 通过不断的调整, 专家可以看到逐渐调整达成共识水平, 这使得决策结果更容易被专家接受, 获得的结果更有说服力。 同时, 文中考虑多重自信水平定义了犹豫偏好关系, 称为基于自信的犹豫模糊偏好关系、
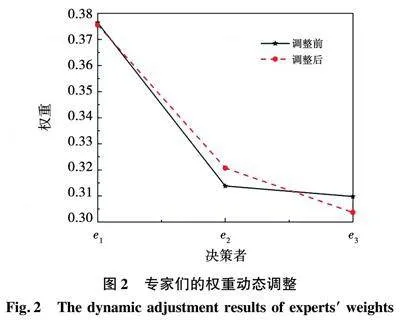
基于自信的犹豫乘法偏好关系和基于自信的犹豫模糊语言偏好关系。 此外,本文还提出了调整决策专家权重的方法, 根据动态调整后的偏好信息, 可以确定新的专家权重。 决策者动态调整如图2所示。 从图2中可以看出, 决策者的权重在偏好调整过程中变化不大。 这与文[26]、[29]中相关研究的决策过程中决策者的权重值不变基本相符。
5.3 本文的主要研究与贡献
随着社会的飞速发展, 决策问题的复杂性不断增加, 单个专家所得到的决策结果很难说服大家。 这种情况下, 群决策更具有科学性和合理性。 基于自信的异构犹豫偏好关系, 根据决策中的实际情况, 决策者能够更加灵活有效地表达对所比较对象的偏好信息。 显然, 文中提出的基于自信的异构犹豫偏好关系群决策模型, 扩展了现有异构犹豫偏好关系的群决策研究。
本研究重点建立了一个决策模型, 该模型基于自信异构犹豫偏好关系, 同时考虑群共识达成度。 通过该研究, 对决策理论和实践做出了一定贡献。
1)定义了3种基于自信的犹豫偏好关系, 及其一致性, 拓展了犹豫偏好关系的表达外延。
2)分别建立了3种处理异构犹豫偏好关系的优化模型。 通过相应模型, 可以很容易得到备选方案的优化权重。 进一步, 根据决策者的一致性程度, 可以得到决策者的权重。
3)考虑决策者的群共识度, 提出了一种反馈机制, 通过调整决策者的偏好信息, 逐步达到预定的群共识水平, 使得决策结果更加合理, 科学更具有说服力。
4)基于决策者提供的偏好信息的一致性水平, 构建了一种动态调整决策者权重的机制。
5)通过对三江源自然保护区保护治理方案选择这个具体实例的研究, 说明文中所提出的异构犹豫偏好关系群决策模型的适用性。 同时, 通过对比分析, 进一步阐明该决策模型的优点。
6 结 论
本文研究了基于自信度的异构犹豫模糊偏好关系, 并应用于群决策问题中。 首先, 分别定义了3种犹豫偏好关系的一致性, 并建立3个优化模型以获得备选方案的权重向量。 同时, 考虑群共识水平,建立了一个群决策模型。 基于备选方
案的权重向量和个体决策者的一致性水平, 构建群共识达成过程,并通过反馈机制为决策者提供调整方向, 通过逐步调整偏好关系, 达到满意的决策结果和群共识水平。 最后, 利用该模型解决了三江源自然保护区保护治理方案的选择问题, 进一步验证了本文所建立的模型在复杂决策环境中的适用性。
文中所考虑的异构犹豫偏好关系包含3种, 也可以考虑更多异构偏好结构, 建立群决策模型。 此外, 本文所提出的决策模型也可用于复杂的决策场景, 例如风险投资、紧急救援等。
参 考 文 献:
[1] BASILIO M P, PEREIRA V, COSTA H G, et al. A Systematic Review of The Applications of Multi-Criteria Decision Aid Methods[J]. Electronics, 2022, 11(11): 1720.
[2] PEREIRA D A D M, DOS S M, COSTA I P D A, et al. Multi-Criteria and Statistical Approach to Support the Outranking Analysis of the OECD Countries[J]. IEEE Access, 2022, 10: 69714.
[3] KIM S H, CHOI S H, KIM J K. An Interactive Procedure for Multiple Attribute Group Decision Making with Incomplete Information: Range-Based Approach[J]. European Journal of Operational Research, 1999, 118(1): 139.
[4] SAATY T L. Axiomatic Foundation of The Analytic Hierarchy Process[J]. Management Science, 1986, 32(7): 841.
[5] KACPRZYK J. Group Decision Making with a Fuzzy Linguistic Majority[J]. Fuzzy Sets and Systems, 1986, 18(2): 105.
[6] SONG Y M, LI G X. A Mathematical Programming Approach to Manage Group Decision Making with Incomplete Hesitant Fuzzy Linguistic Preference Relations[J]. Computers and Industrial Engineering, 2019, 135: 467.
[7] SONG Y, HU J. Large-Scale Group Decision Making with Multiple Stakeholders Based on Probabilistic Linguistic Preference Relation[J]. Applied Soft Computing, 2019, 80: 712.
[8] LI G X, KOU G, PENG Y. A Group Decision Making Model for Integrating Heterogeneous Information[J]. IEEE Transactions on Systems, Man and Cybernetics, 2018, 48(6): 982.
[9] LI Y, KOU G, LI G, et al. Multi-attribute Group Decision Making with Opinion Dynamics Based on Social Trust Network[J]. Information Fusion, 2021, 75: 102.
[10]ORLOVSKY S A. Decision-Making with a Fuzzy Preference Relation[J]. Fuzzy Sets and Systems, 1978, 1(3): 155.
[11]XU Z S. On Compatibility of Interval Fuzzy Preference Relations[J]. Fuzzy Optimization and Decision Making[J]. 2004, 3(3): 217.
[12]XU Zeshui. Intuitionistic Preference Relations and Their Application in Group Decision Making[J]. Information Sciences, 2007, 177(11): 2363.
[13]TORRA V. Hesitant Fuzzy Sets[J]. International Journal of Intelligent Systems, 2010, 25(6): 529.
[14]RODRIGUEZ R M, MARTINEZA L, HERRERA F. Hesitant Fuzzy Linguistic Term Sets for Decision Making[J]. IEEE Transactions on Fuzzy Systems, 2011, 20(1): 109.
[15]XIA Meimei, XU Zeshui. Managing Hesitant Information in GDM Problems Under Fuzzy and Multiplicative Preference Relations[J]. International Journal of Uncertainty Fuzziness and Knowledge-Based Systems, 2013, 21(6): 865.
[16]ZHU Bin, XU Zeshui, XU Jiuping. Deriving a Ranking From Hesitant Fuzzy Preference Relations Under Group Decision Making[J]. IEEE Transactions on Cybernetics, 2014, 44(8):1328.
[17]HE Yue, XU Zeshui. A Consensus Reaching Model for Hesitant Information with Different Preference Structures[J]. Knowledge-Based Systems, 2017, 135: 99.
[18]SONG Yongming, FENG Yuan. An Interactive Consensus Model for Group Decision-Making with Incomplete Multi-Granular 2-Tuple Fuzzy Linguistic Preference Relations[J]. Mathematical Problems in Engineering, 2018, 1: 8197414.
[19]JIN Feifei, LI Chang, LIU Jinpei, et al. Distribution Linguistic Fuzzy Group Decision Making Based on Consistency and Consensus Analysis[J]. Mathematics, 2021, 9(19): 2457.
[20]SONG Yongming, LI Guangxu, ERGU D J, et al. An Optimisation-Based Method to Conduct Consistency and Consensus in Group Decision Making Under Probabilistic Uncertain Linguistic Preference Relations[J]. Journal of the Operational Research Society, 2022, 73(4): 840.
[21]CHEN Xia, ZHANG Hengjie, DONG Yucheng. The Fusion Process with Heterogeneous Preference Structures in Group Decision Making: A Survey[J]. Information Fusion, 2015, 24: 72.
[22]LIU Wenqi, DONG Yucheng, CHICLANA F, et al. Group Decision-Making Based on Heterogeneous Preference Relations with Self-Confidence[J]. Fuzzy Optimization and Decision Making, 2017, 16(4): 429.
[23]LIU Wenqi, ZHANG Hengjie, CHEN Xia, et al. Managing Consensus and Self-Confidence in Multiplicative Preference Relations in Group Decision Making[J]. Knowledge-Based Systems, 2018, 162: 62.
[24]SONG Yongming. An Interactive Consensus Model in Group Decision Making with Heterogeneous Hesitant Preference Relations[J]. Axioms, 2022, 11(10): 517.
[25]HERRERA F, MARTíNEZ L. A 2-tuple Fuzzy Linguistic Representation Model for Computing with Words[J]. IEEE Transactions on Fuzzy Systems, 2000, 8(6): 746.
[26]LIU Wenqi, DONG Yucheng, FRANCISCO C, et al. Group Decision-Making Based on Heterogeneous Preference Relations with Self-Confidence[J]. Fuzzy Optimization and Decision Making, 2017, 16: 429.
[27]YAGER R R. On Ordered Weighted Averaging Aggregation Operators in Multi-criteria Decision Making[J]. IEEE Transactions on Systems, Man and Cybenetics, 1988, 18(1): 183.
[28]YAGER R R, FILEV D P. Induced Ordered Weighted Averaging Operators[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 1999, 29(2): 141.
[29]ZHANG, ZHEN, GUO Chonghui. Fusion of Heterogeneous Incomplete Hesitant Preference Relations in Group Decision Making[J]. International Journal of Computational Intelligence Systems, 2016, 9(2): 245.
(编辑:温泽宇)
基金项目: 国家自然科学基金(12261071,61862055,12371459);国家重点研发计划项目(2020YFC1523300);科技援青合作专项(2022-QY-203).
作者简介:冯 雪(1989—),女,博士,讲师.
通信作者:耿生玲(1970—),女,博士,教授,博士研究生导师,E-mail:geng_sl@126.com.
