基于轻量化深度迁移神经网络的电子元器件识别∗
2024-01-29夏玉果董天天
夏玉果,董天天,丁 晟
(江苏信息职业技术学院微电子学院,江苏 无锡 214153)
电子元器件是现代电子智能制造的基础,在电子产品的焊接、组装、检测等多个生产工序中必须进行元器件的识别。所谓电子元器件识别就是根据不同元器件的外形特性来判断其所属的元器件类别,随着电子信息技术的发展,电子元器件的种类和数量迅速增长,因此快速准确的元器件识别对于提高现代电子产品的生产效率具有非常重要的意义。
电子元器件的识别主要依据图像处理和模式识别的原理和方法。传统的识别方法是通过提取不同元器件的特征,再根据这些特征匹配进行类别判定,如杜思思等[1]提出的电子元器件自动分类的算法,对于有引脚的元器件的检测分类取得很好的结果。但是随着微电子技术发展,贴片元器件特别无引脚或短引脚元器件的大量使用,这种算法的弊端日益凸显。近年来,随着深度学习在机器学习领域不断的成功,人们提出了基于深度神经网络(Deep Neural Networks,DNN)的元器件识别算法,如陈翔等[2]提出的基于AlexNet 的电子元器件分类方法,在5 类常见的电子元器件数据集上取得不错的分类效果。陈文帅等[3]则利用目标检测算法对极性电子元器件类别与方向识别进行了研究,这些大大推进了元器件识别的研究。相对于传统的分类算法,深度学习算法能够自动学习不同元器件的特征,不需要再针对不同元器件选取不同的特征,降低了算法的复杂度。另一方面,深度学习算法在效果上大大提升了识别率,但同时也存在模型训练的计算量大、内存需求量大、对硬件设备要求高等缺点,由此导致模型移植到移动设备或嵌入式设备困难,无法满足实时运行需要。
针对以上问题,本文提出一种基于轻量化深度迁移网络的元器件识别方法。该方法首先以轻量化神经网络模型MobileNet 为基础,通过引入通道注意力机制和新的激活函数,构建基于MobileNetV3 的主干网络。其中通道注意力机制进一步对图片的关键特征进行加权,提升模型的分类能力。其次采用迁移学习(Transfer Learning,TF)算法,通过预训练模型实现模型参数迁移,并进行微调,进一步降低算法的参数量,并且避免了由于数据集小引起的过拟合现象,提升了算法的泛化能力。最后将此训练模型部署在树莓派系统中,实验表明,该算法能够准确识别出12 种常见的元器件,并能很好满足边缘端计算和运行的需要。
1 轻量化深度迁移神经网络的电子元器件识别算法
1.1 轻量化深度迁移神经网络的整体架构
以轻量化神经网络和迁移学习构建的模型结构如图1 所示,其中上半部分为ImageNet 上的预训练模型[4],主要完成迁移学习。下半部分为轻量化网络MobileNetV3 的模型结构,主要包括卷积层、block层、池化层以及注意力模块。
1.2 MobileNetV3 网络
MobileNet 系列模型是Google 团队提出的主要针对移动端或嵌入式设备的轻量级深层神经网络,与传统的卷积神经网络相比,MobileNet 在保证正确率的基础上,大大降低了模型参数和运算量,并具有延时低的特点。MobileNet 系列可分为MobileNetV1、V2 和V3 三种模型。
MobileNetV1[5]是在经典的卷积神经网络(Convolutional Neural Networks,CNN)网络结构基础上,将池化层、部分全连接层用卷积层来代替,并引入了深度可分离卷积。深度可分离卷积的核心思想是将标准卷积分为两步:第一是深度卷积(Depthwise),即对每个输入通道应用单通道的轻量化滤波器;第二是点卷积(Pointwise),负责计算输入通道的线性组合并构建新的特征。它使用更少的参数进行特征的学习,能够有效减少计算量和模型参数。
MobileNetV2[6-7]在MobileNetV1 的基础上,借鉴ResNet 的残差连接思想,提出倒残差结构,如图2 所示,该结构先使用点卷积进行特征升维,再使用3×3的深度卷积提取各通道的特征,最后使用点卷积进行特征降维。当步长为1 时,使用倒残差结构;当步长为2 时,使用串联结构。这样的结构使得网络允许更小的输入和输出维度,降低网络的计算量和参数量,提升梯度传播效率,使得网络表达能力更强。
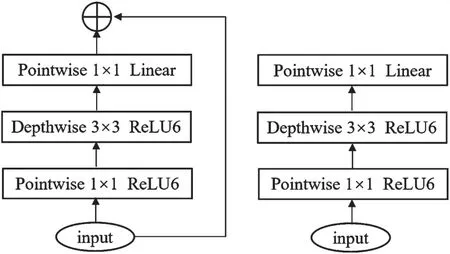
图2 MobileNetV2 中倒残差结构
1.2.1 注意力机制
注意力机制(Attention Mechanism,AM)已成为深度学习领域的研究热点,它通过模拟人脑机制,关注视觉内有突出特点的重要信息,忽略不重要的信息,从而进一步提升有效特征的区别性。在图像处理领域中常使用空间注意力(Spatial Attention)和通道注意力(Channel Attention)[9],根据轻量化网络的特点,这里引入通道注意力机制中的SE 网络模块(Squeeze and Excitation,SE)[10]。
通道注意力机制SE 是在特征通道维度上动态调整各通道的权重,加大对网络性能好的特征通道权重,减小对网络特性不好的特征通道权重,实现对通道权重的重新分配。它主要包含压缩(Squeeze)和激励(Excitation)两种操作,其中压缩操作如式(1)所示:
式中:zc为压缩操作结果,uc为输入特征,H、W分别为输入特征的高度和宽度。激励操作如式(2)所示:
式中:sc为激励操作结果,σ和δ分别表示激活函数Sigmoid 和ReLU(Rectified Linear Unit),经过以上操作后,通道注意力输出为激励操作输出产生的权重与特征图进行相乘,从而实现特征的加权,如式(3)所示:
先用较坚硬的石块回填槽孔,石块不宜太大;然后进行重新造孔。重新造孔进尺不宜太快,发现孔斜时应再次回填石块重复造孔。
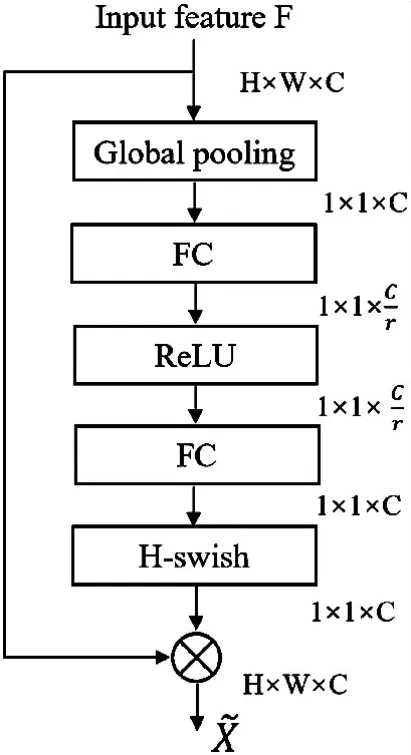
图3 通道注意力SE 模块结构图
在此结构中,首先对输入特征矩阵的每一个通道进行全局平均池化操作,然后通过两个全连接层得到输出的向量。其中第一个全连接层节点个数为特征矩阵通道数的四分之一,第二个全连接层的节点个数等于特征矩阵的通道数。最后,第二个全连接层输出结果是对特征矩阵的每一个通道赋予不同的权重,对于比较重要通道赋予较大的权重,反之较小,从而更加突出特征的区别性。其中第一个全连接层使用激活函数ReLU,第二个全连接层使用激活函数H-swish。
1.2.2 激活函数
激活函数是在人工神经网络神经元上运行的函数,主要负责神经元之间的信息映射。激活函数将非线性特性引入神经网络,从而增加神经网络模型的非线性因素,使得网络可以学习和理解更加复杂的事物。
在MobileNetV2 中使用的激活函数是swish,它具有非单调性、无下界、平滑的特点,在深层网络的效果优于传统的ReLU 函数,如式(4)所示:
由于swish 函数求导复杂,增大计算量,不利于量化,因此MobileNetV3 在swish 上进行改进,使用了一种新的激活函数H-swish[x],如式(5)所示:
1.3 迁移学习
迁移学习[11]是通过在已有领域中学习获取的知识,转移到新的相关领域中,以此来改进新的学习任务,并获得更好的学习效果。实践表明,迁移学习[12]在解决小样本学习问题上有较好的效果。本文将在ImageNet 数据集上训练得到的预训练模型迁移到电子元器件识别中,首先利用预训练模型对新的网络模型进行初始化,去掉最后的全连接层,作为特征提取,再在电子元器件数据库上进行训练,同时降低学习率,并对模型进行微调,即冻结所有层,只训练全连接层中的卷积层,并将网络的输出类别数改为电子元器件分类任务的12 类,最后得到电子元器件识别模型。通过采用迁移学习的MobileNetV3 网络模型,不仅加快模型的学习效率,而且进一步提升模型的泛化能力。本文迁移学习的流程如图4 所示。
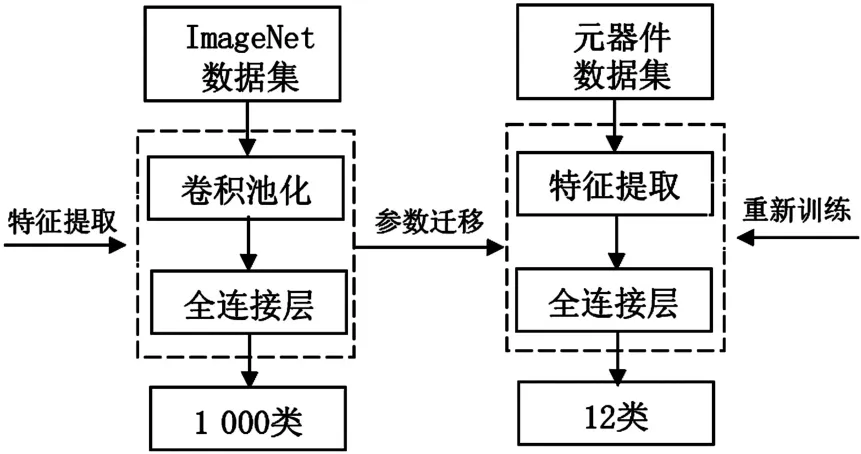
图4 迁移学习流程
2 实验结果
为了验证本文方法的有效性,在12 类常见的电子元器件数据集上进行实验,并将本文算法与其他深度学习模型的迁移学习算法进行对比。
2.1 数据集
目前,国内还没有公开发布的电子元器件数据库,本实验利用工业相机、人工拍摄和网络搜索等方式采集电子元器件图像并构建数据集,该数据集包括插件电阻器、贴片电阻器、插件电容器、贴片电容器、电解电容器、插件电感器、贴片电感器、插件二极管、贴片二极管、发光二极管、插件三极、贴片三极管等12 种常见的元器件,共计3 105 张,具体分布如图5 所示。在实验中,按8 ∶1 ∶1 的比例拆分成训练集、验证集和测试集,为了保证模型性能所需的大量样本数据,实验中对数据集进行增强处理[13],包括随机裁剪、翻转、缩放等方法进行预处理,以增加样本的多样性。

图5 电子元器件种类
2.2 实验设置
本实验操作系统为Windows 10,两块16G 显存NVIDIA GeForce GTX 2060 显卡,CPU 为Intel Core i7-7700K,Python 版本为3.8,深度学习框架为TensorFlow2.3。实验利用GPU 加快模型训练速度,选择Adam 作为模型参数优化器,损失函数选择交叉熵损失函数,学习率为0.000 1,训练周期为100 次,每批次训练的图像为16 张。
2.3 实验结果
2.3.1 考察迁移学习的效果
为了验证不同模型在采用迁移学习方法后的识别效果,这里选取典型的 VGG16、ResNet50、InceptionV3 和MobileNetV3 模型作对比实验,并选用TOP1 和TOP5 识别准确率作为评价指标,实验结果如表1 所示,其中TF 是迁移学习Transfer Learning 的简称。
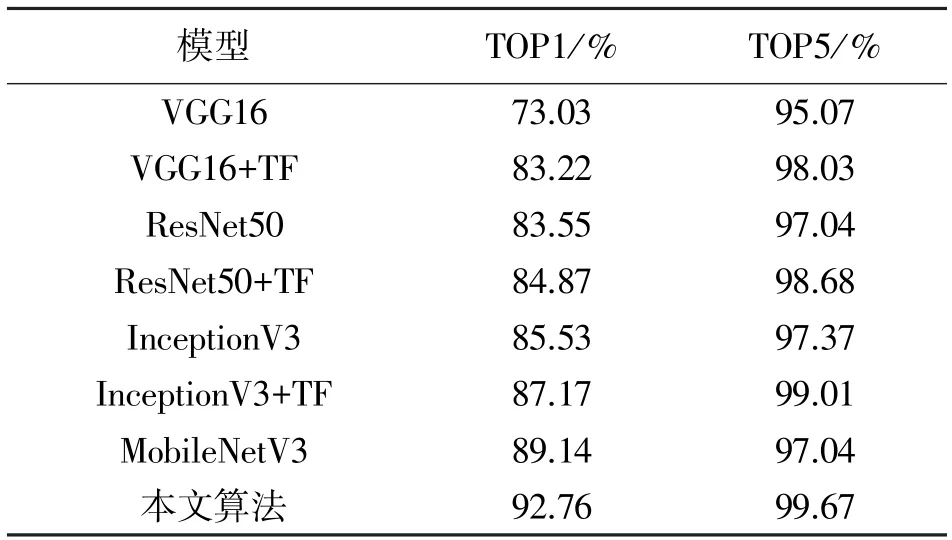
表1 不同模型的迁移学习结果
从表1 可以看出,这4 种模型在采用迁移学习算法后TOP1 和TOP5 的识别正确率均获得了提升,其中VGG19 模型提升幅度最大为10.19%,本文提出的MobileNetV3 的迁移学习算法提升了3.62%,说明采用迁移学习方法,可以进一步提高模型识别的准确率。另外,在训练中,这4 种模型的损失率稳步降低,准确率稳步提升,这表明采用迁移学习算法后模型的性能更加稳定,其中本文提出的算法表现最好。
2.3.2 考察不同模型的迁移特性
为了进一步考察不同模型在采用迁移学习后的特性,本实验选择VGG19、ResNet50、InceptionV3 和MobileNetV3 为实验对象,主要考察模型识别率、训练时间和模型参数量三个方面指标,实验结果如表2 所示。
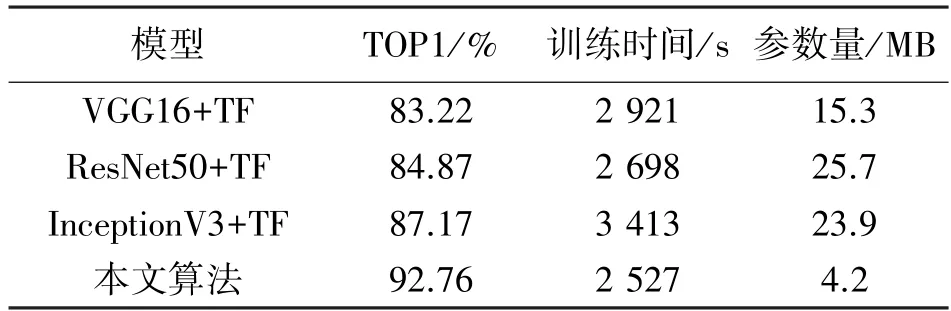
表2 不同模型的迁移特性
从表2 可以看出,本文提出的算法在TOP1 识别正确率、训练时间和模型参数量方面都取得了很好的结果,其中识别率远高于传统的VGG16 和Res-Net50 网络,虽然InceptionV3 网络在识别率上与本文提出算法相差不大,但是在模型训练时间和参数量上,本文提出的算法远远低于InceptionV3 网络,突出了轻量化的特点,为模型部署到移动端或嵌入式系统提供了条件。
2.3.3 考察轻量化系列网络的迁移特性
针对模型的部署和使用,将本文提出的算法与典型的轻量级网络MobileNetV1 和MobileNetV2 作对比实验,主要从识别率、模型大小和参数量三个方面考察,实验结果如表3 所示。

表3 轻量化网络迁移学习的实验结果
由表3 可以看出,本文提出的算法在TOP1 和TOP5 的识别准确率远高于传统的MobileNetV1 和MobileNetV2 网络,其中TOP1 准确率分别提高了3.94%、2.3%,Top5 准确率分别提高了0.66%、1.97%。在模型大小和参数量方面,本文提出的算法训练的模型介于MobileNetV1 和MobileNetV2 两者之间,这也为模型的部署提供了很好的基础。图6 给出了3 种轻量化深度迁移神经网络识别结果的混淆矩阵,从图中可以看出,相比于其他元器件,3 种模型均对插件电阻的识别率最高,其中本文提出算法的识别率为100%,而在元器件最低的识别率分布上,则表现得比较分散,这是由于这些元器件在数据库中的数据量相对较少,现实中这些元器件的种类也较少,如贴片二极管、贴片三极管和插件电感,其中本文提出算法对元器件的最低识别率要高于MobileNetV1 和Mobile-NetV2 网络。
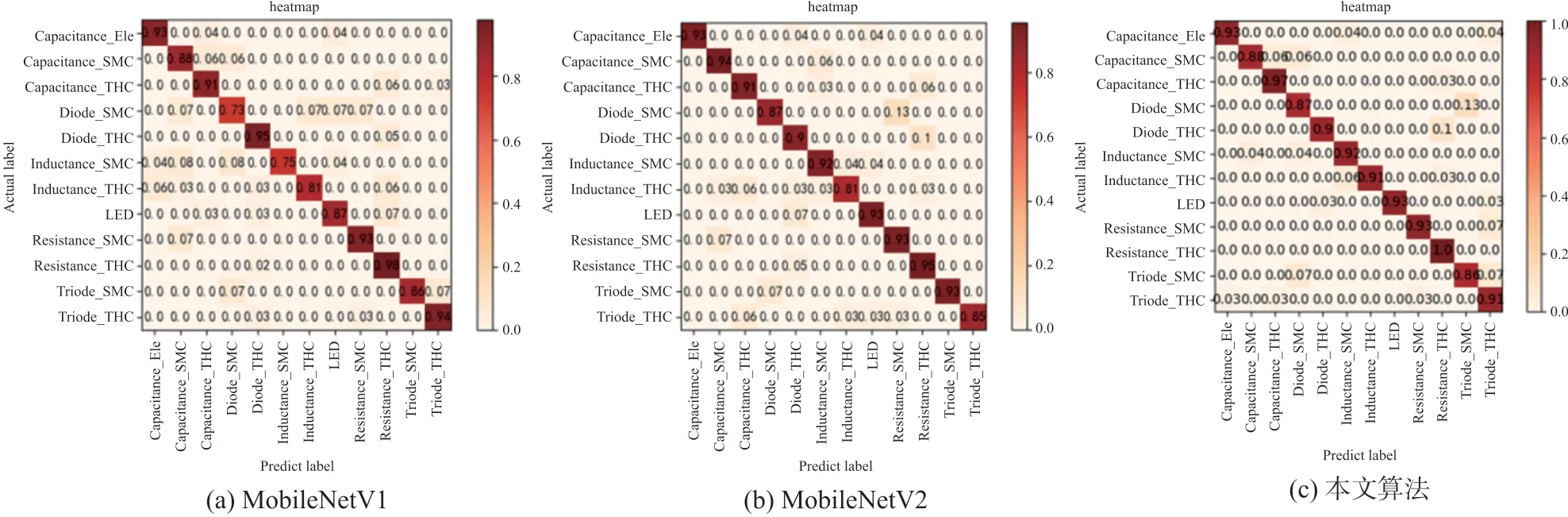
图6 轻量化网络迁移学习识别结果的混淆矩阵
2.3.4 嵌入式系统部署
为了更好满足边缘端的使用,本文通过TensorFlow Lite 将模型部署在树莓派嵌入式系统中[14-15]。TensorFlow Lite 是Google 公司开发,旨在帮助开发者在移动端或嵌入式设备上高效运行机器学习模型,并将训练好的模型通过转化、部署和优化,进一步提升运算速度、减少内存和显存,其工作流程如图7 所示。
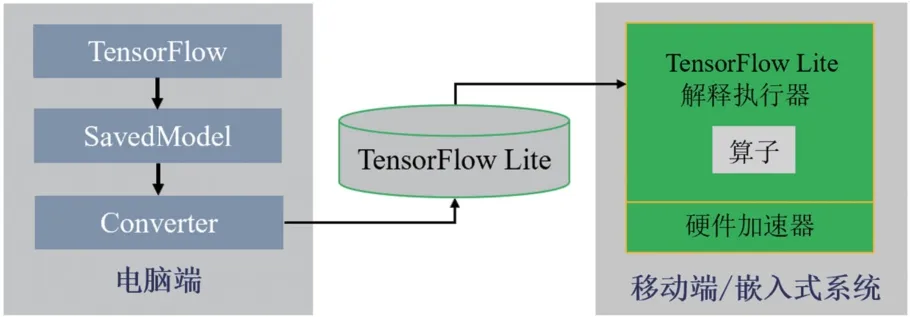
图7 模型部署流程图
按此工作流程,构建基于树莓派开发电子元器件识别系统,将经过训练的模型保存为.h5 模型,然后将其转换为.tflite 模型,并将其部署在树莓派系统中,这里选用树莓派型号为工业级CM4,海康威视2K 高清摄像头,操作流程如图8 所示。
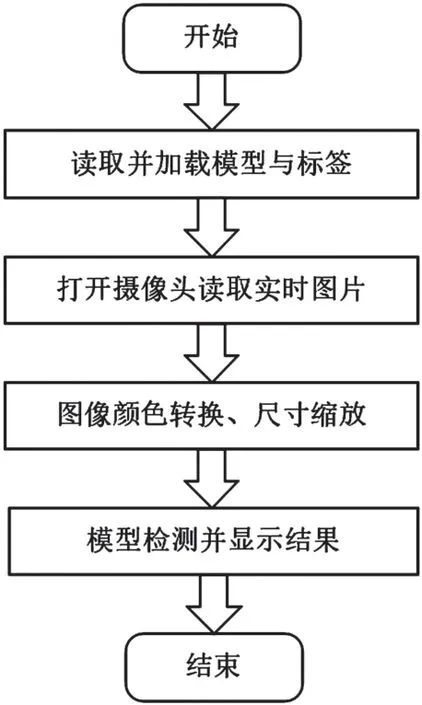
图8 树莓派系统操作流程图
实验显示的识别结果如图9 所示,不难看出,在不同的环境下,通过摄像头拍摄元器件,无论是单个元器件还是多个元器件的组合,树莓派系统都可以准确地识别出元器件类别,而且实时性好。

图9 树莓派系统识别结果
3 总结
针对现代电子产品生产中电子元器件种类多,差异小的特点,提出了基于轻量化深度迁移网络MobileNetV3 的识别方法。在传统的MobileNet 系列模型的基础上,通过迁移学习,将预训练模型的参数迁移到电子元器件图片的训练模型MobileNetV3中,在进一步提升模型识别率的同时,解决了传统模型所需训练样本多、训练参数量大以及部署应用端困难等问题。实验结果表明,本算法提高了识别效果,并在树莓派系统中表现出很好的实时性。今后将进一探讨本模型在移动手机端的应用研究。
