基于CiteSpace的我国护理风险预测模型可视化分析
2024-01-25赵丽丽李海霞
陈 琴,陈 红,赵丽丽,常 林,马 丽,李海霞
风险预测模型是指利用数学公式估计特定个体当前患有某病或将来发生某结局的概率,并按照概率的大小分层以供评估者对不同风险概率的群体在临床实践中进行针对性的干预[1]。近年来,随着计算机网络技术和大数据在医疗领域的广泛应用以及“5P医学模式”的发展,将机器学习算法引入护理研究领域构建护理风险预测模型已深受护理研究者的青睐,通过精准预估疾病预后结局、症状发生可能性等概率,从而协助医护人员制订个性化预防性治护方案[2]。现有护理风险预测模型研究在慢性病进展预测[3-4]、不良事件预估[5-6]、护理教育改革[7]等方面已有大量研究,因此本研究基于CiteSpace软件对国内护理风险预测模型研究现状进行可视化分析,总结当前研究热点与前沿,为后续护理研究者开发护理风险预测模型提供参考依据。
1 资料与方法
1.1 文献检索策略
在预检索的基础上确定检索式,对中国知网、万方数据库、维普数据库收录的关于护理风险预测模型的文献进行检索,检索时限为建库至2023年4月13日,共获取584篇文献,文献筛选流程见图1。以万方数据库为例,检索式如下。
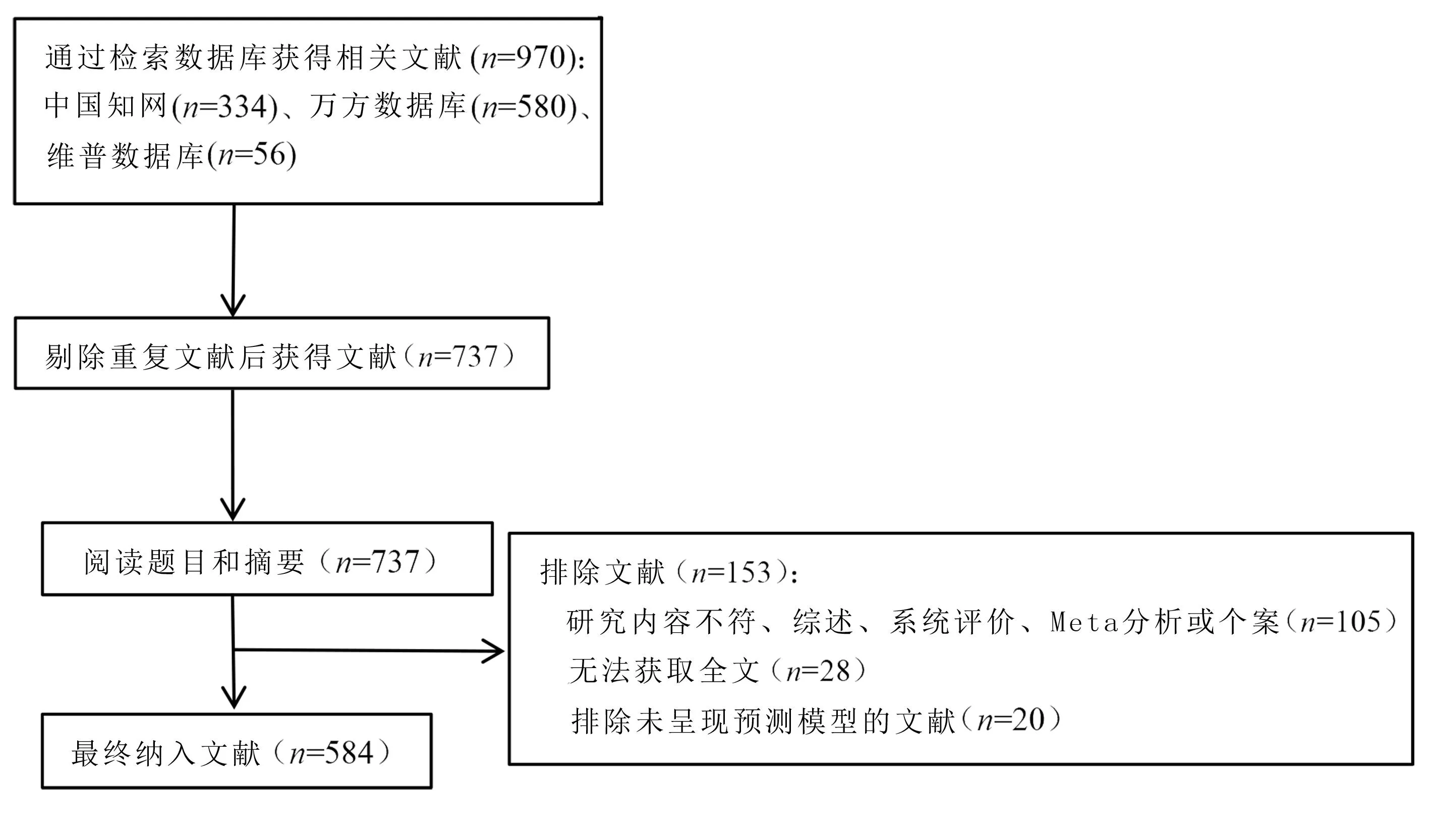
图1 文献筛选流程图
#1 风险预测模型OR预测模型OR风险模型
#2 护理
#3 构建
#4 #1 AND #2 AND #3
1.2 文献纳入和排除标准
纳入标准:1)我国护理领域所有已经发表的风险预测模型的文献;2)针对特定的临床护理问题,通过严谨的方法学构建预测模型的文献。排除标准:1)综述、系统评价、Meta分析或个案类文献;2)会议类文献;3)重复发表的文献;4)无法获取全文的文献;5)未提供预测模型的文献。
1.3 文献筛选
首先将检索的文献导入NoteExpress软件进行整理和去重。由2名受过澳大利亚Joanna Briggs Institute(JBI)循证卫生保健研究中心循证方法培训的研究者严格按照纳入及排除标准,阅读文献题目和摘要进行初筛,然后进一步查阅全文进行复筛。对筛选结果有争议时,邀请第3名专家进行判定。
1.4 研究方法
本研究使用CiteSpace 6.2.R1软件对数据源进行统计学分析,从数据库导出题录,应用NoteExpress 3.6.0软件去除重复及与主题不符文献。将去重后题录导出,以download_.txt格式命名保存至input文件夹,将数据导入CiteSpace 6.2.R1软件在Data中转换为软件可识别的中国知网(CNKI)格式,导出文件保存至output文件夹中。在CiteSpace 6.2.R1软件界面中,时间区域为2011—2023年,时间切片为1年,阈值数值设置为Top N%=50%,pruning算法为Pathfinder。选取的节点类型分别为“机构”“作者”和“关键词”,通过构建关键词聚类知识图谱、突现词分析图谱、作者合作网络可视化图谱和发文机构合作网络可视化图谱,对近年来护理风险预测模型的研究热点和发展趋势进行分析。
2 结果
2.1 我国护理风险预测模型发文数量及趋势情况
2005—2011年发文数量基本稳定,处于探索期,年发文量少于10篇;2012—2018年为逐步增长期,年发文量为20~30篇;2019—2022年呈井喷式增长,年发文量>80篇。
2.2 我国护理风险预测模型核心作者及发文数量作者合作网络分析
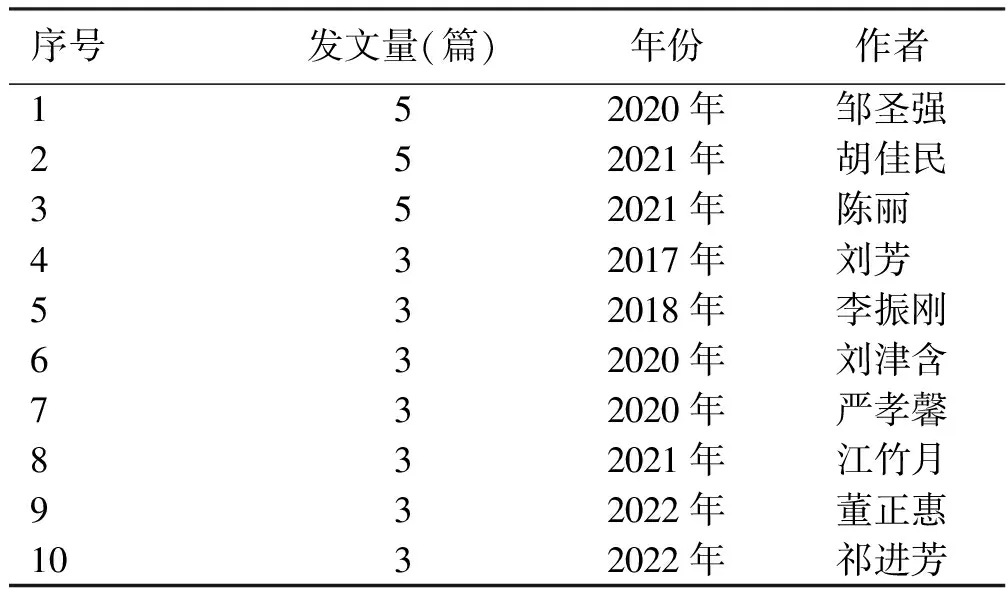
表1 国内发文量排名前10位的核心作者情况
利用CiteSpace 6.2.R1软件制作作者合作网络可视化图谱,时间切片为1,阈值为1,得到269个节点,251条连线。作者合作网络可视化图谱见图2,在可视化图谱中,节点大小、作者字体大小代表发文量高低,作者之间的联系粗细代表作者之间关联度的高低。其中,邹圣强、陈丽、胡佳民字体及节点最大且连线较多,代表他们发表此类文献最多且有合作关系;董正惠、祁进芳、李振刚发表相关文献较多,他们之间也存在合作关系。
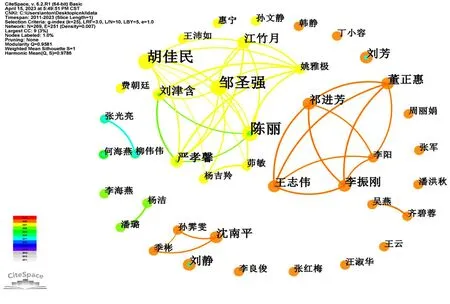
图2 2011—2023年我国护理风险预测模型相关领域的作者合作网络可视化图谱
2.3 我国护理风险预测模型研究机构发文情况及合作网络分析
湖州师范学院发文量最多14篇;其次是江苏大学、安徽医科大学发文量分别为9篇和8篇。国内发文量排名前20位的核心研究机构情况见表2。

表2 国内发文量排名前20位的核心机构情况
在CiteSpace 6.2.R1软件中的institution模块对文献的发文机构进行分析,制作发文机构合作网络可视化图谱见图3,时间切片为1,阈值为25,得到165个节点,87条连线,密度为0.006 4。机构发文量的多少与节点大小和机构字体大小成正比。机构之间的联系粗细代表作者之间关联度的高低。通过研究发文机构之间的连线能够清楚地发现,风险预测模型在我国护理领域研究尚未形成机构群,机构间的合作仅存在于医院护理部与其各病区之间、高校及其附属医院,其他机构之间的合作较为分散。
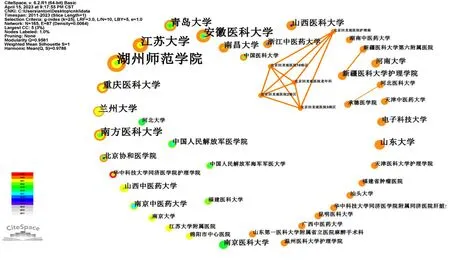
图3 2011—2023年我国护理风险预测模型相关领域的发文机构合作网络可视化图谱
2.4 研究热点分析
2.4.1 关键词聚类分析
聚类分析是用算法把相同或相近的关键词进行归纳汇总,以此更好反映概念间的关系[9]。CiteSpace依据网络结构和聚类的清晰度,提供了模块值(Q值)和平均轮廓值(S值)2个指标,Q>0.3意味着划分出来的社团结构是显著的,当S值在0.7时聚类是高效率、令人信服的,若在0.5以上,聚类一般认为是合理的[7]。因此,在关键词共现网络基础上进行关键词聚类分析,能够更直观地反映风险预测模型在护理领域的研究热点。通过在CiteSpace.alias中进行文本编辑,合并同义关键词节点,利用CiteSpace 6.2.R1软件进行关键词共现后运用对数似然比(LLR)算法聚类生成该领域关键词聚类网络见图4,此图谱呈现365个节点,549条连线,且模块值Q=0.870 5,轮廓值S=0.982 8,表明聚类结果的可信度较高,节点的大小代表聚类的大小。由图4可知,研究主题主要集中在预后结局和疾病预测方面;重点关注人群为老年人、护士、妇女,这与王晶等[10]的研究结果一致。此外,能够发现运用机器学习和人工智能建模已经成为护理风险预测模型构建的趋势。
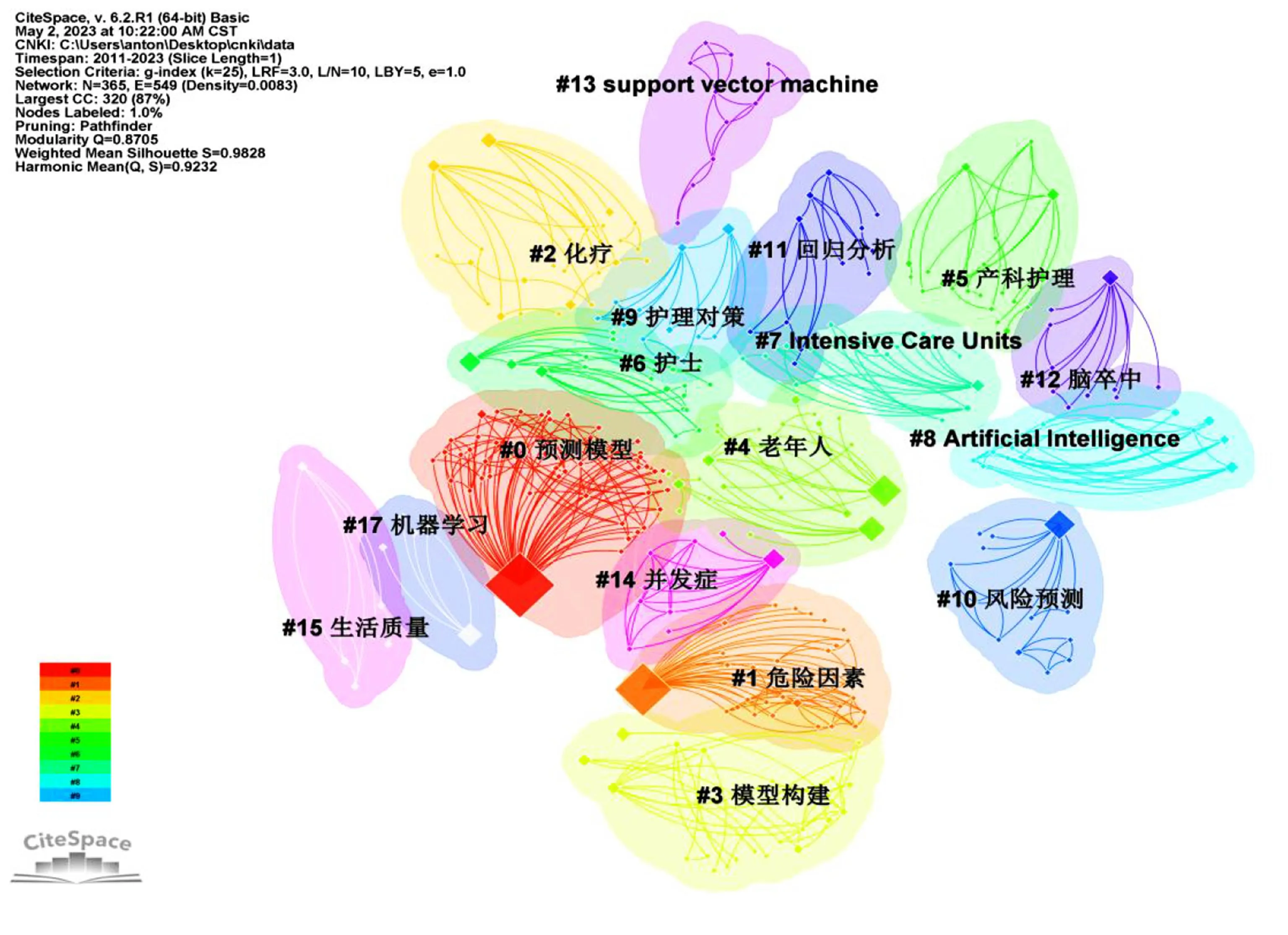
图4 2011—2023年我国护理风险预测模型的关键词聚类网络图谱
2.4.2 关键词突现分析
突现词是利用突变词探测技术生成,代表某研究领域的热点词汇,可用来识别该领域的研究热点与发展趋势[11]。关键词突现分析,可以了解研究领域的前沿知识热点和发展演变趋势。本研究通过CiteSpace 6.2.R1软件将突现参数γ设置为0.3,最短时间设置为2年,运行Burstness得到19个突现词,见图5,显示这些突现关键词的突现时间和持续时间分布。根据突现结果可以看出,突现持续时间最长的关键词为生活质量,时间为2015—2020年,其次是早产儿;最新出现的突现关键词为失能老人、nomogram model、临床护理、烧伤和吞咽障碍,表明2019年以来使用工具由回归模型转变为nomogram model;同时在护理领域的研究前沿和热点比较集中在失能老人、临床护理和预后结局。病人预后转归、智能数据挖掘会是未来研究的重点方向。2011—2023年我国护理风险预测模型前15位关键词见表3。
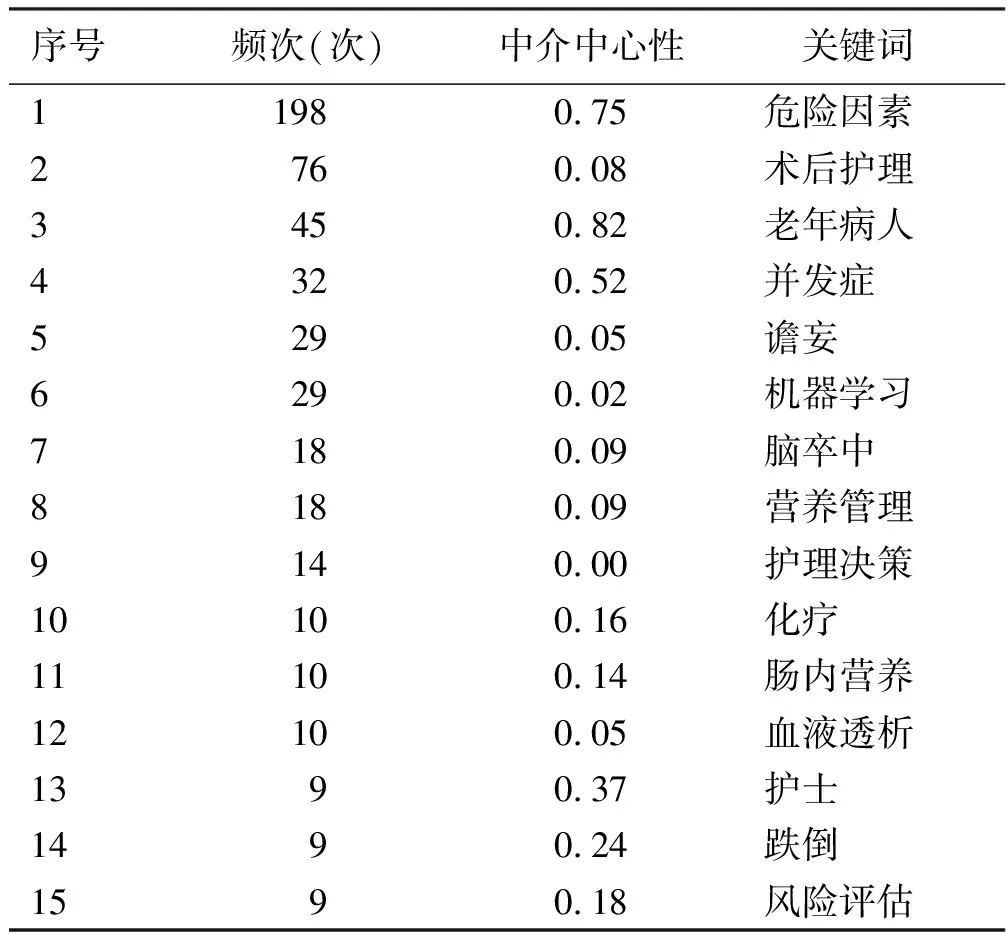
表3 2011—2023年我国护理风险预测模型前15位关键词
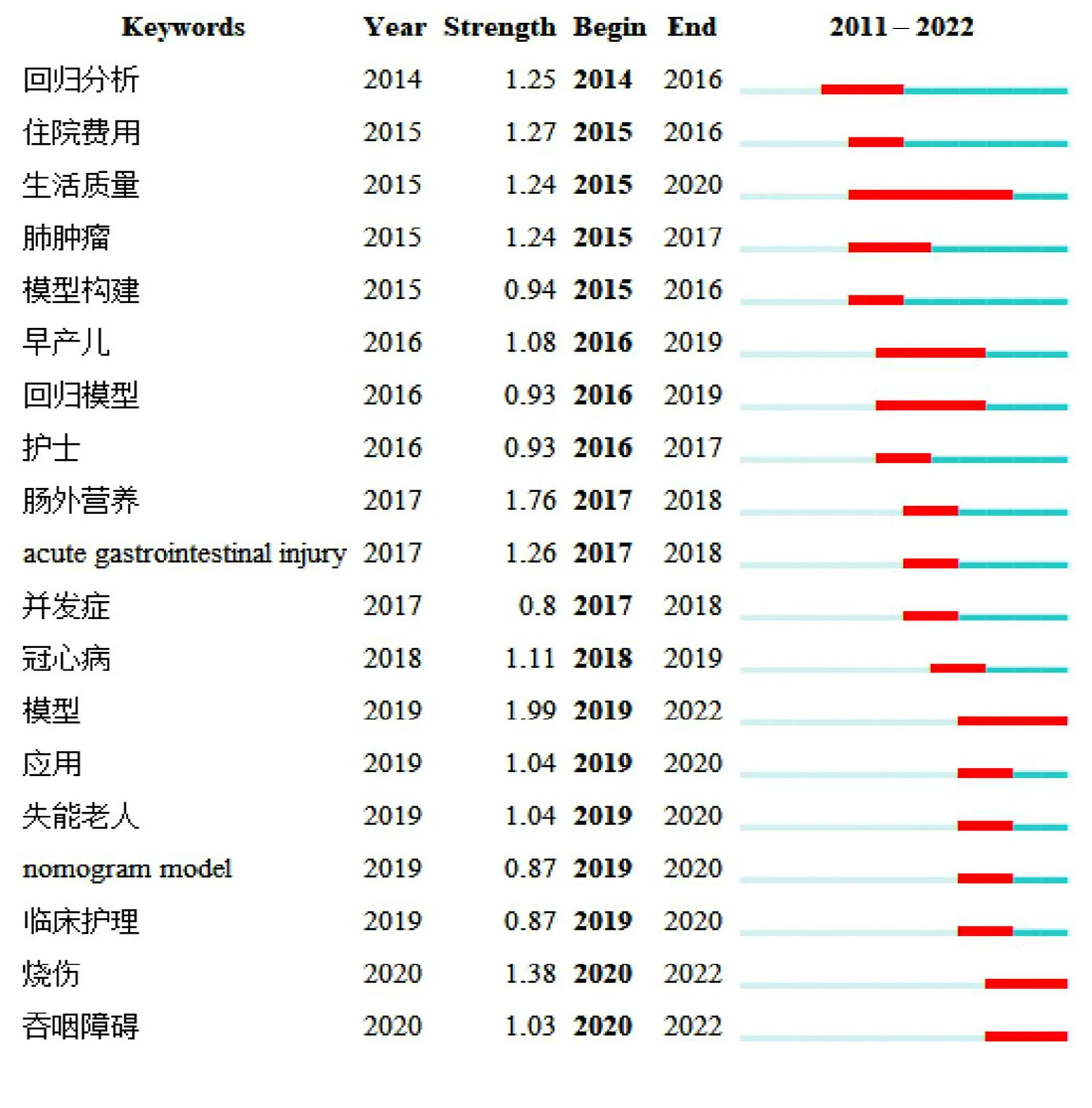
图5 2011—2023年我国护理风险预测模型的关键词突现图谱
3 讨论
3.1 我国的护理风险预测模型研究总体现状
2011—2023年我国护理风险预测模型相关研究发文量呈上升趋势,处于蓬勃发展状态,然而部分文献未能成功构建预测模型或模型建立后未进行性能评价,其可重复性和外推性有待考察,同时相较于国外发文量较低,因此我国的护理风险预测模型构建研究仍处于相对劣势。关于护理风险预测模型的文献多发表于中华护理杂志等文献质量较高的核心期刊,说明我国学者在护理风险预测模型领域的研究方法已较为成熟。未来随着风险预测模型研究的深入开展,以及技术的持续更新迭代,发文量预计将会进入下一个循环周期。
3.2 各研究区域发展不平衡,核心作者和机构群尚未形成
从表2看出,我国内部机构文章大多出现于北京、浙江、江苏、安徽等经济和医学相对发达地区,西部地区文章较少,这与其他研究者在护理创新领域的研究统计结果一致[12]。发文量和分布趋势可以一定程度上反映某领域的研究现状和水平,因此迫切需要国家政策的支持,加大经济不发达地区教育及科研资金投入。好的合作能够推动科学研究正向发展,合作度既能反映研究领域的相互渗透、交叉程度,又能反映研究领域的质和量[13],各学者、机构和地区之间开展合作,利于推动护士科研水平的发展。本研究结果显示,我国护理风险预测模型研究领域缺乏核心作者和机构群,作者之间及机构之间相互合作匮乏、疏散。因此,亟待加大资金与政策的扶持力度,促进多学科、多机构间的科研学术交流与交互融合发展,促进科研成果转化。
3.3 研究前沿与热点
本研究结果显示,术后护理、老年病人、并发症、谵妄、机器学习、脑卒中等研究主题出现的频次较高。说明随着我国老龄化进程的加速,老年人照护需求飞速增加,加之国家养老政策的推动,老年人护理需求、医养结合、长期护理风险的预测研究已持续成为老年人研究领域的热点[14]。其中,由于骨折和卒中的高发病率和高致畸率特点,同时伴随多种并发症,严重影响老年人的生活质量,因此已成为未来持续关注的重点。有研究表明,关于骨折的临床研究多集中在围术期护理、术后康复及舒适护理,且以高龄病人居多[15]。陈旭娟等[16]通过探讨老年髋部骨折术后病人肺部感染的影响因素,构建的风险预测模型可以有效预测老年髋部骨折术后病人肺部感染的发生。孙超等[17]研究构建的老年缺血性脑卒中病人非计划性再入院的风险预测模型可帮助医务人员早期识别老年缺血性脑卒中病人非计划性再入院高危人群。术后谵妄是指外科手术后出现的谵妄,是手术后常见并发症之一[18]。叶丽等[19]研究表明针对不同病人构建不同的术后谵妄风险预测模型有利于医护人员早期识别并采取差异化护理方案,提示未将“疼痛”作为第五大生命体征纳入重要影响因素进行分析,是构建术后谵妄风险预测模型研究的不足之处。
同时,本研究结果表明吞咽障碍和烧伤是当前较前沿的研究主题。神经功能的缺损会直接导致病人吞咽功能减退,因此促进神经功能恢复、降低吞咽障碍发生风险是卒中护理未来重要的研究方向。近年来,烧伤病例仍在上升,死亡率非常高,尽管有关烧伤的研究已相对成熟,但是大面积烧伤合并谵妄的研究很少,而开发和验证大面积烧伤病人谵妄发作的预测模型更是少见,由此也为基于机器学习的谵妄预测研究提供了方向[20]。
值得注意的是,依托“互联网+”目前护理领域中应用机器学习算法构建的风险预测模型已经取得一定的成果,汪淑华等[21]研究表明基于机器学习算法预测模型性能在敏感性和准确性上优于传统Logistic回归模型;王沛如等[22]研究也表明基于机器学习算法建立的护理人员心理健康状况预测模型预测价值更高。俞臻梁[23]的研究也得出同样的结果。构建护理风险预测模型最重要的基础是前期数据和记录的准确性和全面性。然而,目前基于机器学习构建模型的研究大部分为回顾性研究,这可能成为建模结果不理想的原因,提示未来开展前瞻性研究构建护理风险预测模型效果更佳。王晶等[24]的研究提示护理研究者应寻求高效的多学科合作,利用信息化技术开展护理风险预测模型研究,不断创新方法,拓展研究的广度和深度。
综上所述,通过基于CiteSpace对我国护理风险预测模型研究进行可视化分析,结果显示护理风险预测模型的研究和应用仍是目前护理领域研究的热点。然而,大部分研究为回顾性研究且尚未进行模型性能评价,临床推广较少,因此应注重提升护理人员自身数据挖掘知识储备,培养护理信息技术专业人才,在后续建模时,能够通过不同科学算法对同一研究问题构建多种模型,再进行模型性能评价寻找最优模型,以便更好地推广于临床。我国护理风险预测模型构建研究实践发展仍然面临着区域、作者及机构较为分散、合作不紧密、发展不平衡等多方面困难,需要相关政策扶持及机构培训,从而促进个体及系统层面全方位发展。但是,本研究仅检索了我国3个数据库,对我国学者在国外期刊发表的文章未进行分析,研究结果存在一定的偏倚和局限性。
