基于无监督预训练的跨语言AMR解析*
2024-01-24范林雨李军辉
范林雨,李军辉,孔 芳
(苏州大学计算机科学与技术学院,江苏 苏州 215006)
1 引言
抽象语义表示AMR(Abstract Meaning Representation)[1]是一种新兴的语义解析表示形式,旨在从句子文本中抽象出语义特性,并利用图结构呈现句子的结构化语义信息。AMR将句子语义结构表示为一个单根的有向无环图。图1所示示例是以德文作为目标语言文本,首先解析为AMR序列,再将AMR序列转化为AMR图。图1c中的节点表示文本中的概念,如“take-01”表示“获取”这个概念,“01”表示take的第1种词义;图中的边表示概念之间的语义关系,如“:ARG0”表示概念“both”为概念“take-01”的施事者。由于AMR是对文本进行抽象语义表示,抛开了句子的语法结构保存了文本的语义信息,因此它可以被应用于许多语义相关的自然语言处理任务中,如文本摘要[2]、机器翻译[3]等。
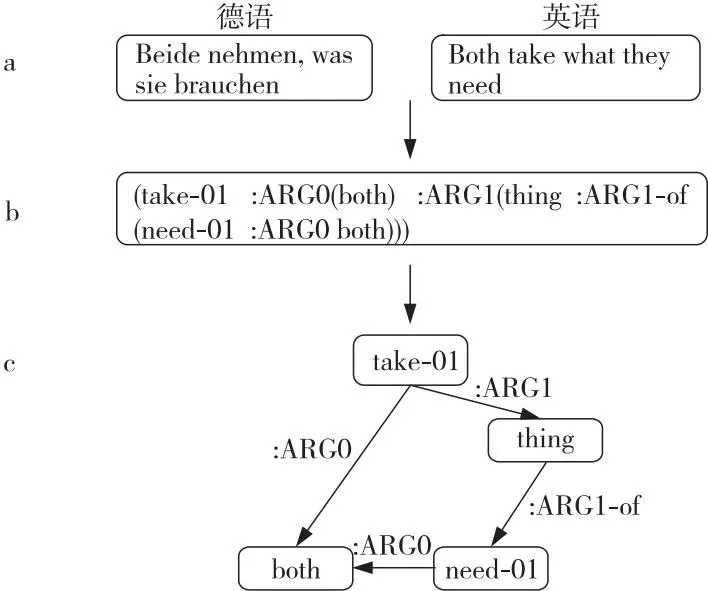
Figure 1 Example of cross-lingual AMR parsing图1 跨语言AMR解析示例
近年来,AMR解析的相关研究多是围绕英文开展。Konstas等人[4]首次将AMR解析看作是一个序列到序列的问题,引起了广泛关注。随后,基于Transformer序列到序列模型[5]的AMR解析成为AMR解析的主流方式。Ge等人[6]通过向序列到序列的AMR解析模型中引入句法和语义知识,提高AMR解析性能。Xu等人[7]也将AMR语义解析作为序列到序列的任务,并联合机器翻译任务、句法分析任务以及AMR解析任务进行预训练,最后在AMR语料上进行微调,最终性能获得了极大的提升。Yu 等人[8]探究在使用序列到序列模型时融入AMR图的结构化信息,针对解码端已经解码的字符构建AMR子图,再根据当前解码端的输入字符,在子图中找到其祖先结点,将这部分信息融入到解码端,辅助解析下一个字符。Bevilacqua等人[9]以预训练模型BART(Bidirectional and Auto-Regressive Transformers)作为初始化模型。与Ge等人[6]和Xu等人[7]的工作不同的是,该文献对AMR图的线性化方式有所改变,使用自定义符号对AMR图的概念进行替换,解决了AMR图线性化过程中共入概念信息不一致的问题。
受语料资源的限制,目前大部分AMR的相关研究都是面向英文的。受启发于句子的语义表示是跨语言的,Damonte 等人[10]首次提出跨语言AMR解析任务,其实验结果表明AMR语义表示可以在不同语言之间共享;还对AMR数据集LDC(Linguistic Data Consortium)2015E86[1]中的测试集进行了翻译,并公开了其他非英文(德文、西班牙文、意大利文和中文)的AMR解析测试集,即LDC2020T07[10]数据集。图1是跨语言AMR解析的一个例子,可以看到,对于语义相同的英文和德文,它们的AMR是一致的。
在特定语言的AMR解析任务中,由于缺少人工标注的AMR语料,相关研究多集中于跨语言AMR解析,即以AMR作为公共的语义表示,实现目标语言的AMR解析。例如,Xu等人[11]利用大规模平行语料,提出多任务预训练的方法进行跨语言AMR解析,以德文为例,在预训练过程中联合英-德和德-英机器翻译、英文AMR分析、德文AMR解析、AMR-英文文本生成和AMR-德文文本生成共6种任务,并提出了多种微调方法,最终在德文AMR解析上获得了70.45%的SmatchF1值。Cai等人[12]也借助已有的翻译系统,将目标语言翻译为英文,并联合英文输入进行跨语言AMR解析。
以上相关研究假设存在英文与目标语言的平行句对,或存在高性能的英文与目标语言翻译系统。与这些相关工作不同的是,本文是探讨在没有平行句对或高性能翻译系统的情况下的跨语言AMR解析。也就是说,假设仅存在英文和目标语言单语文本,如何实现高性能的跨语言AMR解析。受启发于无监督机器翻译任务[13]以及Xu等人[11]的相关工作,本文将AMR解析看作是序列到序列的生成任务,并与无监督机器翻译任务一起进行基于多任务学习的预训练。具体地,在数据方面,本文主要是围绕单语英文语料进行,同时借助单语目标语言语料实现跨语言AMR解析任务。为了实现目标语言到AMR的映射,需要构建(英文,目标语言,AMR)三元(伪)平行语料。首先,构建平行语料(英文,AMR),本文采用AMR解析工具,对单语英文进行解析,获得(英文,AMR)的伪平行语料;然后,构建目标语言与平行语料(英文,AMR)英文端的映射,以英文作为桥梁,构建(目标语言,AMR)训练语料。由于不具备(英文,目标语言)平行语料,本文主要是在预训练阶段引入机器翻译任务,实现英文到目标语言的翻译。在任务方面,本文引入无监督机器翻译方法构建英文到目标语言的翻译;为了更好地指导目标语言AMR解析任务,在预训练阶段还引入英文AMR解析任务;预训练的最后一个任务是目标语言AMR解析任务。在预训练阶段结束后,利用预训练后模型的翻译能力对AMR 2.0金标准语料的源端英文进行翻译,获得(目标语言,AMR)银标准语料,并基于该语料进行微调。本文分别以德文、西班牙文和意大利文作为目标语言,实现跨语言AMR解析。基于LDC2020T07[10]的实验结果表明,本文提出的方法是有效的,在德文、西班牙文、意大利文分别获得了67.89%,68.04%和67.99%的SmatchF1值。
本文的主要工作包括:
(1)首次探索了在没有目标语言和英文平行语料或者高性能英文-目标语言翻译系统的情况下,如何实现高性能的跨语言AMR解析。
(2)提出了融合无监督机器翻译和AMR解析的多任务学习预训练方法。在预训练过程中,随着翻译性能的提升,跨语言解析的质量也将逐步提升。
(3)基于LDC2020T07[10]进行实验,实验结果表明,以德文、西班牙文和意大利文为目标语言的跨语言AMR解析性能分别达到了67.89%,68.04%和67.99%的SmatchF1值。
2 相关工作
2.1 AMR解析
自从Banarescu等人[1]提出了英文AMR的标注准则,并且公布AMR的标注语料,就开启了一系列针对AMR解析的研究。目前基于AMR解析的研究主要是基于以下几种方式:首先是两阶段的AMR解析[14-17],该方法首先生成节点,然后再构建边;其次是基于转移的AMR解析[18-20],这种方法将源端词汇与目标端AMR图的概念进行对齐,随后针对源端不同的词汇采取不同的转移行动来构建边或插入节点;然后是基于图的AMR解析[21,22],提出该方法是为了更好地建模图结构,基于图的遍历顺序DFS(Depth First Search)或BFS(Breadth First Search)生成节点;最后是基于序列到序列的方式进行AMR解析[7,23,24],该方法首先对AMR图进行序列化,序列化的方法包括BFS和DFS,然后使用序列到序列模型进行AMR解析。
上述这些方法中,序列到序列的方法使用广泛且受到很多研究人员的青睐,因为该方法实现简单且性能可观。且随着预训练模型在AMR解析任务中成功应用,使用预训练模型进行AMR解析也逐渐形成主流。如Bevilacqua等人[9]使用BART作为预训练模型,以序列到序列的方式进行AMR解析,通过探索不同的线性化方法达到了当时最好的性能;Bai等人[25]在BART预训练模型的基础上,针对AMR的图结构提出了图的预训练方法,并将预训练与微调的任务进行统一,在AMR解析任务中取得了不错的性能提升。
2.2 跨语言AMR解析
上述所有相关的研究都是探究英文AMR解析任务。由于缺乏跨语言AMR的训练语料,针对目标语言AMR解析任务的研究非常有限。实际上,能否将AMR应用在不同语言仍然是个开放性的问题。
Vanderwende等人[26]首次进行跨语言AMR解析任务,首先将目标语言文本解析为语义形式,然后将其作为锚点解析成AMR图。Damonte 等人[10]试图将目标语言词汇与AMR的概念进行对齐,使用基于转移的方法进行跨语言AMR解析。Xu等人[11]提出了跨语言AMR解析的预训练模型,实现跨语言AMR解析以及AMR到文本的双向预测。该模型主要在预训练阶段引入机器翻译任务,联合跨语言AMR解析任务在大量外部语料的使用下,实现模型对文本语义的理解。抛开外部语料的使用,Cai等人[12]提出了一种新的方法,将金标准AMR语料的英文端使用机器翻译模型翻译成目标语言,随后以英文和目标语言为输入,进行跨语言AMR解析。
上述研究都是在具备(英文,目标语言)或者(英文,AMR)平行语料的情况下进行的。本文主要探索仅围绕单语英文和单语目标语言的情况下如何进行跨语言AMR解析,并提出具体的实现方案。
3 模型和数据准备
3.1 任务定义
跨语言AMR解析是以目标语言文本作为输入,输出为目标语言文本对应英文翻译的AMR图。在这个任务中,AMR图的节点依然依托于英文单词、PropBank(Proposition Bank)集合以及AMR关键词。
以德文为例,图1给出了跨语言AMR解析的一个例子。通过图1可以观察到,跨语言AMR解析的输入为德文文本,输出为德文文本对应的AMR序列,最后通过后处理,将AMR序列转换为AMR图。
3.2 序列到序列模型
本文使用Transformer[5]作为实验的模型架构。Transformer使用了缩放的点乘自注意力机制。具体来说,该注意力机制包括查询矩阵Q、关键信息矩阵K和值矩阵V。注意力矩阵的计算如式(1)和式(2)所示:
(1)
S=QKT
(2)
其中,Q,K,V∈RN×d,N表示句子长度,d表示模型维度;M是掩码矩阵,用于屏蔽句子中无关字符的信息。
Transformer模型包含一个编码器和一个解码器。对于编码器,它包含若干个堆叠的相同层,每一层都有多头自注意力机制和全连接层。对于多头自注意力机制的每一个头,它的计算方法如式(1)和式(2)所示。对于解码器,它也是由若干个堆叠的相同层构成,每一层都由多头自注意力机制、上下文注意力机制以及全连接层组成。它的2个注意力机制的计算方式也如式(1)和式(2)所示。不同于多头自注意力机制,上下文注意力机制的K和V来自编码端的输出。
3.3 数据预处理
本文的语料仅包括单语英文、单语德文、单语西班牙文以及单语意大利文。在数据准备阶段,使用AMR解析器对单语英文进行解析,构建(英文,AMR)银标准语料。对于AMR图的序列化,本文借鉴Xu等人[7]在AMR解析中的预处理方式对AMR图进行预处理。首先,删除图中的指示变量,因为指示变量只是用来指代图中的相同节点而不具备任何语义信息,删除后不会影响模型的训练。本文也去除图中的wiki链接(:wiki),原因为模型可能会链接维基百科中不存在的对象。至于共入节点,本文只是简单地对概念进行复制。最终,将AMR图转换为一棵树,使用以前序遍历的方式线性化树,其效果可见图1b。
3.4 数据后处理
在测试阶段,需要将模型输出的AMR序列进行还原,才能使用评测工具对其进行性能评估。具体做法是恢复在预处理阶段去除的变量、wiki链接以及共入节点。本文使用Noord等人[24]提供的预处理和后处理工具进行处理。
4 无监督预训练的跨语言AMR解析
图2以德文作为目标语言展示了本文预训练过程的整体架构。图2a为无监督机器翻译的过程,包含2个子任务,分别为去噪自编码和反向翻译。图2a以英文输入为例展示预训练过程,目标语言输入预训练过程与之相同。其中,虚线箭头代表生成,虚线文本代表模型生成文本。图2b是跨语言AMR解析过程,包含2个子任务:英文AMR解析以及目标语言AMR解析

Figure 2 Pre-training process of cross-lingual AMR parsing图2 跨语言AMR解析的预训练过程
4.1 无监督预训练
实验使用Transformer作为基础模型架构。为了在模型中引入翻译功能并且考虑到实验现有的数据,本文在模型中增加了无监督机器翻译。为了提高无监督机器翻译的性能,Lample等人[13]使用XLM预训练模型作为起始模型。简单来说,本文是在XLM预训练模型的基础上继续进行预训练。本文定义序列为S,其中英文序列、目标语言序列以及AMR序列分别表示为SE、ST和SA。
4.2 无监督机器翻译
对无监督机器翻译而言,预训练是关键因素[27,28]。Lample等人[29]的实验结果表明,使用预训练的跨语言词向量去初始化模型的词向量能够使无监督机器翻译取得重大进展。本文遵循Lample等人[13]的方法,使用XLM预训练模型作为启动模型。
无监督机器翻译任务主要分为2个任务。任务1是去噪自编码。该任务是针对英文和目标语言展开。先对输入文本进行加噪,加噪的方式为删除、打乱和遮掩;然后将输入的噪声文本还原为真实文本。这一任务的目的是为了提高模型的鲁棒性。任务2是反向翻译任务。该任务针对单语输入文本,首先利用模型翻译为对应的目标语言文本构建伪平行语料,然后进行机器翻译。具体到本文是目标语言到英文以及英文到目标语言的双向翻译任务。以目标语言到英文翻译为例,首先针对输入SE,生成对应目标语言文本ST,构成(ST,SE)的伪平行句对,进行机器翻译训练。对于英文到目标语言的翻译,是以目标语言作为输入按上述相同的步骤进行操作。
4.3 跨语言AMR解析
由于缺乏跨语言AMR的训练语料,本文将英文文本作为锚点。考虑到仅有单语英文和单语目标语言,如何构建目标语言到AMR的映射是主要问题。首先给定单语英文序列SE,使用AMR解析器对其进行解析,获得(SE,SA)的伪平行句对。由于预训练中引入了无监督机器翻译,模型具备英文和目标语言之间翻译的能力,因此利用模型对平行句对(SE,SA)的源端SE进行翻译,得到目标文本ST,构建(SE,ST)的伪平行句对,最终以锚点SE形成(SE,ST,SA)的三元平行句对。
Xu等人[11]在进行跨语言AMR解析预训练时,采用联合多任务的方法试图缩小英文和目标语言之间的差距,并且为了更好地指导跨语言AMR解析,又增加了一项AMR解析任务。Xu等人[11]的实验结果表明,在预训练中加入AMR解析任务指导目标语言到AMR序列的映射是可行的,因此本文也增加了AMR解析任务。具体来说,跨语言AMR解析主要包括2个任务:
(1)英文AMR解析任务。该任务主要是针对平行句对 (SE,SA)进行,其主要目的是指导目标任务跨语言AMR解析。
(2)目标语言AMR解析任务。该任务为本文的目标任务,在平行句对(ST,SA)上进行,该平行语料构造过程如上所述。
值得注意的是,在预训练中跨语言AMR解析的语料始终围绕单语英文SE进行。平行句对(SE,SA)和(SE,ST)均是通过SE进行翻译获得。
4.4 联合多任务预训练
到目前为止,预训练阶段一共包含4个任务,分别是去噪自编码、反向翻译、英文AMR解析和目标语言AMR解析。其中,去噪自编码和反向翻译任务根据输入的语言类型又分别包含2个子任务:英文的去噪自编码、目标语言的去噪自编码;英文到目标语言翻译、目标语言到英文翻译。为了将上述任务融合到一个模型中,本文采用多任务学习训练的方式。
算法1为预训练阶段的整体训练过程。算法1训练集中下标N和M表示数据集的规模。算法1第3行首先采样训练批数据,第4~22行分别是本文预训练阶段的4个任务。通过算法1可以看到,本文的多任务训练方式按多个任务顺序执行,对于每个任务加载对应批数据进行训练,更新完模型后再执行下一个任务。

算法1 跨语言AMR解析预训练过程训练集:英文ARM Dpara∈{(SE1,SA1),(SE2,SA2),…,(SEN,SAN)},单语目标语言Dmono∈{ST1,ST2,…,STM}1:forepoch=1,…,K do2: forstep=1,…,B do3: 采样训练批数(XE,YA)∈Dpara,XT∈Dmono;4: #任务1:去噪自编码5: #noisy(*)表示对输入*进行加噪6: L1=-log(XE|noisy(XE));7: 更新模型;8: L2=-log(XT|noisy(XT));9: 更新模型;10: #任务2:反向翻译11: #translate1(*)表示将输入翻译为目标语言12: L3=-log(XE|translate1(XE));13: 更新模型;14: #translate2(*)表示将输入翻译为英文15: L4=-log(XT|translate2(XT));16: 更新模型;17: #任务3:英文AMR解析18: L5=-log(YA|XE);19: 更新模型;20: #任务4:跨语言AMR解析21: L6=-log(YA|translate1(XE));22: 更新模型;23: end for24:end for

4.5 微调(Finetuned)
在获得上述任务的预训练模型后,就要将其应用在金标准语料上。在微调阶段,本文使用AMR 2.0语料,即英文对应的AMR官方语料。对于英文-AMR平行句对(SE,SA),使用前述预训练完毕的模型将源端英文文本SE翻译为目标语言ST,构建(ST,SA)的训练文本,形成(SE,ST,SA)的三元训练文本。本文的目标是跨语言AMR解析,因此在微调阶段只进行目标语言AMR解析。需要说明的是,本文也尝试用预训练阶段数据在微调阶段进行联合多任务微调,但是效果并不明显。
5 实验及结果分析
本节以德文DE(DEntsch)、西班牙文ES(ESpaol)、意大利文IT(ITaliano)作为目标语言,通过实验验证本文跨语言AMR解析方法的有效性。
5.1 数据处理
在预训练阶段,对英文、德文、西班牙文以及意大利文使用WMT16的新闻领域的单语语料。对于单语英文而言,训练数据包含4.4×106个单语句子;对于单语德文、单语西班牙文以及单语意大利文,训练集的规模为5.0×106个单语句子。为了获得英文到AMR的伪平行语料,需要使用AMR解析器对单语英文进行解析。本文使用Bevilacqua等人[9]的AMR解析系统,该系统在英文AMR解析任务上获得了84.5%的SmatchF1值。
微调阶段使用AMR 2.0数据集,其训练集包含36 521个平行句对,开发集和测试集的规模分别为1 368和1 371。
5.2 实验设置
本文使用在17种语言上(包括德文、西班牙文、意大利文)预训练的XLM模型作为基础模型,实验使用的代码为XLM的代码。实验使用GELU(Gaussian Error Linear Unit)激活函数,丢弃率(Dropout)设置为0.1。模型训练使用Adam优化器对参数进行更新,其中β1=0.9,β2=0.98。实验的预热步数(Warm up)为4 000,学习率在 10-4~ 5×10-4,在解码过程中使用束搜索(Beam search),束的大小设置为5。预训练阶段,模型针对不同的任务设置不同的批次大小。对于无监督机器翻译部分,每个子任务的批次大小为2 048个形符(Token);对于跨语言AMR解析部分,每个子任务的批次大小为4 096个形符(Token);微调阶段的批次大小为4 096个形符。实验在Tesla V100 GPU上进行。对于预训练阶段,训练分为9个阶段(epoch),每个阶段在单个任务上迭代了2 000次;对于微调阶段,训练分为5个阶段(epoch),每个阶段迭代2 000次。
5.3 评测
为了评测模型的性能,本文使用LDC2020T07[10]语料库。该语料库包含对AMR 2.0测试集人工翻译的1 371个句子,翻译的目标语种包含德文、西班牙文以及意大利文。对于AMR解析性能,使用Smatch[30]以及其他细粒度的评判指标[31]。
5.4 实验结果
表1给出了本文的实验结果。其中Baselinenone表示以英文为枢轴语言的跨语言AMR解析性能,即使用AMR 2.0语料训练英文AMR分析器(SmatchF1值为72.58%);然后再将LDC2020T10[10]测试集中的德文、西班牙文以及意大利文使用本文的预训练模型分别翻译成英文;再调用英文AMR分析器获得相应的AMR分析结果。Baselinepre-trained表示本文实现的无监督预训练模型,该模型未进行微调。Finetuned为将无监督预训练后的模型在AMR 2.0语料上按3.5节的方法进行微调的结果。从表1可以看出,本文提出的无监督预训练方法,在性能上远远超过Baselinenone的,在德文、西班牙文以及意大利文上的SmatchF1值分别提高了15.24,13.57和14.62。在Baselinepre-trained的基础上进行微调又进一步提升了跨语言AMR解析的性能,在德文、西班牙文以及意大利文上的SmatchF1值分别较Baselinepre-trained的提高了1.58,1.40和1.79。表1的实验结果表明,本文在预训练阶段引入的无监督机器翻译任务能够缩小语言之间AMR分析性能的差距。Finetuned和Baselinepre-trained的对比结果表明,尽管本文在预训练阶段使用了质量较好的银标准数据,且体现出的效果也很好,但还是和AMR金标准数据存在差异,使用金标准数据微调依然可以提升AMR解析性能。
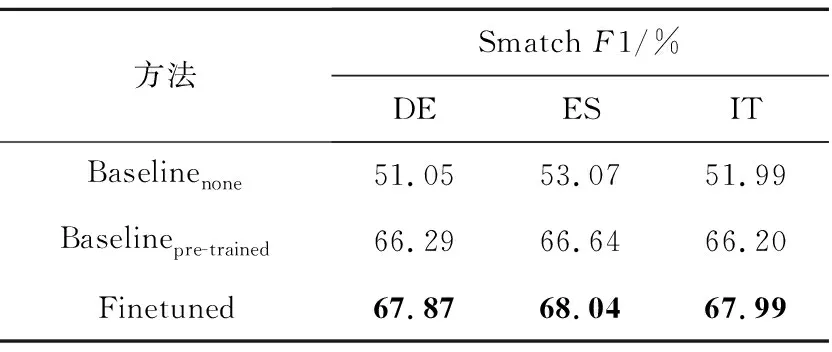
Table 1 Performance of cross-lingual AMR Parsing 表1 跨语言AMR解析性能
表2给出了各种细粒度指标的F1值。从表2可知,本文提出的无监督预训练+微调方法在各个细粒度指标上均远超Baselinenone的,并且在微调后各个细粒度指标均有不同程度的提升。
5.5 翻译性能影响
本文实现跨语言AMR解析主要借助自无监督机器翻译任务。因为本文在预训练以及微调阶段进行跨语言AMR任务的源端数据是通过模型的翻译功能对AMR语料的源端英文进行翻译所得,所以本节探究在预训练的不同阶段,翻译性能对跨语言AMR解析性能的影响。
图3以德文为例给出了预训练不同阶段的德文AMR解析的SmatchF1值和英文到德文的BELU值,使用的测试集为AMR 2.0测试集中的英文和其对应的德文翻译,其中横轴表示迭代次数,纵轴分别表示SmatchF1值和BLEU值。从图3可以看出,随着迭代次数的增加,模型翻译的性能得到了逐步提升,同时目标语言到AMR解析的性能也得到了逐步提升。同时,还观察到,由于无监督机器翻译的翻译性能有限,导致了跨语言AMR解析的源端数据质量不高,因此如何在这种情况下继续提升跨语言AMR解析的性能是将来研究的重点,其次在未来还将探索在更多语种上进行跨语言AMR解析。

Figure 3 Cross-lingual AMR Parsing performance versus unsupervised translation performance in pre-traing phase图3 预训练阶段跨语言AMR解析性能 与无监督翻译性能趋势图
6 结束语
本文在既无英文-目标语言平行语料又无英文-AMR平行语料的情况下,探索如何完成跨语言AMR解析任务。以单语英文为锚点构建英文-目标语言-AMR三元语料,具体地,通过在预训练阶段引入无监督机器翻译实现英文到目标语言的翻译;并且借助AMR解析器获得(英文和AMR)的平行语料。以德文、西班牙文和意大利文为目标语言,实验结果表明本文提出的方法能够在跨语言AMR解析任务中取得很好的效果。但是,在实验中也发现,预训练阶段和微调阶段使用的目标语言-AMR银标准训练语料的源端目标语言和测试集的金标准语料的源端目标语言存在着质量上的差异。因此,接下来的工作中,将探索如何缩短这种差异,提高跨语言AMR解析的性能。

Table 2 Smatch F1 of fine-grained metrics for cross-lingual AMR parsing表2 跨语言AMR解析的细粒度指标的Smatch F1值 %
