Gloo+:利用在网计算技术加速分布式深度学习训练*
2024-01-24黄泽彪董德尊齐星云
黄泽彪,董德尊,齐星云
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
聚合通信是分布式深度学习训练中最主要的通信方式,是训练时用于梯度信息同步的方式之一[1]。其中主要包括Allreduce、Barrier、Broadcast等操作,这些聚合通信操作由于涉及全局,常常对应用程序并行效率产生巨大的影响。为了进一步减少分布式训练时间,许多研究人员针对聚合通信进行了研究,并提出了多种优化方法,例如腾讯公司2018年提出的层次Ring Allreduce[2]。虽然相关优化方法也很好地提升了聚合通信的效率,但是这些优化方法仅仅是在软件层面上对聚合通信操作进行了改进,改进后的操作依然需要在网络中进行多次通信才能完成整体操作,且很容易引起网络拥塞。而且,当系统规模增大时,通信的计算步骤、计算量以及进程之间的距离都会相应增大,进一步产生较大的通信开销,且随着系统规模的增大,这种通信开销的增加是非常迅速的,使得软件层面实现的聚合通信可扩展性较差。
在网计算能够大幅度降低聚合通信时间,极大地提高分布式深度学习训练的速度。在传统的基于软件实现的聚合通信操作中,CPU在发起聚合通信操作后,会阻塞至操作完成。这导致该形式的聚合通信操作难于实现计算与通信的重叠,造成计算资源的浪费;同时,随着通信数据量的增加,CPU在聚合通信操作中的计算负担愈加沉重。相对于软件实现方式,在网计算实现的聚合操作完全卸载到网络硬件(网卡或交换机),减少了系统噪声的影响,这进一步加快了聚合操作的执行速度。硬件卸载的方式允许程序以非阻塞的方式执行,有效地实现了计算和通信的重叠,缩短了训练时间。目前有很多针对在网计算开展的研究[3-8],例如Barefoot公司主导提出的SwitchML交换机系统[3]、Mellanox公司提出的聚合通信网络卸载协议SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)[4]等。这些研究的实验结果表明了在网计算有助于缓解分布式应用程序网络通信问题,进而提升应用程序的整体性能。
聚合通信库是分布式深度学习训练中执行通信操作的重要部件。目前常用的聚合通信库有Gloo[9]、MPI(Message Passing Interface)[10]、NCCL(NVIDIA Collective Communications Library)[11]等。如果能够在这些通信库中集成聚合通信在网计算技术,那么将很有可能极大缩短分布式深度学习训练过程中的通信时间,进一步提升分布式深度学习训练的整体性能。当前NVIDIA已经在Open MPI[12]和NCCL中集成了SHARP技术,但是Open MPI是个体系结构比较庞大的通信库,且有很多分布式深度学习训练不需要的功能,而NCCL虽然是开源的,但是关于聚合通信操作内部的实现并没有公开,所以不方便研究人员分析和修改聚合通信操作的具体通信细节。虽然Gloo是一套开源的面向分布式深度学习的轻量级聚合通信库,但是它只实现了软件层面的聚合操作,并不能利用在网计算技术来加速分布式深度学习训练。
据我们所知,我们是目前第一个设计并实现了一款轻量级、完全开源并且能够利用在网计算技术来加速分布式深度学习训练的通信库。本文在实现该通信库时解决了2个挑战。第一个是内存注册开销大。SHARP每次执行聚合通信操作之前都需要进行内存注册和绑定,即使在同一块内存被不同聚合操作反复使用到的情境中。这是个很耗费时间的过程,需要降低这个过程所带来的影响。第二个是功能不适配。SHARP目前实现的聚合操作比较少,有一些必要的聚合操作它没有实现,例如Allgather。这导致某些操作没法利用在网计算技术来加速。
本文设计并实现了Gloo+,这是一款在Gloo的基础上设计并实现的集成SHARP技术的聚合通信库。Gloo+使用2种方法来分别应对上述挑战:(1)对同一个内存地址只进行一次注册和绑定,然后采用哈希表存储该内存的相关信息,以方便不同的聚合通信操作对其进行操作;(2)根据聚合操作的语义,利用SHARP已经实现的聚合操作来设计其未实现的一些聚合操作。
本文的主要工作包括以下3个方面:
(1) 在Gloo通信库的基础上,设计并实现了Gloo+。Gloo+能够利用SHARP技术加速分布式深度学习训练,使研究人员能够便捷地利用在网计算技术;
(2) 评估了Gloo+对分布式深度学习训练性能的影响;
(3) 详细分析了基于SHARP的聚合通信操作的优势和局限性。
2 背景介绍
2.1 聚合通信操作
聚合通信操作是高性能计算领域的经典技术,主要包括Barrier、Broadcast、Allreduce等。在梯度同步过程中,Allreduce操作最常被使用,并且衍生了很多不同的算法来实现Allreduce操作。在现有的算法中,Ring Allreduce[13]是最常被用到的一个算法,如图1a所示。
在Ring Allreduce的基础上,衍生了很多改良方法[14-16]。例如,腾讯公司提出的层次Ring Allreduce,其主要思想是对各个进程进行分组,然后采用组内各进程进行reduce操作,各组的主进程进行组间allreduce操作,最后组内进行主进程的broadcast操作,这种方法旨在充分利用组内高带宽网络的同时,降低各组之间低带宽网络带来的影响;还有IBM公司提出的BlueConnect算法,其主要思想是考虑了节点间不同机器和交换机(机器内、机器间交换机、上层交换机/路由器)的带宽不同,从而对进程进行不同的分组,以达到最优的多机通信。还有其他各种采用通信调度等软件方法来优化Allreduce操作的工作[17,18],都在不同程度上提升了Allreduce的性能。
虽然当前有很多针对聚合通信操作进行优化的工作,但是大多数的工作都是在软件层面上对聚合通信操作进行优化。经过优化后的聚合通信操作依然需要在网络中进行多次通信才能完成整体操作,这样很容易引起网络拥塞,而且软件实现的聚合通信可扩展性较差。在网计算将聚合操作卸载到网络中,如图1b所示。在网计算可以有效地提升通信效率,提高训练性能,所以有不少研究人员开展了聚合通信操作在网计算的研究工作。Barefoot公司提出的SwitchML交换机卸载系统,其主要设计思想是使用可编程交换机替代机器学习中传统的参数服务器,利用交换机的高吞吐率来加速参数更新。还有Mellanox公司开发的聚合通信网络卸载技术——SHARP,是当前工业界广泛使用的一项在网计算技术。
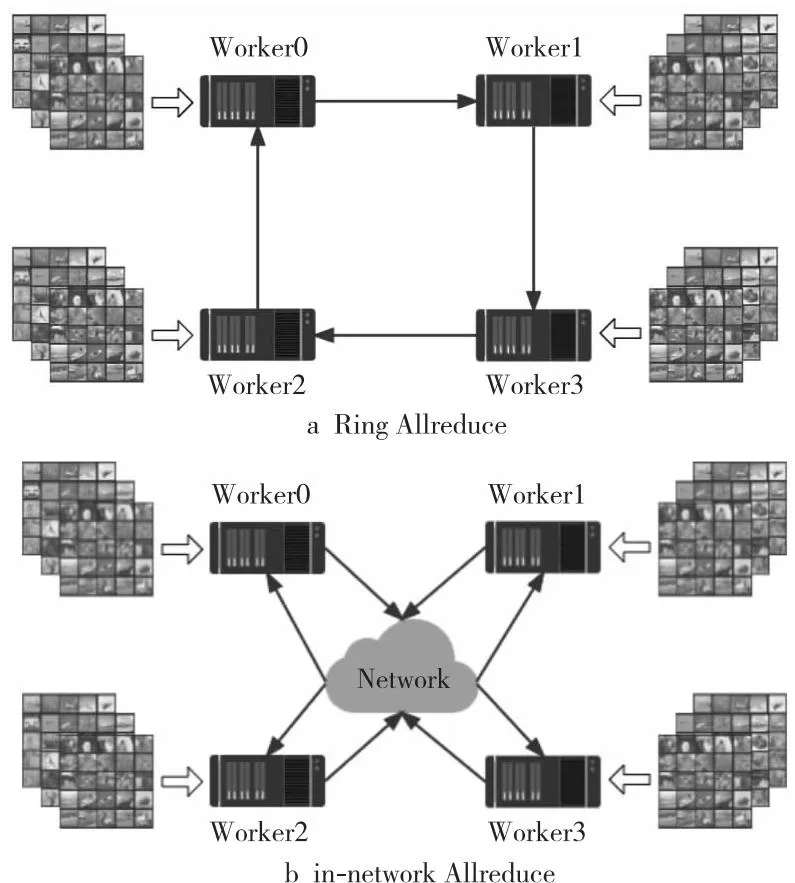
Figure 1 Two ways of Allreduce图1 Allreduce的2种不同的方式
2.2 聚合通信库
在分布式训练中,各节点之间的聚合通信操作通常由各种通信库来执行。最常用到的通信库有MPI、NCCL和Gloo。
MPI是分布式和并行应用常用的消息传递模型的定义,其规定了若干通信原语的接口标准,主要包括点对点通信和聚合通信2类。点对点通信由MPI_Send和MPI_Recv操作组成,用于2个节点间传递信息。聚合通信是在点对点通信基础上进行多节点间的通信操作,有MPI_Allreduce、MPI_Bcast等。MPI标准规定了这些操作接口的参数,所有MPI库都需要遵循这些接口标准来实现。Open MPI和MPICH[19]是2个常用的MPI库。
NCCL聚焦于GPU间的数据通信,主要针对GPU上的分布式训练通信进行优化,以充分发挥PCIe、NvLink和Infiniband等硬件性能,进而实现GPU间的高性能聚合通信接口。NCCL算法丰富度不及MPI库的,主要提供了Allreduce、Broadcast及点对点发送等操作。NCCL在GPU上的分布式训练中应用广泛,被大部分深度学习框架采用。
Gloo是Facebook针对分布式深度学习训练推出的开源通信库,为分布式深度学习训练提供了有用的聚合通信操作。该通信库向上提供了聚合通信操作的接口,向下提供了对不同网络的支持,且支持主流的深度学习训练框架,例如MXNet[20]、TensorFlow[21]和PyTorch[22]等。该库代码结构简洁。相关研究人员可以通过该通信库简单高效地实现自己的算法并在更多的环境配置下进行实验,进而获得更广的影响。
在网计算技术可以极大地提升聚合通信操作的性能。但是,目前在分布式深度学习训练中没有办法直接使用在网计算技术。如果能够在分布式深度学习常用的通信库中集成在网计算技术,那就可以使得分布式深度学习训练更方便地使用在网计算技术。通过调研了解到,目前NVIDIA已经在Open MPI和NCCL中集成了SHARP技术。但是,Open MPI是个庞然大物,总共有2 445个文件,包含了288 667行代码。而且Open MPI有很多深度学习研究中不需要的功能。NCCL在GPU间的通信功能强大,但是其聚合通信操作的内部实现并没有公开,使得研究人员很难通过它来开展对分布式深度学习聚合通信操作细节的分析。相反,Gloo是一个开源的轻量级聚合通信库,该通信库总共只有208个文件,仅包含25 136行代码。Gloo提供了分布式深度学习训练中常用的聚合通信算法,没有其他多余的复杂功能,其体系不会很庞大,而且整体架构简洁,便于分析和改动。能够在Gloo中集成SHARP技术来实现该通信库聚合通信操作的在网计算技术,对分布式深度学习的研究来说意义重大。

Figure 2 Topology structure of SHARP tree图2 SHARP树形拓扑结构
2.3 SHARP
SHARP是一种允许将聚合通信操作卸载到网络中的技术。SHARP在物理拓扑的基础上建立逻辑聚合通信树形结构,其树形结构图如图2所示。高层次通信库中的进程子集用于形成SHARP组,该组用于定义SHARP树中的末端节点,这些节点输入要归约并向上传输的数据。SHARP树中的非叶子节点是聚合节点,聚合节点负责执行聚合通信操作。当数据到达SHARP的根节点时,便开始进行分发操作,将聚合通信操作完成的数据分发给SHARP组中的各个节点。其设计的网络接口芯片与互连交换芯片硬件都具备数据聚合处理能力,共同构成逻辑树中的聚合结点。使用SHARP的好处是可以释放CPU资源供应用程序使用,消息通信效率高、延迟低,而且受到系统噪声的影响极少。该技术目前已经引入到Mellanox公司开发的交换机上,在交换机芯片中集成了计算引擎单元,可以支持16位、32位及64位定点计算或浮点计算,可以支持求和、求最小值、求最大值、求与、求或及异或等计算,可以支持Reduce、Allreduce等操作。
3 Gloo+通信库
本节将描述Gloo+的设计与实现。本文主要是在Gloo的架构上进行改动,将SHARP集成到Gloo中以实现基于SHARP的Allreduce、Reduce、Allgather操作,使其能够利用SHARP技术进行节点间的聚合通信操作。
Gloo的代码结构主要分为Transport、Context、Collective Operations 3个模块,其中Transport模块主要负责提供数据通信功能,如连接建立、数据的发送和接收等;Context模块主要负责管理全局通信的环境,如节点的rank、size、address等信息以及建立全局连接等功能;Collective Operations模块主要负责提供聚合通信操作,如Allreduce、Allgather、Broadcast等。3个模块之间的关系主要是Collective Operations模块中使用Context模块来获取全局的通信能力,在Context模块中使用Transport模块来完成具体的通信操作。本文主要在Context模块中实现了SHARP通信域的构建,在Collective Operations模块中实现了SHARP聚合通信操作的具体执行算法。图3展示了Gloo+的系统结构。
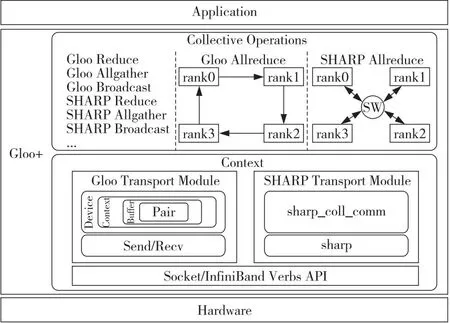
Figure 3 System structure of Gloo+图3 Gloo+整体架构
3.1 基于SHARP的Allreduce
Gloo中对于Allreduce操作的实现主要采用了ring和bcube这2个算法。本文在Gloo+中设计的基于SHARP实现的Allreduce操作是完全独立于Gloo本身Allreduce操作实现细节的个体。其主要分为3个步骤:首先,利用Gloo的contex来对SHARP通信域及操作进行初始化,构建一个SHARP通信域;然后,进行发送缓冲区和接收缓存区的注册绑定,使得SHARP守护进程可以对相关数据进行操作;最后,根据前2个步骤提供的一些参数调用SHARP提供的Allreduce接口,利用聚合通信在网计算技术进行Allreduce操作。
本文将Gloo+集成到Horovod中。但是,当在Horovod框架上用深度学习训练框架进行模型训练时,发现每一次Allreduce操作的执行都需要预先进行发送缓存区和接收缓存区的注册与绑定,这是一项很消耗时间的操作。同时还发现,在深度学习模型训练的过程中,训练启动时已经基本分配好了相应的一些内存空间来供各种数据使用,有可能多组不同的数据在不同的时间点上共享同一个内存空间,所以本文对Allreduce操作的内存注册进行了优化。如果需要进行操作的数据对应的内存地址还没有注册,那么就按正常流程对该地址进行注册和绑定,此时会获得一个对应的内存句柄,这个内存句柄是下文提到的“reduce_spec”结构的其中一个参数。本文会将首次进行内存注册的内存地址对应的内存句柄存放到一个哈希表中。如果需要进行操作的数据对应的内存地址已经注册过,那么哈希表中将会有该内存地址对应的内存句柄,就只需要直接从哈希表中取出该内存句柄然后进行下一步的操作。这样就避免了对同一个内存地址进行多次注册绑定,大大降低了时间开销。
在这个过程中,本文会用到SHARP提供的一个数据结构——reduce_spec。该结构定义了SHARP的聚合操作相关输入参数,包括数据类型、操作方式、聚合模式、发送缓冲区、接收缓冲区等详细信息。可以通过对reduce_spec中的一些参数进行设置,来满足执行相关聚合操作所需要的条件,进一步利用它来完成聚合操作。在本文中,Allreduce、Reduce以及Allgather的实现都需要用到reduce_spec。
3.2 基于SHARP的Reduce
在对SHARP的功能进行测试和分析的时候发现一个令人不解的问题,即实现的Reduce操作是一个有缺陷的操作。它的Reduce操作在数据量的个数少于16 KB时,会出现错误并停止执行任务,而在数据量个数大于16 KB时,就可以正常开展作业的执行。因为SHARP是不开源的,所以对于其内部的具体实现细节也无从得知,无法分析产生该问题的原因。
当利用SHARP的Reduce实现Gloo+的Reduce操作时,针对上面发现的问题,本文进行了一些优化,使得Gloo+中的Reduce在数据量个数少于16 KB时,也能正常使用SHARP的在网计算技术。因为Allreduce和Reduce的语义很相似,只不过Allreduce是将归约后的结果分发给所有节点,而Reduce是将归约后的结果给指定的节点,所以本文设计的主要思想是,对于个数少于16 KB的数据量,对其采用SHARP的Allreduce功能。具体实现如下:(1)给所有进程分配一块内存作为发送缓存区并进行注册和绑定;(2)对需要执行操作的数据量进行判断,如果数据量少于16 KB,给所有进程分配一块内存作为接收缓存区并进行注册和绑定;当数据量大于或等于16 KB、且当前进程是指定的root进程时,给当前进程分配接收缓冲区;(3)调用SHARP提供的接口进行聚合通信操作。如果数据量少于16 KB,则调用Allreduce接口,否则调用Reduce接口;(4)在数据量少于16 KB时,除了指定的根进程,其他进程均将接收缓冲区的数据丢弃。
3.3 基于SHARP的Allgather
本文在对SHARP进行分析测试时发现它只实现了Allreduce、Reduce、Broadcast和Barrier 4种操作。与此同时,在对Gloo实现的聚合操作进行分析时发现它实现了一些SHARP没有实现的操作,比如Allgather等。因此,考虑到可以借助SHARP的Allreduce操作来实现Gloo+中基于SHARP在网计算技术的Allgather操作,进一步使得Gloo+能够利用SHARP的在网计算技术加速Allgather操作。
众所周知,Allgather的语义其实跟Allreduce的语义很像,同样都是对所有进程的数据进行收集然后分发回去。唯一不同的是,Allreduce会对从各个进程收集回来的数据进行归约操作,例如求和、求均值等。而Allgather操作则不会对各个进程的数据进行归约操作,而只是收集起来,然后将收集到的所有数据再分发给各个进程,使得每一个进程都拥有一份所有进程的数据。
鉴于上面的分析,本文针对Allgather操作的主要设计思想是:根据进程的数量给每个进程开辟2个具有一定容量的内存作为发送缓冲区和接收缓冲区,然后根据进程号来确定所要用到的数据在发送缓冲区中的位置,接着进行Allreduce操作。如图4所示,首先,假设有4个进程,需要执行Allgather操作的数据量是1个,那么就分配两块能容纳4个数据的内存分别作为发送缓冲区和接收缓冲区;然后,根据每个进程的序号,来确定数据在发送缓冲区中的存放位置,比如对于rank2,它的数据从内存中的偏移量为2的位置开始存放,占用一个数据量大小的长度,其余的位置全部用0填充;接着,调用SHARP的Allreduce接口执行Allreduce操作,所有进程的数据在交换机中执行求和操作,这样每个进程提供的数据跟其他进程提供的0进行求和,最终便会得到一个存放着所有进程的数据的大数据块;最后,交换机将求和后的结果分发给各个进程,那么每个进程都会拥有一份所有进程数据,这样就完成了Allgather的整个操作过程。
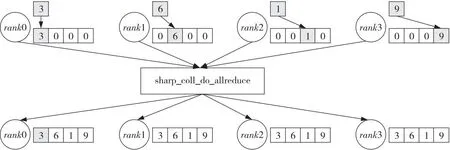
Figure 4 Allgather operation using SHARP’s Allreduce API图4 使用SHARP的Allreduce接口实现Allgather操作
4 实验评估
本节对Gloo+中实现的Allreduce、Reduce、Allgather进行测试评估,并与Gloo和MPI进行比较;还分别将Gloo+、Gloo和MPI应用于分布式深度学习训练中进行神经网络模型训练,测量了其吞吐量。
4.1 实验环境
实验主要在5台Intel®Xeon®Gold 6230R服务器和1台NVIDIA Quantum 200 Gb/s InfiniBand交换机组成的集群上进行。每台服务器都包含一个双插槽主板,每个插槽都有一个运行频率为2.10 GHz的26核处理器。该集群网络包含Mellanox InfiniBand HDR适配器,在计算节点之间提供100 Gb/s的带宽。
4.2 基准测试
本节描述了本文涉及的Allreduce、Reduce、Allgather操作在不同的消息大小上的实验结果,并对实验结果进行了分析。
图5展示了在不同消息大小上对Allreduce、Reduce、Allgather操作的性能测试结果,包括消息大小对Gloo+、Gloo和MPI通信延迟的影响。其中,X坐标轴代表消息大小(以字节为单位),Y坐标轴表示延迟(以微秒为单位),4条折线分别代表Gloo、Gloo+及MPI在以太网模式(网卡接口为ib)和IB网模式(网卡接口为mlx5)的情况。

Figure 5 Latency of collective operations with Gloo+, Gloo and MPI across various message sizes图5 使用Gloo+、Gloo和MPI 对各种消息大小的聚合操作的延迟
在Allreduce操作中,Gloo+相比于Gloo,当消息大小小于64 KB时,Gloo+加速比能达到100以上;而当消息大小大于64 KB时,其加速比也能达到10以上;Gloo+跟MPI进行比较,相比于MPI的以太网模式,Gloo+的加速比在10~57;而相比于MPI的IB网模式,Gloo+的加速比在10以内。在Reduce操作中,Gloo+相比于Gloo,当消息大小小于2 KB时,Gloo+的加速比能达到100左右;在消息大小增大到2 KB以上时,其加速比能达到十几,甚至几十;Gloo+跟MPI进行比较,相比于MPI的以太网模式,Gloo+的加速比在2~16;而相比于MPI的IB网模式,当消息大小小于或等于8 KB时,Gloo+的性能比MPI的还差,而当消息大小大于8 KB时,其性能相对较好,相比于MPI加速比在0~6。通过分析可知,在Allreduce和Reduce这2个聚合操作中,Gloo+相对于Gloo的性能提升都比较大,加速比从10到100以上;而跟MPI相比较,在以太网模式下,Gloo+性能也比MPI的好,不过在IB网模式中的消息大小比较小的情况下,Gloo+的性能比MPI的差,当消息大小较大时,Gloo+则更有优势。
在Allgather操作中,SHARP同样也提升了该操作的性能。因为本文是采用SHARP的Allreduce接口来实现基于SHARP的Allgather操作,所以每次Allgather操作所传输的消息大小比实际的有效消息大小要大,这会导致整体通信性能偏低。但是,通过跟Gloo比较发现,即使基于SHARP的Allreduce实现的Allgather通信性能偏低,还是比Gloo中实现的Allgather的通信效率高。当消息大小小于128 KB时,基于SHARP的Allreduce接口实现的Allgather操作相对于Gloo中实现的Allgather操作的加速比能达到10~50,可以看到这样的加速效果还是很好的。当消息大小大于128 KB时,Gloo+所带来的加速比也能维持在7左右。将Gloo+与MPI进行比较,在以太网模式中,Gloo+性能比MPI的好,加速比在5~24。而在IB网模式中,Gloo+跟MPI的性能比较接近。通过分析可知,在Allgather操作中,将Gloo+与Gloo进行比较,在消息大小比较小的时候,Gloo+能达到十几甚至几十的加速比。随着消息大小的增大,其加速比会呈现一个下降的趋势,但最终都会稳定在7左右。而与MPI进行比较,在以太网模式下,Gloo+仅在消息大小较大的情况下性能提升较明显,而在IB网模式下,其性能与MPI的接近。
4.3 深度学习应用测试
本节给出Gloo+和Gloo在分布式深度学习训练应用中的实验结果。本文将Gloo+和Gloo集成到Horovod框架中,在该框架上采用MXNet深度学习训练框架来进行模型训练。本文采用ImageNet数据集分别对VGG19、AlexNet神经网络模型进行训练,对每个神经网络模型都进行了16,32,64和128这4种批大小的独立训练。图6和图7分别展示了2个神经网络模型的实验结果。
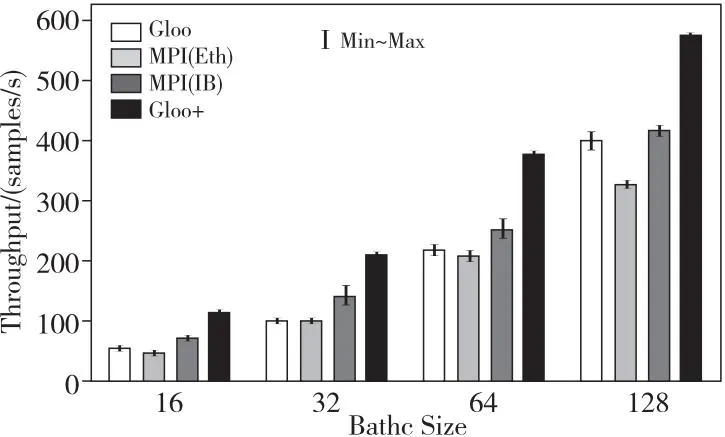
Figure 6 Throughput of training VGG-19 with different batch size图6 VGG-19在不同批大小下的吞吐量

Figure 7 Throughput of training Alexnet with different batch size图7 Alexnet在不同批大小下的吞吐量
图6展示了VGG19神经网络模型训练的实验结果。该模型的参数量高达1.4亿个,模型大小为534 MB,其在训练过程中的通信量很大。从图6可以看到,在不同批大小中,Gloo+表现都很优异。在批大小为16和32时,Gloo+相对于Gloo能够达到1.1以上的加速比,而在批大小为64和128时,则分别能够有0.7和0.4的加速比。相比于以太网模式下的MPI,在批大小为16和32的情况下,Gloo+能够达到1左右的加速比,在批大小为64和128的情况下,则有0.7的加速比。相比于IB网模式下的MPI,在4种批大小中,Gloo+的加速比依次为0.54,0.49,0.47和0.35。
图7展示了AlexNet神经网络模型训练的实验结果。该模型的参数量有6 200万个,模型大小为237 MB,该模型的大小相对VGG19来说小一些,但对于其他神经网络模型来说也是一个比较大的模型,其通信开销在整个训练的过程中占比也不小。从图7可以看到,跟VGG19实验结果表现的一样,在不同批大小中,Gloo+表现依然很优异。在4种批大小中相对于Gloo和以太网模式下的MPI均能够达到1.1以上的加速比,而相对于IB网模式下的MPI其加速比依次为0.26,0.34,0.52和0.36。
通过对以上实验结果的分析发现,当深度学习神经网络模型参数数量较多时,其通信量则相应地会比较大,那么Gloo+就能够使得神经网络模型训练性能得到很大的提升。当批大小越小时,训练完整个数据集所需要的迭代次数越多,相应的通信频率就越高,那么此时Gloo+也能表现出很好的训练性能,极大地减少模型训练的通信开销。总而言之,Gloo+不仅在基准测试中表现优异,在分布式深度学习模型训练的应用中也展现出了很好的效果。
5 结束语
本文设计并实现了基于SHARP的聚合通信库Gloo+,使分布式深度学习训练能够利用网络的计算能力来加速聚合通信操作。本文评估了Gloo和Gloo+中聚合通信操作的性能,并且将Gloo+集成到Horovod中,然后使用MXNet在Horovod中训练神经网络模型,从而评估Gloo+在实际应用场景中的真实效果。
本文对Gloo+的实验评估结果表明,不管是在Allreduce、Reduce和Allgather等基准测试中,还是在分布式深度学习训练的实际应用中,Gloo+的表现都极其优秀。
