基于改进Deformable DETR的无人机视频流车辆目标检测算法*
2024-01-24江志鹏王自全张永生程彬彬赵龙海张梦唯
江志鹏,王自全,张永生,于 英,程彬彬,赵龙海,张梦唯
(1.战略支援部队信息工程大学地理空间信息学院,河南 郑州 450001;2.32016部队,甘肃 兰州 730000)
1 引言
近年来,随着算法的不断优化以及算力和数据量的快速增长,基于深度学习的计算机视觉技术研究进入了新的发展时期。其中,目标检测作为计算机视觉技术研究的重要分支,是根据神经网络模型的输出将图像中的目标以边界框的形式提取出来,并且赋予目标类别与置信度信息,可认为是图像分类技术向“对象级”应用的延伸。当前,目标检测已经广泛应用于自动驾驶[1]、遥感图像解译[2]、智能交通[3]、人脸识别[4]和场景行为对象追踪[5]等领域,对于推进智慧城市的智能化和信息化有着重要作用。
1.1 基于卷积神经网络的单帧目标检测算法
早期的目标检测算法主要依托人工设计的特征,采用支持向量机[6]、HOG(Histogram of Oriented Gradient)[7]等策略对预先设定好的目标候选区域进行分类。在卷积神经网络CNN(Convolutional Neural Network)技术兴起后[8],循环卷积神经网络RCNN(Region-CNN)系列算法[9-11]开启了双阶段目标检测算法的研究,其基本思想是:首先使用一个网络模型RPN(Region Proposal Network)生成若干候选框,然后在检测头部对RPN产生的候选框进行边框回归和分类,最后经过非极大值抑制NMS(Non-Maximum Suppression)计算得到预测结果。在经典的Faster R-CNN算法[11]中,引入了锚框机制,即预设一定数量和大小的候选框位置、尺寸,后续预测真实物体和锚框之间的偏移,有效提升了目标检测的可靠性与收敛性。
由于神经网络模型只能接受固定格式的张量输入,而RPN提取出的感兴趣区域形状大小不一,Fast R-CNN[10]为了解决这一问题提出了感兴趣区域池化(Region of Interest Pooling)技术,将所有的感兴趣区域池化到同样的大小后再输入后续的检测头中。然而,这样势必会导致物体变形。Purkait等人[12,13]先后提出了SPP-Net(Spatial Pyramid Pooling Net)和新的感兴趣区域空间对齐方式ROI-Align。SPP-Net根据输入图像大小不同,采用空间金字塔池化结构(Spatial Pyramid Pooling Layer),将不同尺度的信息池化为固定长度的特征向量后再组合。采用这种方式获取图像对应的特征时,不仅允许在训练时输入不同尺寸的图像,也允许测试时输入不同大小的图像,整体逻辑更为清晰简明。ROI-Align[13]采用双线性插值法,对感兴趣区域映射到的空间进行更加精细的采样,有效提升了中小目标的分割与检测精度。
为了提高目标检测的效率,有研究人员开始尝试不在中途提取候选区域,而是直接预测目标所在的位置和类别,这种做法被称为单阶段目标检测技术,如YOLO(You Only Look Once)系列[14-17]。其中,YOLOv1[14]将图像划分为固定大小的网格组合并对网格进行回归操作,检测出的结果较为粗糙且容易漏检;YOLOv2[15]引入了锚框机制,并进行了维度聚类,提升了模型的准确率;YOLOv3[16]采用了多尺度特征融合的做法,提升了小目标检测的有效性,并且保持了原有的计算速度;YOLOv4[17]则采用了大量模型构建技巧,并将目标检测网络划分为特征提取网络(Backbone)、特征聚合网络(Neck)及目标检测头(Head)。在后续非官方的YOLO系列(v5~v7)[18,19]中,大量新的特征融合方式被引入进来。同时期的单阶段目标检测网络还有SSD(Single Shot multibox Detector)[20]等。
单阶段目标检测算法是“密集预测”思想的典型代表。由于没有RPN网络生成有限数量的候选区域,单阶段目标检测网络将锚框设置到了原始图像的每一个像素上,并且为了考虑多尺度的特征融合模块,特征图也被设置了锚框[21]。在训练过程中,网络同时对数十万个锚框进行偏移量的预测与回归,而其中真正含有目标的锚框只占很少一部分(称为“正样本”,对应不含目标的锚框称为“负样本”)。正负样本数量的极大不平衡是单阶段目标检测网络始终面临的问题。对此,RetinaNet[22]提出了FocalLoss,侧重以损失函数的形式调节模型训练的关注度,从而增加对正样本的学习有效性。有些研究人员还开发了无需锚框(Anchor-free)的算法,典型的有CornerNet[23]和CenterNet[24]等。
1.2 基于Transformer的单帧目标检测算法
可以看出,目标检测技术存在大量人工设计的步骤,例如人工设计的锚框、非极大值抑制的后处理等,其中超参数的设置对提高模型性能起到了关键作用。单阶段目标检测算法中,密集预测的方式并不符合智慧生物对场景中目标的认知方式,这导致基于CNN的目标检测结构难以做到“简洁”的端到端训练与测试。将Transformer[25]技术应用到计算机视觉后,这一问题有了新的解决思路。Carion等人[26]开发了基于Transformer的端到端目标检测模型DETR(DEtection TRansformer)。DETR将经过ResNet[27]骨干网络的图像特征进行序列化,然后经过编码器(Transformer Encoder)得到图像上各部分的关联特征,而后设计指定数量的物体查询向量object_query,连同编码器Transformer Encoder输出的特征进入解码器(Transformer Decoder),最后经过前馈网络FFN(Feed Forward Network)进行维度变换,得到不多于指定object_query数量的目标分类和定位结果。检测出的目标根据其位置和真值标签进行匈牙利匹配,最后利用损失值构建矩阵,选其中最小的损失作为模型的损失驱动训练。因此,DETR无需锚框、无需NMS后处理,并且将密集预测方式转换为依托固定数量object_query的预测,无需考虑正负样本失衡问题,是目标检测领域里程碑式的创新。
然而,DETR的缺点也很明显:首先,基于Transformer的目标模型收敛速度过慢,DETR在COCO目标检测数据集[28]上训练了500个epoch才达到较好的精度,这是因为注意力图过大,加之Transformer模型和CNN模型相比,没有良好的归纳偏置[29],导致在训练过程中注意力图从稠密转至稀疏需要很长的时间,而一般的目标检测算法只需要约36个epoch;其次,DETR受限于自注意机制(Self-Attention)所需要的庞大计算量,只能使用骨干提取网络的最后一层输出作为序列化输入,也没有多尺度的操作策略,这些原因导致其对于小目标的检测效果较差。针对这2个问题,Zhu等人[30]提出了基于多尺度可形变注意力MDA(Multi-scale Deformable Attention)的Deformable DETR。该方法在特征提取部分引入了多尺度的特征融合模块,并且接受多尺度特征的输入。在计算注意力的核心模块中,不再使用逐点对齐的密集注意力,而只根据当前点的特征,仿照可形变卷积[31],选择性地在多个尺度的特征图上计算偏移量,找到K个关联点,然后只使用这K个点计算注意力图,极大地减小了注意力图的尺寸,从而加速了模型的收敛,并且由于使用了跨尺度的表示方法,Deformable DETR的小目标检测性能也得到了改善。
1.3 视频流目标检测算法
视频流目标检测算法的基本思想是利用视频连续帧之间的相似度,对特征进行聚合补充,从而提升目标检测性能。Zhu等人[32]提出了面向视频识别的深度特征流(Deep Feature Flow)。若将一个典型的目标检测网络划分为特征提取网络Nfeat和特征解码网络Ndet,则Ndet的运行开销远小于Nfeat的。因此,该方法以固定的间隔获取关键帧,只在关键帧上运行特征提取网络Nfeat,然后利用光流网络FlowNet[33]计算各参考帧与关键帧之间的光流,将关键帧上提取好的特征传播到参考帧上,最后运行Ndet,从而加速了视频目标检测的速度。在后续的工作中,Zhu等人[34]提出了由光流引导的特征聚合方法FGFA(Flow-Guided Feature Aggregation)。该方法利用时间信息聚合相邻帧的特征,从而提升了每帧的特征质量。
2019年,Wu等人[35]提出了序列层级语义聚合的视频目标检测方法SELSA(SEquence Level Semantics Aggregation),该方法认为特征的融合应当由语义的相近程度引导,而不是时间的接近程度。因此,SELSA中完全随机采样参考帧进行融合,没有过多地考虑时序信息和局部语义信息,只利用全局信息,对双阶段目标检测器提取的候选区域进行融合,实现了鲁棒性更强的相似度引导。在此基础上,Chen等人[36]提出了基于记忆信息增强的全局-局部特征聚合方法MEGA(Memory Enhanced Global-local Aggregation)。他们认为只聚合相邻的特征并不足以持续地对视频整体进行理解和建模,因此提出了新型的长距离记忆LRM(Long Range Memory)机制,当检测器抽取当前帧时,MEGA会从LRM中抽取之前的几帧进行信息交互,从而有效提升了MEGA对视频的全局建模能力,取得了视频流目标检测领域的最好表现。
然而,基于光流和基于语义引导的目标检测方法均不适用于无人机视频检测任务。首先,在标准光流训练数据集(如Flying Chair)[33]上预训练好的FlowNet网络,在无人机目标检测下没有对应的损失函数计算方法,即利用无人机视频数据集进行模型训练时,对基于光流网络构建的特征融合模块起作用的是依托于目标框损失的“间接监督”;而近景数据集和无人机视频数据集在视角、目标变换上的差异十分显著,导致光流网络计算出的结果十分模糊,难以体现目标层级的空间变换,在聚合特征时反而容易引起错误和缺漏导致精度下降。采用视频流目标检测算法得到的检测热力图和特征传播光流图如图1所示。

Figure 1 采用视频流目标检测算法得到的检测热力图 和特征传播光流图(数据集为UAVDT)图1 Detection heat map and optical flow map of feature propagation obtained by video stream target detection algorithm (Dataset is UAVDT)
其次,使用特征融合和语义引导的方法,时间和运算资源消耗较大。FGFA聚合前后15帧特征时,运算速度FPS下降为2。SELSA、MEGA等方法的运算处理速度FPS也不超过5,远不如单帧目标检测算法的。且特征融合模块占用了大量计算资源,Batchsize=1时,显存消耗约为8 GB,不利于后续的轻量化处理。最后,经过实验表明,视频流目标检测算法所能达到的最终性能,是在其基准模型上有一定的提升。因此,使用性能更好的基准模型能使视频流目标检测算法获得更好的性能。
综上,本文以当前较为优秀的单帧目标检测算法Deformable DETR为基线算法进行改进,用于无人机视频流车辆目标检测任务中。在编码器部分,融入跨尺度特征融合模块,拓展编码时每个像素级处理单元(token)的感受野,并提升每个token的上下文信息交互能力;在解码器部分,融入面向object_query的挤压-激励模块,提升关键目标的响应值;在数据处理方面,使用在线难样本挖掘方法OHEM(Online Hard Example Mining)[37],改善数据集中大多为car而bus和truck类别较少的不平衡情况。实验结果表明,本文算法能够较好地完成无人机视频流车辆目标检测任务,相较基线算法提升了性能并保持了较高检测速率,可满足实时检测需求。
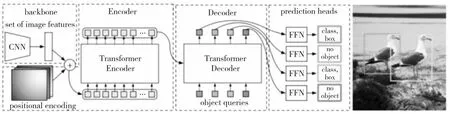
Figure 2 DETR流程图2 Workflow of DETR
2 Deformable DETR检测算法
2.1 基于Transformer的端到端目标检测
DETR使用Transformer结构完成了端到端的简洁目标检测框架,也是将Transformer较早应用到计算机视觉细分任务中的工作。其算法流程如图2所示。
首先,输入的图像在经过以ResNet为骨干网络的特征提取器后,得到输出特征,经过序列化与位置编码后,投入Transformer模块。Transformer模块由编码器Encoder和解码器Decoder构成。组成二者的部件为标准Transformer Layer,每个Layer由自注意力计算层和前馈网络FFN(Feed Forward Network)组成。从骨干网络输出的特征先进入Encoder,编码每个像素级处理单元token之间的自注意力关系,重复上述操作N次(N为Encoder中Transformer Layer的数量)。然后,编码的特征被缓存进系统,和预先设置的object_query一起投入到Decoder中。在这一步,object_query将反复和自身作Self-Attention计算,这是为了尽量学习到物体之间的关联,使其均匀地分布在图像之中。在所有计算过程中,涉及自注意力机制的计算参数有查询向量q、关键字向量k和值向量v。q和k是带有位置编码的,而随着模型结构的固定,v也随之固定,也具备位置信息,且因结果生成需要从v上取值,故无需添加位置编码。Transformer Encoder与Decoder部分的数据流如图3所示。其中object_query表示目标查询向量,MHSA(Multi-Head Self-Attention)表示多头注意力机制层,FFN表示以多层感知机为主体的前馈网络层。

Figure 3 Transformer 编码器和解码器数据流图3 Data flow of transformer encoder and decoder
Decoder的输出向量包含所有object_query的编码信息,经过分类分支和回归框分支,得到对应每一个目标框的分类信息和坐标框信息。然后,在得到的object_query与真值框之间进行二分图匹配,构建损失矩阵,驱动模型训练。
2.2 多尺度可形变注意力机制
如前文所述,DETR使用的是标准的多头自注意力模块MHSA,其核心的自注意力图计算方式如式(1)所示:
(1)
其中,dk为注意力头的个数;Q代表用于计算注意力权重的向量,它通过与K进行点积来得到注意力分数;K是用来衡量Q与其他向量的相关性的向量;V则是包含了输入序列信息的向量。可以看出,MHSA的计算复杂度与Q和K的大小密切相关,而Q和K的维度由token的数量确定。例如,一个14×14的特征图,经过块嵌入(Patch Embedding)后的序列化特征维度为196,即token数量为196,即会产生一个由196个查询向量q组成的Q矩阵,关键词向量k和对应的K矩阵亦然。从而注意力图的大小为196×196。随着图像尺寸的增长,MHSA的计算量会以O(n2)的复杂度增加。这对于模型在下游任务上的应用十分不利,也限制了DETR只能使用骨干网络提取出的最小尺寸的特征图,从而难以对较小的目标进行识别和检测,且难以运用多尺度特征。
注意力图过大造成的另一个问题是模型收敛速度慢。式(1)中,Q和K矩阵乘法本质上是每个token彼此之间利用查询向量q和关键字向量k进行的相似度计算。在模型开始训练时,注意力图被随机初始化,是“稠密”的矩阵;在模型最终收敛时,token之间的相似度关系也被学习到,那么注意力图应该只有少部分接近1,大部分接近于0,表示网络已经学习到了特定token之间的相似度关系,即注意力图应当是“稀疏”的。注意力图很大时,从稠密到稀疏的收敛过程非常缓慢,也导致了DETR模型训练时间过长的问题。
Deformable DETR对DETR的改进主要集中在使用多尺度可形变注意力MDA替换了原有的自注意力机制,前向传播的流程与DETR的基本相同,仍是Transformer Encoder和Transformer Decoder的组合。
如图4所示,多尺度可形变注意力MDA的做法为:对多尺度特征图上的每一个token,采用线性全连接层计算n个偏移量,表征其“应该注意到”的点,在计算注意力时,聚焦在这有限个token上,从而极大地减少了注意力计算的成本。在Encoder部分,MDA模块将输入的多尺度特征图上每一个token都进行了编码,并存储进缓存中备用。在Decoder部分,MDA则将object_query表示为可学习的锚框,只对固定数量的目标查询向量编码query_embedding进行操作,经过位置编码后,和Transformer Encoder上下文信息进行注意力交互计算,从而查询出所需要的目标信息。

Figure 4 Data flow of multi-scale deformable attention图4 多尺度可形变注意力机制计算流
3 基于改进Deformable DETR的车辆目标检测算法
3.1 算法框架
本文使用Deformable DETR作为基线网络,在Encoder的基础层中嵌入跨尺度特征融合模块,在Decoder的基础层中嵌入object_query挤压-激励模块。在进行编码时,数据先经过其自有的MDA模块,而后投入跨尺度特征融合模块中进行整合,旨在进一步增强其空间感知能力。在进行解码时,query_embedding向量和Encoder编码向量进行多尺度交叉注意力机制计算,然后投入object_query挤压-激励模块,旨在赋予每个目标不同的权重,以突出关键目标的重要性。在训练时,采用在线难样本挖掘策略,以缓解数据集类别样本不平衡的问题。算法整体框架如图5所示。
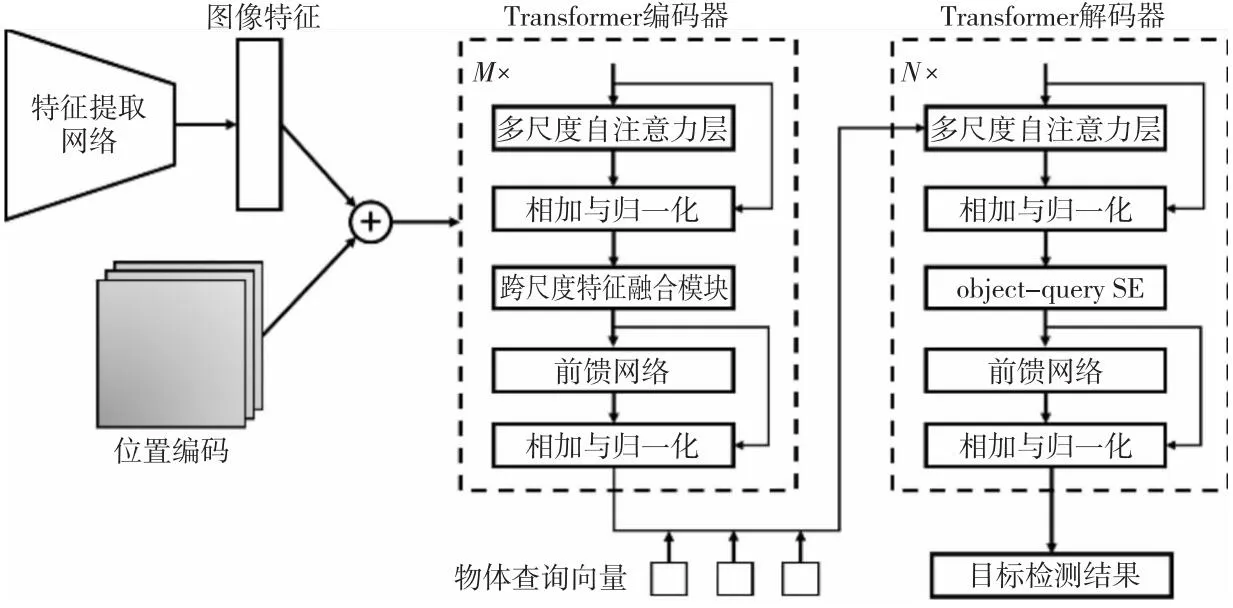
Figure 5 Algorithm framework图5 算法框架
3.2 跨尺度特征融合模块
在卷积神经网络中,卷积核大小决定了当前卷积后特征图感受野的尺寸。对于不同尺寸的目标而言,使用不同尺寸感受野的特征图能够更好地接近真实物体的轮廓。对于在视频流中不断变化的车辆而言,目标变化过程具有多尺度、多角度的特性,故设计能够融合多个感受野的跨尺度特征融合模块CRF(CRoss scale feature Fusion)对提升目标分类和定位精度有着重要作用。受语义分割算法Deeplab[38]启发,考虑到Deformable DETR在单个MDA模块中融入了4个尺度的信息,所以设计了4条并行的跨尺度特征融合模块。
如图6所示,设定输入图像高度为H,宽度为W,则第i个尺度的高度和宽度如式(2)所示:
(Hi,Wi)=(H/2i,W/2i),i=0,1,2,3
(2)
所有待编码的token数量如式(3)所示:
(3)
每个尺度的起算点如式(4)所示:
(4)
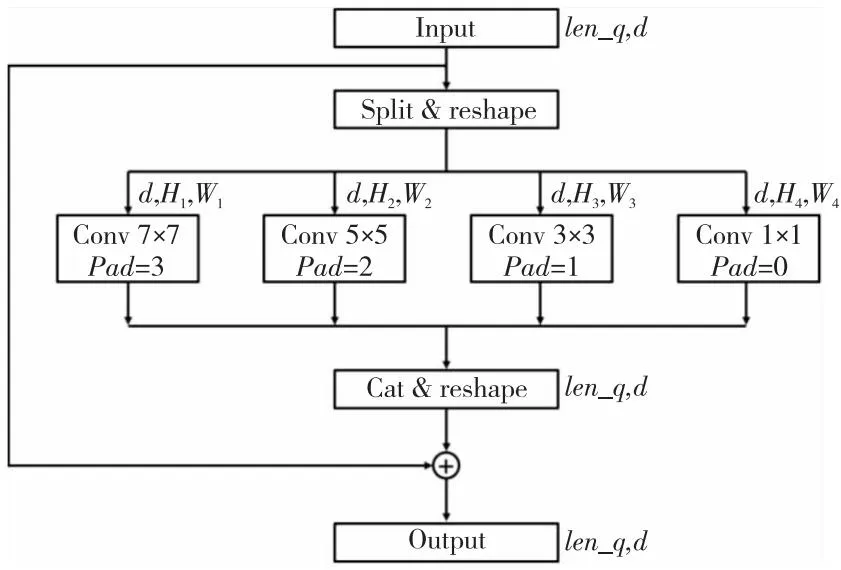
Figure 6 Cross scale feature fusion module图6 跨尺度特征融合模块
设模型的通用编码维度为D,批处理大小为B,则图6中输入的维度为[B,N,D]。然后,经过一个线性层将其映射为具备较低描述维度d的向量,再按照每个尺度的起算点对映射后的输入进行切分并重新排列成4个二维特征图t,其尺寸如式(5)所示:
Size(ti)=[B,d,Hi,Wi],i=1,2,3,4
(5)
设置卷积核大小为klist,分别作用在输出的特征图上,如式(6)所示:
Xi=Convklist[i](ti)
i=0,1,2,3,klist=[7,3,5,1]
(6)
多尺度卷积步骤完成后,重新排列成序列输入格式,按照通道维度进行拼接,再使用一个线性层,将拼接后的现有维度特征d映射回原有的维度D。这样,不同尺度的信息就通过拼接和线性层映射操作得到了强处理。借鉴残差网络思想,该部分的输出经过Sigmoid激活函数之后,和原有输入相加得到最终结果。
3.3 object_query挤压-激励模块
object_query是模型查询图像上某一位置是否存在目标的向量,而模型根据Encoder提供的特征图来提供答案。在训练结束时,object_query的关注点和物体的位置将十分贴合。设object_query的维度为n_query,通常设置为100或300。在本文数据集中,单个图像上的目标数量一般在50个左右,因此设置的object_query数量存在冗余。原有的object_query经过编码后的query_embedding向量在重要程度上是均匀的,基于此,本文借鉴SENet[39]思路,设计了面向object_query的挤压-激励模块OqSE(Object_query Squeeze-and-Excitation),如图7所示。
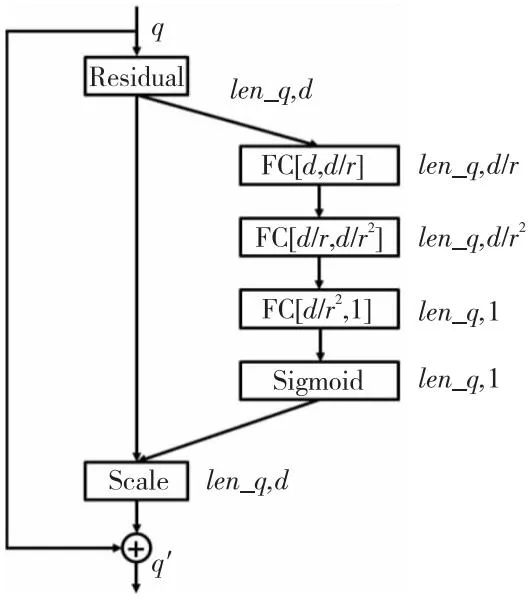
Figure 7 Decoder layer with object_query squeeze and excitation module图7 带有object_query挤压-激励模块的解码器层
对于具备D维描述特征的query_embedding向量,对其包含的信息进行逐层降维(Reduction)操作。本部分即Transformer Decoder采用一个渐进式降维多层感知机MLP(MultiLayer Perceptron)逐渐将query_embedding的维度降为1,对每个特征赋予权重。该部分的数据流可描述为式(7):
s=z(1+σ(z·MLP(z)))
(7)
其中,OqSE模块的输入为z,MLP(·)为采用的多层感知机结构,s为模块的输出,σ(·)为Sigmoid激活函数。
3.4 在线难样本挖掘
在线难样本挖掘OHEM[37]是一种缓解数据集中样本类别不均衡以及识别难度大等问题的方法。其基本假设为:数据集中某一类的数量很少时,网络模型学习到该类样本特征的次数少于其他类样本的,导致难以对该类样本进行正确分类和定位,称这类样本为“难样本”。
本文所使用的UAVDT(UAV Detection and Tracking benchmark)数据集中,类别car的样本数远多于bus和truck的(如表1所示)。且存在不同角度、不同时间和不同天气状况下拍摄的大量小目标。基于此,本文采用OHEM算法来加强对难样本的训练,对训练过程中各个样本的损失进行排序,选择损失较大的样本投入负样本池,增加其被学习到的次数;而对于损失较小的样本则认为已经学习到其正确的检测知识,赋予较小的权重。此方法能有效提高对bus、truck这类小样本以及小目标的检测性能。

Table 1 Statistical table of dataset annotation information表1 数据集标注信息统计表
4 实验与结果分析
4.1 实验环境及数据集
数据集采用无人机视频流目标检测数据集UAVDT[40]中的多目标检测以及追踪子集UAV-benchmark-M。该子集包含50个视频序列,共40 409幅图像,依据视频序列的个数按照3∶2的比例划分出训练集和测试集。其中训练集包括30个视频序列(含23 829幅图像),测试集包括20个视频序列(含16 580幅图像)。部分标注图像如图8所示。

Figure 8 Examples of UAV-benchmark-M图8 数据集标注实例
数据集的类别不均衡,car的数量远高于另外2类的。如表1所示。除了类别不均匀,数据集中也包含了大量的小目标,如图9所示。绝大多数目标的面积均小于50 × 50像素,其中有2/3的目标面积小于32×32像素,符合MS COCO(MirocSoft COmmon objects in COntext)数据集对“小目标”的定义。宽高比分布相对较为均匀,但仍存在一部分较为狭长的目标,这些因素的存在均对检测性能提出了一定挑战。
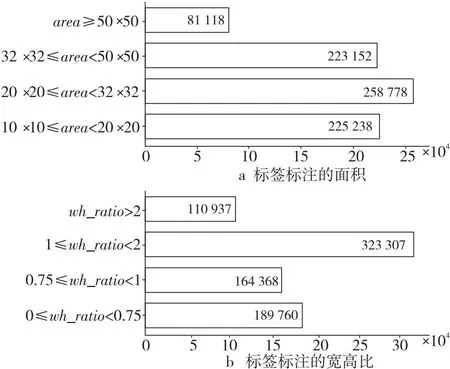
Figure 9 Area and statistical data of annotations图9 标签标注的面积和宽高比情况
算法依托深度学习框架PyTorch[41],版本为1.6.0,使用NVIDIA的Tesla v100进行训练。使用OpenMMLab(Open MultiMedia Lab)中的MMDetection(open MMLab Detection toolbox and benchmark)[42]和MMTracking(open MMLab multiple object Tracking toolbox and benchmark)框架完成相关对比实验,具体见表2。

Table 2 Experimental environment表2 实验环境
4.2 评价指标
在目标检测研究中,常用MS COCO[28]中的评价指标来衡量性能。主要指标是平均精度AP(Average Precision),表征了对某一类目标的检测性能。AP由交并比IoU(Intersection-over Union)确定,即预测目标框与真值目标框的重叠程度。其他评价指标还包括参数量Param以及每秒可检测的帧数FPS(Frames Per Second)。本文所使用的评价指标如表3所示。
4.3 实验结果分析
将本文算法在UAV-benchmark-M上进行训练,得到改进的网络模型和权重文件。验证算法性能时,选择了11个经典的目标检测算法进行性能对比。

Table 3 Evaluation indexes表3 评价指标
实验采取原始Deformable DETR的结构,用原有的Channel-Mapper进行特征融合,将不采用在线难样本挖掘的算法作为基线算法。实验结果如表4所示。从表4可以看出,本文算法与基线算法相比,在没有显著增加模型大小的情况下,检测精度得到了提升,其中在mAP、AP50和AP75等指标值分别提升了1.5%,1.6%和0.8%,表明本文的改进工作能够提升Deformable DETR的性能;本文算法在APs、APm、APl上也均有提高,小目标检测平均精度相较于基线算法的提升了1.8%,中等目标的平均精度提升了1.2%,大目标的平均精度提升了2.2%。相比于其他算法,本文算法在精度上也达到了最好的性能,说明本文的创新点可以有效提升模型的检测能力。此外,本文算法相较于基线算法仅增长了0.4×106的参数量,FPS仅减少了0.2,计算消耗并不大。在视频流目标检测算法中,采用了DFF、FGFA和SELSA共3种不同的视频流目标检测算法。可以看到,无论是仅有特征传播的DFF,依托光流特征融合的FGFA,还是基于语义融合的SELSA,在采用相同检测器Grid-RCNN+FPN的情况下,这些算法的性能均较单帧检测器的有所损失,这是特征传播不准确导致的。除DFF在算法运行速度上大幅提升之外,FGFA和SELSA的检测速度也因光流融合而被拖慢,难以满足无人机视频流实时与近实时的目标检测需求。
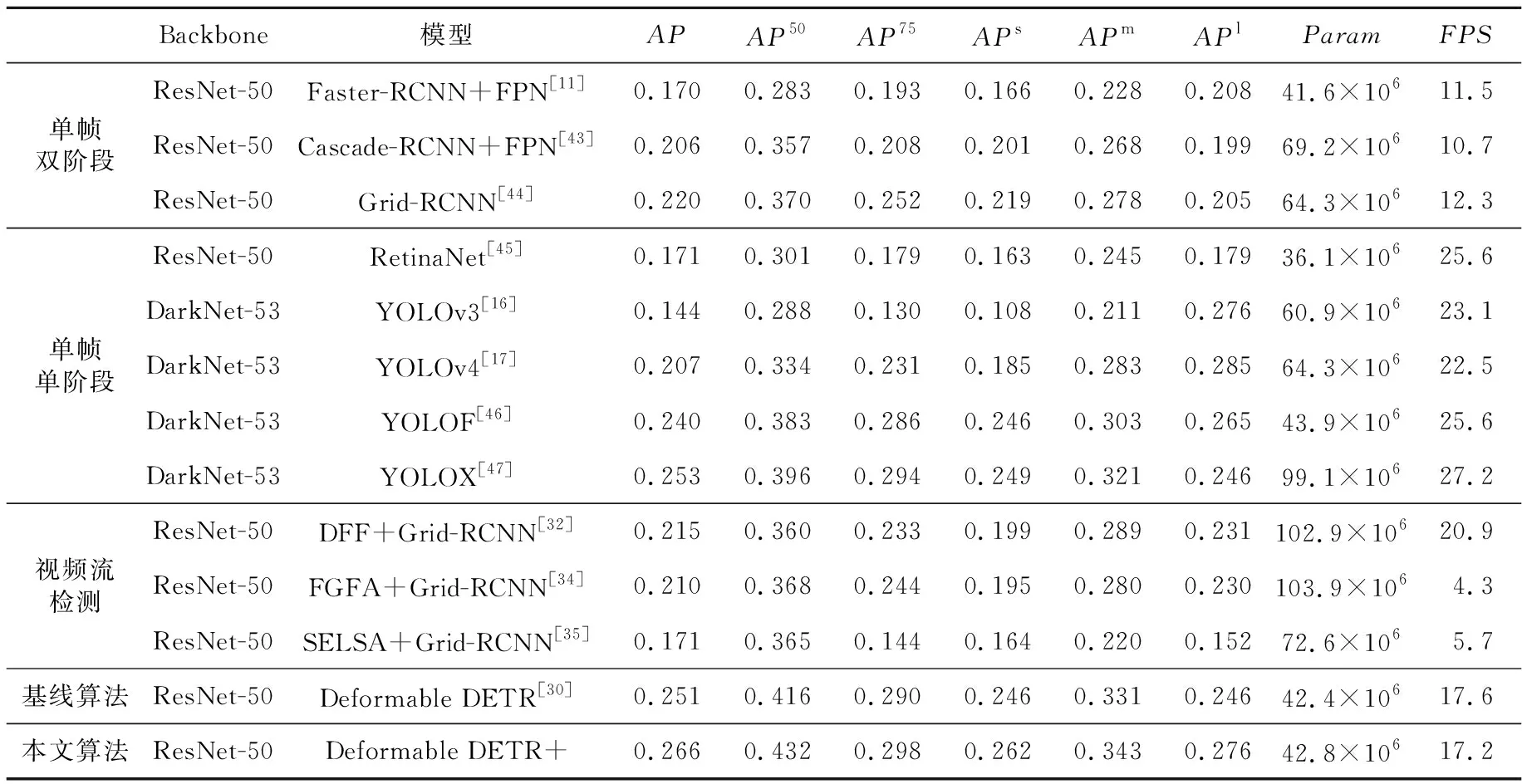
Table 4 Results comparison of different algorithms表4 不同算法结果对比
本文算法和基线算法的检测结果对比如图10所示。图10a中本文算法能准确检测出公交车,然而基线算法将卡车视作数段普通车辆,说明本文算法相较于基线算法更注重整体性且突出了关键目标。图10b中基线算法出现了误检测,将收费站的柱子判断成了车辆,本文算法误检测较少。图10c中基线算法将公交车识别错误,但本文算法能够识别正确。图10d中基线算法在小目标和查全率上均不如本文算法。同时发现,虽然图10a和图10b中改进算法相对于基线算法存在漏检现象,但由于数据集中该类目标(目标区域只有部分在图内)未进行标注,从侧面证明了该检测算法对于目标全局检测能力的提升。

Figure 10 Experimental results comparison图10 对比实验结果示例
4.4 消融实验
为了验证本文工作对于目标检测算法的影响,设计了消融实验。消融实验依然以原始Deformable DETR且无OHEM辅助的算法作为基线算法进行对比。6组消融实验是单一或者两两模块的组合,最后一组是本文的完整算法,即Deformable DETR+CRF+OqSE+OHEM,具体实验结果如表5所示。
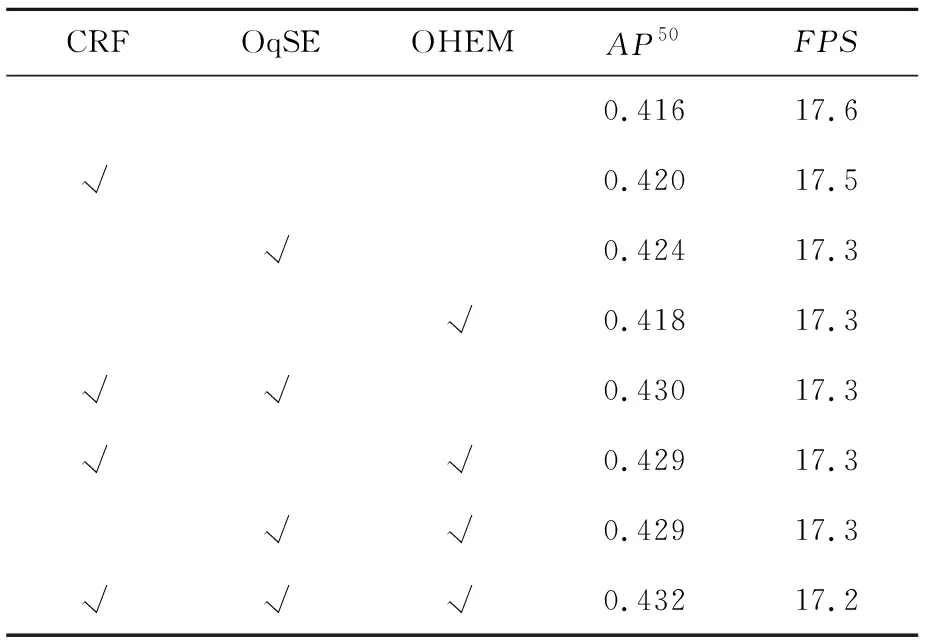
Table 5 Results of ablation experiments表5 消融实验结果
实验结果表明,单一以及组合模块的改进在检测准确度和处理速度上大多可以产生较好的优化效果,表明对原始基线算法的改进是有效的。其中,加入CRF模块可将模型的检测性能提升0.4%,加入OqSE模块可将模型性能提升0.8%,说明OqSE模块可有效提升重要目标的检测效果。在基线算法上单独应用OHEM对检测精度也有一定程度的提升。
5 结束语
本文提出了一种基于改进Deformable DETR的无人机视频流车辆目标检测算法。该算法在整体检测精度、小目标检测精度上均优于基线算法的,结合消融实验,论证了算法核心模块的有效性。本文的工作主要包括以下3个方面:
(1)针对原有Deformable DETR在多尺度上感受能力相同的特点,提出了适用于Transformer目标检测框架的跨尺度特征融合模块,并将其使用在Transformer编码器层中,提升了特征融合的效能和表现能力;
(2)针对原有Deformable DETR在object_query重要程度上均衡导致重点不突出的问题,提出了基于object_query的挤压-激励模块,并将其使用在Transformer解码器层中,使目标之间的关系得到了更深刻的表达;
(3)针对数据集中类别样本不均衡导致的训练效果不佳的问题,使用OHEM方法对损失函数进行改进,提升了基于UAVDT数据集的训练效果。
下一阶段的研究重点是进一步研究目标检测模型的特征提取能力,并尝试在更多的数据集上进行实验,以及采用知识蒸馏等策略将算法迁移至移动端平台,测试其实际检测效果。
