针对顶点策略优化的三维模型可逆数据隐藏算法
2024-01-24张国有
张国有,米 佳
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
1 概 述
随着计算机等电子设备的发展和互联网技术的普及,数字多媒体在日常生活中被广泛使用,三维模型作为一种重要的媒体类型,成为人们分享和传递信息的重要载体。由于数字化本身具有强移植和易传播的特点,给其安全问题带来了严峻的考验,譬如模型数据的窃取、盗版和非法篡改等。随着各种媒体类型外包到云端的需求越来越大,云计算为存储多媒体和数据操作提供了巨大的优势,保护隐私和数据机密性成为目前云计算技术广泛关注的问题。因此,为了防止未经授权的信息泄漏,原始模型数据在外包到云之前会被加密,云端会在网格中嵌入海量重要数据以识别模型的真实性和完整性。同时云服务提供商无权在数据嵌入信息的过程中对模型造成破坏,因此需要可逆数据隐藏(Reversible Data Hiding,RDH)技术将附加数据嵌入到数字媒体后,实现高质量恢复[1]。
应用在图像媒体的RDH技术主要分为普通域和加密域[2]。普通域包括直方图平移、差分扩展、图像插值、整数变换技术等[3-6],而加密域根据是否需要对图像媒体进行预处理分为加密后腾出空间(Vacating Room After Encryption,VRAE)[7-9]和加密前预留空间(Reserving Room Before Encryption,RRBE)[10-13],其中VRAE框架是图像媒体直接在云端进行加密嵌入,RRBE框架通过加密前预留空间获得大量冗余提高嵌入率。
现有的三维模型的RDH方法主要分为四个域:空间域、变换域、压缩域和加密域。空间域方法[14-16]利用网格的空间相关性来嵌入数据,例如通过修改顶点坐标和网格拓扑结构进行嵌入。变换域方法[17-19]是将数据嵌入到变换系数中,并且文献[19]将附加信息嵌入到模型的颜色信息中,通过傅里叶变换提高算法的性能。压缩域方法[20-22]是通过压缩网格顶点将数据嵌入到模型中。
加密域中的RDH则是一种更为可靠的方案,它可以起到更好的隐私保护作用[23-27]。Jiang等人[23]使用缩放和量化将三维网格模型的顶点坐标映射到整数,通过流密码加密获得加密的网格,翻转加密坐标的几个最低有效位(LSB)嵌入附加数据。在接收端对标记的加密网格进行解密,然后利用设计的平滑度量函数实现数据提取和网格重建。但此算法在嵌入容量和重建网格质量方面存在不足。为了改善算法性能,许多研究者针对文献[23]提出改进[24-27]。
Li[24]将三维模型划分为不重叠的补丁,用每个补丁的三个方向值来嵌入水印提高嵌入率.。Shah[25]提出了一个同态Paillier密码系统的两层RDH框架,这种框架在简单和密集的网格上成功实现了高嵌入率。Xu[26]提出了一种预测误差检测的方法,利用环预测提高嵌入率及恢复质量。Hao[27]采用交叉预测及自适应阈值来提高安全性,但是由于加扰与嵌入的统一进行,模型恢复质量不被确定。
通过对以上方法的分析,为解决高嵌入率下的模型恢复质量问题,该文利用预测策略和拉普拉斯算子进行优化,提出一种针对模型顶点策略优化的可逆数据隐藏算法,通过划分全邻域计算新的重心顶点集合,采用预测策略预测所有顶点集合的最高有效位来确定最大嵌入长度,在接受端迭代半窗拉普拉斯算子得到光滑的恢复模型和局部细节特征, 提高嵌入率和重建网格质量,并采用余切拉普拉斯算子对模型进行可视化分析,提高人眼对恢复模型感知力。
2 方 法
三维网格模型以各种文件格式表示,例如OFF,PLY,OBJ等。假设M=(V,E,F)是一个给定的包含了N个顶点的三角网格模型,其中V表示模型中顶点的集合,E表示模型中边的集合,而F表示模型中面的集合。E与F为网格的拓扑部分即连接关系。
2.1 预处理
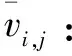
(1)
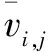
(2)
bi,j,w为整数坐标的二进制位表示,即原始网格的二进制坐标形式。接收者可以通过式3将处理后的整数坐标转换为浮点坐标,以便对网格模型进行光滑处理。
(3)
m是确定网格无损恢复的重要参数。m的值对应于整数坐标的位长L为:
(4)
不同的m对应不同的位长L,这意味着m影响恢复网格的恢复质量和每个阶段的运行效率。
根据模型顶点的浮点值压缩为整数坐标值后,发送方按照升序遍历网格数据中的所有顶点,根据顶点之间的拓扑信息计算预测集合C和参考集合R。首先遍历数据中的第一个顶点,将这个顶点加入到C中,找到它的相邻顶点加入到R中,得到一环局部平均邻域(全邻域)。
遍历完所有顶点的全邻域后进行划分,从而计算新的重心顶点集合E进行顶点值预测。全邻域处理的具体算法步骤如下:
(1)计算顶点V0的坐标值为vi,其微分坐标即δ坐标,如式5所示。
(5)
其中,δi=(δx,δy,δz),|NV(vi)|是vi的相邻顶点的集合即全邻域,如图1(a)。|NV(vi)|也是vi的直接邻居数。
(2)计算vi的质心,如式6所示,检索其他邻居到全邻域平面的最短距离。选择距离最短的邻居并将其与vj配对,将NV(vi)与直线vi,vk分为左和右两个邻域(子集/窗口)即生成2|NV(vi)|。
(6)
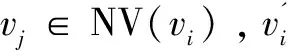
(7)
遍历其中一个子集的所有顶点和面,分配大小为顶点数和面数之和的空间,利用网格结构拓扑关系连接新顶点坐标,如图1(b)。将所有新顶点坐标添加到一个新的顶点集合,即重心集合E。
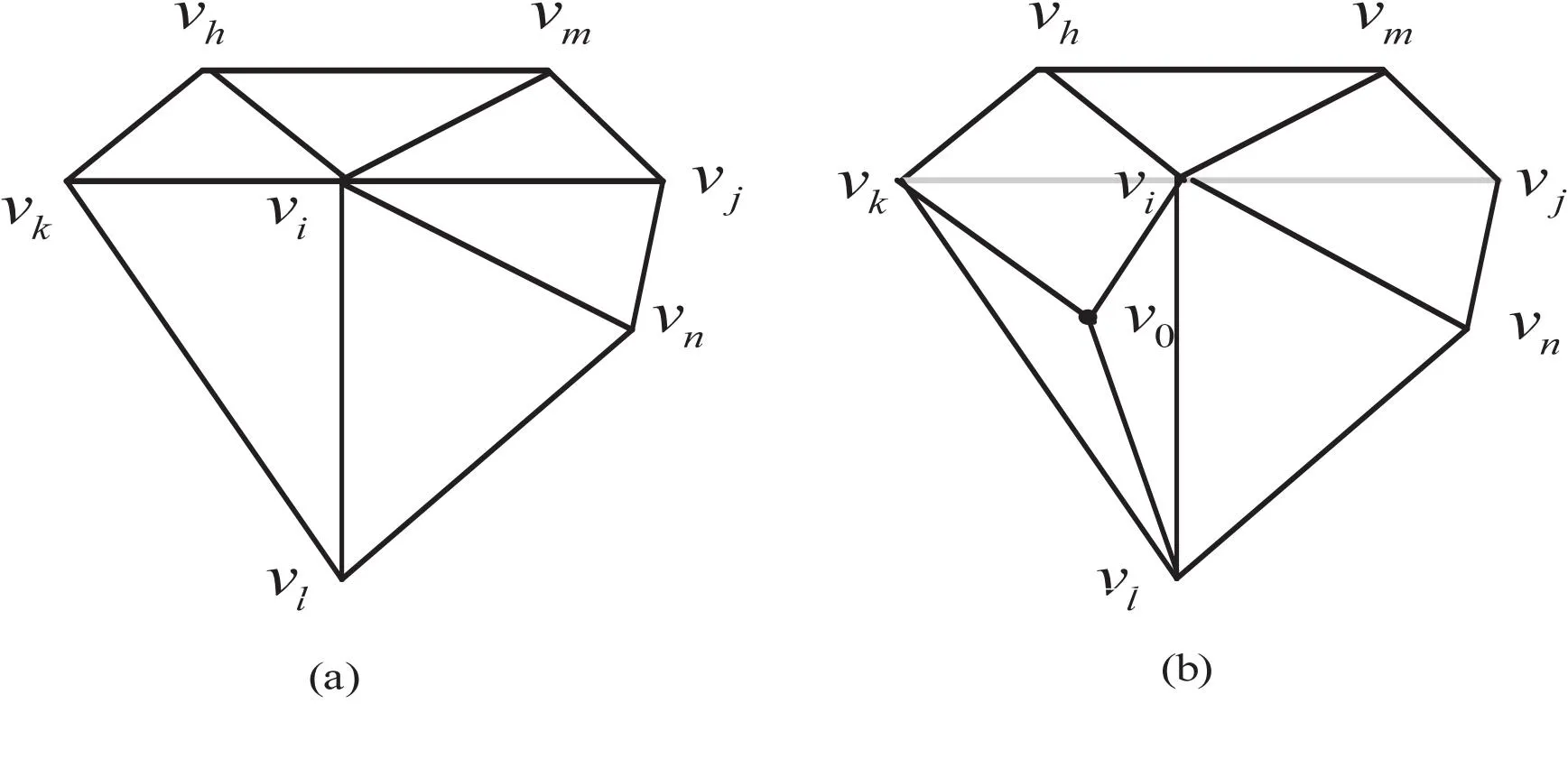
图1 平面上全邻域划分及重心添加图示
2.2 预测策略
嵌入重要数据前对模型顶点进行预测检测可以获得大量冗余[26],从而提高嵌入率。数据嵌入时除了使用顶点笛卡尔坐标的三个坐标向量、两个原始顶点集合外,新顶点重心集合也用于预测策略,从而进一步实现高嵌入。
预测集合C与重心集合E归为嵌入集合,用于嵌入附加数据,参考集合R用于在整个过程中不修改顶点的情况下恢复网格。测试C与E中的顶点是否有预测误差以及可嵌入顶点的最大嵌入长度,而具有预测错误的顶点不进行数据嵌入。预测策略步骤如下:
(1)将求出的重心坐标转化为二进制坐标,如公式8:
(8)
其中,bi,j,c表示重心坐标的二进制流。
(2)以图2为例,以坐标x向量为例进行两次预测,分别为E和C,R之间的预测以及C和R之间的预测。
(3)对于新顶点集E,如果C和R的坐标0的个数大于等于1的个数,则预测位为0;如果0的个数小于1的个数,预测位为1。
(4)从MSB到LSB依次比较各坐标的每一位直到某一位出现不同,在这一位置进行取反与前面的相同位的位数(label)一起得到最大嵌入长度为 label+1位。
(5)同理,在确定C的最大嵌入长度时用R进行预测,如果R的坐标0的个数大于等于1的个数,则预测位为0;如果0的个数小于1的个数,预测位为1。
(6)对于坐标的y向量和z向量使用相同的预测策略,最大嵌入长度为每个集中所有顶点的最大嵌入长度。
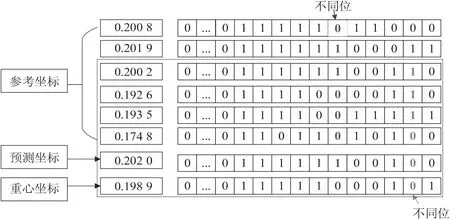
图2 预测策略图示
2.3 流密码加密
为了确保在云端存储的安全性,发送端对预测策略下的集合数据进行流密码加密,如式9、式10所示:
bi,j,k=bi,j,w∪bi,j,c
(9)
ei,j,k=bi,j,k⊕si,j,k
(10)
其中,si,j,k是二进制随机密码流,bi,j,k是坐标二进制位,ei,j,k是生成的密码,⊕为异或运算。
(11)
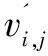
2.4 数据嵌入
发送方将嵌入集合中的数据嵌入到每个顶点的附加信息长度中,将x,y和z坐标值的t+1个MSB替换为t+1位进行嵌入,即在嵌入集合中的每个顶点嵌入3×(t+1)位。发送方获得带有附加数据的加密网格,即标记的加密网格。
(12)
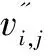
2.5 数据提取
在收到标记的加密网格后,接收者可以使用数据隐藏密钥提取附加数据,或者选择直接对网格进行解密及光滑恢复。
从嵌入集合的顶点坐标中提取没有预测误差的t+1个MSB,然后使用数据隐藏密钥获得相应的明文附加数据。
(13)
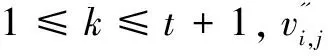
2.6 网格解密及光滑恢复
使用加密密钥对标记的加密网格执行异或解密,恢复参考集合的坐标,根据预测策略,恢复嵌入集合的坐标,同时为了更好地去除噪声和减轻收缩,采用半窗拉普拉斯算子对模型进行光滑恢复,以此保留网格模型的特征[28],实现高质量恢复。光滑恢复的算法步骤如下:
(1)计算顶点vi的法向量,如式14:
(14)
对每一个子集有:
(15)
(2)将半窗拉普拉斯算子投影到2|NV(vi)|的传统拉普拉斯算子上,如式16:
δi=(di·ni)ni
(16)
其中,Vsub是所有子集,d表示半窗拉普拉斯算子,n表示传统拉普拉斯算子的方向。
(3)计算每个顶点的正则化能量,如式17:
(17)
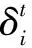
(4)采用半窗拉普拉斯算子迭代更新顶点位置使模型趋于平滑。
Vt+1=Vt+λdt∇2Vt
(18)
其中,dt为时间步长,λ是热扩散中的扩散速度, ∇2Vt是给定网格顶点上的梯度散度。
3 实验结果及讨论
文中算法在The Princeton Shape Retrieval and Analysis Group(http://shape.cs.princeton.edu/benchmark/)和The Stanford 3D Scanning Repository(http://graphics.stanford.edu/data/3Dscanrep/)数据集上进行测试,并从以下几个方面分析了该方法的性能:嵌入容量、恢复质量以及阈值m及顶点处半窗拉普拉斯算子迭代次数对恢复模型质量的影响。同时与现有文献进行了比较来评估对比不同模型和不同方法的算法性能,最后采用平均曲率进行可视化分析。
3.1 实验环境
算法程序在Windows10,Visio Studio 2017开发,搭建matlab环境实现优化顶点策略,并配置OpenGL开发环境实现模型渲染。实验服务器为CPU:i7-10870H(8核 2.20 GHz),系统内存16 GB,硬盘512G。
实验中相关参数设置如下:算法阈值m是在恢复模型质量和过程的计算开销之间的权衡,在m对应的整数坐标位长L={8,16,32,64}中寻优取得,迭代次数t是模型恢复质量和人眼感知的权衡,在t={1,2,3,4,5,6,7}中寻优取得,最优参数结果在第3.3节中详细介绍。
3.2 数据集
该文使用两个数据集评估算法的有效性。(1)The Princeton Shape Retrieval and Analysis Group。这是广泛使用的三维模型库基准,The Princeton Shape Retrieval and Analysis Group共包含161个大类覆盖的1 814个.off格式的三维模型,其中907种模型用于训练和验证,剩余的907种模型通过训练后的参数来进一步得到测试集结果。(2)The Stanford 3D Scanning Repository,其数据集在.obj文件格式模型上进一步测试文中算法对密集网格的适用性及有效性。
3.3 评价指标
通过Hausdorff距离和信噪比来判断网格恢复质量,通过嵌入率判断模型嵌入的最大信息量。
3.3.1 恢复质量
Hausdorff距离和信噪比(Signal to Noise Ration,SNR)可用于测量网格的几何失真[29],Hausdorff距离是描述两组点之间相似度的度量,是对两组点之间距离的定义。
(19)
其中,M和N代表两个集合,D(M,N)代表集合M中任意点M和集合N中任意点N之间的欧氏距离。
在网格内容中加入一些噪声后网格的几何失真可以通过信噪比(SNR)来衡量,其定义如下:
SNR=
(20)
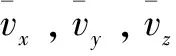
该文测试了原始模型和恢复模型之间的 Hausdorff距离和SNR,m的变化。因此,改变m的次数观察计算原始模型和恢复模型之间的 Hausdorff距离和SNR。如图3、图4所示,Hausdorff 距离随着m的增加线性减小,而SNR线性增加,表明模型的恢复质量随着m的增加而提高。可以观察到m=6平衡了模型的恢复质量和开销时间。因此,选择m=6进行实验。
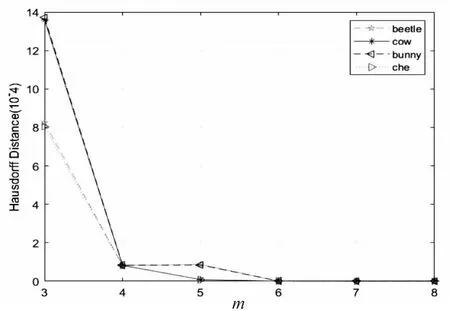
图3 测试模型在不同m下的Hausdorff距离
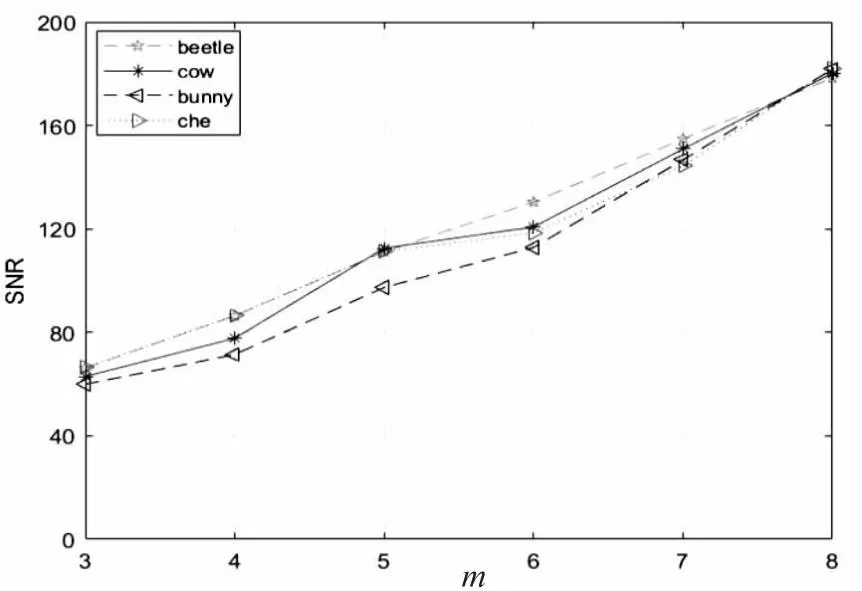
图4 测试模型在不同m下的SNR
3.3.2 嵌入容量
嵌入率是通过每顶点比特数来衡量的,它是网格模型中嵌入比特数与顶点数的比值。嵌入率(Embedding Rate,ER)越大,可以隐藏的附加信息越多。如前所述,若选取m=4的值,对应16位的二进制位长来表示整数坐标值。顶点坐标值用16位长表示,对于新嵌入集合,在一个全邻域中的可候选嵌入位数从 1×16位增加到(η+1)×16位,其中η为重心坐标个数。
3.4 不同模型的比较
该文选择测试常用模型beetle,mushroom,mannequin,将Hausdorff距离、SNR、ER与现有算法进行了比较,如表1所示,可以看出对模型顶点进行策略优化在评价指标上有一定的提高。
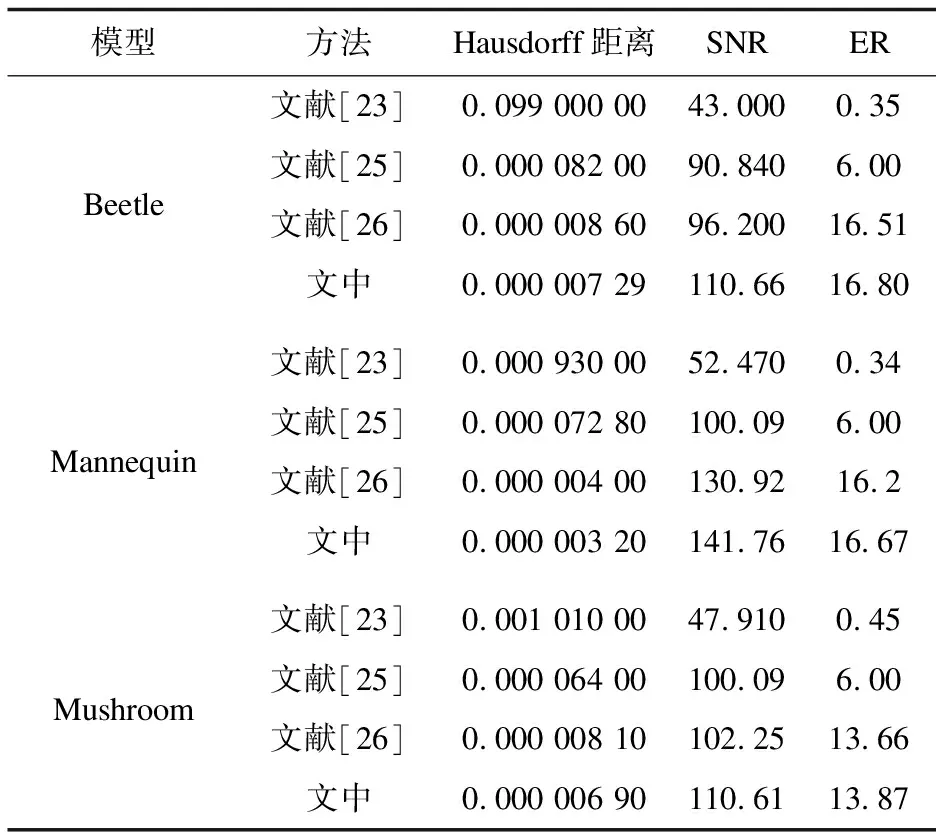
表1 不同模型在现有算法上的性能比较
3.5 不同方法的比较
将所提框架的信噪比和嵌入率与现有文献的进行了比较,如图5和图6所示。在图5中,通过半窗拉普拉斯算子恢复顶点位置,使得文中算法的SNR明显比其余算法的高,恢复质量得到提高;在图6中,新重心集合的添加增大了嵌入集合容量,优化后的预测策略增大了嵌入位,使文中算法的嵌入率比其余四种算法的高。

图5 文中方法和现有方法测试网格平均SNR的比较
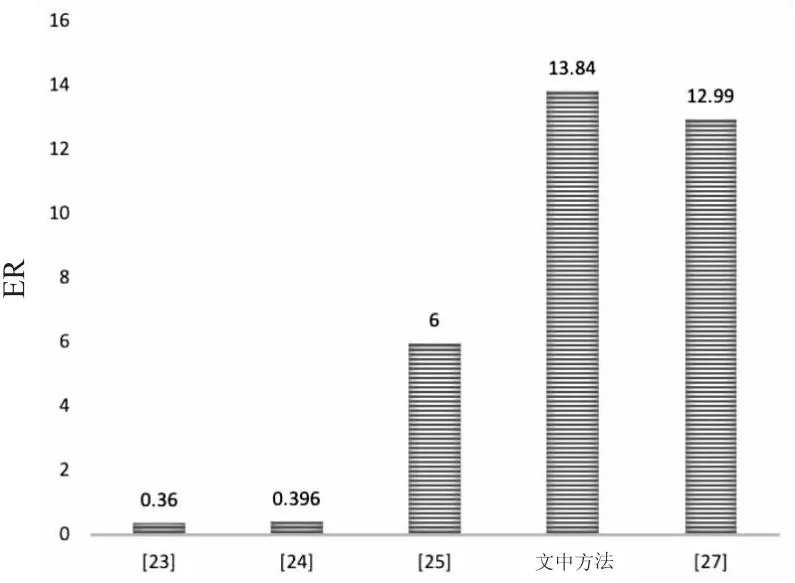
图6 文中方法和现有方法测试网格平均ER的比较
3.6 可视化展示
相比于其他算法中传统的评价指标,例如Hausdorff距离和信噪比(SNR),经过颜色渲染的网格模型更容易进行人眼感知。采用顶点余切拉普拉斯算子对应到平均曲率法线[30],绘制彩色散点图对恢复模型进行可视化分析。在图7中,模型顶点数依次由小到大排列,其中内圈代表模型颜色,外圈代表曲率颜色,不同模型有不同的曲率值,每个模型随机选取局部曲率值来映射颜色,平均曲率值越大,色彩越鲜艳。相比经过平均曲率渲染的模型,利用散点图可以看出较平坦区域颜色以青绿色为主,而曲面弯曲程度较大的部分以紫色为主,因此对于恢复模型,除传统评价指标Hausdorff 距离和SNR外,也可以通过人眼观察模型紫色区域判断恢复质量。
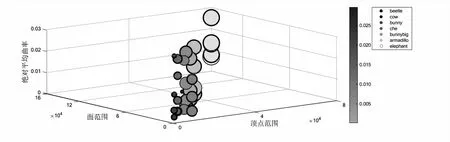
图7 模型在绝对平均曲率下的局部散点图
图8分别为mushroom,mannequin,beetle模型的算法效果,从左到右依次为原始模型、加密模型、嵌入模型、1次迭代光滑模型、3次迭代光滑模型、5次迭代光滑模型、7次迭代光滑模型,即模型使用顶点处半窗拉普拉斯算子进行不同次迭代后光滑恢复的效果。可以看到,随着迭代次数的增加,网格模型不可避免地会出现收缩特征,如mannequin的眼睛、鼻子等尖锐部分,从而降低了恢复质量。同时可以看出光滑模型较原始模型,颜色较深处的高曲率区域即紫色区域,在去噪的同时更好保留了细节特征,实现了可逆数据隐藏下的顶点策略优化效果。因此,为了保证模型高恢复质量支撑良好的实验效果,实验中迭代1次进行光滑得到算法指标。
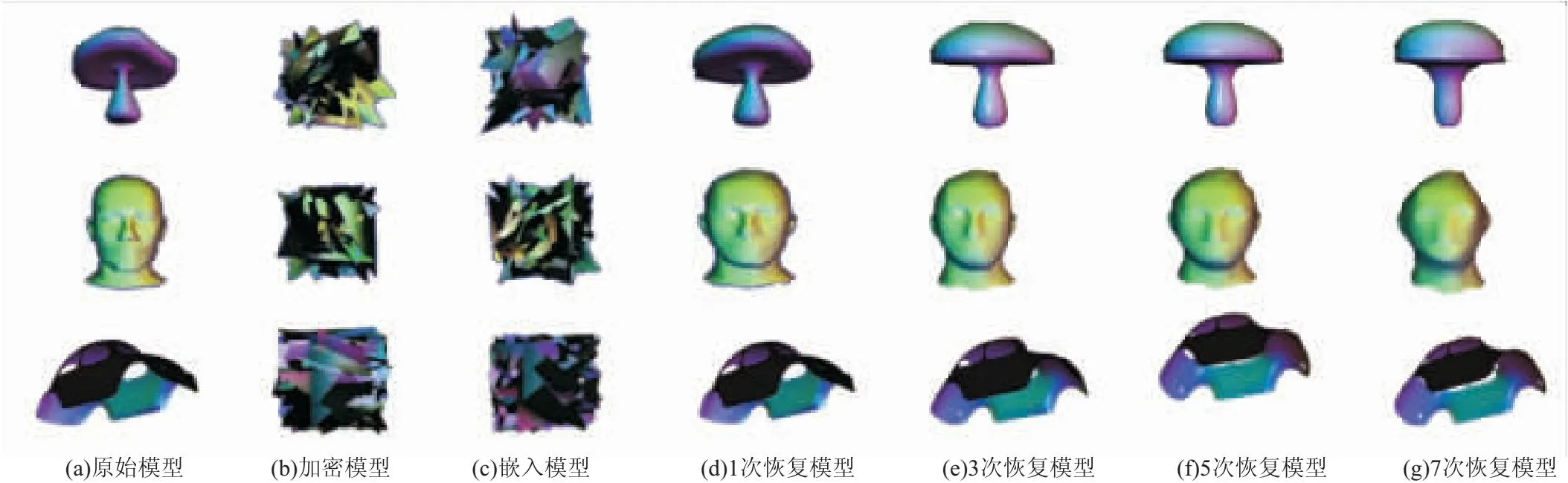
图8 模型算法效果
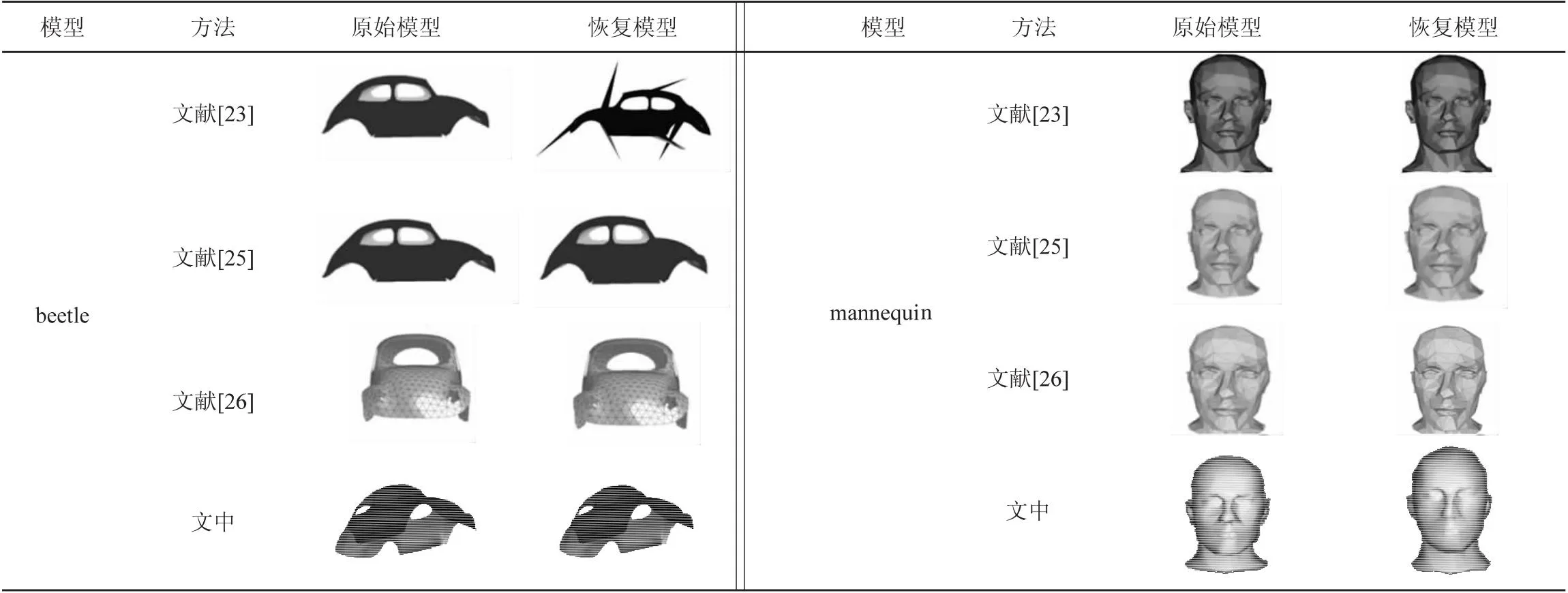
表2 与现有方法的方案效果对比
表2对比了beetle模型和mannequin模型在不同方法下的人眼感知效果。
综上所述,文中算法不仅在一定程度上实现了高嵌入率,而且获得了更高质量的恢复网格,可以进一步对恢复模型人眼感知。
如表3,在The Stanford 3D Scanning Repository中针对顶点密集网格模型Stannf bunny进一步测试性能,其顶点数为34 843,面数为69 541。展示了文中方法相比于其他方法的可视化性,密集网格模型可广泛用于3D打印,表明文中方法有一定的性能,并且进一步验证了对顶点密集型网格的适用性和有效性。

表3 不同方法下Stannf bunny(bunnybig)的可视化度
4 结束语
如今三维网格广泛应用于多媒体、建模、渲染、3D打印等实际领域,网格模型的发展也越发具有意义。为提高模型安全性,围绕顶点处预测策略和拉普拉斯算子,提出一种策略优化的可逆数据隐藏算法。采用模型顶点到切平面的最短距离将全邻域划分为两个子集,以生成新的重心集合,预测策略预测所有顶点集合的最高有效位确定最大嵌入长度,迭代半窗拉普拉斯算子得到高质量的恢复模型,采用余切拉普拉斯算子下的平均曲率绘制三维散点图渲染模型,从而实现实际场景下的安全应用。实验结果表明,在高嵌入率下有效提高了恢复质量,并且在人眼感知光滑模型方面也有较好的效果。未来将探索运行效率更高的优化算法,提高模型在深度学习等实际领域中的安全性。
