基于EfficientNet的无锚框目标检测模型
2024-01-24卜子渝刘纯平
卜子渝,杨 哲,,刘纯平
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006;2.江苏省计算机信息处理技术重点实验室,江苏 苏州 215006;3.江苏省大数据智能工程实验室,江苏 苏州 215006)
0 引 言
目标检测是计算机视觉的基础任务之一,关注图像中特定目标的类别及位置,传统的目标检测模型的待检测目标种类往往是单一的,并且模型整体性能不高[1-2]。随着卷积神经网络的兴起,涌现出了大批基于深度学习的目标检测模型。主要分为两类:二阶段模型(two-stage)和单阶段模型(one-stage)。
二阶段目标检测模型诞生较早,基本由两部分构成,分别完成候选框提取任务(Region Proposal)以及分类回归任务(Classification &Regression)。二阶段模型在早期较单阶段模型有着更高的检测精度,但是算法复杂。而单阶段目标检测模型直接将目标框的定位问题视为回归任务来处理,可以直接预测不同目标的类别和位置。单阶段模型的速度占优,并且在精度上正逐渐赶超二阶段模型[3]。
随着单阶段模型的发展,还演进出了无需锚框(Anchor-Free)的目标检测器,降低了人工设置参数的数量,如CenterNet[4],FCOS[5]等,并有相关应用[6]。此外,为了获得更高的精度,检测模型运用可缩放的主干网络也成为一种主流方法,如ResNet[7],ResNeXt[8],AmoebaNet[9]等,可以将输入图像分辨率泛化到512至1 536。然而,在训练过程中,单阶段模型往往会遇到正负样本数量不均衡的问题,Lin等人提出了Focal Loss尝试解决该问题[10]。但在Redmon提出的YOLOv3中,作者在引入Focal Loss后,检测精度却下降了大约2%[11]。
该文提出了一种无锚框的单阶段目标检测模型,并引入了一种动态分配正负样本的方法,缓解了模型训练时正负样本不均衡的问题。模型主干网络采用可缩放的EfficientNet[12]。EfficientNet将网络深度、网络宽度和输入分辨率联系起来,不仅性能与其他常见的主干网络相当,还减少了网络的参数量和计算量。回归损失函数的计算上,文中模型采用CIOU(Complete-IOU)[13],解决了预测框与真实框不重叠时无法进行反向传播的问题。
1 相关工作
1.1 传统目标检测模型
深度学习兴起之前,目标检测任务主要依靠滑动窗口和分类器来完成。其检测过程大致可以分为三步:先利用不同尺寸的滑动窗口选取图像中的某些部分作为候选区域,再提取候选区域相关的视觉特征,最后使用一个已经训练好的分类器完成对目标的分类。经典的模型有:Viola和Jones在2001年提出的人脸检测器,在AdaBoost算法的基础上,使用Haar-like小波特征和积分图方法进行人脸检测[14]。Dalal等人则结合方向梯度直方图(Histogram of Oriented Gradient,HOG)和支持向量机实现了对行人的检测。然而,这些传统模型除了可检测目标的种类单一外,还存在检测速度慢的问题。
1.2 二阶段目标检测模型
深度神经网络被引入目标检测领域后,使模型性能有了大幅提升。首先出现了二阶段目标检测模型,如R-CNN[15],SPP-Net[16],Faster R-CNN[17],HyperNet[18]等。二阶段目标检测的流程可分为区域建议(Region Proposal)阶段和分类回归(Classifier &Regression)阶段。R-CNN是最早出现的二阶段目标检测模型[15],在区域建议阶段使用选择搜索算法(Selective Search),从图像中提取可能包含物体的候选区域,再利用卷积神经网络提取每个候选区域特征,最后输入到SVM进行分类。SPP-Net则改进了R-CNN因为候选区域尺寸不同而需要统一缩放的缺陷,通过特征金字塔池化,实现了多尺度输入[19]。Faster R-CNN则在区域建议阶段提出了区域建议网络来替代选择搜索,并首次引入锚框(Anchor)——模型基于锚框完成目标的定位任务,提升了检测速度。总的来说,二阶段模型较为复杂,需要训练两部分网络,难以到端到端,检测速度也不如单阶段模型。因此,单阶段目标检测模型逐渐成为了主流。
1.3 单阶段目标检测模型
单阶段目标检测模型直接在深度神经网络中提取特征,完成定位和分类任务,有着更快的检测速度,主要有SSD[20],RetinaNet以及YOLO系列[21-22]等。YOLO模型率先采用一个卷积神经网络实现端到端的目标检测,检测速度提升显著,但精度表现一般。SSD和YOLOv3都引入了多尺度特征图提高检测精度,并效仿了Faster R-CNN,基于锚框完成定位任务。针对单阶段模型在训练时的正负样本数量不均衡问题,Lin等人在RetinaNet中提出了Focal Loss,从损失函数的角度来弥补负样本数量远大于正样本的差异。但是在YOLOv3中,作者引入Focal Loss后,模型的检测精度却损失大约2%,其原因是负样本过多,造成了噪声干扰。YOLOv4主干网络使用了CSPDarknet53,并引入了CIOU提高检测精度,YOLOv5使用了可缩放的主干网络,进一步提升模型性能,但二者仍依赖基于手工设置的锚框来预测目标位置,这些锚框的参数往往会对精度产生较大的影响,找到完美的预设锚框也十分困难[23]。于是有研究者提出了Anchor-Free目标检测模型,意在去掉预设锚框的环节,让网络自行学习目标框的位置与形状,代表的模型有CenterNet和FCOS等。CenterNet将目标检测视为关键点预测问题,使用关键点三元组(左上,右下,中心点)来确定一个目标,但只对网络最后一个特征层做处理,缺乏多尺度信息。FCOS提出中心度的概念,衡量边界与目标中心的归一化距离。但是该方法增加了算法复杂度,并且模型在不预测中心度的情况下,性能会弱于Anchor-Based的检测模型。
针对单阶段模型存在的这两个问题——正负样本不均衡以及锚框需要人工设置,该文提出一种基于EfficientNet的无锚框单阶段目标检测模型。该模型以特征点直接预测目标框的中心点和宽高,省去了人工设置锚框的环节,并引入了一种正负样本动态分配的算法。与Focal Loss不同的是,该分配算法能够先过滤无用的特征点,并在训练时动态分配正负样本,无需通过损失函数来弥补样本不平衡带来的差异。此外,文中模型使用CIOU计算回归损失,解决了预测框与真实框不重叠时无法进行反向传播的问题,进一步提高了检测精度。最后通过与主流模型在VOC07+12数据集上的对比,证明了该方法的有效性。
2 基于EfficientNet的无锚框单阶段目标检测模型
2.1 模型整体结构
提出的AEOD模型整体结构如图1所示。AEOD使用EfficientNet作为模型的主干网络,提取网络中{L3,L4,L5,L6,L7}五个特征层组成特征金字塔,这五个特征层分别经过上下两个方向的特征融合后(图1模型整体结构中的虚线部分),输出三个尺度分别为64×64,32×32以及16×16的有效特征层。模型根据有效特征层中的特征点与目标框的相对位置,筛选出负责预测目标框的特征点,再基于特征点的预测结果计算代价矩阵动态分配正负样本。这些特征点直接预测目标框在图像中的中心点以及宽高,并对目标进行分类。最后使用CIOU计算回归损失,使用二分类交叉熵(Binary Cross Entropy)计算分类损失。
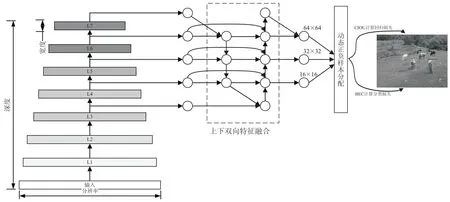
图1 AEOD的整体结构
2.2 主干网络——EfficientNet
为了获得更高的检测精度,将可缩放的主干网络运用于目标检测模型已经是一种常用方法,如ResNet,ResNeXt和AmoebaNet等。然而它们都没有关注卷积神经网络的深度(卷积层数,Layers)、宽度(卷积核通道数量,Channels)以及输入图像的分辨率(图像的宽高,Resolution)之间的关系。使用规模庞大的神经网络对一幅分辨率较低的图像进行卷积时,有效的特征提取往往在浅层就已经完成了,导致计算量和参数量的浪费,而对于高分辨率的图像,应该用更深,更宽的网络,从而获得更大的感受野。EfficientNet则可以平滑地控制模型的深度、宽度以及输入分辨率,形成一种组合关系。其关系如下:
(1)
其中,α,β,γ为常数,可以由网格化搜索得到。Φ为缩放系数。由于模型的总体计算量FLOPs与d·w2·r2成正比,将神经网络的深度增加一倍意味着计算量增加一倍,而增加一倍的宽度或者输入分辨率,计算量则会增加两倍。因此整体模型的计算量可以近似使用(α·β2·γ2)Ф来衡量。该文将α·β2·γ2限制在2左右,因此缩放因子对整体计算量的影响保持为2Φ。
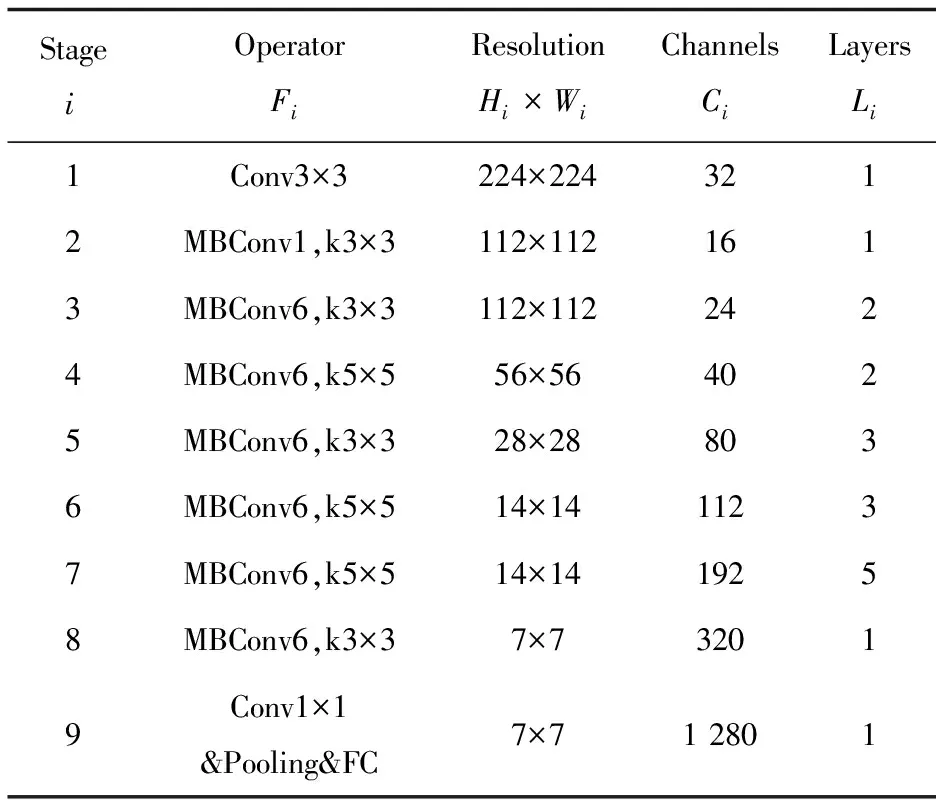
表1 EifficentNet-b0的网络结构
表1为用于图像识别任务的EifficentNet-b0的基准结构(Baseline)。EifficentNet使文中模型的输入图像分辨率可以覆盖512×512至1 280×1 280的范围。检测精度也随着分辨率的上升而提高,但计算量(FlOPs)与参数量(Params)会有所增加。表2为文中模型的配置值,其中α,β,γ三个参数分别为1.1,1.1和1.18。
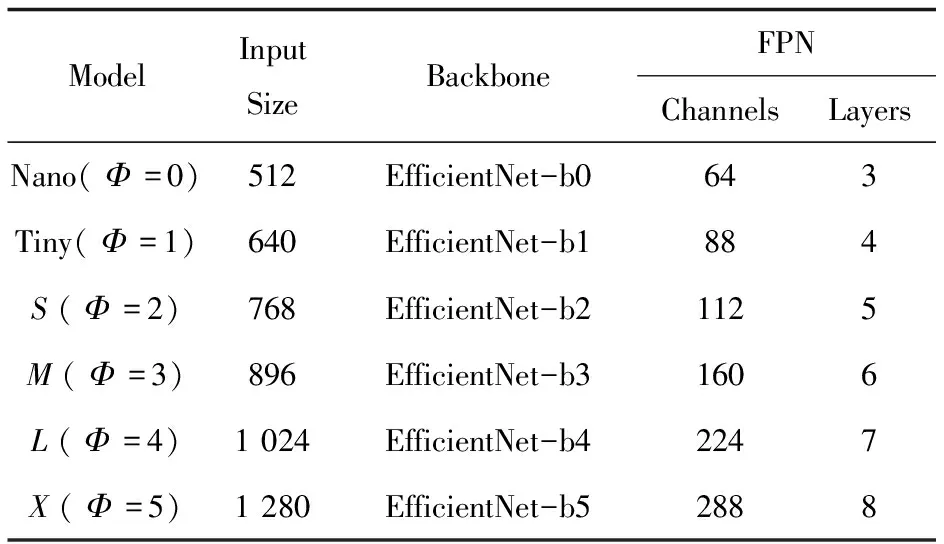
表2 AEOD的模型配置
AEOD在网络前向转播过程中提取{L3,L4,L5,L6,L7}五个特征层组成特征金字塔,这五个特征层分别经过上下两个方向的特征融合,输出三个尺度分别为64×64,32×32以及16×16的有效特征层。特征融合过程采用通道注意力机制,设置可学习的参数w,让网络在训练过程中自我学习特征通道的权重。特征融合如式2、式3所示,其中ε设置为0.000 1,避免训练时出现数值不稳定。
(2)
(3)
2.3 无锚框(Anchor-Free)
AEOD基于提取的有效特征层中的特征点直接预测目标框的中心点和宽高。这些特征层的宽高分别为64×64,32×32和16×16。以输入分辨率为512×512为例。有效特征层映射至输入图像上,特征点在图像上均匀分布,步长为8,16和32,分别形成了由4 096,1 024和256个网格点组成的网格图。网格点即对应特征层中的特征点。通过前向传播AEOD为每个特征点预测一组数据(预测框),包括目标可能的中心点位置、宽高以及目标的类别。
预测框的中心点、宽高根据如下公式获得,基于第i个特征点得到的目标框以li=(lx,ly,lw,lh)表示,pi=(px,py,pw,ph)为模型为第i个特征点所预测的数值,grid为网格中的特征点位置,stride为步长。
(4)
(5)
(6)
(7)
2.4 动态正负样本分配算法
针对单阶段目标检测模型在训练时容易产生正负样本不平衡的问题,AEOD引入一种动态分配正负样本的方法,根据特征点位置、特征点所产生的预测框与真实框的IOU,为目标动态分配正负样本。模型在训练的过程中主动筛选正负样本,从而达到平衡二者数量的目的。具体算法流程如图2所示。模型先筛选出落在目标框内的特征点,对基于这些特征点得到的预测框计算与真实框的IOU损失和分类损失,最后根据这些损失组成的代价矩阵来动态分配正负样本。

Algorithm: Dynamic P/N Sample AssignmentInput:I is an inputimgaeA is a set of anchor pointsG is the ground-truth annotations for objects in image IL is location of each anchor point in imageOutput:π is the dynamic P/N sample assignment plan1. m←|G|, n←|A|2.Tm×n←ZerosInit3.Pcls, Pbox←Forward(I, A)4. For i=0 to m do:For j=0 to n do:Ti,j←IsInGround-TruthBox(Lj, G)5. Pairwisecls cost: ci,j = BinaryCrossEntropyLoss(Gicls, Pjcls)6. Pairwise reg cost:ci,j = IOULoss(Gibox, Pjbox)7.Costm×n←cls cost+ reg cost+ ~Tm×n8. If Ai in ground-truth box according to Tm×n: (1) Select the leastCosti,j for Gi as positive sample (2) Select others as negative sample9. Compute assignment plan π according to Eq.810. Return π
2.5 CIOU
在单阶段目标检测模型中,IOU(Intersection of Union)是预测框与真实框交集与并集的比值。IOU损失则用来度量这两个框的差异。然而,在预测框与真实框没有重叠部分时,IOU的数值是0,无法产生梯度,参数无法得到更新,模型得不到训练。此外,当多个形状不同的预测框与真实框的IOU相同时,IOU损失无法度量它们之间的优劣。
(8)
LOSSIOU=1-IOU
(9)
AEOD引入了CIOU。CIOU不仅可以描述预测框与真实框重合面积的大小,还可以度量二者的长宽比的差异与中心点距离。即使两个框没有重叠部分,仍可以依靠其他差异来产生梯度,模型参数仍可以获得更新。CIOU的计算流程如下:
(10)
(11)
(12)
(13)
其中,c2表示目标框与预测框的最小外接框的对角线距离,ρ2(b,bgt)表示两个框的中心点距离,v则表示二者在长宽比上的差异。
图3直观地表示了IOU与CIOU的区别。
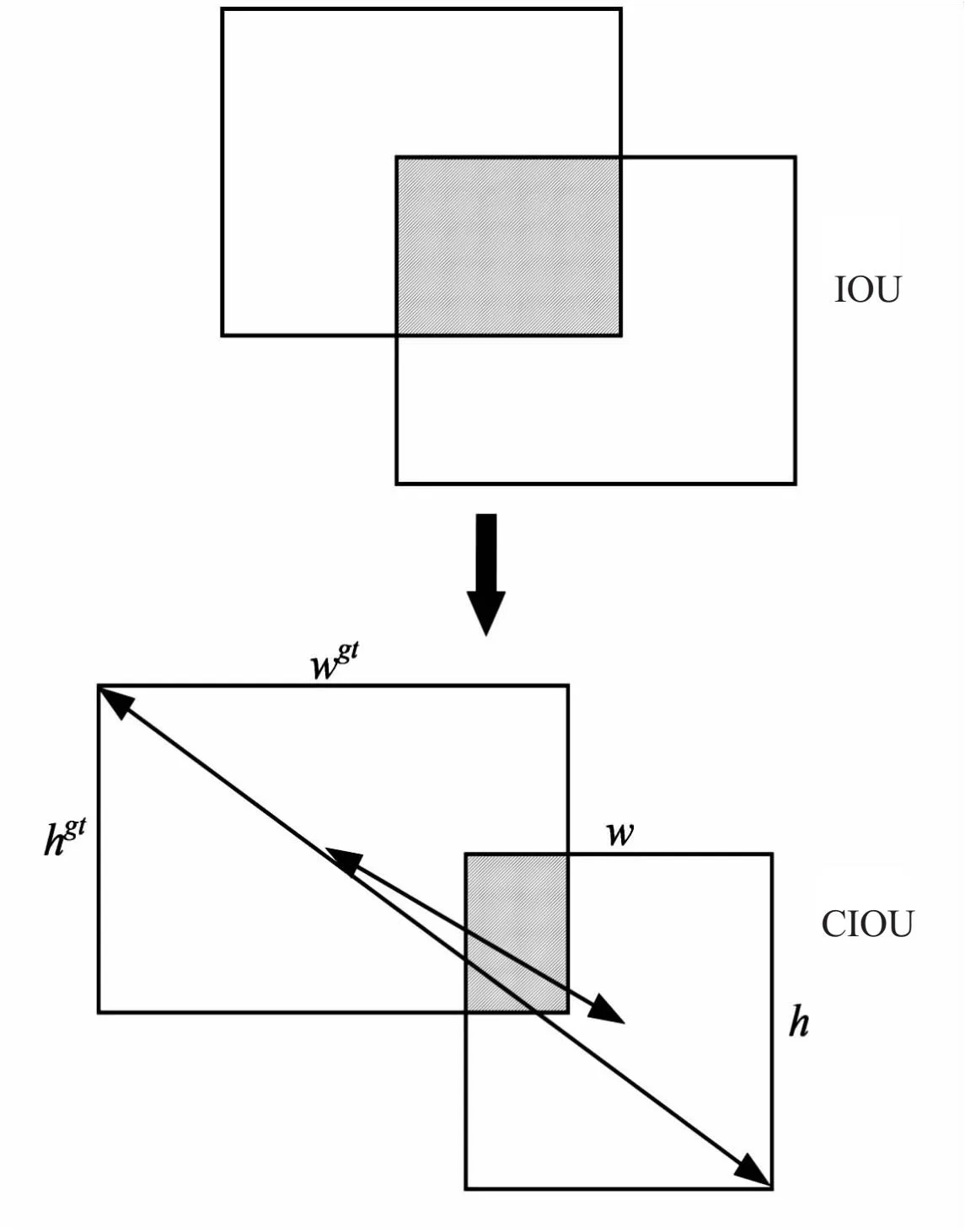
图3 IOU与CIOU对比
3 实验与分析
3.1 实验环境
实验环境配置如下:Ubuntu18.04操作系统,32核Intel CPU,32 GB内存,英伟达GeForce V100,128 GB存储空间。程序采用Python语言编写,版本为3.7。深度学习框架为Pytorch1.7,其他第三方库包含Numpy1.19,Scipy1.4.1以及Pycocotools2.0.2等。图形处理器驱动为CUDA10.1和Cudnn7.6。
3.2 预训练与数据增强
预训练是训练深度学习模型的常用技术手段,该文将模型的主干网络在ImageNet数据集上进行预训练,主干网络的参数不再随机初始化。
除了随机缩放和随机水平翻转等数据增强方法外,该文还采用了mosaic数据增强。不仅丰富了待检测物体的背景,还增加了数据集中小目标的数量,进一步提高了模型的训练效果。
3.3 数据集与评价指标
该文使用目标检测领域中的通用数据集——Pascal VOC来评估模型的性能。实验训练集默认使用VOC07+12数据集,测试集使用VOC07test。模型的主要评价指标包括:平均精度均值(mean Average Precision,mAP)、小目标识别精度(Average Precision for Small Objects,APS)、中目标识别精度(Average Precision for Medium Objects,APM)、大目标识别精度(Average Precision for Large Objects,APL)和速度指标每秒帧数(Frames Per Second,FPS)等。其中小、中、大目标分别指图中像素在32×32以下,32×32至96×96之间及96×96以上的物体[24]。除了精度指标外,还比较模型在召回率上的表现。其中RecallS,RecallM和RecallL分别表示对小、中、大目标的召回率。
3.4 实验结果
表3展示了文中模型(AEOD)与其他目标检测模型在VOC07test数据集上的测试结果。由表3可以看出,文中模型的平均精度均超过了与之对应的YOLOv5模型,分别达到了87.6%(+3.3%),89.1%(+1.9%)和90.2%(+1.2%)。YOLOv5针对网络不同的深度和宽度主要分成了S,M和L,但是输入分辨率固定。由于使用了宽度、深度、分辨率组合缩放的主干网络EfficientNet,AEOD的输入图像大小并不固定,可以随着网络的扩大而增加。此外,文中模型也取得了较快的检测速度,如缩放因子Φ=3的AEOD-M检测速度达到了58.8 FPS,超过了同样是无锚框的CenterNet(+23.8 FPS)和FCOS(+6.6 FPS),并且检测精度较二者分别提升了12.0%和4.8%。表3还比较了基于Transformer的Detr[25],AEOD在mAP和FPS指标上较其都具有优势。
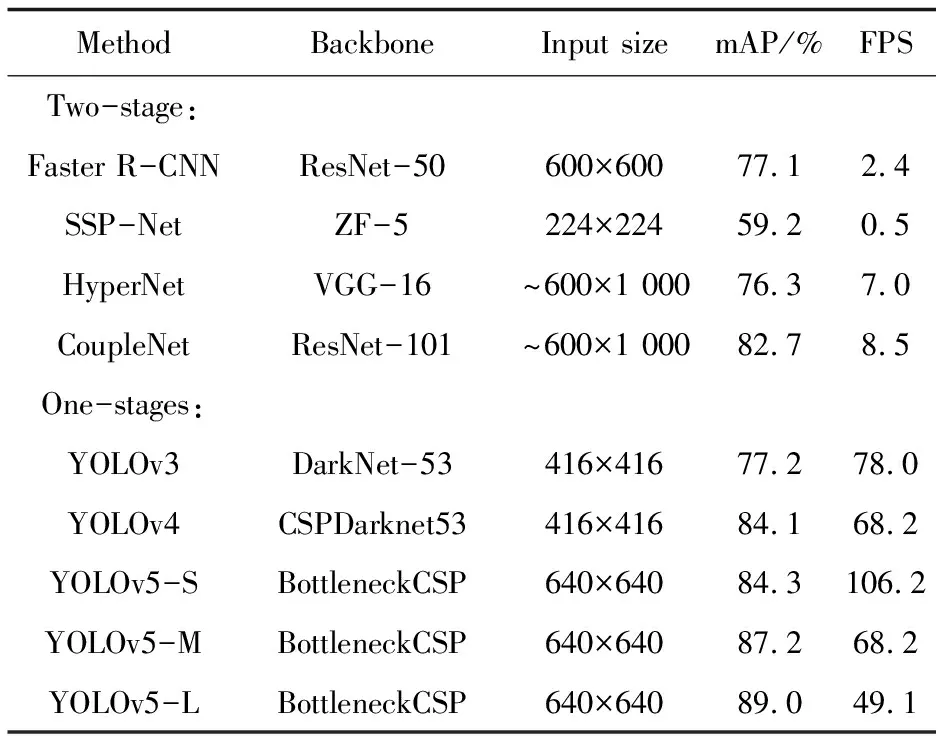
表3 各模型在VOC07test上的测试结果对比
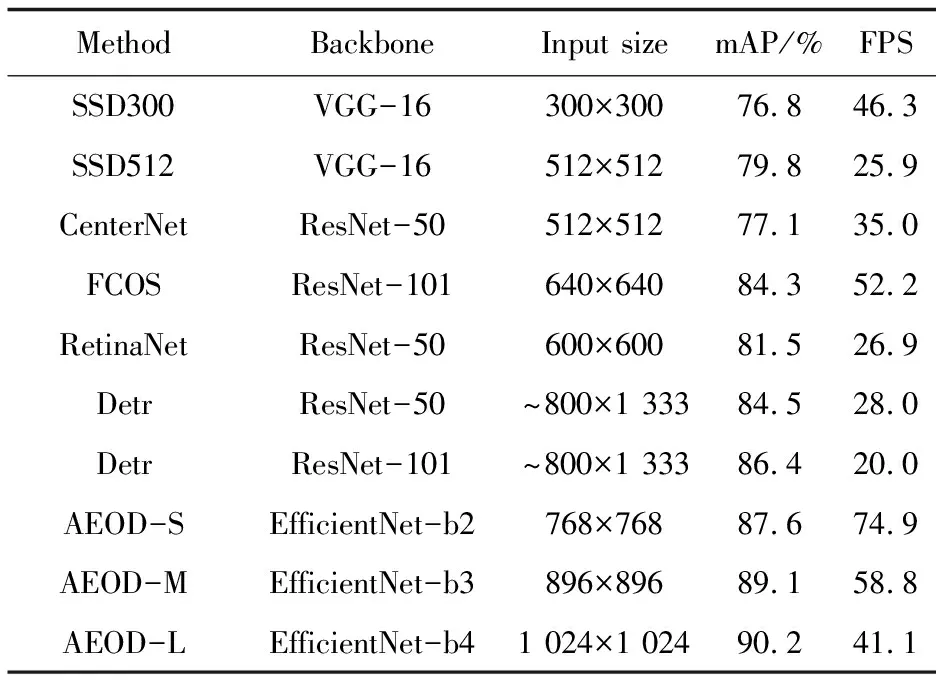
续表3
模型在VOC07test数据集上完整的测试结果如表4所示,指标除mAP与FPS外,还有总浮点运算次数(FLOPs)以及参数量(Params)。从表中可知,文中模型可接受图像分辨率能够从512×512泛化至1 280×1 280,检测精度也随着上升。其中精度最高的AEOD-X模型(缩放因子Φ=5)输入分辨率为1 280×1 280,平均精度达到了91.3%,检测速度为32.1 FPS。但是模型的扩大也带来了计算量和参数量的增加,AEOD-X拥有最大的40.9 G总计算量和25.3 M的总参数量。最轻量的AEOD-Nano检测速度最快,可以达到102.3 FPS,同时检测精度也保持在了80%以上(80.2%)。

表4 AEOD各模块在VOC07test上的测试结果对比
表5展示了模型对不同大小的目标检测精度对比。其中mAP@0.5和mAP@0.75表示IOU的阈值分别为0.5和0.75时的平均精度,mAP@[0.5,0.95]表示:获取IOU以0.05的步长从0.5开始递增到0.95时的全部mAP后再取平均。APS,APM和APL分别表示对小、中、大目标的AP值。从表中可以看出mAP最高的AEOD-X对于各种不同大小目标的检测效果也最佳,但计算量和参数量最大。
表6展示了模型在VOC07test数据集上对不同目标的召回率(Recall)表现。表中的maxdets=k,k=1,10,100,分别表示取置信度最高的1个,10个或100个预测结果进行评估。而RecallS,RecallM和RecallL分别表示对小、中、大目标的召回率。表6中数据呈现了与表5基本相同的规律,对于mAP 较高的模型,在召回率上也有较好的表现。
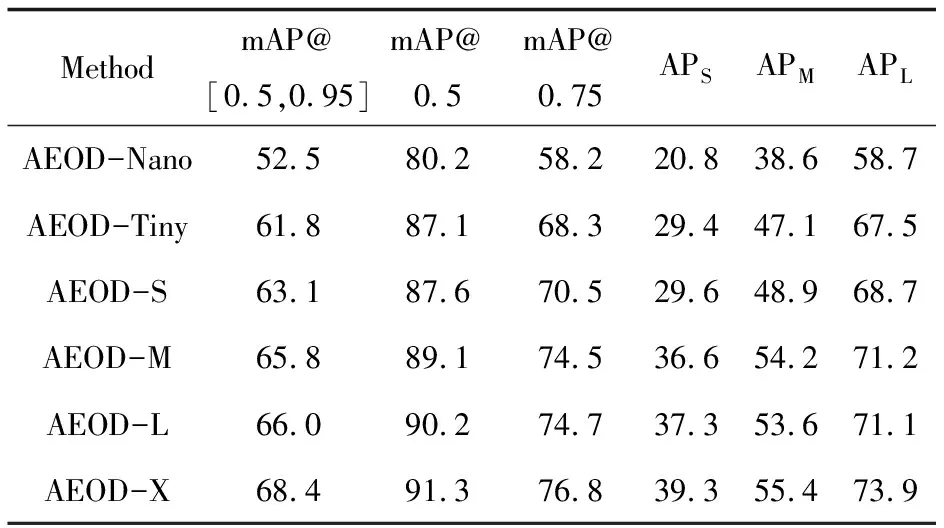
表5 AEOD各模块在VOC07test中对不同目标的平均检测精度

表6 AEOD各模块在VOC07test上的召回率
4 结束语
该文提出了一种基于可缩放的EfficientNet的Anchor-Free单阶段目标检测模型。EfficientNet不仅仅简单缩放模型的宽度、深度以及输入分辨率,还将三者的关系考虑了进来,是一种更合理的主干网络。该模型也做到了Anchor-Free,省去了手工设置锚框的过程,让网络自动学习目标框的大小和形状。针对单阶段目标检测模型普遍存在的正负样本不均衡问题,提出了一种动态分配正负样本的算法,以目标框内的特征点作为样本,训练时动态分配。最后通过实验证明了该方法的有效性。但是可以观察到,模型对较小目标的检测精度仍然落后于中大型目标,如何有效检测小型目标,仍是目标检测领域值得去探索的议题。在后续工作中,可以考虑采取特征提取能力更强大的Transformer主干网络替换EfficientNet,继续提升模型的性能。
