一种面向商品检索的多尺度度量学习方法
2024-01-24行阳阳张索非吴晓富
行阳阳,张索非,宋 越,吴晓富,周 全
(1.南京邮电大学,江苏 南京 210003;2.95958部队,上海 200120)
0 引 言
随着互联网技术和电子商务的飞速发展,人们的购物方式逐渐从传统的线下购物转变为线上购物。为了充分满足客户海量、多样化的网上购物需求,人工智能零售系统需要快速、自动地从图像和视频中识别出存货单元(Stock Keeping Unit,SKU)级别的商品类别。与此同时,深度学习在计算机视觉领域取得了突破性进展,特别是在大型图像分类任务方向如ImageNet。大规模商品识别是计算机视觉领域的一个新兴课题。但是,许多SKU级商品都是细粒度的,并且它们在视觉上是相似的。如何正确并快速地通过深度神经网络来进行快速识别仍面临技术挑战。
网上购物平台上的商品种类繁多。如图1所示,为了方便商品的管理,很多商品的子类别根据不同的用途或储存方法被划分在不同的父类别中。换句话说,一个父类别包含许多子类别。一种商品既属于某个子类别,同时也属于某个父类别。不同语义下的类别信息即商品图像多尺度标签信息。需要注意的是,商品的层级分类并不完全迎合商品的视觉相似性。不同父类别下的商品图像也可能具有相似的外观。例如,如图1所示,以“护手霜”为父类别的第三行第四列商品与以“洗面奶”为父类别的第四行第二列商品外观较为相似。造成这种现象的原因是商品并不是按照外观进行分类。这种现象会给商品图像的标签带来噪音并给检索出正确的商品类别带来技术挑战。
此外,在商品识别任务中,手动标记标签并收集所有类别商品图像的数据集总是费时且昂贵的。首先,要在网上购物平台上识别不同商品的数量可能是巨大的。对于每一类商品,需要数百张训练图像,通常从几个不同的角度拍摄。其次,商品零售平台需要定期上架新的商品类型,现有商品的外观也会不时发生变化。在实际部署过程中,更新不断增加的训练图像是一个棘手的问题。由于上述原因,如果没有这些新商品类别的训练样本,传统的图像分类模型往往无法获得令人满意的性能。相比之下,度量学习方法更适合于商品检索,因为它可以将输入图像嵌入到一个紧凑但有分辨能力的特征空间中。这种嵌入可以很容易地推广到未知类别,而不需要任何额外的训练成本。因此,将网络购物平台中的商品图像识别问题转化为大规模度量学习任务有利于问题的解决。目前,许多SKU级别的商品图像数据集已经进行了公开。例如,AliProducts-Challenge[1]数据集包含近300万张图像,覆盖5万个SKU级商品类别;Products-10K[2]数据集包含近15万张图像,覆盖1万个SKU级商品类别。
综上所述,商品检索问题可以看作是一个多尺度度量学习问题。商品类别的标签通常符合一种层级结构。许多公开可用的商品图像数据集还包含多尺度的标签信息,而不是只包含单尺度的标签信息。利用多尺度标签信息进行模型训练,可以使得网络充分挖掘商品图像不同尺度特征的关系并更可能满足不同尺度下的识别需求。
该文提出了一种充分利用商品图像的多尺度监督信息的MSML(Multi-Scale Metric Learning)模型。在大规模商品图像检索数据集上的实验结果表明,该方法是有效的,与传统的单尺度度量学习相比,显著提高了识别的综合性能。
1 相关工作
1.1 商品识别
在过去的十年中,深度学习在计算机视觉领域取得了巨大的成功。近年来,基于深度学习的商品识别得到了广泛的研究,关于这一领域已经有了大量的工作。在文献[3]中,作者提出了一个多任务级联的卷积神经网络(MTCD-CNN)进行商品图像检测并采用分层频谱聚类进行层级的图像分类。文献[4]提出了一种对商品模型进行无标签半监督的商品识别方法。该方法基于Self-training训练两个目标检测模型,提高了无标签预测的准确性。文献[5]报道了通过AlexNet学习到的特征被用于杂货商品识别。该研究表明,深度学习方法在复杂场景下更有效。此外,文献[6]提出了一种基于YOLOX模型的商品检索算法。该算法采用轻量级网络MobileNet-V2作为主干网并使用改进的相似度检索方法进行推理,使得网络在不增加检索速度的情况下增加识别准确度。文献[7]融合商品图像的图像特征和文本特征的识别算法,利用商品的图像和文本进行多模态融合,提高了识别系统鲁棒性。文献[8]提出了一种融合金字塔池化策略并使用一种名为哈希网络的SHN模型提高了模型对于图像形变带来的负面影响。
1.2 深度度量学习
深度度量学习(DML)广泛应用于计算机视觉任务,包括人脸识别、行人重识别、车辆再识别和商品识别。通常,这些任务的目标是检索与查询图像最相似的所有图像。近年来,深度度量学习取得了显著的进展。这些方法主要分为两类,即成对样本计算嵌入特征度量差异的方法和基于分类区分嵌入特征的方法。基于样本对的方法在深度嵌入的特征空间中优化样本对之间的相似性,例如,Triplet Loss[9],N-pair Loss[10],Multi-Simi Loss[11]。相比之下,基于分类的方法通过在训练集上训练各种分类模型来学习嵌入,例如Cosface[12],ArcFace[13],NormSoftmax[14]和Proxy NCA[15]。最近的一项工作[16],考虑从统一的角度结合这两种方法。通过对两种损失进行加权,给出了一般的损失函数。与传统的度量学习只利用单一尺度的监督信息不同,该文提出的方法充分利用了多个语义尺度的监督信息来对模型进行训练。
2 基于多尺度度量学习的商品检索
使用商品多个尺度的标签信息用于度量学习模型的训练即为多尺度度量学习。在多尺度度量学习中,会考虑商品图像的多个尺度。例如,该文考虑了商品标签的两个尺度,即粗粒度的组别和细粒度的类别。组标签和类标签符合层次结构,其中一个组别包含多个类别。根据实际的应用场景,不妨假设类级别的任务是开集识别任务,组级别的任务是闭集识别任务。网络设计的目标即同时完成组级分类任务和类级检索任务,并使两者尽可能没有干扰。文中模型采用了三个分支网络来满足这两个层次的识别需求。特别地,该方法利用协同注意力分支将组别级特征与类别级特征相结合,充分利用了图像标签的层次性信息。
2.1 总体方案
如图2所示,所提网络模型是一个以ResNet50作为骨干网的三个分支网络。三个分支分别是粗粒度特征提取分支、细粒度特征提取分支和融合特征提取分支。粗粒度特征提取分支和细粒度特征提取分支分别对商品图像进行粗粒度和细粒度特征的提取。融合特征提取分支则对另外两个分支提取到的特征以一定方式进行融合形成新的融合特征并最终用于商品图像的检索。
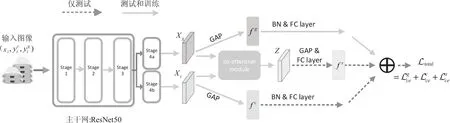
图2 所提出的MSML深度神经网络模型架构
MSML可以采用任何用于图像分类的深度网络作为主干网,例如谷歌Inception和ResNet。考虑到ResNet50的竞争性能和相对简洁的架构,该文主要采用ResNet50作为主干网。在文献[17]的基础上,去掉了ResNet的Stage4(包括框架中的Stage4a和Stage4b)中最后一个空间向下采样操作,以增加特征图的大小。
为了更好地提取粗粒度和细粒度级别的特征,MSML使用了Stage4a和Stage4b从骨干网将两个级别所优化的特征空间分开。Stage4a和Stage4b都是从原始ResNet中的Stage4复制而来,并在Stage3后面并行连接。Stage4a和Stage4b在结构上是相同的,但是在网络训练过程中网络参数的更新是不同的。从Stage4a派生的分支用于粗粒度级别的特征提取并在经过全连接层用于商品组别的分类,从Stage4b派生出的分支用于细粒度级别特征的提取。对Stage4a和Stage4b的输出进行GAP(Global Average Pooling)运算,可以得到两个2 048维的特征向量。不同粒度的特征提取使用不同的分支网络可以缓解粗粒度特征和细粒度特征在一个特征空间提取所造成的相互干扰。此外,利用协同注意模块将粗粒度和细粒度特征相结合,充分利用了图像标签的层次信息。
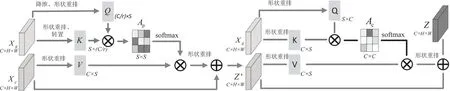
图3 协同注意力模块结构示意图
2.2 融合特征提取分支
融合特征提取分支使用协同注意力机制将粗粒度和细粒度特征进行融合形成新的融合特征。注意力模块已被证明是多种机器学习场景下的有效机制[18],并广泛应用于自然语言处理(NLP)、图像处理(CV)、语音信号识别等各类机器学习任务中。注意力机制利用特征之间的相关性,迫使网络更加关注有用的信息。
在商品图像识别的情况下,对于同一个样本,网络在粗粒度级别和细粒度级别学习的特征应该是不同的。为了更好地使网络挖掘到图像的重要特征,该文使用一种协同注意机制,将粗粒度级别的特征引入细粒度级别的特征中,如图3所示。这两个协同注意模块由一个空间注意力模块(PAM)和一个通道注意模块(CAM)组成。设Stage4a和Stage4b的输出特征Xc,Xg∈RC×(H×W)为协同注意模块的输入特征,其中C,H,W分别为特征图的通道数、高度和宽度。PAM将每个位置的特征Xg映射重塑到两个低维子空间上,这些子空间是由核大小为1×1的二维卷积实现的。经过重塑降维操作最终得到查询Q∈RC/r×S,键K∈RC/r×S。其中S=H×W为特征图的空间大小,r为控制子空间维数的超参数。该文将遵从注意力机制一般的实验配置,简单的将其设置为8。与自注意模块不同的是,协同注意中的值V并不是来自与键相同的特征图,而是来自另一个特征图。在所提出的模型中,直接将Stage4b的输出Xc经过大小重排作为值V∈RC×S。那么Xc和Xg的经过空间注意力的输出可以由查询Q、键K和值V计算为:
Z'=attentionp(Xc,Xg)=Vσ(Ap)=Vσ(QTK)
(1)
其中,σ(·)为Softmax函数,Z'∈RC×(H×W)为PAM的输出,Ap为位置权重矩阵,可以度量Xg不同位置特征之间的相关性。与PAM类似,同样使用了通道注意力模块(CAM),从通道角度赋予网络关注关键信息的能力。CAM直接从PAM的输出Z'中获取键K和查询Q。最终融合特征分支可表示为:
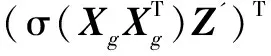
(2)
2.3 损失函数
在MSML中,最终的总损失是三个单独损失的加权和,即:
(3)
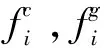
在训练阶段,ResNet的Stage1,Stage2和Stage3会同时被这三个损失函数进行优化,网络的其余部分仅由相应的损失函数进行优化。基于以上分析,任何分支的优化都可以通过影响公共部分Stage1,Stage2和Stage3来影响其他分支的优化。
3 实 验
在本节中,设置了一些对比神经网络模型与文中模型进行比较,并使用多个基于分类的损失函数来证明所提MSML模型的有效性。此外,文献[17]商品识别的冠军方案模型和文献[19]基于自注意力模块(S-A based)的图像检索方法将应用于商品检索任务,并与文中模型进行了性能比较。
3.1 数据集
实验所采用的数据集是来自公开数据集Products-10k[2],为便于实验,进行了重新分割,最终形成新的商品检索数据集MSML-Product。其中,源商品数据集Products-10k是一个基于商品识别应用场景的开放数据集。Product-10k包含在线零售平台频繁购买的10 000种商品,涵盖时尚、3C、食品、保健及家居等所有品类。所有SKU级别的商品都被组织到一个层次结构中,总共有近19万张图片。在实际应用场景中,图像数量的分布并不均衡。所有图像都由生产专家团队手动检查和标记。
对Product-10k的所有图像进行重新分布,使数据集符合一般图像检索数据集的形式。将处理后的数据集MSML-Product分为三组:训练集、查询集和待查询集。查询集和待查询集用于测试模型,训练集用于训练模型。
MSML-Product中的每个图像都有两个标签:类别和组别。这两个标签满足一个层次结构,即一个组别包含多个类别。对于类别而言,MSML-Product保持开集设置,即训练集和测试类别没有交集。测试集中的类别对于网络来说是全新的。对于组别而言,MSML-Product保持闭集设置,即测试的所有类别均已在训练集出现过。MSML-Product数据集的详细信息如表1所示。
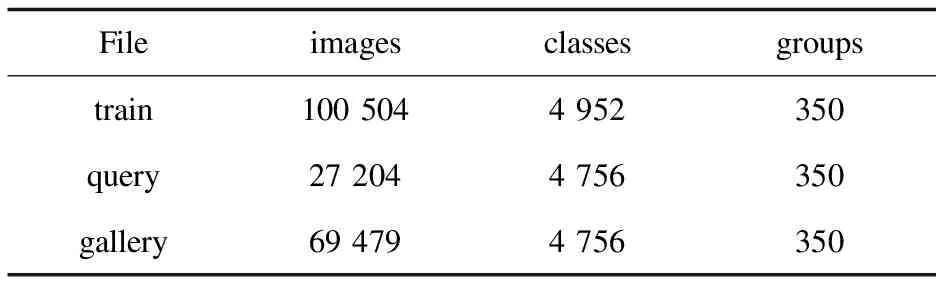
表1 数据集类别分布和样本数量
3.2 评价指标
实验基于图像检索常用的三种评价指标,即累积匹配特征(Cumulative Matching Characteristics,CMC)、平均精度均值(mean Average Precision,mAP)和准确率。CMC表示在前k排序列表中存在真匹配的概率(如Rank-1表示第一位匹配正确的概率)。准确率(Precision)考虑在被模型判断为真的样例中,实际为真的样例比例。本次实验考虑将模型返回的前10个最相似的样本去计算准确率,并记为Prec-10。相比之下,mAP同时考虑了检索结果的精度和查全率。当一个查询有多个正确匹配时(这是常见的情况),mAP强调识别所有正确匹配的能力,特别是那些困难的样本。
3.3 实验细节
该模型的训练主要采用典型的度量学习方法并重点参考了行人重识别领域的相关技术。在训练网络之前,先从ImageNet加载预训练的骨干网络,用于权重参数初始化。需要注意的是图2中主干网Stage4a和Stage4b参数初始化相同。它们都使用预训练模型的Stage4作为初始化。训练中采用标准的图像增强方法,包括随机水平翻转、随机裁剪、随机擦除。每张图像大小调整为224×224像素。训练方面使用了Adam优化器,其初始学习率为3.5e-5,并在30和50个epoch时将学习率缩小0.1倍,直到收敛。实验在Intel E5-2680CPU 2.4 GHz的硬件环境下进行,4张NVIDIA Tesla P100 GPU。该模型每个批量包含16个细粒度类别在内的256个训练样本。对于损失函数权重参数kc,kg和kx,所提模型中先固定其中两个权重参数,每隔0.2对另外一个权重进行每次增大或缩小0.2,直到取最优值。经测试,权重参数最佳配置为1∶1∶1。所有的实验其损失的权重均设置为1∶1∶1。
3.4 实验结果
3.4.1 所提模型的消融实验结果
为便于比较,实验共设置了三种对照模型,以突出文中模型各个模块的有效性。首先采用基线网络作为第一个对照模型,然后在基线网络的基础上,在模型的基础上逐个添加一些模块,以构建其他模型。原始基线模型采用ResNet50骨干网将原始输入图像映射到特征空间。类别和组别共享一个Stage4提取特征。然后在ResNet50后直接连接两个FC层,并使用两个交叉熵损失函数进行优化。
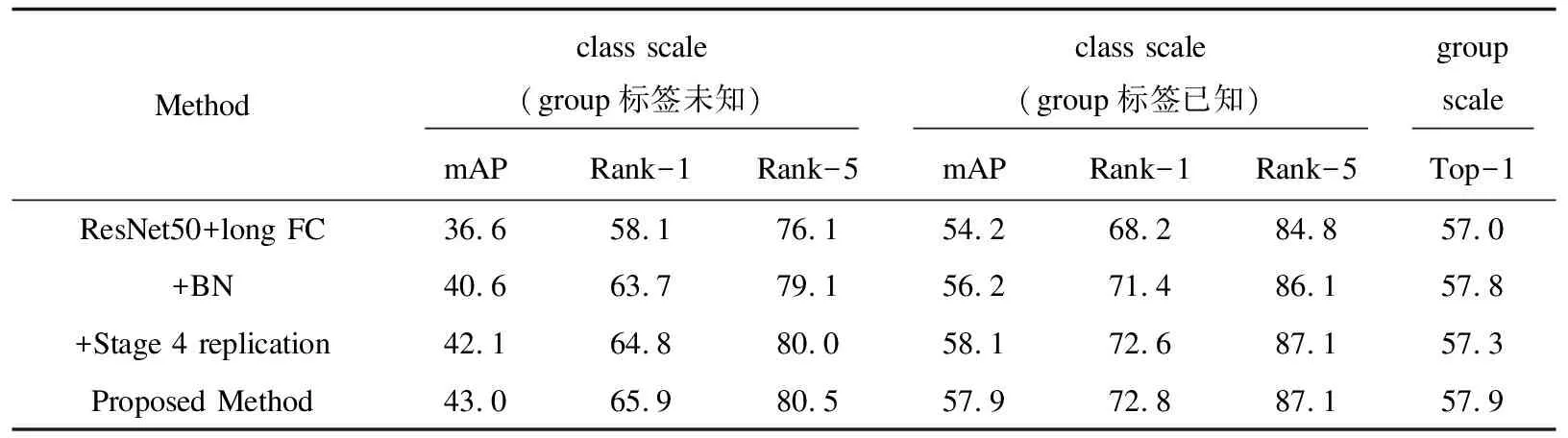
表2 与对照模型的实验结果比较 %
与基线模型相比,第二个对照模型在GAP操作后只增加了一个BN层。第三个对照模型与第二个对照模型相比增加了Stage4复制操作。该模型通过使用Stage4a和Stage4b分离粗粒度和细粒度特征空间。所提模型可以通过在第二个对照模型中添加协同注意模块来获得。实验将所提方法与所有对照方法进行了比较。为了充分证明所提模型的有效性,在已知组标签的情况下也进行了类别检索的相关实验。在表2中列出了这些模型在Softmax损失函数优化下的实验结果。可以看出,在损失函数相同的情况下,所提方法的综合性能最好。从第一个基线模型到所提模型,组别标签未知时,mAP从36.6%上升到43.0%,组别标签已知时,mAP从54.2%上升到57.9%。
对比对照模型的实验结果,可以得出结论,Stage4的复制分离了粗粒度和细粒度级别的特征空间,缓解了不同尺度之间的冲突。此外,协同关注模块融合了类级和组级的层级关系信息,提高了模型的性能。
3.4.2 与相关文献方法对比实验结果
除了与设计的对照模型比较外,实验还包括与文献[18]中最先进的(SOTA)模型与文献[17]中基于自注意力机制的检索模型的比较。SOTA模型是为了解决商品分类问题而设计的。该SOTA模型同样采用ResNet作为骨干网,并使用一种特殊的池化操作——广义均值(GeM)对ResNet输出的特征图进行池化。在池化之后,使用两个BN和FC层分别对组和类进行分类。文献[17]使用将主干网提取到的局部特征经过自注意力模块得到局部融合特征并加在原来的局部特征之后得到最终融合特征进行图像的检索。
为了进一步验证所提方法的有效性,实验在每个模型上分别使用了不同的基于分类的损失函数,即Softmax损失,Cosface和Arcface。从表3可以看出,所提模型与文献[18]中SOTA模型和文献[17]中基于自注意力模块的方法相比性能是最好的。在测试阶段,SOTA模型最后一个FC层将被移除用于图像检索,与所提方法进行比较。实验结果表明,在使用Softmax损失函数进行训练时,所提模型和SOTA模型的性能都是最好的。在使用Softmax损失函数的情况下,无论组别标签是否已知,所提模型总是表现最佳。
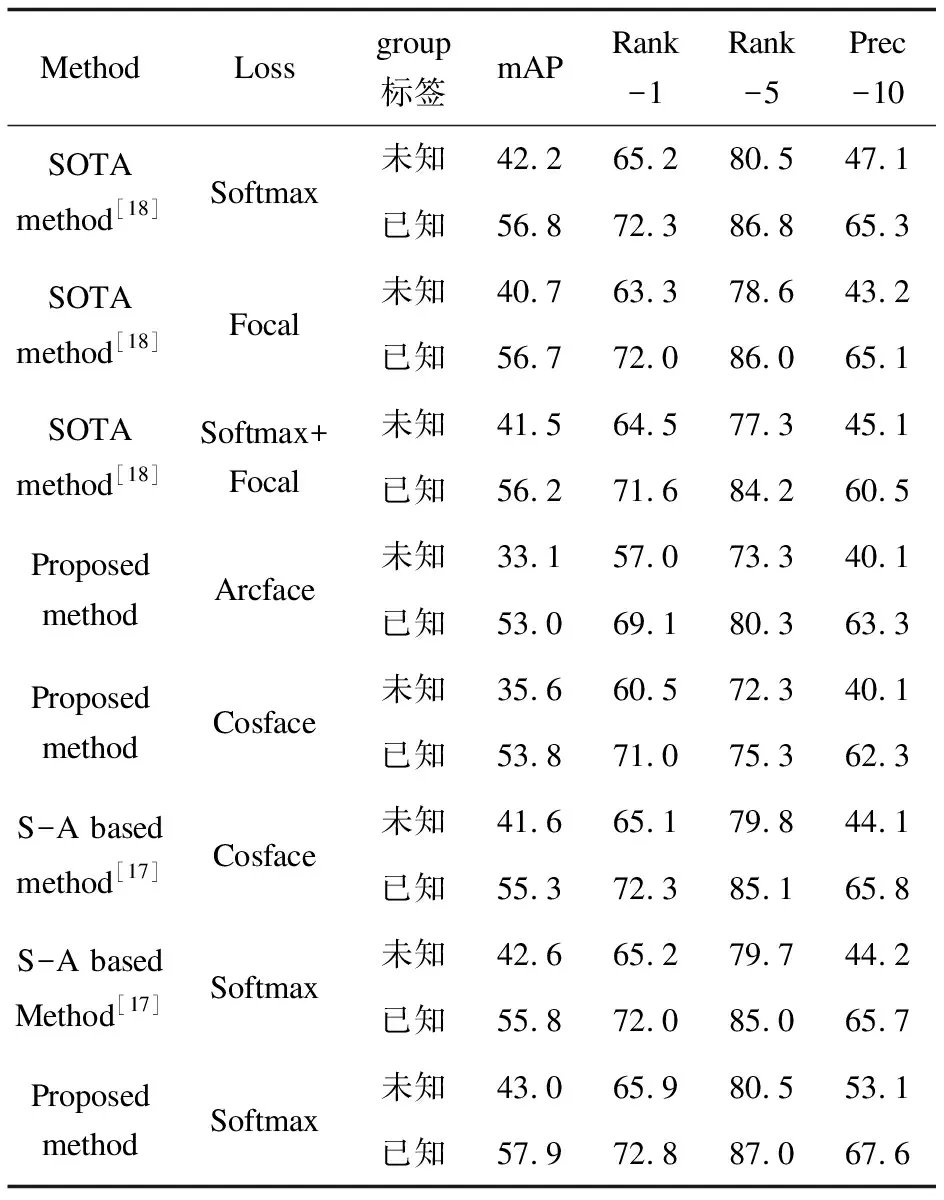
表3 与SOTA模型的实验结果比较 %
此外,在检测速度上,所提方法的检索速度与文献[18]与文献[17]相差不大。所提方法的检索速度为5.4e-4s/张,文献[18]和文献[17]的检索速度分别为4.0e-4s/张和5.3e-4s/张。可以看到,所提方法在没有显著增加检索时间的基础上显著提高了性能。
4 结束语
利用多尺度度量学习的方法,解决了大规模商品识别中使用有限类别的图像识别新增类别商品图像的问题。重点提出了一种充分利用商品图像多尺度信息的MSML模型。在大规模商品图像检索数据集上的实验结果表明,该方法是有效的,显著提高了商品识别的综合性能。
