基于类间排名相关性的解耦知识蒸馏
2024-01-24朱子奇徐仕成
陈 颖,朱子奇,徐仕成,李 敏
(武汉科技大学 计算机科学与技术学院,湖北 武汉 430065)
0 引 言
卷积神经网络(CNN)的出现革新了深度学习图像识别领域。因为追求深层次规模架构网络优秀的性能表现和小型网络在生活中的适用性,知识蒸馏(KD)随之诞生并且被广泛应用于图像分类[1]、目标检测[2]和语义分割[3]等任务。其核心思想是将一个繁琐的已优化模型(教师网络)产生输出概率,用于训练另一个简化模型(学生网络)[4]。知识蒸馏不仅在培养学生网络方面取得了不错的效果,而且在通过自蒸馏改进教师网络方面也非常有效[5-6]。
解耦知识蒸馏(Decoupled Knowledge Distillation,DKD)将教师网络和学生网络的logits输出解耦成两部分,一部分是目标类知识蒸馏(Target Class Knowledge Distillation,TCKD),另一部分是非目标类知识蒸馏(Non-Target Class Knowledge Distillation,NCKD),两者单独进行蒸馏[7]。通过对TCKD和NCKD的分析验证与实验,证明了NCKD的重要性。由于传统知识蒸馏糅杂TCKD与NCKD一起蒸馏训练,使用学生网络的预测匹配教师网络的预测,这将抑制NCKD发挥作用。即传统知识蒸馏的高耦合性导致logit蒸馏的图像分类效果并不理想。因此,可以通过解耦知识蒸馏解决传统知识蒸馏的高耦合性问题。
知识蒸馏和解耦知识蒸馏都遵循精确的恢复方式,即学生损失应严格接近教师损失指标,教师损失应相应地改进学生网络以达到和教师网络近似一样的结果[8]。然而,由于近似差距,这一假设并不总是成立的,这将给学生网络的优化带来偏差,导致次优结果或逆向结果。换句话说,模型不是追求评估度量的精确恢复,而是体现度量的目的,即蒸馏模型的性能。如果一个模型的损失比另一个模型小,那么它的度量应该更好。然而,当前教师网络和学生网通常都存在代理损耗与评价指标之间的关系较为薄弱的问题。理想情况下,代理损失应保持评价指标与模型的强相关性。相比起知识的个体,知识的构成可以更好地被知识表现的关系呈现出来。而结构关系中包含更多的知识,因此保留教师和学生类间的预测关系对于优化蒸馏表现是有效的[9]。
在这些方法中,知识蒸馏以及解耦知识蒸馏被证明是一种通过模仿深层次结构网络行为来提高小型网络性能的有效方法。它通过在每个输入实例的教师和学生的输出上添加一个基于概率的点对点式精确匹配的强一致性约束,来鼓励学生去模仿教师的行为。然而,在这样强的约束条件下,直接优化学生损失很难得到准确的预测。该文并不只关注点对点的恢复,这忽略了类之间相对值的排名关系,而是通过显式地学习类间排名的相关性来缓解“紧张”的约束,并获得显著的性能和效率的提高。
针对上述问题,通过类的排名相关性作为蒸馏的师生模型中代理损失与评价指标之间的关系,该文提出了一种排名相关一致性解耦知识蒸馏的方法来直接放大排名相关性。具体来说,该方法直接利用简单的皮尔逊相关系数[10]。与精确恢复概率相比,基于相关性的优化更易于知识的迁移学习,并且损失函数可以与目标指标保持良好的关系一致性,与原始的解耦知识蒸馏损失相比,获得了更好的相关性。主要贡献如下:
(1)提出了一种新的排名相关一致性解耦知识蒸馏方法,它关注了不同类之间的相关性,解决了输出的强一致性约束带来的分类准确率下降问题。这是首次将类间排名相关性引入解耦知识蒸馏的方法;
(2)提出了一种能够直接衡量类间排名相关性的新损失函数;
(3)通过充分的消融实验和对比实验表明,该方法在不同的任务如CIFAR-100和ImageNet-1K中都能有效提高蒸馏性能,取得良好的图像分类精度。
1 相关工作
知识蒸馏这一技术的理论最早由Hinton[4]于2015年提出,是一种基于“教师-学生”网络的模型训练方式。知识蒸馏是构建一个小型的学生模型,利用性能更好的大型教师模型的监督信息来训练这个学生模型,使得小型的学生模型可以拥有更好的性能和更高的精度[11]。与直接使用One-hot标签的训练不同,知识蒸馏使用的概率分布可以提供更多关于样本相似性的信息,这些信息被称为“暗知识”。因为知识蒸馏中从教师网络迁移到学生网络的知识不同,所以知识蒸馏的知识可以分为基于响应的知识、基于特征的知识和基于关系的知识。
1.1 基于响应的知识
基于响应的知识一般指模型最后输出层的logits结果,然后学生网络直接模仿教师网络的最终预测[12]。当选择用来进行表示学习的神经网络的层次越深,中间层的监督就显得越重要,因此基于响应的知识蒸馏逐渐淡出知识蒸馏的研究视野。近几年新提出的解耦知识蒸馏使得基于响应的知识蒸馏潜能被发现。解耦知识蒸馏是出于传统知识蒸馏的高耦合性考虑,把logits分为目标类和非目标类,然后分别对它们进行知识蒸馏。
1.2 基于特征的知识
基于特征的知识一般指最后一层的输出和中间层的输出。基于特征的知识蒸馏方法通过学生网络学习教师网络的中间层结构进行知识的迁移。FitNet[13]首次提出了一种提取教师的中间层作为hints层和学生中间层(guided层)进行特征输出匹配的知识蒸馏。Zagoruyko等人[14]将原始特征图中的“注意图”作为知识,然后提取出来进行匹配。OFD[15]引入了一个margin ReLU函数并提出了一个新的损失函数来避免对学生有不利影响的冗余信息。CRD[16]在知识蒸馏中引入了对比性学习,借用对比目标实现知识从教师到学生的传递。ReviewKD[17]采用温故知新的原理,提出了新的知识蒸馏复习机制,利用教师网络的多层次信息指导学生网络的一级学习。
1.3 基于关系的知识
基于关系的知识研究了不同层和数据样本之间的关系。Yim等人[18]提出了能体现任意两个特征图的关系的FSP矩阵来进行知识蒸馏。Lee等人[19]通过两个特征图之间的相关性,利用奇异值分解进行蒸馏。Park等人[20]认为迁移样本间的关系比起迁移单个样本的特征会更有效,提出了一种对模型输出的结构信息进行蒸馏的方式。Peng等人[21]注意到了实例之间的相关性,提出了相关同余的方法。
值得注意的是,Peng等人提出的实例间的相关同余和Park等人提出迁移样本间关系的方法与文中方法有一些相似之处。但是文中方法侧重于类间排名的关系,着重分析了在教师网络和学生网络差距过大时限制解耦知识蒸馏潜力的因素。文中提出使用类间排名相关一致性来解决问题,同时提出了新损失函数来优化模型,提升任务效果。
2 文中方法
2.1 基于类间排名相关性的解耦知识蒸馏
解耦知识蒸馏虽然证明了NCKD的重要性,但它和传统的知识蒸馏都是采用学生网络精确匹配教师网络输出概率的方法,体现不了教师网络和学生网络内部类间的关系结构。而拥有更深层次规模架构的网络会取得更好的表现,因此会选取一个庞大的教师网络,这也就导致了教师网络和学生网络规模相差较大。在这种差距下,使用传统的KL散度来精确地恢复预测变得更为乏力。
该文提出了一种利用皮尔逊相关系数进行关系匹配的方法。相比于KL散度的精确式匹配,提出的更为宽容的匹配方式不再关心教师中NCKD输出的预测分数,而是注意到教师预测非目标类的相对排名的关系。如图1所示,解耦知识蒸馏借助学生各个类的预测分数与教师各个类的预测分数一对一精确匹配从而进行知识的迁移。越大的预测分数意味着这个类与目标类越相似,最终NCKD中各个类之间会形成一个预测分数的排名。文中方法提取NCKD中各个类排名的关系,把学生网络中NCKD的排名关系与教师网络中NCKD的排名关系进行匹配。相比起一对一精确匹配,基于类间排名相关性的方法只需让学生保持和教师相似的排名关系,然后进行学生和教师的关系匹配,所以文中方法包含了更多的知识,知识间的构成也可以更好地表现出来。通过这种方式,学生不再需要精确的一对一匹配教师的输出概率,而是更多地关注整体的关系信息。

图1 模型架构
文中方法提倡维护教师网络与学生网络之间的类间关系,以类间排名相关性作为知识进行传递,实现从优秀的教师中更好地进行知识蒸馏。
2.2 NCKD的类间排名相关性匹配
知识蒸馏的目标是在训练有素的大型教师网络的指导下培养更便于部署的小型学生网络。而在解耦知识蒸馏中,通过最小化教师网络与学生网络的TCKD和NCKD的预测分数之间的差异实现知识从教师网络到学生网络的转移。在蒸馏中,训练有素的教师网络提供了超出通常数据监督的额外语义知识,而挑战在于如何对教师的知识进行编码和转换,使学生的表现可以达到最大化。
对于来自第t类的训练样本,学生网络和教师网络的logits输出分别为Z(T)∈R1×C和Z(S)∈R1×C,其中[Z(T),Z(S)]∈Z。分类概率可以表示为P=[p1,p2,…,pT,…,pC]∈R1×C,其中pi表示第i个类的概率,C表示类的个数。分类概率p中的每个元素都可以通过softmax()函数和温度因子T进行评估:
(1)
非目标类∧P是众多类的集合(除去目标类),即∧P=[∧p1,…,∧pT-1,∧pT+1,…,∧pC]∈R1×(C-1),其中每个类的概率可表示为:
(2)
对于解耦知识蒸馏,需要解耦目标类和非目标类。因此定义b=[pT,pN]∈R1×2,b代表目标类和所有非目标类的二值概率,pT代表目标类的概率,pN代表非目标类的概率:
(3)
(4)
根据式1~式4可以推断出pi=∧pi×pN,所以KD的loss可表示为:
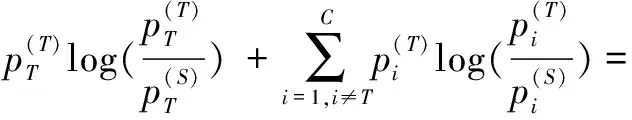
(5)
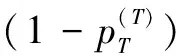
LKD=αTCKD+βNCKD
(6)
对于预测向量∧p(T)和∧p(S),若x=y,则x和y之间可以得到一个精确的匹配距离为0,即d(x,y)=0。该文使用一种较为“轻松”的匹配方式,所以引入关系映射f()和g():
d(x,y)=d(f(x),g(y))
(7)
文中方法注重x,y之间的内部关系,所以并不要求x和y完全一样。为了不影响NCKD向量所包含的信息,映射f()和g()应该是等值的,因此选择恒等变换:
d(x,y)=d(a1x+b1,a2y+b2)
(8)
其中,a1,a2,b1,b2都是常数。
该文使用皮尔逊相关系数。皮尔逊相关系数广泛用于衡量两个变量之间的相关程度,反映了两个变量之间的线性关系和相关性的方向。最重要的一点是皮尔逊相关系数有一个很重要的数学特性:当变量x和y的位置发生变化时,皮尔逊相关系数不会发生变化。也就是说把变量x和y移动为ax+b和cy+d(其中a,b,c和d皆为常数)并不会引起x和y相关系数的变化,而这一点数学特性恰好完美地契合了文中方法所追求的特性d(x,y)=d(a1x+b1,a2y+b2)。皮尔逊相关系数ρ∧p(x,y)可表示为:

(9)
2.3 损失函数
皮尔逊相关系数的变化范围为[-1,1],当相关系数值为0时代表两个变量之间没有任何线性关系,故皮尔逊距离应当为1。所以,皮尔逊距离d(x,y)和皮尔逊相关系数ρ∧p(x,y)的关系可以表示为:
d∧p(x,y)=1-ρ∧p(x,y)
(10)
所以,该文的损失函数是:
LKD=αTCKD+βd∧p(x,y)
(11)
文中方法通过最大线性相关来保留教师网络和学生网络在每个实例的概率分布上的关系,所以可以更好地泛化到输出的整个分布,是一种更为稳健有效的方法。
3 实验与分析
3.1 数据集介绍及评价标准
CIFAR-100[22]是知识蒸馏分类领域应用最为广泛的一个数据集,也是文中实验所采用的一个数据集。CIFAR-100数据集包含50 000张训练图像和100个类别。每个类别有600张大小为32×32的彩色图像,其中500张作为训练集,100张作为测试集。对于每一张图像,它有fine_labels和coarse_labels两个标签,分别代表图像的细粒度和粗粒度标签。
ImageNet-1K[23]是ImageNet的子集,来自于斯坦福大学的课程项目,是一个极具挑战性的数据库,也是图像分类任务中使用次数较多的大型数据库。ImageNet-1K共有1 000个类别,训练集有1 281 167张图片且附带标签,验证集有50 000张图片并且附带标签,测试集有100 000张图片。
该文引入了图像分类任务中的准确率(Accuracy)作为实验的性能评价指标,该基本指标代表在所有样本中预测正确的概率,是图像分类任务中最直观的性能评价指标。Top-1 Accuracy代表排名第一的类别与实际结果相符合的准确率。
(12)
其中,TP代表被判定为正样本,实际上也是正样本的样本数;TN代表被判定为负样本,实际上也是负样本的样本数;FP代表被判定为正样本,但实际上是负样本的样本数;FN代表被判定为负样本,但实际上是正样本的样本数。
3.2 实验参数
实验皆在Linux系统上进行并基于Pytorch框架,使用了五张NVIDIA GeForce RTX 2080 Ti GPU。实验中使用ResNet[24],VGG[25],ShuffleNet[26-27],MobileNet[28]和Wide ResNet[29]网络。对于CIFAR100数据集,实验的Batchsize大小为128,不同的学生网络设置了不同的学习率初始值,如表1所示。实验所有模型进行240个Epoch的训练,在150个Epoch之后,每30个Epoch的学习率衰减0.1。对于ImageNet-1K数据集,实验使用标准的训练过程,将Batchsize大小设置为256,所有模型进行100个Epoch的训练,实验将学习率初始化为0.1,然后每30个Epoch衰减学习率。文中方法的总损失函数中的超参数α和β分别设置为1.0和8.0。

表1 在CIFAR-100数据集上不同网络设置的学习率
3.3 消融实验
为了研究损失函数对于蒸馏模型性能的影响,使用ResNet32×4作为教师网络,ShuffleNetV2作为学生网络,对三种方法分别训练240次,在CIFAR-100数据集上实验得到的精度结果如表2所示。传统的知识蒸馏图像分类达到了74.07%的准确率。接下来选取基于解耦的知识蒸馏作为基准网络,解耦目标类和非目标类进行蒸馏,图像分类达到了76.45%的准确率,解决了因为传统知识蒸馏的高耦合性带来的精度降低问题。最后是该文提出的基于非目标类类之间预测排序关系的知识蒸馏,改善了强一致性约束后,模型达到了77.38%的准确率,相比基准网络提升了0.93百分点,解决了解耦知识蒸馏强一致性约束对精度带来负面影响的问题,证明了该方法的有效性。消融实验结果表明,该方法可以更好地体现类之间的相关性并泛化到输出的整个分布,降低了教师和学生因模型架构悬殊和强一致性约束所带来的影响,具有更优秀的分类准确率。

表2 不同方法在CIFAR-100数据集上的实验结果
同时,文中方法和基准方法的loss变化对比如图2所示,文中方法的loss不仅波动更为平缓,而且比基准方法的loss更小一些(差值在0.01~0.05之间波动)。
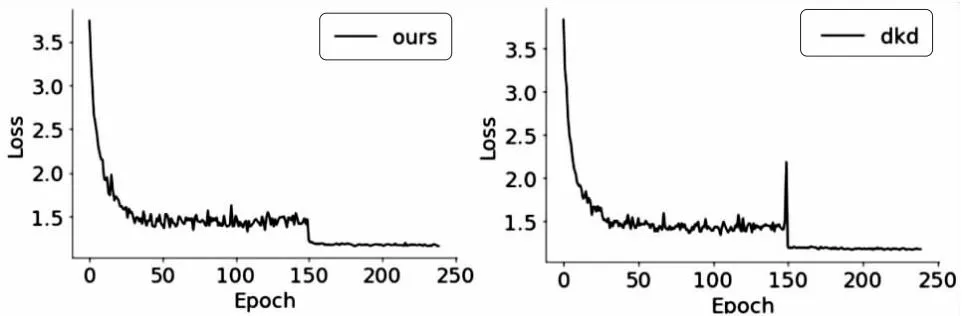
图2 loss变化对比
3.4 对比实验
为了验证文中方法的先进性,在图像分类任务上将文中方法与其它先进的方法进行比较。文中使用的基准方法是解耦知识蒸馏,加入基于类间排名相关性模块后,在数据集CIFAR-100和ImageNet-1K提升了0.2~1百分点。实验结果表明,与基准方法和传统知识蒸馏相比,文中方法在教师学生网络组中一致取得了改善。基于CIFAR-100数据集,文中方法在同系列教师学生网络组中获得了0.2~0.8百分点的提升,在不同系列教师学生网络组中获得了0.2~1百分点的提升,这进一步证明了文中方法的先进性。
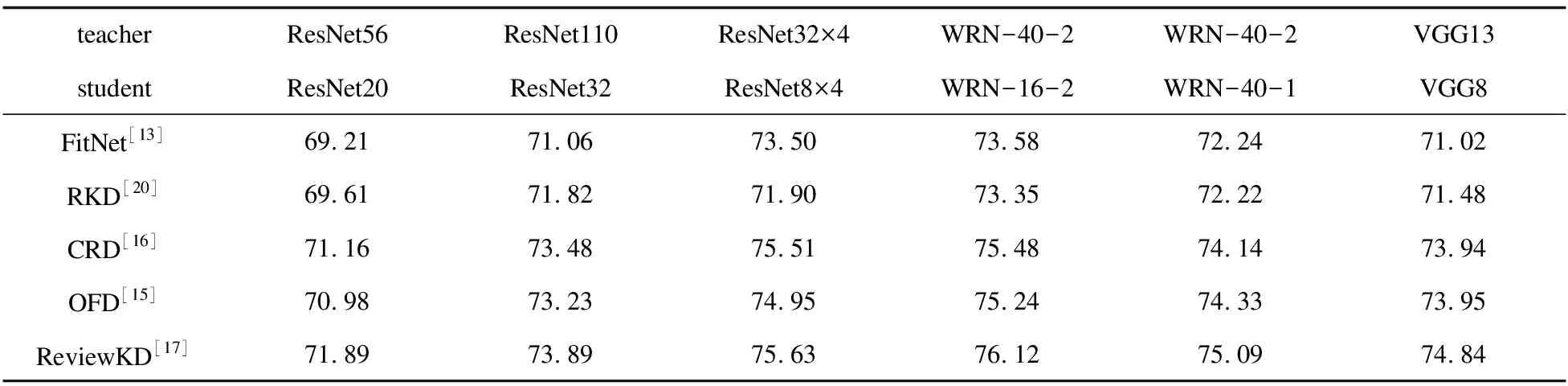
表3 同系列教师学生网络实验结果 %
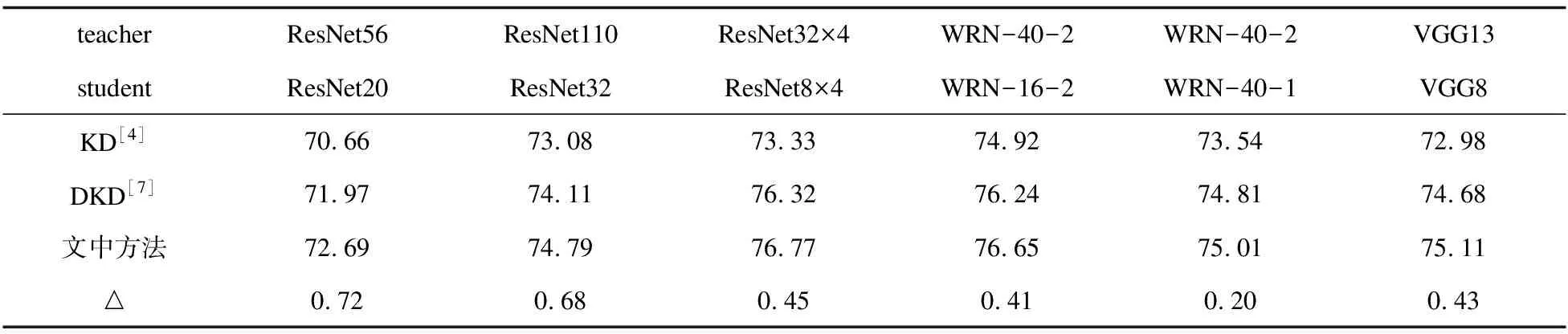
续表3
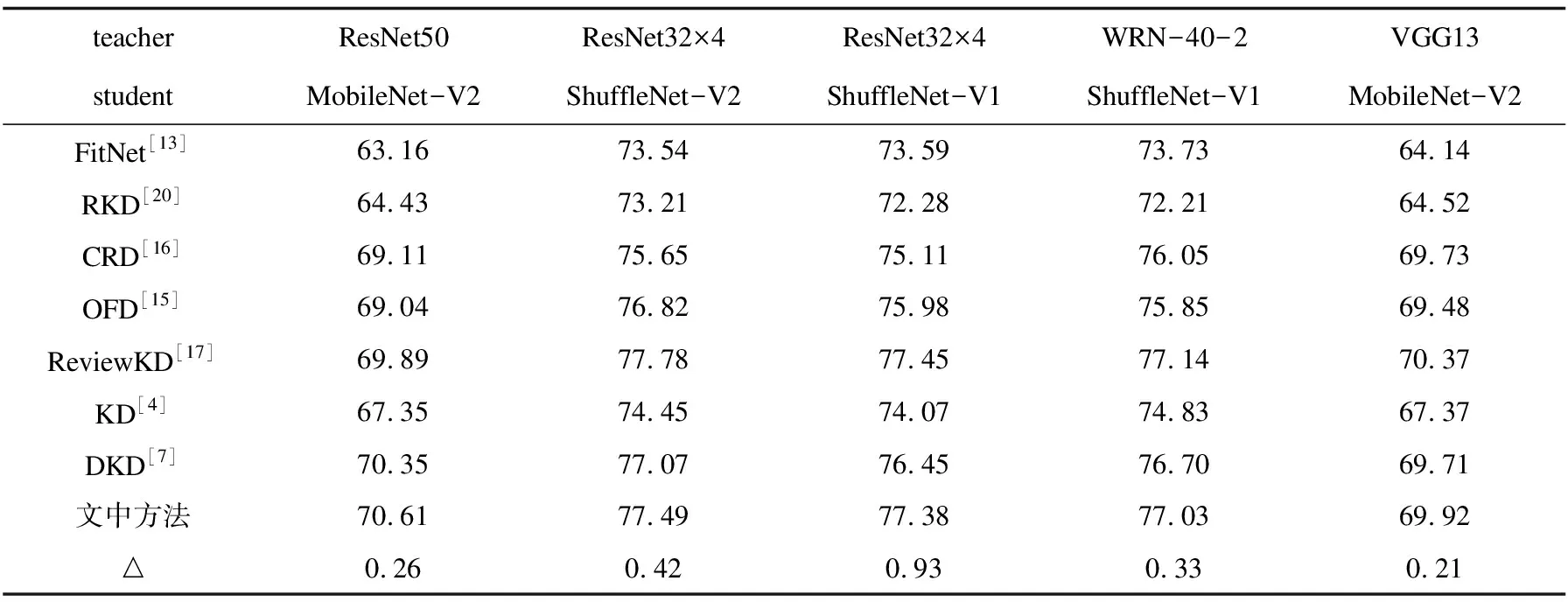
表4 不同系列教师学生网络实验结果 %
由于CIFAR-100的图像数量较少,因此在ImageNet-1K上进行了实验来验证文中方法的可扩展性。实验了从ResNet34到ResNet18的蒸馏设置,文中方法再次优于所有其它方法,如表5所示。
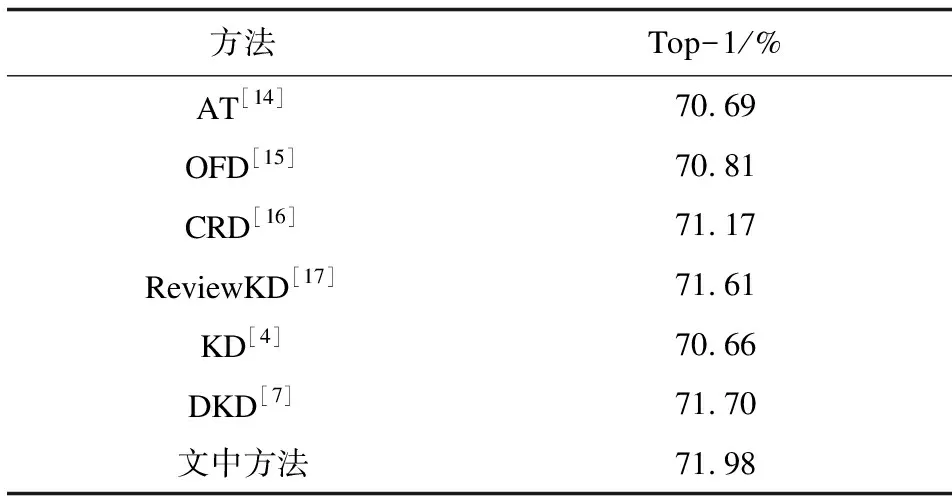
表5 ImageNet-1K数据集的对比实验结果
4 结束语
在解耦知识蒸馏中,针对架构规模悬殊的教师网络和学生网络使用点对点式强一致性约束精确匹配预测概率的问题,提出了一种相关一致性解耦知识蒸馏的方法,即类间排名相关性。该方法针对NCKD采用了类间排名相关性进行一致匹配来缓解logit蒸馏强一致性约束。通过在同系列教师网络和学生网络以及不同系列教师网络和学生网络上的训练测试,该模型的图像分类准确率显著提高,有效提高了解耦知识蒸馏的图像分类能力。
