网购虚假评论识别方法研究
——基于情感极性及多维特征
2024-01-24闵雪
闵 雪
(浙江商业职业技术学院,浙江 杭州 310053)
近年来,随着新零售及移动支付的快速发展,网上购物已成为社会主流消费方式, 作为网络购物的产物,在线评论也随之大量产生。这些评价一方面已经成为影响消费者购买决策的重要因素之一(1);另一方面,在线评论越来越多地影响商品的推广与销量,在利益驱动下,出现了商家背后操纵评论的现象,以达到推销自己商品的目的。 虚假评论的愈演愈烈对网络购物平台秩序造成严重冲击,也给消费者权益带来严重损害。 基于此,本文提出基于情感极性及多维特征的购物平台虚假评论识别方法,针对批量在线评论进行情感分析及特征分析,形成一套有效虚假评论识别方法。
一、相关研究
自2008 年Jindal 等提出虚假评论广泛存在与商品评论中的问题后, 虚假评论的识别就成为电商领域的一个研究热点(2)。 综合国内外近十年对虚假评论识别领域的研究, 目前虚假评论的识别方法大致可以归纳为三类,基于内容的识别方法、基于行为的识别方法、基于内容和行为相结合的识别方法。
Ott、刘玉林等人相继开发了“数据集”和情感指数,对虚假评论进行识别,从而为异常评论识别奠定基础(3-4)。 Li 等通过与大众点评合作,通过分析评论者行为识别虚假评论(5)。 余传明等建立评论个人行为、评论者消费行为、商家行为指标体系,搭建虚假评论者主体关系模型, 实现虚假评论及相关主体的识别(6)。 陈晋音等通过构建用户、商店和评论之间关系的图结构,基于双循环图过滤算法,实现识别(7)。颜梦香等从用户和产品两个角度分别来研判评论文本, 提出了一种基于层次注意力机制的神经网络模型,用于虚假评论识别(8)。
通过总结已有的研究,发现大多数研究都是从文本内容本身、评论者或被评论者行为出发来建立虚假评论的识别模型。 本文从评论内容的角度出发,融合情感极性分析与逻辑回归模型,提出一套行之有效的虚假评论识别方法。
二、评论情感极性分析
以往的研究表明,从心理学及语言学的角度出发,相比正常评论,虚假评论往往有更加强烈的情感表达(9)。核心表现为虚假评论具有极强的目的性,使用大量的极限词,以极力鼓吹或恶意贬低某个商品,从而形成情感强度较大的评论。 本章节将从这一理论依据出发,基于情感极性计算方法,通过情感打分的方式进行文本情感极性研判,将情感极性分为正向、负向、中立三类,再进一步判断每条评论的情感偏离大众情感的程度,从而实现虚假评论的初筛。
目前常见的情感极性计算方法大致分为两类,基于情感词典的方法和基于机器学习的方法(10)。 情感词典方法对评论文本进行分词,之后对比情感极性词库,通过计算句子的正向得分与负向得分及两者相加的综合得分,设定阈值进行比较,得到该文本的情感极性程度。 本文采用Jieba 分词对在线评论进行自然语言切分, 将NTUSD 简体中文情感词典、知网情感极性词典作为基础情感词典,同时纳入否定词词典、程度副词词典,引入NLP 研究领域中的n-gram 方法进行词组搭配,依托前影响词、后中心词的情感方向和影响程度来实现情感极性值的计算,整体流程图如图1。

图1 基于情感词典方法的在线评论情感极性计算流程图
三、基于逻辑回归模型的虚假评论识别
(一)在线评论数据集
从某电商平台数码、手机、食品、服装、美妆、箱包六个典型类目中, 选取各类目排名前十的商品。通过Python 设计爬虫程序进行在线评论数据的采集,借助大众公开平台的虚假评论过滤系统进行虚假评论的标注,得到在线评论数据集。 对采集数据进行标注处理后,得到正常评论8195 条,虚假评论2843 条,具体情况如表1。
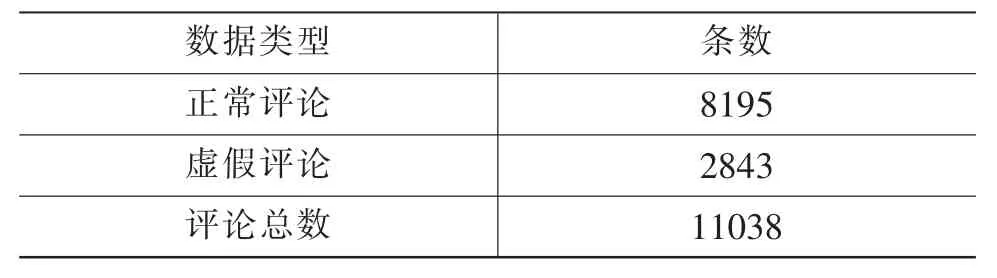
表1 在线评论数据集
(二)文本特征工程
文本特征即基于评论文本的元数据特征,尽管虚假评论刻意伪装并具有较高的迷惑性,但评论内容是建立在不真实的购物经历上,在情感极性与文本特征上必然与正常评论存在一定的差异。 通过对大量虚假评论内容进行分析以及总结虚假评论特征现有研究的结果,纳入上一章节评论情感极性值结果, 本文定义以下10 个可能影响虚假评论的特征,如表2 所示。
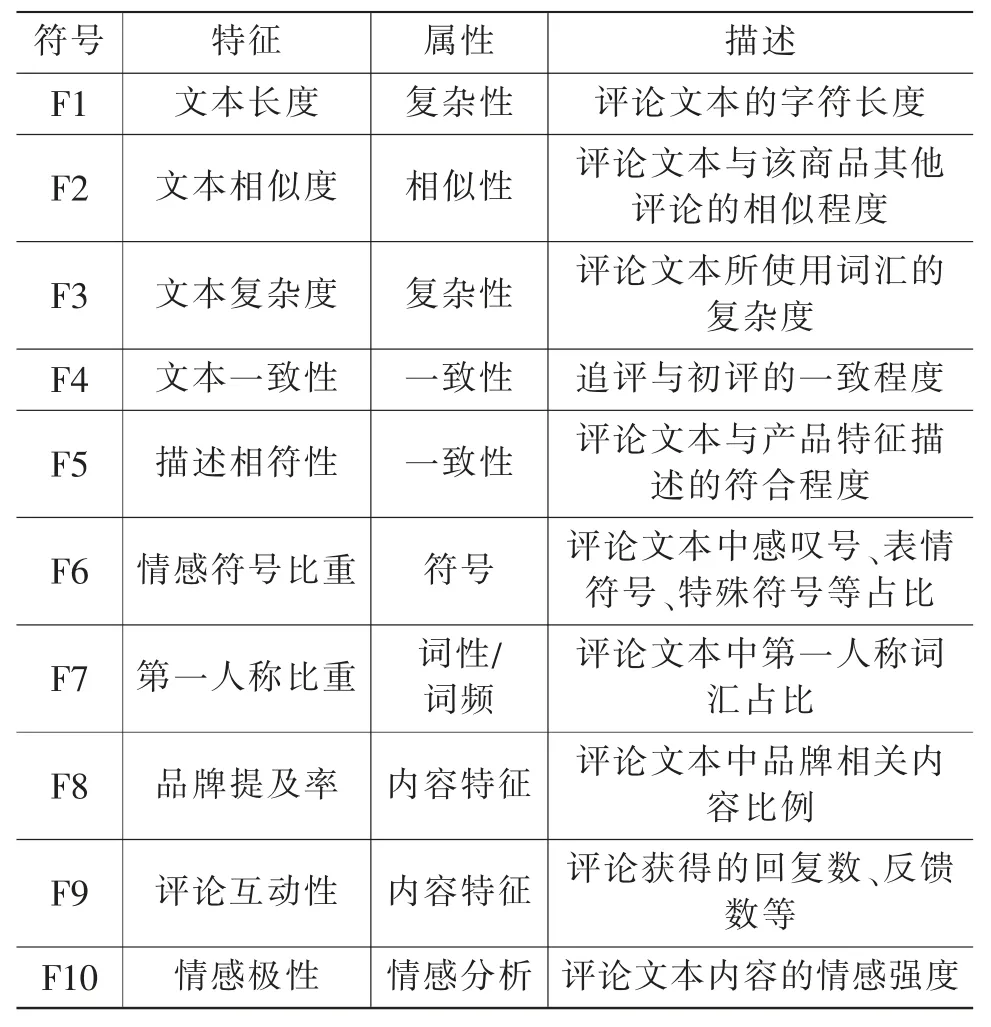
表2 虚假评论的文本特征及描述
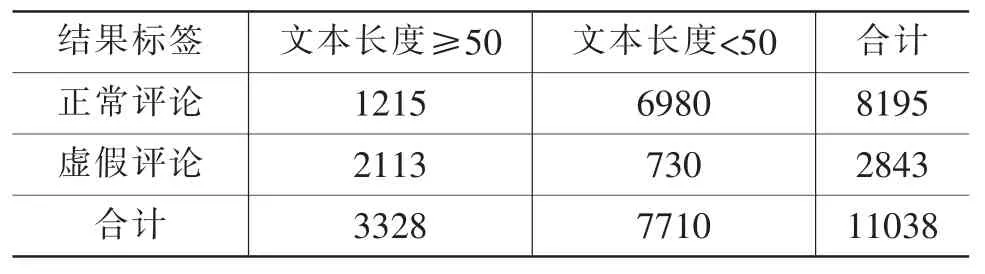
表3 文本长度特征分布表
具体分析:(F1)文本长度即评论文本的字数,正常评论者往往懒于给出评论或给出较短的评论,虚假评论者为达到鼓吹或贬低的目的通常会给予较为冗长、细节性的商品描述。(F2)文本相似度即该条文本内容与本商品其他评论内容的相似程度, 正常评论者基于自身真实的购买和使用体验, 通常会给出较为主观和相似度低的评论; 而虚假评论者为完成评论任务, 往往大量复制商品已有评论内容进行拼凑。(F3)文本复杂度,虚假评论者往往使用大量复杂和专业的词汇。 (F4)文本一致性即初评与追评的内容、时间的一致性,虚假评论往往初评与追评有极高的一致性,且间隔时间较为短暂。(F5)描述相符性即评论文本与产品特征描述的相符程度, 正常评论往往贴合商品的特征,而虚假评论者为了快速评论,会复制一些模棱两可甚至不相关的文本内容。 (F6)情感符号比重即评论文本中感叹号、表情符号、特殊符号等的占比,虚假评论中为了表达强烈的情感,往往会使用大量的情感符号。(F7)第一人称比重,评论文本中第一人称词汇所占的比例比较高, 以增加评论的可信性(11)。 (F8)品牌提及率即评论文本中品牌相关内容占整体内容的比例,本文认为,虚假评论为了推广自身的品牌, 通常会在评论中大量提及自身品牌,以实现品牌的快速种草。(F9)评论互动性即评论获得的回复数、反馈数等,一般来讲,正常评论往往为消费者带来更加实用的信息, 从而产生大量的互动;而虚假评论往往疏于后期的互动管理,从而具有较低的互动性。(F10)情感极性即评论文本的情感强度,基于上个章节的研究,虚假评论为实现鼓吹或变贬低某个商品, 往往使用大量的极限词从而形成较强的情感极性。
(三)基于逻辑回归模型的特征选择
特征选择即特征子集选择(FSS),是指从已有的特征集中选择相关性最好的特征子集,使得模型的识别目标最优化,常用的方法有方差选择法、卡方检验、互信息法、递归特征消除、树模型等。 本文定义的是离散数值特征,同时考虑虚假评论识别也是一个二分类问题, 因此采用Logistic 回归模型进行特征的筛选及后续虚假评论的识别。
1.逻辑回归。 Logistic 回归是机器学习中的一种分类模型,在线性回归的基础上,套用逻辑函数用于估计某种事物的可能性。 使用场景大概有两个,一是用来预测; 二是用来寻找因变量的影响因素。目前,Logistic 回归模型常用在垃圾邮件的识别、电商商品推荐、疾病诊断等二分类问题上。 本文关于虚假评论的识别也是一个典型的二分类问题,因此借助该模型,一方面研究各个文本特征对因变量结果的影响程度从而实现特征的筛选;另一方面基于因变量的预测值实现垃圾评论的快速识别。 Logistic回归模型的一般形式如下:
其中F1,…,Fn为特征自变量,θ1,…,θn为回归系数,P 为在n 个特征变量影响下虚假评论发生的概率。 因变量Y 为二分类变量,因此取值为
2.特征变量衡量标准及筛选。 Logistic 回归用在寻找因变量影响因素的场景时,通常需要基于优势比OR。 优势比为实验组的事件发生概率/对照组的事件发生概率的比值,反映的是某种暴露(特征)与结局的关联强度。 具体到定量分析上,当结果出现记为1,不出现记为0 时,OR 值的含义可以总结为:
接下来以文本长度为例来展示优势比的计算逻辑及衡量标准,这里我们定义评论文本字数≥50为长文本。
则优势比OR=1.739/0.105≈16.562, 因此文本长度特征对虚假评论的结果出现呈现显著的促进作用。 本文利用Python 中statsmodels 算法包,分别计算本文定义的10 个可能影响虚假评论特征的优势比OR,结果如表4。
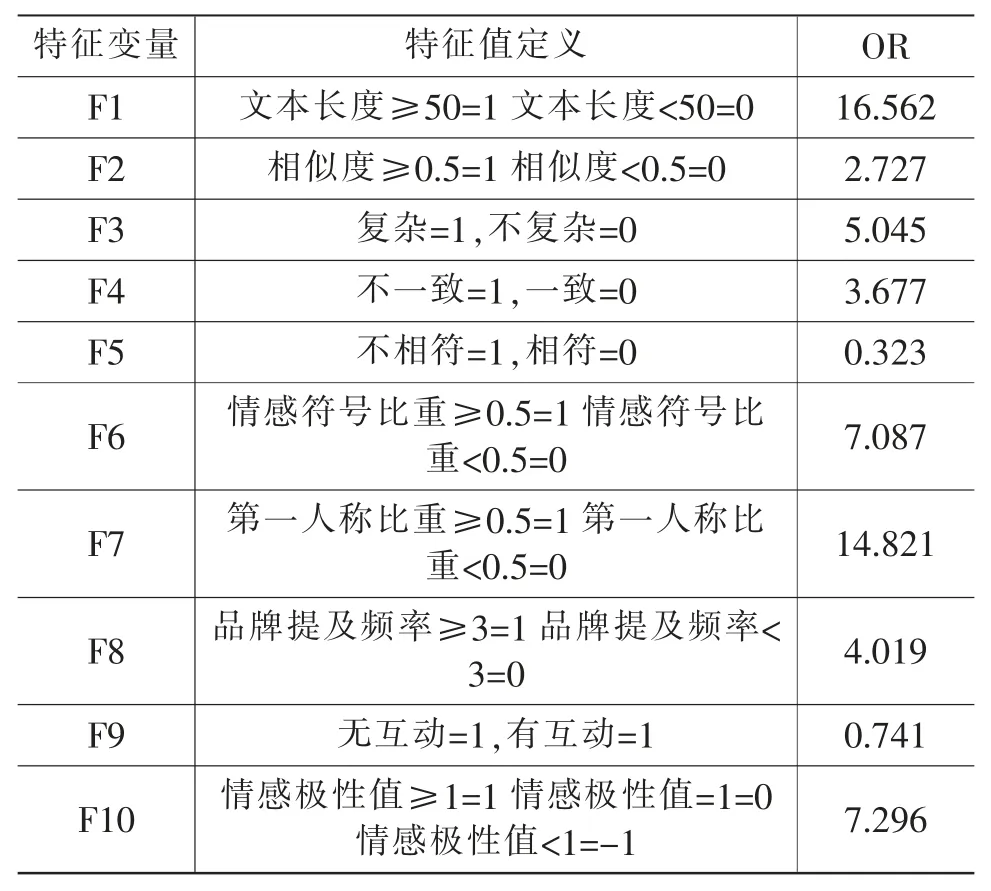
表4 10 个可能影响特征的优势比
同时在广义线性回归模型中,也会采用前向选择、 后向选择和逐步回归等方法进行变量的筛选。这里使用逐步回归的方法, 对上述10 个特征变量逐一引入模型自变量池中进行检验,最终变量筛选结果与优势比OR 衡量的结果一致。
(四)虚假评论识别
基于已筛选出来的特征变量,本文使用Logistic回归来进行虚假评论的识别,具体实现流程如图2。

图2 基于逻辑回归模型的虚假评论识别流程
具体分析:(步骤1)数据集的选取划分,对已有的标注好的10038 条在线评论数据, 按照8:1:1 的方式随机划分为训练集、验证集、测试集,来进行模型的训练和测试。(步骤2)训练逻辑回归模型,利用Logistic 回归对训练数据进行训练,并且为了防止过拟合的问题,这里为模型增加正则项。(步骤3)模型优化,初步训练出来的模型往往有各种不足,因此需要不断地优化模型, 让模型逐渐达到理论最优值。 常用的优化方法有三类,特征提取、正则化和降维。在这里,我们采用正则化的方法。通过不断调整正则参数c 的大小, 模型的预测效果也随之变优,具体优化过程如图3 所示。(步骤4)模型评估,这里使用精确率、召回率、F1-score 作为模型结果评估的指标,根据步骤3 优化情况,选择使模型达到理论最优的参数值, 之后对测试集数据进行分类预测,汇总分类结果可得表5 测试集的混淆矩阵。 Logistic回归对虚假评论的分类模型在测试集上的分类精确率为0.862, 召回率为0.790,F1 得分为0.825,意味着模型有较好的分类预测性能。

表5 基于测试集的混淆矩阵
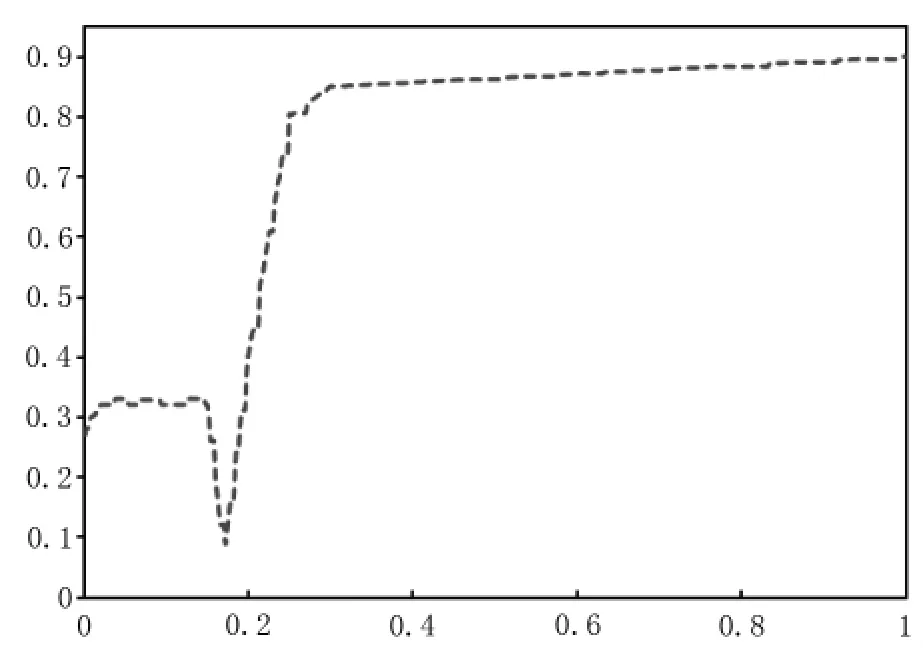
图3 Logistic 回归训练过程
(五)案例识别分析
从上述模型的预测结果为虚假评论的结果集中随机抽取若干案例,进行人工校验分析,由于篇幅有限,粘贴部分评论,见表6。

表6 部分虚假评论
以上部分在线评论乍一看并无不妥,如若不是有专业的知识储备,或许并不会敏锐地发现有任何问题。 基于Logistic 回归模型的虚假广告分类对各个特征做了较好的拟合,针对以上虚假评价均做了正确地识别。 譬如第1、2 条不仅文本长度长、多次提及品牌、使用专业的术语,同时第2 条还大量使用了情感符号。 第4、6、7、10 条,为了突出效果使用大量的情感词,描述空洞,尤其4、10 不排除存在恶意评价的嫌疑。 第3、8 条具有高重复性和不一致性,现实中一个真正的消费者大概率是不会这样评论自己购买的商品的。 由此可见基于Logistic 回归的虚假评论识别是有效果的。
基于情感极性及多维特征,本文实现虚假评论的初筛。 在情感极性特征的基础上,本文定义了关于虚假评论的10 个特征变量,并使用优势比OR 和逐步回归方法筛选8 个特征变量子集纳入模型特征工程, 最终使用Logistic 回归实现虚假评论的识别,通过混淆矩阵检验本文的识别方法取得了较好的效果。
注释:
(1)郭恺强,曹丽.基于隐含语义分析的电商虚假评论识别方法初探[J].今日财富,2021(17):97-99.
(2)Jindal Nitin,Liu Bing.Opinion spam and analysis[C]. Proceedings of the International Conference on Web Search and Data Mining(WSDM),California,USA,2008:219-230.
(3)任亚峰,尹兰,姬东鸿.基于语言结构和情感极性的虚假评论识别[J].计算机科学与探索,2014(03):313-320.
(4)刘玉林,菅利荣.基于文本情感分析的电商在线评论数据挖掘[J].统计与信息论坛,2018(12):119-124.
(5)薛晨杰,王召义.文本情感分析在虚假评论识别中的应用研究[J].闽西职业技术学院学报,2021(01):33-37+93.
(6)余传明,冯博琳,左宇恒,陈百云,安璐.基于个人-群体-商户关系模型的虚假评论识别研究[J].北京大学学报(自然科学版),2017(02):262-272.
(7)陈晋音,黄国瀚,吴洋洋,贾澄钰.基于双循环图的虚假评论检测算法[J].计算机科学,2019(09):229-236.
(8)颜梦香,姬东鸿,任亚峰.基于层次注意力机制神经网络模型的虚假评论识别[J].计算机应用,2019(07):1925-1930.
(9)缪裕青,欧威健,刘同来,刘水清,文益民.基于情感极性与SMOTE 过采样的虚假评论识别方法[J].计算机应用研究,2018(07):2042-2045.
(10)程永胜,徐骁琪.基于用户评价数据的电动汽车造型意象决策模型[J].太原理工大学学报,2022(05):886-894.
(11)尹春勇,朱宇航.基于垂直集成Tri-training 的虚假评论检测模型[J].计算机应用,2020(08):2194-2201.
