基于情感特征和用户关系的虚假评论者的识别
2016-06-08邵珠峰姬东鸿
邵珠峰 姬东鸿
(武汉大学计算机学院 湖北 武汉 430072)
基于情感特征和用户关系的虚假评论者的识别
邵珠峰姬东鸿
(武汉大学计算机学院湖北 武汉 430072)
摘要随着电子商务的迅速发展,人们越来越亲睐于网上购物。在网上购物之前,消费者往往会参考该产品相关的评价以决定是否购买。因此虚假评论者的识别具有非常重要的意义。基于虚假评论者和真实评论者在情感极性上存在的差异,在特征建模过程中增加了评论文本的情感特征,并结合用户之间对于特定商品之间的关系,创建了一个多边图的模型并提出了一种识别虚假评论者的方法。实验结果验证了该算法的有效性。
关键词电子商务虚假评论者情感特征用户关系
0引言
Web 2.0的到来极大地改变了人与人之间交流的方式,人们可以在各种社交平台上发表自己的观点。Web 2.0 网络应用中,电子商务是发展最快的领域之一。因此,网上购物越来越受到人们的欢迎。消费者在购买商品之前,通常会阅读与此产品相关的评论,根据评论的好坏再决定是否购买。但是,不是所有的评论都是真实的,一些虚假评论者在利益的诱引下写下虚假评论以误导消费者。所以,虚假评论者的识别对于电子商务的发展有很重要的意义。
在网上购物时,评论信息可以直接影响消费者的购买决策。因此,在利益的驱动下,一些商家雇人为自己的商品发布一些不切实际的正面评论以提高信誉,或者为了诋毁竞争对手而发布一些恶意的负面评论。这些虚假评论者严重影响了电商平台上的正常竞争。通过总结之前研究者对虚假评论者的认识,本文将虚假评论者分为以下2类:
1) 类型1(欺骗性评论发布者):蓄意发布一些正面评论以提高商家名声,或者故意写下恶意评论破坏商家声誉。
2) 类型2(破坏性评论发布者):发布一些与商品无关的评论、广告。
因为人们可以很容易地识别破坏性评论,所以破坏性发布者的危害不大。但是欺骗性评论发布者可以刻意地掩饰自己所发表的虚假评论,使其与正常评论看似没有差别,即使是人工识别方法也难以检测。而且,到目前为止,欺骗性评论者的检测方法不是很多,且效果不好。本文主要面向于这种识别难度更大的欺骗性虚假评论者的研究,创新性地采用了评论者之间情感方面的差异来构建特征模型,并结合用户之间的关系构造出一种多边图的模型,最后计算出用户不可靠分数来识别虚假评论者。
1相关研究
最近几年,虚假评论者的识别已经成为数据挖掘领域最为活跃的研究之一。相关研究者提出了许多新颖的方法,但是仍然有许多问题存在。由于在很多情况下,正常用户也无法识别一个评论是否为虚假评论,从而造成标注数据不足以及难以评估检测效果,这也是虚假评论者识别研究中所面临的最大问题之一。
自从Jindal等人提出虚假评论的广泛存在[1],研究者已经提出了许多识别技术。其中一个主要的是有监督的学习方法。Jindal、Liu通过提取评论文本、评论者和商品的特征进行建模来区分重复评论和非重复评论[1,2]。Li等人[4]利用评论和评论者的特征提出一种双视图、联合训练的半监督学习方法,取得了很好的效果。
由于缺乏标注数据,无监督的学习方法也被提出识别虚假评论者。Jindal等利用一种基于用户行为的无监督方法识别那些操纵特定商品评分等级的虚假评论者。Lai等人[5]根据高阶概念关联的挖掘方法提供一种基本术语关联知识的无监督识别方法。Wang等人[6]通过捕捉评论者、评论和商家之间的关系提出一种基于关系图的无监督方法。Mukherjee等人[7]发现了评论者之间不同的行为分布,总结出9类用户行为特征。Liang等人[8]将用户之间关系和用户特征结合起来,识别准确率取得了很大的提高。
由于虚假评论者团体可以很轻松地提高或破坏特定商品的声誉,虚假评论者团体的识别成了近几年研究的热点。Liu等人[9]首次提出通过计算虚假评论指标值来检测虚假评论者,然后他们又构造了一种团体、个人评论者以及他们所评论商品之间的关系模型[10]。
2用户情感分析及特征定义
2.1用户情感分析
传统的评论文本分析大多基于客观的要素,而忽略了其中所蕴含的主观要素,比如用户的情感信息、心理特征等。近年来,对评论文本的情感分析成为信息科学研究的热点,心理学关于情感的研究成果也对分析网络信息具有重要的参考价值。由于虚假评论是蓄意发布以提高或破坏产品名声,虚假评论者在写评论时的情绪、情感等心理特征和正常评论者必然存在一定差异。因此,本文创新性的在建模过程中加入了用户的情感特征。
2.2特征定义
根据先前研究者对特征定义和构建的方法[2],并结合用户心理语言学知识以及情感极性的分析,本文总结了以下8个特征。每个特征的取值范围为[0,1],特征值越大,该用户为虚假评论者的可能性就越大。表1列出了相关符号的定义。
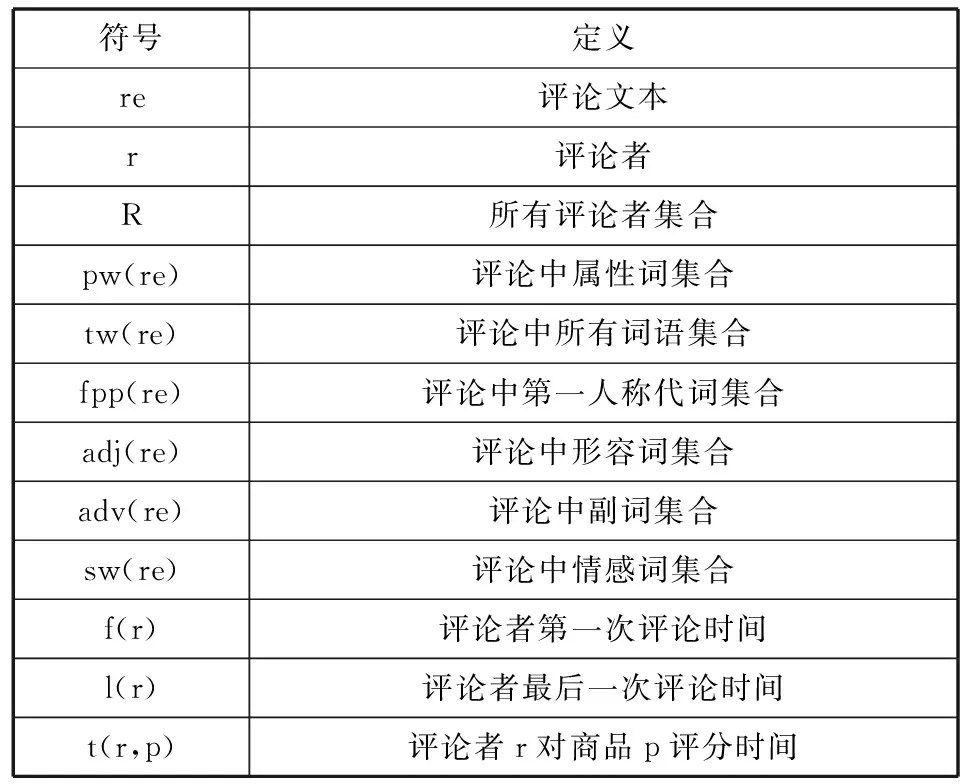
表1 符号定义

续表1
2.2.1商品属性词提及度
商品属性词汇量是指评论中描述商品各项属性的词的个数。如果评论中商品属性词出现频率越高,评论内容与商品的相关度就越大,该用户为垃圾评论者的可能性就越小,反之可能性就越大。本文采用评论中属性词所占总词汇的比重作为商品属性词提及度。
(1)
因为设定的特征值得分越高,越可能为虚假评论者,因此定义此特征为:
f1=1-RPW(r)
(2)
2.2.2第一人称代词词频
在评论中使用第一人称代词可以把评论者置于显现的位置从而增强评论的真实性和亲切感。所以本文认为虚假评论者应会更多地使用第一人称代词,以加强评论的可信性。
(3)
2.2.3词汇的多样性
词汇的多样性是指句子中使用不同词语的比例。其中形容词和副词可以更准确地表达评论者的情感。本文认为虚假评论者使用词汇的多样性少于正常评论者。这里采用形容词和副词的占总词汇的比例代表词汇的多样性。
(4)
f3(r)=1-LV(r)
(5)
2.2.4用户活跃度
虚假评论者一般不是某一网站的长期用户[10],然而真实的用户会经常使用自己账户购买东西并发表相关评论。这里通过计算用户第一次评论与最后一次评论之间时间间隔来判定评论者的活跃度,评论时间间隔越久,评论者为虚假评论者的可疑性就越高。
(6)
其中ζ为时间间隔阈值,本文根据下文所构建的数据集,利用启发式的方法设定阈值,此处ζ设定为60天。
2.2.5用户积极性
用户在网上购买商品时往往依赖于该商品靠前面的评论来抉择是否购买。因此,虚假评论者会尽量抢占评论靠前的位置以迷惑消费者[4]。本文通过计算评论者对某商品的评论时间与该商品第一条评论之间的时间间隔来判断评论者的积极性。
(7)
其中β为时间阈值,此处设定β为150天。当用户评论时间与该商品第一条评论时间间隔小于150天时,我们认为此用户可能为虚假评论者。间隔时间越短,该用户的可疑度就越大。
2.2.6用户极端评分
虚假评论者更容易给出极端的评分(5分或1分)以最大限度地提高或损害商品的名声。当用户评分为5分或1分时,我们设定此特征值为1,其他评分时则设置特征值为0。
(8)
2.2.7情感表达强度
情感是人对客观现实的一种特殊反映形式。因此,用户对产品的使用体会越深刻,在评论中所表达的情感的显性程度越大。而虚假评论者往往没有商品体验经历,情感表达强度会偏低。本文通过建立情感词典,并计算情感词占总词汇的比例来代表情感表达强度。
(9)
2.2.8平均评分的偏差
虚假评论者通常是给质量不好的商品以好的评价,而给质量好的商品以差的评价。因此,虚假评论者的平均评分和总的用户平均评分有一定偏差。本文认为偏差越大,该用户为虚假评论者的可能性就越大。
(10)
2.3特征组合
我们将前面总结的8个特征组合在一起,并根据实验和经验对每个特征赋予一定的权重,来计算用户的特征初始得分,这一步对识别虚假评论者很关键。首先分别计算每个评论者的这8个特征值,然后根据式(11)得出该用户得分的初始值。得分越高,该用户为虚假评论者的可能性就越大。
(11)
3用户关系模型构建
3.1用户关系分析
虚假评论者是被商家雇佣以促进自己商品销售或中伤竞争对手的商品。因此,评论者、评论和商品之间必然存在着一定的联系:
1) 虚假评论者通常对于目标商品会给出一样或者相似的评分,而与真实评论者的评分却有一定的偏差。
2) 虚假评论者通常被信誉不好的商家所雇佣以促进自己商品的销售,而信誉好的商家一般不会。
3) 评论的真实性取决于所评论商品的可靠性以及与该商品其他评论的一致性。
4) 商品的可靠性取决于信誉高的评论者所给出的评分。
3.2模型构建
为了说明评论者、评论和商品之间存在的联系,本文构建了一个异构图的模型,如图1所示。图中有三种类型节点:评论者、评论和商品。同时,图中有两种类型的边:(i)评论者节点与他所发表的评论节点之间的边。(ii)评论节点指向其所评论商品节点的边。
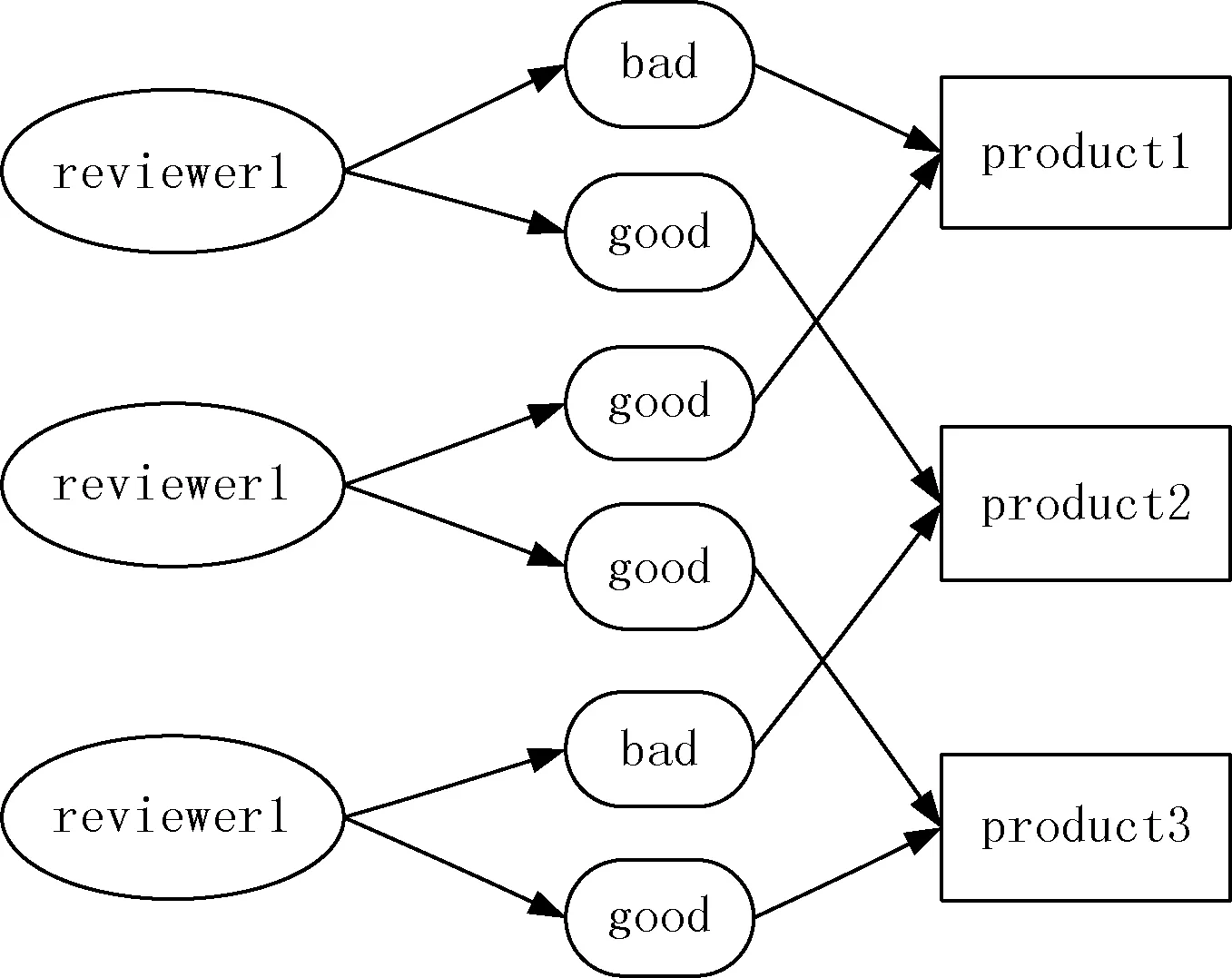
图1 用户、评论、商品之间关系
由图1可知,不同评论者对于商品有着相同或相反的评论。例如用户1给商品1差评,而用户2给商品1好评,评分相反;用户2给商品3好评,用户3也给商品3好评,评分相同。为了更好地阐述他们之间的关系,本文根据图1构建了用户之间关系的多边图的模型,如图2所示。图中每个节点代表一个评论者,两个节点之间的边代表评论者之间的关系。在此模型中定义了两种类型的边:
• “支持边”:如果两个评论者对于商品评价相同或相似,两个节点之间添加一条“支持边”。如评论者2与评论者3对于商品3的评价相同,因此他们之间就添加一条关于商品3的“支持边”。
• “反对边”:如果两个评论者对于商品评价相反或相差很大,两个节点之间添加一条“反对边”。如评论者1与评论者2关于商品1的评价不同,在他们之间添加一条关于商品1“反对边”。

图2 用户之间关系
4虚假评论者识别
4.1数据集构建
本文采用httpclient模拟浏览器从亚马逊购物网站上(http://www.amazon.cn/)获取了关于日用商品的一些评论信息。每个评论信息包含以下属性:用户编号、商品编号、商品评分、评论日期以及评论文本。通过对评论信息的一些预处理操作,最后获得5961条评论、2342位评论者以及412个商品作为实验数据集。然后根据以上据数据集构建了评论者之间的关系模型,其中有21 675条同意边以及10 184条反对边。
4.2用户不可靠分数
本文基于TrustRank[11]方法,并结合上文所构造的用户关系模型和特征工程计算评论者不可靠分数。我们根据以下准则计算用户的不可靠分数:
1) 评论者的不可靠分数不是根据所评论的数量多少,而是根据所评论的真实性。虚假评论越多,评论者不可靠分数越高,该评论者为虚假评论者的可疑度就越大。
2) 评论者的分数应当增加/减少如果和其他评论者之间有同意边/反对边,因为虚假评论者通常都协同合作,对特定商品给一样或相似的评价。
3) 不可靠分数由评论者特征初始值和用户之间关系共同决定。
因此,我们定义用户的不可靠分数的计算方法为:
(12)
其中score(r)由式(11)所得,表示用户的特征初始值,本文α设定为0.2。此公式采用了以e为底的指数函数作为削减函数。由公式可知,当有其他评论者支持该用户评论时,不可靠分数会增加;反之,当有其他评论者反对此评论时,该用户的不可靠分数会相应减少。特别的,如果当前用户没有相关联的支持边,公式的第一项值为0,不可靠分数则由用户特征初始值决定。
4.3虚假评论者识别
本文采用的识别虚假评论者的方法既考虑了评论者的情感特征又考虑了评论者之间的关系。具体步骤如下:
输入:用户、评论、商品数据集合
输出:虚假评论者候选集合
步骤1构建评论者之间的关系图。
步骤2根据式(11)计算所有用户的特征初始值。
步骤3归纳用户相对应的支持边与反对边的集合。
步骤4根据式(12)计算用户最终的不可靠分数。
步骤5将用户不可靠分数按照降序排列,排名越靠前的用户放入虚假评论者的候选集合。
5实验结果评估与分析
5.1评估策略
本文采用基于信息检索的评估策略,首先选取不可靠分数排名靠前的用户作为虚假评论者的候选。然后我们邀请三位标记人对候选者进行人工标记,以判断候选者是否为虚假评论者。相似的评估方法在之前的研究中已经被广泛运用了[2,4],因此这是一个完善的评估方法。具体评估流程如下:
(1) 选择候选集合
我们选择得分最高的100个最有可能为虚假评论者的用户,把他们放入候选集合之中。然后将他们随机排序,这样他们的顺序和不可靠分数就没有关联。
(2) 对候选者进行人工识别
由于在评论信息中没有虚假评论者的标签,因此采用人工评估是必要的。我们的标记人为计算机专业学生并且拥有丰富的网上购物经验。人工识别虚假评论者是一项非常复杂的工作,不仅要研究评论者所发表的评论,而且要查看所评价的商品和商家的其他评论以及他们的品质和信誉。在识别过程中还可能受到主观和直觉因素的影响,因此我们制定了一些虚假评论者的识别准则:
•经常与其他大多数评论者评论相反。
•经常发布重复或者相似的评论。
•经常给声誉不好的商家以正面评论。
•经常是某些特定商品的前排评论者。
•经常夸张地赞扬某商品完全没有任何缺点。
5.2实验结果
在选取的候选集合中,3位标记人根据自己的经验以及上文制定的准则独立的进行标记。一个用户如果同时被2位及以上的标记人标记为虚假评论者,则该用户被认为是虚假评论者。最终,61个用户被标记为虚假评论者(49个用户得到3票,12个用户得到2票),准确率为61%,对于49%的准确率有很大的提高[1]。表2给出了标记结果以及标记人之间的一致度。

表2 人工标记结果
5.3结果分析
根据表2,我们可以看出3位标记人分别标记了57、59、68个虚假评论者。标记人1与标记人2有52个相同结果与标记人3有56个相同结果;标记人2与标记人3有58个相同结果。为了研究标记人之间的一致性,我们采用Fleiss’ kappa[12]方法,得到本次的标记信度为62.4%,达到了实质上一致性的区间[0.61,0.80],证明了本次人工标记的有效性。
6结语
本文基于用户在情感极性方面的差异,总结了用户情感特征。并结合用户之间复杂的关系创新性的构造了评论者之间多边图模型,提出一种无监督虚假评论者的识别方法。最后通过实验证明了该方法的有效性。
目前此方法仍有一些不足,如对用户情感特征分析不是很全面,人工标记存在一定的偏差,影响实验结果的评估。未来将更透彻分析不同用户之间情感差别,并将用户更多主观特征加入特征集构建中。为了更好地评估方法效果,改进评估策略也是本文下一步的工作。
参考文献
[1] Jindal N,Liu B.Review spam detection[C]//Proceedings of the 16th international conference on World Wide Web,Banff,AB,Canada,May 08-12,2007.New York,NY,USA:ACM,2007:1189-1190.
[2] Jindal N,Liu B.Opinion spam and analysis[C]//Proceedings of the international conference on Web search and web data mining,California,USA,Feb 11-12,2008.New York,NY,USA:ACM,2008:219-230.
[3] Li F,Huang M,Yang Y,et al.Learning to identify review spam[C]//Proceedings of the 22nd international joint conference on Artificial Intelligence,Barcelona,Spain,Jul 16-22,2011.Palo Alto,CA,USA:AAAI,2011:2488-2493.
[4] Lim E,Nguyen V,Jindal N,et al.Detecting product review spammers using rating behaviors[C]//Proceedings of the 19th ACM international conference on Information and knowledge management,Toronto,ON,Canada,October 26-30,2010.New York,NY,USA:ACM,2010:939-948.
[5] Lai C,Xu K,Lau R,et al.High-order concept associations mining and inferential language modeling for online review spam detection[C]//Data Mining Workshops (ICDMW),2010 IEEE International Conference,Sydney,NSW,Australia,Dec 13-13,2010.Washington,DC,USA:IEEE,2010:1120-1127.
[6] Wang G,Xie S H,Liu B,et al.Review Graph Based Online Store Review Spammer Detection[C]//Proceedings of the 11th International Conference on Data Mining,Mesa,Arizona,USA,April 28-30,2011.Washington,DC,USA:IEEE,2011:1242-1247.
[7] Mukherjee A,Kumar A,Liu B,et al.Spotting opinion spammers using behavioral footprints[C]//Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining,Chicago,IL,USA,August 11-14,2013.New York,NY,USA:ACM,2013:632-640.
[8] Liang D X,Liu X Y,Shen H.Detecting Spam Reviewers by Combing Reviewer Feature and Relationship[C]//Informative and Cybernetics for Computational Social Systems (ICCSS),2014 International Conference,Qingdao,Shandong,China,Oct 9-10 2014.Washington,DC,USA:IEEE,2014:102-107.
[9] Mukherjee A,Liu B,Wang J,et al.Detecting group review spam[C]//Proceedings of the 20th international conference companion on World wide web,Hyderabad,India,March 28-April 01,2011.New York,NY,USA:ACM,2011:93-94.
[10] Mukherjee A,Liu B,Glance N.Spotting fake reviewer groups in consumer reviews[C]//Proceedings of the 21st international conference on World Wide Web,Lyon,France April 16-20,2012.New York,NY,USA:ACM,2012:191-200.
[11] Gyöngyi Z,GarciaMolina H,Pedersen J.Combating web spam with TrustRank[C] //Proceedings of the Thirtieth international conference on Very large data bases,Toronto,Canada,August 31-September 3 2004.San Fransisco,CA 94104,USA:Morgan Kaufmann,2004:576-587.
[12] Fleiss J L,Cohen J.The equivalence of weighted kappa and the intraclass correlation coefficient as measures of reliability[J].Educational and Psychological Measurement,1973,33(3):613-619.
SPOTTING FAKE REVIEWERS BASED ON SENTIMENT FEATURES AND USERS’ RELATIONSHIP
Shao ZhufengJi Donghong
(SchoolofComputer,WuhanUniversity,Wuhan430072,Hubei,China)
AbstractWith the rapid development of e-commerce, online shopping becomes more and more appealing. Before shopping online, consumers usually tend to refer to the relevant comments to decide whether to buy the products or not. Therefore, to identify fake reviewers is of great significance. Based on the difference of emotional polarities between fake reviewers and real reviewers, we added the sentiment features of comment text to feature modelling process. Combined with the inter-relationship between users and specific commodities, we constructed a multi-edge graph model and came up with a method of spotting fake reviewers. Experimental results verified the effectiveness of the proposed algorithm.
KeywordsE-commerceFake reviewersSentiment featuresUsers relationship
收稿日期:2015-01-12。邵珠峰,硕士,主研领域:自然语言处理。姬东鸿,教授。
中图分类号TP3
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.05.039
