基于DenseNet 的人脸表情识别方法研究∗
2024-01-23顾状状许学斌路龙宾豆阳光
顾状状 许学斌 路龙宾 豆阳光
(1.西安邮电大学计算机学院 西安 710000)(2.长安大学地质工程与测绘学院 西安 710054)
1 引言
近年来,随着计算机科学技术的迅猛发展,机器学习以及深度学习技术伴随着智能终端的推广成为了一个极其热门的研究方向,推动了人脸识别技术的飞速发展。目前人脸识别[1]技术的识别精度已经远超人类所能识别的范围,使得其在多个领域占据着不可或缺的一席之地。人脸表情识别作为人脸识别技术的一个重要分支:其在人机交互、安全、机器人制造、自动化、医疗、通信和驾驶等领域备受关注[2],且在近十年里也取得了由量到质的突破,成为国际前沿研究领域的热门领域之一。
人脸表情的研究,起源于心理学。1972 年达尔文就从心理实验中得出结论,并在他的著名论著《The Expression of the Emotions in Animals and Man》中阐述了人脸表情和动物面部表情的联系和区别[3]。在1978 年,Ekman 和Friesen 制定了FACS(Facial Action Coding System)系统,该系统主要用来检测面部的变化,并定义了六种基本表情,即:伤心、开心、厌恶、害怕、愤怒和惊讶[4]。计算机领域对人脸表情的研究最早是在1978 年,Suwa 和Sugie等人对人脸表情图像中面部的20 个点进行追踪进行表情识别,提出了在图片流中对人脸表情进行自动分析[5]。1981年,通过仿生学方法建立了人脸表情模型[6]。20 世纪90 年代初,K.Mase 和A.Pentland提出了光流法,该方法很快被应用到人脸表情识别研究中[7]。Rashid T A 提出了一种使用不同的面部表情不平衡数据集来识别面部表情的技术[8]。Fathallah 等提出基于CNN 的用于面部表情识别的新架构网络,并使用视觉几何组模型(VGG)微调了架构以改进结果,精度达到了71.04%[9]。Cheng S 等提出一种改进的视觉几何组(VGG)深度卷积神经网络(CNN)的表情识别模型,改进后的VGG-19 网络模型在人脸表情识别上可以达到96%的准确率[10]。目前为止人脸表情识别研究已历经了半个世纪,然而它的热度不降反升,近年来更是伴随着神经网络技术的发展成为了一个热门的研究课题。
本文提出了一种基于稠密卷积神经网络的人脸表情识别方法,通过特征复用与旁路连接的方式,实现人脸表情特征提取,在扩展的KDEF 数据集数据集上训练卷积神经网络,对面部表情进行分类,精度达到了96.88%,并利用预先训练的网络模型开发出一个可以实时检测人脸表情的操作软件。本文不仅在人脸表情识别网络的学术领域取得了一定的成果,也对社会生产实践有一定的指导意义。
2 人脸表情识别方法
2.1 人脸表情识别过程
人脸表情[11]是传递人类情绪信息和协调人际关系的有效手段。人脸表情是由面部多处肌肉(如,眼部,口部等)的变化组合来表达人类自身的各种心理状态。人类的面部表情至少包含21 种,1971 年,心理学家Ekman 与Friesen 首次提出人类的6 种主要情绪状态,分别是:生气(Anger)、开心(Happiness)、伤心(Sadness)、惊讶(Surprise)、厌恶(Disgust)和害怕(Afraid)[4]。本文所研究的人脸表情即是在此六种基本表情基础上加入了中立(Neutrality)表情。
人脸表情识别主要基于三个步骤组成:人脸表情图像获取、图像特征提取、特征分类[12],如图1 所示。

图1 人脸识别过程
2.2 DenseNet网络模型
从CNN 开始不断地加深网络,梯度消失和模型退化问题就一直存在,其中批量规范化使得梯度消失问题得到一定程度的缓解,ResNet[11]的出现进一步减少梯度消失和模型退化问题的发生。DenseNet[13]的优势在于其通过特征重用和旁路设置,使得网络的性能得到大幅度提升。相比于ResNet,减少了可训练参数量,加强了特征的传递,更加有效地利用特征,减轻了梯度消失和模型退化问题。
ResNet 将每一层和前面的某一层短路连接起来,在一定范围内减轻了该问题的发生,而DenseNet做了一个更加激进的紧密连接机制:将每一层网络都和前面所有的层连接起来(如图2),即在DenseNet网络的第n 层有(n-1)个连接与前面的所有层。这种紧密连接机制,避免了特征信息在层之间传递导致的梯度消失问题。
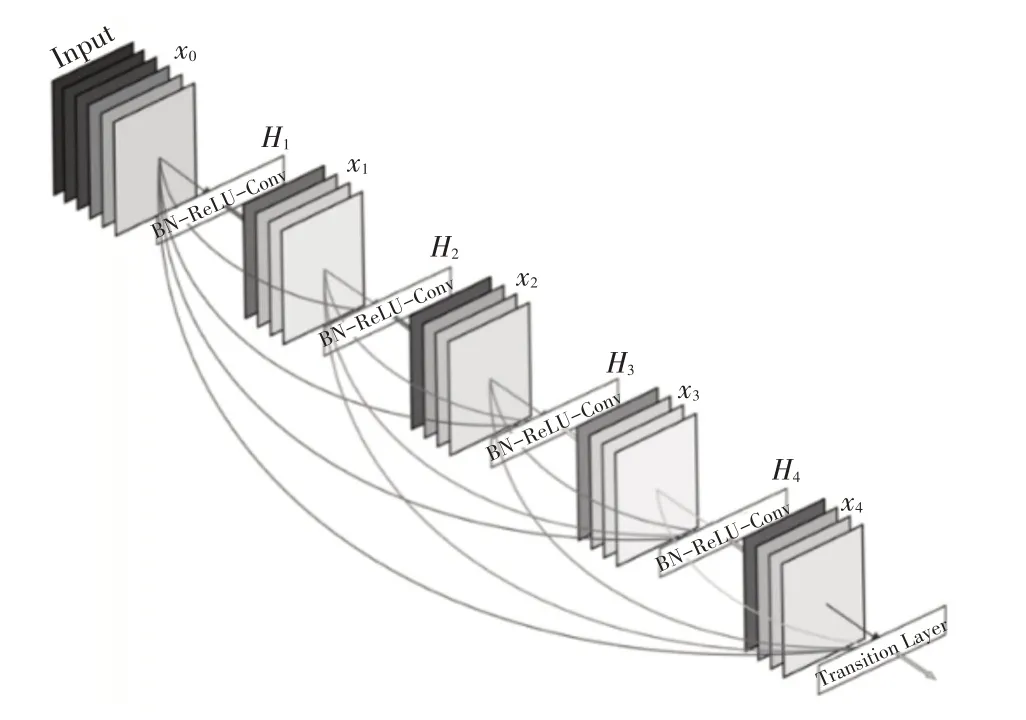
图2 DenseNet短路连接机制
2.3 基于DenseNet 预训练网络的人脸表情识别方法
2.3.1 人脸表情识别数据集
本文所采用的数据集由KDEF 和手动制作的人脸数据集组成。
KDEF[14]数据集包含了70个年龄位于20岁~30岁之间的成年人,由35 个男性,35 个女性从5 个不同的角度:正前方,左前方,左侧,右前方,右侧,拍摄了7 种表情:生气、开心、伤心、惊讶、厌恶、害怕和中立,每个表情拍摄两次,总共4900 张人脸表情图片。图片为562*762 像素的RGB 图像,图3 所示为KDEF中的部分表情图片。

图3 KDEF部分图片示例
手工制作的人脸表情数据集同样包含7 种表情,每种表情包含10 张不同的图片,共70 张,图片为420*620 像素的RGB 彩色图像,部分图片如图4所示。

图4 手工制作数据集部分示例
训练集包含KDEF数据集中的3780张图片,以及手工制作数据集中的56 张图片,验证集包括KDEF 数据集中的1120张图片,手工制作数据集中的14张图片。
2.3.2 数据处理
归一化处理[15]可以提升训练模型的收敛速度、训练精度以及防止梯度爆炸。文章采用了最大-最小标准化方法对输入的图像数据进行归一化处理,数学定义式为
式中:x为数据灰度值,max 为图像灰度最大值,min 为图像灰度最小值。
文中采用了随机上下、左右翻转和随机裁剪对图像进行数据增强,对图像进行随机上下左右翻转和随机裁剪,大大扩充了样本量,训练出来的模型泛化能力更强[16]。
2.3.3 网络模型
本文采取的人脸表情识别方法是基于DenseNet预训练网络搭建的。为了减轻梯度消失和梯度爆炸问题,在模型中用添加BatchNormalization层做批量正则化处理,选择ReLU作为激活函数,可以减轻梯度消失和梯度爆炸问题,而且计算量小,收敛迅速。添加一层GlobalAveragePooling,对特征信息的高度和宽度两个维度进行平均化求值。
两层Dense 做分类器,第一层Dense 有1024 个隐藏单元,使用ReLU作为激活函数,最后一层输出层Dense 隐藏单元数为7,使用softmax 作为激活函数。
网络模型如图5 所示,该模型共有8098375 个参数,其中可训练参数为8012679个。

图5 人脸表情识别方法整体结构
2.4 编写实时人脸表情识别系统界面
文章编写了一个系统,来实时检测人脸表情。将训练好的模型加载进来,调用计算机摄像头,在视频流中获取到每一帧的图片,然后调用OpenCV提供的人脸识别分类器,找出人脸所在的坐标,并记录下来,按下空格键,系统则会先保存下当前图像,将图像按照人脸识别出来的坐标裁剪出合适的图片,用于人脸表情识别。此时载入人脸表情识别模型,对图片内容进行识别,并识别内容返回,使用OpenCV在显示图像的每一帧时将上一次的识别结果放在图片左上角,按下Q 键则退出系统,软件操作界面如图6所示。

图6 人脸表情识别系统软件界面
3 实验结果分析
3.1 优化模型
经过测试512*512、256*256、224*224、128*128 不同大小尺寸的图像输入网络后的结果,如表1 所示,可以看出当输入图像尺寸为256*256 和224*224的时候,都取得了93%的较高准确率,但是大小为224*224 像素时每次迭代训练速度更快,模型收敛速度也略快,所以最终采用图像的输入尺寸为224*224像素。
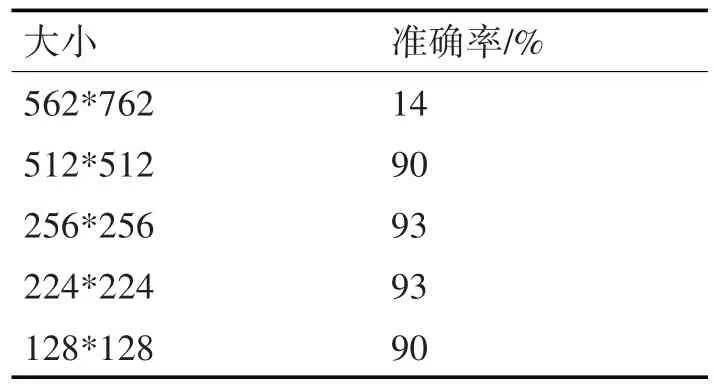
表1 不同尺寸的图像输入对准确率的影响
3.2 结果分析以及模型评估
文章建立的数据集对模型进行5000 次迭代的训练,模型的准确率随着训练进行产生的变化如图7 所示,图中红色的线表示训练集上的准确率情况,蓝色的线表示验证集上的准确率情况,横轴表示迭代的次数,纵轴表示准确率。在进行第2085次迭代之后,模型的准确率达到了5000 次训练的最大值96.88%。
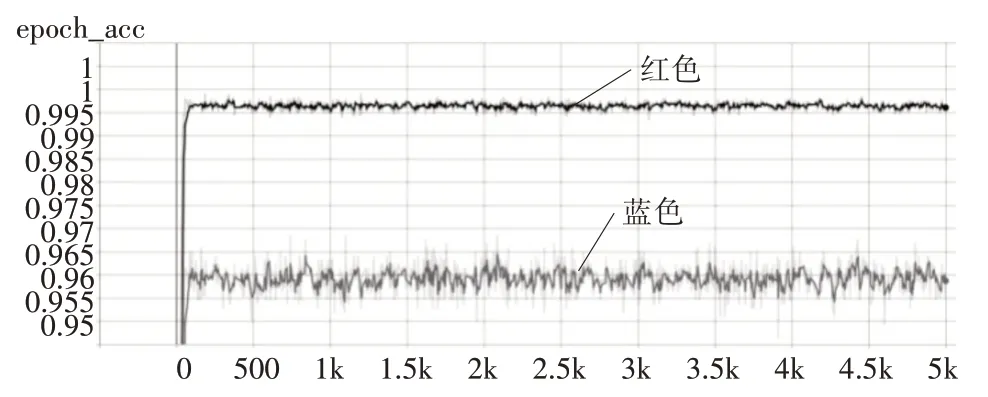
图7 模型准确率变化情况
除了训练集和验证集的准确率和损失,本文还运用了其他评估方法对模型进行了评估。
1)计算模型在不同人脸表情上的识别精度,如表2所示。

表2 不同表情上的识别准确率精度
2)计算混淆矩阵。本文中的人脸表情识别模型的混淆矩阵[17]如表3 所示。引入了五个分类精度评价指标,分别为准确率(Accuracy)、精确率(Precision)、召回率(Recall)、特异度(Specificity)、F1-值(F1-score)。其中,准确率是所有的预测正确的样本数占总预测样本个数的比重,数学公式为
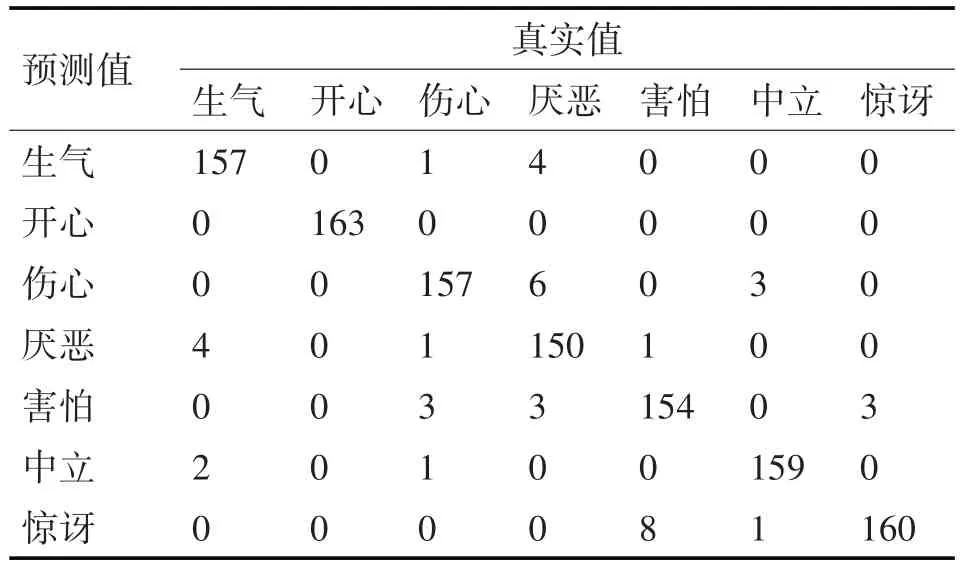
表3 混淆矩阵精度评估表
式中:TP表示预测值为当前表情且预测正确,TN则为预测值为非当前表情且预测正确,FP 表示真实值不是当前表情且预测错误,FN 则为真实值是当前表情且预测错误。
精确率表示预测值为当前表情且正确预测的样本数占预测正确的样本数的比重,精确率的数学公式:
计算出每一个表情的精确率,如表4。
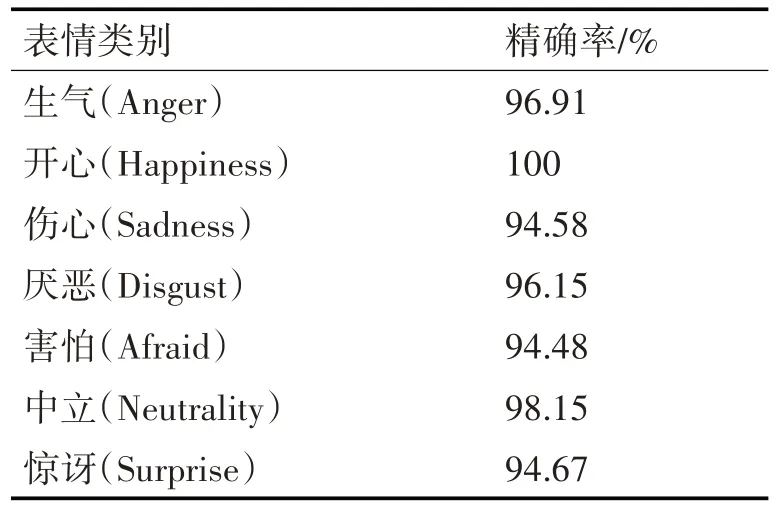
表4 精确率的精度评估表
召回率表示预测值为当前表情且正确预测的样本数占全部预测当前表情的样本数的比重,召回率的数学公式为
每个表情的召回率如表5。
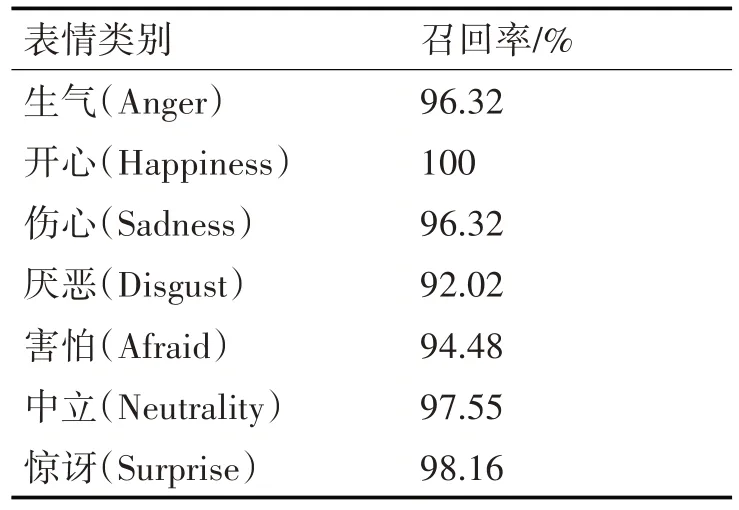
表5 召回率的精度评估表
特异度是错判的样本数占全部预测错误的样本数的比重,特异度的数学公式为
计算结果如表6所示。
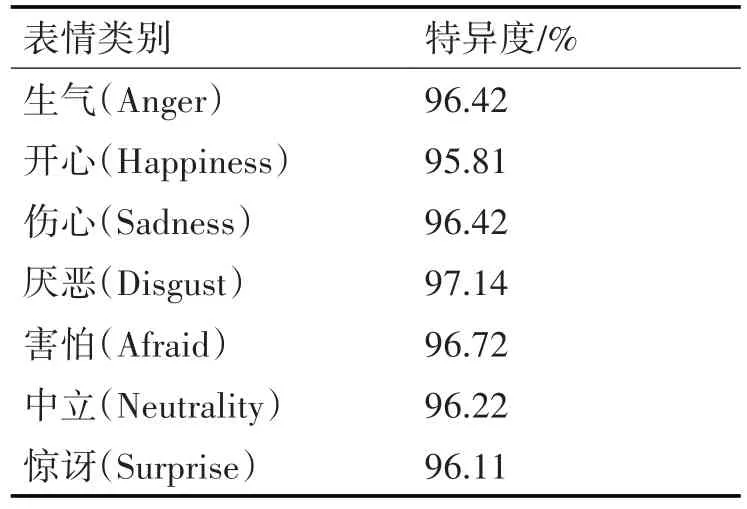
表6 特异度的精度评估表
F1 Score是P和R 的调和平均数,F1 Score的数学定义为
式中:P 代表精确率,R 代表召回率,所以每个表情的F1 Score值如表7所示。
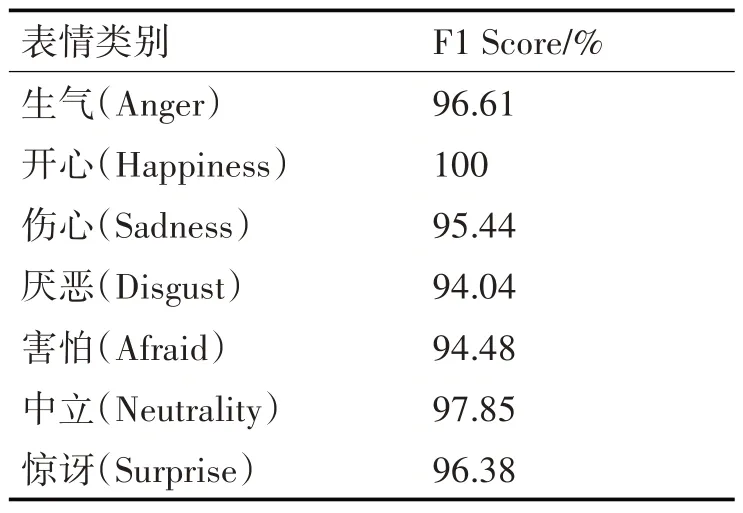
表7 F1 Score值的精度评估表
3.3 对比其他人脸表情识别方法
本文提出的基于DenseNet 预训练神经网络的人脸表情识别方法,相对于直接使用DenseNet有较大的优势,从表8 中可以看出,DenseNet121 预训练网络模型在本文的数据集下最高准确率为93.66%。

表8 不同的网络模型的识别准确率
使用文章中的数据集对ResNet121、MobileNet流行的预训练网络模型以及传统方法PCA+KNN、2DPCA[18]、Gabor+2DPCA、NFM+SVM进行了对比试验。ResNet121 同样采取跳接的方式,取得了85.62%的准确率,但DenseNet 更为激进的跳接方式在特征提取上取得了更好的效果。MobileNet 在体积上有着很大的优势,极大地减少了参数量,但与此同时损失了精度,准确率为90.54%。传统机器学习方法:PCA+KNN、2DPCA相对于卷积神经网络对图像特征提取能力较差,人脸图像识别准确率较低。Gabor+2DPCA 中Gabor 类似于人体视觉细胞刺激响应方式,能够较好提取局部特征信息,取得了82.51%的准确率。NFM+SVM 能够快速学习到高阶线性组合图像特征,取得了较高的准确率83.17%。综上,文章所提出的基于DenseNet 的人脸表情识别方法在准确率上明显优于其他方法。
4 结语
本文提出的基于稠密卷积神经网络的人脸表情识别方法,最终取得了验证集上96.88%的准确率,与此同时设计出了人脸表情识别原型软件,利用已经训练好的模型实时检测人脸表情,取得了很好的效果。本文主要做出的贡献如下:
1)提出基于稠密卷积神经网络的人脸表情识别方法,该模型能够有效提取人脸表情特征信息,识别率较高,收敛速度快。
2)手工制作了人脸表情数据集并结合目前主流的公开数据集,测试了不同图像尺寸下模型的表现情况。
3)设计出了人脸表情识别的原型软件,对人脸表情识别的普及推广具有重要的现实意义。
文中所提出的模型虽然已经取得了不错的识别效果,但是还需要继续增大训练数据样本,其普遍性无法推广到整个人类的表情数据,还需要经过更多的数据检验。其次,文中所提出的模型方法,需要提供拥有非常强大算力的计算机,训练参数达到了百万级,训练过程较长,在不降低模型性能的基础上,适当优化模型,减少模型训练参数,以减少计算量。
