AdaBoost 改进的规划识别方法在入侵检测中的研究∗
2024-01-23胡广朋
陈 磊 胡广朋
(江苏科技大学计算机学院 镇江 212000)
1 引言
当今世界的网络信息技术发展非常迅速,引领了社会生产新的变革。但是随着互联网的快速发展,网络安全问题也变得越来越重要,传统的网络安全防御往往要依赖安全专家的知识广度和深度。但是在如今海量的应用程序和数据之下,这种专业人才的防护方式逐渐无法满足需求,人们开始寻求利用自动化的方式来应对这个问题。所以人工智能慢慢成为网络安全防御新的热点。
规划识别是人工智能中的一个重要分支。规划识别问题,是指从观测到的某一智能体的动作或动作效果入手,推导出该智能体目标/规划的流程问题[3]。入侵检测是通过对用户行为、日志记录或其他相关数据进行分析,识别到对系统的恶意入侵或入侵的目的的技术。从二者的概念上讲,无论是规划识别还是入侵检测,它们都是依据某些特殊的行为来分析出智能体的目的。它们在很多方面都有共同点,比如在应用的环境,对系统的输入输出和最终判定的手段。在入侵检测系统中引入规划识别的方法,就可以预知入侵的发生,并可以提前采取相应措施。
集成学习是一种通过结合构建多个学习器来完成任务的一种学习策略[3]。大多数问题都可以通过这种思想来得到效果上的提升。AdaBoost 算法属于集成学习中的一个典型代表[4],而且是一种串行的集成学习算法,它可以使得整体的效果越来越好。目前AdaBoost应用广泛,它可以和很多机器算法结合以此来提高识别精度,在很多领域都有着广泛的应用。比如在农业方面,康洋等为了解决梯田地形复杂,提取效果差的问题,使用改进的Ada-Boost算法对梯田特征的提取[5]。在工程方面,胡启国等针对工程结构可靠性设计中存在的问题,提出基于MEA-AdaBoost-BP模型的可靠性求解方法[6]。在军事领域,李园等提出了一种基于AdaBoost的作战目标属性判定方法[7]。在经济学领域,李赵飞等利用基于代价敏感的Adaboost 算法提高了贷款违约样本的识别率[8]。在医疗方面,高泽伦等提出了一种Bagging-Adaboost-SVM 的多分类诊断模型[9],在针对糖尿病诊断方面取得了不错的进展。
本文将AdaBoost算法引入规划识别,以规划识别方法做为弱预测器。由此可建立基于AdaBoost改进的规划识别方法,并应用于入侵检测领域。
2 AdaBoost算法简介
Adaboost 算法属于boosting 算法中的一个重要代表[10]。它是一种串行的集成学习算法。按照boosting算法的思想,要建立多个模型,并且将它们一个一个串联在一起,依据各样本权重的改变从而变更基分类器的权重,最后综合获得一个性能较强的分类器其步骤大致如下:
步骤一:对每个样本赋予相同的权重,然后划分类别使得误差率最低。
步骤二:如果误分类没有达到预设值0,那么提高分类错误的样本权重,降低分类正确的样本权重。
步骤三:依据新权重,再切一刀划分类别使得误差率最低。
步骤四:误分类未达到0,重复步骤二。
步骤五:重复步骤三。
步骤六:误差率如果已经达到0,整个过程结束。
以下用几张图来表示这个过程,如图1所示。
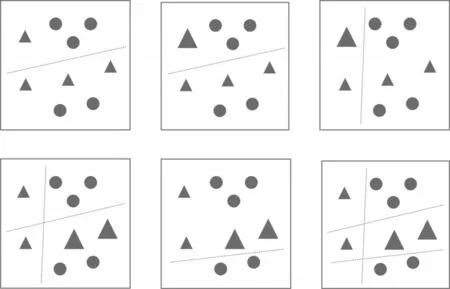
图1 Adaboost算法步骤示意图
Adaboost 的核心思想总地来说是先对每个样本赋予相同的权重,之后选取当前误差最小的分类器计算其权重并且更新其样本的权重,对这些样本不断地进行迭代训练,模型会慢慢提高对这些分错样本的准确率,最终可以获得一个较好的分类结果。最后通过集成各个基分类器共同得到一个较好的分类模型。
3 Adaboost改进的规划识别
在规划识别系统中,先输入一个动作序列,在序列输入时依据相关动作对智能体的预测规划做出修改[11]。根据修改后的预测,规划器需要生成对下一个行为的预测。所以规划识别系统会产生一系列的预测结果。在这些结果中,有很多并不满足新观察到的实际情况,识别器会对已生成的预测进行修改,以满足实际观察到的情况。简单来说是先预测可能的结果,然后在有新观察时再筛选结果。按照Kautz 的规划识别方法,可以将它看成一个逻辑层次结构[12]。在入侵检测领域攻击者往往会采取一定的入侵手段,并且入侵者的动作是一个线性过程,符合输入序列的特征[13]。Adaboost算法与大多识别算法兼容性都很好,以规划识别方法做为弱预测器。由此可建立基于AdaBoost 改进的规划识别方法,并应用于入侵检测领域。
针对复杂的网络环境及入侵手段,本文提出AdaBoost 改进的规划识别方法ABPR(Adaptive boosting planning recognition)。Adaboost 算法作为一种串行的集成算法,其核心思想是通过不断改变样本权重训练弱学习器,再将这些弱学习器组合使得整体效果越来越好。根据其原理,我们可以将规划识别方法视为一种弱预测器。首先,使用规划识别算法对样本进行训练和分类,若其在预设的误差范围之外就不断更新对应样本的权重,再次训练分类,迭代t 次达到误差允许范围内。在这个过程中可以得到T 个规划识别预测器。最后将这T 个规划识别预测器线性组合得到一个强预测器。最终输出强预测器的识别结果。
ABPR 方法应用于入侵检测领域主要有以下四个部分构成,即数据预处理、训练模型调整相关参数、判断当前安全状态和对未来安全状态预测。数据预处理主要是进行冗余数据删除、缺省数据填充和对相关数据规范化,接着对数据集进行划分并根据上述流程训练模型调整相关参数。输入一组信息序列提取相关目标,将目标分解降低其抽象层并更新扩展已有规划,不断重复这个过程,直至规划中只存在原始动作。最后预测层对输入信息序列做行为预测。下面对整个算法步骤做一个详细阐述:
1)样本数据选择并导入训练样本,初始化样本权重分布;
其中m为样本总数,Di为各样本初始权重;
2)设置弱预测器的数量T 与模型的结构,用规划识别算法不断训练样本
3)计算弱预测器训练样本的误差率ec;
4)将误差率ec和误差阈值e比较,重新加权样本;
5)计算第t个规划识别弱预测器误差率:
F是规划识别弱预测器所预测的结果,yi是样本的实际值,I是指示函数。
6)计算第t个规划识别弱预测器的权重:
7)计算下一次迭代的样本权重:
Bt:归一化因子;如果没有到达迭代次数,返回第二步继续迭代,迭代T次为止;
8)T 次迭代后得到T 个弱预测函数ft(x)及其各自权重,通过线性组合得到强规划识别预测器。
其流程如图2所示。

图2 AdaBoost改进的规划识别预测流程图
4 实验及分析
4.1 实验数据集
本节实验采用的数据集是NSL-KDD,它是由KDD99 数据集改进而来,该数据集中包括正常流量和四类攻击流量,分别为Normal,DOS,U2R,R2L和Probing attack。Normal 表示正常流量,DOS 是拒绝服务攻击,U2R 是提取攻击,R2L 是远程用户攻击,Probing attack 是端口扫描攻击。NSL-KDD 数据集的每条记录都是由41 个属性和一个类别标签构成,其中包括9 个离散特征。这个类别就是Normal 和Attack。Attack 又依据数据具体特征划分为上述四种攻击类别。这四种攻击又能进一步划分为39 种入侵类型。这39 种攻击类别只有22 种在训练集中出现,其余17 种只存在于测试集。数据集构成如图3。

图3 NSL-KDD的数据构成
4.2 检测评价指标
入侵检测的评价标准主要有四个部分,即准确率(Accuracy),精确率(Precision),召回率(Recall)和F1分数(F1-score)。

表1 混淆矩阵
根据这些度量,各个评价标准计算方法如下:
准确率(Accuracy):分类正确的样本占样本总数的比例。
精确率(Precision):正确识别为攻击样本占模型识别为攻击数量的比例。数值越大越好。
召回率(Recall):被正确识别为攻击的样本占实际攻击样本的比例。同样越大越好。
F1分数(F1-score):精确率和召回率的调和平均。
4.3 实验结果与分析
根据上述相关介绍,NSL-KDD 数据集中包含41 个相关特征属性,但是并不是每个特征都对模型的建立有影响,并且维度过高也不利于相关计算,所以采取皮尔逊相关系数[14]和线性判别分析[15]对数据进行降维,最后得到22 个相关特征。将这22 个相关特征作为Adaboost 改进的规划识别模型的输入因子考虑,将其作为输入变量,以此建立基于Adaboost 改进的规划识别预测模型。可以通过输入变量数和输出变量数确定相关输入输出节点。由上述可知,输入变量为22 个,输出变量为5个,因此设置输入节点n为22,输出节点m为5。可以确定隐含层大致范围,具体参数设置见表2。

表2 规划识别参数
基于AdaBoost算法的原理,我们把每个规划识别模型视为一个弱预测器,并设定规划识别弱预测器的个数为100,以构建一个改进的AdaBoost 规划识别预测模型。用规划识别训练样本数据,将误差超过0.005 的样本设置为下次加强的训练样本,变更相应的权重,经过迭代训练获得100 个弱预测器和每一个预测器的相应权重,最终加权线性组合得到一个规划识别强预测器。用最终得到的预测器对测试集测试。其中,没有改进的规划识别预测模型的各项参数与上述参数相同。
本次实验是基于五分类的,使用两种方法分别测试了22544个样本的混淆矩阵。
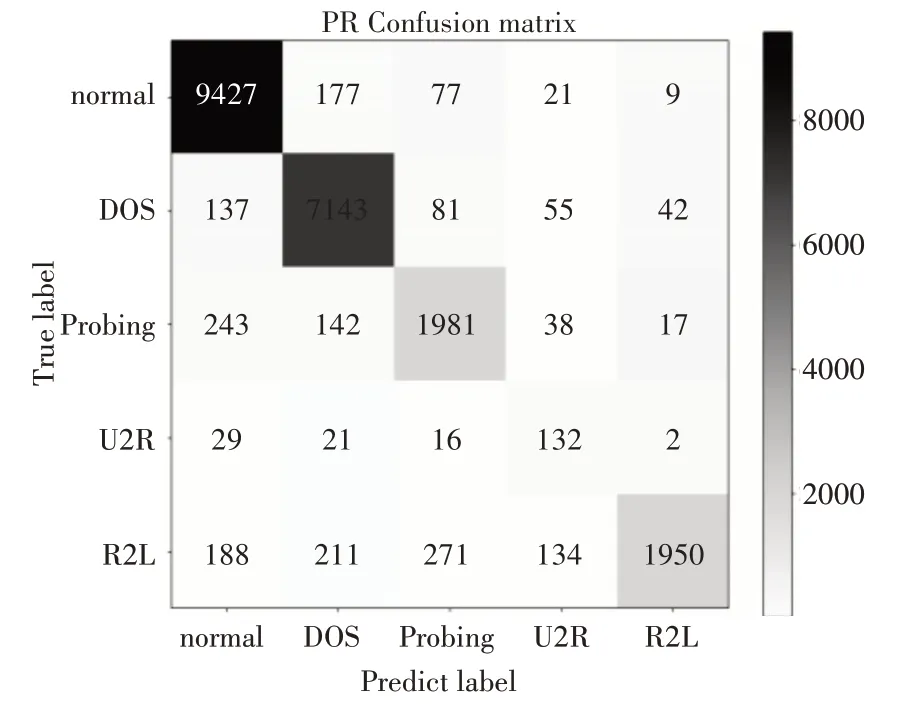
图4 PR方法的混淆矩阵
PR 方法测试集中9711 个正常样本有9427 个被正确识别,12833 个异常样本有11206 个被正确识别。根据上表和上节的计算公式可以求得相关评价指标,这里我们主要分析精确率和召回率,由于训练样本有限,U2R 和U2L 的分类效果不太好。表3展示了相关评价指标。
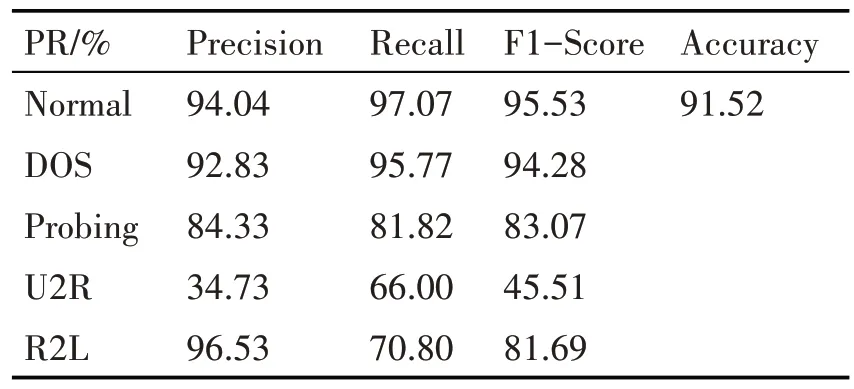
表3 PR方法各项评价指标结果
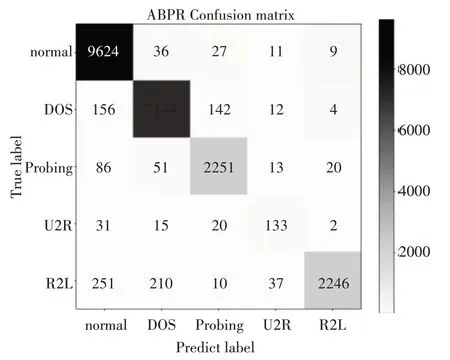
图5 ABPR方法的混淆矩阵
使用ABPR 方法,相比PR 方法对正确样本的识别数量提升到了9624 个,对异常样本的识别提高到了11744 个,对各种攻击类别的识别也有明显提升,各个指标对比见表4。
下面主要分析两种方法的精确率和召回率的比较,如图6所示。
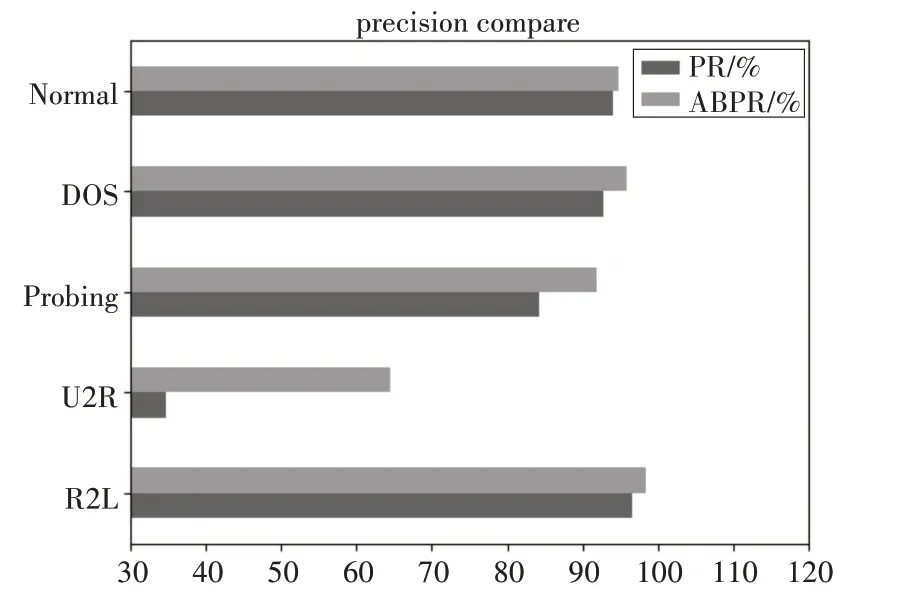
图6 精确率比较
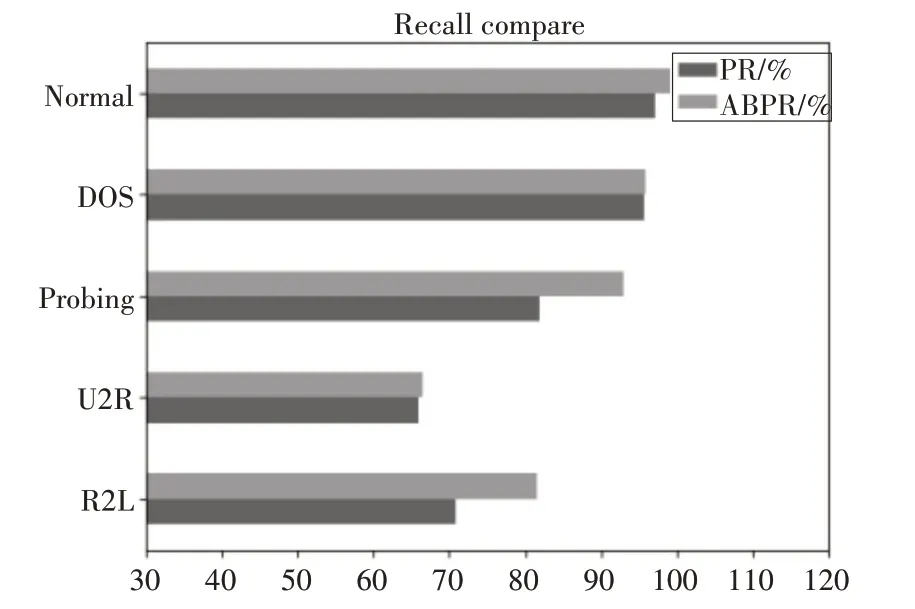
图7 召回率比较
基于ABPR的IDS在精确率和召回率方面都要比PR 方法有所提升,特别表现在样本较少的情况下。在训练集中数量较多的三种类型Normal、DOS和Probing 中,都表现出较高的精确率和召回率。在召回率方面Probing 类攻击,ABPR 相较于PR 方法提升了11.16%,R2L 攻击提升了10.57%。这两种攻击类型改进的规划识别方法提升较大。另外几种提升较小几乎持平。但是在精确率方面,对四种攻击的识别都有一定的提升。特别是U2R 攻击类型上。对于整个模型的分类准确率上ABPR 的准确率94.92%也要略高于PR方法的91.52%。
综合上述比较,AdaBoost改进的规划识别方法相比于传统规划识别方法在入侵检测方面的效果更好,对各种攻击的识别都有一定的提升。
5 结语
本文介绍了一种AdaBoost 改进的规划识别算法并用于入侵检测中。该方法的主要思想是把串行的集成算法与传统的规划识别算法相结合,将各个规划识别模型作为弱分类器,先利用规划识别算法对样本进行训练分类,如果不在设定的误差范围内就不断更新错误样本的权重,再次训练分类,迭代t次达到误差允许范围内。最后将这个过程中得到的T 个规划识别预测器线性组合成一个强预测器。最终输出强预测器的识别结果。实验结果对比表明,本文提出的方法相比传统方法有着更好的识别效果。
