基于真实历史反馈的自适应值预测器的设计与优化*
2021-03-01隋兵才
隋兵才
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
现代处理器已经进入多核多线程时代,但是高性能应用对于单核单线程性能的需求仍然没有止境。传统乱序处理器的指令级并行度通常通过增大指令窗口,提升发射宽度来增加串行程序的指令并行度。为了配合指令窗口的增大,前瞻调度执行机制需要的乱序执行和控制资源,如寄存器文件、重定序缓冲ROB(ReOrder Buffer)和发射队列等,必须相应增加,以支持背靠背的执行或者乱序控制或者旁路机制,这又必然会导致功耗和面积开销的进一步增加。
物理寄存器文件必须随着指令窗口的增大提供更多的读写端口,以匹配ROB的增大[1]。但是,寄存器文件的端口增多,给现代高性能处理器的面积和功耗带来巨大挑战,设计的复杂度也呈指数级增长。同时,指令窗口增大,INFLIGHT的指令数目急剧增加,所需要的寄存器的数目也相应增加,也会导致操作数的访问时间增长[2]。
乱序控制逻辑中所能获得的性能提升越来越有限,因此学术界开始重新转向数据的并行性和相关的值预测进行研究[3,4]。20世纪90年代,Gabbay等[5-7]进行了值预测的相关研究,但是由于当时处理器发展的限制,并没有引起相当多的关注。
Gabbay等认为可以通过预测数据值的方式提前执行存在数据相关的指令,以缩短关键路径的执行时间。但是,最初的研究中值预测器的预测精度一般,并且预测失效的开销比较大,因此值预测的性能提升有限。
Lipasti等[8,9]提出了新值预测方法LVP(Last Value Prediction),并对Gabbay[5,6]所提出的预测方法在不同情况下性能提升原理进行了分析研究。Sazeides等[9]将值预测的预测器分为计算型预测和上下文型预测2种。计算型预测器通过对所获得的数据进行一定规则的运算来产生最终的预测数据,称为步长预测器,都是通过将获得的值加上步长来产生最终的预测值。而上下文预测器利用值预测的历史信息,通过一定的模式匹配产生最终的预测值,如文献[9]所提出的FCM(Finite Contex Method)预测器。上下文预测器一般分为2级结构,第1级用于保存和索引值预测历史,通过第1级索引获得的预测历史用于索引第2级值预测表来产生最终的预测值。上下文预测器通常还包含一个置信度的计数器,以判定所预测值的可信度。
Goeman等[10]在FCM预测的基础上增加了预测历史和值预测表的差别关系分析,在上次预测值的基础上递增一定的步长值来计算最新的预测值,而不是简单地根据数值本身预测结果,因此具有更大的空间有效性。Zhou等[11]基于全局值历史信息分析了数值的局部特性,并提出了gDiff预测器。gDiff预测器通过计算某条指令与之前n条指令之间的差异来判定信息。如果检测出固定模式的差异值,可以通过之前的n条指令产生预测值,但gDiff在预测时需要增加一个单独的预测器以判定前瞻的全局值历史信息。Ishii[12]提出了一种将预测值和步长共享存储的预测器CBC-VTAGE(Context-Based Computational Value predictor TAGE),并采用数据压缩缓存来检索数据以最大化存储效率。CBC-VTAGE利用一个专用的预测精度表控制预测的准确度,并维护一个预测失效的黑名单以提高预测的准确度。但是,CBC-VTAGE在预测失效时,并未考虑到预测器的重新训练时间,导致重新训练的时间较长;虽然CBC-VTAGE对预测器的置信度进行了阈值控制,但是并没有根据正确结果对所预测的结果进行修正,以提高预测器的准确度。
本文针对CBC-VTAGE预测器存在的部分缺陷进行了改进,提出了基于真实历史预测反馈的上下文预测器RH-VTAGE,针对预测器的实际预测行为反馈判定预测值正确与否。同时针对预测失效后,处理器现场切换开销较大的问题,优化了RH-VAGE的置信度计数器控制逻辑。
论文的结构如下:第1节介绍值预测的相关背景;第2节介绍值预测器的结构及改进设计;第3节分析RH-VTAGE的性能并进行性能对比;第4节总结全文。
2 基于真实历史反馈的上下文值预测器
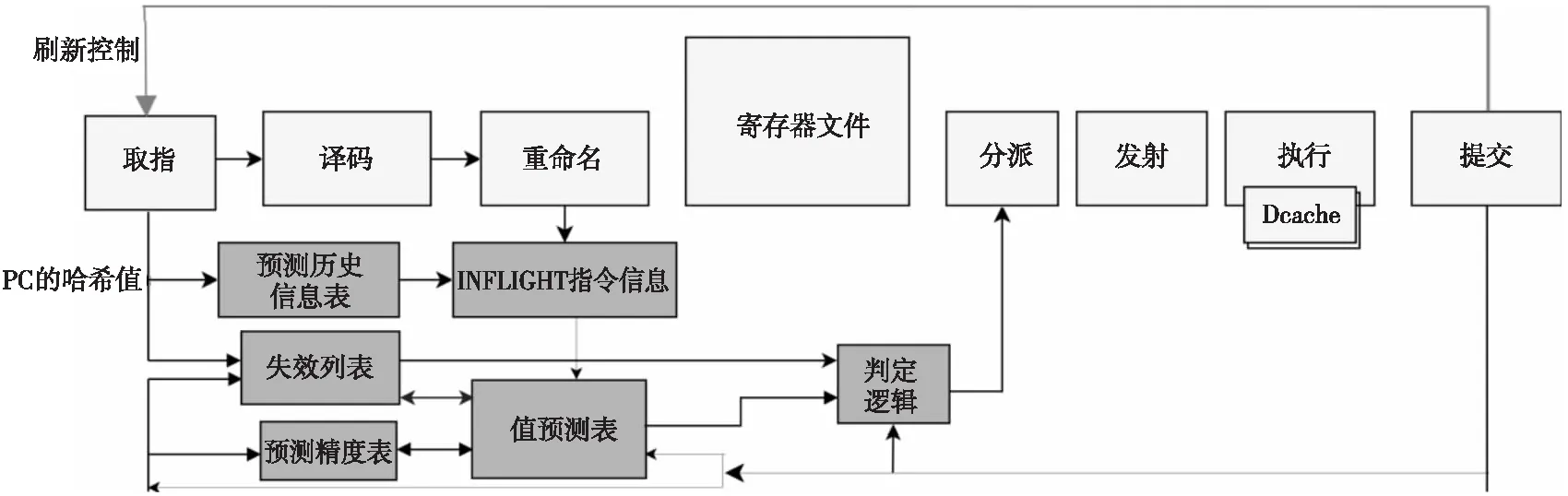
Figure 1 Structure of RH-TAGE
RH-VTAGE预测器的结构如图1中灰色部分所示。预测器根据取值部件所获得的指令PC值,更新预测历史信息表、失效列表和预测精度表。预测历史信息表根据所得到的PC的哈希值,通过重命名的相关控制,存储INFLIGHT指令的index、tag信息和INFLIGHT的指令数目。值预测表根据INFLIGHT的指令信息同步更新预测表的所有存储项,并根据PC值对当前指令进行值预测。值预测表在进行预测的过程中需要查询预测精度表,如果当前的预测精度不满足预期值,则本次预测的置信度就会比较低。预测的置信度低于给定的阈值时,则不进行相应的预测输出。由于值预测失效时,需要对流水线中已经前瞻执行的指令进行相应的刷新操作,并且流水线的刷新操作对性能的影响较大,因此RH-VTAGE中设置了失效列表和预测精度表来控制反馈RH-VTAGE的预测精度,以减少预测失效时流水线的恢复开销。
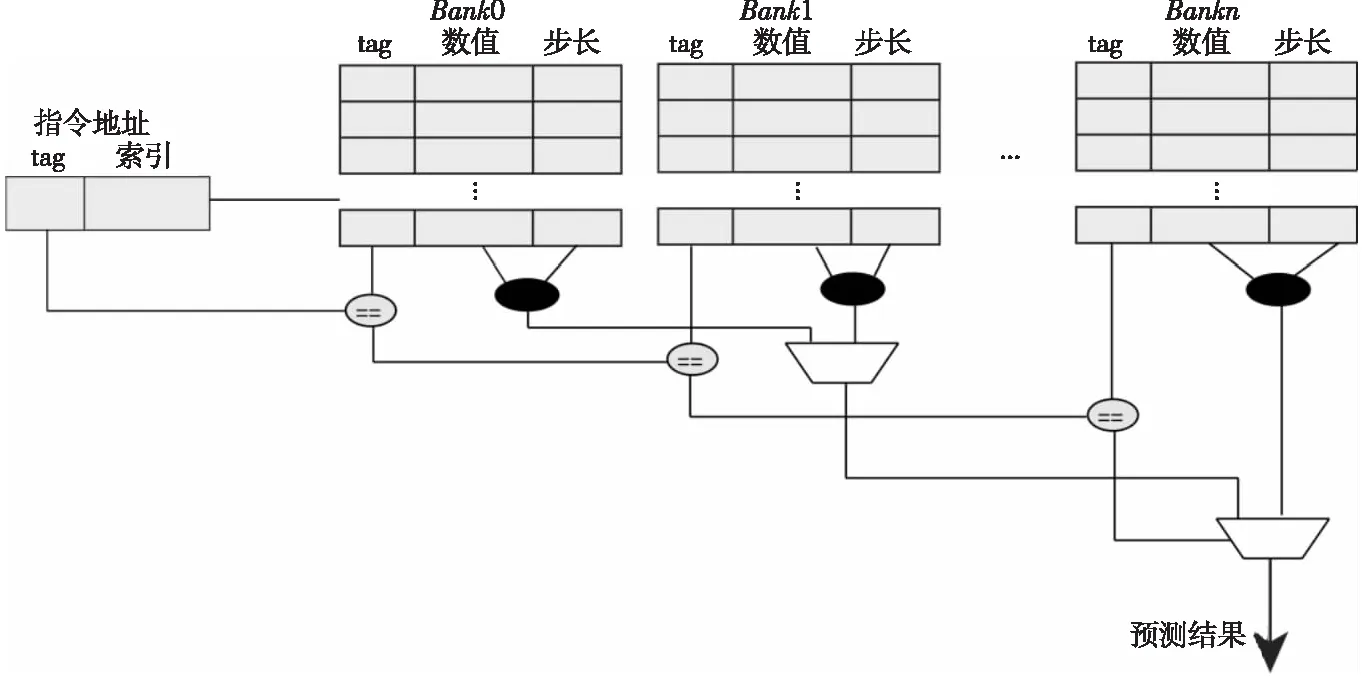
Figure 2 Structure of value predict table
RH-VTAGE预测器的预测表结构如图2所示。预测表包含多个Bank,每个Bank通过PC的哈希值进行索引,索引出来的项的tag值如果与所预测指令的tag域匹配成功,则表示该Bank存储的值为所需要的预测值。如果多个Bank同时匹配成功,则以最长历史的Bank的值作为预测结果值。预测表每一项的格式如图3所示。预测表项中包含tag、数据值和置信度3个部分。tag用于查找表的匹配,数据值分为步长和数值部分,根据模式的不同可以用作数值或者指针。对于大部分的预测值,其高位或者低位部分具有固定的模式,因此不需要在预测表的每一项中存储所有的数据部分,可以使用一个单独的压缩数据缓冲来保存预测值的固定部分数值。根据每一项的模式位选取数据段的步长或者数据指针索引压缩缓存,所得到的数据进行拼接或者符号扩展之后通过计算得到最终的预测值value,如式(1)所示:
Value=Last_value+inflight*Stride
(1)
其中,Last_value为预测器中保存的最新数值,Stride为步长值,inflight为当前PC的指令在指令窗口中的指令数目。

Figure 3 Format of value predict table entry
预测精度表的结构如图4所示。预测精度表根据指令的类型和指令的延迟分别维护不同的精度队列,根据当前指令的PC值进行索引。由于值预测主要针对LOAD指令,所获得的性能提升明显,因此预测精度表中针对不同延迟的LOAD指令维护不同的精度队列。通过预测精度表索引得到的精度参数用于控制预测表的置信度生成,预测表的最终预测结果反馈到精度预测表对应的精度控制队列中。预测精度表的精度参数代表了值预测对应当前指令的预测精度,如果所预测的精度达不到所需要的阈值,那么预测表所预测结果的置信度就会相应地降低,最终的预测结果就不会由控制逻辑输出。
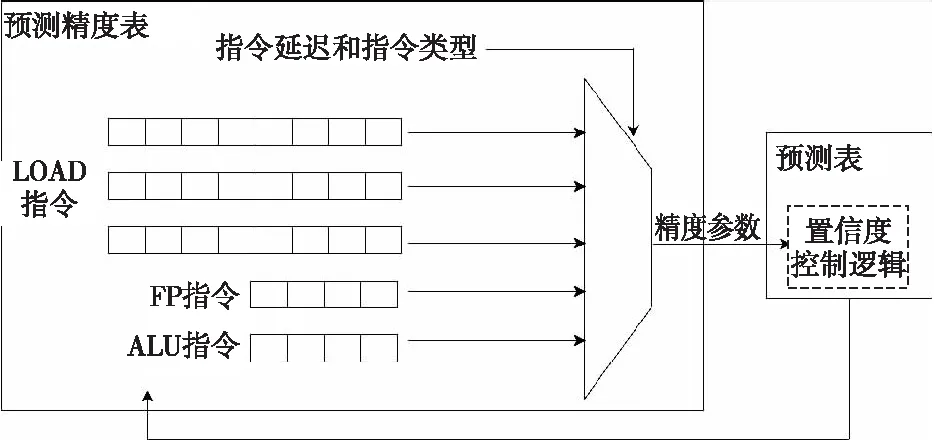
Figure 4 Structure of accuracy prediction
失效列表结构如图5所示。失效列表通过指令的PC值进行索引,并根据tag进行匹配,所匹配项的置信度用于标识所预测的指令是否存在预测失效行为。如果所匹配项的置信度不高,说明预测表对当前指令的预测行为不准确,失效列表会抑制预测表对指令的预测行为。预测表每次预测的结果也被用于同步更新失效列表。
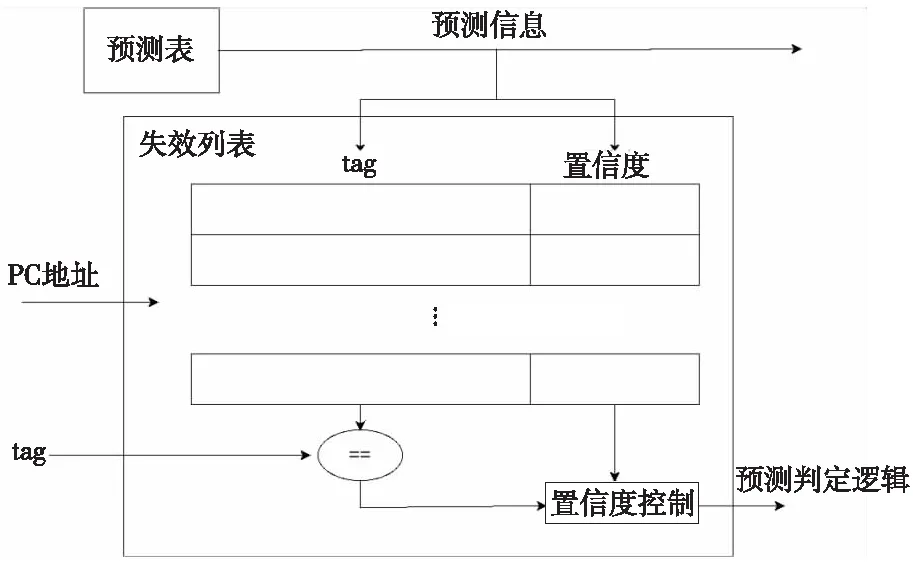
Figure 5 Structure of failure table
3 结构改进与性能优化
3.1 基于真实历史反馈的自适应预测
由于预测表的准确度与实际程序的行为紧密相关,因此存在预测表预测值与最终的值不一致的现象,这就会导致处理器的流水线进行刷新。由于处理器流水线刷新的开销很大,所以一次预测失效会导致整个处理器流水线的重启,对性能影响较大,这种情况在分支预测器中也不可避免地存在。因此,为了提高值预测的准确度,降低预测失效对处理器流水线的影响,本文在值预测器的最后阶段增加了真实历史反馈的控制计数器。在指令提交时,如果预测值与指令的真实值一致,反馈控制计数器递增。一旦出现预测失效,计数器就被复位为0。只有在预测器连续正确预测指定次数后,预测器的预测结果才会被用于指令的前瞻执行。本文通过分析cvp的基准测试程序,可以确定RH-VTAGE的预测器的模式长度为20。
所有的值预测器都包含置信度控制逻辑。只有置信度达到指定的阈值,所预测的值才具有一定的可信度。大部分值预测器在预测失效时,会将置信度计数器复位为0,而在预测成功时,将置信度计数器递增。但是,对于不同程序中的不同指令,如果置信度以固定的模式递增,必然导致不同指令之间预测的乒乓效应,预测表中置信度低的项可能很快被替换,这对预测的准确度会产生一定的负面效应。因此,本文在RH-VTAGE预测器中专门设计了自适应的置信度计数器控制逻辑来分别处理预测正确和预测失效2种情况。在RH-VTAGE预测器中,当预测正确时,对于不同类型的指令,按概率对置信度进行递增操作。长延迟的LOAD指令更新计数器的概率为1,而单周期的整数指令更新计数器的概率为1/256。同时,当预测器预测失效时,需要将置信度计数器复位为0。但是,对于特定的模式,一旦置信度计数器复位为0,流水线要重新使用预测器所预测的值,就必须等到置信度计数器重新达到阈值。预测器再将置信度恢复到阈值以上的时间为预测器的热训练时间。通过对比分析标准的值预测程序的执行踪迹后,我们发现预测器的单次失效并不表示该指令的预测值无意义,相反该值预测表项很有可能再次被使用。因此,RH-VTAGE在预测失效时并不立即将置信度计数器复位为0,而是根据计数器值与阈值的关系进行不同的递减处理。如果计数器值大于阈值,则将计数器值设置为小于阈值。如果计数器值小于阈值,则将计数器值递减;当计数器值小于某个特定值时,直接将计数器复位为0。
3.2 性能评测
基于135个值预测的基准测试程序,RH-VTAGE预测器的IPC(Instructions Per Cycle)执行结果如表1所示。相对于无值预测,RH-VTAGE的IPC(几何平均)由2.779提升为3.265,约提升17.5%。相对于CBC-VTAGE,改进后的RH-VTAGE的IPC均有所提高。主要原因是RH-VTAGE能够将预测的真实历史反馈到预测器中并控制预测值的输出,同时在预测的置信度控制上根据不同的指令类型和指令延迟按概率采取自适应的递增或递减策略。相对于典型的 E-Sride和E-VTAGE预测器,RH-VTAGE的性能有较大提升,主要在于RH-VTAGE同时存储了数值与步长,采用压缩数据缓冲的结构共享步长和数值。

Table 1 Comparison results of IPC
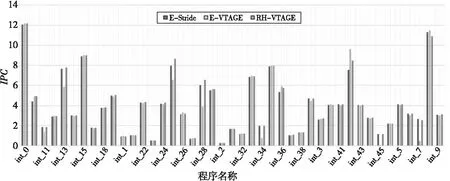
Figure 7 IPC results comparison of integer-point program
RH-VTAGE预测器与其他预测器的浮点与整数测试程序的IPC结果对比如图6和图7所示。对于整数程序,3个预测器的性能相当,对于部分程序RH-VTAGE的预测性能甚至还有一定的下降(相对于E-VTAGE最大下降4%)。这是由于RH-VTAGE 在自适应预测过程中,偏重于访存和长延时的指令,对于ALU指令预测器的置信度控制偏弱。对于浮点程序,RH-VTAGE的预测性能要明显高于其它2种预测器(相对于E-VTAGE最大提升31.2%)。RH-VTAGE同时融合了步长和数值预测2种预测器的结构,能够同时适应数值预测和步长预测的模式,可以匹配预测多种程序的数据模式。

Figure 6 IPC results comparison of floating-point program
4 结束语
本文设计了基于真实历史反馈的自适应预测器RH-VTAGE。在该预测器中,只有预测器连续正确预测指定次数后,预测器的预测结果才会被用于指令的前瞻执行。此外,该预测器还包含专门设计的自适应置信度计数器控制逻辑来分别处理预测正确和预测失效2种情况。当预测正确时,对于不同类型的指令,按概率对置信度进行递增操作;预测失效时,并不立即将置信度计数器复位为0,而是根据计数器值与阈值的关系,进行不同的递减处理。相对于无值预测,RH-VTAGE的几何平均IPC提升了17.5%。
