档案文献的本体构建与知识推理
2024-01-22谭碧云王秀梅
■谭碧云,王秀梅
(1.惠州市排水管理中心,广东 惠州 516000;2.广东药科大学,广东 广州 510006)
数字档案项目已在台湾国家自然科学博物馆(NMNS)建立。该项目旨在设计各种自然科学领域,如动物学、植物学、地质学和人类学。尽管可以使用查询或通过元数据模式或超链接手动表示内容,但这项研究认为,数字档案是提供“知识”的一个有前途的模型。当前NMNS 的可用性只关注于提供明确的静态信息。因此,当前的系统不足以支持高级知识工程,例如,知识推理过程。
一、研究的目的
数字博物馆应用信息技术建立在线服务,用户无需亲自到场即可访问。我们还要考虑当前信息系统面临的一些挑战,以使公众能够重复使用和共享知识。本体是一种用于知识管理的方法,用于创建定义良好的知识库。本体需要以系统的、细粒度的方式构建,因为现实世界的认知和本体的概念结构之间存在很大的差距,需要发展构建。因此,本研究具有以下目标:设计一种有效识别本体概念结构的方法以及设计使用基于逻辑的语言辅助知识推理的方法。为了实现这些目标,本研究检查了现有的提取方法,调查了相应的工具,并进行了必要的修改。本研究采用形式概念分析(FCA)来识别概念并确定其层次关系,简化描述在本体中的应用。此外,开发人员不需要太多的设计时间或数学技能应用DL模型。
二、本体的概念
为了建立本体概念框架并发现概念之间的层次结构,本研究采用形式概念分析(FCA)方法。FCA 最初是一种基于词汇和层次问题的数据分析方法,将元素分类为形式对象和形式属性。正式对象和属性的集合,以及它们之间的关系,形成了一个“正式上下文”。当对象和属性中的关系不能增加时,这对关系是封闭的,并进一步称为“形式概念”。概念格包括形式上下文的概念集合和概念之间的层次关系。
折线图直观地表示FCA 形式上下文。图1 中的线图由节点、线和所有对象的标签(在节点下方表示)以及给定上下文的属性(在节点上方表示)组成。折线图描述了形式概念之间的依赖关系。形式概念可以定义为{(对象集),(属性集)}。例如,形式概念{(G),(Herb)}被附加到{(天南星科),(草本,种子,乔木)}和{(槭树科),(草本,蕨类)}节点之上的节点。在其超级节点之下的每个节点都表示一个“超级- 子”关系,即“is-a”层次概念集群。因此,FCA是一种确定概念之间稳定依赖关系的有用技术。
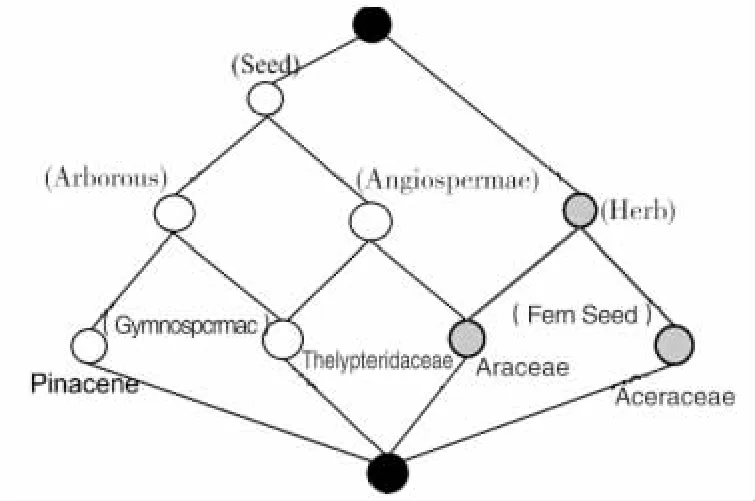
图1 FCA 分析的维管植物的一个例子
三、本体的构建
文献的本体构建早已被用来表达人类对信息的共同理解。Gruber 将本体定义为“概念化的规范”。概念化是一种抽象的、简化的世界视图。也就是说,文献的本体构建是对概念、属性和关系的正式描述,这些概念、属性与关系涉及建立对现实世界事件认知的共同理解。知识库社区通过定义一组术语、话语和公理,采用文献的本体构建方法。因此,本体对于定义用于表示共享知识的通用词汇表是有价值的。广泛的共识是,采用基于文献的本体构建的系统的开发人员必须专注于特定的领域问题,并提供对单个概念的共同理解。然而,从现实世界中获得认知,从而设计本体概念方面存在挑战。
XML 技术最近被引入各种应用领域的数据交换和系统开发中。本体研究使用XML 为本体开发语言构建和模式库。此外,已经开发了许多基于XML 的本体编辑工具。两种本体语言DAML+OIL 和OWL 描述如下。
DARPA 代理标记语言(DAML)。自2000 年以来,DAML(DARPA 代理标记语言)被开发为XML 和RDF的扩展。最近发布的DAML 加本体交换语言(OIL)为构建本体和标记信息提供了一组丰富的构造,使其机器可读和可理解。
本体Web 语言(OWL)。OWL 是W3C 开发的最新的基于XML 的本体语言。OWL 继承了DAML+OIL 的大部分特性,现在已成为正式标准。根据OWL 规范,该标准有三种表达能力越来越强的子语言,适用于不同级别的可用性:OWL Lite 设计用于分类层次结构和直接的约束特征;OWL-DL支持在保持计算完整性和可判定性的同时希望获得最大表现力的用户;OWL-Full 对于具有最大表现力但没有计算保证的推理系统具有有用的计算财产。
四、知识推理
知识推理是根据已有的知识的过程,通过已有的知识三元组构建实体之间的关联,对传递关系、对立关系等诸多有价值的实体关系进行推理,是档案文献本体的核心应用之一,也是档案文献本体构建的价值之一。
知识推理表示特定格式的信息系统的专业知识。描述逻辑(DL)是一个可描述的片段,由类、财产和表示属性或类关系的逻辑符号组成。DL 已被包括OIL 和OWL在内的各种本体开发方法广泛用作表示格式。为了提高推理能力,本研究使用OWL-DL 作为知识推理。描述逻辑推理器可以计算所有命名概念的包容层次结构。概念被分类为已定义或原始类。默认情况下,每个描述都是原始的,即至少有一组必要的条件。相反,如果类具有描述和充分条件,则定义该类。基元类和已定义类之间的区别在于,已定义类可以同样双向。在表达式C≡D 中,如果一个实例是概念D 的成员,那么它必须满足概念C的成员。基元类中的实例不是同样双向的。以下DL 模型旨在帮助开发人员定义正确的逻辑表达式。
为了定义概念的详细语义,DL 为精确描述应用了属性限制,例如,量词、基数和赋值。
在定义档案文献的本体构建概念时,上述模型有助于解决大多数情况。然而,一些例外情况,如不相交和不相关,需要进一步的支持补充。不相关的概念是不属于彼此的概念,因此彼此冲突。赋予相关概念或个体双向关系。例如,如果ChasValueD表示DL表达式,其中C 和D表示两个类,则DL表达式需要由DisValueC给出。
五、示例
为保护和传播中国档案文献,中国于1995 年成立了“世界记忆工程中国国家委员会”,并于2000 年创建了“中国档案文献记忆工程”项目。以国家档案局形成《中国档案文献名录》为依托,迄今共142(组)档案文献,并于2022 年3 月1 日开展第五批“中国档案文献”申报工作。中国档案文献具有记录、证据、信息的工具价值,实施档案文献影响力提升工程,为中国国际传播能力建设助力,为“构筑世界记忆”拓展深层次内涵价值。故本研究以此为实践案例。
(一)数据获取与预处理
1.资料搜集。与档案相关的报刊和官方档案网站,都有大量权威可靠的档案文献传承知识,是很好的资料来源。为构建《中国档案文献名录》本体模型,用于对名录中的文献的相关实体进行提取,主要从两个源头进行数据采集:一是利用八爪鱼工具,对中国、中国档案全国档案网站、省、市档案文献遗产事迹记述文字资料进行采集;二是利用OCR 技术,采集世界记忆中国官方网站图片资料,获取中国档案文献文本资料。选取“式样雷图档”文献遗存为典型案例,建构“清代式样雷图档”这一体例。收集CNKI“风格雷图档”高相关期刊论文,检索有效论文76 篇,不包括建筑工程等类别。资料收集时间为2021 年10 月15 日,获取档案文献文本净资料1 份。
2.资料储存。最终获得档案文献文本资料《中国档案文献名录》142 篇,档案文献事迹记述文本64 篇,相关期刊论文39 篇。《中国档案文献名录》资料包括辑次、名称、形成年代、数量、保存者、地址、邮编、申报人、文献内容、解说词等9 个字段,以CSV 格式存放。档案文献事迹记述文本内容主要包括,以机器学习可读取的UTF-8 编码TXT 形式存储的形成的时间、地点、人物、事件以及社会自然环境等内容。此外,挖掘提取的资料也要补正,主要人物的职务、机构、事件、职务、著述等信息,尤其要注意补充。
3.资料预处理。所收集的资料异构资料分析易受杂音影响,故资料清洗、去停用词、中文分词等预处理步骤应包含在资料分析前:(1)资料清洗:对初始资料资料清洗,删除与档案文献传承无关的词组或语句。(2)去停用词:以停用词库集合表36 为基础,降维文本集的特点向量。(3)中文分词:常用词典由于档案文献域内词语的特殊性,对所需的专业名词难以识别,需要对域内词典进行重构。从已收集处理的资料中筛选出“档案文献名录”中的文献内容和评介文本资料共142 项,再通过ROSTCM社会化网络分析软件筛选高频词、增补近似词等方法,整理成《档案文献领域辞典》。
经过对上述资料的清理、遣词断句、汉语分词等预处理操作,最终形成档案文献的完整语料库。数据的实体提取和基于语料库的本体构建。
(二)档案文献本体构建
1.分析核心概念对象
以“档案文献名录”的概念对象及其相互关系,按照领域本体对抽取的核心实体进行分类、划分等级。而特定日期、物品种类、事件等类别则受限于命名实体辨识、关键词提取等技术,主要依赖于手工抽取。按频次降序排列地理位置、责任者、民族、时期、语言等。增加和补充档案文献领域的核心概念对象是一个不断丰富和扩展的过程,在此后的工作中,作者将继续收集档案文献资料,完善补充档案文献中的概念名词的类别和描述,并对我国档案文献名录项目内容的本体概念图,在相关文献专家的指导下进行整理。
2.构建应用本体
利用Protege 5.5.0 本体开发工具,在分析中国档案文献名录中档案文献的核心概念间的基础上,构建各概念的层级结构和关联关系,从而完成档案文献本体的构建过程。某一中国档案文献项目的创建实例,是根据本体定义的核心类和对象和数据属性等框架,精选而成的档案文献概念本体网络(见图2)。
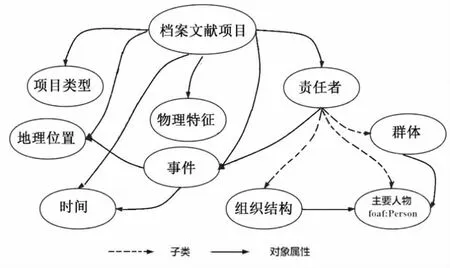
图2 档案文献本体模型部分内容
《清代式样雷图档》是清代雷氏家族参与设计绘制的故宫、颐和园、清东陵、清西陵等工程的图样和文字档案资料的建筑历史资料。《中国档案文献名录本体模型展示与说明》选择《清代式样雷图档》作为研究案例。本体构建“清代风格雷图档”语义组织概念模型,链接案例实体与本体之间的关系,实现对“清代风格雷图档”项目中实体、语义的内在逻辑结构及其实体以实体、属性、关系等三元组的形式进行描述。在已建立的类目下增加相应的例题,共有198 个属性。
《清代样式雷图档》应用本体概念图的形象化,图谱中的结点是遗存本体的概念,结点间的有向线段是实体间的语义关系。该家八代、样式该图档相关人物共同构成有向的社会网络图,群体之间形成纵横交错的关系网络,具体表现为师徒、父子、配偶等诸多关系,以及参与保护、任职等由保护文献形成的关系。就具体事例而言,本体可检索到的文献项目名称为《清代样式雷图档》,有雷发达、雷金玉、雷声徵等均为该遗产的主要人物姓名,而雷家玺正是秘密将图档运回家中并加以保存的父亲雷景修,因此保存了大量式样该图档。
(三)知识推理
本体推理的主要应用:对于本体的建立者,推理的主要应用是对建立的本体进行一致性检验。对于本体的使用者,推理的主要应用是获得本体中的知识和运用本体中的知识解决问题。
1.传递关系
对于关系R 和任意实体X、Y、Z,如果存在三元组(X、R、Y)和(Y、R、Z),并由此推理得到(X、R、Z),则关系传递关系。档案文献本体建设中,档案文献项目“包含”责任者条目,同时责任者条目“包含”主要人物,且通过经验可以判断,档案文献中应当“包含”主要人物(见图4),那么“包含”关系为传递关系。在对档案文献遗产本体实例化时,仅构建了档案文献项目与责任者条目、责任者条目与主要人物间的关联,通过人为方式筛选其包含的主要人物并添加其关系较为耗费人力,且容易遗漏,因此可以由档案文献本体推理进行完善。
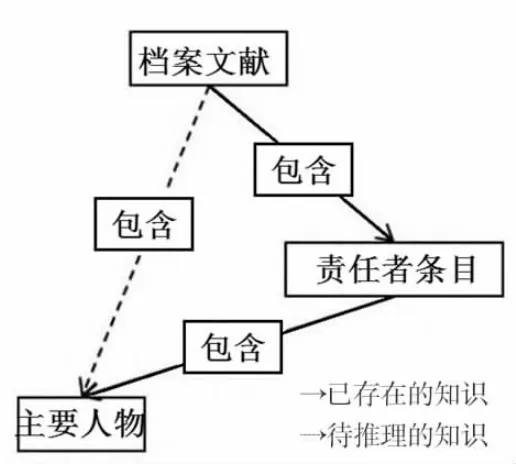
图4 传递关系包含知识推理
在进行知识推理之前,只能通过作为中间节点的词条进行检索,且重复结果较多,查询效率较低,所以通过语义web 规则语言(swrl),定义推理规则sso:consistof(?X、?y_^so:consistof(?Y、?Z)->SSO:Consistof(?X、?z,进行知识知识推理后再次检索,本体实例关系的完善、语义表达与知识检索能力的加强等,都是通过知识推理追根溯源、不断发现新的隐含关系、构建更为完善的档案文献知识体系、助力档案文献传承与保护的有效途径。
2.对称关系
对关系R 和任意实体X、Y,如果存在三元组(X、R、Y),并由此推理出(Y、R、X),则关系对称关系。档案文献中常有多种字的异形之间是对称关系,即A 的异形为B,则B 的异形为A。但现有的例题关系和录入方式难以做到全面的知识关联,所以凡是相关的异形,如果通过某一刊物或典籍检索到主语为录入的,都可以通过它查到;反过来说,检索到的是“异形”的其他的异形就很难找到了。但该例中能全面检索到的概率只有1/12,知识检索的查全率较低,完善档案文献本体急需知识推理。通过SWRL 定义推理规则"SSO:SAMEWord (?X、?y)->sso:SameWord(?Y,是吗?x,实现关系推理的“异形”。推理而来,方向相反,实现了对称关系推理,完善了档案文献本体,提高了其知识检索时的查全率。
3.互反关系
对于关系R1、R2 与任意实体X、Y,如果存在(X、R1、Y),并由此推理得到(Y、R2、X),反之,则关系R1 与R2 是相互对立的关系相似,但更为普遍,大多数关系反向关系,通过对互反关系的定义、推理,有效提高了档案文献本体语义检索的查全率和查准率,同时也提高了档案文献本体语义检索。
六、结束语
传统方法可能只提供系统集成,而不是在知识层中推断其内容。也就是说,知识共享不仅涉及系统连接,还涉及知识推理机制的参与。可以得出以下与开发技术相关的经验结论。第一,形式概念分析(FCA)可以作为一种知识获取方法,从专业知识中获取概念和属性。第二,OWL-DL 可以用作知识推理语言,提供形式化逻辑表达式来描述知识概念。因此,本研究表明文献的本体构建技术具有良好的知识构建潜力,应开展未来研究,以构建相关文献的本体构建,并与其他文献的本体构建知识库进一步合作。
