面向混合负载的分布式气象数据管理系统设计
2024-01-21顾青峰
陈 超,顾青峰
(中国气象局气象发展与规划院,北京 100081)
0 引 言
气象数据具有数据规模大、数据类型多样化等特点[1]。例如欧洲中期天气预报中心(European Centre for Medium-Range Weather Forecasts,ECMWF)目前每日数据增量为300 TB,当前数据存量已经超过500 PB。随着气象传感器的增加与气象高性能计算能力的提升,经纬度的精度越来越高,气象数据的规模也呈现爆发性增长。而且,气象数据不仅规模大、增速快,同时也面临天气预报、气候变化分析等很多种气象业务的大量查询需求,其中很多查询的延迟要求非常高[2-3]。
因此,气象数据管理系统需要同时具备大容量、高速写入、高速查询的需求。目前气象数据管理系统优先满足大容量的需求,大部分放在大规模存储系统中维护,应对查询,特别是复杂查询的能力不足,迫切需要构建一套面对读、写混合负载时能够达到高性能的新一代大容量分布式气象数据管理系统。本文基于国际上最先进的类Spanner 分布式数据库架构,重点对分布式数据库同时应对数据写入与查询的能力进行优化,设计和实现一套面向混合负载的分布式气象数据管理系统,能够在保持高写入性能的前提下,将复杂查询的性能提升3.13倍。
1 相关工作
气象数据[4-5]符合大数据的4 个V 特征,包括海量的数据规模(Volume)、快速的数据流转和动态的数据体系(Velocity)、多样的数据类型(Variety)和巨大的数据价值(Value)[6-7],这也给气象数据管理系统带来很多挑战。以气象数据中占比很高的气象模式数据为例,可以看出气象数据不仅规模大、类型复杂,而且数据快速流动、查询类型多样。在气象数据中,由卫星、高空和地面的大量气象传感器记录的状态信息传送到高性能计算机后,高性能计算机根据最新的天气实况数据,通过物理方程计算运算产生了模式数据。模式数据包含了各个经纬度、海拔上的多种预测的物理量(例如温度、湿度、风速等),而且包括未来不同时间点的预测值(如未来3 h、6 h、72 h 等)。每天高性能计算机都需要计算和产生多次模式数据,用于提升天气预报的准确度。近年来,涌现了大量数值模式相关的研究。同时随着高性能计算机计算能力的不断增长,模式数据的精度越来越高,规模也越来越大。天气预报等大量气象应用同时对模式数据进行各种复杂查询。
气象数据管理系统面临着同时进行高频度的数据写入与数据查询的需求,非常符合Gartner 在2014年提出的新型混合事务和分析处理(Hybrid Transaction and Analytical Processing,HTAP)[8-9]应用程序框架,兼顾传统联机事务处理(Online Transactional Processing,OLTP)[10-11]和联机分析处理(Online Analytical Processing,OLAP)[12-13]的特点,因此对数据管理系统的要求也更高。典型的HTAP 数据库产品包括Oracle Dual-Format[14]、MySQL HeatWave[15]等。目前我国气象信息系统一般采用分布式存储系统为主、数据库系统为辅(例如存储模式数据在文件系统中的位置,相当于索引的作用)来构建气象数据管理系统。这类系统应对大规模存储的能力强,但是应对负载查询的能力严重不足。
而国际上的大规模数据管理系统,在过去几十年,经历了单机数据库(例如PostgreSQL、MySQL 等)、大规模并行处理(Massive Parallel Processing,MPP)数据库[16]、NoSQL[17-18]架构,逐渐提升系统扩展性,可以管理更多数据。但是NoSQL 系统使用键值对等数据模型,放弃了严格的事务保障和复杂查询能力,需要应用做很多额外开发工作。因此,最近几年,以Google 公司的Spanner[19]为代表,涌现了一批新的NewSQL 分布式数据管理系统,包括CockroachDB[20]、TiDB[21]等,可以兼顾事务保障和优秀的扩展性的能力。
类Spanner 分布式数据库系统的架构如图1 所示。系统一般由本地存储引擎、分布式共识层、分布式事务层和SQL 引擎层构成。本地存储引擎目前多为键值对存储引擎,如RocksDB[22]。同时为了提升系统的可靠性和可用性,一般同一份数据在不同节点上部署多个副本,防止部分节点出现软硬件崩溃或网络故障,从而导致系统中的数据无法访问。分布式共识层一般采用Paxos 协议族[23-24],例如Raft 协议[25]、ZAB[26],保障系统的多个存储副本达成一致,即使在部分节点崩溃时,系统仍能正常工作,不出现错误和一致性问题。分布式事务层一般采用两阶段提交(Two-Phase Commit,2PC)[27]方法在多个节点之间提供事务ACID 属性的保障。SQL 引擎层负责SQL 语言解析、查询计划、优化和执行等功能。此外,系统中一般会有元数据管理节点来管理全局的元数据、提供时钟服务和协调服务等。
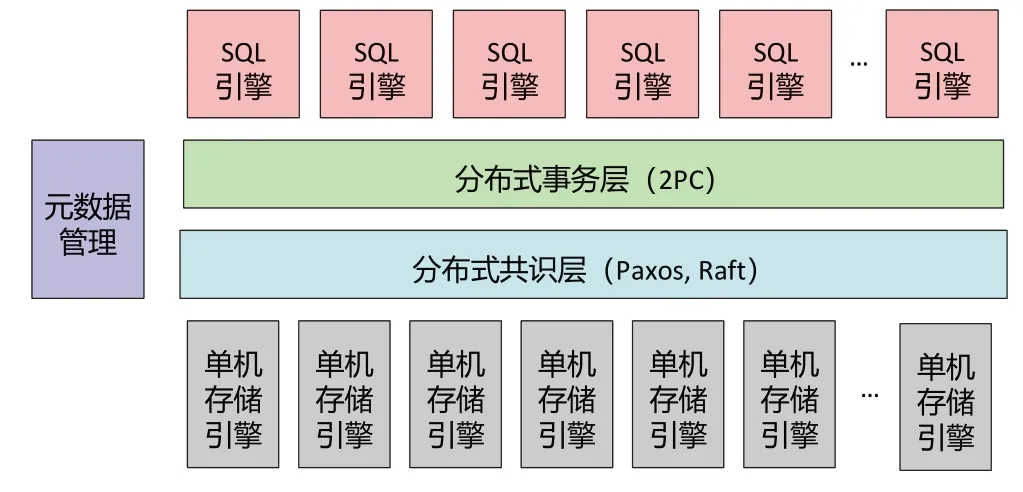
图1 类Spanner分布式数据管理系统架构
但是这些NewSQL 系统主要是处理写入为主的业务,应对复杂查询的能力不强,无法很好支撑HTAP 应用,也不适合直接用于支持气象数据管理。目前已有的HTAP 工作中,一般仍然是将多个子系统进行组合,部分子系统负责OLTP,部分子系统负责OLAP,在2 个子系统之间进行数据同步[21,28],并没有在系统设计上面向HTAP 进行原生的系统设计。气象数据迫切需要一套扩展性好,同时应对HTAP 能力强的新型分布式数据管理系统
2 气象数据特征分析
气象数据中最重要的是模式数据,大约70%的气象数据为模式数据[29-30],而且模式数据不断更新。天气预报等气象业务中,预报员也需要对模式数据频繁地进行查询。模式数据是根据大量气象传感器采集的天气状态信息,由高性能计算机计算出的地球表面不同海拔上每个经纬度空间点上的多个物理量(如温度、湿度、风速等)在未来一段时间内的预测值(例如3 h、6 h、9 h、24 h、72 h 等)。由于计算和存储能力有限,也因为空间上相邻区域的天气状况非常接近,因此一般每个海拔高度上经纬度空间的精度一般为几千米范围,这个空间范围在计算时会被抽象为一个“格点”。如果模式数据的每条记录对应一个格点,那么模式数据中这个格点的属性值非常多,经常达到几万个甚至更多,一般包括1000个左右的物理量以及每个物理量未来几个时间段的预测值,而且一般会同时根据不同的算法计算多套模式数据,如表1所示。

表1 气象模式数据示意图
2.1 模式数据的更新
模式数据在不断进行更新,高性能计算机根据最新采集的天气状况,不断重新计算,并更新气象数据管理系统中的模式数据,以提升天气预报的准确度。随着高性能计算机计算能力的不断提升,模式数据更新的频率不断提升,天气预报的准确度也在不断提高。
2.2 模式数据的查询
预报员对模式数据的查询类型非常多样,例如查询一个经纬度平面的格点数据(比如查询某个省未来3 h 的地表气温)、查询某个格点的时间序列数据(例如查询某地未来一段时间的湿度变化)、查询某个格点的不同物理量、查询某个格点不同模式计算产生的数据用于比较等。因此,模式数据的查询呈现以下2个特点:
1)每次查询经常是查询格点数据的一小部分列,例如只查询未来某个时段的温度,可能涉及一个列,或者几个列。而且不同类型的查询,关注不同的列。
2)点查询和范围查询并存,可能只关注一个格点的数据,也可能关注一定空间范围的数据,例如一个省,甚至全国的数据。
2.3 模式数据管理的挑战
模式数据的管理属于典型的HTAP 应用,模式数据一边在更新,一边在进行查询。目前已有的数据管理系统,很难在读写2个方面都做好。
3 面向混合负载的分布式气象数据管理系统设计
本文在目前主流的类Spanner分布式数据库系统的基础上,充分利用存储层多个副本的特点,部署不同的副本形态,从而可以应对混合负载中不同应用的需求。例如有的副本更适合气象数据的插入、更新操作,有些副本更适合气象业务的数据查询,从而提升混合负载下气象数据系统的整体性能。
3.1 系统架构
本文设计的面向混合负载的分布式气象数据管理系统应对HTAP 需求的关键是在多个存储副本采用不同的存储模式。一部分副本更适合数据的写入、更新,以及对一个数据项的大量属性的访问;而另一部分副本更适合对某个属性或某几个属性的查询,可以避免很多无关气象数据的读取,尤其是对于气象模式数据这样属性非常多的情况来说。
如图2 所示,为了支持异构数据副本机制,分布式气象数据管理系统的大部分层次都需要做专门的调整:
1)单机存储引擎层:副本的具体存储模式包括2种不同的气象数据存储模式,具体实现将在3.2 节中详细介绍。
2)分布式共识层:主要的区别是在异构副本下,所有的副本都需要支持读取。传统Raft 协议的实现多数支持领导者副本的读取,追随者副本只是提供冗余,提高系统可靠性;但Raft 协议的设计实际是支持追随者副本读取的[11],本文系统采用标准Raft 的追随者副本读取设计。
3)SQL 引擎层:需要增加访问路由策略模块,每次对气象数据的访问都可能有多个副本的多个选择,因此需要选择最适合的副本进行访问。具体的策略将在3.3节详细阐述。
4)元数据管理:需要额外记录每个副本采用的气象数据存储模式,以便SQL引擎进行访问路由决策。
3.2 气象异构存储方案
气象模式数据的每条记录对应一个格点的属性信息,传统模式一般用一个气象格点的所有属性作为数据库的一条记录,即以格点为中心的存储模式(简写为格点存储模式)。但是如前文所述,每个格点的属性可以达到上万个甚至更多,包括多种气象模式计算出的约1000 个物理量,每个物理量还有多个未来时段的预测值。因此如果气象查询只涉及气象格点其中一个属性或少数一些属性,那么传统的格点存储模式(如图3(a)所示,每个格点的所有属性聚集在一起存储,在单机存储引擎上表现为一个键值对),访问时绝大部分数据都是无效数据,因此实际的数据访问吞吐会非常差。

图3 格点存储模式和属性存储模式对比
如果缩小记录的粒度,以单个格点的单个属性或少数属性构成的属性组作为一条记录,即以属性为中心的存储模式(简写为属性存储模式),那么可以显著减少气象业务查询时对无效属性数据的访问,从而可以显著提升气象查询的性能。具体如图3(b)所示,每个格点的属性可以分为多个组,每组包括一个或多个属性,每组用一个键值对来存储。属性存储模式的优点是在应对单个属性或少量属性的大范围查询时,可以有效提升读取数据的有效率,避免I/O 浪费。但是如图3(b)所示,其缺点是键中除了格点坐标外,还需要包括属性组的ID 信息,因此长度有所增加,会消耗更多存储空间。此外,属性存储模式下键值对的数量会显著增加,CPU计算和处理的开销会增加。不过对于属性特别多的气象模式数据来说,属性存储模式对很多气象业务的查询性能提升效果会比较显著。具体属性组的大小、属性的聚集,需要根据气象应用的查询特征来设置,以达到最优化的效果。
3.3 查询路由策略
当存储层有格点、属性2 种类型的多个副本可供选择时,SQL引擎层需要通过一定的查询路由策略来决定访问哪个副本。本文系统中,查询路由策略主要采用启发式规则方式,按照优先级从高到低,采用以下3类规则来决定路由选择:
1)由于气象业务中预报员对模式数据的查询比较多样化,但整体来说,一般分为2 大类:一类是对某个格点的多个属性的查询,例如对某个地点的时间序列查询,或多个物理量的查询,或者多个气象模式的比对,这种情况比较适合访问格点存储模式副本,可以保障一次键值对访问能获得所有需要的数据。第二类是对少量属性的大范围空间查询,例如对一个地区(如一个省、一个市)某个海拔的温度、湿度查询,这时比较适合访问属性存储模式副本,以减少无关属性的访问。
2)事务分为读写事务、纯写事务、纯读事务3 类。由于在Raft 协议中,只有领导者副本能够处理写请求,而所有副本都可以处理读请求,因此读写事务和纯写事务一定会路由到领导者副本,纯读事务可能路由到所有副本,具体将通过以下2 条规则确定。值得注意的是,为了更好地处理写请求,领导者副本一般都默认设置为格点存储模式副本;但是当原有的领导者副本所在节点崩溃,其余副本均为属性存储模式副本时,只能由属性存储模式副本当选领导者,这时属性存储模式副本仍然可以处理写情况,只是写入性能相较于格点存储模式副本会低一些。
3)此外也需要考虑到各个副本所在节点的负载情况。如果系统中出现热点,某个目标副本所在节点的整体负载超过阈值,则会访问其他负载较低的副本,从而减少请求排队时间,提升系统整体的负载均衡程度和整体性。
4 实验结果与分析
本文的分布式气象数据管理系统主要由元数据管理、SQL引擎、分布式事务、分布式共识和单机键值存储引擎等部分组成。其中单机键值存储引擎采用目前主流的LSM-Tree 架构[31],在访问性能和存储空间效率方面都具有明显优势。分布式共识协议采用Raft协议[25],分布式事务采用主流的2PC协议。
在实验测评中,系统部署于8 个物理节点上,每个节点包括2 个Intel 4208 CPU、64 GB 内存和2 块1 TB 的固态硬盘。实验数据采用典型的气象模式数据,一方面在不断更新模式数据,通过系统每秒进行的数据更新事务数目来量化性能;另一方面在多线程进行模式数据的典型查询,通过查询的平均延迟来反映性能。实验过程中,读写线程数量一样。本文提出的异构气象存储模式将与传统的格点存储模式进行性能比较。
当气象业务访问线程数量从4 增长到128 时,系统写入性能如图4 所示,系统查询性能如图5 所示。由图中的实验结果可以看出,本文提出的异构气象存储模式相对于TiDB 等分布式数据库系统中普遍采用的传统存储模式,在写入性能上略有下降,但是在查询性能方面有显著的提升,特别是在高并发的情况下。

图4 系统并行写入性能

图5 系统并行查询性能
写性能下降的主要原因是异构气象存储模式的多副本混合采用格点存储模式和属性存储模式,其中属性存储模式中键的长度增加,占用更多存储空间,写入负载下实际写入系统的数据规模更大,而且键值对数量增加,需要更多CPU 处理。因此写入的平均速度略有下降;不过下降幅度并不大,平均下降2.19%。
如图5 所示,异构气象存储模式的读性能提升的幅度非常大,查询性能平均提升3.13倍。主要原因是本文系统的列存储模式在处理少量属性的范围查询时效率非常高,读取的无效数据很少,而且负载均衡程度更高,在高并发、高负载的情况下效果更为显著。
5 结束语
作为典型的科学大数据,气象数据规模大、增长快、数据类型和查询多样化,而且价值大,尤其是符合HTAP 应用特征,对数据更新和数据查询要求都非常高,因此迫切需要能够高效支持HTAP 的新型分布式数据管理系统来支撑。本文设计和实现了一套面向混合负载的气象数据管理系统,通过存储层格点存储模式、属性存储模式的异构设计,以及SQL 引擎层的智能查询路由,可以同时高效地满足气象模式数据的并行更新和查询。相对于传统模式,可以在高写入性能的前提下,将气象的复杂查询的性能提升3.13倍。
读写混合负载的特征在气象应用中越来越普遍,HTAP气象数据管理系统具有很好的发展前景。本文方法为了显著提升查询性能,对写入性能有少量的牺牲。未来将进一步研究可调节的HTAP方法,在读、写性能之间进行调节,精确满足具体气象应用的需求。
