基于可学习记忆特征金字塔网络的小样本目标检测
2024-01-21夏千涵何胜煌吴元清赵乐乐
夏千涵,何胜煌,吴元清,赵乐乐
(1.广东工业大学计算机学院,广东 广州 510006;2.上海交通大学自动化学院,上海 200030;3.威斯康星康考迪亚大学,威斯康星梅库恩WI 53097)
0 引 言
近年来,随着CNN 网络的发展,目标检测任务性能得到了极大的提升。而现实场景如工业领域的产品质检等领域中,受限于有限的缺陷样本,导致训练出来的模型泛化效果很差,不能够很好地进行移植使用,成为限制其发展的一大因素。因此小样本目标检测这一内容逐渐得到关注。它与传统的目标检测的差别在于,小样本检测需要克服在极少的训练数据这一前提下,面对新加入的样本能够很好地学习其特征并完成正确分类。
目前主流的解决方案主要可以归类为以下3种:
1)基于度量学习的方法。度量学习一般指的是学习相似度度量,在上述标准下,相似的样本有着较高的得分,而不相似的样本的得分则比较低。相似度度量可以是样本的空间距离、特征距离或是任一算法皆可,只要方法能够反映样本和特征之间的相似度即可[1]。
2)基于数据增强的方法。小样本的检测性能较差主要是因为原始数据较少,模型很难拟合得到一个较好的效果。而数据增强则是提高训练样本数量和扩增样本多样性的一种简易方法,很多基本操作例如旋转、裁剪、平移、缩放、错剪、拼接等都可以使得样本的多样性得以提高。例如本文实验对比中的TFA 模型是采用重采样的方式进行实现,相当于另一种数据增强方式,通过改变样本之间的高方差来降低模型遇到新类别物体时的学习难度。但这种方式的提升仍然是有限的,所以部分人提出对样本特征进行增强,如跨模态的增强,或是借助外部信息对特征进行针对性增强等。这种增强模块通常都是即插即用的模块,能够带来一定的收益[2-3]。
3)基于元学习的方法。元学习的方式是通过在相似任务训练得到一个泛化性较好的模型后,迁移应用到小样本的检测中去[4-5]。实现的方法是先构建一个量级较大的数据集,将其拆分为不同的任务,通过利用测试集对任务进行调整,使得其在少量的数据集上也可以表现优秀[6-8]。简单来说,就是通过学习大量的任务,找到其共通的关系,从而使得模型能够快速准确地处理新的同类任务。
目前较为先进且性能较好的方法绝大部分都是基于上述第3 种方式采用迁移学习的方式来实现,即在源数据域上进行预训练,然后在目标场景下进行针对性的模型微调。通过上述预训练方式使得模型在接收到新类别时具有基础的特征提取能力,从而达到在少量样本作为基础的情况下,面对新物体也能有良好的兼容性。人们发现这种方式虽然能够在目标物体分布较为相近时有良好的效果,但是如果涉及稍微复杂的场景时容易出现分类错误的情况,即使能够在定位上偏差很小,但是在分类精度上却仍然表现不佳。产生上述现象的原因就是小样本的场景下数据量小,导致相近类别容易产生误判混淆,最根本原因是模型无法提取到目标物体的判别性信息。例如在本文实验中所对比的Context-transformer,该文选择使用上下文信息进行辅助分类,在区分目标物体是马还是狗的情况下可以通过是否有人骑在上面进行判断,即充分利用目标物体周边的物体信息即上下文信息进行特征信息补充。笔者认为,模型能否提取到干净的判别性特征才是影响分类性能的关键,面对新场景的情况下,模型需要有一定的学习能力去自行找寻关注点进行特征提取,并且与数据集中的相似类别进行区分。
从上述主流的解决方案可以发现需要找到各类目标的判别性特征,越丰富越干净的特征对于其效果呈正相关关系,所以笔者认为如何更好地保留目标特征且剔除无关背景噪声,是解决小样本目标检测这一问题的新思路。因此,在特征金字塔网络(FPN)的启发下,提出一种可学习的特征金字塔网络。它主要包含2个模块:
1)自适应特征融合模块。传统的FPN 在相邻2层特征之间采取直接相加的方式得到新层级特征,然后反馈给上一级做相同的操作。但是对于不同尺度的目标在各层的响应值应当是不一样的,例如大尺度的目标应当在顶层特征层更具有判别性,而小尺度目标则在低层特征图具有更丰富的细节信息。所以在不同层级的特征融合之前加入了一个可学习的权重系数矩阵,通过大量的数据去训练使得模型能够在面对不同尺度目标的情况下选择不同的比重去融合相邻层级的特征,避免了有效的特征被淹没的情况。
2)特征监督模块。现有的基于FPN 的目标检测框架都是基于backbone 提取目标图像特征后,传入FPN进行处理,在FPN中进一步做下采样和上采样融合。而下采样的过程中,特征的响应点会发生一定的偏移,导致不同层级间的特征做融合时会发生特征错位的情况,容易产生特征混淆效应。所以通过加入一个特征对齐模块,计算不同层级间特征点的偏移量,通过偏移量对特征进行纠正,这样就能弱化不同层级间特征的不一致性。
本文的工作可以归纳为以下3点:
1)提出一种可学习的特征金字塔网络,可以在保留更多的有效特征信息的同时剔除无关背景噪声。
2)解决现阶段FPN 中存在的特征混淆效应问题以及不同尺度间特征存在差异性的问题,使得提取的目标特征更具有效性。
3)本文的方法在COCO 数据集和VOC 数据集上超过现有的基于FPN的目标检测范式。
1 相关研究
1.1 小样本学习
小样本学习在机器学习领域有重大的意义和挑战性。对于人类而言,可以通过极少数的个例去认识一个新的物品,而不像机器学习那般需要用大量的数据去拟合;所以小样本学习这一方法就应运而生。研究人员希望模型在学习了大量的数据已经能够掌握提取物体共性的这一能力,可以在面对新物体的时候仅仅依靠少量的样本数据就能完成快速学习,这就是小样本学习解决的问题[9-11]。当前在工业检测领域不可避免地遇到了对小样本学习这一能力的需求。现实的工业场景中,可投入的生产线其不良率是有一定控制的,所以对于研究人员希望如以往那样搜集大量的样本来训练模型就变得异常困难。而如果可以将小样本学习应用到实际场景中,那样就可以一定程度上摆脱对于数据量的依赖性,使得深度学习的落地变得更便捷。
以往面对小样本的问题的主要解决方案是基于数据增强和度量学习等。前一种方式是通过简单地对现有数据做增广等操作来丰富样本的多样性,使得模型能够达到同基于大量数据训练一样的效果,但是这种方案对于数据集的依赖性较强,在面对场景改变时效果则会大幅降低;第2 种方式主要指的是学习样本间的相似性度量,通过该特征来指导模型的拟合[12]。
1.2 小样本目标检测
目标检测任务是计算机视觉领域的最基础任务之一,其主要目的是对图像中的目标进行定位和分类。然而目前的目标检测框架都是基于大量已标注数据去拟合得到的良好效果,对于数据的依赖性则限制了其在部分场景下的应用[13-15]。传统的小样本目标检测解决方案是通过在充足的样本作为基类的条件下,使得模型能够拥有一个良好的特征提取和特征学习能力,然后再到少数的新类样本上进行测试,让模型能够在少量样本的条件下也有着较好的表现。
目前主流的解决方案是通过模型微调和对比学习来解决样本缺少的问题。而这2 种方案归根结底还是需要有着良好的特征信息作为前提,本文所提出的方法能够使得模型保留足够的特征信息,同时还能抑制不同尺度目标信息的不一致性,使得模型可以得到一个干净有效的特征,对后续的分类和回归可以起辅助作用。
1.3 注意力机制
注意力机制自从提出以来一直在计算机视觉的各个领域得到了应用,随之而来的各种变形也给注意力机制的性能带来了一定程度的提升和优化[16-18]。通俗地来说,借助注意力机制使得模型能够关注到希望其关注的地方,减少其他变量因素对其的干扰进而提升模型性能。例如常见的通道注意力机制和空间注意力机制,前者主要目的是找到不同通道数据之间的相关性,通过网络自身学习去赋予不同通道不同权重系数,从而来抑制不必须的信息干扰;而后者主要是提高关键区域的响应,弱化无关位置的输出,达到过滤噪声的目的。
注意力机制的应用场景有很多,例如在细粒度的图片分类任务中,由于该场景下类间差异小、类内差异大,很多时候会出现误分类的情况,所以笔者引入注意力机制,可以明确看到模型所关注的物体区域,从而判断模型的学习效果,结合认知经验去分辨模型是否能够关注到希望其重点关注的地方。
2 方法
2.1 概述
可学习记忆特征金字塔网络主要包含2 个部分,第1 个部分为一个自适应的特征融合模块,第2 个部分为回溯特征对齐模块。下面将详细介绍这2 个模块。网络的整体架构如图1 所示,本文所提出的特征金字塔网络和传统FPN[19]一样有4层输出,而输入则对应着主干网络中的C2、C3、C4、C5这4 层特征层。将每一层的输入对应送入LFM 模块(可学习自适应特征融合模块),将LFM 模块的输出作为SFA-M 模块(回溯监督对齐模块)的输入,通过计算矫正采样权重,得到最终的4层输出P2、P3、P4、P5。随后分别将上述4 层特征送入后续检测器执行和传统Faster RCNN相同的检测流程,如搜索建议框筛选。

图1 LMFPN模块结构图
2.2 自适应特征融合模块LFM
FPN 自从提出以来一直都被广泛地应用到各种场景中,与先前的特征提取范式不同点在于,它既能保存底层特征的细节信息,又能提取到顶层特征的强语义信息,并将该信息自顶向下作了一个共享,使模型能够获得细节信息的同时也能得到丰富的语义信息辅助分类。在网络结构方面实现了高层语义和低层语义的共享。自适应特征融合模块LFM 结构如图2所示。

图2 自适应特征融合模块LFM结构图
然而,在这个过程中最常用的操作是特征层堆叠,文献[19]将小尺度特征图上采样后通过点对点相加的方法来融合不同层级的信息。这种方法带来一种问题,对于不同尺度的目标,并非每一层的特征都对当前尺度目标起着判别性作用,直接相加的方法可能会导致有效特征被掩盖,反而削弱了多尺度的表征方式,让模型很难学习到干净有效的特征。因此,笔者提出一个可学习的自适应特征融合模块,通过引入一个权重监督机制,对融合前的特征层赋予不同的权重,使得模型可以倾向性地选择更有效的特征层级进行特征提取,而不是对每一层都赋予相同的提取侧重比。这样可以使得模型在面对不同尺度的目标时都能够自主地提取到更丰富的判别性特征。具体实现如下:
以C2、C3层为例,首先将C3特征层通过扩张比率为1、6、12、18 的扩张卷积进行特征提取,另外对原始特征通过均值池化和一个全连接得到一个one-hot特征向量,按比重与扩张卷积的结果对应相乘,从而实现对不同层级特征赋予不同的关注度,然后将上述得到的特征层通过Concat的方式进行堆叠得到输出,再对该输出进行扩张倍率为2 的亚像素卷积,使其尺度扩张为与C2对应的尺度得到C′3。C2通过一个3×3 卷积得到C′2,随后对C′3和C′2进行均值池化,并通过一个全连接层转为一个one-hot向量,分别与原输入对应相乘,最后将相乘结果送入回溯特征对齐模块进行矫正。
本文的方法充分考虑了不同尺度特征之间的差异性,因为原本的上采样是通过填充0 这样的虚假数据来达到扩增尺度的效果,因此通过引入一个亚像素卷积,利用不同通道的信息对所缺的像素点进行填补。另外传统的直接叠加方式会使得与目标同等尺度的特征层的信息有被其他层级掩盖的风险,所以引入权重参数矩阵,通过训练使得模型可以通过对不同尺度的特征层赋予不同的权重来侧重对更具有判别性特征的特征层进行特征提取。
该模块具体公式如下:
式中,θSFA-M对应回溯特征对齐模块,θC表示融合操作,θD表示空洞卷积,θF表示全连接操作。
2.3 回溯特征对齐模块SFA-M
回溯特征对齐模块SFA-M 结构如图3 所示。在传统的FPN中,相邻层级的特征经过上采样后通过堆叠的方式得到输出,随后再经过一个3×3卷积提取特征后送入检测头进行分类和回归。输入数据在经过多次下采样后再通过上采样还原至高尺度表达的时候会由于双线性插值算法的特性带来特征在空间上的偏移,因为上采样的方式是通过在相邻像素点添加相同数据来达到低分辨率转高分辨率表达的效果。这种填补方式弱化了真实数据中真实的空间分布特性,在给物体边缘的表征效果带来损失的同时会引入一定的虚假数据。在此基础上对2 层特征进行叠加的话会导致特征在空间上发生偏移。所以受可变形卷积的启发,通过引入特征偏移量来改变采样权重,从而弱化特征偏移带来的负面影响。具体实现如下:

图3 回溯特征对齐模块SFA-M结构图
以经由自适应特征融合模块得到的C′2和C′3层特征层为例,首先通过自适应特征融合模块根据目标大小赋予不同尺度的特征层相应的权重,随后将通过上述块中的亚像素卷积上采样得到的C′3作为回溯特征对齐模块SFA-M 的输入。首先以和C′3同尺度的C′2作为参考,通过可变形卷积引入偏移量的计算得到偏移权重矩阵对C′3进行重采样得到C_3,可以通过训练进一步调整重采样矩阵参数,使得下采样带来的特征偏移效应逐步削弱,得到更干净的特征表达;简单来说,就是加入一个优化模块,通过对比上采样后的特征图与原图的差异来进一步改善上采样的性能。为了更好地分析不同通道数据对模型的影响,引入一个自监督模块——回溯监督矩阵,首先随机初始化一个权重矩阵,尺度与输入尺度相同,每次有新的输入时会计算其与已有权重矩阵的L1 距离,距离小于阈值的会与对应矩阵做哈达玛积后输出,并同步更新矩阵参数,若没有符合的权重矩阵则会新加入纳入后续计算。经过回溯监督矩阵后的输出P2作为最终输出。
提出的SFA-M 方法考虑了不同层级特征之间的空间不一致性,通过在下采样的过程中引入特征偏移量来优化采样方式,通过赋予不同权重的采样比率来缓解下采样带来的偏移效应。另外还借鉴了度量学习的方法,通过在训练的过程中保存不同基类的数据信息,并与新数据计算L1距离,可以使得模型在接收新类型数据的时候也能有比较好的特征提取能力,在遇到已知类的时候能够有针对性的特征提取效果,从而使得模型获得更具有判别性的特征,辅助后续的分类器进行分类。
该模块具体公式如下:
式中,Fc表示深度可分离卷积,Fθ表示求L1距离。
2.4 回溯建议损失
受到对比损失的启发,设置回溯建议损失如公式(3)和公式(4)所示。
式中:N代表当前送入模型的特征批量的大小;n表示选取的4 个尺度的特征,对应上文的P2~P5;aij表示低尺度特征层通过亚像素卷积上采样得到的高尺度特征层;bij表示通过传统下采样中的对应尺度特征层;λaij和λbij分别表示在空间投影中aij和bij的余弦相似度。通过上述优化可以调整亚像素卷积上采样的效果,从而使得小尺度特征层的高分辨率表示更贴近真实值,减少上采样的差异性,进而使得面对不同层级的特征层做上采样操作时可以进行适当调整。
在训练过程中单阶段检测器选用的是标准的Faster R-CNN 进行训练,其包含了用于建议框拟合的rpn 损失,还有用于分类器的cls 损失,以及用于回归的reg 损失。通过实验发现,加入回溯建议损失可以使得训练有更好的拟合效果,具体的损失计算如公式(5)所示。
3 实 验
3.1 数据集
3.1.1 VOC数据集
VOC 数据集包含一个训练集(5011 张图片)与一个测试集(4952 张图片),总共9963 张图片,20 个类别。根据VOC 数据集的标准来评估平均准确度(mAP)以及每一类的准确度。
3.1.2 COCO数据集
COCO 数据集全称为Microsoft Common Objects in Context (MS COCO),它是一个大规模(largescale)的对象检测(object detection)、分割(segmentation)、关键点检测(key-point detection)和字幕(captioning)数据集。此数据集由32.8 万张图像组成。本文采用的主要是2014 版本的COCO 数据集。它包含16.5 万张图像,分为训练集(8.3 万张)、验证集(4.1 万张)和测试集(4.1万张),一共80个类别。
3.2 硬件参数详情
本文训练都是在联想塔式服务器上完成。操作系统为ubuntu 20.04,CPU 为英特尔i9-13900k 5.8 GHz,内存条采用海盗船4 条32 GB,频率为3600 MHz,显卡选型为2张NVIDIA GeForce GTX 3090显卡,单张显存为24 GB。另外,所有实验都是基于Py-Torch框架进行实现。
3.3 实验设置
为了验证本文方法的有效性,在VOC 数据集[26]和COCO[27]数据集上进行了大量的实验。参照标准的小样本检测的数据集构建和评估的指标,进一步确保数据的有效性和真实性。
采用Faster R-CNN[28]作为检测器,主干网络选用Resnet-101。batchsize 设置为8。优化器选用的是标准的SGD,动量为0.9,衰减为1e-4,总共训练迭代次数为12次。
首先对数据集作划分,划分规则主要参考小样本目标检测的划分模式,对COCO数据集和VOC数据集进行划分以满足小样本分布的规律。初始学习率设置为0.0025,每一个小类数据集会重复跑10 次,并取最终的AP 均值作为最终的AP 值代表。所用的训练集和测试集均为上述声明的公开数据集,分别为VOC2007&2012 和COCO2014 数据集。对于上述2 个数据集都会先进行类别划分的工作准备,简单来说就是将原数据集根据实验需求将其中部分类别作为训练的初始类别参与模型预训练工作,将剩余的类别作为实验类别,模拟小样本数据集进行实验设置。
采用标准的VOC 数据集作为训练数据,其中一共包含20个类别,将其中15个类作为基本类别,剩余的5 个类作为新类别。所有的实验在k-shot 的设置下进行,其中k=1,2,3,5,10。
同上,对于COCO 数据集的80 个类别,将和VOC相同的20个类作为新类,剩余的60个类作为基类,所有实验都在k-shot的设置下进行,其中k=10,30。
建筑电气工程需要考虑使用者的经济条件和使用要求。在施工的过程中,需要首先考虑的就是用户的使用要求,要使安装的电气能够满足用户的使用要求,并使其在使用过程中方便、安全。同时,电气施工还要考虑到用户的经济条件,在满足安全适用条件的基础上,为用户节省资源,也要坚持我国节约型社会的建设。
为了验证本文方法的有效性,总共设置了3 组实验,分别是基线实验、消融实验以及可视化实验。
3.3.1 基线实验设置
基线实验主要是针对与常规公开数据集上的先进方法进行对比,通过实验结果可以得知本文方法与目前最先进方法的指标差距,具有广泛的代表性和真实性。本文采用标准的小样本目标检测数据集划分方式,对于VOC 和COCO 数据集都进行相同的实验,初始学习率设置为0.0025,训练迭代次数为12次。
3.3.2 消融实验设置
消融实验是通过逐步替换本文中所提出的创新模块进行与基线实验条件相同的实验,根据实验结果可以得知所提出的不同模块各自带来的性能提升。消融实验的实施方式除了将LMFPN 模块中包含的自适应特征融合模块和回溯特征对齐模块进行单独实验外,其余实验设置与基线保持相同。此外,笔者还将上述2 个模块分别加入同类型的特征金字塔网络中进行实验,验证所提出的方法是否具有普适性。
3.3.3 可视化实验设置
可视化实验是通过热力图的方式来呈现模型在训练过程中所关注的特征信息,通过经验和以往常识判断加入的模块是否可以起辅助模型判断的作用。可视化实验将基线实验中的前向推理过程中的特征图进行抽离并根据其权值进行可视化,对高权值的赋予高亮色进行表示,对低权值的进行浅色表示,从而分辨模型在训练过程中所关注的物体特征是否满足需求,根据可视化的结果对实验模块进行进一步调整以更好地适应不同检测场景的需求。
3.4 实验结果分析
实验结果如表1 和表2 所示,可以看到本文方法在COCO 数据集和VOC 数据集都取得了较好的检测效果。

表1 基于VOC数据集的基线实验结果

表2 基于COCO数据集的基线实验结果
如表1 所示,可以看出在k=1,2,5,10 这4 种情况下本文方法的检测指标均优于其他算法,表明本文方法在小样本目标检测这一任务中的有效性。可以看到在k=5的先验条件下,AP值提升最大,达到了4.8。
如表2 所示,按照相同的测试方法在COCO 数据集上进行测试,k分别设置为10、30。可以看出模块能够在原有基础上带来极大的提升。特别是在k=30的情况下,检测性能超过了同类别的其他算法。
为了进一步验证模块的有效性,笔者还做了可视化对比。将Faster R-CNN 作为检测基线对比。可以看到图4 中,第1 列的检测结果为基准检测结果,第2列的检测结果为本文方法的检测结果。2 幅图片分别是对图片中的火车及图片中的猫进行检测,这个是基线和本文方法在训练2 个迭代时的结果。该对比同时涵盖了大目标和小目标。从实验结果来看,基线将目标物体火车错分为公交以及目标物体猫错分为狗,而本文方法在同样的迭代次数下的分类是准确的,从中可以看出在面对复杂场景的分类任务时本文所提出的方法分类结果更精确并且更好训练。

图4 基线方法和本文方法检测结果对比
3.4.2 消融实验结果分析
为了进一步验证提出的可学习的特征金字塔网络中各模块的有效性,设计了消融实验,结果如表3所示。
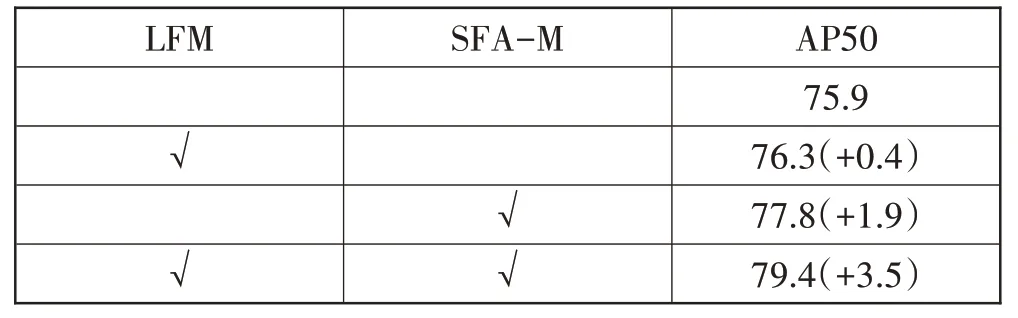
表3 本文方法中各模块的消融实验
同样采用Faster R-CNN 作为基准检测器,主干网络选用Resnet-101。通过4 次实验,分别对应基线网络,以及分别加入自适应特征融合模块LFM 与回溯特征对齐模块SFA-M,和同时加入上述2个模块作为实验条件。可以看出,在加入自适应特征融合模块后可以带来0.4的AP提升,在加入回溯特征对齐模块后可以带来1.9的AP提升,同时加入上述模块后最终可以带来3.5的AP提升。通过对实验结果进行分析,认为回溯特征对齐模块之所以可以带来更高的检测性能提升是因为数据集中包含了较多尺度不一致的目标,而其中偏小的目标对于位置的敏感性较大,在原本的特征金字塔结构模块中由于没有进行位置矫正,导致特征叠加的时候使得该尺度的目标特征产生混淆,从而影响了模型性能。
另外,为了和现阶段同类型的其他特征金字塔模块进行性能比较,还设置了一组消融实验,结果如表4 所示。在该实验中,分别替换LMFPN 模块和FPN、CEFPN 以及AugFPN 模块进行消融实验对比,这样可以更好地体现LMFPN 的兼容性和鲁棒性。根据实验结果可以看出,LMFPN 模块在该实验中取得了最高的AP指标,相较于改进前的FPN 模块方法带来了3.5的AP 提升,实验结果均优于同类型的其他特征金字塔模块。

表4 LMFPN模块与同类型模块消融实验
3.4.3 可视化实验结果分析
为了更好地验证提出的方法的有效性,对检测结果进行可视化,结果如图5 和图6 所示。首先先将模型的检测结果可视化,并且标注了所检测的物体位置信息以及分类信息。由于希望更好呈现本文方法的有效性,还做了热力图可视化。通过调取前向传播的数据,可以看到其特征响应值。根据响应值高低分布得到了热力图,红色区域即高亮区域为模型最关注的位置,蓝色区域则反之,为模型选择性忽略的位置。

图5 本文方法检测结果可视化

图6 基线方法检测结果可视化
图5 和图6分别对应本文方法的检测效果以及基线方法的检测效果。可以对比看出在基线方法中在第1 行的图中对于尺寸稍小的目标物体长颈鹿得出的分类结果被错误地归类至鸟这一类别,通过热力图可以看出其在小尺寸的长颈鹿目标区域其响应值较为分散,其关注程度明显低于其他的目标物体;而在第2 行的图片中,在基线方法的检测中小猫被错误地归类至披萨这一类别,通过热力图可以发现模型在检测猫的时候关注点被错误地下移至女孩的手部,有理由相信这是由于空间偏移带来的影响。而上述错误的分类通过引入本文方法后都能被纠正。
通过上述热力图可以看出模型的关注物体能力更好,可以提取到更具有判别性的特征。笔者认为带来当前效果的提升首先归功于所提出的自适应的特征融合模块,对于不同尺度的物体可以选择性选取对应的特征层进行特征提取,其次就是回溯特征对齐模块,通过借鉴度量学习的模式,可以在以往的模型学习数据中进行搜索并根据搜索结果赋予一定的权值,并且在对齐过程中减少了背景对模型检测的扰动,从而呈现了更好的检测效果。
4 结束语
本文主要针对现有的特征金字塔网络FPN 进行改进,所提出的可学习金字塔针对FPN中的特征混淆和特征偏移效应进行了改进。主要提出了2 个模块,第1 个模块是自适应的特征融合模块,替代了原始FPN中直接按同比例相加的方式,引入了一个权重矩阵,使得模型在训练时可以不断优化权重参数,在面对不同尺度的目标时可以针对性地选取对应尺度的特征层,保留更多判别性特征;第2 个模块是回溯特征对齐模块,引入了可变形卷积来纠正双线性上采样带来的特征点偏移这一影响,同时引入了回溯监督矩阵,通过类似于度量学习的方式,可以拉近相同类别的距离,使得模型在遇到新物体时也能有一个良好的特征提取能力。实验表明,在VOC和COCO数据集上都取得了良好的成绩,对比原来的FPN带来了更客观的提升。同时,本模块也可以作为一个即插即用的模块,适用于所有基于FPN的单阶段或双阶段检测器。
