基于自监督学习和数据回放的新闻推荐模型增量学习方法
2024-01-21林威
林 威
(华南师范大学计算机学院,广东 广州 510631)
0 引 言
在线新闻服务的便捷性使得许多用户的新闻阅读习惯已经从传统的实体报纸转向数字新闻内容,但新闻平台上无时无刻都在发布的海量内容也让用户不堪重负。因此,个性化的新闻推荐技术对于缓解信息过载和提高用户阅读体验极为重要,被广泛应用于今日头条、微软新闻等主流的在线新闻平台。近年来,随着深度学习技术的不断发展,个性化的新闻推荐技术也越来越受到学术界和工业界的广泛关注[1]。
现有的大多数新闻推荐方法都依赖于用户的点击行为来推断用户兴趣并基于固定数据集进行迭代训练。然而,在线新闻平台每时每刻都会出现大量新的新闻数据和用户交互记录,在现实世界中运行的新闻推荐系统需要从持续的新闻平台数据流中动态学习新的新闻和新的用户。
为此,本文基于以上现实场景提出增量学习设置,在新闻推荐任务中引入增量学习方法帮助模型进行增量更新。具体而言,新闻推荐模型以数据更新周期为单位不断更新,更新后的新闻推荐模型在下一个数据更新周期前为用户提供新闻推荐。
增量学习的主要挑战为灾难性遗忘问题[2],表现为在新任务上训练完成后的模型在过往的旧任务上的性能发生断崖式下跌。最简单的解决方案为联合训练(Joint Training),在每个数据更新周期都使用所有历史数据重新训练模型,但对于在线新闻平台来说,历史数据的不断累积会导致新闻推荐模型的训练时间和存储开销不断增大,无法直接应用。
新闻推荐模型进行增量学习需要处理新闻推荐任务输入流的非平稳分布导致的灾难性遗忘问题。通常,新闻推荐任务数据流随着时间变化,在t时刻,仅利用当前时刻的数据进行更新的新闻推荐模型Ft对于t时刻前的新闻和用户的建模不可避免地发生偏移,无法很好地拟合旧数据。新闻推荐模型的关键在于新闻文本的建模和用户偏好的建模。目前,以BERT[3]为代表的预训练语言模型(Pre-trained Language Models)凭借其强大的文本建模能力已经在自然语言处理领域取得了巨大的成功,并且可以很好地应用于新闻推荐任务以挖掘新闻文本的深层语义特征[4]。因此,本文的研究重点在于如何在新闻推荐模型增量学习过程保持相对稳定的用户偏好,使得模型不会忘记之前的用户偏好。
针对上述问题,本文提出基于自监督学习[5]和数据回放(Self-supervised Learning and Data Replay)的新闻推荐模型增量学习方法SSL-DR。SSL-DR 方法通过构建自监督学习任务来捕获用户在新闻推荐模型增量学习过程中的稳定偏好,使得用户特征具有任务无关性。代表用户稳定偏好的用户特征继续参与新闻推荐模型的训练,可以适应任务输入流的变化,有效地减轻灾难性遗忘问题。此外,鉴于基于回放的增量方法的优越性能,SSL-DR 方法提出基于用户对于候选新闻的点击概率分数的采样策略,从旧任务中选取具有代表性的数据,在新任务的训练阶段进行回放和新任务的数据联合训练。在此基础上,SSLDR 方法基于知识蒸馏[6]的思想将旧模型的知识强制转移至新模型中,进一步加强对于已学知识的记忆。
本文的主要工作如下:
1)出于对现实世界中的新闻推荐场景的考虑,本文在新闻推荐任务中引入增量学习设置,并通过自监督学习来学习用户的稳定偏好。
2)为了巩固对于已学知识的记忆,本文提出基于用户对于候选新闻的点击概率分数的采样策略实现样本回放,并通过知识蒸馏策略加强约束。
3)在公开新闻推荐数据集MIND[7](包括2 个版本:MIND_large 和MIND_small)的实验结果表明了SSL-DR 方法在新闻推荐模型的增量学习方面的优越性能和减轻灾难性遗忘的能力。
1 相关工作
1.1 新闻推荐
传统的新闻推荐方法通常基于协同过滤技术,根据用户和新闻之间的相似性预测新闻的排名。然而,基于协同过滤的方法通常存在冷启动和数据稀疏性等问题。为此,大量基于内容的新闻推荐方法或混合推荐方法被提出。比如,Son 等人[8]提出了一种基于位置进行分析的新闻推荐方法,每个位置对应一个与该位置相关的地理主题。
近年来,基于深度学习的方法广泛应用于新闻推荐领域,可以很好地建模用户和新闻之间的交互。其中,Zhu 等人[9]利用卷积神经网络CNN(Convolution Neural Network)和注意力机制,综合考虑用户的历史序列和用户当前的兴趣偏好。Wu 等人[10]提出了基于个性化注意力机制的新闻推荐模型,将用户ID 作为用户偏好动态选择新闻的重要信息。Zhang 等人[11]将知识图谱视为辅助信息的来源,基于用户行为中的主题和实体挖掘用户偏好。
然而,现有的新闻推荐方法专注于用户偏好建模或新闻建模,对于现实场景下的增量学习设置以及相应的灾难性遗忘问题仍待探索。
1.2 增量学习
增量学习旨在使得模型不断学习新任务,同时保持在已学习任务上的性能。通常,增量学习分为3 种类型[12],即:任务增量、类增量和域增量。任务增量需要每个任务与之对应的输出单元,类增量学习需要不断学习从未出现过的新类别,域增量学习则需要处理非平稳分布的数据流。
增量学习面临的主要挑战为灾难性遗忘问题,现有方法可简单分为:基于正则化的方法、基于回放的方法以及基于动态网络结构的方法。基于动态网络结构的方法在增量学习过程中动态扩展网络结构,在现实场景下持续扩展网络结构是不切实际的,因此本文只关注前面2类方法。
1.2.1 基于正则化的方法
基于正则化的方法主要通过在新任务的损失函数增加正则化项来缓解灾难性遗忘。Li 等人[13]提出通过知识蒸馏的方式保留之前任务的知识,将旧模型的知识强制转移至新模型中。Kirkpatrick 等人[14]通过FIM(Fisher Information Matrix)近似估计模型参数的重要性,约束重要参数在增量训练中不会发生明显变化。Zenke 等人[15]以及Chaudhry 等人[16]进一步扩展了此类方法。
1.2.2 基于回放的方法
增量学习通常假设模型在学习新任务时无法获取旧任务数据。基于回放的方法放宽这一限制,允许保存部分旧任务数据。Rebuffi 等人[17]首次提出基于回放的方法并通过Herding 技术来选择旧任务的样本,与新数据组合用于模型训练。Riemer 等人[18]提出经验回放ER(Experience Replay)方法,通过Reservoir Sampling 进行样本选取并将其结合到当前任务的训练批中。Buzzega 等人[19]在ER 的基础上,依靠暗知识提取旧任务的经验。
1.3 自监督学习
自监督学习旨在提供强大的深度特征学习,而不需要大规模的标记数据集,在许多下游任务中几乎达到甚至超过监督学习的性能[20]。
最初,基于实例判别的对比学习方法取得了巨大成功,基本思想是将每个实例视为一个类,在嵌入空间中将同一实例的视图拉得更近,不同实例的视图推得更远。然而,这类方法需要从内存[21]或当前批中[5]搜索不同实例,成本较高。最近,Grill 等人[22]和Chen 等人[23]引入不对称的自监督学习架构,只使用输入的一个扭曲版本进行更新,而来自另一个扭曲版本的特征表示则用作固定目标,很好地解决了以上问题。通过自监督学习,模型可以学习到可转移的通用特征。受此启发,本文在新闻推荐任务中引入自监督学习任务,学习通用的用户特征。
2 方 法
2.1 新闻推荐问题定义
本文的新闻推荐问题可以定义为根据用户在新闻平台上的新闻点击历史预测用户是否会点击之前没看过的候选新闻。给定候选新闻xt以及用户u的新闻点击历史,新闻推荐系统根据候选新闻的特征表示和用户的特征表示之间的相关性计算得分并决定是否向用户推荐该新闻。
基于深度学习的新闻推荐模型通常由新闻编码器(News Encoder)、用户编码器(User Encoder)和点击预测器(Click Predictor)组成。新闻编码器N和用户编码器U分别对新闻和用户进行建模,点击预测器C根据新闻特征和用户特征计算得分。
训练过程中通过负采样联合预测k+1 个新闻(k个负样本和1 个正样本)的点击得分,相应的损失函数为:
其中,ŷ′i为点击预测器的得分,S+为正样本集合,yj为样本真实标签。不失一般性,本文方法将基于以上结构的NPA模型[10]作为基础模型。
2.2 基于域增量学习的新闻推荐问题
新闻推荐任务的增量学习场景属于域增量学习的研究范畴,因此在本节中,为新闻推荐任务制定了域增量学习设置,以模拟增量训练新闻推荐模型的实际场景。新闻推荐任务数据通常随着时间变化。具体而言,在t时刻,新闻推荐模型Ft仅利用t时刻的数据Dt进行训练,并在t+1 时刻的数据来临之前为用户进行新闻推荐。
2.3 SSL-DR方法总体架构
本节将详细描述SSL-DR 方法的主要内容,包括基于自监督学习的用户稳定偏好和基于用户点击概率分数的样本回放2个方面,总体架构如图1所示。
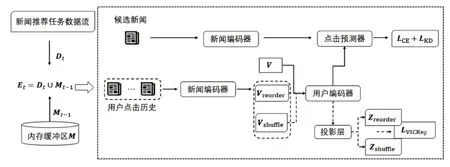
图1 总体架构
2.3.1 基于自监督学习的用户稳定偏好
通常,用户的兴趣偏好在浏览新闻的过程应是保持相对稳定的,不会剧烈变化,但通过增量学习更新的新闻推荐模型无法直接保持旧用户的特征表示,使得旧用户的兴趣偏好发生偏移。自监督学习的广泛应用已经表明了其在学习可泛化的通用特征方面发挥着关键作用[20]。
为此,本文提出在用户编码器上构建自监督学习任务来捕获用户在新闻推荐模型增量学习过程中的稳定偏好,从而可以学习到具有任务无关性的用户特征,适应任务输入流的变化。
具体而言,用户的点击历史通过新闻编码器得到的新闻特征集合为V={h1,h2,…,hci},其中ci表示当前用户点击历史的数量。首先,需要在新闻特征集合上进行不同的数据增强。
实验表明[24],用户点击历史的序列信息不会导致新闻推荐性能的明显差异。不难推断,不同顺序的用户点击新闻序列可能对应相同用户偏好。为此,本文使用用户点击新闻的逆序列和打乱用户点击新闻的序列来生成新的视角:
Va和Vb分别经过用户编码器U得到新的用户特征u=U(V),用户特征通过投影层G得到z=G(u),投影层对用户特征进行改造用于进行自监督学习任务。
本文选择VICReg[25]作为SSL-DR 方法的自监督损失函数,以最小批作为单位,构建Za={z1,z2,…,zn},Zb={z′1,z′2,…,z′n},其中zi,z′i∈Rd,n为批次大小,d为向量维度,zj表示Za中每个向量的第j个元素组成的向量。
VICReg从方差(Variance)、不变性(Invariance)以及协方差(Covariance)这3个角度进行了考虑。
方差项v(Z)为最小批中向量的方差,以Hinge 损失函数的形式进行计算:
其中,γ=1,ε=0.0001,S为正则化标准差。
不变性项s(Za,Zb)为Za和Zb之间每对向量的欧几里得距离,Za和Zb未经过归一化处理:
协方差项c(Z)为最小批中向量的协方差:
VICReg完整的损失函数包含以上三者:
其中,本文设置μ=0.5,λ=1,v=0.05。至此,原始点击历史V通过U可以得到具有任务无关性的用户特征u,和通过新闻编码器N得到的新闻特征一起输入到点击预测器进行计算。
2.3.2 基于用户点击概率分数的样本回放
为了保持新闻推荐模型对于旧任务知识的记忆,SSL-DR方法存储旧任务的部分样本,并在新的时刻t回放数据参与新模型的训练。
通常,用户对于候选新闻的点击概率分数越高,新闻推荐系统越可能将其推荐给该用户。反之,分数越低,推荐的概率也更低。正样本分数越高,负样本分数越低,新闻推荐模型的推荐性能越佳。
为此,本文认为,符合以上原则的样本更有助于模型训练。因此,本文提出根据点击概率分数高低进行旧任务的样本选取。具体而言,k+1 个新闻(k个负样本和1 个正样本)经过点击预测器会得到相应的点击概率分数{ŷ′1,…,ŷ′k,ŷ′k+1},正样本分数不变,负样本分数累加,得到排序主体为:
其中,ypos为正样本分数,yneg为负样本{ŷ′1,…,ŷ′k}分数之和,sort(·)函数根据ypos倒序、yneg升序排序,S为经过sort(·)函数排序的样本集合。
为了便于在整个增量过程中对内存进行管理,本文通过内存缓冲区M存储总数为m的样本。t时刻训练完成后,从S中选择m/t个样本,放入M中,M中t时刻前的每个任务对应样本数量更新为m/t。假定新来的数据为Dt,此时缓冲区中旧任务数据为Mt,t+1 时刻的数据集更新为Et+1=Dt+1⋃Mt。
基于E进行训练,新闻推荐模型预测用户会否点击候选新闻的损失函数为:
其中,为E中的正样本集合。
为了加强新模型对于旧的新闻和用户的记忆,本文进一步基于知识蒸馏的思想,让新闻推荐模型Ft对于新样本的点击得分趋近于Ft-1对于当前样本的点击得分,将Ft-1的知识转移至Ft中:
注意,此处不能直接作用于用户特征,否则会破坏其任务无关性。
结合自监督学习任务损失,新闻推荐模型增量学习最终的损失函数为:
3 实 验
3.1 实验数据集和评估指标
本文选用MIND[7]作为实验数据集,官方下载地址为https://msnews.github.io。MIND 是目前新闻推荐算法研究领域应用最广泛的大规模数据集,主要包含behaviors.tsv 和news.tsv 这2 个文件。behaviors.tsv 收集了微软新闻平台下匿名用户的行为日志。news.tsv 为新闻文章的文本信息。MIND 数据集有2个版本:MIND_small 和MIND_large,具体统计信息如表1所示。
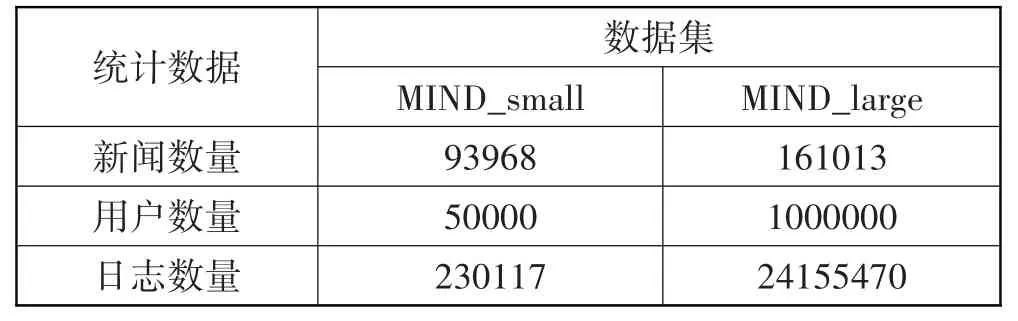
表1 数据集信息
为了模拟新闻推荐模型增量学习场景,本文根据用户行为日志的日期对数据集以天为单位进行划分,可以得到2019 年11 月9 日至11 月15 日的日志,即7个数据更新周期,仍命名为MIND_small 和MIND_large。其中,MIND_small 每个周期的数据量为10000,MIND_large每个周期的数据量为30000,80%作为训练集,20%作为测试集。
本文实验中的评估指标包括4 个常用的新闻推荐评估指标,即AUC(Area Under the Curve)、MRR(Mean Reciprocal Rank)、NDCG@5 (Normalized Discounted Cumulative Gain)、NDCG@10。每个实验独立重复5次,并报告平均性能。
3.2 基线方法
本文提出方法与以下主流增量方法比较:
1)Finetune:在每个更新周期中仅使用新数据对新闻推荐模型进行微调,存在灾难性遗忘问题。
2)Joint:在每个更新周期都使用所有历史数据重新训练模型,作为实验性能的上界。
3)LWF[13]:基于知识蒸馏的思想,强制新旧模型对新来数据的输出一致。
4)oEWC[26]:EWC (Elastic Weight Consolidation)首次提出通过约束重要参数来减少灾难性遗忘,oEWC(Online EWC)进行改进只需一个正则化项。
5)iCaRL[17]:第一个基于回放的增量方法,存储先前任务的样本用于新任务的训练。
6)DER++[21]:在ER的基础上匹配暗知识。
以上方法都是基于先进的新闻推荐模型NPA[10]进行增量训练,使用ADAM 优化器优化模型,基于回放的方法在MIND_small和MIND_large 上回放的样本数量分别为2000和3000。
注意,本文实验比较的不是单个新闻推荐模型的推荐性能,而是在新闻推荐模型中应用增量学习方法后在增量学习过程中的整体推荐性能。
3.3 实验结果与分析
3.3.1 与基线方法的对比实验
本节将3.2节中的基线方法与本文方法SSL-DR进行对比,表2 和表3 显示了所有方法在MIND_small 和MIND_large上经过7个更新周期后的平均推荐性能。

表2 MIND_small数据集上的性能比较

表3 MIND_large数据集上的性能比较
从表2 可以看出,Finetune 方法在新闻推荐模型的增量学习过程中能取得不错性能。Finetune 与Joint之间的差距较小,主要是因为新闻推荐任务流的数据变化过程较为缓慢,旧的用户和新闻会重复出现。基于正则化的方法如LWF 和oEWC 的推荐性能略优于Finetune 方法。显而易见,一般的正则化手段不能有效缓解灾难性遗忘问题;与之相比,基于回放的方法如iCaRL 和DER++通过重放数据参与新任务的训练,表现出更好的推荐性能。最后,参与新任务的训练,表现出更好的推荐性能。SSL-DR 方法在MIND_small 和MIND_large 中所有评估指标都能取得最优性能。例如,在表3中,本文方法的4个指标比目前最好的性能分别提升了0.71、0.61、0.69和0.62个百分点。这主要是因为:1)基于自监督学习的用户稳定偏好具有任务无关性,即使任务输入流是非平稳的,也不会影响对于旧的用户的偏好特征;2)基于回放的方法对于增量学习的灾难性遗忘有明显作用,并且SSL-DR方法通过知识蒸馏进一步巩固了所学知识。
3.3.2 消融实验
本节通过消融实验检验本文所提方法中各主要组件的有效性。实验包含3种变种方法:
1)M1:在SSL-DR方法中,只使用自监督学习学习用户稳定偏好,而不使用数据回放。
2)M2:在SSL-DR 方法中,只使用数据回放,而不使用自监督学习。
3)M3:在SSL-DR方法中,同时使用自监督学习学习用户稳定偏好和数据回放。
图2 和图3 给出3 种变种方法在MIND_small 和MIND_large 数据集上不同指标的对比结果。不难发现,相对M1 和M2,M3 的4 个指标都能在MIND_small 和MIND_large 数据集上取得最佳性能。这说明,无论是通过自监督学习来学习用户稳定偏好,还是通过数据回放巩固已学知识,对于提高新闻推荐模型增量学习的整体推荐性能和缓解灾难性遗忘问题,均有作用。
3.3.3 不同自监督损失函数的对比实验
本节主要研究不同自监督损失函数对于SSLDR方法的性能影响。实验考虑了目前有效的自监督学习损失函数,包括BYOL[22]、SimCLR[5]、Sim-Siam[23]、Barlow Twins[26]和VICReg[25]。SSL-DR 方法使用以上损失函数分别在MIND_small 和MIND_large上进行测试,结果如表4和表5所示。一般而言,使用VICReg 作为损失函数可以获得更好的性能。结合表2和表3中基线方法的性能,SSL-DR方法的用户稳定偏好可以通过不同的自监督学习损失函数来实现并取得不错的性能。

表4 不同自监督损失函数在MIND_small的对比实验

表5 不同自监督损失函数在MIND_large的对比实验
4 结束语
考虑到现实世界中的新闻推荐场景,本文提出了基于自监督学习和数据回放的新闻推荐模型增量学习方法SSL-DR。SSL-DR 通过在新闻推荐任务中加入自监督学习任务辅助学习代表用户稳定偏好的用户特征,可以适应增量学习的过程。特别地,SSL-DR针对新闻推荐任务的特点,提出基于用户点击概率分数进行采样以实现基于数据回放的策略,有效缓解了灾难性遗忘问题。
然而,基于回放的方法带有更多的内存占用的同时,也会引发数据隐私泄露问题(学习新任务时获取旧任务数据)。因此,解决数据隐私问题将作为未来工作的重点。
