杨树杂交群体苗期生长性状的全基因组选择研究
2024-01-20杜常健周星鲁胡建军
杜常健,张 敏,周星鲁,张 磊,2,胡建军,2*
(1.中国林业科学研究院林业研究所,林木遗传育种国家重点实验室,国家林业和草原局林木培育重点实验室,北京 100091;2.南方现代林业协同创新中心,南京林业大学,江苏 南京 210037)
杨树(PopulusL.)具有速生、易繁殖、适应性强和生产力高等特性,在木材加工、碳汇造林、制浆造纸和生物燃料等方面发挥着重要作用[1]。杨树提供了大量木材,但是杨树人工林土壤氮素缺乏导致其木材产量受到严重制约[2-4],因此选育高产量的杨树品种具有重要意义。作物育种的关键步骤是选择,而常规育种是以表型选择为基础的。基于亲本杂交和后代表型选择的传统育种费时费力,挖掘和公布一个新的品种需要至少10 a 以上的时间。基因组选择(Genomic selection, GS)也被称为基因组预测,通过在早期阶段淘汰潜力较小的个体来降低育种成本[5-7]。基因组选择现在被广泛用于数量性状的遗传改良,GS 可以减少植物育种中表型观察所需的成本和工作量[8]。通过使用详细的基因组信息揭示一个基因型的基因优势,可以使农业和林业生产发生革命性的变化[9]。
GS 的预测准确度影响因素包括群体的大小、群体结构、亲缘关系、分子标记、表型的精度、目标性状的遗传力和统计模型等[10-11]。分子标记的数量和密度影响基因组预测的准确度和效率,因此需要足够的分子标记并且选择适合模型才能得到准确的育种值[12]。统计模型在GS 研究中具有重要地位,其对表型和基因型数据的训练效果决定着标记效应是否估计准确,进而对后续的育种计划产生影响[13]。采用固定和随机效应的混合线性模型(Mixed linear model,MLM)直接预测个体的遗传优点,被称为最佳线性无偏预测(Best Linear Unbiased Prediction,BLUP)。VanRaden 借助BLUP 于2008 年提出了基于G 矩阵的gBLUP(Genomic BLUP)方法[14]。目前gBLUP 已经广泛应用于动植物育种研究中,并且因为它的高效、稳健等优点,现在仍饱受青睐。Wang 等人基于gBLUP,压缩个体分成不同的组构建了cBLUP (Compressed BLUP)模型和区段化标记(bin 标记)构建了sBLUP(SUPER BLUP)模型[15]。
育种计划的成功取决于对遗传参数的精确估计,包括对育种值的可靠预测[16-17]。育种值是遗传效应对该性状表型值的加性效应[18],它消除了环境影响,反映了真实的遗传效应,提高了选择的准确性。通过估算亲本和杂交后代的育种值进行基因型选择可以代替表型选择,从而提高选择的效率和准确性。育种值的估算对重要造林树种的遗传改良起到了重要作用。有效地建立基因型-表型关系,以便作出可靠的预测,指导探索巨大的遗传选择空间。对于杂交作物来说尤其如此,因为潜在杂交品种的数量太高,无法进行广泛的测试。由于GS 在提高动物育种遗传收益方面取得的巨大成功,因此GS 被引入到植物育种研究的许多方面,如自交系性能预测、亲本选择和杂交预测[19-20]。利用GS 对植物的重要的经济性状进行预测育种值,加快育种计划具有重要的意义。目前在杨树的经济相关性状的全基因组选择方面的研究十分欠缺,亟须展开基因组选择相关的研究工作。
在F1杂交育种中,随着自交系数量的增加,需要测试的亲本组合数量呈指数增长。因此,利用GS 对有杂种优势的F1代进行预选,可以实现高效育种。本研究对高氮和低氮环境下的地径、株高和茎生物量等性状进行全基因组选择研究,利用3 个全基因组选择模型(gBLUP、sBLUP、cBLUP)和已经观测364 个基因型的表型观测值(包含2 个亲本和362 个杂交F1代)对502 个基因型进行预测育种值,为杨树遗传育种工作奠定基础。
1 材料与方法
1.1 试验材料和设计
美洲黑杨丹红杨(Populus deltoides‘Danhong’)具有速生和干形通直等优良特性[21-22]。青杨派小叶杨优树通辽1 号杨(Populus simonii‘Tongliao1’)具有抗旱、抗冻和抗病虫害等特点,但是生长缓慢[23-24]。以丹红杨为母本,通辽1 号杨为父本的F1群体种植于中国林业科学研究院试验田,包括2 个亲本和500 个杂交F1代。于2020年4 月采集亲本及杂交子代1 年生枝条进行扦插繁殖,5 月选择生长一致的杨树幼苗移栽大田。田间试验采用随机区组设计,设施氮肥处理(与对照相比定义为高氮条件)和对照为不施氮肥处理(与处理组相比定义为低氮条件)2 个区组,种植株行距为30 cm × 50 cm。6 月、7 月和8 月在高氮处理区每株追施尿素(CON2H4,含氮量46.0%)4 g。干旱季节和雨后需要正常灌溉和除草。试验设计了两个处理条件,3 次生物学重复,364 个基因型(包括2 个父母和362 个F1代),每次重复3 株幼苗,共计6 552 棵树。
1.2 表型测定
11 月份杨树生长季节结束后进行所有杂交后代表型测定。地径:利用电子卡尺在根基部以上5 cm 处,从垂直的两个方向测定地径;株高:从茎基部5 cm 处测量苗高;茎生物量:茎砍伐后自然风干,称取茎的质量。
两个环境中的F1种群的广义遗传力(H)计算公式如下:
Vg代表遗传方差,Ve代表残差,L代表环境的个数。
1.3 基因型数据
全基因组重测序数据来自于2 个亲本和500 个杂交群体[23]。毛果杨(Populus trichocarpaTorr.& Gray)基因组V3.1 作为参考基因组。对SNP(Single Nucleotide Polymorphism, SNP)位点进行过滤,以确定标记缺失率<10%,次要等位基因频率(MAF)>5%。为了获得独立的SNP 标记,根据LD 值进行过滤,窗口为50 kb,步长为2 个SNP,R2阈值为0.7。最终保留总共1 447 341个高质量的SNP 用于GS 分析。通过TASSAL5.0软件对502 基因型的过滤后的重测序数据进行主成分分析(Principal component analysis,PCA),利用R 软件ggplot2 包绘制PCA 的散点分布图。
1.4 全基因组选择统计模型
统计模型是GS 的核心,极大地影响了基因组预测的准确度和效率。利用gBLUP、cBLUP 和sBLUP 模型进行GS 分析。通过 R 软件的GAPIT3包进行3 个模型的基因组选择分析[25]。
1.5 gBLUP 统计模型
gBLUP 模型公式如下:
y是表型向量,X是固定效应系数关联矩阵,b是固定效应,Z是随机加性遗传效应的关联矩阵,g是随机加性遗传效应,e是残差向量。
混合模型方程组如下:
其中,k=σ2e/σ2μ,G阵是基因组关系矩阵,计算模型如下:
其中,m是标记数目,M是个体基因型信息矩阵。Pi是第i 位点的第二等位基因频率。P矩阵是按照每个位点的第二等位基因频率减去0.5 然后乘以2 规则构建。
1.6 cBLUP 和sBLUP 统计模型
cBLUP[15]由相应的全基因组关联分析(Genome-wide association study, GWAS)方法压缩混合线性模型(Compressed mixed linear model,CMLM)开发而来。sBLUP[15]由相应的SUPER GWAS 方法开发而来。
1.7 育种值的准确性
育种值的准确性是基因组预测育种值(GEBV)和真实的育种值(True Breeding Values,TBV或观测值)的相关系数,计算公式为
1.8 数据统计分析
所有数据经过excel、R 语言和SPSS 软件进行统计分析和相关性分析,并且作图。
2 结果与分析
2.1 杂交群体结构分析
前期试验获得了2 个亲本和500 个杂交F1代的全基因组重测序数据[23]。重测序数据经过过滤后,获得了1 447 341 个高质量的SNPs,均匀分布在19 个染色体上(图1)。对500 个杂交群体和2 个父母的SNP 数据进行PCA 分析。结果可以看出丹红杨和通辽1 号杨的差异较大,杂交群体可以分为2 个亚群体。一个亚群偏向于丹红杨,一个亚群偏向于通辽1 号杨(图2)。

图1 SNPs 在19 条染色体上的分布Fig.1 Distribution of SNPs on 19 chromosomes

图2 杂交群体重测序数据的主成分分析Fig.2 PCA analysis of resequencing data of a hybrid population
2.2 生长表型分析
丹红杨的地径在高氮和低氮条件下分别比通辽1 号杨提高2.2 倍和2.9 倍。丹红杨的株高在高氮和低氮条件下分别比通辽1 号杨提高了1.8 倍和2.5 倍。丹红杨的茎生物量在高氮和低氮条件下分别比通辽1 号杨提高了20 倍和33 倍。结果说明丹红杨的生长表型在不同氮环境下显著高于通辽1 号杨。在夏皮罗-威尔克检验中(表1),杂交群体中3 个性状的W 检验值范围为0.96~0.99,接近1,说明表型数据符合正态分布。在高氮和低氮环境下,杂交群体的地径、株高和茎生物量的变异系数在0.13~0.42 之间。氮素利用率相关性状的变异系数表明F1群体具有丰富的遗传变异和选择潜力。地径、株高和茎生物量的遗传力分别为0.72、0.70 和0.70(表1)。

表1 杨树杂交群体表型性状观测值的统计分析Table 1 Statistical analysis of phenotypic traits of poplar hybrid populations
2.3 高氮条件下预测育种值
在502 个基因型中包括具有田间测定表型值的364 个基因型和没有测得表型的138 个基因型。利用cBLUP、gBLUP、sBLUP 模型对杂交群体在高氮条件下的地径、株高和茎生物量进行了全基因组预测育种值(图3)。结果表明cBLUP 模型对地径、株高和茎生物量的预测的准确率分别为0.139、0.012、0.001。gBLUP 模型对地径、株高和茎生物量的预测的准确率分别为0.990、0.987、0.990。sBLUP 模型对地径、株高和茎生物量的预测的准确率分别为0.544、0.803、0.829。结果说明gBLUP 预测结果最准确接近于1,而cBLUP 预测结果的准确性最低。
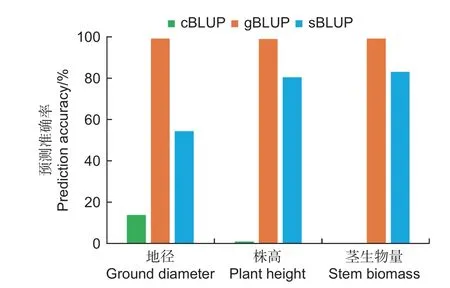
图3 不同模型计算高氮环境下表型性状育种值的预测准确率比较分析Fig.3 Comparative analysis of prediction accuracy of phenotypic traits breeding value under high nitrogen environment calculated by different models
364 个基因型的观测值TBV 和cBLUP、gBLUP、sBLUP 计算的地径的均值分别为17.91、17.94、18.28、18.08;株高的均值分别为292.28、293.75、297.28、293.68;茎生物量的均值分别为144.61、144.61、144.61、144.61(表2)。结果说明3 个模型计算的育种值的均值和观测值的均值差异较小。观测值TBV 和cBLUP、gBLUP、sBLUP 计算的地径的方差分别为2.96、0.42、2.90、1.76;株高方差分别为69.89、23.05、59.80、40.59;茎生物量的方差分别为58.45、19.49、58.45、42.89(表2)。通过方差的比较分析,可以看出cBLUP 模型计算的方差值远小于观测值的方差值。

表2 高氮环境下观测值和育种值的统计分析Table 2 Statistical analysis of observed value and breeding value under a high nitrogen environment
2.4 低氮条件下预测育种值
群体试验在单一环境下进行,受环境因素影响的表型数据不稳定,在不同的环境下鉴定表型性状的育种值更具有稳定性。图4 所示,cBLUP 模型对低氮条件下的地径、株高和茎生物量的预测的准确率分别为0.108、0.052、0.055;gBLUP 模型预测的准确率分别为0.985、0.991、0.990;sBLUP 模型准确率分别为0.574、0.590、0.777。

图4 不同模型计算低氮环境下表型性状育种值的预测准确率比较分析Fig.4 Comparative analysis of prediction accuracy of phenotypic traits breeding value under low nitrogen environment calculated by different models
364 个基因型观测值TBV 和cBLUP、gBLUP、sBLUP 计算地径的均值分别为16.23、16.24、15.81、15.98 ; 株高的均值分别为277.54、277.68、273.78、275.49;茎生物量的均值为109.01、109.01、109.01、109.01。结果说明低氮条件下地径、株高和茎生物量的育种值和观测值的均值比较分析发现差异较小(表3)。观测值TBV 和cBLUP、gBLUP、sBLUP 计算的地径的育种值的方差分别为3.31、0.35、1.92、2.14;株高的方差分别为48.32、2.50、22.32、29.42;茎生物量的方差分别为46.59、2.55、46.59、35.00(表3)。通过方差的比较分析可以看出cBLUP模型计算的方差值较小,gBLUP 和sBLUP 计算的育种值的方差与观测值的方差较为接近。
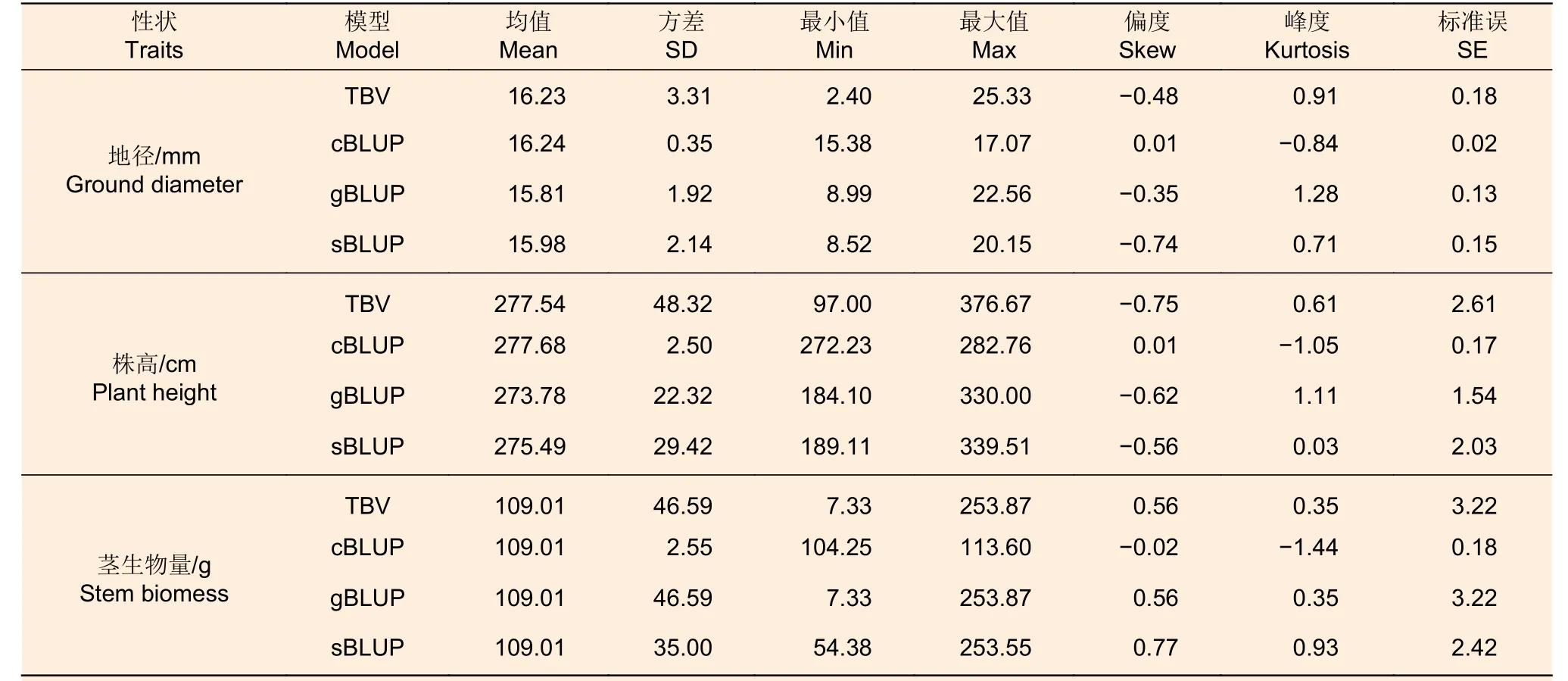
表3 低氮环境下观测值和育种值的统计分析Table 3 Statistical analysis of observed value and breeding value under a low nitrogen environment
2.5 优良基因型早期选择
因为gBULP 预测的育种值准确率较高,因此利用了杂交群体502 个基因型的茎生物量的育种值进行了评价和筛选。根据高氮和低氮条件下茎生物量的均值把F1代群体划分为4 种类型(图5)。低氮高效型(Ⅰ区域):本区域F1代的茎生物量在低氮条件下高于均值,在高氮条件下低于均值。双高效型(Ⅱ区域):本区域F1代的茎生物量在低氮和高氮条件下均高于平均值。高氮高效型(Ⅳ区域):本区域F1代的茎生物量在低氮条件下低于均值,在高氮条件下高于均值。低氮低效型(Ⅲ区域):本区域F1代的茎生物量在低氮和高氮条件下均低于平均值。双高效型(Ⅱ区域)包括191 个基因型,均值(茎生物量在低氮条件和高氮条件下的均值)的前20 名包括16-1-16、16-1-194、13-116、13-73、13-481、13-268、13-286、13-566、13-173、13-578、16-1-65、13-242、16-1-189、13-40、13-608、16-1-170、16-1-22、13-237、13-272、13-335。双高效型中前20 名符合育种目标的要求,可作为优良遗传材料保存,进一步研究。

图5 利用茎生物量划分杂交群体氮利用效率类型Fig.5 The types of nitrogen use efficiency of hybrid populations were divided by stem biomass.
3 讨论
在林业生产中,为了避免与粮食生产竞争肥沃的土地,经常在贫瘠的土地上植树造林,而且人工林种植和管理较少施肥。因此杨树人工林的生产力取决于基因型的正确选择,需要研究高生物量生产的杨树品种,以便在边际土壤上种植。本研究利用丹红杨、通辽1 号杨和杂交群体在田间进行了施氮肥试验,调查了364 个基因型在低氮和高氮条件下的地径、株高和茎生物量。丹红杨的茎生物量在高氮和低氮条件下分别比通辽1 号杨提高了20 倍和33 倍。结果说明丹红杨的生长表型在不同氮环境下显著高于通辽1 号杨,具有优良的生长表型性状。田间试验更加贴合实际的木材生产情况,不同的氮肥处理条件下的生长表型性状的调查,可以帮助我们选择优良的高氮利用、耐低氮和高生物量生产的基因型,具有指导实际生产的意义。
基因组选择方法被迅速应用于动物育种[26]和植物育种的研究中[27]。基因组选择研究对多年生树木具有重要的应用价值,因为通过使用基因组标记来预测个体的遗传价值,可以在幼苗阶段选择个体,显著缩短选育周期,例如在林业树木中松树(Pinus pinasterAit.)[28]、桉树(Eucalyptusspp.)[29]、油棕(Elaeis guineensisJacq.)[30]。高通量测序技术的发展显著降低了分子标记的成本,覆盖全基因组的高密度分子标记使得复杂性状的基因组选择技术迅速发展。本研究中我们利用全基因组重测序数据,获得了1 447 341 个SNPs 位点,覆盖了整个基因组的遗传信息,保证了后续的基因组选择的需求。GS 利用覆盖全基因组的高密度SNP 标记,结合表型记录或系谱记录对个体育种值进行估计,其假定这些标记中至少有一个标记与所有控制性状的QTL(Quantitative trait locus)处于连锁不平衡状态,这样使得每个QTL 的效应都可以通过SNP 得到反映,将所有标记效应值累加,获得基因组估计育种值[31]。木本植物的选育大多基于田间表型选择,但是田间试验工作量大且繁琐和世代时间长,无法对大量杂交群体展开表型调查。本研究利用364 个基因型的表型观测值和3 个全基因组选择模型,对502 个基因型(包括已知表型和未知表型的所有个体)进行育种值预测。对杨树杂交群体的地径、株高和茎生物量的观测值和3 个GS 模型计算的育种值的均值和方差进行了分析。群体育种值的均值差异较小,说明整体预测较差异较小;群体育种值的方差差异较大,说明个体预测3 个模型差异较大。基因组预测研究结果可以帮助我们预测只有基因型数据没有观测表型值的杨树基因型个体,减少了田间测试的工作量和成本,提高了育种效率。对cBLUP、gBLUP、sBLUP 三种预测模型的准确性结果进行了比较分析。gBLUP 对生长表型性状预测结果最准确接近于1 。sBLUP 预测结果的准确性范围是0.5~0.9。cBLUP 预测结果的准确性小于0.2。研究结果表明gBLUP 模型预测的结果较为准确,cBLUP 预测的结果最差。基因组最佳线性无偏预测(gBLUP)在计算速度上具有优势,而且在对极端复杂性状的预测精度上较高,因次适合大范围应用到林木的选育工作中。
我国杨树优良基因型资源的收集、筛选和鉴定工作做得相对较少,这是因为品种的选育需要耗费大量的人力与物力。优良的种质资源是通过大量种质资源筛选出来的,需要科学的评价方法,通过育种值进行评价筛选工作更加稳定和可靠,具有大范围推广的应用价值。由于gBLUP 计算的育种值较为准确,因此本研究选择了gBLUP 计算的502 个基因型的育种值进行了后续的评价和筛选工作。杨树是以收获木材产量为主,因此本研究通过高氮和低氮条件下的茎生物量把F1代群体划分为4 种类型,包括双高效型、高氮高效型、低氮高效型和低氮低效型。其中双高效型属于高生物量生产的类型,前20 名可以作为优良基因型的备选,如16-1-16、16-1-194、13-116、13-73、13-481、13-268、13-286、13-566、13-173、13-578、16-1-65、13-242、16-1-189、13-40、13-608、16-1-170、16-1-22、13-237、13-272、13-335。育种值的预测和筛选帮助我们实现了早期选择,基因组选择的研究结果具有指导实际生产的意义。全基因组选择的育种应用虽然仍有一些瓶颈,但它必然是智能育种时代非常重要的一项技术,也是未来育种一个重要的方向,它将极大影响未来林木育种的方式和进程。
4 结论
丹红杨和通辽1 号杨的生长表型性状差异显著,杂交群体的生长表型性状具有丰富的遗传变异。基因组选择结果表明gBLUP 模型预测的结果较为准确,cBLUP 预测的结果最差。筛选出高生物量生产的优良基因型16-1-16、16-1-194、13-116、13-73 、13-481 、13-268 、13-286 、13-566、13-173、13-578、16-1-65、13-242、16-1-189、13-40、13-608、16-1-170、16-1-22、13-237、13-272、13-335。全基因组选择帮助杨树育种工作完成了早期选择,减少了表型测定成本,缩短了育种周期。
