基于匹配语义感知的单板缺陷图像修复研究
2024-01-19葛奕麟,孙丽萍,王頔
葛奕麟,孙丽萍, 王頔






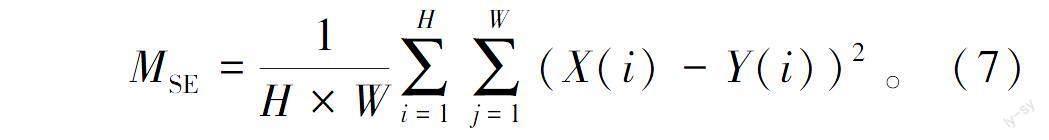





摘要:单板的质量决定单板类人造板的使用价值,单板上的缺陷处理成为木材加工中的重要环节。为处理单板的缺陷,提高木材的利用率,提出一种基于匹配语义感知的单板缺陷图像修复方法。首先使用匹配语义感知模块获取远距离的特征,提升模型的精度;然后使用双卷积模块,捕获多尺度上下文信息,并在整个网络中使用区域归一化,避免均值和方差偏移。使用峰值信噪比(Peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity index,SSIM)为评价指标。研究结果表明,改进后方法的PSNR达到28.48,SSIM达到0.91,与全局和局部判别器网络(Globally and Locally Consistent Image Completion,GL)相比,PSNR和SSIM分别提升1.03%和0.05%。研究结果表明该方法可取得结构、纹理一致的修复效果,为单板缺陷修复提供指导性意见。
关键词:图像修复;深度学习;单板缺陷;匹配语义感知;区域归一化
中图分类号:S781.5; TP391.4文献标识码:A文章编号:1006-8023(2024)01-0098-08
Image Inpainting Research of Veneer Defect Based on Match Attention
GE Yilin1, SUN Liping1*, WANG Di2
(1.College of Computer and Control Engineering, Northeast Forestry University, Harbin 150040, China; 2.College of Petroleum Engineering, Harbin Institute of Petroleum, Harbin 150028, China)
Abstract:The quality of veneer determines the grade of veneer wood-based panels and the treatment of defects on veneer becomes an important part of wood processing. In order to deal with veneer defects and improve wood utilization, an image inpainting method of venerr defect based on match attention is proposed. The method proposes a match attention module to acquire features at a distance to enhance the accuracy of the model and uses a double convolution module that captures multi-scale contextual information. Then region normalization is used throughout the network to avoid mean and variance bias. Peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) are used as evaluation indicators. The results show that the PSNR of the improved method reaches 28.48, and the SSIM reaches 0.91. Compared to the globally and locally consistent image completion (GL) method, the PSNR and SSIM are improved by 1.03% and 0.05%, respectively. This method can achieve consistent effect in structure and texture, which providing guidance for the inpainting of the veneer defects.
Keywords:Image inpainting; deep learning; veneer defect; match attention; region normalization
0引言
由于人們长期对森林资源无节制的开采利用,生态环境受到严重破坏,大力发展人造板产业会促进林业发展,不会过多破坏林业资源[1]。单板类人造板是以胶合板、细木工板等为基材,以单板为饰面材料的人造板材,因其价格低廉并给人以真实感,因而被广泛地应用于家具行业[2]。此外,消费者更喜欢购买无缺陷、纹理自然的家具。因此,木材加工企业为了去除缺陷提升人造板的等级,使用单板修补机对单板缺陷区域进行挖补,再用颜色、纹理相近的补片进行拼接[3-4],但是单板缺陷周围的纹理复杂,这种方法不能保证单板表面视觉的一致性和美观性,导致修复后的单板不能作为人造板的贴面,因此如何去缺陷使单板周围纹理一致是目前急需解决的问题。用图像修复的方法对单板缺陷区域进行修复,使修复后的区域接近单板自然状态,对于提高单板的利用率和单板类人造板的产品质量具有重要意义。
单板表面的缺陷是指能够降低单板商品价值的特征总称,只要能降低单板的使用价值,影响其质量,均称之为单板的缺陷。在单板加工行业中,活节、死节和虫眼是最常见的缺陷,活节(图1(a))的木质没有被破坏,因此与周围相邻的颜色变化较小,但活节改变了纤维的走向,在视觉上影响了单板的美感;死节(图1(b))的木质已经基本或全部改变,因此降低了木材的力学性能;虫眼(图1(c))是指昆虫蛀蚀木材产生的孔眼,在各类木材中都有可能出现,虫眼缺陷既破坏了单板的完整性,又会引起木材腐朽。综上所述,本研究主要考虑活节、死节和虫眼3方面的缺陷。
图像修复是计算机视觉中的经典研究。目前图像修复主要分为传统修复方法和深度学习修复方法,传统图像修复方法可以填充区域较小的结构和修复简单的纹理,并处理边界区域的不连续性和模糊问题,但是这类方法在修复缺陷区域较大、强语义和纹理复杂的图像任务中仍然表现不佳,不能保证生成图像整体的一致性[5]。
近些年,深度学习方法在图像修复技术中取得了巨大的进步,图像修复技术也随着深度学习的快速发展不断取得突破。基于生成对抗网络(Generative adversarial network,GAN)[6]的深度生成方法不断弥补传统图像修复方法的缺陷。GAN通过从大规模数据集学习高维抽象特征,用近似真实的替代内容填充损坏的图像,成为修复领域的主流模型。然而,基于GAN的修复模型仍然有局限性,其修复模型大多存在图像结构信息丢失和生成纹理不真实等问题,通常会导致模糊和几何扭曲的结果。
为解决上述问题,最近的一些研究获取了更多的上下文信息,以生成更好的修复结果,这些研究可以分为2种模式。一类研究表明,利用空洞卷积[7-8]可以使图像在不丢失分辨率的情况下扩大感受野,获得多尺度上下文信息,更好地预测缺失区域的内容。Iizuka等[9]使用空洞卷积来修复人脸图像,Noord等[10]使用空洞卷积来修复自然街景图像,武昭乾[11]引用空洞卷积提高火控故障预测的泛化程度,都取得了不错的效果。另一类研究[12]表明,U-Net网络能够将低级和高级的语义特征相融合,获取更多的语义信息,增加模型的泛化能力。Fang等[13]提出一种基于U-Net的新模型,集成所有尺度的信息,以生成更高质量的图像;刘昱等[14]运用U-Net网络中的跳跃连接,通过对低层卷积信息的再利用,更好地修复大面积破损的人脸图像;邬开俊等[15]在U-Net网络和GAN网络的基础上,加入改进的注意力模块,解决大面积破损修复效果差的问题;Zeng等[16]以U-Net网络为主干结构,将高层特征图上通过注意力机制计算出的受损区域和未受损区域的区域相似度,应用在下一层低层特征图上的特征补全,补全后的特征图继续指导下一层特征图缺失区域的补全。但是仅使用U-Net网络和空洞卷积模块,只能扩大模型的感受野,获取多尺度信息,无法保证模型的精度,从而导致模型修复后的图像模糊。
基于上述研究,提出一种基于匹配语义感知的单板缺陷图像修复方法,该方法采用双卷积网络获取更多的内容信息,并引入了匹配注意力模块,保证生成内容的语义相关性和特征连续性,还在模型中加入区域归一化,提升模型精度。试验结果表明,该方法既能去除单板缺陷又能重建缺失区域的内容,为后续识别出与修复区域颜色、大小和纹理都相近的单板贴补片提供指导。
本研究的具体贡献如下。
1)考虑到卷积神经网络只能获取相邻像素的特征,而对空间距离较远的特征神经网络无法获取,因此提出匹配语义感知模块提升模型的精度。
2)为防止模型梯度爆炸,引入区域归一化,将像素划分为不同的区域,解决单板修复精度低的问题。
3)与一些先进的图像修复方法相比,改进后的方法获得了更高质量的结果,并生成了具有视觉一致性的纹理。
1试验与方法
本研究目的是对单板缺陷区域进行纹理重建,先用无缺陷的单板纹理数据集训练基于GAN网络的图像修复模型,再将缺陷数据集遮盖掩膜后输入到修复模型中,从而获得缺陷区域的内容。因此,数据集分为单板纹理数据集和单板缺陷数据集两部分。
1.1试验数据及环境
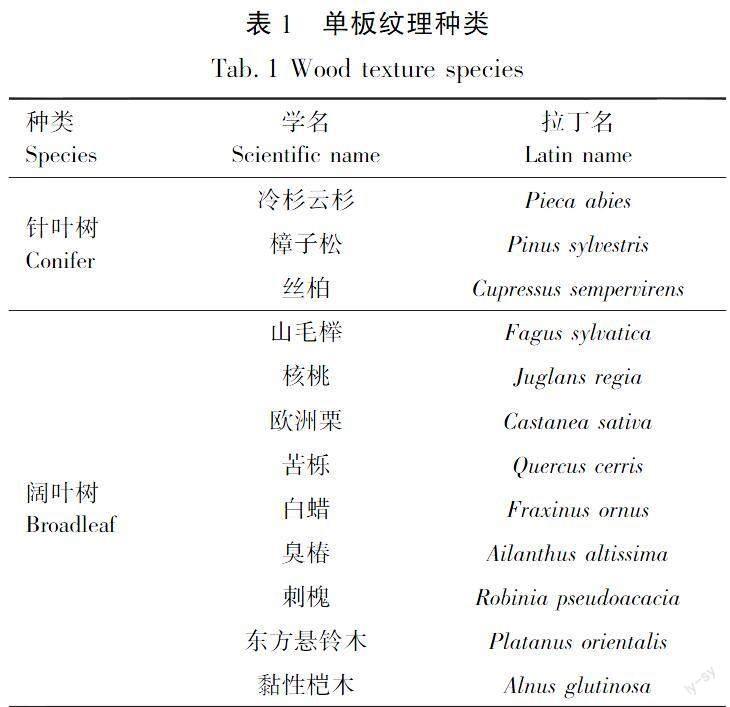
单板是一种天然高聚物,其表面性质十分复杂,受纹理、光泽和颜色等因素的影响,能选取树的种类众多。针对针叶树材和阔叶树材的不同,选取WOOD-AUTH数据集[17]中的12种不同种类的单板作为试验材料,构建单板纹理数据集。其分类见表1。
购入表面带有缺陷的红松、柞木、落叶松和水曲柳样本进行单板缺陷表面图像的采集。单板缺陷数据集使用试验室搭建的图像采集设备进行拍摄,原始图像使用OscarF810CIRF工业相机拍摄单板表面缺陷,当单板在传送带上向前移动时,红外线传感器触发CCD(Charge coupled device)相機的信号,使用LED均光板进行打光,以采集单板缺陷图像。其系统结构示意图如图2所示。本设备共拍摄了2 730张单缺陷图像,其中活节1 000张,死节860张,虫洞870张。
深度学习模型训练集样本数量越大,其训练效果越好,因此在训练过程中采用了数据增强技术。本研究共使用了8种图像增强方法,包括翻转(水平翻转、垂直翻转)、裁剪、仿射变换、3种模糊方法之一(高斯模糊、平均模糊和中值模糊)、添加高斯噪声、对比度归一化、局部仿射和弹性变换。对于每张图像,2种翻转方法中只有1种会被使用,其他7种方法将以50%的概率随机使用。此外,所选方法的操作顺序是随机的。图3为部分缺陷图像增强后的结果,第一列为原始图像,其他列为上述混合运算的增强结果。对每张图像增强5次,使原始数据集增大6倍。所有缺陷图像增强完成后,单板纹理数据集总共获得41 354张图像,缺陷数据集总共获得16 380张图像。将数据集分为训练数据集和测试数据集,分别占80%和20%。
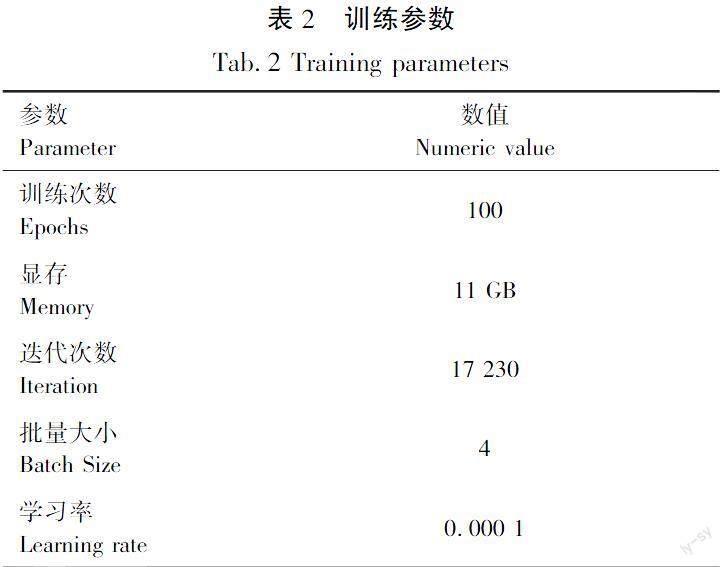
试验模型基于Pytorch[18],在一个电脑配置为GPU:NVIDIA 2080TI上进行训练,使用Adam优化器进行优化,超参数α=0.5和β=0.9。生成器和鉴别器的学习率固定为 10-4,训练参数见表2。
1.2研究方法
目前较为先进的图像修复网络—全局和局部判别器网络(Globally and locally consistent image completion,GL)[9]在修复人脸、建筑物等任务中显示了卓越的效果,但是木材与人脸、建筑物等不同,木材表面的纹理排列方向不同,而且种类较多,因此通过对GL的改进来构建新的修复模型,使该模型在单板缺陷修复领域能取得较好的效果。具体的改进如下。
1.2.1生成器整体设计
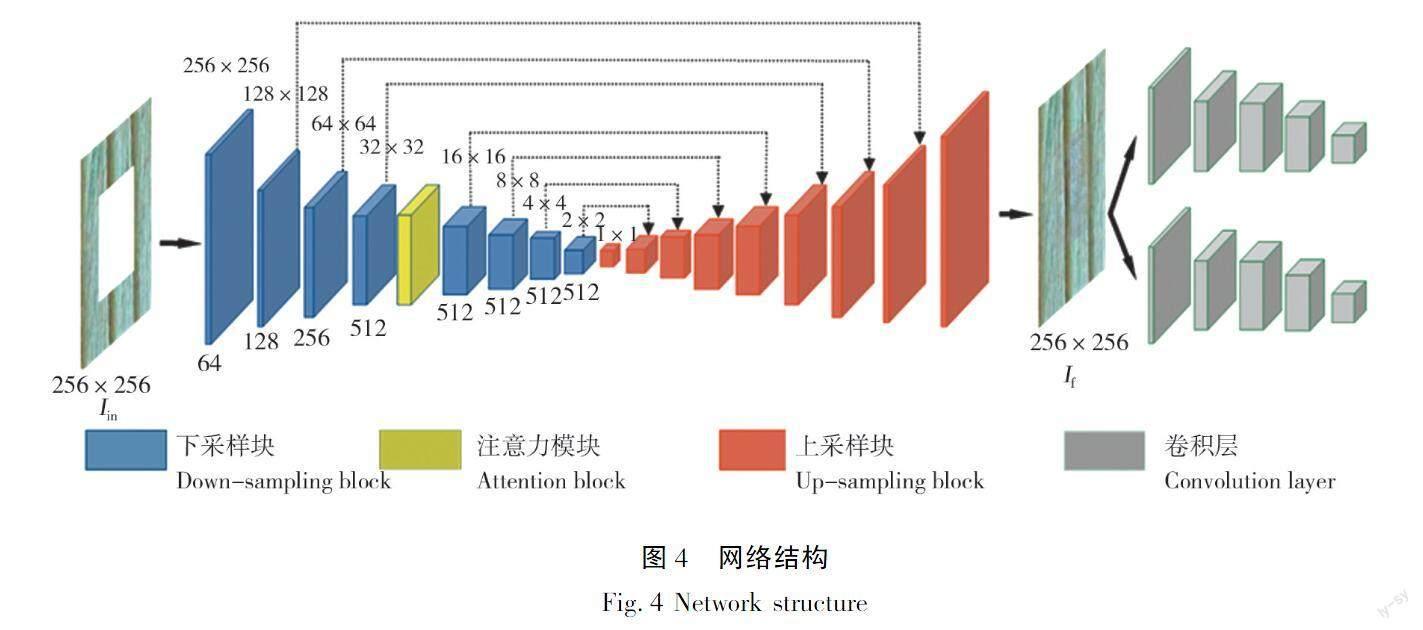
模型的生成器是由编码器组成,整体模型如图4所示,将一张带有孔洞的256×256的单板图片Iin输入到网络模型中,得到最终的图片If,使得修复后的图像If接近真实图像Igt。
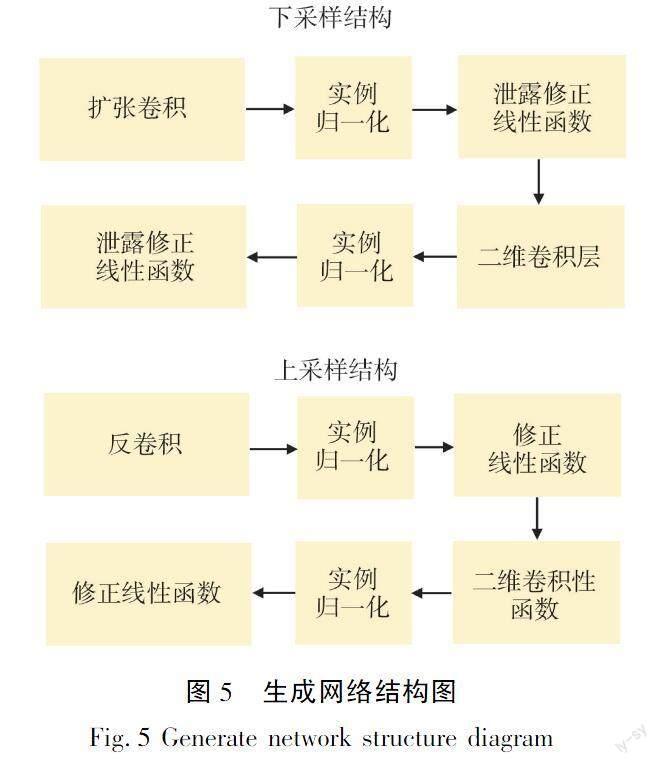
在编码器中,不同于GL模型选择卷积层和池化层进行特征提取,而基于匹配语义感知模型采用卷积层和空洞卷积进行特征提取。因为池化层在增大感受野的同时降低了空间分辨率、损失了部分输入的信息原始,导致细节丢失无法通过上采样进行还原。而与池化层相比,空洞卷积在增大感受野的同时减少了信息的损失。因此,下采样部分使用卷积层和空洞卷积的双卷积模型共同进行特征提取,让每个卷积的输出都包含较大范围的信息。生成的网络展开如图5所示,下采样的每一层都由一个3×3的卷积和一个4×4的空洞卷积组成,在每个卷积层都采用泄露修正线性函数(Leakg Rectified Linear Unit, Leaky Relu)和前期区域归一化。上采样部分采用了步长为1的3×3转置卷积和stride为2的转置卷积,每个卷积层都采用Relu和后期区域归一化。
1.2.2匹配语义感知模块
GL网络只应用卷积神经网络,使用逐层处理法获取图像特征,因此只能获取相邻像素的特征,而对空间距离较远的特征神经网络无法获取。为了达到更好的修复效果,在模型中设计匹配注意力模块(Match Attention,MA),提高修复任务处理的视觉一致性。MA模块首先从已知区域选取3×3的像素块,并将其重塑为卷积核,再对图片的未知区域(r)进行卷积,将未知区域的像素和已知区域的像素进行相似度计算,选取相似度最高的补块,并将其移至相应的未知区域。匹配语义感知模块如图6所示。
1.2.3区域归一化
不同于其他的任务,图像修复任务分为缺失区域和完整区域,若对2个区域同时归一化,容易导致均值和方差偏移,因此本研究应用区域归一化(Region normalization,RN)[19]方法对图像修复任务进行归一化。根据掩膜将像素划分为不同的区域,并计算各个区域的均值和标准差。
区域归一化分为前期的区域归一化(RN-B)和后期的区域归一化(RN-L)。RN-B通常用于编码器以解决较大的未缺失区域造成的严重平均值和方差变化。然而,经过多次的卷积,未缺失和缺失区域将融合在一起,如果仍然使用RN-B,这种方法有效性变差。因此,将RN-L用于解码器中,这不仅可以检测缺失区域还能够促进缺失区域的重构。
1.2.4损失函数
损失函数能够判断模型的预测值和真实值之间的差距,在深度学习模型中起到决定性作用,损失函数越好,模型的拟合程度越好,性能越好。不同的损失函数能够解决不同类型的问题。本研究在GAN损失的基础上加入梯度惩罚,在判别器上加强利普希茨(Lipschitz)约束,使用瓦瑟斯坦生成对抗网络(Wasserstein Generative Adversarial Network, WGAN)损失[20]作为损失函数。Wasserstein距离(式中记为W(Pr,Pg))如式(1)所示。
W(Pr,Pg)=1Ksupf L≤K
Euclid Math TwoEA@
x~Prf(x)-
Euclid Math TwoEA@
x~Pgf(x)。 (1)
式中:Pr为真实数据分布;Pg为生成数据分布;sup是最小上界;f是1-Lipschitz函数;K为常数;
Euclid Math TwoEA@
为期望值。
对于每一个可能的联合分布Pr而言,可以从中采样x~Pr得到真实样本x。为了在一个小的空间中訓练参数W,在每次梯度更新时使用了一个约束。该约束不能太大或太小,太大会使得训练时间过长,太小会导致梯度弥散。因此需满足以下约束条件,如式(2)所示。
f(x1)-f(x2)≤x1-x2。(2)
判别器网络fw为了使得损失L尽可能大,将不是非线性激活层的最后一层和参数W组成在一起,如式(3)所示。
L=
Euclid Math TwoEA@
x~Prfw(x)-
Euclid Math TwoEA@
x~Pgfw(x)。(3)
L此时接近于生成分布和真实分布之间的Wasserstein距离,生成器可以通过最小化L来近似Wasserstein距离,由此生成器的损失函数如式(4)所示。
L=-
Euclid Math TwoEA@
x~Pgfw(x)。(4)
全局判别器和局部判别器使用WGAN对抗性损失进行训练,对抗损失表示如式(5)所示。
Ladversarial=
Euclid Math TwoEA@
x~Pgfw(x)-
Euclid Math TwoEA@
x~Prfw(x)。(5)
判别器由全局损失Ladversarial-global和局部损失Ladversarial-local共同组成的,因此则判别器的损失函数如式(6)所示。
LD=Ladversarial-global+Ladversarial-local。(6)
2结果与分析
为证明模型在图像修复任务中的效果,将本研究的方法与上下文编码器(Context Encoder,CE)[21]和全局和局部判别器网络(Globally and Locally Consistent Image Completion,GL)[9]方法进行比较。
2.1生成性结果分析
将提出的方法与CE、GL方法在单板纹理数据集上进行比较,验证方法的修复效果。其修复后的视觉效果如图7所示,图7中从左至右分别为带有中心掩膜的输入图像,CE、GL对比方法的修复结果、本方法的修复结果以及原图像。从图7可以看出,CE方法的修复结果呈现出模糊的结果,GL方法使用了全局和局部判别器,在视觉上比CE有所改善,但是依然存在纹理扭曲和模糊现象。本研究方法利用了匹配语义感知模块和RN,并对细节进行了处理,从视觉上能够看出本研究方法生成的图像明显优于CE方法和GL方法,改进后模型的纹理更加清晰,结构更加连续。
2.2有效性结果分析
图像的修复效果不能只从视觉效果上评价修复后图像的质量,还要凭借评价指标判断图像质量的好坏。为了对比规则缺陷的模型修复效果,使用20%~30%的中心矩形掩膜遮住单板纹理图像并进行修复试验,再将3种方法最后6个训练模型得到的测试结果值相加取平均数,最后使用3个评价指标对方法进行有效性分析。本研究采用3种评价指标对生成的图像与原始图像进行比对,从而判断修复后图像的质量。
均方误差(Mean Square Error,MSE,式中记为MSE)如式(7)所示,H、W分别为图像的高度和宽度,X为原图,Y为修复后的图像。
MSE=1H×W∑Hi=1∑Wj=1(X(i)-Y(i))2 。(7)
峰值信噪比(Peak Signal to Noise Ratio,PSNR,式中记为PSNR)是最常用的一种图像质量评价指标,定义如式(8)所示,式中n为图像中每个像素的色彩深度。
PSNR=10log102n-12MSE。(8)
结构相似性(Structural Similarity,SSIM,式中记为SSIM),能够从3个不同方面度量2张图片的相似性,从而反映图像的质量。SSIM认为亮度(Luminance,式中记为L)、对比度(Contrast,式中记为C)、结构(Structure,式中记为S)3要素能够反映2张图片的差异。SSIM的亮度、对比度、结构分别如式(9)—式(11)所示。
L(X,Y)=2μXμY+c1μ2X+μ2Y+c1。(9)
C(X,Y)=2σXσY+c2σ2X+σ2Y+c2。(10)
S(X,Y)=σXY+c3σXσY+c3。(11)
c1=(k1L)2,c2=(k2L)2,c3=c22。(12)
式中:uX、uY分别为图像X和Y的均值;σX、σY分别为图像X和Y的标准差;σ2X、σ2Y分别表示图像X和Y的方差;σXY代表图像X和Y协方差;c1、c2、c3為常数;取k1=0.01, k2=0.03;L为像素值的动态范围,一般都为255。则SSIM如式(13)所示。
SSIM(X,Y)=(2μx μy+c1)(2σXY+c2)(μ2x+μ2y+c1)(σ2X+σ2Y+c2) 。(13)
PSNR和SSIM的值越高则证明修复效果越好,MSE的值越低证明失真越小。3种方法对中心掩膜修复后图像的有效性分析结果见表3。
从表3可以看出,本研究方法修复结果在3个评级指标中都是最好的,因此本研究模型对于图像修复任务具有有效性。
2.3消融试验
本研究提出的想法能够考虑到图像中的语义特征,使生成图像的纹理保持一致性和连续性,其主要原因在于:首先引入MA模块提取已知区域的特征,从而恢复缺失区域的细节信息;其次使用RN,避免了均值和方差偏移,有效提升模型的精度。为了验证MA模块和RN对图像修复任务的有效性,利用消融试验评估两者的效果。试验结果如图8所示,图8(a)是带有缺陷的输入图像,图8(b)是没有使用MA层方法的生成结果,虽然方法使用了RN,但是图像中的纹理信息和结构特征依然丢失。图8(c)是没有使用RN的结果,尽管方法使用匹配语义感知模块从已知背景中选取特征信息的内容以生成缺失的内容,但是依然缺少深度信息特征的语义,由图8可以看出,只使用MA模块生成的图片比只使用RN生成的图片效果好。图8(d)是同时使用MA模块和RN生成的结果,可以由图8(d)看出,其修复的结果能基本保证纹理的一致性和结构的连贯性。上述结果证明通过MA模块能够从已知区域借用精确特征,减少纹理和结构信息的丢失,RN能够避免发生偏移,提高修复网络质量。
2.4缺陷区域生成试验
纹理是单板的重要特征,上述的试验证明本研究方法能够重建单板的纹理。通过试验来评估修复模型对缺陷区域重建的效果,其修复效果如图9所示,修复后的图片基本能够去除节子和虫眼等缺陷,可以为后续进一步对缺陷区域补绘填充作技术指导。
3结论
本研究提出了基于匹配语义感知模块的单板缺陷图像修复方法,针对GL方法生成图像效果不理想等问题,利用双卷积进行特征提取,还在模型中加入注意力模块重新构建了网络模型,并在整个网络使用RN,改善图像的修复结果,最后针对训练不稳定和模式崩塌的问题,结合了 Wasserstein的损失函数进一步提升网络的性能。通过对比CE方法和GL方法,本研究方法不仅在视觉效果上表现得最好,并且通过评价指标证明方法的有效性,试验证明,改进后模型的PSNR值达到28.48,SSIM值达到0.91,与GL方法相比,提升了1.03%和0.05%。因此以该模型修复的图像作为单板缺陷修复模板,能够提高单板和单板类人造板的利用率,减少资源浪费。
【參 考 文 献】
[1]苏立琢.林业生态环境保护下的林业经济发展探讨[J].山西农经,2022(2):118-120.
SU L Z. Exploring the development of forestry economy under forestry ecological protection[J]. Shanxi Agricultural Economy, 2022(2):118-120.
[2]秦莉,于雪斐.人造板产品质量分析与建议[J].中国人造板,2022,29(2):5.
QIN L,YU X F. Analysis and suggestion on quality of wood-based panel products[J]. China Wood-Based Panels, 2022, 29(2):5.
[3]石煜.面向单板表面缺陷实时检测的运动模糊图像复原方法[D].北京:北京林业大学,2020.
SHI Y. Image restoration for motion blur in real-time detection system of veneer sheets surface defects[D]. Beijing: Beijing Forestry University, 2020.
[4]王阿川.基于变分PDE的单板缺陷图像检测及修补关键技术研究[D].哈尔滨:东北林业大学,2011.
WANG A C. Research on the key technology of veneer defect image detection and patching based on variational PDE[D]. Harbin: Northeast Forestry University, 2011.
[5]李明亮.家具木坯料表面缺陷自动检测修补关键技术及设备研究[D].赣州:江西理工大学,2019.
LI M L. Research on key technologies and equipment for automatic detection and repair of surface defects of furniture wood blanks[D]. Ganzhou: Jiangxi University of Science and Technology, 2019.
[6]GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Advances in Neural Information Processing Systems, 2014, 27:2672-2680.
[7]YU F, KOLTUN V, FUNKHOUSER T. Dilated residual networks[C]// In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017:636-644.
[8]YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[C]//Proceeding of International Conference on Learning Respresentations, 2016.
[9]IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics, 2017, 36(4): 1-14.
[10]NOORD N V, POSTMA E. Light-weight pixel context encoders for image inpainting[J]. 2018. arXiv:1801.05585[cs.CV]
[11]武昭乾.基于卷积神经网络的火控计算机故障预测研究[D].沈阳:沈阳工业大学,2022.
WU Z Q. Research on failure prediction of fire control computer based on convolutional neural network[D]. Shengyang: Shenyang University of Technology, 2022.
[12]RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 18th International Conference on Medical Image Computing and Computer-assisted Intervention. Munich, 2015, 234-241.
[13]FANG Y C, LI Y F, TU X K. Face completion with hybrid dilated convolution[J]. Signal Processing: Image Communication, 2020, 80:115664.
[14]劉昱,刘厚泉.基于对抗训练和卷积神经网络的面部图像修复[J].计算机工程与应用,2019,55(2):110-115,136.
LIU Y, LIU H Q. Facial image restoration based on adversarial training and convolutional neural networks[J]. Computer Engineering and Applications, 2019, 55(2):110-115, 136.
[15]邬开俊,单宏全,梅源,等.基于注意力和卷积特征重排的图像修复[J].计算机应用研究2023,40(2):617-622.
WU K J, SHAN H Q, MEI Y, et al. Image restoration based on attention and convolution feature rearrangement[J]. Application Research of Computers, 2023, 40(2):617-622.
[16]ZENG Y, FU J, CHAO H, et al. Learning pyramid-context encoder network for high-quality image inpainting[J]. 2019, arXiv:1904.07475[cs.CV].
[17]BARMPOUTIS P, DIMITROPOULOS K, BARBOUTIS I, et al. Wood species recognition through multidimensional texture analysis[J]. Computers and Electronics in Agriculture, 2018, 144:241-248.
[18]PASZKE A, GROSS S, MASSA F, et al. PyTorch: An imperative style, high-performance deep learning library[J]. 2019, arXiv:1912.01703[cs.LG].
[19]YU T, GUO Z Y, JIN X, et al. Region normalization for image inpainting[C]//Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January-1 February 2019; 34:2733-12740.
[20]ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein generative adversarial networks[C]//Proceedings of the 34th International Conference on Machine Learning, PMLR, 2017, 70:214-223.
[21]PATHAK D, KRAHENBUHL P, DONAHUE J,et al. Context encoders: Feature learning by inpainting[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27-30 June, 2016:2536-2544.
