改进的多项式曲线拟合轨迹预测算法
2024-01-16黄万炎杜万和杨淑珍
黄万炎, 杜万和,2,*, 杨淑珍,2, 俞 涛
(1. 上海大学机电工程与自动化学院, 上海 200444;2. 上海第二工业大学智能制造与控制工程学院, 上海 201209)
0 引 言
目前,想要快速、准确地预测无规律、复杂多变的运动目标轨迹,仍然具有很大的挑战;然而这样的轨迹预测,在很多领域都有需要。在自动驾驶领域,为了避免发生事故,需要对路上车辆、行人的运动轨迹进行实时预测,然而车辆的轨迹充满不确定性,行人的轨迹主观性很强,比较随意,使得预测比较困难[1-2]。在围捕运动目标时,为了更快速、准确地围捕运动目标,需要对运动目标进行实时预测,然而围捕方无法准确获知运动目标的运动参数,而且运动目标具有较强的逃逸能力,使得围捕方很难完成围捕任务[3-4]。在涂胶应用中,目标轮廓弯曲复杂。激光传感器在获取目标轮廓时,目标轮廓容易偏离扫描区域,因此需要对目标轮廓进行轨迹预测,使得传感器更加准确地获取轮廓数据。对于无规律、复杂多变的轨迹预测,设计合适的算法主要面临两个难点:其一,轨迹不断变化,动态更新,很难实时、快速地预测运动目标的轨迹,因此对算法的实时性要求较高;其二,轨迹无规律,弯弯曲曲,复杂多变,很难准确地预测运动目标的轨迹,因此对预测算法的准确性要求较高。
常用的动态轨迹预测算法主要有3类[5-6]。第1类是基于曲线拟合的轨迹预测算法,所选取的曲线通常为多项式曲线。传统的多项式曲线拟合轨迹预测算法(polynomial curve fitting trajectory prediction algorithm, PCFTPA)具有原理简单、计算量小、预测速度快等特点,在对实时性要求较高的场合,具有很好的优势。胡俊等[7]在研究围捕机器人对移动目标的快速围捕时,考虑到移动目标运动轨迹复杂多变,机器人需要先通过预测算法快速地预判移动目标未来一小部分的运动轨迹,然后才能根据预测的轨迹对运动目标实施围捕这一情况,选择曲线拟合轨迹预测算法,该算法很好地满足了快速预测的需求。张强等[8]在嵌入式态势显示设备中,针对运动目标轨迹更新延迟的问题,提出基于曲线拟合的轨迹预测算法。该算法只需将靠近预测点的部分采样点进行拟合,无需存储大量的历史数据,使得算法计算量小、所需存储空间较小,很好地解决了嵌入式态势显示设备对运动目标轨迹更新延迟的问题。李世杰等[9]需要对高超声速再入滑翔目标进行轨迹预测。考虑到运动目标具有较强的机动能力,其轨迹是复杂多变的,并且预测方无法准确获知运动目标实际机动模式的信息,作者采用最小二乘曲线拟合算法进行预测。Cao等[10]充分利用多项式曲线拟合的快速性优势,实时预测动态目标在未来一小段时间内的运动轨迹,进而实现对动态目标的围捕。可见,PCFTPA应用于轨迹预测的优势非常明显,即计算量小、预测速度快。然而传统的多项式曲线拟合主要是通过输入样本点求出多项式的系数,这样一条理论曲线对于真实、复杂多变的轨迹并不能很好地逼近,导致多项式曲线拟合对于复杂多变的轨迹预测无法取得较好的预测效果。因此,很多学者尝试研究第2类、第3类轨迹预测算法。第2类是基于自适应滤波器的轨迹预测算法,其优点是对采样点的异常情况适应性强[11-14]。为了更准确地预测飞机爬升的轨迹,Thipphavong等[15]提出了一种基于观测数据动态调整模型参数的自适应轨迹预测算法。Han等[16]为了解决具有动态时间尺度的浮萍飘移轨迹预测问题,设计了一种自适应参数变时间尺度卡尔曼滤波器,可精确地预估浮萍的轨迹。第3类是基于神经网络的动态轨迹预测算法[17-21],该算法对于非线性系统具有很好的映射能力。Zhang等[22]为了准确地预测乒乓球在未来时刻的位置,提出基于多层神经网络的轨迹预测算法。Akabane等[23]为了使移动机器人更准确地跟随人,提出了基于长短期记忆(long short-term memory, LSTM)网络的轨迹预测算法。Yang等[24]为了更合理地预测行人的轨迹,提出了一种基于图注意和卷积LSTM的模型;该模型具有较高的预测精度,生成的轨迹更符合社会理性和物理约束。虽然第2类、第3类算法对于复杂多变的轨迹预测准确率较高,但实时性较差,因此本文选择第1类算法进行研究。第1类轨迹预测算法研究的不足为:① 没有对预测误差较大的轨迹部位进行准确识别并加以处理;② 未考虑采样点间隔不一对轨迹预测的负面影响;原始点数据采集时,由于采集速度不均,导致点与点之间的间隔大小不一以及轨迹变化的连续性受影响,对轨迹预测的结果有负面影响;③ 忽略了采样点之间时序上及空间上的关系。数据采集是有先后顺序的,而且相邻两个采样点变化并不会很大,因此相邻两次预测的误差较接近。
因此,本文在PCFTPA基础上,提出一种改进的PCFTPA(improved PCFTPA, IPCFTPA)。改进之处为:① 通常预测误差较大的部位,轨迹的曲率、挠率值也较大。本文通过曲率、挠率阈值确定算法(curvature and torsion thresholds determination algorithm, CTTDA)获得曲率、挠率阈值,建立曲率、挠率及误差的对应关系,从而将可能导致预测误差较大的轨迹部位识别出来并加以处理;② 多项式曲线拟合轨迹预测受轨迹不规则程度的影响,另外采样点之间间隔不一,因此本文提出插值滚动预测算法(interpolation-rolling prediction algorithm, IRPA)。通过样条曲线插值,得到采样间隔较小且较均匀的点,然后截取末了一小段轨迹进行预测,使得所需预测的轨迹更加规则,采样点也更加均匀。在这些点的基础上,得到少于预测目标点数、较准确的预测点,接着将这些预测点当做待拟合点再次进行预测,如此循环,直到完成预测任务;③ 通过双误差预测值更新算法(double errors predictive value update algorithm, DEPVUA)建立采样点之间时序上及空间上的关系。该算法不仅将未更新时的预测值误差进行了考虑,还将单误差预测值更新时的误差也进行了考虑,进而建立双误差预测值更新机制,实现对预测值的纠正。
1 多项式曲线拟合轨迹预测模型
1.1 问题描述及轨迹表示
图1(a)中,L为运动目标的实际轨迹,L′为L的未来一小段的预测轨迹。由于目标不断运动,轨迹L的形状也不断变化,因此需要根据历史轨迹实时、动态地预测L′。

图1 轨迹离散化示意图Fig.1 Schematic diagram of trajectory discretization
在三维空间中,运动目标的轨迹是一条连续的曲线,然而在获取轨迹时,只能通过一定频率的采样得到离散的轨迹点。根据Nyquist-Shannon采样定理[25]可知,连续的信号可用一定时间间隔的采样点完整地表示,当采样频率大于原始信号最大频率的2倍时,可根据采样点完整地恢复原始信号。因此,对于运动目标轨迹预测的研究,可转化为对轨迹离散点的研究(见图1(b))。通过对轨迹离散点的预测,得到所需要的预测轨迹L′。
轨迹L可表示为
L≈{Pi(xi,yi,zi),i=1,2,…,N}
(1)
假设这些离散的点均在空间参数曲线上
r(t)={x(t),y(t),z(t)},t∈[a,b]
(2)
其中,t是曲线的参数。那么,曲线r(t)的空间特征可以反映轨迹的空间特征。因此,可以通过对曲线r(t)的研究,研究轨迹L的预测。
本文选择确定的空间参数曲线r(t)表示空间中运动目标的轨迹,并对r(t)作如下限定:
(1) 曲线为连续光滑的曲线,即r(t)具有连续的一阶导数,排除曲线包含比较“尖锐”的点;
(2) 曲线为正则曲线,即在曲线的每一点处,r′(t)≠0,排除了切向量变化不连续的特殊点,比如带尖点的曲线;
(3) 对r(t)的采样频率远大于r(t)最大频率的2倍。
1.2 多项式曲线拟合算法原理
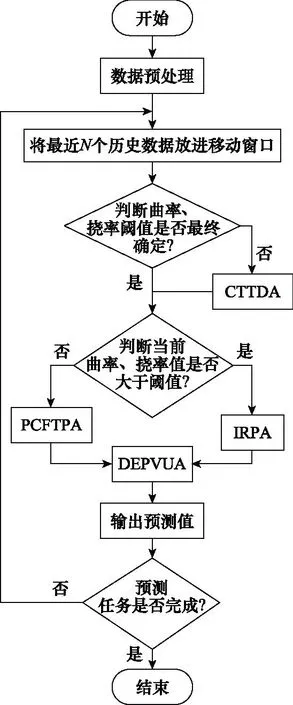
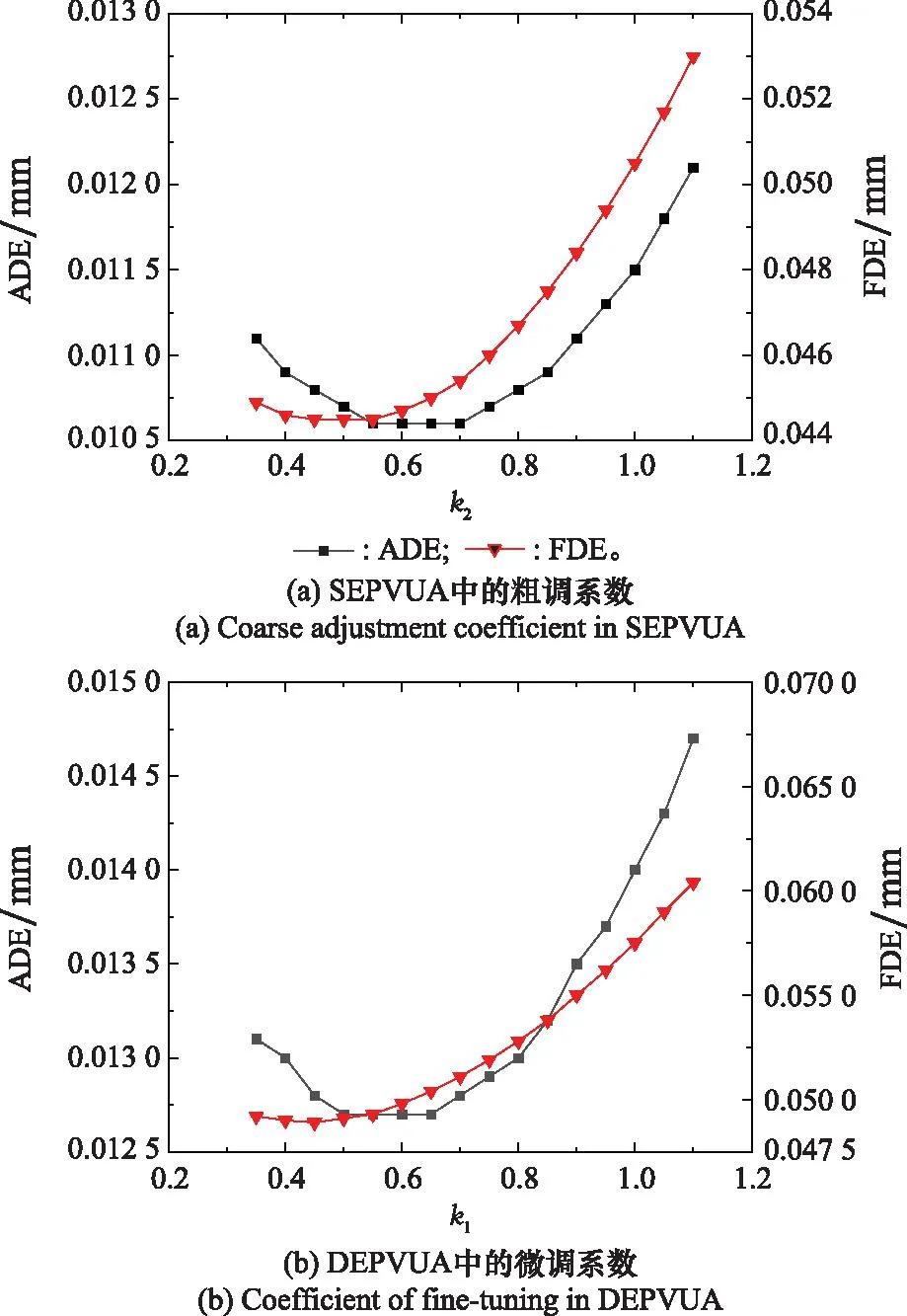
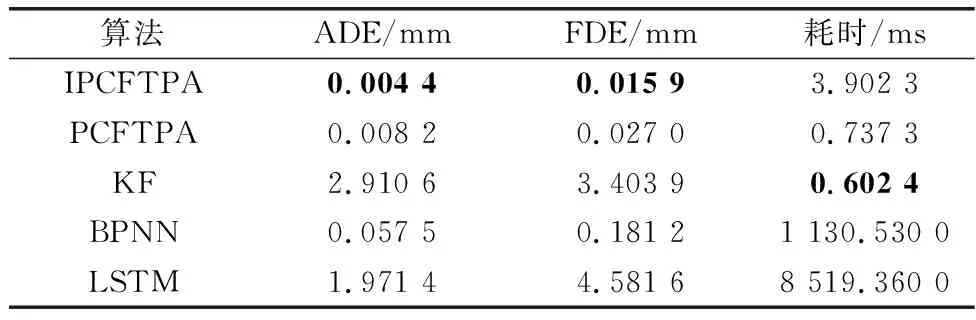
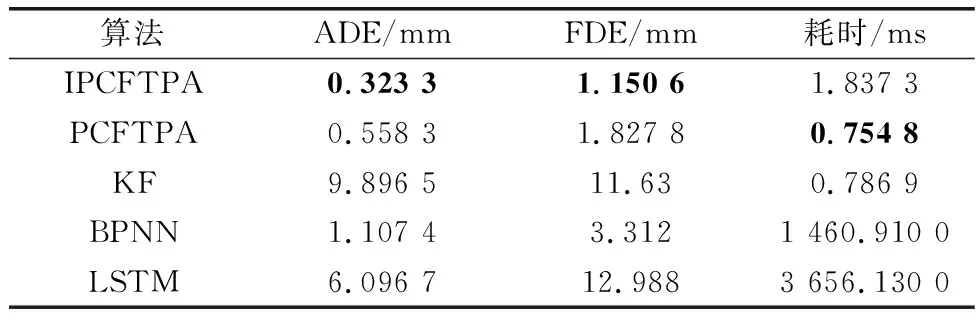
对于空间中的轨迹,可在投影面中分别进行曲线拟合。设投影面上的采样点为{(xi,yi),i=1,2,…,N},用k(k y=akxk+ak-1xk-1+…+a1x+a0 (3) 根据采样点,通过最小二乘法,便可计算出多项式的系数。 对于无规律、复杂多变的轨迹,未来一小段的轨迹只与较近部分的历史轨迹有关,而与较远的历史轨迹没有关系[8]。因此,在轨迹预测时,只需对较近的轨迹点进行拟合。轨迹预测模型示意图如图2所示,预测过程如下: 图2 轨迹预测模型示意图Fig.2 Schematic diagram of the trajectory prediction model 步骤 1选取N个历史轨迹点,作为待拟合点(滑动窗口S内); 步骤 2根据待拟合点进行最小二乘拟合,得到一条与轨迹相近的空间曲线; 步骤 3通过一定的方式外推得到未来的一小段轨迹L′上的轨迹点; 步骤 4当获取新的采样点时,滑动窗口S往前一步,回到步骤2继续进行预测。 图3更直观地展示了轨迹预测模型的动态性。 图3 轨迹动态预测模型示意图Fig.3 Schematic diagram of trajectory dynamic prediction model 平均位移误差(average displacement error,ADE)和最终位移误差(final displacement error,FDE)通常用来评估轨迹预测算法的准确性[21,24,26]。ADE为平均距离误差,对每一个预测点与对应点之间的距离求平均值。其表达式为 (4) FDE为最后一个预测点的距离误差,主要体现最后一个预测点的偏离程度。其表达式为 (5) 空间曲线的特征可以用曲率和挠率来反映,因此可充分利用曲率、挠率对曲线的不同部位进行表征[27-29]。曲率的几何意义为曲线的切向量对弧长的旋转速度。曲线在某一点的弯曲程度越大,切向量对于弧长的旋转速度就越大,即曲率也会越大。因此,某一点的曲率可以反映曲线在该点的弯曲程度。挠率的绝对值是曲线的副法向量对于弧长的旋转速度。曲线在某一点的扭转程度越大,副法向量对于弧长的旋转速度就越大,因此挠率可以反映空间中曲线在某一点处的扭转程度。 对于空间参数曲线r(t),其在t处的曲率为 (6) r(t)在t处的挠率为 (7) 在轨迹预测时,预测误差与曲率、挠率值一般具有如下的关系:当预测误差较大时,曲率或挠率值也较大,即曲线弯曲程度较严重的部分或扭曲程度较严重的部分预测准确率较低;反之亦然。因此,可通过确定曲率、挠率阈值,识别轨迹预测误差较大的部分。CTTDA算法的流程如下。 算法 1 CTTDA输入 动态更新的待拟合点集P输出 阈值Kmax1. set errorMax; ∥用于确定局部误差最大值 2. for each prediction3. ∥K为待拟合点的曲率或挠率4. K=calculate K(P); 5. K_mean=mean(K); ∥计算K的平均值6. P'=curvefitPredict(P); ∥PCFTPA7. errorMean=getMeanError(P, P'); 8. ∥找到误差局部最大值9. if errorMean>errorMax and other conditions10. errorMax=errorMean;11. end if12. ∥确定曲率或挠率阈值13. if errorMean>errorMax and other conditions14. Kmax=K_mean;15. end if16. end for17. output Kmax (1) 设置errorMax初始值(第1行); (2) 实时计算待拟合点集的曲率或挠率平均值(第4行、第5行); (3) 根据待拟合点预测未来的轨迹点,并计算误差(第6行、第7行); (4) 确定局部误差最大值(第9~11行); (5) 当误差值超过errorMax,将当前的曲率或挠率平均值作为曲率、挠率的阈值Kmax(第15~17行); (6) 对errorMax可以先赋较小值,并保证先确定误差局部最大值errorMax,然后才执行Kmax的赋值。另外,局部误差最大值和曲率、挠率阈值均只确定一次。 2.2.1 轨迹预测与采样间隔的关系 缩小采样间隔可以提高轨迹预测准确率。如图4所示,当输入的待拟合点缩小采样间隔时,轨迹采样点数增多,滑动窗口内的轨迹变短,所代表的轨迹段更有规律,此时相同阶数的拟合函数更容易逼近该曲线段,预测结果也会更准确。 图4 缩小采样间隔的轨迹预测示意图Fig.4 Trajectory prediction schematic diagram with the reduced sampling interval 2.2.2 算法具体步骤 IRPA算法充分利用了采样间隔对轨迹预测的影响,通过对采样点进行插值,得到更密集的点,然后选择靠近预测位置的部分点进行预测。由于所预测的点准确率很高,因此可将其近似当做真实的点,选取这些点继续进行预测,就可以滚动地预测所需的轨迹。 算法 2 IRPA输入 待拟合点集P输出 预测点P'(最终预测M个点)1. set predictNumber=K; ∥单次预测点数2. newP=interp1(P); ∥插值得到较密的点集3. N=M/K; ∥M为K的倍数,N为滚动次数4. for i=1 to N5. ∥取最后N个点作为待拟合点6. P_=newP(end-N:end); 7. tempP=curvefitPredict(P_); ∥PCFTPA8. ∥将预测点放进待拟合点,进行滚动预测9. newP=append(tempP); 10. ∥保存每一轮的预测结果11. P'=append(tempP);12. end for13. output P' 具体步骤如下: (1) 确定单次预测点数K(第1行); (2) 通过插值,缩小采样间隔(第2行); (3) 对插值后的点集newP,取最后N个点作为待拟合点P_(第6行); (4) 对待拟合点进行拟合,得到K个预测点tempP(第7行); (5) 将所预测的点tempP添加到newP点集中,构成新的待拟合点集(第9行); (6) 循环预测N次,输出预测点P′(第13行)。 利用预测值之间的误差对预测值进行更新是很有必要的[30]。图5是相邻两次预测中的x、y、z方向的误差对比;两次预测分别预测12个点。由图5可知,相邻两次预测的误差有相同的规律,即随着预测点数的增多,误差值越来越大,并且在相同预测点位置误差大小相近。这是由于相邻两次预测时,滑动窗口内的轨迹段整体相似,用相同算法预测得到的结果也会相近。 图5 相邻两个预测点的误差比较Fig.5 Comparison of error of two adjacent prediction points 基于相邻两次预测误差的规律,可得到如下的预测值更新策略。设 (8) 则 (9) (10) 图6 单步预测中双误差预测值更新示意图Fig.6 Double error prediction value update schematic diagram in single-step prediction 对于k(k>1)步预测,由于第i次预测时,第i-1次预测中的k个误差值只有第一个误差可利用,因此errori-1只能取近似组合值。如图7所示,为errori-1的取值过程(假设k取3)。 图7 多步预测第i-1次误差取值过程(k=3)Fig.7 Process of error value extraction in step i-1 in multi-step prediction (k=3) 具体算法流程如下: 算法 3 DEPVUA输入 预测点P'i,上一次预测误差errori-1输出 更新的预测点newDoubleP'i1. for i=1,2,…2. ∥单误差预测值更新3. if i>k4. newP'i=P'i - k1×errori-1;5. newSingleErrori=newSingleP'i-Pi;6. end if7. if i>k+18. ∥双误差预测值更新9. newDoubleP'i=10. P'i-k1×errori-1-k2×newSingleErrori-1; 11. end if12. end for13. outputnewDoubleP'i 相邻两次预测滑动窗口内的数据变化并不是很大,预测值之间也不会差别太大,因此可以限制预测值之间的偏差在一定的范围。设 (11) (12) 式中:k1、k2为偏差的缩放系数,满足0 本文所设计IPCFTPA算法的流程如图8所示。 图8 IPCFTPA流程图Fig.8 Flowchart of IPCFTPA (1) 数据预处理阶段,对于不光滑的轨迹数据需进行平滑处理,比如采用3次B样条曲线拟合; (2) 曲率、挠率阈值可设置较大的初始值,使得算法一开始先按PCFTPA进行预测; (3) 一旦曲率、挠率阈值最终确定,CTTDA不再执行; (4) 当当前曲率、挠率值小于阈值时,说明该位置误差在可接受的范围,选择PCFTPA进行预测;当曲率、挠率值大于阈值时,说明该位置误差可能较大,选择IRPA进行预测; (5) 对于PCFTPA及IRPA的预测值,均需通过DEPVUA进行更新,并将更新过的预测值作为最终的预测值。 为充分验证本文算法的可行性和有效性,选择3组仿真数据及3组真实数据进行详细的对比分析。本文将所提算法与PCFTPA、基于卡尔曼滤波的轨迹预测算法(Kalman filtering trajectory prediction algorithm,KF)、基于反向卷积神经网络的轨迹预测算法(back propagation neural network trajectory prediction algorithm,BPNN)、LSTM作对比。另外,本文研究的算法针对空间中复杂多变、未知的轨迹,因此LSTM和BPNN没有提前训练模型,而是根据部分历史轨迹点实时训练并预测。本次实验所使用的仿真软件为Matlab R2019b。 (1) 表1为3类仿真数据的参数方程及其描述,图9为仿真数据的三维图。 表1 3类仿真数据及其描述Table 1 Three types of simulation data and their descriptions 图9 仿真数据三维图Fig.9 3D diagram of simulation data (2) 3组真实数据分别从3组不同的三维轮廓数据源提取,数据特征类似,处理方式也类似。本文对真实数据1作详细说明。真实数据1如图10所示。该数据是通过三维激光传感器扫描得到目标轮廓的点云,然后提取目标轮廓的中心线而得。轨迹数据点为370个。 图10 真实三维空间轨迹Fig.10 Real 3D trajectory 由于真实数据存在一系列问题,包括局部数据不光滑、部分轨迹点跳跃性比较大等,因此在数据预处理阶段需对其进行样条拟合,使轨迹相对光滑[31-33]。预处理后的轨迹如图11所示,数据点为370个。 图11 预处理后的轨迹Fig.11 Preprocessed trajectory 以仿真数据1为例,探究IPCFTPA中重要参数(多项式拟合系数、插值间隙、粗调系数和微调系数)对轨迹预测的影响。 图12为不同拟合阶数对轨迹预测的情况。由图12可知,拟合阶数并不是越大越好。拟合阶数过大,ADE、FDE、单次预测耗时均增大。综合拟合阶数对3个因变量的影响,对于仿真数据1,本文选择拟合阶数为3。 图12 不同拟合阶数的轨迹预测情况Fig.12 Trajectory prediction with different fitting orders 图13为粗调系数及微调系数对轨迹预测的影响。其中,图13(a)为SEPVUA中粗调系数对轨迹预测结果的影响,图13(b)为DEPVUA中微调系数对轨迹预测的影响。 图13 调节系数对轨迹预测的影响Fig.13 Influence of adjustment coefficient on trajectory prediction 由图13可知,k1取0.5、k2取0.55时对轨迹预测效果最好。 图14用仿真数据1对比了PCFTPA、IRPA、SEPVUA及DEPVUA的ADE情况。其中,相对于PCFTPA,IRPA的ADE降低了40.3%,SEPVUA的ADE降低了51.71%,DEPVUA的ADE降低了59.7%,验证了DEPVUA的可行性和有效性。后续IPCFTPA均采用IRPA+DEPVUA。 图14 仿真数据1不同算法不同位置的ADE情况Fig.14 ADE situation of different algorithms at different positions in simulation data 1 图15用仿真数据1探究不同方法、不同预测步长对轨迹预测的影响。 图15 仿真数据1用不同方法在不同预测步长下的轨迹预测情况Fig.15 Trajectory prediction with different prediction steps by different methods in simulation data 1 图15(a)、图15(b)具有相同的规律:步长不同时,IPCFTPA相较于其他方法,ADE、FDE均最低;随着步长的增大,不同方法ADE、FDE均变大。从耗时上看,BPNN、LSTM由于在预测时还需训练模型,因此耗时都比较长,而PCFTPA、IPCFTPA、KF耗时均比较小。 对于第2组、第3组仿真数据及真实数据1的预测结果如表2、表3、表4所示(选取10个历史轨迹点,预测步长为12,耗时均指单次预测耗时;真实数据2、3不同方法的对比情况与真实数据1类似,预测结果在表5中展示)。 表2 仿真数据2不同方法的预测情况Table 2 Simulation data 2 prediction of different methods 表3 仿真数据3不同预测方法的预测情况Table 3 Simulation data 3 prediction of different methods 表4 真实数据1不同方法预测情况Table 4 Real data 1 prediction of different methods 表5 不同数据IPCFTPA相较于PCFTPA的ADE、FDE降低比例Table 5 ADE and FDE decreasement rate of IPCFTPA of different data compared with PCFTPA % 由表2、表3、表4可知,本文算法的ADE、FDE均小于PCFTPA、KF、BPNN、LSTM。从预测耗时上看,改进的曲线拟合轨迹预测算法相较于BPNN和LSTM具有明显优势,相较于PCFTPA略有增大。 表5统计了不同数据IPCFTPA相较于PCFTPA的ADE、FDE降低比例情况。其中,KADE为ADE降低比例,KFDE为FDE降低比例。 由表5可知,真实数据的ADE、FDE降低比例较仿真数据低,主要是因为真实数据表示的轨迹,虽经过光滑处理,但依然不如仿真数据光滑,并且真实数据有较多的弯曲部分,使得整条轨迹的曲率变化较大。由表5可知,本文算法相较于PCFTPA,对于仿真数据,ADE平均降低了49.38%,FDE平均降低了39.26%。对于真实数据,ADE平均降低了36.15%,FDE平均降低了33.99%,充分说明了本文算法的可行性和有效性。在运动目标轨迹预测中,对于对高实时性、高准确率有较高要求的场合,本文算法具有一定的参考价值。 本文提出基于PCFTPA的算法IPCFTPA。改进之处主要有3点:① 通过CTTDA确定曲率、挠率阈值,并根据该阈值识别预测误差较大的轨迹部位;② 通过IRPA对预测误差较大的部位进行插值滚动预测;③ 通过DEPVUA对预测值进行更新,建立相邻两次预测中时间及空间上的关系,提高预测准确率。实验结果表明,IPCFTPA相较于PCFTPA,ADE平均下降了42.77%,FDE平均下降了36.62%,单次平均预测时间略有增加;与LSTM、BPNN轨迹预测算法相比,IPCFTPA在单次预测耗时上具有非常大的优势;与KF、LSTM、BPNN相比,IPCFTPA预测准确率具有明显的优势。另外,在多项式曲线拟合用于轨迹预测的算法中,多项式系数也呈现出一定的规律。下一步将研究多项式系数的变化规律,进一步提高轨迹预测的准确性,以充分发挥多项式曲线拟合在轨迹预测中的优势。1.3 基于多项式曲线拟合的空间轨迹预测模型


1.4 评价指标


2 改进的曲线拟合轨迹预测算法
2.1 曲率与挠率阈值的确定


2.2 IRPA


2.3 DEPVUA

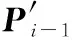




2.4 预测值偏差限制

2.5 算法流程
3 算法验证
3.1 数据描述




3.2 重要参数选取

3.3 对比实验





4 结束语
