基于多核DSP的星载双基FMCW SAR成像算法实现
2024-01-16肖国尧全英汇任爱锋别博文邢孟道
陈 洋, 肖国尧,*, 全英汇, 任爱锋, 别博文, 邢孟道
(1. 西安电子科技大学电子工程学院, 陕西 西安 710071;2. 西安电子科技大学前沿交叉研究院, 陕西 西安 710071)
0 引 言
调频连续波(frequency modulated continuous wave, FMCW)合成孔径雷达(synthetic aperture radar, SAR)结合了FMCW技术和SAR技术,推动了小型化、轻量化、低功率高分辨率成像雷达的诞生,使其易于安装在无人机等小型设备上[1]。与传统的脉冲式SAR相比,FMCW SAR降低了传感器的峰值传输功率,对SAR发射机的要求较低[2]。近年来,FMCW SAR成像研究得到了更多关注,国内外也研制出多款FMCW SAR信号处理系统。
基于传统的SAR成像算法,结合FMCW SAR特征,目前已经提出了一系列FMCW SAR成像算法。文献[3]研究了正弦非线性函数对FMCW SAR系统的影响,提出了相位误差修正算法来检测目标;文献[4]基于压缩感知技术,提出了一种用于恢复FMCW SAR原始数据的稀疏重建方法;文献[5]提出了星载方位中断FMCW SAR信号模型,并利用广义正交匹配追踪算法重构信号;文献[6-7]基于改进的波数域成像算法实现了最优成像;文献[8]提出了一种考虑传感器运动的方法,解决了在发送/接收过程中由连续路径造成影响问题;文献[9-12]基于改进的距离多普勒(range-Doppler, RD)算法实现了FMCW SAR数据聚焦。文献[13]提出了一种改进的逆线性调频Z变换算法来处理距离-方位耦合项;文献[14-16]提出了FMCW SAR稀疏成像方法,可以校正实际机载FMCW SAR数据中的运动误差。
SAR成像的数据量大,对实时性有较高的要求。这种情况下,高性能、灵活的处理SAR信号是目前面临的挑战之一。传统的单核数字信号处理器(digital signal processor, DSP)计算能力有限,难以满足工程应用的要求,FT-M6678是国防科学技术大学研制的八核高性能浮点数字信号处理芯片,具有超高的运算能力和传输性能。目前,已经有许多科研人员利用DSP处理器进行SAR成像算法的实现。文献[17]采用多核DSP设计了聚束SAR成像系统;文献[18-20]基于多核DSP提出了大斜视机载SAR的实时成像处理架构;文献[21]提出了一种混合异构并行加速技术,结合现场可编程门阵列(field programmable gate array, FPGA)和DSP的优点,实现了机载SAR的实时处理。文献[22-23]针对机载前斜视SAR成像的特点,建立了高性能的SAR实时处理系统;文献[24]设计了一种虚拟单节点并行处理方法,采用8个DSP实现SAR成像处理的大容量分布式存储;文献[25]提出了一种基于多核DSP的星载SAR欺骗式干扰实时产生算法优化方法;文献[26-28]基于FMCW SAR提出了一种实时成像的软件体系结构。
目前,面向双基地FMCW SAR成像的研究不断增加,但针对天基平台的研究较少[29]。这是因为卫星运动速度远大于载机飞行速度,在高分辨或超高分辨成像条件下使用传统的FMCW SAR成像算法,会导致成像效果不佳。本文在此背景下进行改进研究,建立起一种适宜星载双基FMCW SAR的频域算法,并选用实验室自主研发的以FT-M6678处理器为主的国产化信号处理平台构建适用于星载双基SAR成像算法的并行处理架构,完成软硬件设计实现。
1 星载双基FMCW SAR成像算法
1.1 回波模型
同航线双基FMCW SAR成像几何模型如图1所示,收发卫星以相同的速度v飞行,沿航线两卫星距离为dx,高度为H。以零时刻星下点为原点建立坐标系。此坐标系中,由星下点指向基线中点和卫星运动的方向分别为z轴和y轴,然后根据二者叉乘确定出x轴。对于任意一个目标p=(xn,yn,zn),收发卫星与它的瞬时斜距记作Rt(ta)和Rr(ta)。
对收发卫星的瞬时斜距进行分析,当采用2阶瞬时斜距表达式时,斜距近似精度满足成像要求。在零点对瞬时斜距Rt(ta)和Rr(ta)进行泰勒展开,并且保留到二次项,得:
(1)
式中:(xT,yT,zT)为参考点的坐标;[x0,t,vx,t,ax,t],[y0,t,vx,t,ax,t],[z0,t,vx,t,ax,t]分别为发射卫星轨迹的三维运动参数;[x0,r,vx,r,ax,r],[y0,r,vx,r,ax,r],[z0,r,vx,r,ax,r]分别为接收卫星轨迹的三维运动参数;[k0,t,k1,t,k2,t]和[k0,r,k1,r,k2,r]分别为发、收平台到参考点的瞬时斜距泰勒展开系数。
FMCW SAR发射连续的线性调频信号,其信号模型为
(2)
式中:tr为快时间;ta为慢时间;Tp为发射信号的脉宽;fc为载波频率;γ为调频斜率。则
可以确定R(tr,ta)处接收的回波为

(3)
式中:td是回波时延。需要注意的是,对传统脉冲SAR而言,发射信号的脉宽较小,在进行近似处理时主要采用“走-停-走”方法,但FMCW SAR是在整个脉冲重复间隔内发射信号,需要考虑雷达平台连续运动引起的距离偏移[30]。为了避免收发平台移位带来的相位误差,提高成像精度,不再对回波时延进行近似,可表示为
(4)
传统的脉冲体制SAR需要构造参考函数去斜,而FMCW通常采用接收时去斜,具体的实现方式为,将回波信号与参考信号共轭相乘。设置参考距离为Rref,其对应的回波信号的共轭设为参考信号,表达式为
(5)
式中:tref=2Rref/c=(k0,t+k0,r)/c;k0,t和k0,r分别为发、收平台到参考点的瞬时斜距泰勒展开系数。若RΔ=R(tr,ta)-Rref,则去斜之后的信号为

(6)
式中:A是复常数,最末的指数项是视频残余相位(residual video phase, RVP),该指标对成像质量会造成明显的影响,因而去斜处理后,应该先将RVP去除,之后只需要对距离维进行相应的傅里叶变换就能实现距离脉压。
1.2 算法实现流程
本文通过分析雷达在信号发射期间运动所带来的距离徙动影响,以及去斜所带来的RVP影响,介绍了一种适于星载双基的FMCW SAR成像算法,具体操作流程如图2所示。

图2 星载双基FMCW SAR成像处理流程Fig.2 Spaceborne bistatic FMCW SAR imaging processing process
步骤 1对距离维回波信号做傅里叶变换,将二维时域信号转换为距离频域信号进行距离脉压。
步骤 2与补偿函数H_rep相乘,在距离维频域去除RVP。
步骤 3与补偿函数H_fdc相乘,在距离维频域进行多普勒中心补偿。
步骤 4在距离多普勒频域和补偿函数Hrcm相乘,实现距离徙动校正。
步骤 5利用匹配滤波函数H_az在二维频域实现方位脉压。
步骤 6将信号转换到方向维时域,得到聚焦后的SAR图像。
2 基于多核DSP的星载双基FMCW SAR成像处理架构
2.1 成像处理平台设计
本文用于实现星载双基FMCW SAR成像算法的硬件平台,是基于全国产化芯片研发的处理平台,在满足百分百国产化要求的基础上,可以实现多种应用场景下的任务需求。其整体架构如图3所示。系统采用虚拟路径交叉连接(virtual path cross-connect, VPX)标准架构,可以划分成5个功能模块,各模块间采用高速数据总线进行信息传输。

图3 全国产化信号处理平台硬件架构Fig.3 Domestically produced signal processing platform hardware architecture
信号采集模块的职责是采集外部模拟信号,实现多通道模数转换功能。采集到的数字信号在经过预处理后,可以通过高速串行接口(serial rapid I/O, SRIO)传输到信号处理模块进行成像算法。
信号回放模块可以按照一定的脉冲重复频率放出回波信号,然后经过SRIO接口传输到信号采集模块进行预处理。
主控模块负责监管每个处理器的工作状态,为其他模块分配任务以控制整个系统的工作流程,并可以通过以太网与上位机进行信息传输,是整个系统的控制核心。
数据交换模块可以通过配置交换芯片的相关参数控制SRIO接口进行数据路由,这极大提高了系统内通信的灵活性。
信号处理模块由FPGA和DSP组成。其中,FPGA作为控制芯片,负责时序控制、数据交互和通信等功能,其内部大量可编程资源和丰富的接口也可以提高系统的扩展性。DSP作为主算法处理器,负责对输入数据进行实时处理,可以完成大规模高精度的数字信号处理。
本文采用国防科大的FT-6678系列8核DSP芯片。此芯片主频最高为1.25 GHz,单核浮点运算能力可达10 GFLOPS,每个核包含32 KB的一级存储器,512 KB的二级存储器,核外集成4 MB的多核共享存储器,外部挂载8 GB扩展存储空间,用来储存成像算法中大量的中间数据。综上所述,FT-M6678在运行速率和存储空间具有较大优势,可以实现大规模实时信号处理。
2.2 成像算法软件设计
2.2.1 多核多任务并行处理设计
SAR成像算法复杂,实时性要求高,需要进行多核并行处理以提高代码的执行效率。鉴于算法各模块之间存在数据依赖现象,本文采用主从方式进行并行运算,0核是主核,负责与外设互联,任务分配和汇总。非0核是从核,从核之间地位相等,不直接进行数据交互与通信,负责子任务执行。DSP工作时,0核先初始化外设,当接收到FPGA通过SRIO总线传输的门铃信息后就开始执行星载双基FMCW SAR成像算法。为了最大限度地使用硬件资源,需要在DSP的8个核内合理分配任务与数据。为避免多核之间不同步导致的数据错误,本文将采用信号量的方式控制8个核同步执行算法的各个模块,图4是通过信号量进行核间通信的流程框图。

图4 核间通信流程Fig.4 Intercore communication flow
2.2.2 算法功能与硬件映射
FPGA将预处理后的数据传输到DSP,可以获得一个2 048×8 192的复数矩阵,其中8 192是距离维点数,2 048是方向维点数,该矩阵按照距离维的顺序连续储存在双倍率同步动态随机存取存储器(double data rate, DDR)内部,作为后续算法模块的输入数据。算法处理过程中使用的一些雷达参数是不变的,这些不变参数可以只进行一次计算,之后采用查表的方式获得相应的数据,避免重复计算的时间消耗。星载双基FMCW SAR成像算法的软件处理流程如图5所示。

图5 星载双基FMCW SAR成像算法软件处理流程Fig.5 Software processing flow of spaceborne bistatic FMCW-SAR imaging algorithm
(1) RVP补偿和多普勒中心补偿
星载双基FMCW SAR成像算法中有四种补偿因子,需要通过雷达参数构造,每个补偿因子的计算结果需要与相应的距离维或方向维快速傅里叶变换(fast Fourier transformation, FFT)、快速傅里叶逆变换(inverse fast Fourier transform, IFFT)结果复乘,才能完成补偿操作,考虑到算法的实时性,本文在进行RVP补偿和多普勒中心补偿时只计算一次补偿因子,并将其结果存储在共享内存(multicore shared memory controller, MCMC)中,从而有效地减少了补偿因子的计算时间,具体的软件处理流程如图6所示。
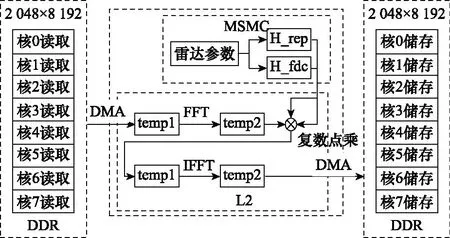
图6 RVP补偿和多普勒中心补偿的软件处理流程Fig.6 Software processing flow of RVP compensation and Doppler center compensation
由图6可知,需要先将数据按照距离维划分成8份到每个内核。因为内核对L2的存取速率高于DDR,所以需要通过直接存储器访问(direct memory access, DMA)将每一组距离维的数据搬移到L2,存放在动态变量temp1中。DMA可以在后台进行批量数据的传输,避免了资源竞争,从而实现DDR与其他读取速度更快的存储器之间的数据交换。随后对temp1进行距离维FFT处理并将结果存放在动态变量temp2中,将temp2与查表所得的RVP补偿函数H_rep和多普勒中心补偿函数H_fdc复数点乘后,再次存放在temp1中,此操作可有效节省空间开销,提升空间利用率。然后对temp1进行距离维IFFT操作并将结果再次放在temp2中,最后基于DMA将temp2搬移到DDR中,按照地址顺序合并8个内核中的数据,方便后续模块执行。
(2) 转置
RVP补偿和多普勒中心补偿处理完成之后,需要对数据进行方向维FFT处理,与仿真实验中提供的抽象机制不同,在DSP中对按照距离维顺序储存的数据进行方向维处理时要进行地址跳变,这会浪费时间,因此在距离徙动校正之前需要进行转置操作。待转置矩阵大小为2 048×8 192,本文采用矩阵分割拼接法进行处理,步骤如下。
步骤 1将待转置矩阵横向均分成8个子矩阵,大小为256×8 192。
步骤 2将每个256×8 192大小的子矩阵纵向均分,使得每个小正方形子矩阵的大小为256×256。
步骤 38个内核同步使用EDMA从源地址按序读取一个256×256的子矩阵缓存在L2,对每个正方形小矩阵进行转置。
步骤 4每个内核将转置后的子矩阵纵向拼接,可以得到大小为8 192×256的矩阵。
步骤 5将8个8 192×256大小的子矩阵横向拼接即可得到转置后的矩阵,大小为8 192×2 048。
其中拼接过程是通过EDMA按顺序写回目的地址实现的。在后续算法流程中还涉及到方向维顺序储存的数据进行距离维处理的转置操作,与上述方法相同,图7是使用矩阵分割拼接法实现转置的示意图。
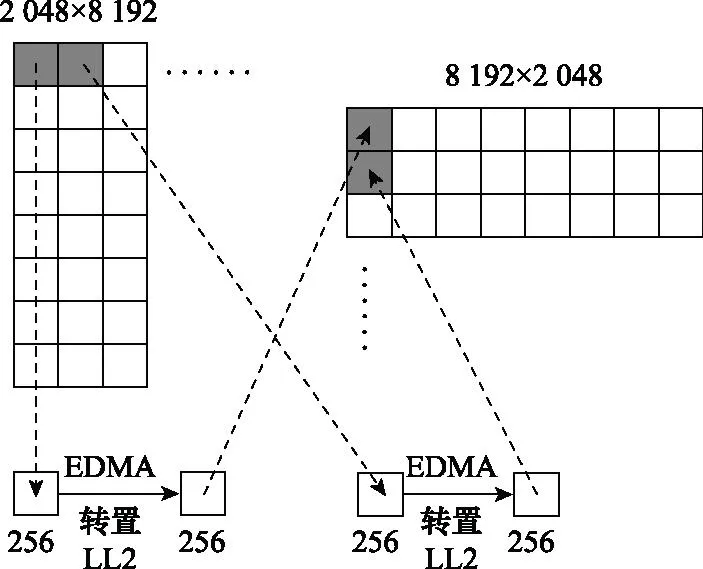
图7 矩阵转置示意图Fig.7 Schematic representation of matrix transpose
(3) 距离徙动校正
距离徙动校正是对回波数据的方向维进行处理,方位向处理模块参照上述补偿操作,将数据按方向维均匀划分成8个区域到所有内核进行并行运算。首先,通过EDMA将每一组方向维的数据搬移到L2的动态变量temp1中,随后对temp1进行方向维FFT处理并将结果存放在动态变量temp2中,将temp2与距离徙动补偿函数H_rcm复数点乘后,将结果再次存放在temp1中。最后通过EDMA将temp1从L2搬移到DDR中。距离徙动校正的软件处理流程如图8所示。
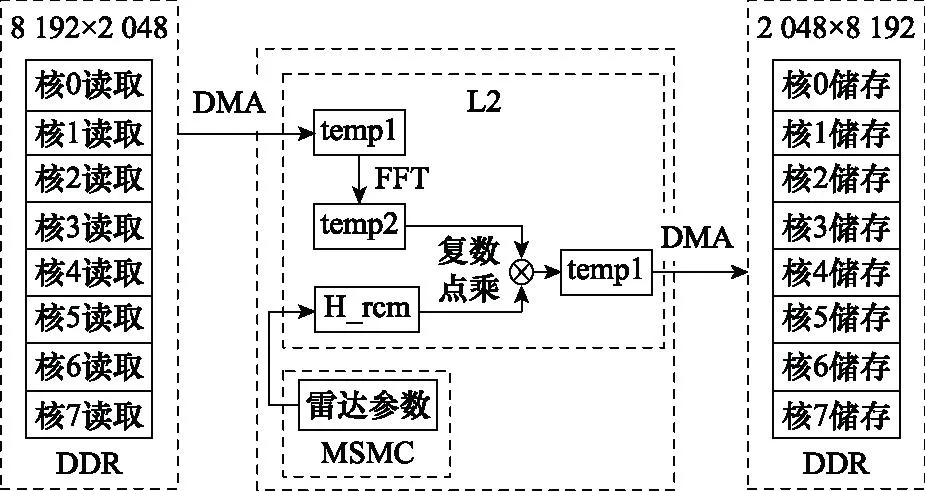
图8 距离徙动校正软件处理流程Fig.8 Software processing flow of range migration correction
(4) 方位脉压
方位脉压与距离徙动校正模块一样都是对信号进行方向维处理,具体实现流程大致相同,不同的是方位脉压模块将动态变量temp1与H_az相点乘后,在方向维进行IFFT操作,即可得到最终结果。其中,H_az是方位匹配滤波函数。方位脉压的软件处理流程如图9所示。

图9 方位脉压软件处理流程Fig.9 Software processing flow of azimuth pulse pressure
需要注意的是,H_rcm和H_az的构造方式与H_rep和H_fdc不同,前者是在算法处理过程中按照方向维一组一组构造的,存放在L2中,后者是在进行算法处理之前构造的,放在共享内存中。这是因为H_rcm和H_az所占的内存空间很大,只能储存在DDR中,但内核对L2的存取速率高于DDR,所以采用在L2中按组构造补偿因子的方法提高算法执行效率。
2.2.3 性能优化
在完成成像算法的软件设计后,为了加快代码的运行效率,提高程序性能,本文采用了以下2种方法进行优化。
(1) 编译器优化
C/C++编译器在应用过程中可进行高级和低级优化,其中前者主要是针对变量、寄存器、函数相关的对象进行优化。后者则是在代码生成器内处理,主要负责调整代码尺寸,优化代码。最简单的激活优化的方法是使用编译程序,在编译器命令行可以指定优化级别控制优化的类型和程度,本文主要采用O3优化对编译器进行处理。
(2) 内联函数与循环展开
在DSP软件实现过程中,为更好地满足代码的可移植性要求,常采用C语言进行编程,然而C语言编译器无法将DSP的处理性能充分发挥。汇编语言可以直接对芯片内部寄存器进行操作提高代码运行效率,但是编程难度大,开发效率低。与线性汇编类似,内联函数可以充分利用DSP芯片大位宽、并行处理的性能,同时又可以像C语言一样实现参数的传递增强代码的可读性与复用性。因此,在底层函数编写过程中,先使用C语言进行功能实现,再通过内联函数优化程序。德州仪器(Texas instruments, TI)提供的库函数可以执行FFT、IFFT和四则运算等处理,基本满足使用需求,但是TI库中并没有提供SAR成像算法中常用的复数点乘、求指等函数,这就需要手动实现对应的运算。本文中,复数点乘、求指、频谱搬移等运算都使用了内联函数进行优化,以复数点乘为例,在运算处理时合并了4次32位乘法和2次32位加法,转换为1次64位乘法运算,减少了时间开销。此外,还在for循环中执行展开处理,即一个循环可以计算多组数据,这可以减少循环次数提升资源利用率。
3 仿真结果与分析
系统测试环境如图10所示,整个系统综合化设计,采用统一的软件进行管理及控制,人机交互友好。采用图形化用户界面工具编写上位机软件可以控制整个系统的启止,还可以通过以太网口与硬件平台进行数据交互,实现回波数据下发与成像结果显示等功能。

图10 系统测试环境示意图Fig.10 Schematic diagram of system test environment
3.1 点目标数据成像结果验证
为了说明星载双基FMCW SAR成像算法工程化实现的正确性,在对算法的性能进行仿真分析时,应用了点目标仿真数据,其主要参数如表1所示。

表1 仿真参数Table 1 Parameter of simulation
图11(a)和图11(b)分别是仿真结果和DSP处理结果。对比分析可发现,DSP处理结果与仿真结果基本一致,为进一步分析成像效果,图12和图13给出了图像中心点的二维剖面对比图。

图11 成像结果对照图Fig.11 Comparison of imaging results

图12 距离向剖面对比图Fig.12 Distance direction profile contrast diagram

图13 方位向剖面对比图Fig.13 Azimuth direction profile contrast diagram
对图像中心点的二维剖面图进行评估分析,可以得到距离维和方向维的峰值旁瓣比(peak side lobe ratio, PSLR)和积分旁瓣比(integrated sidelobe level ratio, ISLR),如表2所示。

表2 点目标性能指标Table 2 Point target performance indicator dB
由表2可知,相对于仿真结果,DSP处理结果中的PSLR和ISLR性能指标有所下降,这是因为仿真计算在处理数据时默认为双精度浮点型,但DSP中采用单精度浮点型数据进行成像处理,这会导致数据精度下降,但最终成像效果差距很小,可以满足实际应用中的成像需求。
3.2 目标场景数据成像结果验证
在经过对点目标仿真数据的处理验证后,需要更接近实际目标场景的回波数据来验证成像算法工程化实现的有效性。但实验所需的回波数据需要基于卫星载体飞行采集,目前尚无法获得实际数据,因此本文主要采用模拟机载数据进行验证,实验所需参数配置如表3所示。
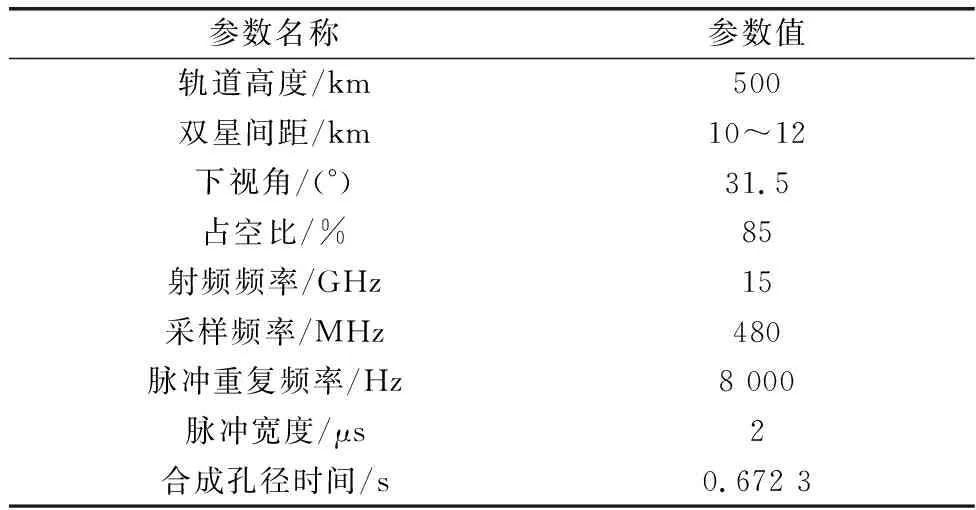
表3 SAR回波模拟参数配置Table 3 SAR echo simulation parameter configuration
将模拟得到的回波数据传输到DSP端进行成像处理,并将最终成像结果发送到上位机显示,图14(a)、图14(b)和图14(c)分别是目标场景图、仿真结果和DSP处理结果。

图14 成像结果对照图Fig.14 Comparison of imaging results
由图14可知,目标场景中的建筑、车辆等信息被成功分辨出来,验证了算法的准确性,此外,基于国产化信号处理机实现的成像算法结果与理论仿真结果是一致的,充分验证了基于FT-M6678多核DSP的成像处理架构的有效性与可靠性。
3.3 实时性分析
本文主要采用了编译器优化和内联函数循环展开的方式对代码进行优化。优化完成后,使用DSP内部计时函数对算法各模块的运算时间进行统计,表4给出了优化前后各模块处理时间。

表4 优化前后各模块耗时统计Table 4 Time statistics of each module before and after optimization s
由表4可知,优化后算法各模块加速效果显著。在输入回波数据大小为8 192×2 048(方位向×距离向)的情况下,该软件处理架构能够在3 s内获得一副8 192×2 048的SAR图像,可以满足实时处理需求。
4 结 论
本文基于FT-M6678多核DSP设计适用于星载双基FMCW SAR成像算法的并行处理方案,并对算法流程中的补偿处理、转置、距离徙动校正和方位脉压模块进行流程设计与资源分配,然后通过编译器优化和内联函数循环展开的方式优化代码,提高程序性能。最后,对比仿真结果与调试结果验证该软件架构可以满足星载FMCW SAR成像的准确性与实时性需求。后续可以将单片FT-M6678处理器拓展至多片协同处理,提高系统成像效率。
