基于 SG 平滑处理的水利算据有效性改进方法
2024-01-08傅媛媛潘跃建陈日剑
李 军,傅媛媛,潘跃建,陈日剑
(浙江省水利水电勘测设计院有限责任公司,浙江 杭州 310002)
0 引言
推进数字孪生流域建设是适应现代信息技术发展形势的必然要求,也是强化流域治理管理的迫切要求。数字孪生流域以物理流域为单元、时空数据为底座、数学模型为核心、水利知识为驱动,对物理流域全要素和水利治理管理活动全过程进行数字化映射、智能化模拟,实现与物理流域同步仿真运行和虚实交互[1-2]。算据、算法、算力建设是数字孪生建设的重要支撑,可为实现具备预报、预警、预演、预案功能的“2+N”业务应用体系提供基础技术保障。但水利数据通常需要经过筛选、清洗、聚合、转换等一系列流程,才能成为有用、有效的算据,才能和水利行业模型进行无缝结合产生价值。因此,算据建设是构建水利数据底板的最重要内容之一,不仅为模型提供元素依据,还为数字孪生流域多维度、多时空尺度的高保真模拟和虚实交互打牢数字赋能的基础。
目前水利数字孪生建设中用到的水利预测方法主要是基于流域水文模型的预测方法,计算机科学的发展,机器学习和神经网络等技术的应用,为水利数字孪生建设提供了新的解决方案并取得较多成果,如 LSTM(长短期记忆)循环神经网络模型[3]和 BP神经网络模型[4]等应用。同时很多学者提出通过雨洪特征的相似度分析查找历史相似洪水进而完成预测,如陈建等[5]通过雨洪多指标相似性计算进行相似洪水的查找,王海潮等[6]将暴雨指标化后进行相似度分析,预测暴雨洪水趋势,欧阳如琳等[7]采用 DTW(动态时间规整)算法计算相似洪水过程。其中基于DTW 的洪水相似度分析使用较为广泛,因为洪水过程不存在严格的时序对应关系,且时序长短可能相差很大,DTW 可以将时序数据进行线性缩放、扭曲操作以达到时序语义上的对齐,从而进行一对多映射的距离计算,非常适合复杂时序数据的弹性度量。
但是无论采用何种模型进行洪水预测,由于算据质量经常受到噪声数据、异常数据和随机误差等影响,都会导致模型计算结果精度较低和稳定性较差,为此需要对算据进行平滑处理,以减少数据变化或波动。常用的平滑处理算法有移动平均滤波、局部加权回归散点平滑、线性回归和 SG 多项式平滑(以下简称 SG)等算法,通过试验可知 SG 算法更能保持数据自身的变化趋势,更能保证模型计算结果的正确性。为此,本研究提出一种基于 SG 平滑处理的水利算据有效性改进方法。
1 DTW和SG 算法介绍
1.1 DTW
在给出算法定义之前,先阐述时序语义相似[8]的概念。假设将经过平滑处理后的某断面洪水过程的时序数据分段,递增段记为 U,下降段记为 D,则生成时序数据的语义模式为 UDUD,如果 2 条曲线的语义模式相同,则这 2 条时序数据曲线是相似的。后续说的洪水相似度本质就是语义相似度。
DTW 用于衡量 2 个长度不同的时序数据的相似度,被广泛应用于语音、手势、视频动作识别,以及数据挖掘和信息检索等模板匹配的场景中。DTW 将未知序列的长度进行伸缩,直到与参考模板的长度一致,在此过程中未知序列会产生扭曲,以便特征量与标准模式对应。DTW 定义[9]如下:假设给定连续时序数据X={(X1,T1),(X2,T2),…,(Xn,Tn)}和Y={(Y1,T1),(Y2,T2),…,(Ym,Tm)},函数d(i,j)=f(Xi,Yj)≥0,为X序列第i点到Y序列第j点的距离函数。通常采用欧式距离公式构建X和Y的距离矩阵B,公式如下:
式中:n,m分别为X和Y序列的长度,i≤n,j≤m。
基于构建的距离矩阵B,找到一条从d(1,1)到d(n,m)的路径,使得路径经过的元素值之和最小,即求扭曲曲线。假设路径为W,W的第k个元素定义为Wk=(i,j)k,表示第k个路径点X与Y的对齐关系,则有:
式中:Wp为路径W的最后 1 个节点;p为路径点的个数,max(m,n)≤p≤m+n-1,max(m,n)为取m和n中的较大值。
由于时序数据的特点,寻找路径需要满足如下限制条件:
1)边界条件。若W1=(1,1),Wp=(m,n),则弯曲路径从W1开始,结束于Wp。若Wk=(a,b),1≤a≤n,1≤b≤m,a和b分别表示Wk节点对应矩阵B横向和纵向的序位。
2)连续条件。假如Wk-1=(a′,b′),下一个路径点Wk=(a,b),则有(a-a′)≤1,(b-b′)≤1,即 2 个时序点在对齐时,不会出现遗漏和跨越对齐情况。
3)单调性条件。假设Wk=(a,b),Wk-1=(a′,b′),则(a-a′)≥0,(b-b′)≥0。
满足约束条件的规整路径有多条,需要最短累计距离的路径公式如下:
式中:p用来对不同长度的规整路径W进行补偿。则累积距离φ(i,j)可表示为
式中:初始条件设置为φ(i,j)=d(X1,Y1),从起始点开始根据式(3)和(4)进行迭代计算,最终得到最小累加值φ(n,m),该累加值即为时序数据X和Y的最短累计距离 DTW(X,Y)。
1.2 SG 算法
预处理常用的平滑方法中[10],SG 算法的最大特点为在滤除噪声的同时可以确保信号的形状、宽度不变,所以被广泛运用于数据平滑除噪的应用场景。
SG 算法[11]是一种卷积滑动窗口的加权平均算法,设滤波窗口的宽度w=2i+1,i∈[1,n],i为半窗宽度,x代表数据点在窗口内的相对位置,x∈[-i,i],数据点所在位置对应的函数值为P(x)。根据窗口内的数据点,构造n阶多项式,拟合得到f(x)表达式[12]:
式中:an0,an1,…,ann表示拟合多项式f(x)的拟合系数。经过最小二乘法拟合,得到残差E的表达式为[13]23
式中:残差E表示拟合曲线与原始数据之间的差异,用来衡量拟合曲线与原始数据的拟合程度。若要f(x)获得最佳的拟合质量,应使残差E趋于最小,假定式(6)中各项系数的导数为εz,z=(1,2,3,…,n),将εz设置为 0,可得如下公式[13]23:
化简式(7)可得式(8)[13]24:
当滑动窗口大小与平滑阶数固定时,将待拟合窗口[P(-i),…,P(0),…,P(i)]内数据带入式(8),可求得多项式系数列表[an0,an1,…,ann]T,其中 T 表示矩阵转置。
在实际程序计算时通过调整窗口大小和幂次等参数,可以平衡平滑效果和保留数据细节的程度。
2 算据有效性论证
改进数据挖掘模型输入算据的质量是数据挖掘的重要步骤[13],数据预处理技术可以有效改进算据质量,从而保证数据挖掘模型的可靠性和高效率。水文数据一般通过人工录入或传感器采集,因此不可避免产生随机误差和噪声数据,如数据采集设备故障、人为因素产生的误差,以及数据传输过程中出现的错误等。为提高 DTW 的可靠性和预测能力,本研究在进行相似度计算前,对洪水过程数据进行平滑处理,并观察平滑前后 DTW 计算结果的变化。随机抽取钱塘江流域开化县水文测站 3 场洪水的过程数据,洪水时间分别为 2004—05—14(场次 1),2004—06—19(场次 2)和 2006—06—27(场次 3),用突跳、缺失和扰动对场次 3 进行异常处理,得到的洪水场次分别为 3.1,3.2,3.3,各场次洪水过程如图 1 所示。
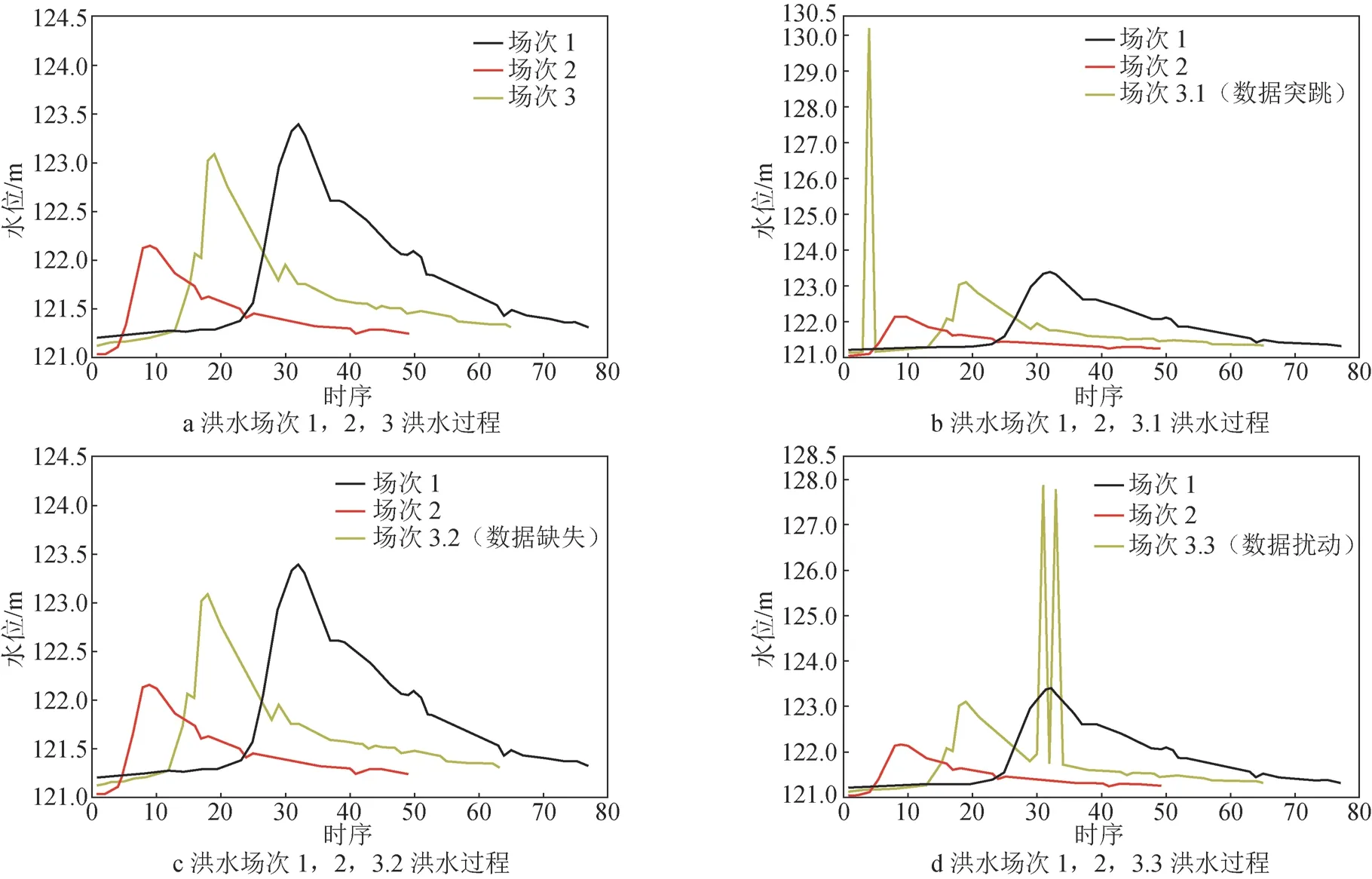
图1 开化县水文测站各洪水场次洪水过程
根据场次 1,2,3 洪水过程数据,以及异常处理后的洪水场次 3.1,3.2,3.3 数据,可得到场次 1 和场次 2,3,3.1,3.2,3.3的DTW 计算结果分别为13.65,3.64,17.55,3.61,21.39。经过比较可知:场次 1 和场次 3 的相似度高于场次 1 和场次 2 的相似度,且差距明显;经过异常处理的洪水场次数据3.1,3.3 和场次 1 的相似度,相对于场次 3 和场次1 相似度发生了较大偏离,DTW 计算结果均大于场次 1 和场次2 的结果 13.65;因为 DTW 计算不需要严格的时序对应,故场次 1 和场次 3.2 的结果几乎不受影响。由此可知,算据质量较差会导致 DTW相似度算法发生偏差甚至失效。此时对各洪水场次数据用 SG 算法进行平滑,平滑前后结果如图 2所示。

图2 开化县水文测站洪水过程平滑处理前后数据变化
图2 中虚线表示平滑后的数据,显然平滑算法对突兀的尖峰进行了有效处理。此时用平滑后的洪水场次数据再进行 DTW 计算,可得到场次 1 和场次 2,3,3.1,3.2,3.3的DTW 计算结果分别为 16.86,5.61,12.76,5.61,11.15。由图 2 可知:经过平滑处理后的场次 1 和场次 3.1,3.2,3.3 的相似度,均高于场次 1和场次 2 的相似度,符合实际情况,由此说明平滑算法较好地保留了算据的趋势特征,同时也保证 DTW 结果的稳定性。
3 试验和分析
本研究试验的主要目的是分析 SG 算法的优越性,以及平滑处理改进算据的有效性。试验首先对开化县水文测站的洪水过程样本数据用移动平均滤波、局部加权回归散点平滑、线性回归和 SG 等算法进行平滑处理,然后用平滑后的洪水过程数据进行 DTW计算,以验证不同平滑算法对于 DTW 算法的有效性。使用各平滑算法处理后的各场次的洪水过程如图 3 所示。
由图 3 可知:通过算法平滑后,原始数据中比较突兀的尖峰得到了很好的处理(尤其是图 d和f ),增加了数据的可视性。用不同算法平滑处理后的洪水场次数据进行 DTW 计算,各场次 DTW 结果如表 1 所示。
表1 中“<>”表示平滑后结果较平滑前有较大偏离,由表 1 可知:移动平均滤波、局部加权回归散点平滑和线性回归等算法均发生 1 项或者 2 项计算结果的偏离,而 SG 算法未导致洪水场次 3.1,3.2 和3.3 的计算结果发生偏离,平滑效果较其他算法好。
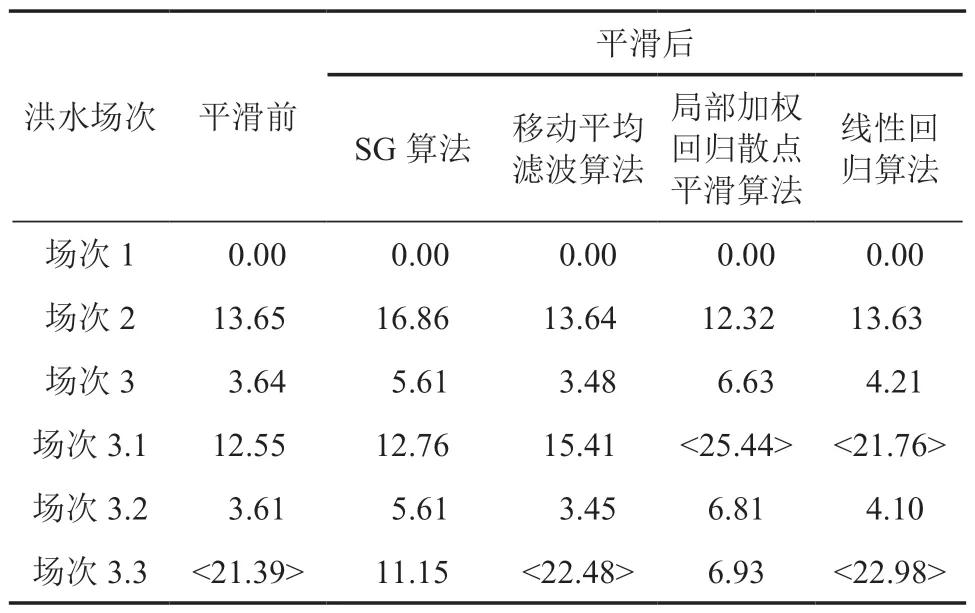
表1 平滑处理后各场次洪水和场次 1的DTW 计算结果

表2 平滑前后用 DTW 求得的相似洪水
为进一步验证 SG 算法能否有效改进算据的有效性,抽取开化县水文测站 2002—2020 年典型的60 场洪水(按时间先后顺序从 1到60 编号)进行分析。平滑前,用各洪水场次 DTW 计算结果查找最相似洪水场次,同理,平滑后找到最相似洪水场次,结果如表 2 所示。然后用相似洪水场次的匹配程度说明 DTW 算法的有效性,匹配程度用相似洪水的洪峰演进时长和当前洪水真实的演进时长的误差说明,演进时长和误差如图 4 所示。

图4 SG 平滑前后相似洪水洪峰演进时长情况
由图 4 可得:未经平滑处理的算据求得的相似洪水的洪峰演进时长的平均误差为 2.02 h,经过平滑处理的平均误差为 1.80 h,即经过平滑处理的算据使DTW 计算准确率提高了 10.89%,更能确保算法的稳定性、可靠性和预测能力,由此得到 SG 平滑处理能改进算据有效性的结论。
4 结语
算据有效性对算法的验证和使用起着至关重要的作用,能保证算法的稳定性、可靠性和预测能力。本研究抽取开化县水文测站的 3 场洪水数据作为数据样本,对场次 3 洪水数据进行异常处理,然后用平滑前后的洪水数据进行 DTW 相似度计算,结果表明经过平滑后的算据更适应 DTW 计算,从而说明平滑处理能改进算据的质量,提高算据的有效性。为了使结论更有说服力,抽取开化县水文测站 60 场典型洪水数据进行试验,平滑处理后找到的相似洪水比平滑前的匹配度更高,表明本研究观点符合预期。
需要提出的是,本研究讨论的算据改进方法没有特定的流域、测站和要素限制,计算的水位数据没有覆盖整个钱塘江流域,计算的要素没有包含降雨、流量等。对于不同流域、测站和要素的改进效果验证是后续需要继续开展的工作;同时本研究提出的平滑处理只是改进算据的一个方面,要充分改进算据的有效性需要采用综合的方法,根据不同的数据特征采用不同的方法,同时需要大量的试验进行论证,这也是后续需要开展的工作。
