基于对应分析的高校读者借阅行为特征探究
2024-01-06孟志强李慧
孟志强 李慧
摘 要:高校各学部的读者借阅特征不同,文章基于对应分析方法,选取吉林某高校2012—2014级本科生大学期间借阅数据进行多维度分析,揭示了不同专业不同年级本科生的借阅行为特征。研究结果有助于高校图书馆合理建设馆藏体系,适时正向引导同方向读者的阅读行为,解决现有高校图书馆的馆藏文献与高校读者需求不匹配的问题。
关键词:图书馆数据;对应分析;借阅行为
项目基金:吉林省社科基金项目《基于语义的高校图书馆数字资源聚合研究》(项目编号:2019wt39)研究成果;吉林大学基本科研业务费哲学社会科学研究种子基金项目《广度关联与深度语义融合的数字图书馆资源聚合服务质量评价与提升策略研究》(项目编号:2017ZZ026)研究成果
引言
随着目前的技术手段的完善,大数据分析已经不再构成技术瓶颈[1]。挖掘各院系(专业)读者的需求,并对各院系(专业)读者在不同年级的阅读需求变化进行精细分析,已经提上日程。通过对读者借阅行为特征进行分析研究,为图书馆文献采购提供科学的依据,为相关读者提供精准服务推送并对图书分布进行合理规划安排。这个问题是一种典型的属性数据处理的问题[2]。所以本文采用属性数据的处理方法——对应分析来进行分析研究。
本文研究了2012—2014级本科生的借阅行为特征,这些学生来源于8个不同学部(白求恩学部,地球科学学部,工学部,农学部,人文学部,社会科学学部,信息科学学部,理学部),涵盖了该高校的主要学科类别,能够确保研究数据具有较高的覆盖面。所选学部学生的在校时间均为5年,相比4年的本学学部,可以提供更加稳定丰富的数据支持。
1.1 对应分析
对应分析方法是在r型和q型因子分析的基础上发展出来的一种多元统计分析方法,又称r-q型因子分析[3]。它比因子分析更适合样本量大的数据。对应分析主要用于分析二维列表或可以表示为二维表的数据。它依赖于主成分分析中的降维方法,可以在低维空间中更直观地观察和分析行变量与列变量之间的关系[4]。通过对应分析,可以在二维分布图上反映行变量和列变量的分布特征以及行变量和列变量的各类之间的关系[5]。如果不同类别的行变量有相同的特性,它们在对应图上的分布会彼此接近,相似度越高。这同样适用于不同类别的列变量的分布[6]。不仅如此,如果某些类别的行变量和列变量之间有密切的关系,它们在对应图上也会彼此接近。
1.2 常规简单统计方法及结果
为了分析不同学年学生的借阅行为特征,我们首先绘制了学年-图书借阅量的折线图。在考虑学年借阅行为特征的时候,为了消除学部属性对图书借阅量的影响,我们分别根据8个学部的数据独立地做了不同折线图。
折线图表现如下:
第一,对于同一种书目,在不同学年它的借阅量是不同的。
第二,在相同学年不同书目的借阅量不同。
第三,对于同种书目,在相同学年里每个学部的借阅量也是有差异的。
第四,对于3个年级他们的折线的趋势几乎相同,这表明我们所发现的规律是具有稳定性的。
此外,我们可以看到每个书目的借阅量并得到其随学年的变化趋势。然而,正是这些书目使得其他书目的发展趋势难以识别,所以我们删除了这些比其他书目借阅量大得多的书目,重新做了折线图,如图1所示。
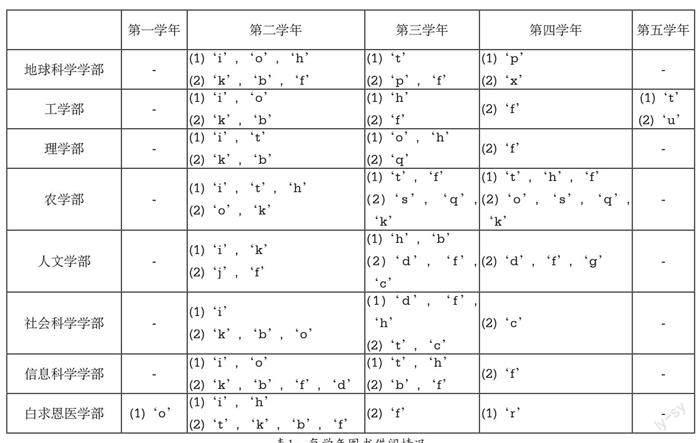
通过图1我们可以看到每个书目的借阅数量并得到每个书目随学年的变化趋势。例如,对于地球科学学部,我们可以看到在移除书目‘i‘t‘o‘h后,书目“k”“p”“b”“f”“x”被学生借得较多,且呈现出不同的变化情况。可见:学生在不同学部和学年需要借用不同的书目。为了更好地发现潜在规律,对比内容整理成表格1。
1.3 对应分析在读者借阅数据上的应用及结果
不同学年和不同学部的学生通常借用不同的书目,我们也在第1.2小节中做了一些简单的分析。在这一部分,我们将通过对应分析进一步分析学生的借阅行为特征。首先,对各学部单独进行了对应分析以反映各学部的借阅行为特征。数据组织结构如下:行变量为学年,列变量为22个书目。我们选择所有书目和2012级、2013级、2014级学生的在校学年作为对应分析的属性,发现不同学部的借阅行为特征是不同的,如:地球科学学部的学生在第一学年、第二学年和第三学年借书倾向是不同的,而在第四学年和第五学年借用同样的书目。在第二学年更偏向借阅书目“s”“i”“d”“h”“j”“k”,在第三学年更偏向借阅书目“t”“f”“q”“d”“h”,在第四学年和第五学年则更偏向借阅书目“x”“t”“f”“n”“p”。
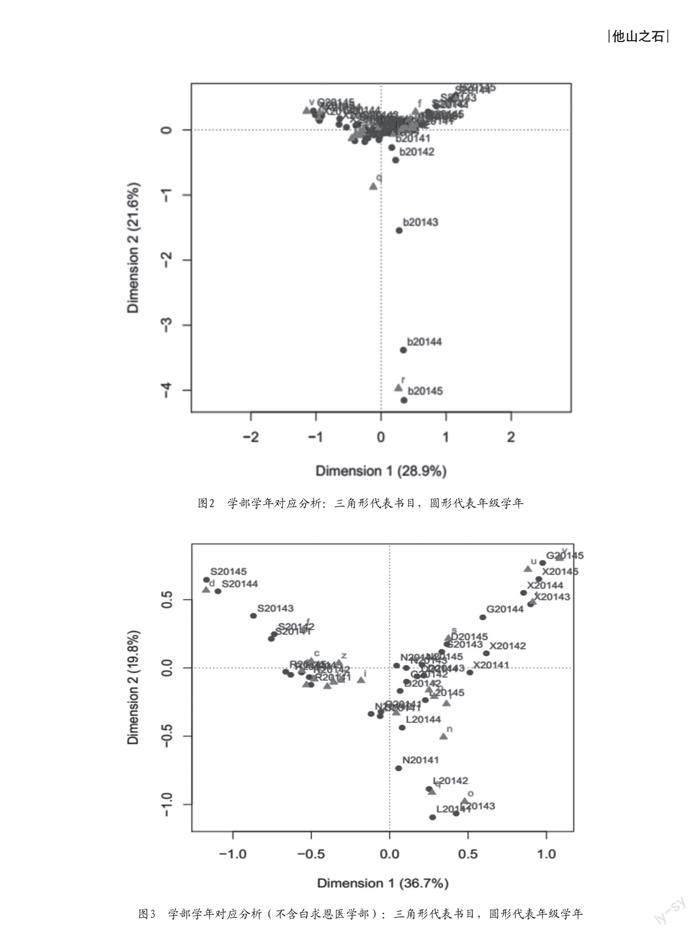
选择2014年的图书借阅情况进行进一步分析,分析结果如图2和图3所示。
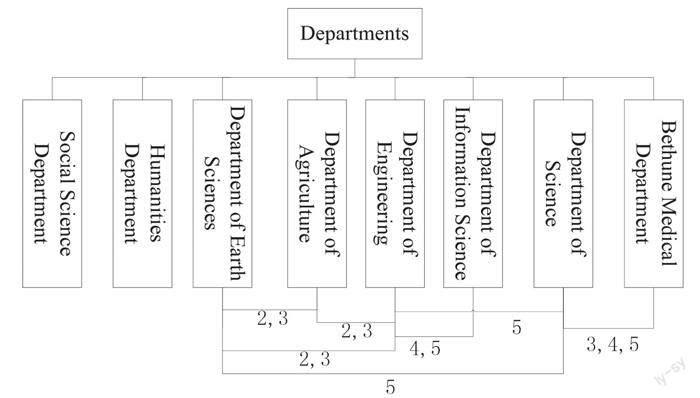
在图2中,我们找不到更多的东西,因为数据点太近,很难区分。因此,我们在移除白求恩医学部后重新做了对应分析,得出了图3。分析可知:首先,我们分析各学部之间以及各学年之间的关系。人文学部和社会科学学部是两个独立学部,不与其他学部产生交叉。工学部和信息科学学部有很强的相似性。这主要反映在他们的学生在第四、五学年借的书目非常相似。工学部、农学部和地球科学学部在第一学年和第二学年相互交叉。各学部间的具体联系我们用图4表示。单从书目的角度来看,我们发现22种书目聚集成了5个类别,第1类包含书目“f”“d”,第2类包含书目“a”“b”“c”“g”“i”“j”“k”“h”“z”,第3类包含书目“e”“n”“q”“o”,第4类包含书目“s”“x”“p”“r”,第5类包含书目“t”“u”“v”。
2 結论与讨论
首先,通过对吉林某高校的图书馆的数据的分析,我们得出了一些结论。一是对于同一种书目不同学年的借阅量是有差异的;二是在相同学年不同书目的借阅情况也是有差异的;三是对于同种书目,在同一学年中每个学部的借阅情况是有差异的;四是在不同学部和学年里学生的借阅偏好不同;五是一些学部之间有关联;六是根据某种规则书目可以被分成几个类别。
然后,这些结论对图书馆的服务与管理产生一些帮助。一是我们建议图书馆在不同学年向学生推荐最合适的书,例如,对于工学部的学生,在第二学年向其推荐书目“i”“o”,在第三学年向其推荐“h”,在第五学年向其推荐“t”“u”。这种推荐体系将激发学生的阅读兴趣,提高图书利用率。二是我们发现不同学部的学生借阅不同的书目,有些书目只被一个学部大量借阅,而有些书目则被许多学部大量借阅,还有一些书目几乎不被任何学部大量借阅。三是从对应分析中我们知道一些书目聚集在一起,这表明聚集在一起的图书有很强的联系。因此,就图书分布而言,我们建议将书目“f”“d”放在一起,书目“a”“b”“c”“g”“i”“j”“k”“h”“z”放在一起,书目“e”“n”“q”“o”放在一起,书目“s”“x”“p”“r”放在一起,书目“t”“u”“v”放在一起,使读者更容易找到他们需要的书。
最后,高校图书馆可以根据相近阅读特征的读者需求将资源进行归纳整合,形成多个同类型资源子库,进而合并成大学生就业指导数据总库,并在图书馆服务网站挂出就业指导资源总库链接,这样相关专业的毕业生就可以根据需求,在高校图书馆获得相应的资源支撑,进而帮助学生获得提升。
参考文献
[1]陈列柱.高校学生利用图书馆纸本资源现状调查[J].中国报业,2019(12):46-47.
[2]ShiozakiR,Eisenschitz T.Role and Justification of Web Archiving by National Libraries:A Questionnaire Survey[J].Journal of Librarianship&Information Science,2009,41(2):90-107.
[3]Greenacre,Michael J.Multiple correspondence analysis and related methods[M].Chapman&Hall/CRC,2006:148-156.
[4]黄维玲,成全.基于Logistic模型的高校学生借阅行为影响因素分析[J].武漢理工大学学报(信息与管理工程版),2021,43(3):268-274.
[5]施国良,张潇潇,杨小莉.高校读者群体差异对其借阅行为和阅读偏好的影响研究[J].图书馆,2020(4):59-64,78.
[6]艾金勇.基于关联规则的高校图书馆读者借阅行为研究——以西藏民族大学图书馆为例[J].西藏民族大学学报(哲学社会科学版),2017,38(4):142-146.
作者简介:孟志强(1976— ),吉林大学图书馆馆员,研究方向:数据挖掘;李慧(1983— ),吉林大学图书馆副研究馆员,研究方向:信息分析。
