数据库中多源异构异常数据清洗方法
2024-01-05王彩霞
王彩霞,陶 健
在互联网技术迅速发展的背景下,数据量呈现爆发式增长.为了有效应对大规模数据存储和访问的需求,较多不同类型的数据库被开发出来,使得多源异构数据的生成量较大[1].在对数据库中的多源异构数据进行管理的过程中,基于外界环境干扰、数据传输错误等原因,数据库中可能存在一些异常数据[2].这些异常数据将会对数据库数据的取用造成一定的影响,导致数据库应用效率降低.基于此,对数据库中的多源异构异常数据进行清洗逐渐成为当前该领域专家与学者的重点研究方向之一,很多研究人员提出了异常数据清洗方法.
韩红桂等[3]基于ISVM 建立数据补偿模型,计算约束条件对该模型进行优化,避免模型过拟合,采用粒子群算法对该模型参数进行优化,多次迭代后,使用优化后的模型对数据进行清洗.但数据清洗完成后,多源异构数据的可扩展性较差,数据清洗效果有待提升;刘云鹏等[4]基于变分模态分解方法建立变分模型,在该模型中对数据进行自适应的信号分解,运用拉依达准则对分解后的数据进行异常识别,利用长短期记忆神经网络计算数据特征相似度量,清洗小于阈值的数据.但利用该方法所获取的数据清洗结果查全率较低,多源异构异常数据清洗不充分,数据清洗质量不高.李琳等[5]利用DBSCAN 算法建立数据空间,计算数据点之间的欧式距离,按照升序的方法对空间中的数据进行重新排列,根据排列结果进行聚类处理,采用箱线图法对数据进行清洗,计算数据的边缘特征值,并进行区间划分,按照数据的区间进行清洗.但该方法无法有效识别异常的多源异构数据,数据清洗完成度较低.
考虑到上述文献所提出的异常数据清洗方法无法满足数据库中多源异构异常数据的清洗需求,提出一种基于时序关联和密度聚类算法的数据库中多源异构异常数据清洗方法.该方法通过计算数据特征的时序关联度,采用密度聚类算法对异常数据进行识别,填补异常数据缺失,完成异常数据的清洗.
1 数据库中多源异构异常数据清洗方法设计
1.1 预处理多源异构数据/SVM
将数据库中的多源异构数据进行统一采集,将采集到的多源异构数据汇集成数据集,根据该数据集建立数据空间,在数据空间中进行排列[6].对空间中的数据进行去噪处理.对数据特征点的密度进行计算,如公式(1)所示.
式中:θ表示数据特征点密度,i表示数据,k表示空间中的数据维度,a表示数据在空间中的分布大小.
根据现实的数据去噪需要,为去噪过程设定一个阈值.以该阈值为界限,将数据在空间中划分为两个数据群[7].建立数据特征点的二维图,对数据划分界线进行调整,直至一个界限中的数据完全符合噪声要求.
完成多源异构数据的去噪过程后,对去噪后的数据进行归一化处理,如公式(2)所示.
式中:j表示去噪后的数据,zj表示归一化后的标准格式数据,nj表示去噪后的数据特征量,表示数据特征量均值,s表示数据特征点标准差,η表示密度系数.
在式(2)的计算中,密度系数的取值由去噪阈值决定,将完成上述两个处理步骤的数据在复数空间进行映射[8],完成数据库中多源异构数据的预处理过程.
1.2 计算数据特征的时序关联
在1.1 小节所构建的多源异构数据复数空间中,对数据特征进行提取.构建数据特征提取的网络模块,将空间中的数据在该模块中进行匹配[9].将数据特征以散点的形式进行排列,以此建立散点特征矩阵,如图1 所示[10].
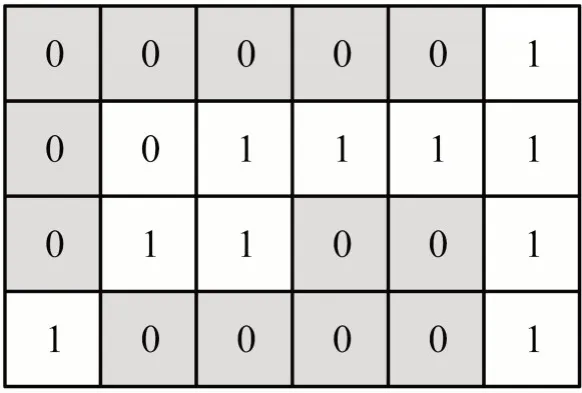
图1 数据特征散点矩阵
结合图1 散点矩阵设计原理对多源异构数据的特征进行分类提取,对提取出来的数据特征进行分析,计算数据特征之间的时序关联.建立三元时序模块对原始数据特征进行全局性的时序关联[11].在该模块中进行数据特征的耦合,计算有序功效函数,如公式(3)所示[12].
式中:f表示有序功效函数,Gj表示数据j的有序程度,Gmax和Gmin分别表示数据空间中的最大有序程度和最小有序程度.
由此对多源异构数据的时序关联进行表达,如公式(4)所示[13].
式中:F表示多源异构数据时间序列.
基于数据的时间序列,对数据特征的时序关联度进行计算,如公式(5)所示.
式中:δ表示数据特征时序关联度,表示时间序列均值,L表示数据特征的长度.
通过上述步骤,完成多源异构数据特征时序关联度的计算.
1.3 基于密度聚类算法识别异常数据
根据上述步骤计算得到多源异构数据特征时序关联度,对数据库中的异常数据进行识别.本研究采用密度聚类算法进行异常数据的识别步骤.将多源异构数据按照计算所得的特征时序关联度在原始数据空间中进行反馈.设置数据与其相邻数据的聚类簇点,以此确定该数据的聚类归属[14].计算数据与其聚类簇点之间的欧式距离,如公式(6)所示.
式中:d表示数据与簇点在空间中的欧式距离,o表示数据聚类的簇点,lj表示数据在空间中的位置,lo表示簇点在空间中的位置.
对聚类完成后的数据进行密度计算,如公式(7)所示.
式中:θ'表示聚类后的数据空间密度,m表示数据序列,x表示聚类连接点.
对密度聚类算法进行不断迭代,直至数据密度的计算值达到最优,且不再变化[15].根据最终的数据密度计算结果,对异常数据进行识别.设定异常识别的边界值,如公式(8)所示.
式中:μ表示密度均值,σ表示密度标准差.
将数据密度的计算值不属于上述区间的数据进行逐一筛选,完成基于密度聚类算法的异常数据识别过程.
1.4 清洗多源异构异常数据
对识别出来的多源异构异常数据进行清洗.对异常数据的缺失数据点进行分析,根据异常数据时序关联度的不同将异常数据划分为局部缺失和长期缺失两种异常类型.通过矩阵对其求解,如公式(9)所示.
式中:h表示数据缺失的时间序列长度,c表示数据当前的维度.
建立最小化缺失函数对异常数据的缺失部分进行填补,如公式(10)所示.
式中:J表示为异常数据填补的缺失内容,Y表示与异常数据时序关联度相同的正常数据的时间序列长度.
对填补后的数据进行异常值检测,判定其缺失度是否满足需求,填补失败的异常数据返回重新进行矩阵求解与填补,直至全部数据完成缺失填补过程.将填补后的数据在原始数据空间中进行反馈映射,将其导回至数据库中,完成数据库中多源异构异常数据的清洗过程.
2 实验
2.1 实验准备
设计实验对本文所提出的数据库中多源异构异常数据清洗方法进行有效性验证.实验采用某个公开数据库中的数据信息作为实验数据的模拟样本,选取的数据库包含大量多源异构数据.该数据库中的数据已经进行过隐私处理,确保不会对数据来源造成隐私泄露的安全问题.对该数据库中的数据进行异常分析,得到结果如图2 所示.
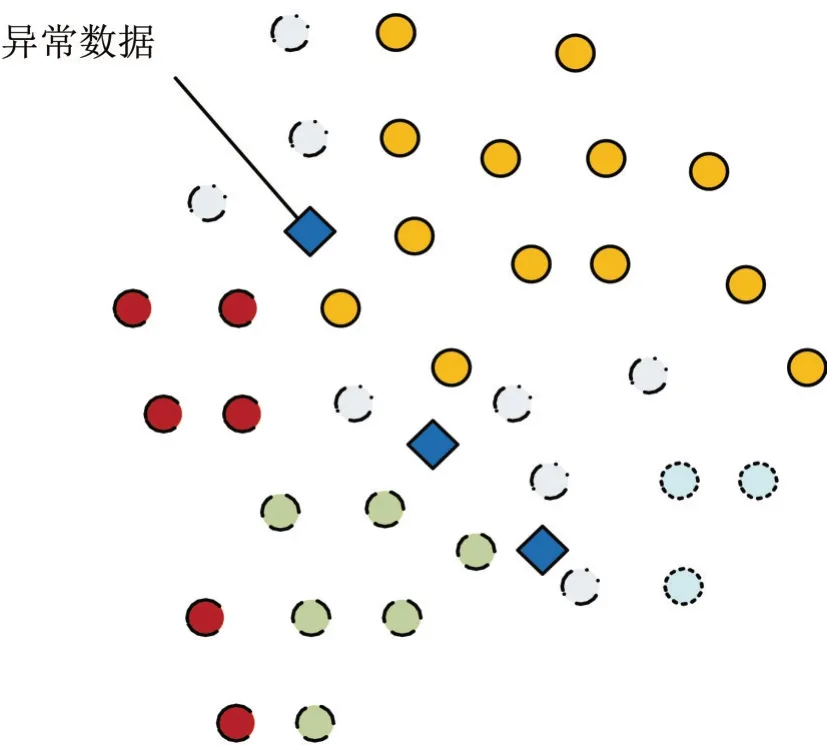
图2 数据样本异常分析
图2 中,数据的不同线型代表该数据库中的数据为异构数据,数据的形状表示了该数据的状态.由图2 可知,该数据库中的多源异构数据存在异常数据,可用于实验数据的模拟.
对该数据库中的多源异构数据进行采集.采用串口数据线将数据采集器与数据库进行连接.将该数据库中的多源异构数据进行数据采集与传输,并对数据库中的数据进行单独采集.根据采集得到的数据库多源异构数据样本进行实验数据模拟.将采集的数据样本通过数据采集传输装置传输至本次实验所用的主控计算机,如图3 所示.

图3 实验设备
图3 中,将数据采集传输装置利用连接线路与主控计算机进行连接,导出采集到的数据.再通过主控计算机与数据模拟装置进行连接,进行实验数据的模拟.其中,本次实验所使用的数据采集传输装置的参数配置如表1 所示.

表1 数据采集传输装置参数配置
实验所使用的主控计算机配置参数如表2 所示.
在上述环境中,开展本次实验.将模拟所得的数据按照3∶1 的比例进行划分,其中的3/4作为训练数据集,对本次实验应用到的算法及模型进行训练,剩余的1/4 作为测试集,用于数据清洗实验.
完成上述准备后,开展本次数据库中多源异构异常数据清洗实验.
2.2 数据库中多源异构异常数据清洗
对本文所提出的基于时序关联和密度聚类算法的数据库中多源异构异常数据清洗方法进行可行性测试.使用实验测试集中的数据进行本次测试.随机筛选出测试集中的部分多源异构数据,共筛选出2 000 条多源异构数据.使用本文所提方法对其中的异常数据进行识别,将异常数据识别的结果绘制成混淆矩阵,如图4 所示.
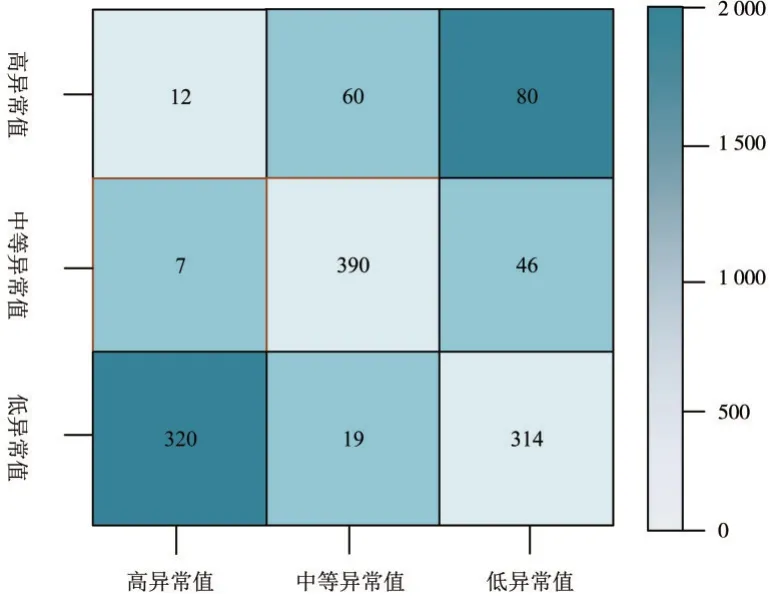
图4 异常数据识别混淆矩阵
对识别得到的异常数据进行清洗,分析清洗后得到数据的可扩展性(图5).由图5 可知,应用本文所提方法得出的异常数据清洗,仅用1.6 min 完成了异常数据的识别,使用2.5 min 完成了异常数据的清洗,且清洗后的多源异构数据可扩展性大幅度提高,提升幅度达0.97,效果较为明显.在完成异常数据的清洗后,多源异构数据的可扩展性变化较为平稳.从这一清洗结果可以初步判断,本文所提出的多源异构异常数据清洗方法结果较优,表明本文所提方法在数据库多源异构异常数据清洗实践中具有可行性.
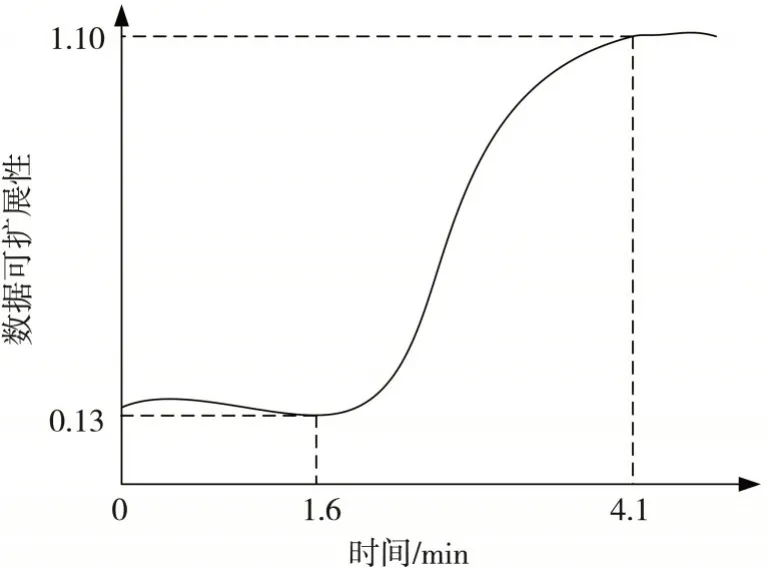
图5 多源异构异常数据清洗
2.3 结果评价指标
为了更加直观地体现出本研究所提方法的有效性,对异常数据清洗的质量进行评估,本次实验采用数据清洗的查全率作为实验结果的评价指标,其计算方法如公式(11)所示.
式中:λ表示清洗结果查全率,N表示实验数据总数量,n1表示识别出的异常数据量,n2表示成功清洗的数据量.
其中,成功清洗的标准设定为该数据的可扩展性达到1.0 以上.查全率能够有效对异常数据清洗的质量进行评价,计算所得的查全率结果数值越高,说明该方法识别并进行清洗的异常数据越多,对数据库中多源异构异常数据的清洗越充分.查全率的计算结果与异常数据清洗方法的可靠性呈正相关,查全率越高,则该方法的可靠性就越高,具备更高的实践应用价值.
2.4 结果分析与讨论
为了体现本研究所提方法实验结果的有效性,分别应用文献[3]和文献[4]所提出的异常数据清洗方法作为本文所提方法的对比对象,将三种方法的清洗结果进行横向对比评价.
为了减少实验误差,本次实验共进行10次,每次导入的多源异构数据不同,但同一轮次为每种方法导入的数据保持一致,确保实验变量唯一.经过实验,得到三种方法的异常数据清洗结果如图6 所示.
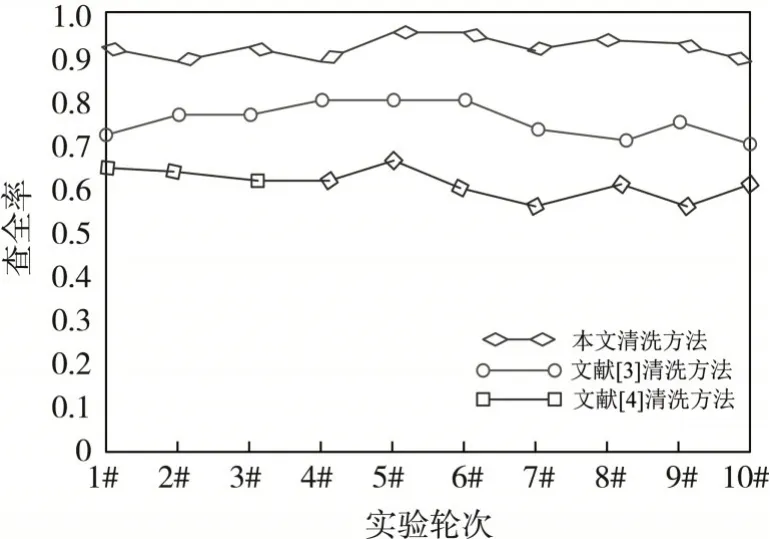
图6 不同方法异常数据清洗结果
由图6 可知,在10 个轮次的清洗实验中,本文所提方法的查全率结果始终比较高,均值可达0.94,而文献[3]和文献[4]所提出的异常数据清洗方法的查全率结果的均值分别为0.75 和0.63.将三种方法的查全率结果进行对比可知,本文所提出异常数据清洗方法的查全率提升显著.
从实验结果可以看出,本文所提出的数据库中多源异构异常数据清洗方法查全率较高,说明该方法能对异常的多源异构数据进行有效识别和清洗,并且清洗的完成度比较高.由此可见,本文所提方法具备较高的可靠性,在数据库中,对多源异构数据的管理实践过程中,应用效果较优,具备较高的实践应用价值.
3 结语
在数据库的运行过程中,多源异构数据基于各种各样的原因存在着不定量的异常数据,对数据库的存取性能造成了较大的影响.对此,本研究提出了一种数据库中多源异构异常数据清洗方法.实验结果显示,依据所提方法得出的异常数据清洗结果查全率较高,表明本文研究内容能够有效对多源异构异常数据进行识别并清洗,有助于推动多源异构数据库的应用与发展.
