基于随机循环网络的汉字骨架生成
2024-01-04高奕星
高奕星,施 霖
(昆明理工大学信息工程与自动化学院,云南 昆明 650500)
0 引 言
汉字的结构复杂、形态多样,每个汉字都具有结构的唯一性,汉字骨架作为汉字字形的重要拓扑描述具有重要意义。汉字骨架生成广泛应用于字形技术[1]、汉字识别[2]、汉字生成[3]等汉字信息处理领域。
汉字骨架可由一段书写序列进行表示,与图像表示相比,序列格式的汉字骨架包含更多的动态信息,如时间顺序、轨迹等,这些信息对汉字的笔画连接、拓扑结构等有更为清晰的描述,同时书写序列可以很容易地转换为图像[4]。循环神经网络(RNN)广泛应用于序列建模,如自然语言处理[5]、语音处理[6]等领域。目前基于RNN已经提出了生成英文字符骨架的方法。文献[7]利用带有长短期记忆[8](LSTM)的RNN 结合递归混合密度网络[9](RMDNs)能够学习并生成可辨识的书写轨迹序列。文献[10]提出了一种条件变分递归神经网络(C-VRNN),将字符的风格样式和骨架分离,对两者的分布进行建模,实现对字符骨架的编辑或生成全新的字符骨架。文献[11]在VRNN 的基础上引入了解耦样式描述符(DSD)模型,提高了模型从不同风格样式的字符中学习字符骨架的能力。
相较于英文这种仅有几十个字母的文字,汉字不仅具有数万种字形且具有高层次的信息和复杂的形状结构,因此汉字骨架的生成难度更大。文献[12]首次尝试使用RNN 生成汉字骨架,在带有LSTM 的RNN 框架下生成了无宽度信息的汉字,即汉字骨架,但其合成结果的质量较差,会生成不存在的汉字或生成结果不可读。文献[13]在Graves 的框架上进行扩展,提出了一种带有字符嵌入的条件生成模型,对手写汉字的分布进行建模,模型从与RNN 相关的概率分布中采样来生成新的汉字骨架,但会出现部分汉字骨架笔画缺失的问题,同时字符嵌入的联合训练模型需要数百万个训练样本。文献[14]提出了一种带有单调注意机制[15]的用于序列样式转换任务的序列到序列[16](Seq2Seq)模型FontRNN,能够从少量的输入样本中学习并生成大规模的汉字骨架。FontRNN 有效改善了文献[13]方法中笔画缺失的问题,但对于序列长度极短的笔画,笔画缺失的问题仍然存在。
尽管上述方法已经表现出了良好的效果,但正如文献[13]所证明的那样,生成性RNN 模型无法捕获小但重要的细节以进行精确绘制,这主要是由于缺乏对汉字高级信息的理解,如笔画的构成和布局。
本文将汉字的结构信息与神经网络相结合,将汉字骨架拆分为两层序列数据:笔画序列和笔画点序列。笔画序列包含了汉字的框架结构信息,增强了汉字字形的描述。文中使用RRN 作为生成模型,RRN 没有使用梯度下降训练方法,而是采用固有算法[17]来更新权重,避免了梯度消失或爆炸的问题。同时,RRN 对生成长序列具有很强的鲁棒性,这使得本文模型能够生成具有更丰富书写细节的汉字骨架。
在RRN 的框架下,生成模型不依赖于大量的训练数据,因此本文使用多个RRN 组成的分布式网络来生成汉字骨架。根据汉字的笔画数量和笔画类型对数据集进行细分,采用分布式训练方法,利用间架结构对笔画进行缩放和重组来生成汉字骨架。通过分布式训练,生成模型可以较少地依赖硬件性能并快速完成训练。
由于汉字的字形和字体多样,本文着眼于规范汉字,后文中所表述的汉字均为手写的规范汉字。
1 方 法
本节介绍了提出的汉字骨架生成方法。首先,简要说明了序列格式的汉字骨架表示;然后,详细描述了基于多个RRN 构建的汉字骨架生成模型。
1.1 数据表示
汉字骨架可由书写序列进行表示,书写序列为可变长的点序列数据,通常由在线方法记录书写时笔尖的运动轨迹获得,可表示为:
式中:Xi和Yi为笔尖水平运动的XY轴坐标;Pi为书写时的压力值。汉字由顺序书写的笔画组成,而笔画又由一段序列点构成。根据书写压力Pi可以将汉字拆解为多个笔画,笔画序列表示为:
式中:Si表示汉字第i个笔画的类型;n为汉字的笔画数;(Δxi,Δyi,Lxi,Lyi)为笔画序列中蕴含的汉字结构信息,用于表示每个汉字笔画的放缩比例和相对位置,Δxi和Δyi表示第i个笔画的第一个序列点与规范化区间的中心点间在XY轴的相对距离;Lxi和Lyi表示第i个笔画相较于整个字在XY轴的比例关系。笔画点序列表示为:
式中:ΔXi和ΔYi表示第i个序列点与第i- 1 个序列点之间XY轴的相对偏移,其中(ΔX1,ΔY1)为(0,0);m为笔画的序列点数;ΔPi表示第i个序列点相较于第i- 1 个序列点书写压力值的变化,其中ΔP1表示第一个序列点的书写压力值。
1.2 汉字骨架生成模型
如图1 所示,本文提出的汉字骨架生成模型包含两个部分:笔画序列生成模型和笔画生成模型。以下将详细叙述这两部分模型。

图1 汉字骨架生成模型示例
1.2.1 笔画序列生成模型
笔画序列生成模型由若干个RRN 构成(图1 中仅展示出一个),每个RRN 生成部分汉字的笔画序列。RRN的隐层由大量稀疏且随机连接的神经元组成,从可变数量的神经元Nin接收输入,网络活动演化可由一阶微分方程表示[18-19]:
式中:ri= tanh(xi)为网络的活动水平,表示神经元xi的放电率;y表示输入脉冲信号;τ表示单位时间常数;WRec为N×N的稀疏循环权重,非0 初始值随机取自均值为0、标准差为的高斯分布,g是突触强度缩放系数,pc是神经元之间的连接概率;WIn为输入权重,由均值为0、单位标准差的高斯分布初始化;网络活动由z读出;WOut为Nout×N的读出权重,Nout表示期望目标活动的维度,初始值来自均值为0、方差为的高斯分布;Inoise为N× 1 随机向量噪声,取自均值为0、标准差为I0的高斯分布。
RRN 的训练需对循环权重WRec和WOut进行更新,更新方法为固有算法[17],通过基于FORCE 算法[20]的递归最小二乘法RLS 实现。循环权重WRec的更新定义为:
其中60%的神经元上的突触是可塑的,B(i)是神经元i突触前循环单位的子集,ei表示神经i的个体误差,定义如下:
式中:ri(t)是权重更新之前神经元i的活动;Ri(t)则是该神经元的固有轨迹活动。固有轨迹活动为权重更新前随机获取的网络活动。
Pi(每个神经元i一个)用于估计突触前输入到神经元i(B(i))的相关矩阵的逆,由式(8)进行更新:
读出权重WOut的更新定义为:
式(10)为定义的误差,f(t) 为目标汉字的笔画序列。
P是网络活动水平r的相关矩阵的逆加上正则化项的运行估计,其表达式为:
笔画序列生成模型中,每条脉冲输入对应一个汉字的笔画序列,即当模型训练完成后,特定的脉冲输入将激活RRN 生成目标汉字的笔画序列。
1.2.2 笔画生成模型
笔画生成模型同样由若干个RRN 构成,每个RRN生成一类笔画的点序列。笔画生成模型的训练过程与笔画序列生成模型基本一致,区别之处在于期望输出的数据维度不同。由1.1 节中可知,笔画点序列为三维数据,通常序列的长度不一,因此通过增加一个维度Di来判断RRN 何时停止输出,此时笔画点序列表示为:
式中:Di为序列点是否为结束的标记,D1~Dm-1均为0,Dm为1,当Di为1 时表示序列结束。其余变量与公式(3)中一致。
一般来说,本文方法是按如下步骤实现汉字骨架的生成:首先通过脉冲信号激活RRN 生成期望汉字的笔画序列,根据笔画序列确定目标汉字包含的笔画和间架结构;然后再次通过脉冲信号激活RRN 生成相应笔画的点序列;最后根据间架结构将笔画按序重组生成目标汉字的骨架。
2 实 验
本节介绍了汉字骨架生成模型上进行的实验,对数据集、超参数配置和RRN 分布式训练方法进行了说明。实验均通过Matlab 程序在一台2.9 GHz AMD Ryzen 7 4800H CPU 和16.0 GB RAM 的PC 上实现。
2.1 数据集
训练RRN 生成模型仅需一个小规模的汉字数据集,该数据集需满足两个条件:其一,汉字样本为规范汉字,即正体字,书写标准且不存在连笔潦草等情况;其二,汉字样本为序列格式且具有大量的特征序列点。
由于并未发现同时满足上述两个条件的公开数据集,所以选择了自建数据集。通过电子手写板采集手写汉字数据,记录下汉字的书写序列。为了保证书写的准确性及规范性,采集的汉字根据《GB 13000.1 字符集汉字笔顺规范》(GF 3002—1999)中规定的笔画数和笔顺进行书写。一共采集了3 755 个手写汉字样本,样本字符来自GB 2312-80 中全部一级常用汉字。每个汉字样本的序列点数一般为数百个,根据2.1 节中描述的方法将3 755 个汉字样本处理为两类数据:3 755 个汉字的笔画序列数据和36 670 条笔画的点序列数据。经过预处理后,每条笔画数据的序列点数m在10 个左右。
2.2 超参数配置
RRN 模型的部分超参数设置为:突触强度缩放系数g= 1.5,神经元间连接概率pc= 0.1,时间常数τ=10 ms,输入脉冲的振幅为4,输入持续时间为100 ms 或200 ms(笔画序列生成模型中为100 ms,笔画生成模型中为200 ms),噪声Inoise的振幅I0= 0.001。
除上述超参数外,还需配置RRN 模型的神经元数N。神经元数决定了RRN 的记忆容量,训练数据规模越大,N也需越大,同时训练数据的序列长度不同,两者之间的对应关系也会发生变化。由于没有现存的经验指明两者之间的准确关系,所以本文通过实验的方法对RRN 的记忆容量进行量化,以探究RRN 的记忆容量与神经元数之间的关系。实验分别在两类生成模型上进行。
笔画序列为五维数据,因此WOut的维度为5 ×N。将笔画序列生成模型中WRec和WOut的更新次数设置为1和5。通过计算RRN 生成的笔画序列与训练数据之间的平均欧几里德距离来判断网络的训练误差。对笔画序列中Si、(Δxi,Δyi)和(Lxi,Lyi)三个类别的数据分别计算误差,其中Si进行四舍五入后再计算欧氏距离,当Si的误差为0 时,记录下此时的神经元数。由于当Si的误差为0 时,(Δxi,Δyi)和(Lxi,Lyi)的平均欧氏距离通常小于0.005,因此以Si的平均欧氏距离作为精度判断标准。从数据集中选取不同规模的笔画序列数据,用来训练不同神经元数的RRN 模型,如图2a)所示,将实验得出的数据进行曲线拟合,在95%置信区间,拟合曲线的公式为:
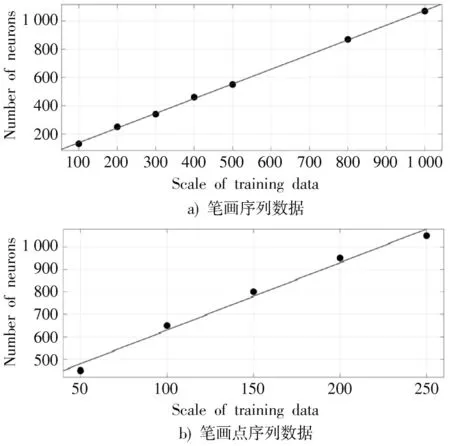
图2 RRN 神经元数与训练数据规模关系图
拟合优度R2为0.999 5。
笔画点序列为四维数据,因此WOut的维度为4 ×N,将笔画生成模型中WRec和WOut的更新次数设置为1 和10。同样采用欧氏距离来判断RRN 的训练精度,对笔画中(ΔXi,ΔYi,ΔPi)计算平均欧氏距离。当欧氏距离刚小于0.17 时记录下此时的神经元数。从数据集中选取了不同规模的笔画点序列数据,用于训练不同神经元数的RRN 模型。如图2b)所示,将实验得出的数据进行曲线拟合,在95%置信区间,拟合曲线的公式为:
拟合优度R2为0.986 8。
通过上述两组实验,对于自建数据集,得出RRN 的神经元数与训练数据规模之间大致的量化关系,在后续训练汉字骨架生成模型时,以此为标准来设置神经元数N。
2.3 分布式训练
笔画序列生成模型和笔画生成模型均采用分布式的训练方法,即运用多个小规模的RRN 组成分布式的网络构建生成模型,同时将数据集拆分为若干个细分数据集,使用细分数据集训练单个RRN。
将不同规模训练数据所需的训练时长作为细分数据集的依据,为此记录了2.2 节中两组实验所用的训练时间。
图3a)为RRN 训练时长与笔画序列数据规模的关系图。对于笔画序列数据,首先将笔画序列按汉字的笔画数分为24 组(自建数据集中汉字的笔画数为1~24),接着将24 组数据以500 条左右为一组继续进行细分,不足500 条的单独作为1 组,最终得到了84 个细分的笔画序列数据集,每个细分数据集训练一个RRN。对于数据规模在500 条左右的细分数据集,RRN 的神经元数N设置在550~600,训练数量规模远不足500 条的RRN,神经元数按照2.2 节中得出的量化关系进行设置。
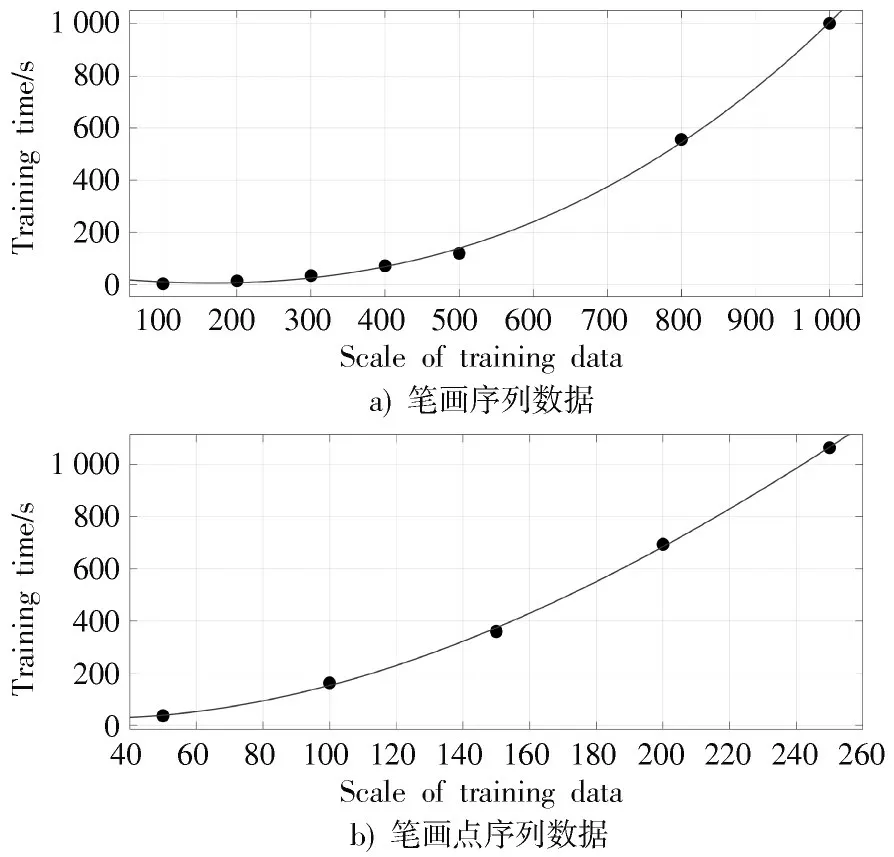
图3 RRN 训练时长与训练数据规模关系图
图3b)为RRN 训练时长与笔画点序列数据规模的关系图,对于笔画点序列数据,首先将36 670 条汉字笔画数据以汉字笔画类型数分为32组(通常汉字包含32 种笔画类型),接着将32 组数据以50 条数据为一组继续进行拆分,不足100 条的单独作为1 组,最终得到了731 个细分的笔画数据集,每个细分数据集训练一个RRN。对于数据规模为50 条的细分数据集,对应RRN 的神经元数N设置为300,训练数据规模大于50 条的RRN,神经元数N按照2.2 节中得出的量化关系进行设置。
3 实验结果分析讨论
本节展示了汉字骨架生成的结果,包括生成笔画的不同变体、不同汉字字符类型的汉字骨架和训练时长,并与相关工作进行了对比。
3.1 汉字骨架生成
训练完成后汉字骨架生成模型可以生成3 755 个不同汉字字符的骨架。图4 展示了汉字“字”骨架的生成示例,图中每列表示生成“字”的笔画序列,每行为生成的笔画序列中对应的每个笔画类型的变体,最后一行为笔画按间架结构进行放缩拼接形成的“字”的骨架。将GF 2001—2001 规范中规定的笔形、折点、折数等作为评估笔画的标准。“字”具有6 个笔画,图中每个笔画都生成了10 个变体,为了便于观察,图中将每个笔画都放缩至相似的大小,可以看出生成的所有笔画都各不相同,每个相同类型的笔画具有的特征点数不尽相同,笔画的特征清晰可辨。从最后一行10 个“字”的骨架可以看出每个骨架对字形的描述都较为准确,肉眼可轻易识别出字形,没有出现错漏笔画和结构异常的情况。

图4 汉字“字”骨架生成图示
为了验证本文提出的方法生成不同汉字骨架的能力,在图5 中展示了9 个不同汉字字符的骨架生成示例。由图中可以看出所有生成的汉字骨架都是可读的且均不相同,肉眼可轻易识别出字符类型。根据GF 2001—2001 规范,每个汉字骨架对笔画的描述都较为准确,且具有较为丰富的书写细节(每个笔画包含的序列段数),水平或竖直的笔画轨迹具有一定的弧度,这与人类真实书写的汉字类似。这些结果验证了本文提出的方法可以生成可识别且书写细节特征丰富的汉字骨架。
3.2 训练时长
本节记录了训练分布式RRN 网络的训练时间,由于RRN 的数量较多,在表1 中统计了两类生成模型的训练总时长。笔画序列生成模型由84 个RRN 组成,训练用时73.3 min。笔画生成模型由731 个RRN 组成,训练用时309.2 min。汉字骨架生成模型由笔画序列生成模型和笔画生成模型组成,共包含815 个RRN,总训练时长为382.5 min,不到6.5 h。

表1 不同生成模型RRN 的数量和总训练时间
上述训练均在一台PC 上完成,通过分布式的训练方法,多个RRN 可以在不同的计算机上同时进行训练,这样训练时间将进一步缩短。
3.3 与相关方法的比较
图6 为本文方法与基于RNN 的方法(文献[13]提出的方法)和FontRNN 的对比图。这是与本文的方法最相关的两种方法。本节结合GF 2001—2001 规范,从以下五个方面来进行对比:
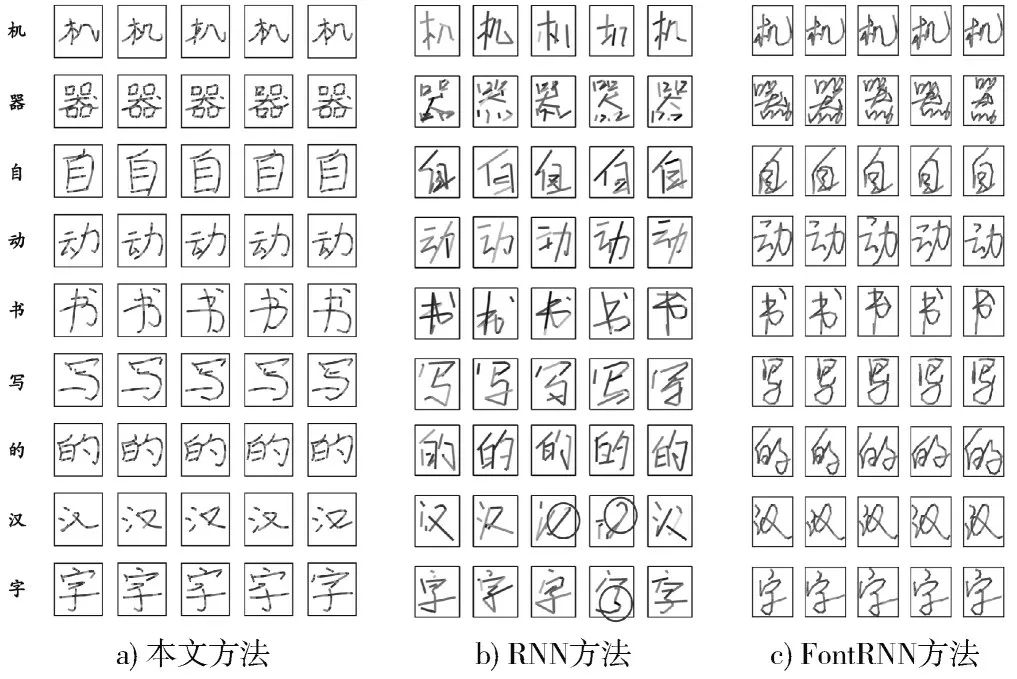
图6 不同方法生成汉字骨架对比图
1)能否通过肉眼辨别汉字。
2)是否存在额外笔画或笔画缺失的情况。
3)汉字骨架蕴含书写细节的丰富度。
4)训练数据规模。
5)训练时长。
从图6 可以看出,三种方法生成的汉字骨架相同字符并不完全相同,且均能通过肉眼进行辨别。笔画层面,如图6b)中圈出部分所示,基于RNN 的方法生成的汉字骨架并不总是准确的,存在部分笔画缺失的情况,而本文方法和FontRNN 的生成结果中则未出现缺失的情况,三种方法均未出现添加额外笔画的情况。图中汉字笔画的不同序列段为相邻序列点相连得到的,序列段越多表示汉字骨架包含的序列点越多,即书写细节特征越丰富。据此可知,本文方法生成的汉字骨架蕴含的书写细节特征最丰富,FontRNN 次之,基于RNN 的方法最少。本文方法与FontRNN 生成的汉字骨架具有类似人类正常书写的弧度,而基于RNN 的方法则明显有别于人类书写。除此之外,根据每个笔画的序列段数可知,本文方法与RNN 生成相同类型的汉字骨架时,骨架所包含的特征点数并不总是相同的,表明这两类方法生成的汉字骨架具有更大的随机性,而FontRNN 生成相同汉字的骨架时,特征点数是一致的。上述与训练数据的规模相关,基于RNN 的方法采用了字符嵌入的联合训练,训练数据的规模超过了200 万,而本文方法使用了一个小得多的数据集,仅包含3 755 个样本。FontRNN 则是采用了迁移学习的策略,使用了更小的训练集(仅2 000 个样本)。训练时长层面,RNN 方法的训练时长大概需要50 h,而FontRNN 在处理775 个样本时耗时近3 h,本文方法则需要不到6.5 h。上述三个方法使用的训练数据规模及设备的性能均不相同,因此训练时长仅作为一个直观的参考,无法直接体现出方法的性能优势。
4 结 论
本文将汉字的结构信息与神经网络相结合,提出了一种基于多个并行的RRN 构成的分布式网络用于生成汉字骨架,该网络可用于快速生成大规模且高质量的汉字骨架。相较于现有大多利用RNN 的方法,本文方法只需小规模的训练数据即可完成训练,同时可以保留更多的骨架特征点,增强了对汉字结构的描述。此外,生成模型采用了分布式的训练方法,可快速完成训练。实验结果表明,本文提出的方法可以快速生成具有更丰富书写细节特征的汉字骨架,这体现了本文方法在汉字骨架生成方面的优势。
