基于混合式特征选择的滚动轴承故障诊断方法
2024-01-04章翔峰张罡铭
司 宇,章翔峰,张罡铭,姜 宏
(新疆大学机械工程学院,新疆 乌鲁木齐 830046)
0 引 言
滚动轴承在汽车工业、风力发电等领域得到了广泛应用[1-2],发挥着重要作用,其一旦产生故障可能会导致巨大的经济损失,甚至引发安全事故,因此开发有效的滚动轴承故障诊断方法一直被作为研究的热点[3]。
近几十年来,机器学习、深度学习等计算机理论技术学科的快速发展,对智能诊断技术的研究产生了积极的影响[4]。在分类器的学习过程中,输入特征直接决定了最后的诊断表现,因此特征选择技术被用于从原始特征集中获取一个维数适中、剔除了无关和冗余特征的最优子集[5],进而减少计算成本并提高分类精度。依据在选择过程中对分类器依赖程度的不同,可将特征选择算法分为过滤式(Filter)、封装式(Wrapper)和混合式(Hybrid)三类[6-7]。Filter 算法独立于分类器,可以快速大量地剔除特征集中的无关特征,具有计算效率高、通用性好的优点,但保留的特征子集往往都不是最优的[8];Wrapper 算法在选择过程中与分类器相结合,将分类精度作为评价标准衡量特征子集的质量,最终保留的特征子集有着较好的分类性能,但该类方法有着较高的时间复杂度[9]。
Hybrid 方法则结合了二者的优点,利用Filter 算法获得的排序信息指导Wrapper 方法的搜索方向,权衡了分类精度和计算成本[10],成为目前的研究热点。现有的混合式特征选择算法大多设计为两阶段框架的形式,如文献[11]首先使用三种不同的Filter 方法从原始特征集中各选取5 个特征,然后通过穷举这些特征间的组合搜索最优子集。文献[12]首先利用Relief-F 算法来初步选择候选特征,然后通过粒子群算法同时搜索最优子集和分类器的参数。文献[13]首先根据特征与类标签的相关性对特征进行排序,然后应用不同的聚类方法将其划分为多个子集并对它们排序,最后通过遍历所有可能的子集,从而获取最优子集。上述文献针对分类精度和计算速度方面已经提出了不同的改进方案,但在适用性方面仍需进一步研究。
基于上述分析,本文提出一种混合式特征选择方法,用于为滚动轴承故障诊断任务提供高质量的特征集。该方法设计为经典的两阶段框架:首先在Filter 阶段中通过费舍尔分值法对特征进行预排序,利用拐点确定预选子集的范围;然后通过遗传算法指导Wrapper 阶段的搜索方向,从预选子集中确定最优子集。最后以最优子集作为输入,通过分类器实现滚动轴承不同故障类型和不同故障程度的诊断。
1 理论基础
1.1 费舍尔分值法
在费舍尔分值法(Fisher Score, FS)中,每个特征都是根据其Fisher 标准分数独立选择的,其目的是找到满足使类间距离最大,而类内距离最小的特征[14]。假设特征集中共有n个样本分别属于Y个标签,每一个标签中分别包含nk个样本。定义第i个特征fi的类间散度Sb(fi)为:
式中:nk表示第k类样本的个数;表示第k类样本在第i个特征上取值的均值;mk表示所有类别的样本在第i个特征上取值的均值。
定义第k个样本在第i个特征fi的类内散度(fi)为:
式中:为在第i个特征中属于第k类样本的第j个样本的取值。
当第i个特征fi的类间散度Sb(fi)越大,类内散度(fi)越小,该特征的表征能力越强,可以得到FS 的计算公式如下:
所得分值越小,特征重要性则越低;所得分值越大,特征重要性越高,表征能力就越强。可以通过设置合适的阈值来决定子集的范围[15],本文中将通过计算拐点以自适应地决定预选子集。
1.2 基于遗传算法的封装式方法
由于Filter 方法没有衡量特征间的相关程度,因此无法排除子集中的冗余特征,需要进一步的搜索手段减少冗余特征。事实上,因为特征选择任务实质上是一个0-1 整数规划问题,因此几乎所有搜索策略都可以用作指导Wrapper 方法的搜索方向。基于遗传算法(Genetic Algorithm, GA)在求解NP 问题时具有的良好性能,本文中将使用GA 指导Wrapper 阶段的搜索方向。
GA 是受自然进化理论启发的搜索算法,通过模拟生物界的生物进化和自然选择过程,将求解过程转化为类似于基因的变异、交叉和淘汰等过程,通过种群的不同进化达到搜索最优解的目的。
GA 的实现步骤如下:
1)参数初始化,如种群规模、变异率、交叉率和迭代次数;
2)建立随机初始种群,通过二进制编码将候选特征的可能组合编码为染色体;
3)计算个体的适应度并排序,同时记录每次迭代中的最优解,在本文中适应度函数定义为个体在送入分类器后表现出的识别精度;
4)对种群进行选择、交叉和变异操作,得到新一代种群,然后继续步骤3)直到达到终止条件。
利用FS 法获得的预选子集作为输入,通过将GA 嵌入Wrapper 阶段,GA 中的每个个体都代表了一种可能的特征组合方案,将该特征子集送入分类器,以识别精度作为对应个体取得的适应度。达到最大迭代次数后,搜索过程结束,给出取得最大识别精度的特征组合方案,即为所提混合式特征选择方法获取的最优子集。
2 基于混合式特征选择的滚动轴承故障诊断
综合以上论述,本文提出一种基于混合式特征选择的滚动轴承故障诊断方法,流程图如图1 所示,具体描述如下:

图1 基于混合式特征选择的滚动轴承故障诊断流程
步骤1:从振动信号中提取故障特征,构建原始高维特征集,然后按照1∶1 的比例随机划分为训练集和测试集。
步骤2:设原始特征集为S,其中包含有m个特征。首先通过费舍尔分值法对特征进行预排序,得到排序集合Sr,设fi为排在第i位的特征:
步骤3:根据特征fi的费舍尔得分将m个特征连接起来,得到得分曲线,计算曲线的拐点,将拐点及拐点之前的特征作为预选子集Sk。
步骤4:将预选子集Sk作为GA-Wrapper 阶段的输入,对GA 的参数进行初始化,在迭代结束后给出最优子集的索引。
步骤5:利用通过训练集获得的最优子集的索引,从测试集的原始高维特征集中选择出对应的最优子集,最终通过经训练集训练好的分类器得到测试集的故障诊断结果。
3 实验与分析
3.1 实验数据说明
为了验证所提方法的有效性,采用来自美国凯斯西储大学的滚动轴承实验数据集进行方法验证。轴承故障类型为6203-2RS JEM SKF 深沟球轴承,使用负载为735.5 W,转速为1 797 r/min,采样频率为12 kHz 条件下的故障数据。
本文通过两组实验来验证所提方法的有效性:
1)不同故障类型诊断。通过滚动轴承的4 种工作状态进行验证,时域波形如图2 所示。
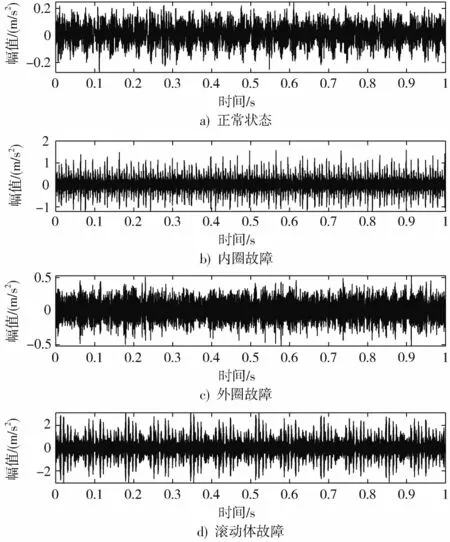
图2 滚动轴承不同状态下的振动信号
2)不同故障程度诊断。通过滚动轴承中5 种损伤程度的内圈故障进行验证,具体数据组成如表1 所示。
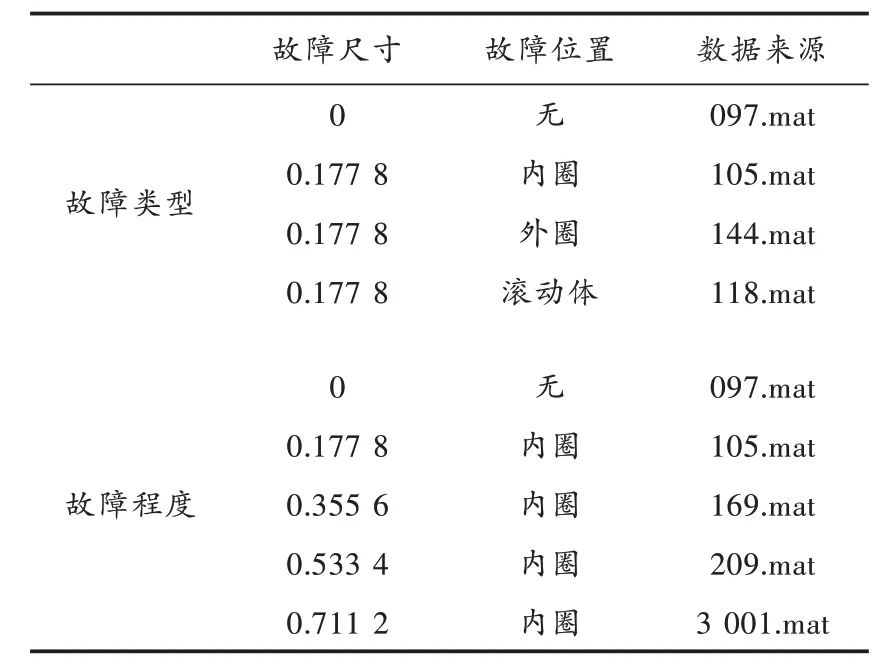
表1 实验数据描述
3.2 特征集构造
由于振动信号存在非线性、非平稳等特点,导致仅提取单一或单域特征往往难以全面描述设备的故障状态。统计特征有着明确物理意义且对设备的运行状态敏感,已在机械故障诊断中得到大量应用[16-18],因此本文通过从振动信号的时域和频域中提取统计特征来构造原始特征集。特征集中共包括11 个时域特征和13 个频域特征,分别表示为T1~T11和F1~F13,其详细参数和表达式见表2。其中:x(n)表示振动信号的时间序列;N表示时间序列的采样数目;s(k)表示信号x(n)的频谱,k=1,2,…,K,K是谱线数。

表2 统计特征表达式
3.3 不同故障类型诊断案例
通过对原始振动信号提取统计特征,每个样本都具有24 个特征,因此包含有4 种状态类型的滚动轴承故障诊断案例获得了一个320×24 维的原始特征集。显然直接将这些特征送入分类器中,会导致高昂的训练成本,需要对训练集使用特征选择方法来筛选出对故障诊断任务最有益的特征子集。首先通过费舍尔分值法对原始特征集进行预排序,根据特征的费舍尔得分按照降序排列,并将其通过曲线连接起来,如图3 所示。
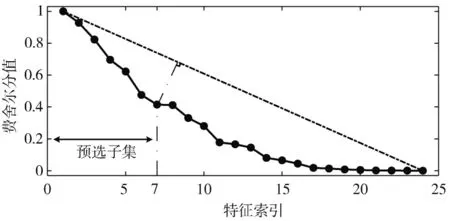
图3 确定评价结果的拐点位置(一)
由图3 可知,曲线的拐点出现在第7 个特征处,因此评价结果中的前7 个特征被选作预选子集,其序号分别为1、2、3、4、13、17 和23。通过前文分析可知,预选子集中存在有冗余特征,需要进一步去除。在GA-Wrapper阶段的搜索过程中,交叉率和遗传率分别设置为0.8 和0.1,初始种群为10,染色体长度为7,以达到最大代数50 作为终止条件。通过最优个体的索引记录相应的特征序号,获得的最优子集中仅保留了3 个特征,其序号分别为1、3 和13。
混淆矩阵可以直观地展示分类性能,进而判断诊断效果的好坏以及算法的优劣。滚动轴承不同故障类型诊断的测试集混淆矩阵如图4 所示,图中S1、S2、S3 和S4 分别表示轴承正常状态、内圈故障、外圈故障和滚动体故障。可见4 种工作状态均被正确地分类到对应的标签中,证明本文方法可以有效地实现轴承故障诊断。
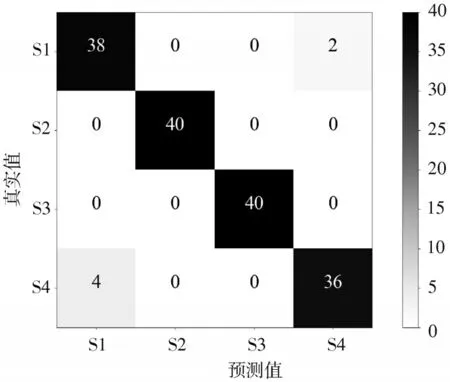
图4 不同故障类型诊断测试集的混淆矩阵
为了更直观地对所提方法的性能进行比较,将原始特征集、预选子集和最优子集的故障诊断结果进行对比,如表3 所示。

表3 不同故障类型诊断结果对比
相比于原始特征集,预选子集和最优子集分别在减少了70.83%和87.50%特征个数的同时,识别精度提升了8.12%和9.37%,且最优子集在进一步减少了预选子集中特征的同时,识别精度反而有着1.25%的提升,充分证明了GA-Wrapper 阶段的有效性。
3.4 不同故障程度诊断案例
与不同故障类型诊断案例的特征提取过程一样,为包含有5 种故障程度的不同故障程度诊断案例构建了一个400×24 维的原始特征集。由于同一特征在不同分类任务中体现出的表征能力可能是截然不同的,因此仍首先通过费舍尔分值法对训练集中的特征进行预排序,根据特征的费舍尔得分按照降序排列,并通过曲线连接起来。如图5 所示,曲线的拐点出现在第11 个特征处,因此预排序结果中的前11 个特征被选作为预选子集,其序号分别为1、2、3、4、12、13、17、20、21、23 和24。
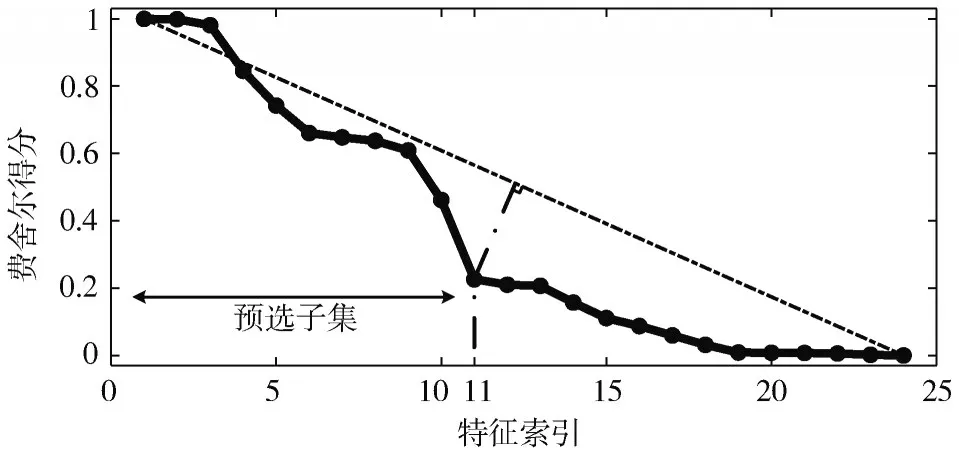
图5 确定评价结果的拐点位置(二)
在GA-Wrapper 阶段的搜索过程中,染色体长度设置为11,其余设置与不同故障类型诊断案例中一致。最终获取的最优子集中保留了6 个特征,其序号分别为1、2、4、13、23 和24。对比故障诊断案例中获取的最优子集,可以发现二者并非是完全重合的,说明适用于不同故障类型诊断任务的特征并不一定适用于不同故障程度的诊断任务,因此对原始特征集进行特征选择是非常必要的。滚动轴承不同故障程度诊断的测试集混淆矩阵如图6 所示,图中S1、S2、S3、S4 和S5 分别表示轴承正常状态、内圈故障0.177 8 mm、内圈故障0.355 6 mm、内圈故障0.533 4 mm 和内圈故障0.711 2 mm。可见对于不同程度的滚动轴承内圈故障,所提方法仍可有效地将其划分至正确的类别中。将原始特征集、预选子集和最优子集的故障诊断结果进行对比,如表4 所示。

表4 不同故障程度诊断结果对比
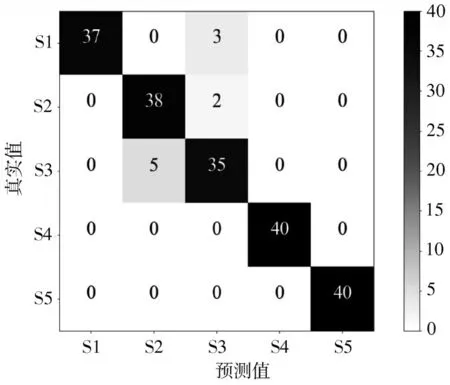
图6 不同故障程度诊断测试集的混淆矩阵
相比于原始特征集,通过特征选择获取的子集分类能力均得到了明显提升,预选子集和最优子集分别提升了1.00%和4.50%,且最优子集在进一步减少了预选子集中特征的同时,识别精度仍有着3.50%的提升,证明了所提混合式特征选择方法在降低原始特征集维数和提升识别精度方面的有效性。
表3 和表4 所示的分类结果均是通过K 近邻(Knearest Neighbor, KNN)算法作为分类器得到的,但所提方法在结合不同分类器使用时均可以获得可观的分类表现。分别以径向基网络(Radial Basis Function Neural Network, RBF - Net)和支持向量机(Support Vector Machine, SVM)作为分类器进行验证,仍以滚动轴承不同故障类型和不同故障程度的两个案例作为对象,将3 个不同分类器在两个诊断任务中的分类表现列于表5中。
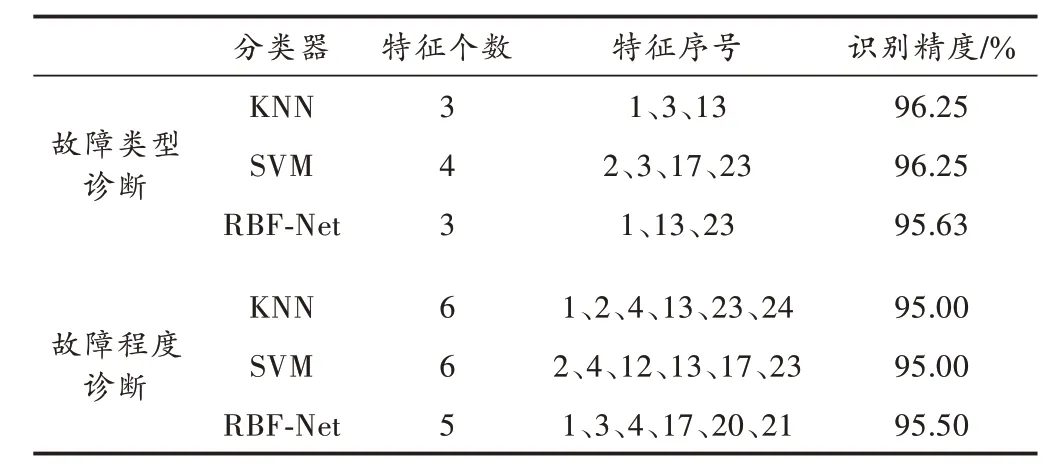
表5 结合不同分类器时的分类表现
从表5 可以发现:在不同故障类型诊断案例中,本文方法在结合KNN、RBF-Net 使用时,获取的最优子集有着最小的维数,结合KNN、SVM 使用时,取得的识别精度最高,但最高识别精度和最低识别精度间仅相差0.62%;而在不同故障程度诊断案例中,将本文方法结合RBF-Net 使用,获取的最优子集有着最小的维数,且取得了最高的识别精度,但仅超过最低识别精度0.50%。说明本文方法在分别结合3 个分类器使用时的分类表现没有明显差距,表明本文方法在结合分类器方面有着极好的适用性,可以根据实际需要进行选择。
4 结 语
针对原始特征集中存在无关和冗余特征,导致分类能力受限问题,以减少计算成本、改善分类效果为目的,本文提出了一种混合式特征选择方法。在滚动轴承不同故障类型和不同故障程度的诊断案例中进行验证,实验结果证明了所提方法的有效性。本文主要结论如下:
1)所提混合式特征选择方法首先在第一阶段中剔除特征集中的无关特征,然后在第二阶段中进一步剔除冗余特征,尽可能降低特征集的冗余性和无关性;
2)所提混合式特征选择方法能够从原始特征集中自动确定最优子集,在降低特征集维数的同时提高识别精度;
3)所提方法不涉及复杂的映射,是一个直观和简单的过程,因此该方法有着较好的物理解释性,有助于揭示故障与相应特征间的联系。
