具有自适应权矩阵的空间滞后模型:权矩阵构造及模型估计
2024-01-03梅长林续秋霞
梅长林, 王 琪, 续秋霞
(西安工程大学理学院,西安 710048)
0 引言
空间滞后模型[1]或称之为空间自回归模型是空间数据分析的一种重要模型。该模型在一般线性回归模型中引入了因变量的空间滞后项,同时考虑自变量的线性效应和因变量的空间自相关性,在空间计量经济学、环境科学、流行病学等众多领域得到广泛的应用。

对于上述空间滞后模型,已发展了诸如最大似然估计[1]、两阶段最小二乘估计[2]、广义矩估计[3]等多种估计方法,并建立了有关估计量的大样本性质[3–4]。虽然空间滞后模型及其他空间计量经济模型在应用上获得了巨大成功[5],但实际困难之一是其中空间权矩阵的确定问题,不同的空间权矩阵可能会严重影响最终的分析结果[6–7]。为此,作为空间数据自相关性分析的一个重要内容,人们在长期的研究中发展了各种空间权矩阵的构造方法:基于Tobler 地理学第一定律[8](即距离越近的事物间的相关性越大)提出的如0-1 值空间权矩阵、逆距离权矩阵、距离衰减权矩阵等多种形式,高乐[9]对这些经典的空间权矩阵的构造方法进行了总结;基于空间局部统计量[10]的空间权矩阵构造方法,如Getis 和Aldstadt[11]的基于临界距离和Aldstadt 和Getis[12]的AMOEBA 空间权矩阵的确定方法。但以上方法均是在模型拟合之前就需要确定其中的空间权矩阵,未能充分考虑因变量观测数据自身所蕴含的自相关性信息,因而有一定的主观性。尤其是最常用的0-1 值空间权矩阵,由模型(1)可知,任何给定空间目标单元处因变量的观测值与其邻接单元处的观测值的相关性都相同(即ρ的常数倍),这未能充分体现Tobler 定律中相关性应随距离衰减的规律。近期,基于机器学习技术确定空间权矩阵的方法得到发展。例如,Seya 等[13]将可逆跳马尔科夫链蒙特卡罗技术与模拟退火方法相结合,建立了自动确定空间权矩阵的算法;Kostov[14]提出了基于逐分量模型,提升算法在一类事先给定的空间权矩阵类中选择最优的权矩阵;任英华和游万海[15]将该方法应用于空间滞后模型,对我国城市服务业集聚机理进行了实证分析;Lam 和Souza[16]通过引入稀疏调节矩阵,基于自适应LASSO 算法选择空间权矩阵。虽然这些数据驱动的空间权矩阵选择方法具有很好的自适应性,但通常都面临较高的计算代价以及权矩阵的可解释性问题。同时,和经典的权矩阵选择方法一样,对于空间滞后模型(1)来说,因变量在任一目标单元处的观测值与其邻接单元处的观测值之间的相关性强度只是一个按固定比例ρ的一个压缩,即是权矩阵中元素的线性函数。
本文以事先给定的描述n个地理单元空间邻接结构的0-1 值权矩阵为基础,将其中具有空间邻接关系的元素(即元素“1”)替换为所对应的两个空间单元之间距离的单调减函数,同时将模型(1)中的自回归参数ρ按一定方式嵌入到距离函数中,变为控制函数下降速度的参数,该参数如模型(1)中的自回归参数ρ一样,可以结合模型的估计方法予以估计。本文在空间权矩阵元素的设计上,通过引入控制其随距离下降速度的参数,使空间权矩阵更具灵活性,在一定程度上克服了经典方法中确定空间权矩阵的主观性;将空间权矩阵中的控制参数的选择与模型估计方法结合,基于数据驱动方法自适应地确定该参数,可使所确定的空间权矩阵能更有效地反映客观实际;较之于机器学习技术确定空间权矩阵的方法,所确定的空间权矩阵各元素不仅能体现Tobler 地理学第一定律的主旨,而且有很好的可解释性;基于本文提出的空间权矩阵所建立的新的空间滞后模型仍可以像传统模型(1)一样,利用最大似然方法拟合模型,且在计算代价上二者相当。
本文其余部分安排如下:第1 节介绍了空间权矩阵的具体构造方法、计算机实现以及权矩阵的重要性质;第2 节给出了新的空间滞后模型及其最大似然估计方法;第3 节通过数值模拟实验验证了空间权矩阵及其模型拟合方法的有效性;第4 节通过波士顿房屋价格数据分析说明本文方法的实际应用;最后一节是全文的总结与讨论,并指出尚需进一步研究的问题。
1 空间权矩阵的构造及其计算机实现
1.1 空间权矩阵的构造及性质
设{si}为n个地理单元所对应的抽样位置,定义
且~wii= 0(i= 1,2,···,n),则可以得到0-1 值空间权矩阵~W= (~wij)。空间单元邻接关系可按传统方法确定,比如对于区域型数据,如果si和sj所对应的区域有公共边界,那么称si和sj相邻;对于点型数据,可用k-最近邻等方法确定si与sj的邻接关系,即对每个si,如果sj到si的距离小于或等于si到它第k个最近邻点的距离,那么si和sj具有邻接关系。
选择一个定义域为[0,∞)×[0,∞),值域为[0,1]的二元函数w(d,γ),使满足:
(i) 给定γ>0,w(d,γ)是d的单调减函数,且limd→∞w(d,γ)=0;
(ii) 给定d>0,有limγ→0+w(d,γ)=0, limγ→∞w(d,γ)=1,且定义w(d,0)=0。
满足上述条件的函数有很多,如下面两类函数
对每个a>0 均满足上述条件(i)和(ii)。
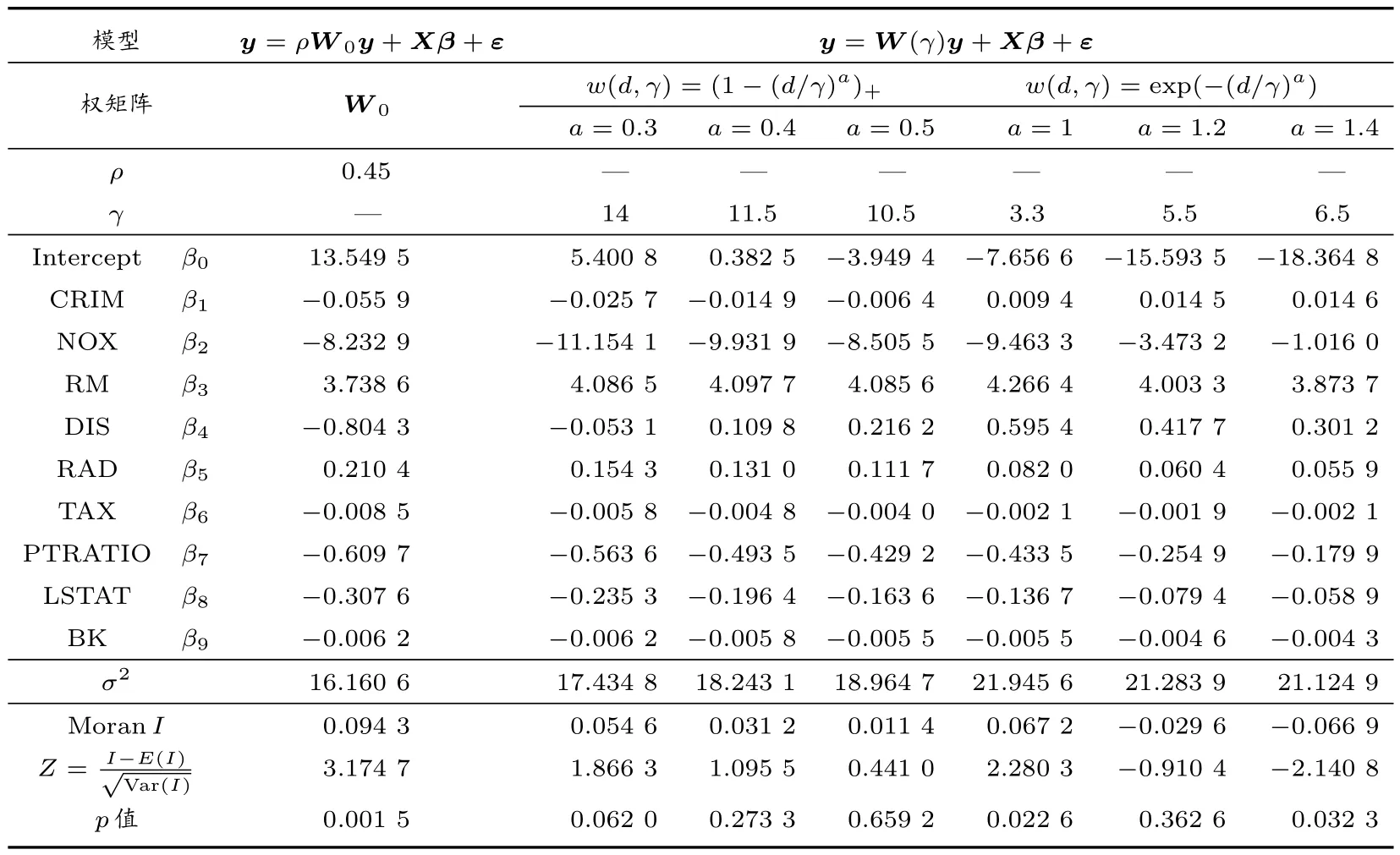
设dij=d(si,sj)为si与sj之间的欧氏距离,也可以是按照实际问题背景所定义的其他距离。将0-1 值权矩阵~W= (~wij)中的“1”用函数值w(dij,γ)替换,即对于1≤i 由函数w(d,γ)的定义及所满足的条件,可知矩阵W(γ)有如下性质: (i) limγ→0+W(γ) = 0, limγ→∞W(γ) = (diag(~w+))-1~W,即0-1 值权矩阵的行标准化矩阵,其中~w+= (~w1+, ~w2+,···, ~wn+)T是0-1 权矩阵~W各行元素之和所构成的列向量,diag(~w+)为以~w+为主对角元素的对角矩阵; (ii)In-W(γ)对每个γ ≥0 是主对角占优矩阵,从而可逆。 由于W(γ)中已嵌入了其非零元素随距离下降的控制参数γ,其作用相当于传统模型(1)中自回归模型参数ρ,因此在W(γ)下的空间滞后模型为 其中y、X、β、ε与模型(1)中各量的定义相同。 如引言所述,以W(γ)替代模型(1)中的ρW,可以更灵活地反映自变量在任一个目标单元处的观测值与其邻接单元处的观测值的相关性,同时体现了Tobler 地理学第一定律[8]中相关性随距离下降的一般规律,参数γ将由观测数据予以估计,因而模型(2)在反映因变量自相关性方面更具自适应性。由W(γ)的性质(i)可知,当γ →0+时,W(γ)→0,这时模型(2)退化为一般线性回归模型,对应于传统空间滞后模型(1)中ρ= 0 的情形,即因变量不具有空间自相关性;当γ →∞时,W(γ)趋于0-1 值空间权矩阵的行标准化矩阵,对应于模型(1)中ρ →1 的情形,即因变量正自相关性最强。因此,基于数据适当选择γ值,可使模型(2)能更自适应地反映因变量的自相关性。 需要指出的是,由于W(γ)的元素均非负,因此模型(2)中的空间自相关项W(γ)y只能反映因变量的正自相关性,即所谓的溢出效应。对空间数据而言,如Griffith[17]所指出的,虽然空间正自相关性普遍存在于实际问题中,但反映竞争效应的空间负自相关性也不应被忽略,也有其存在的许多实例。如果需要探索因变量可能的负自相关性,可在模型(2)中以W(γ)的负矩阵替代W(γ)进行建模分析。另外,在构建W(γ)的过程中,0-1 值空间权矩阵~W是必要的,否则会造成对W(γ)行标准化上的困难。 理论上,传统的空间滞后模型(1)的各种估计方法都可以推广到模型(2),而基于最大似然估计的良好性质以及在最大似然估计框架下,模型(1)和模型(2)的估计过程类似,在此仅给出模型(2)中参数γ、β和σ2的最大似然估计方法及其主要步骤。 令A(γ)=In-W(γ),由ε ∼N(0,σ2In),可得y的对数似然函数为 其中|A(γ)|为矩阵A(γ)的行列式。对数似然函数分别关于β和σ2求导,并令其等于零,则有 关于β和σ2求解上述方程组,得 将~β和~σ2代入式(3),并略去与γ无关的加项,则得到关于γ的对数似然函数为 利用搜索优化方法,求γ使得l(γ)达到最大,则得γ的最大似然估计ˆγ,将ˆγ代入~β(γ)和~σ2(γ)表达式中,则得β和σ2的最大似然估计分别为 本节通过数值模拟实验,说明权矩阵W(γ)的具体构造过程以及相应空间滞后模型的最大似然估计的有效性。 3.1.1 空间区域及抽样点 取空间区域为[0,1]×[0,1]的单位正方形,抽样点按如下两种方式产生: (i) 15×15 格点区域(样本容量n=225),抽样点的空间坐标为 其中mod((i-1)/15)和int((i-1)/15)分别表示i-1 除以15 的余数和整数部分; (ii)n= 225 个服从单位正方形上均匀分布的随机点,即si= (ui,vi)(1≤i ≤225),其中ui和vi从均匀分布U(0,1)独立抽取。 具体抽样点在区域上的分布,如图1 和图2 所示。 图1 格点抽样 图2 随机点抽样 3.1.2 权矩阵的生成 0-1 值权矩阵~W按如下方式产生:格点抽样下取Queen 形式(即一个抽样点所在的小矩形与周围有公共顶点的小矩形中的抽样点相邻);随机点抽样下由k-最近邻方法确定,这里取k=6。w(d,γ)取如下两种形式: 其中a=0.5,1,1.5,2,d取欧氏距离。 3.1.3 模型及数据产生 考虑如下形式的空间滞后模型 其中各个参数的取值及数据产生方式为: 1)β0=0.5,β1=1.5,β2=-2; 2) 自变量X1和X2的观测值xi1和xi2(i=1,2,···,n)分别从标准正态分布N(0,1)和(0,1)上的均匀分布U(0,1)中独立抽取; 3) 误差项从N(0,1)中独立抽取,即εi ∼N(0,1),i=1,2,···,n; 4)γ=0.05,0.1,0.2,0.4,0.6; 5) 因变量Y的观测值向量y=(y1,y2,···,yn)T按如下方式产生 其中β=(β0,β1,β2)T,X为设计矩阵,ε为误差向量。 3.1.4 参数估计精确性度量指标 为降低抽样误差对参数估计的影响,对上述的每种情况重复实验N= 100 次。在此以N次重复下各参数γ、βT和σ2的估计值的均值和标准差来评估参数估计的精确性。以参数γ为例,记N次重复下γ的估计值分别为ˆγk(k=1,2,···,N),则其均值和标准差分别为 不同情况下的数值模拟实验结果如表1 至表4 所示。需要指出的是,当给定具体空间数据集时,抽样点的位置也随之确定。由于W(γ)中的非零元素与两两抽样点的距离dij(1≤i 表1 格点抽样且w(d,γ)=exp(-(d/γ)a)时,100 次重复下的参数估计结果 表2 格点抽样且w(d,γ)=(1-(d/γ)a)+时,100 次重复下的参数估计结果 表4 随机抽样且w(d,γ)=(1-(d/γ)a)+时,100 次重复下的参数估计结果 由表1 至表4 中结果可知,γ、β以及σ2的估计值的均值在各种情况下均十分接近于参数的真值。随着因变量观测值之间自相关性的增强,即γ值的增加,各参数估计的标准差有增加的趋势,反映出和传统空间滞后模型(1)的参数估计类似的特征,即随着ρ值的增加,参数估计的精度会受到一定影响。但总的来看,各参数估计的标准差变化不大,即自变量自相关性增强对参数估计的精度影响是有限的。上述数值模拟结果反映出在新的空间权矩阵下,模型最大似然估计的有效性。对于更大样本容量,如n= 400,我们也就一些典型情况进行了模拟实验,与所预期的一样,各参数估计的偏差,尤其是标准差均有明显减小,即估计的精度有明显提高。 为进一步说明本文所提出的空间滞后模型及其最大似然估计的应用效果,本节将对波士顿房屋价格数据进行分析。该数据集可通过网址http://cran.r-project.org/,从R 软件包spdep 中下载,其中包含了波士顿506 个普查区1970 年自有住房的中位数价格(MEDV,单位:千美元)和13 个解释变量在各普查区的观测值,同时还包括各普查区的直角坐标以及与各个普查区相邻接的普查区信息。在此,我们选择Gilley 和Pace[18]基于线性回归分析表明对MEDV 有显著影响的9 个解释变量作为自变量,具体见表5,以MEDV 为因变量建立有关空间滞后模型。 表5 自变量名称与描述 需要说明的是,原数据集中非洲裔人口比例的取值为经过变换1 000(BK-0.63)2的值,其中BK 为各普查区非洲裔人口每千人的比例。为便于解释,本文采用的是变换回的数据,即,其中B为原数据集的数值。 利用各普查区的直角坐标可求得506 个普查区两两之间的距离矩阵D=(dij)n×n,这里n=506;由各普查区的邻接关系可得到0-1 值空间权矩阵~W=(~wij)n×n。在此,w(d,γ)仍取为如模拟实验所示的截尾幂函数和指数函数形式产生的空间权矩阵W(γ) =(wij(γ))n×n,基此拟合如下新的空间滞后模型 为了比较所提出的空间权矩阵在拟合房价空间自相关性的优势以及对回归系数估计的影响,在此也拟合了0-1 值行标准化矩阵(记为W0)下的传统空间滞后模型。同时,我们以两种模型拟合的残差向量 在0-1 值权矩阵~W下的MoranI指数[19]为统计量检验残差的空间自相关性,以评估不同空间权矩阵提取因变量空间自相关性的能力以及模型的拟合效果,其中以MoranI分布的正态逼近求双边检验的p值。在两种生成空间权矩阵的函数w(d,γ)下,我们尝试了其中参数a的多个取值,通过MoranI检验结果各选择了三种情况,连同在W0下传统空间滞后模型的估计结果列于表6 中。 表6 不同空间权矩阵下各模型的拟合结果 由表6 结果可知,不同的空间权矩阵的确对回归系数的估计有较大的影响,说明在实际应用中选择恰当的空间权矩阵是很重要的。但就表6 结果而言,除CRIM 和DIS 外,各自变量系数估计的正、负号均一致,因而从定性角度解释自变量对房价的影响会得出一致的结论。但从MoranI检验结果看,基于行标准化的0-1 值空间权矩阵的传统空间滞后模型显然未能较好地拟合房屋价格数据的空间自相关性(残差的MoranI检验p值为0.001 5),而本文所构造的空间权矩阵下的空间滞后模型在拟合因变量空间自相关性方面可以通过选择w(d,γ)的适当形式,得到更为满意的结果。 基于MoranI检验结果以及各解释变量的实际意义,基于截尾幂函数w(d,γ) =(1-(d/γ)a)+所生成的三种权矩阵下的空间滞后模型均是较合理的分析波士顿房屋价格数据集的可选择模型。与传统的空间滞后模型的估计结果相比,自变量DIS 的系数估计值变化较大,甚至在a等于0.4 和0.5 时,估计值出现了反号的情况。但由数据集可知,有些普查区(如370∼374 号)DIS 的值很小(在1.1∼1.4 之间),但房价中位数MEDV 达到最高的5 万美元;也有一些普查区(如192∼205 号)DIS 的值均较大(在6.0∼7.7 之间),且MEDV 的值也明显偏大(4 万美元左右)。其实,Li 等[20]通过拟合空间自回归变系数模型,基于所提出的Bootstrap 检验方法得到DIS 的系数随空间位置显著变化,即是一个空间变系数,且系数估计值在大部分普查区都为正值。而本文两种模型下的系数估计可以看作是平均意义下的估计值,同时考虑到传统空间滞后模型未能充分拟合房价的自相关性,而在新的空间权矩阵下,当房屋价格间的自相关性通过W(γ)y项充分拟合后,在平均意义下DIS 与MEDV 呈现正相关是有可能的,或者这时DIS 对MEDV 的影响会变得不显著,但这需要进一步建立在本文所提出的空间滞后模型下参数显著性的检验方法。 本文基于0-1 值空间权矩阵,构造了含有控制参数的距离衰减空间权矩阵,建立了新的空间滞后模型,给出了模型的最大似然估计方法。数值模拟实验表明了其最大似然估计的有效性;实例分析表明所构造的空间权矩阵能更有效拟合因变量的空间自相关性,并且能通过某些模型诊断准则,尝试多种形式的空间权矩阵,选择出更合理的模型。另外,和基于机器学习技术选择空间权矩阵的方法相比,本文构造的空间权矩阵不仅反映了Tobler 地理学第一定律的要旨,而且由于其中参数的明确意义,使其更具可解释性。 本文利用MoranI指数为模型诊断统计量,从残差自相关显著性角度在实际应用中选择更合理的模型,其他如均方误差准则、似然函数准则以及AIC 准则等拟合优度准则均可作为实际应用中模型的选择标准。需要指出的是,本文只给出了空间权矩阵的构造以及相应空间滞后模型的最大似然估计方法,相关统计推断问题仍需要进一步研究。与传统的空间滞后模型不同,新的空间滞后模型将其中的自相关强度参数ρ变为了距离衰减的控制参数γ,纳入在权矩阵元素中,导致相应对数似然函数关于各参数的信息矩阵不再有显式表示,因而传统空间滞后模型下关于参数显著性的似然比检验、Wald 检验以及Lagrange 乘子检验等不能直接应用于新的空间滞后模型,但通过Bootstrap 方法实现对参数的检验似乎是一条可行的途径,这也是我们接下来的主要研究工作之一。1.2 空间权矩阵构造的计算机实现
2 以W(γ)为空间权矩阵的空间滞后模型及其估计
2.1 空间权矩阵W(γ)下的空间滞后模型
2.2 模型(2)的最大似然估计
3 数值模拟实验
3.1 实验设计

3.2 实验结果及分析
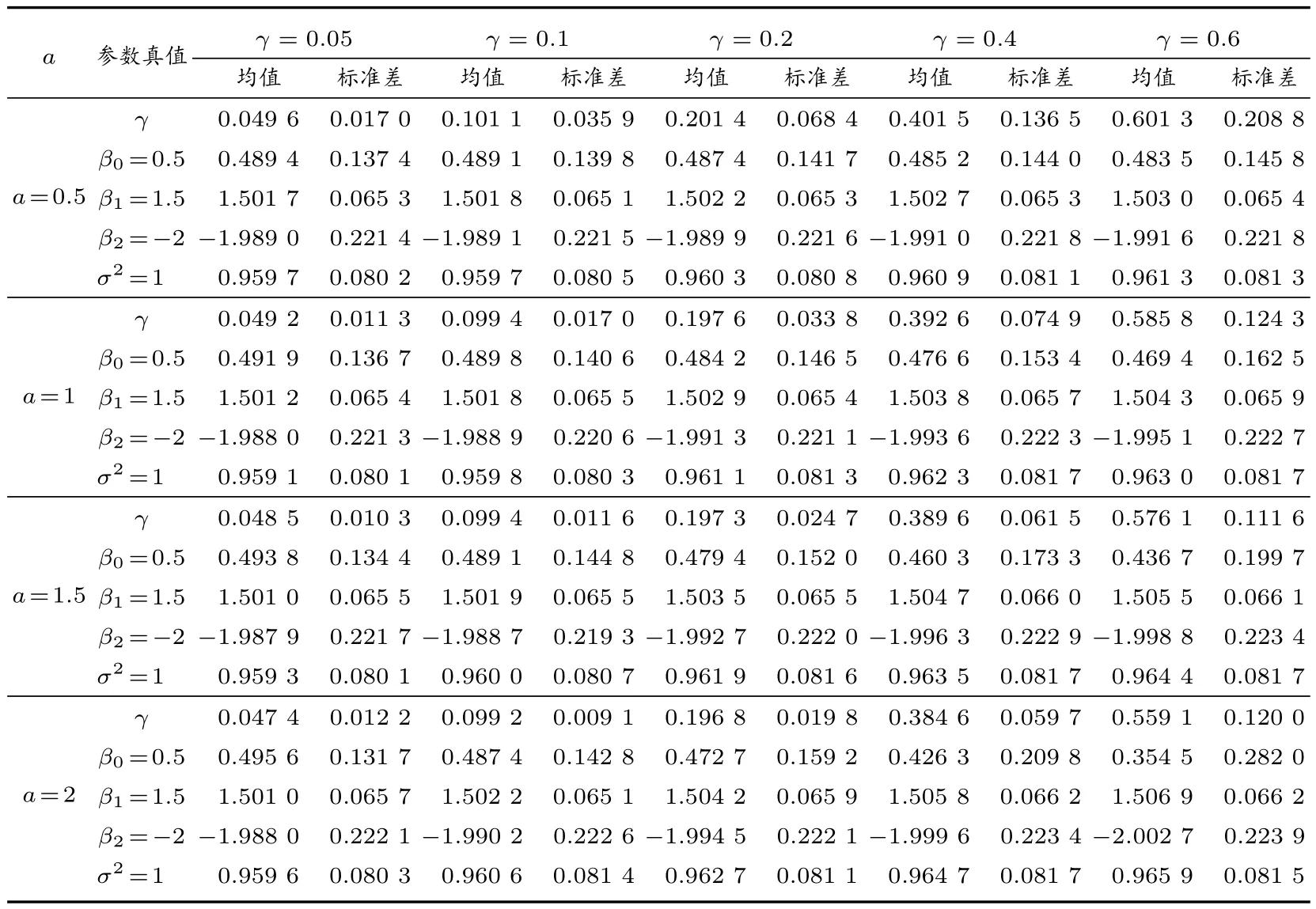
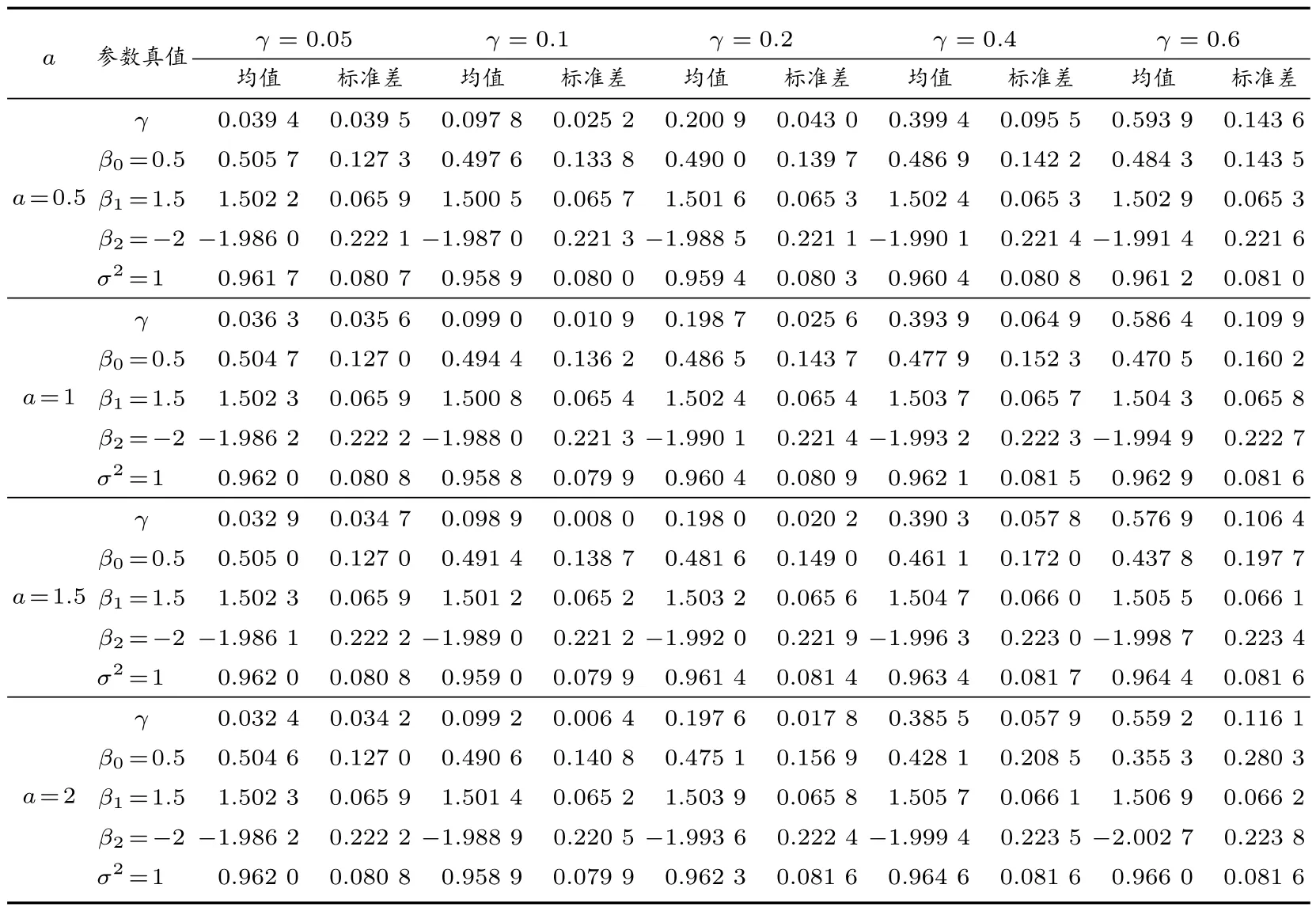
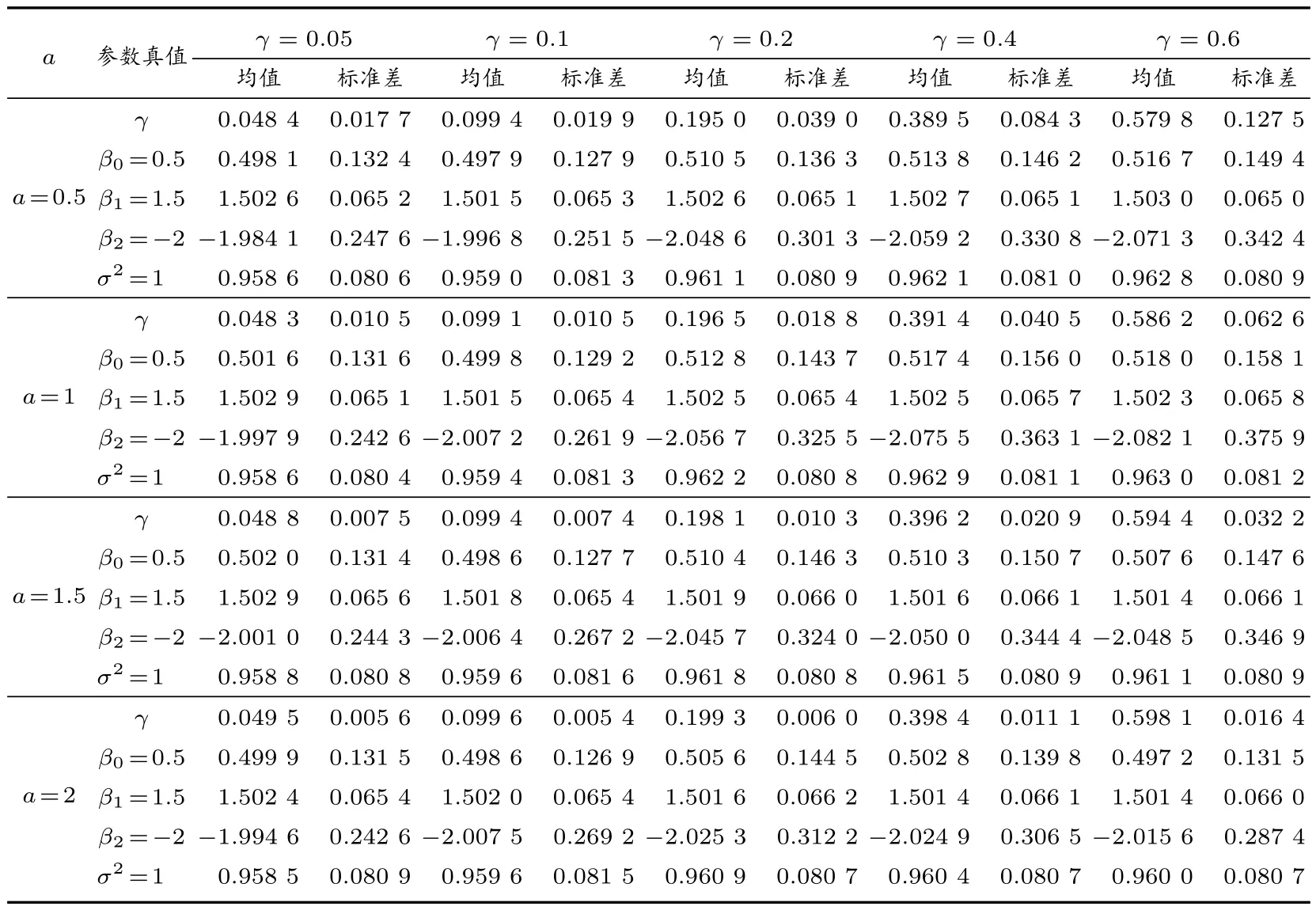
4 实例分析

5 总结与讨论
