考虑样本加权的迁移学习暂态稳定评估模型更新方法
2023-12-28方熙王怀远党然温步瀛
方熙, 王怀远, 党然, 温步瀛
(1. 福州大学电气工程与自动化学院, 新能源发电与电能变换重点实验室, 福建 福州 350108; 2. 陕西飞机工业有限责任公司, 陕西 汉中 723000)
0 引言
随着交直流混联电网的形成、 电力电子技术的发展和具有波动性新能源设备的大规模接入, 对电力系统的暂态稳定性进行分析的难度也在不断增加[1]. 人工智能技术的发展促使学者们探究故障样本特征量和系统暂态稳定性之间的映射关系, 并凭借训练好的机器学习模型进行快速准确的暂态稳定评估[2-3]. 但是, 训练模型的故障样本集仅涵盖有限故障情况, 所得模型无法有效评估某些意料之外的潜在故障. 为了解决上述问题, 迁移学习将训练模型的故障样本和潜在故障分别定义为源域和目标域, 通过提取两者的共同特征并进行知识经验迁移, 达到更新模型的目的[4-6]. 然而, 迁移学习过程并不稳定. 如果两个领域存在较大差异, 难以挖掘相似特征, 模型更新效果就会受到影响[7].
目前, 改善迁移效果的方法主要分为3类[8]. 1) 增加有效源域知识数量. 如, 文献[9]提出一种多源域迁移方法, 利用多重相似性理论与平滑性流形假设, 实现对源域有效数据的扩充. 2) 增加目标领域的样本数量. 如, 文献[10]提出两种基于对抗思想的迁移学习方法. 其中, 基于残差的对抗迁移算法(RAN)对齐不同领域特征并构造自适应分类器, 增强特征的区分性; 基于特征和标签的联合分布对抗迁移算法(FLAN)通过匹配不同领域样本的联合分布, 凸显样本信息的特点. 3) 减少迁移双方数据分布的差异. 如, 文献[11]提出一种基于图形正则化的迁移算法(GTL). 该方法将数据的统计信息和几何信息相结合, 提高潜在因子的平滑性, 改善领域之间数据分布的情况.
在电力系统中, 增加有效源域知识数量会依照扩充规模增大相应的计算量, 与暂态稳定评估的响应需求相悖. 而在实际情况下, 目标域难以获取历史故障数据, 无法有效对该领域内的样本进行补充. 因此, 本研究拟从减小领域之间数据分布差异的角度, 探索改善模型更新效果的方法. 考虑到不同失稳情况所对应的线路故障相似程度均有所不同, 总是存在与目标域相关性较低的源域样本影响知识迁移效果的情况. 本研究通过表征并利用故障之间原始特征的相似性, 提出一种考虑样本加权的迁移学习暂态稳定评估模型更新方法. 该方法既不改变模型更新的迁移过程, 又能对源域的所有故障进行加权, 很好地区分其在迁移过程中的重要程度. 经实验证明, 所提方法是有效的.
1 研究整体思路
在本研究中, 由实验仿真或历史数据库获取的故障情况被称为预期故障. 其为带标注样本, 所构成的源域是知识迁移的主体. 未曾预料到或还未发生过的故障情况被视为潜在故障. 仅少数为带标注样本, 所构成的目标域是迁移学习目标. 在传统迁移学习方法的基础上, 本方法通过样本加权方式对预期故障进行筛选, 改善知识迁移的效果. 所有预期故障相对于潜在故障的原始特征分布差异, 先由一个独立的域判别器进行衡量. 再利用该差异所执行的密度比估计赋予源域中各样本合适的权重,以辨识其在知识迁移中的重要程度. 在迁移学习的过程中, 权重较高源域样本的知识经验会更多迁移至目标域, 使更新后的模型能更好地适应目标域的数据分布. 由源域加权迁移至目标域的评估情况如图1所示.
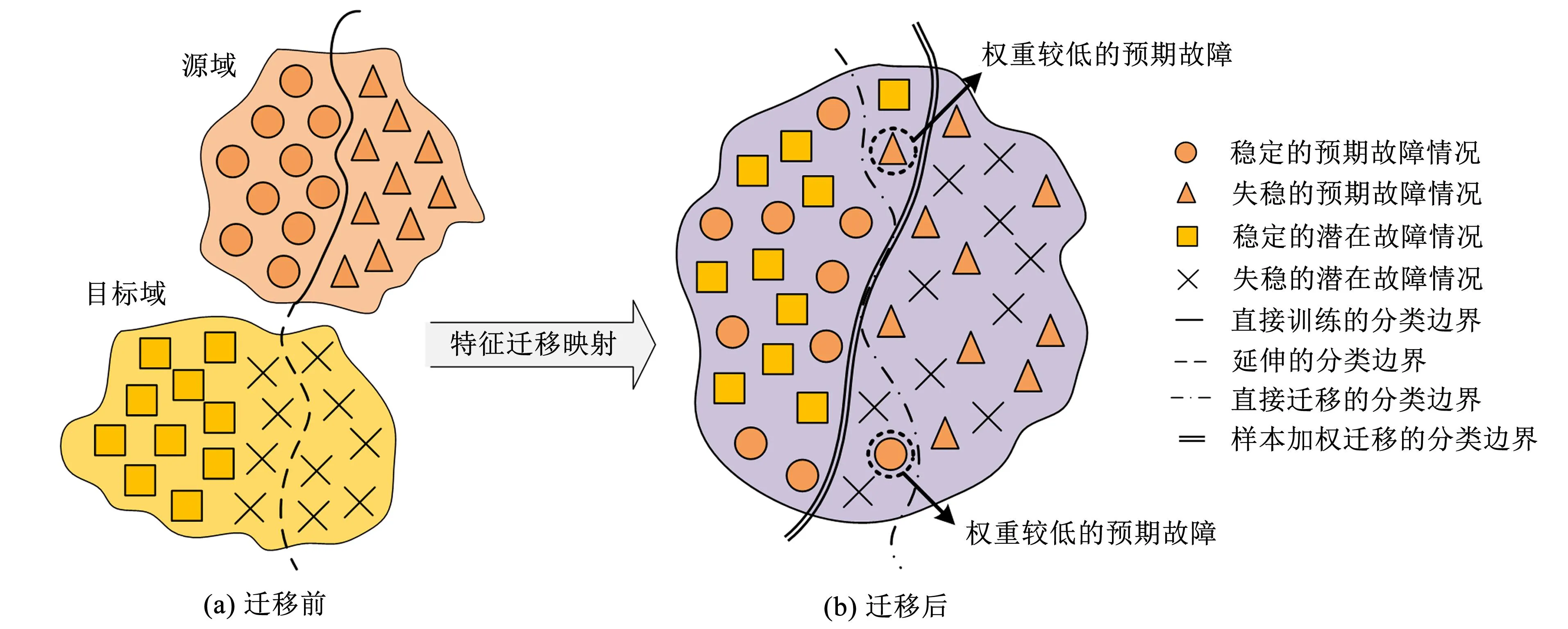
图1 样本加权迁移学习的适用场景Fig.1 Applicable scenario of sample-weighted transfer learning
由图1可知, 在迁移学习前, 源域和目标域数据分布情况存在明显差异. 由预期故障直接训练模型生成的分类边界经过适当延伸后, 仍会对潜在故障造成较多误判. 在直接进行迁移学习后, 故障样本的数据分布会趋于一致, 提高了模型对潜在故障的评估能力. 然而, 部分预期故障和潜在故障的数据分布差异过大, 若同样重视迁移此类故障的知识经验, 将对整体的迁移效果产生影响. 因此, 本研究依据源域各样本和目标域之间的相关程度进行适当加权, 权重较高的预期故障与潜在故障更为相似,蕴含的知识经验会更多迁移至目标域, 从根本上减小不同领域之间数据分布的差异, 进而改善更新后模型的评估性能.
2 建模过程
2.1 长短期记忆网络
长短期记忆网络(LSTM)是循环神经网络(RNN)的一种改进形式[12]. 与RNN相比较, LSTM同时学习时间序列中长期依赖和短期依赖的信息, 可以解决“梯度消失”和“梯度爆炸”等问题. 考虑到故障样本的采样特征与时间序列高度相关, 选用LSTM作为模型框架来深入探索时序特性和暂态稳定性之间的联系.
2.2 最大均值差异
最大均值差异(lMMD)是迁移学习中使用最广泛的一种度量[13]. 与参数准则相比, 最大均值差异计算非参数距离, 避免了昂贵的分布计算代价, 且能够准确衡量两个不同但相关分布之间的差异. 假设p1和p2分别为源域和目标域中样本特征Xs和Xt的概率分布,lMMD的定义式为
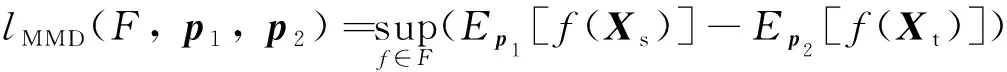
(1)
式中:F被定义为一般再生希尔伯特空间中的一系列映射函数f; sup( )是求取上界的函数, 用于探索不同领域之间最大数据分布差异的上界.
利用再生希尔伯特空间的再生性和内积运算性质, 作为期望无偏估计的均值可以将上式转化为便于计算的一般经验方程. 假设ns和nt分别为源域和目标域的样本数目,lMMD的经验方程为
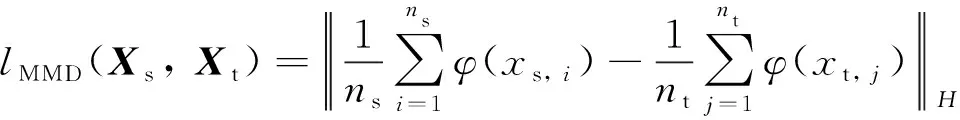
(2)
式中:φ:X→H代表从原始样本空间转移至一般再生核希尔伯特空间的映射关系.
在此基础上, 通过核技巧可以无需显式地表征映射函数φ(x)来求解向量之间的内积, 进一步简化最大均值差异的计算过程. 最终, 对其取平方后, 推导获得的核化方程为
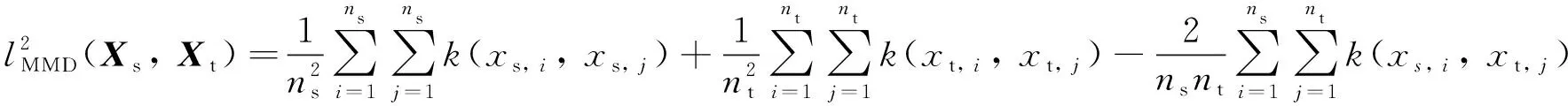
(3)
式中:k(xi,xj)为所有可能的核函数. 由于高斯核函数具有良好泛化能力, 将其选作式(3)的内核参与计算.
综上所述, 相较于其他度量准则,lMMD不仅能够在内积完备的再生核希尔伯特空间中准确反映数据真实分布的差异, 同时也具有计算简单的优势. 因此, 选用lMMD来度量故障样本之间的特征分布差异.
2.3 改进的加权迁移模型更新方法
2.3.1方法背景
在迁移学习的过程中, 源域和目标域之间的相似程度会从源头上影响模型的更新效果. 面对庞大且复杂的预期故障样本集, 传统迁移学习方法默认它们的知识经验同等重要, 而忽视了其中与潜在故障数据分布差异过大的部分样本在迁移中所产生的负面影响. 因此, 本研究通过对预期故障赋予合适的权重, 进一步改善迁移学习更新评估模型的效果.
2.3.2具体实现
本研究采用基于领域自适应的深度迁移学习思想, 通过减小源域和目标域之间数据分布的差异实现知识的迁移. 具体而言, 通过LSTM提取样本特征之后, 源域和目标域会被映射至一个共享的特征空间. 在此空间中, 两个领域的数据分布近乎相同, 并且具有足够的区分性来评估故障的暂态稳定情况. 假设Xs和Ys分别为源域故障的样本特征和实际标签,Xt, l和Yt, l分别为带有标注的少量目标域故障的样本特征和实际标签, 未经加权更新评估模型的目标函数定义为
ltotal=lClassifier+λ·LMMD
(4)
lClassifier=lCLF(C(F(Xs)),Ys)+lCLF(C(F(Xt, l)),Yt, l)
(5)
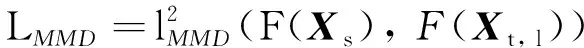
(6)
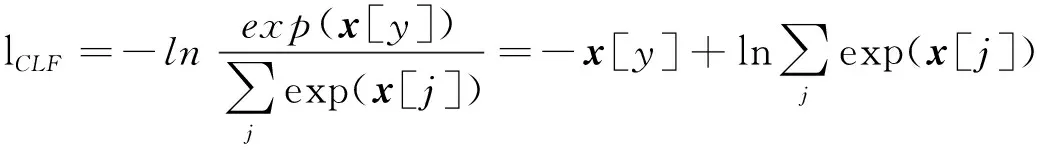
(7)
式中:ltotal为模型更新的总目标函数;lClassifier为源域和目标域中带有标签样本的总交叉熵损失;λ为平衡标签分类损失和特征分布差异的超参数;LMMD为预期故障和潜在故障之间特征分布的差异大小;lCLF为交叉熵损失函数;C( )为生成预测分类标签过程;F( )为特征提取过程;y和x分别为故障样本的实际标签以及经过非线性映射后每个标签类别的预测概率.
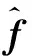

图2 模型更新的整体架构Fig.2 Overall architecture of model updating
为了凸显与目标域相似的预期故障, 在进行知识迁移前, 各源域样本相对于目标域的相似程度需先通过一个独立的域判别器D进行评估. 考虑到样本的联合特征分布情况更能体现出预期故障和潜在故障之间的差异[7], 该判别器将原始特征X和对应的实际暂态稳定标签Y均作为输入, 尝试区分输入样本是来自源域(域标签为0)还是目标域(域标签为1).假设PS(X,Y)和PT(X,Y)分别代表源域和目标域中故障样本的联合分布, 则该域判别过程可表示为
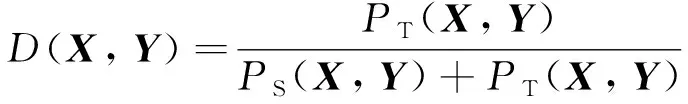
(8)
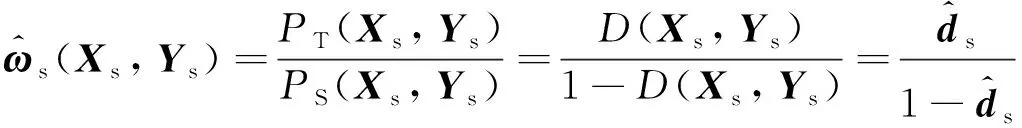
(9)
最终, 源域样本经过加权之后, 更新模型的目标函数(4)和(5)可以修改为
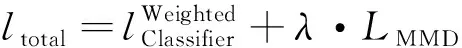
(10)

(11)
与等式(4)和(5)相比, 修改后的目标函数在源域的交叉熵损失部分对各预期故障样本进行适当加权. 在更新模型的过程中, 与目标域相似程度较高的源域知识会更加得到重视. 如此能够提高评估模型对潜在故障的适应能力, 改善迁移学习的效果.
3 实验过程与结果分析
选择IEEE-39节点电力系统和华东某地区的实际电力系统进行测试. 为验证所提方法的有效性, 采用4种评价指标对实验结果进行分析. 即

(12)
式中:PACC为模型预测的整体准确率;NTP和NTN分别代表稳定样本和失稳样本正确预测的数目;NFN和NFP分别表示稳定样本以及失稳样本错误评估的数目;PFN为稳定样本的评估错误率;PFP为失稳样本的评估错误率;F1为评价模型性能的一个重要全局指标.
3.1 IEEE-39节点电力系统
3.1.1样本集的构建
选用IEEE-39节点系统进行测试, 并通过PSD-BPA仿真软件对12 375种故障情况进行模拟, 共生成7 010例稳定样本和5 365例失稳样本. 在仿真过程中, 系统的运行状态存在90%、 95%、 100%、 105%和110%这5种负荷水平; 故障发生的地点分别位于单条线路全长的10%、 50%和90%处; 故障的类型均为永久性三相短路; 故障的持续时间为100~300 ms, 共有10个故障清除时刻. 为满足暂态稳定评估的时间需求, 仅选择故障发生瞬间、 故障清除瞬间以及故障清除后0.05和0.10 s对应时段的采样数据作为故障样本的原始特征. 其中, 每个采样周期内原始特征的种类和个数均相同.
3.1.2加权迁移的有效性分析
所有的电力系统都可以将输电线路划分为源域和目标域两个类别. 源域线路经常发生故障, 具有大量的历史故障数据, 可以涵盖此类线路中发生的各种故障情况. 目标域线路难以获取故障信息, 只有少数带有实际标签的故障样本, 不能很好地表征此类线路中剩余的潜在故障情况. 本实验随机抽取6条线路共计2 250个带有实际标签的预期故障作为源域, 并从剩余的线路中随机选取2条线路共计750个故障样本作为目标域. 假设在目标域中仅有25个带有实际标签的故障样本可以参与模型更新, 剩余潜在故障均作为测试集衡量评估模型性能. 表1给出多种试验情况下暂态稳定评估模型的测试结果.
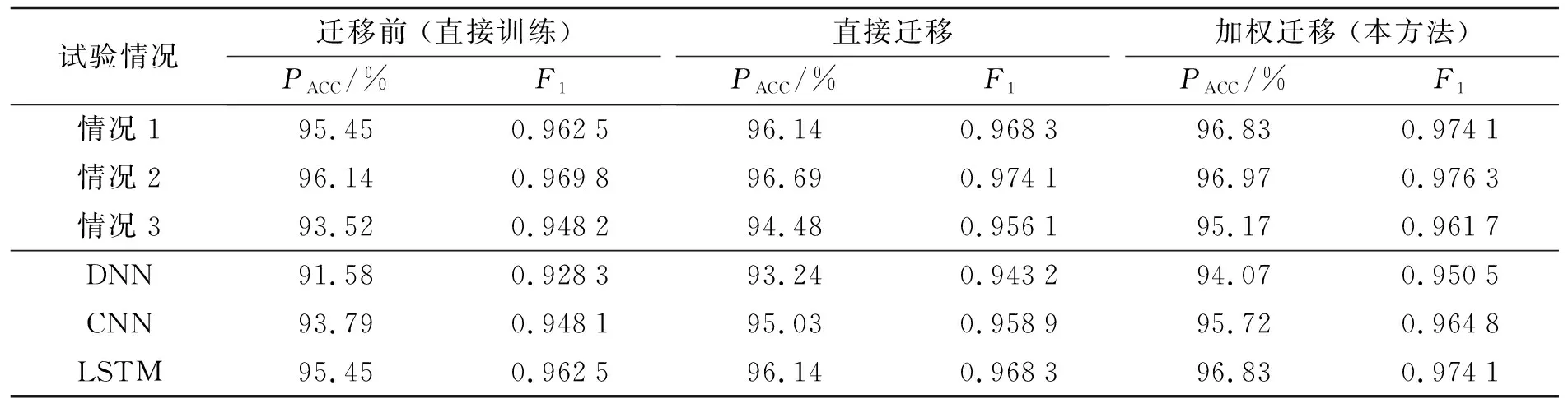
表1 不同试验情况下的评估结果Tab.1 Evaluation results under different test cases
如表1所示, 在均以LSTM为模型框架的基础上, 情况1~3对应行分别表示3种随机抽取且不重复样本情况下评估模型的测试结果. 从中可见, 在多种样本情况下, 迁移学习均能在训练模型的同时令源域和目标域内故障样本的特征分布趋近于一致, 提高模型的评估性能. 在此基础上, 所提方法通过样本加权的方式在迁移过程中对与目标域相关性较高的预期故障进行强调, 与直接迁移方法相比, 进一步提高了评估模型的整体预测准确率, 有效改善模型更新的迁移效果.
此外, 在保证源域和目标域均为情况1的抽样条件下, 为了展示所提加权迁移方法的普适性, 本研究还将其引入深度神经网络(DNN)和卷积神经网络(CNN)中进行了相同测试. 从横向对比测试结果可以看出, 所提方法在迁移学习前先对所有预期故障进行加权筛选, 避免其中一些特征分布与目标域相差过大的故障样本对知识迁移产生负面影响, 使得不同框架下的模型均能对潜在故障达到更好的评估效果, 具有良好的普适性. 另一方面, 从纵向对比测试结果可以看出, 相比于DNN和CNN, LSTM在相同条件下拥有更高的PACC和F1指标. 这种现象表明, LSTM能够更好地发掘样本时序特征和暂态稳定性之间的联系, 更适合作为评估模型的基础框架, 对故障样本的原始特征量进行提取与映射.
3.1.3不同失稳故障对加权迁移的影响
不同输电线路的故障情况存在差异, 对应故障样本的特征分布也各不相同. 然而, 由线路故障所导致的暂态失稳类型却十分有限. 因此, 本实验拟从系统的暂态失稳情况出发, 探究其对加权迁移所产生的影响.
在IEEE-39节点电力系统中, 由线路故障所引发的暂态失稳现象可以大致归纳为38号母线单机失稳、 37和38号母线两机失稳以及30~38号母线多机失稳这3种情况. 本实验从各失稳情况中分别选取1条线路共计1 125个预期故障构成源域, 并从剩余的线路中挑选1条线路共计375个故障作为目标域. 假设只有25个目标域样本带有实际的暂态稳定标签, 剩余的潜在故障均作为测试集来衡量评估模型的性能. 目标域线路处于3种不同的失稳情况下, 评估模型的测试结果如图3所示.

图3 不同失稳情况的测试结果Fig.3 Test results of different instability cases
由图3可知, 通过本方法对源域样本进行适当加权之后, 在稳步提升预测模型整体准确率的同时,稳定样本和失稳样本各自的评估错误率均有所下降, 改善了迁移学习的效果. 此外, 本研究还对加权迁移过程中各暂态失稳情况下源域线路的权重赋予情况进行考察. 以所有线路的平均权重之和作为基准, 各失稳情况所对应线路的平均权重标幺值的分布情况如表2所示.
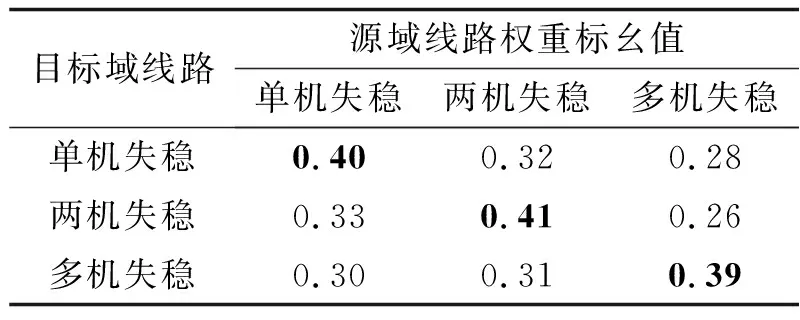
表2 源域各线路的权重分布情况Tab.2 Weight distribution of each line in source domain
从表2所列的实验结果可以看出, 与目标域线路拥有相同暂态失稳情况的源域线路被赋予较高的权重. 这种现象表明, 引发相同失稳情况的线路故障之间相似程度较高, 样本特征的分布情况也比较类似, 更适合进行知识经验的迁移. 因此, 故障样本的暂态失稳情况是影响迁移效果的一个重要因素. 在更新评估模型的过程中, 若选用与目标域具有相同暂态失稳情况的线路故障作为源域, 源域样本的整体权重就会得到提升, 相当于扩充有效的源域知识数量, 可以达到更好的迁移效果.
3.2 大规模实际电力系统
为了验证所提方法在实际应用中的适用性, 以华东某地区的实际电力系统为例进行测试. 该系统共包含705台发电机组, 带有6 040条母线和5 599条输电线路. 在运行过程中, 系统的工作频率始终维持在50 Hz, 且处于100%系统容量的负荷水平. 在此情况下, 输电线路所发生故障的详细情况如表3所示.

表3 输电线路故障的详细情况Tab.3 Details of faults in transmission lines
本实验将150条输电线路的所有故障情况均视为源域, 并从剩余的输电线路中挑选20条线路作为目标域. 假设目标域中只有10%的少量故障带有实际标签, 剩余90%的潜在故障均用于评估模型性能. 在该实际系统下, 本方法对知识迁移的改善效果如表4所示.
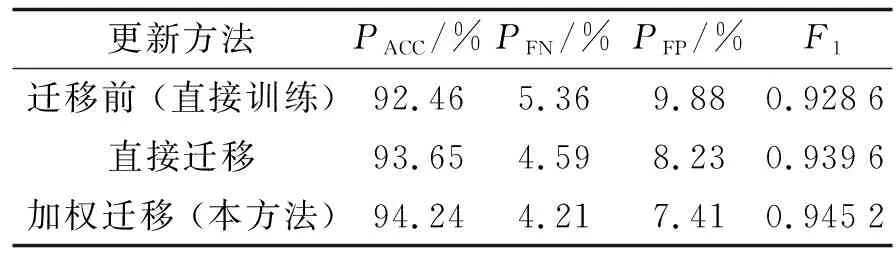
表4 不同更新方法的测试结果Tab.4 Test results of different updating methods
由表4可以看出, 在实际系统下, 源域中潜在有害的预期故障会对知识迁移的效果产生影响. 相比于将源域样本的知识经验直接迁移至目标域, 本方法在迁移之前先对源域样本赋予适当的权重进行筛选, 有效地提高了模型的评估能力.
4 结语
由预期故障和潜在故障之间的相关程度, 提出一种考虑样本加权的迁移学习暂态稳定评估模型更新方法. 在衡量源域和目标域之间故障样本的原始特征分布差异后, 结合两个领域之间的联合概率密度比, 对源域各样本进行适当地加权来过滤潜在有害的预期故障, 以达到改善迁移学习效果的目的. 在IEEE-39节点系统和华东某地区的实际系统中, 对于不同的源域和目标域样本集, 本方法均能有效改善知识迁移的效果, 让更新后的模型具备更好的暂态稳定评估性能.
