面向特征融合与知识蒸馏的恶意软件分类
2023-12-28庄贤陈志豪蔡铁城陈开志廖祥文
庄贤, 陈志豪, 蔡铁城, 陈开志, 廖祥文
(福建省网络计算与智能信息处理重点实验室, 数字福建金融大数据研究所, 福州大学计算机与大数据学院, 福建 福州 350108)
0 引言
恶意软件分类[1]旨在提取恶意软件的关键特征, 并用其来构建分类器, 从而对该恶意软件的类别进行判断, 本质上是一个多分类任务. 对恶意软件进行分类, 可以有效分析不同恶意软件的演变过程, 更好地保障软件应用的安全性. 当前, 随着代码混淆等技术的不断发展, 恶意软件分类面临着更大的挑战. 传统的恶意软件分类方法难以有效应对新型恶意软件[2], 基于深度学习的恶意软件分类方法则因其良好的扩展性和稳定性受到广泛关注[3]. 目前, 基于深度学习的恶意软件分类方法, 依据恶意软件特征提取方法的不同, 主要可以分为如下两类.
1) 基于恶意软件特征的分类方法. 通过静态分析技术和动态分析技术分别提取恶意软件中的静态特征和动态特征, 用于训练不同的模型. Krcál等[4]通过静态分析技术来提取字节序列, 用于训练所提出的深度神经网络模型. Xie等[5]通过静态分析工具提取出汇编指令, 利用LSTM获得每个块的代表性特征, 并结合注意力机制来减少垃圾指令. 郑锐等[6]利用动态分析技术提取API调用序列, 通过双向LSTM对前后API的调用概率关系进行建模. 这类方法需要人工制定特征工程来提取恶意软件特征, 分类器的构建具有较高的成本. 此外, 在新型恶意软件数量激增的情况下, 特征工程难以保持良好的特征抽取能力, 导致模型性能难以提升.
2) 基于恶意软件图像的分类方法. 通过恶意软件可视化算法, 将恶意软件可视化为图像, 并利用卷积神经网络, 从图像中自动抽取恶意软件特征, 并进行学习和分类. Nataraj等[7]最早提出将恶意软件可视化为图像的方法, 根据恶意软件文件的大小, 将恶意软件转换为二维数组, 并生成相应的灰度图. Yuan等[8]则通过计算字节传输概率矩阵, 将恶意软件转换为马尔可夫图, 将其用于训练所提出的DCNN模型(改良的VGG16模型). Kalash等[9]通过VGG16模型, 从灰度图中抽取特征, 并进行学习与分类. Vasan等[10]将灰度图映射成彩色图像, 并对图像进行数据增强, 进而微调预训练的VGG16模型. Aslan等[11]集成两个预训练卷积神经网络, 构建一种混合模型, 从灰度图中抽取特征, 并进行学习和分类. Parihar等[12]利用3个不同的卷积神经网络, 分别从灰度图中抽取特征, 将其用于模型的训练和分类. 这类方法仅通过单一图像语义表示来抽取恶意软件特征, 导致模型无法捕获恶意软件序列特征和分布特征之间的依赖关系, 且模型的规模较大, 对计算资源较为依赖.
针对上述问题, 本研究提出面向特征融合与知识蒸馏的恶意软件分类方法, 基于注意力机制, 模型对不同特征之间的关联性和依赖关系进行挖掘与捕获. 同时, 利用知识蒸馏来降低模型的规模, 以期减少模型对计算资源的消耗.
1 模型方法
本研究模型的框架如图1所示, 共由6个部分组成. 1) 编码层. 通过不同的可视化算法, 将恶意软件二进制序列分别可视化为灰度图和马尔可夫图. 2) 特征抽取层. 使用残差网络, 分别从编码层生成的灰度图和马尔可夫图中, 自动抽取恶意软件的序列特征和分布特征. 3) 特征融合层. 由自注意力模块和双重注意力(attention on attention, AoA)模块[13]构成, 利用注意力机制, 挖掘两种不同特征之间的关联性. 4) 特征修正层. 利用高速神经网络[14], 对特征抽取层和特征融合层的输出向量进行修正. 5)分类层. 通过3层感知机输出预测概率分布. 6) 模型压缩. 首先, 教师网络向多个学生网络进行知识迁移; 然后, 学生网络互相之间进行协作学习; 最后, 选择性能最优的学生网络作为最终的分类模型.

图1 模型框架图Fig.1 Overall structure of model
1.1 编码层
图2为将恶意软件可视化为灰度图和马尔可夫图的过程.

图2 恶意软件可视化过程Fig.2 Malware visualization process
首先, 计算每8位二进制的字节大小(A), 将恶意软件二进制序列转换为字节向量; 然后, 分别根据Nataraj等[7]和Yuan等[8]的方法, 将字节向量重塑为二维数组和计算字节传输概率矩阵; 最后, 通过二维数组和概率矩阵生成对应的灰度图和马尔可夫图. 字节大小(A)的计算公式为

(1)
式中:ai为8位二进制位中的第i位二进制位.
1.2 特征融合层
自注意力模块对恶意软件的序列特征和分布特征进行自注意力计算, 捕捉不同特征之间的依赖关系. 该模块将序列特征向量和分布特征向量进行拼接, 得到输入向量(fatt_in), 分别使用WQ、WK、WV这3个矩阵作为Query、 Key、 Value, 将其映射到相应的特征空间; 然后再进行注意力计算, 得到融合恶意软件的序列特征和分布特征的融合向量(fatt_out). 融合向量的生成过程可用公式表示为
fatt_out=Att(WQfatt_in,WKfatt_in,WVfatt_in)
(2)
式中: Att(·)为自注意力函数.
fatt_out可能存在结果向量与查询向量不匹配的情况, 导致误导信息的产生, 这会影响模型的性能. 将fatt_in和fatt_out作为输入, 利用AoA进行二次注意力计算, 可以过滤掉无关的注意力结果. 最终特征融合层的输出向量, 即AoA的输出向量(fAoA_out), 可定义为
fAoA_out=Dropout((fatt_out⊕fatt_in)W1+b1)⊗δ((fatt_out⊕fatt_in)×W2+b2)
(3)
式中:W1和W2为可训练的矩阵;b1和b2为偏差向量;δ(·)为Sigmoid激活函数; ⊗和⊕分别代表矩阵点乘和拼接. 为防止参数过多带来的过拟合, 本研究以50%的概率删除输出向量.
1.3 特征修正层
为充分利用恶意软件的序列特征和分布特征, 同时增强融合模块的泛化性, 利用高速神经网络的门机制, 可以对不同的特征向量进行修正, 其输出向量定义为

(4)
式中:x为特征抽取层得到的恶意软件的序列特征向量、 分布特征向量或特征融合层得到的融合特征向量; 函数H(·)表示的是一个线性层和非线性层的组合; 矩阵WH、WT为线性层的可学习参数; 非线性层使用Sigmoid激活函数. 函数T(x)的表达式为
T(x)=δ((WT)Tx+bT)
(5)
式中:bT为-1或者-3. 由定义可知, 高速神经网络将会直接保留输入特征向量中的有效信息, 并对其中的无效信息进行映射, 进一步增强特征向量的有效性.
1.4 模型压缩
模型压缩的过程可分为4步. 1) 预训练特征抽取层为ResNet-34的大模型, 对其进行非结构化剪枝[15]后, 将其作为教师网络; 2) 固定教师网络参数, 对多个特征抽取层为ResNet-18的学生网络进行知识迁移[16]; 3) 多个不同的学生网络互相之间进行协作学习; 4) 选择性能最优的学生网络作为最终的分类模型, 用于输出分类结果.
知识蒸馏和协作学习的核心, 都是用于更新学生网络参数的损失计算. 当对第i个学生网络进行参数更新时, 对应的损失(LTL)将由散度值(L1)和混合损失值(L2)进行加权计算得到, 其表达式为

(6)
L2=Mix Loss(pi,y)
(7)
LTL=αL1+βL2
(8)
式中:DKL(·)代表KL散度函数;pi为第i个学生网络的输出向量; 在知识蒸馏阶段和协作学习阶段,pk分别为教师网络和性能最优学生网络的输出向量;y为恶意软件类别对应的数值;α+β=1, 且α>>β.混合损失函数的定义为
Mix Loss(pi,y)=LCE(pi,y)+LFL(pi,y)+LOHEM(pi,y)
(9)
式中:LCE(·)、LFL(·)和LOHEM(·)分别代表交叉熵损失函数Cross Entropy、 聚焦损失函数Focal Loss[17]和难样本损失函数OHEM[18].
优化器选用随机梯度下降(stochastic gradient descent, SGD), 通过SGD来更新模型的参数, 最小化训练数据的损失.
2 实验设计
2.1 数据集描述
本研究采用微软数据集[19]和CCF数据集[20]来验证模型的性能. 微软公开数据集来源于微软于2015年在Kaggle举办的大型恶意软件分类竞赛, 该数据集共有21 741个恶意软件样本, 其中的10 868个样本为训练集, 剩下的10 873个样本为测试集. 该数据集中的每个样本都分别属于9个不同的恶意软件类别或家族, 训练集中的样本数(Ntrain)分布情况如图3(a)所示. CCF公开数据集来源于CCF于2021年举办的基于人工智能的恶意软件家族分类竞赛, 训练集中共有5 841个恶意软件样本, 分别属于10个不同的恶意软件类别或家族, 其样本数分布如图3(b)所示. 两个数据集中的样本均包含去除PE头的PE文件和.asm文件, 分别保存恶意软件的十六进制序列和反汇编代码.
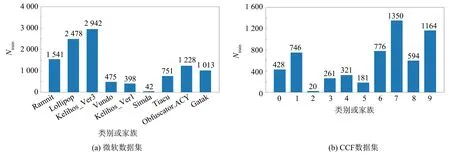
图3 数据集训练样本分布Fig.3 Dataset training sample distribution
2.2 评价指标
对于微软数据集, 可以将测试集的测试结果上传到Kaggle, 官方将以下式计算多分类对数损失. 即
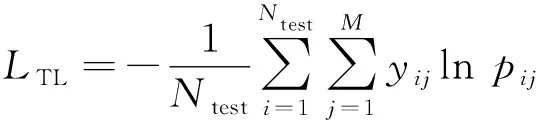
(10)
式中:Ntest为测试集的样本数;M为恶意软件类别数; 当样本i属于y时,yij为1, 否则为0;pij为分类器预测的样本i属于类别j的概率.
对于CCF公开数据集, 只能在训练集上进行两折交叉验证, 采用精确度(PACC)来衡量模型的性能. 其计算式为
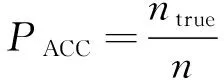
(11)
式中:n表示预测样本的总数;ntrue表示做出正确预测的样本总数.
2.3 基准模型
选取5个模型作为基准模型. 1) M-CNN模型[9]. 将灰度图作为输入, 对 VGG16模型进行训练. 2) IMCFN模型[10]. 将灰度图映射为彩图, 并对图像进行数据增强, 用于微调VGG16模型. 3) DCNN模型[8]. 将马尔可夫图作为输入, 用于训练改良的VGG16模型. 4) NMCD模型[11]. 将灰度图作为输入, 训练所提出的一种基于深度学习的新的混合模型. 5) S-DCNN模型[12]. 将灰度图作为输入数据, 训练所提出的由3个不同卷积神经网络组成的模型.
2.4 参数设定
本研究模型需要50个迭代轮次才能完成训练, 且每训练20个迭代轮次, 都需要将学习率降低10倍. 批大小、 学习率、 权重衰退、 动量、 非结构化剪枝率、 学生网络数据的最优参数分别为8、 0.005、 0.000 5、 0.9、 40%、 4.
3 实验结果与分析
3.1 有效性实验
为验证本研究模型的有效性, 分别测试该模型和基准模型在微软数据集上的Loss和在CCF数据集上的PACC, 如表1所示. 其中, 基准模型的实验结果均是根据对应模型原论文进行复现得出的结果. 在基准模型中, DCNN模型的参数量最小, 且与本研究模型的参数量最为相近, 但该模型的性能明显不如本研究模型. 性能最好且计算量最低的基准模型是NMCD模型, 但该模型的参数量明显高于本研究模型. 由此可知, 相较于基准模型, 本研究模型可以在降低模型规模和计算量的同时, 显著提升模型性能.

表1 各模型在微软和CCF数据集上的实验结果对比Tab.1 Comparison of experimental results of various models in Microsoft and CCF datasets
3.2 单输入实验
表2为通过不同卷积神经网络, 从灰度图或马尔可夫图中抽取特征并进行分类的实验结果. 在以灰度图作为输入数据训练的模型中, 与VGG16模型相比, VGG19模型的性能显著降低, 而ResNet-34模型的性能显著提升. 在以马尔可夫图作为输入数据构建的模型中, 与VGG16模型相比, VGG19模型的性能显著降低, DCNN模型的性能略有提升, ResNet-34模型的性能显著提升. 这主要是因为, 与VGG16模型相比, VGG19模型虽然有更深层的网络结构, 但其全连接层的神经元梯度消失或者爆炸, 会导致模型性能的大幅降低. DCNN模型性能会有略微的提升, 是因为该模型的全连接层具有较少的神经元. 在ResNet模型的网络结构中, 残差块的恒等映射可较好地减少模型退化问题所带来的影响, 该模型可以从图像中抽取到更为丰富的图像语义特征, 因此其性能得到有效提升.

表2 单输入实验结果Tab.2 Experimental results of single input
3.3 消融实验
为验证本研究模型中特征融合层和特征修正层的有效性, 进行相应的消融实验, 分别测试不同结构下模型的LTL和PACC, 结果如表3所示. 可以看出, 特征融合层和特征修正层都可以进一步提升模型性能, 同时包含特征融合层和特征修正层的模型, 其性能最优. 这主要是因为, 特征抽取层通过残差网络从灰度图和马尔可夫图中抽取到的特征向量, 分别具备恶意软件的序列特征和分布特征. 特征融合层利用注意力机制对这两种不同特征进行注意力计算, 可以挖掘不同特征之间的关联性, 捕获不同特征之间的依赖关系. 此外, 特征修正层利用高速神经网络, 对分类结果产生误导的向量进行映射, 进而对输出向量进行修正.
3.4 模型压缩实验
表4为教师网络、 直接训练的学生网络和通过本研究模型压缩算法训练的学生网络的参数量、 浮点运算数、 单个样本预测时间(t)、LTL和PACC. 可以看出, 与教师网络相比, 学生网络具有更小的规模、 计算量和更短的预测时间. 与教师网络相比, 直接训练的学生网络, 其性能将会有所下降, 通过本研究模型压缩方法训练的学生网络, 其性能则会有所提升. 这主要是因为, 通过本研究模型压缩算法对学生网络进行训练时, 教师网络会向其传递有效的知识点, 经此训练的学生网络可以比从头训练的学生网络更快地找到真正有用知识点. 不同学生网络互相之间进行协作学习, 可及时对性能较差的学生网络进行调整. 此外, 非结构化剪枝操作对蒸馏过程起到正则化的作用, 混合损失函数中所包含聚焦损失函数和难样本损失函数, 可以对困难恶意软件样本进行挖掘.
3.5 可解释性实验
为验证通过卷积神经网络从恶意软件图像中抽取特征进行分类的科学性, 实验生成“熊猫烧香”恶意软件的热力图, 并根据热力图中高热值区域像素点的偏移, 定位原始文件中对最终分类结果产生较大影响的字节. 图4为“熊猫烧香”对应的灰度图和热力图. 图5为热力图中热值较高区域所对应的字节通过IDA Pro反汇编的结果. 该区域的字节所对应的字符串为“熊猫烧香”病毒专有的字符串, 具有唯一性. 由此可见, 基于恶意软件图像和卷积神经网络的分类模型可以较为准确地捕获到恶意软件中的关键字节并用于分类.
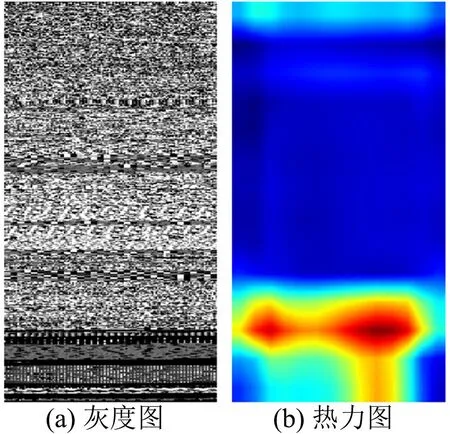
图4 “熊猫烧香”的灰度图和热力图Fig.4 Grayscale and thermograph of “Worm.WhBoy”
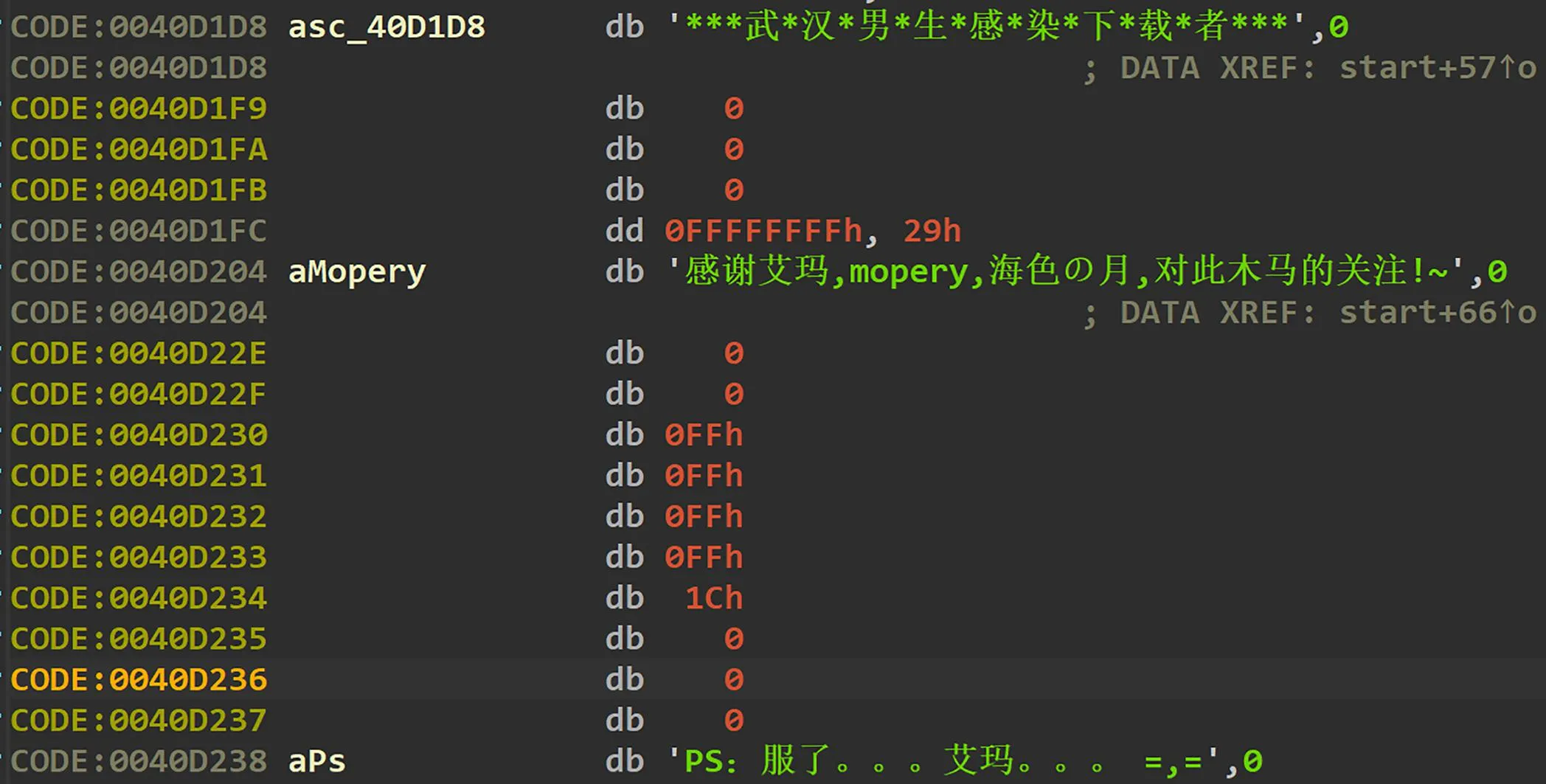
图5 “熊猫烧香”的专有字符串Fig.5 Proprietary string of “Worm.WhBoy”
4 结语
提出一种面向特征融合与知识蒸馏的恶意软件分类方法, 基于注意力机制融合恶意软件的序列特征和分布特征, 对不同特征之间的关联性进行挖掘. 通过知识蒸馏和协作学习技术, 降低分类模型的参数量和计算量. 在微软和CCF两个公开数据集上的实验结果表明, 与基准模型相比, 本研究模型具有更加良好的性能和更小的规模. 此外, 实验分析证明, 卷积神经网络可以从恶意软件图像中抽取关键特征, 并将其用于模型学习和分类. 后续研究将在对恶意软件进行可视化之前, 对恶意软件中无用的垃圾字节进行消除, 以降低作为模型输入的恶意软件图像噪声.
