融合知识共享和精英反向学习的成长优化算法
2023-12-25吴美莲吴杭蕖苏媛媛游方楷贾鹤鸣
吴 迪, 吴美莲, 吴杭蕖, 苏媛媛, 游方楷, 贾鹤鸣
(1.三明学院教育与音乐学院,福建 三明 365004;2.三明学院信息工程学院,福建 三明 365004)
随着科学技术的持续发展,实际问题的复杂性不断提高,对优化技术的需求愈发明显,元启发式优化算法由于其简单性、灵活性和无推导机制受到众多学者的关注[1].近年来,国内外研究者在智能优化领域取得一系列重要的研究成果.这些研究成果为后来者提供新的思路和实践指导,并在各个领域中得到广泛应用,是当今智能优化算法领域发展的主要动力,为智能优化算法领域作出杰出的贡献.现今常见的元启发式算法如教与学优化算法(teaching-learning-based optimization algotithm,TLBOA)[2]、基于知识共享的优化算法[3]、粒子群优化算法(particle swarm optimization algotithm,PSOA)[4]、鲸鱼优化算法(whale optimization algorithm,WOA)[5]、黑猩猩优化算法(chimpanzee optimization algorithm,COA)[6]、海鸥优化算法(seagull optimization algorithm,SOA)[7]、算术优化算法(arithmetic optimization algorithm,AOA)[8]、萤火虫优化算法(fire-fly algorithm,FA)[9]等,在不同的优化问题中具有各自的特点和应用范围.然而,无免费午餐(no-free-lunch, NFL)[10]理论的证明,世上还暂且不存在一种通用的优化算法可以解决所有的工程问题.这是因为不同的问题具有独特的特征、目标和约束条件,因此需要根据具体情况选择合适的优化算法,在应用优化算法时,选择合适的算法来解决具体的工程问题非常重要.并且可以通过混合模式和融合改进策略,对传统的优化算法进行改进,以提高算法的性能和效果[11].
2023年,张庆科等[12]提出一种创新的群智能优化算法,将其命名为成长优化(growth optimizer, GO)算法.该算法的设计灵感源自个体在成长过程中的学习与反思.在学习阶段中,对于每个个体,GO算法利用来自5 个不同特定个体的四种类型的搜索方向信息,并结合适应度值和欧氏距离的概念自适应地平衡这四种方向信息.这种自适应平衡的方法使得GO算法在选择搜索方向时能够更准确地权衡不同的信息,并且显著降低由于错误方向信息的干扰而导致算法陷入局部最优解的机会.通过综合考虑多个方向的信息,GO算法能够在探索解空间时更好地平衡全局探索和局部收敛之间的权衡关系.在反思阶段中,GO算法利用各种计算方式来记录和更新个体的位置.这个过程可以帮助个体在优化过程中进行自我调整和修正,以提高算法的性能和适应能力.对于一般的优化问题,GO算法展现出较优的全局探索和收敛能力.然而,在处理一些复杂的函数测试时,GO算法可能会面临局部最优解的困境.这种情况下,算法可能会陷入某个具体的区域而难以跳出,导致无法找到全局最优解.这是一个需要注意的局限性,对于复杂问题,可能需要结合其他算法或策略来进一步提高GO算法的性能和效果.
针对上述不足,提出融合知识共享和精英反向学习的成长优化算法(KSOBLGO).首先,传统GO 算法是通过随机方式产生种群个体的位置,种群初始化方式可能导致多样性差和不均匀分布在解空间的问题,因此需要改进算法的种群初始化方式.在基于纵横交叉和精英反向学习的鲸鱼优化算法[13]中,采用精英反向学习构造精英个体的反向解,增加种群的多样性,扩展种群的搜索范围,以更好地探索解空间.文献[14]在研究鲸鱼优化算法时,使用精英反向学习策略和Lévy 飞行的方法来对初始化种群进行优化,以增加种群的多样性.在文献[15]中,针对算法过早收敛,初始化种群多样性低的问题,引入精英反向学习和HHO 算法相结合.文献[16]将柯西变异、反向学习策略与麻雀优化算法相融合,提高麻雀优化算法的全局寻优能力.借鉴上述文献的改进思想,通过精英反向学习生成反向解,增加种群多样性,待进入学习阶段后,探索个体间差距并进行学习,之后进入反思阶段,当前个体将会由优秀个体进行引导,弥补自身的不足,若自身某方面的知识无法弥补时,则会选择放弃以往学习的知识,重新进行系统的学习.最后进入知识共享阶段,进行适应度划分,平衡KSOBLGO算法的局部搜索能力和全局搜索能力,通过13个基准测试函数优化实验验证KSOBLGO算法的优化性能.
1 成长优化算法
在GO算法中,个体的社会结构与GR(适应度值)相关,通过P1将其分为三个层次.该结构由上层(包括领导和精英)、中层和底层组成.上层中排名最高的领导者是全局最优解,排名在2到P1范围内的个体称为精英,为全局次优解;排名在P1+1 和N-P1之间的个体代表中层成员;排名位于N-P1+1 和N之间代表底层成员,其中:N为社会成员人数.当P1=5 时可以保证算法的高效、稳定的性能.GO 算法主要分为学习阶段和反思阶段.学习阶段是指个体找到其他个体之间的差距并进行学习,反思阶段是指个体使用不同的策略来弥补自身的不足.
1.1 初始化种群
成长优化算法和大多数算法一样,通过解空间边界范围与维度初始化种群.使用式(1)对种群中第i个个体进行初始化.即
其中:Xi为第i个个体;ub和lb表示搜索域的上边界和下边界;rand表示一个介于0和1之间的伪随机数.
1.2 学习阶段
不同个体之间可能存在一定的差距,造成这种差距的原因有很多,如果能探索差距的原因,并且从中学习就可以极大地促进个体的成长.主要的差距分为四类:领袖和精英成员之间的差距(Gap1),领袖和底层成员之间的差距(Gap2),精英成员和底层成员之间的差距(Gap3)以及两个随机个体之间的差距(Gap4).其中将Gapk(k=1,2,3,4)设为第k类差距.对于第i个个体Xi,每一类的差距公式描述为
其中:Xbest代表社会的领袖;Xbetter是精英成员之一;Xworse是底层成员之一;XL1和XL2都是与第i个个体Xi不同的随机个体.
为反映差距对第i个个体Xi的影响,算法引入学习因子(LF).对于第i个个体Xi,LFk将影响其对第k类差距的学习.当第k类差距较大时,LFk也会较大,第i个个体Xi会从第k类差距中学到更多.LFk的建模为
其中: LFk为第k类差距的欧氏距离归一化比值,范围为[0,1].
在成长过程中,不同层次的人对自己有不同的看法,可以通过引入SFi来评估个体自身可接受的知识范围.SFi越大,说明第i个个体Xi需要更多的知识来提升自己,即
其中: GRi为第i个个体的适应度值;GRworst为所有个体中最大的适应度值.
知识的学习和转化是损耗的.对于第k类差距(Gapk),个体Xi从它们中吸收一些知识,这些知识是第k个知识获取组(KAk).对于第i个个体Xi,KAk是在LFk和SFi在第k类差距上的操作后得到的,上述过程可以描述为
其中: KAk是第i个个体Xi从第k类差距获得的知识,SFi是对其自身情况的评估,而LFi是对外部情况的评估.
第i个个体Xi在两种评估的影响下,从Gapk中识别出自己需要的知识KAk,从而完成学习过程.个体Xi通过从四类差距中学习,完成丰富的知识积累过程,第i个个体Xi的具体学习过程为
其中:Xi为第i个个体;KAk是第i个个体从第k类差距中获取的知识.
个体Xi的适应度值更新过程为
其中:Xit+1为第t+1 次迭代中第i个个体;r1是一个均匀分布于0 和1 之间的随机数;P2为一个常数,通常取值为0.001;P2决定第i个个体不更新时是否保留新获得的知识,其中i≠1是为防止全局最优解被替换导致算法不易收敛.
1.3 反思阶段
学习和反思相互互补,反思也是汲取知识过程中的一个重要阶段.对于第i个个体Xi,Xi会通过向优秀的个体学习,来弥足自身的不足.但是当某一方面的知识无法弥补时,Xi会放弃以往的知识,重新进行系统的学习.第i个个体Xi的反思过程为
其中:r2、r3、r4和r5为在[0,1]范围内均匀分布的随机数;R表示适应度排名前P1的个体之一;Rj为个体R的第j个维度;P3为一个常数,能够控制反思的概率,一般设置为0.3;AF为衰减因子.
2 改进的成长优化算法
在GO 算法中,位置的更新是通过将k类差距相加的方式进行的.但是在某些复杂的寻优问题中,这种更新方式存在不确定性,很难正确指引个体的搜索路径.为提高算法的精度,将精英反向学习引入到GO算法的初始化位置更新中.通过使用精英反向学习,算法可以利用精英个体的优秀特征来指导其他个体的初始化位置.通过学习精英个体的反向解,算法可以更好地初始化个体的位置,从而增加算法的收敛性和优化能力.为进一步平衡算法的探索和开发能力,将基于知识共享的优化算法融合到GO 算法中,这一阶段称为知识共享阶段.在知识共享阶段,个体之间通过共享知识和经验来相互影响和改进.这种知识共享机制能够有效地传递优秀的解决方案和搜索策略,提高算法的优化能力.通过使用精英反向学习策略和知识共享,算法在初始化和演化的过程中获得更多的信息和指导,从而提高寻优能力.这种综合方法可以使GO算法更加准确地探索解空间,更好地平衡全局探索和局部开发之间的关系,进而提高算法的性能和效果.
2.1 精英反向学习对种群进行初始化
精英个体在种群中相比其他个体包含更多的有效信息.通过构造精英个体的反向解,可以增加种群的多样性,并扩展种群的搜索范围,以更好地探索解空间.这种策略有助于避免陷入局部最优解,提高搜索算法的全局优化能力.通过精英反向学习策略来对种群位置进行初始化,通过精英反向学习对种群进行初始化的计算式为
其中:Xi为第i个个体;Xnew为第i个个体所对应的精英反向学习个体.
通过对初始解和反向解进行合并,选取适应度值较优的解作为初始个体,用于组成初始种群,即
其中:Xi为第i个个体;Xnew为第i个个体所对应的精英反向学习的个体.
2.2 知识共享阶段
在一个种群中,“扬长避短”“合理分工”是种群寻找更优适应度值的好办法,即挖掘种群中各个个体的潜力,从而加强算法的性能.通过对适应度排名前P1个的个体采取局部搜索策略,更新公式为
其中:Xi为第i个个体;rand为[0,1]之间的随机数;gBest为全局最优个体.
针对位置较差或相对中等的个体,可以采取一种方法来提升它们的搜索能力。首先,将个体的维度D进行划分,分为初级要素和高级要素.初级要素是维度D中的前Djun个维度,而高级要素则是剩余的DDjun个维度.这种划分的目的是通过初级要素和高级要素之间的差异性来更新个体,以引导个体进行全局搜索.基于初级要素和高级要素的更新策略使得个体在搜索过程中能更全面地考虑不同维度的信息,并根据初级要素和高级要素之间的差异性进行调整.在更新初级要素和高级要素时,可以使用特定的更新公式,即
其中:t为当前迭代次数;T为最大迭代次数;v为知识率,是一个大于0的实数,一般取值为10.
在知识共享阶段中对初级要素进行更新.需要生成一个介于0和1之间的随机数,如果这个随机数小于知识比率rk,个体Xi的第j个维度将按照式(15)对初级要素进行更新;否则不做任何更新.更新完初级要素之后,将对高级要素进行同样的更新处理.同理,需要生成一个介于0和1之间的随机数,如果这个随机数小于知识比率rk,那么将按照公式(16)对高级要素进行更新;否则不做任何更新.式(15)~(16)如下所示
其中:Xi,j表示第i个个体在第j维度上的取值;Xi-1,j表示适应度排名在Xi,j之前的个体中,在第j维度上的取值;Xi+1,j表示适应度排名在Xi,j之前的个体中,在第j维度上的取值;Xm为随机个体,fk为知识因子,一般取值为0.5,rk为知识比率,一般取值为0.9;Xpbest为当前适应度排名最前P1个人之一;Xworst是当前适应度排名最后P1个人之一;Xm为随机个体.
个体Xi的适应度值更新过程如式(7)所示.
2.3 改进成长优化算法实现流程图
综合上述策略,通过精英反向学习策略和知识共享,算法在初始化和演化的过程中获得更多的信息和指导,提高算法的寻优能力.这种综合方法可以使GO 算法更加准确地探索解空间,更好地平衡全局探索和局部开发之间的关系,进而提高算法的性能和效果.改进成长优化算法实现流程图如图1所示
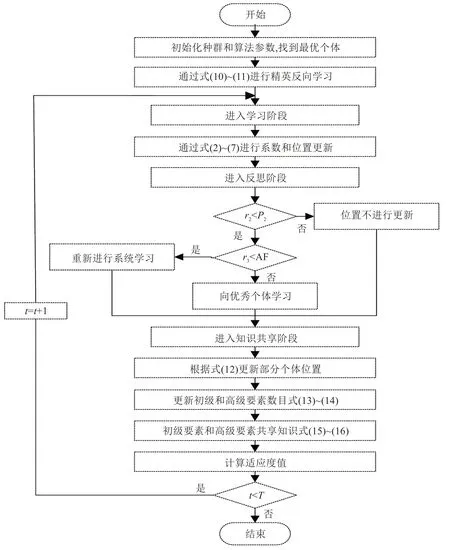
图1 KSOBLGO算法实现流程图Fig.1 KSOBLGO algorithm implementation flowchart
3 实验仿真结果及测试
为验证KSOBLGO算法的性能,通过13个基准函数测试将该算法与成长优化(GO)算法、鲸鱼优化算法(WOA)和算术优化算法(AOA)的寻优结果进行比较.所选的基准测试函数包括两个种类:单峰测试函数编号(F1)~(F7)和多峰测试函数编号(F8)~(F13).这些函数被广泛应用于优化算法的基准测试中,用于评估算法的性能和鲁棒性.这些函数代表不同类型的问题,从而使能够更全面地解KSOBLGO算法在处理不同类型问题时的适应能力和表现.通过对这些基准函数进行测试,并将KSOBLGO算法的结果与GO算法、WOA和AOA进行比较,可以确定KSOBLGO算法在这些问题上的性能优劣.这样的比较有助于解KSOBLGO算法在不同类型问题上的优势和局限性,以及它是否是一个适合解决这些问题的有效算法.函数详细内容如表1所示.
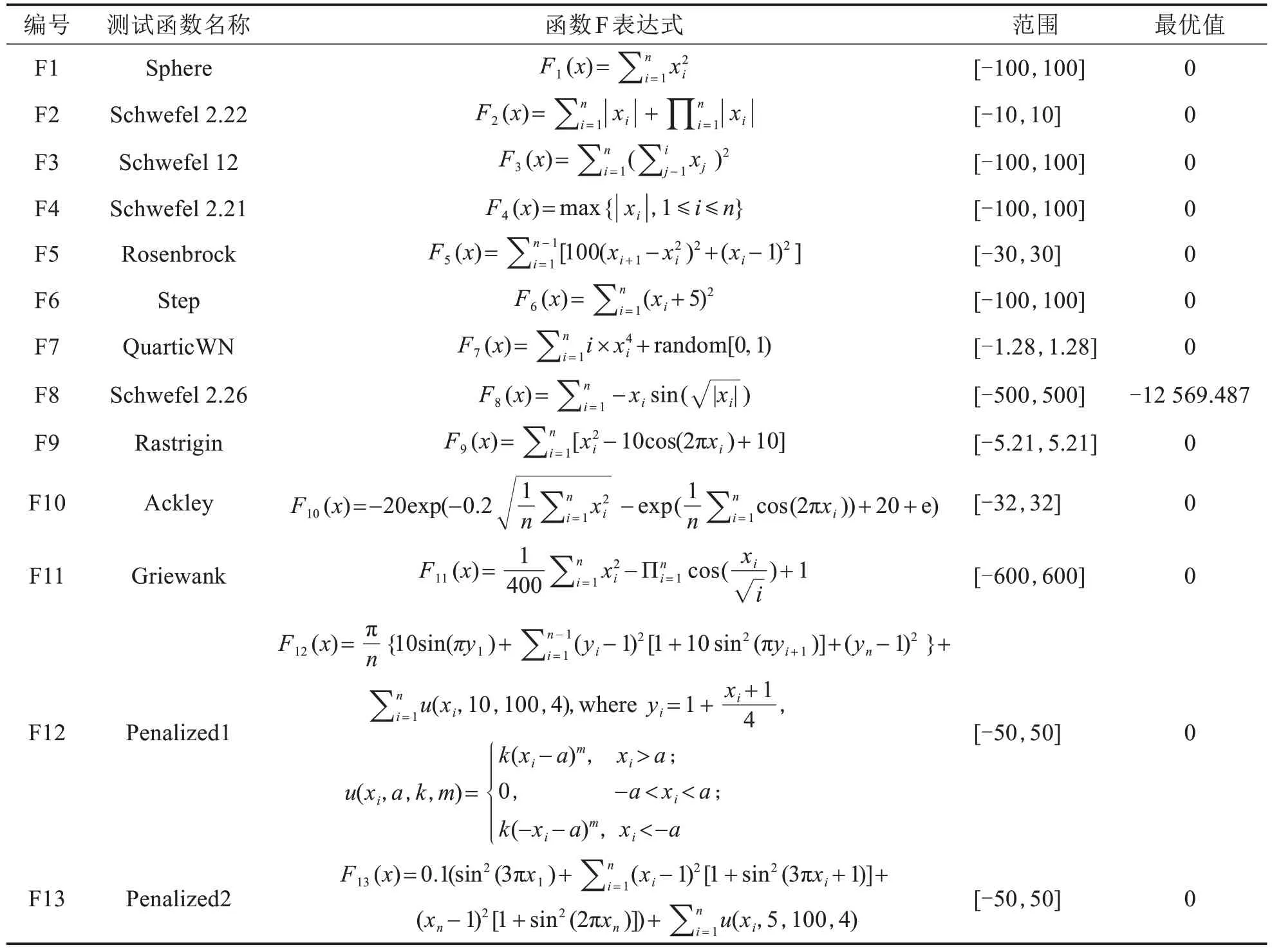
表1 基准测试函数Tab.1 Evaluation functions
3.1 参数设置以及实验环境
确保仿真实验的公平性是非常重要的,其中一个关键因素是统一算法中部分相关参数的设置.在本次实验中,将种群数量设定为40,维度为30,最大迭代次数设定为1 000次.此外,为评估算法的性能稳定性,每个算法都将独立运行30次,以获取更可靠的结果.各个算法的关键参数设置,如表2给出.以平均数、标准偏差值和Wilcoxon符号秩检验为判断标准,其中,平均数与标准差值越小,则证明算法的性能越佳.

表2 算法参数设置Tab.2 Algorithm parameter settings
3.2 实验结果及分析
3.2.1 数据分析
将KSOBLGO 算法与GO 算法、WOA 和AOA 进行对比实验,每种算法对每个函数进行30 次测试,通过30次测试计算函数适应度值的平均值和标准差,实验结果如表3所示(最优结果用粗体表示).
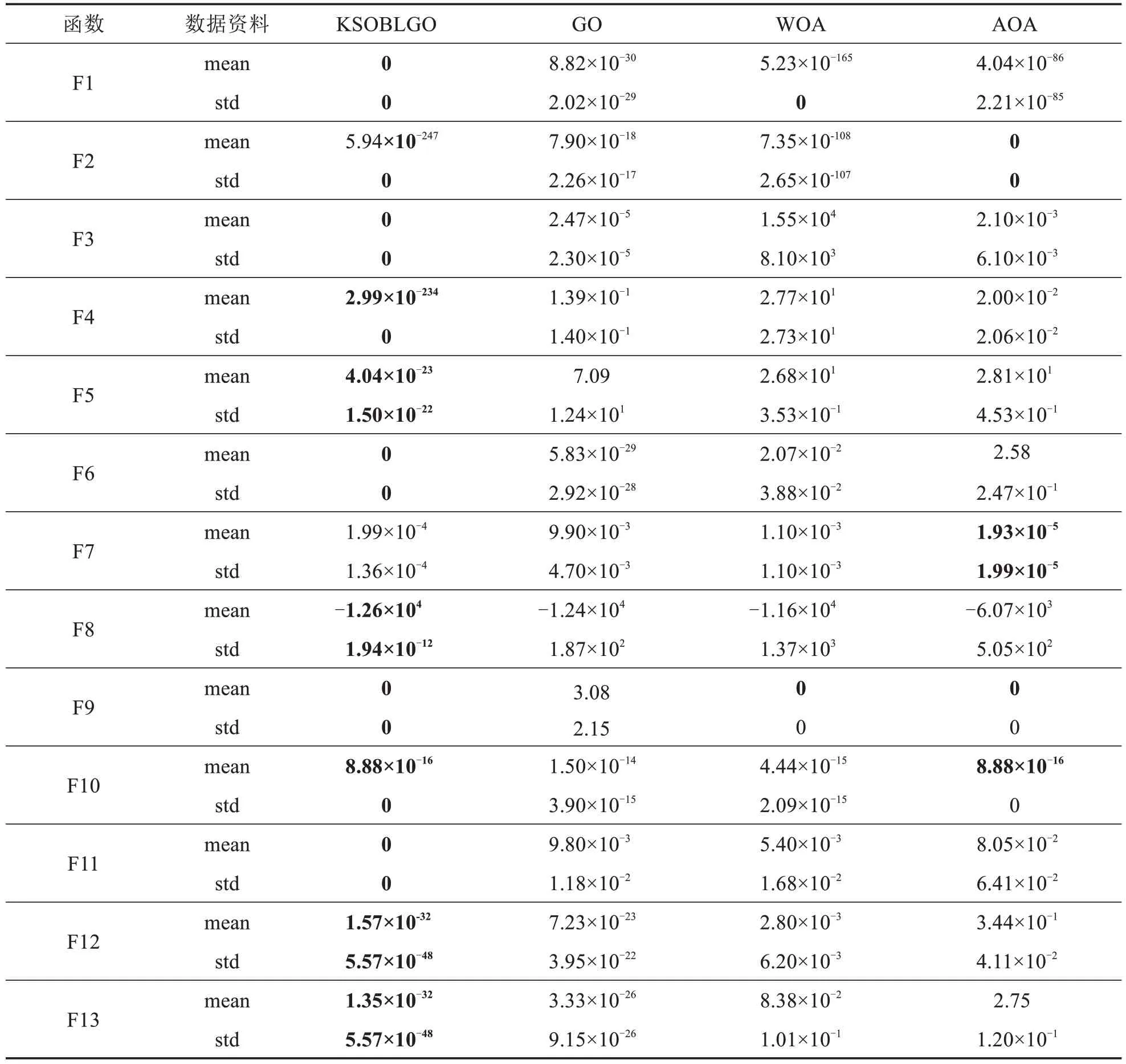
表3 函数寻优测试结果Tab.3 Function optimization test results
由表3的测试函数结果可以看出,KSOBLGO算法对F1、F3、F6、F8、F9、F11寻优过程中都收敛到最优值,具有不错的寻优能力和稳定性.从平均值上看,KSOBLGO算法在8个测试函数中平均值与GO算法和WOA 有显著差别,在10 个测试函数中平均值与GO 算法、WOA 和AOA 有显著差别,在11 个测试函数中平均值都优于GO 算法和WOA,在9个测试函数中平均值都优于AOA.从标准差上看,KSOBLGO 算法在13个基准测试函数中的标准差均小于GO 算法和WOA,在F2和F7上相较于AOA 略有不足.通过基于统计学理论的分析,KSOBLGO 算法在这些基准函数上表现出较高的寻优性能和鲁棒性.它能够更快速、准确地找到全局最优解,并对多峰函数具有良好的搜索能力.这些优势使得KSOBLGO 算法成为解决优化问题的有力工具.
3.2.2 收敛曲线分析
收敛曲线能直观反映优化算法的收敛速度和整体性能.为能够更直观的展现算法在各种函数中所表现出来的性能,选取测试所求得的最优值与平均值较为接近的一次,同时绘制KSOBLGO算法、GO算法、WOA 和AOA 的迭代曲线.从13 个基准测试函数中选取9 个基准测试函数的收敛曲线进行绘制,其中包括6个单峰函数和3个多峰函数,如图2所示.
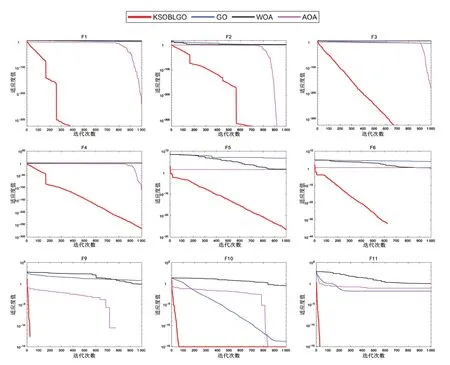
图2 函数优化迭代曲线图Fig.2 Function optimization iteration curve chart
对比四条迭代曲线可明显观察到KSOBLGO 算法在收敛速度和准确度方面表现更优.改进后的GO算法在探索和开发能力方面取得平衡,提升算法的优化性能.验证所采用的改进策略的有效性和可行性.
3.2.3 Wilcoxon符号秩检验
在上述分析中,仅通过平均值和标准差判断算法之间有显著性差异是不充分的.使用Wilcoxon 符号秩检验,显著性水平为0.05,来进一步验证KSOBLGO 算法与其他三种算法在性能优势上的显著性.这种统计检验方法可以用来比较两个相关样本之间的差异,并确定它们之间是否存在显著性差异.对比实验结果如表3 所示,其中符号“+”“=”“-”分别代表KSOBLGO 算法和对比算法的性能间有无显著差异的关系,并对P>0.05的数据进行加粗处理.
从表4 可以看出,KSOBLGO 算法在与GO 算法和WOA 进行比较时,在所有函数的优化结果上都有所改善KSOBLGO 算法和AOA 算法在函数F9 和F10 上都收敛到最优值,两种算法的性能相当.然而,其他函数的数据表明KSOBLGO 算法的性能优于AOA 算法.通过进行Wilcoxon 秩和检验,可以得出结论:KSOBLGO 算法在大多数测试函数中具有更好的优化效果.综合分析表3~4及图2的结果,可以得出以下结论:融合知识共享和精英反向学习的KSOBLGO 算法在勘探和开发方面展现出更强的能力.与GO 算法、WOA算法和AOA算法相比,在优化方面取得更好的结果.
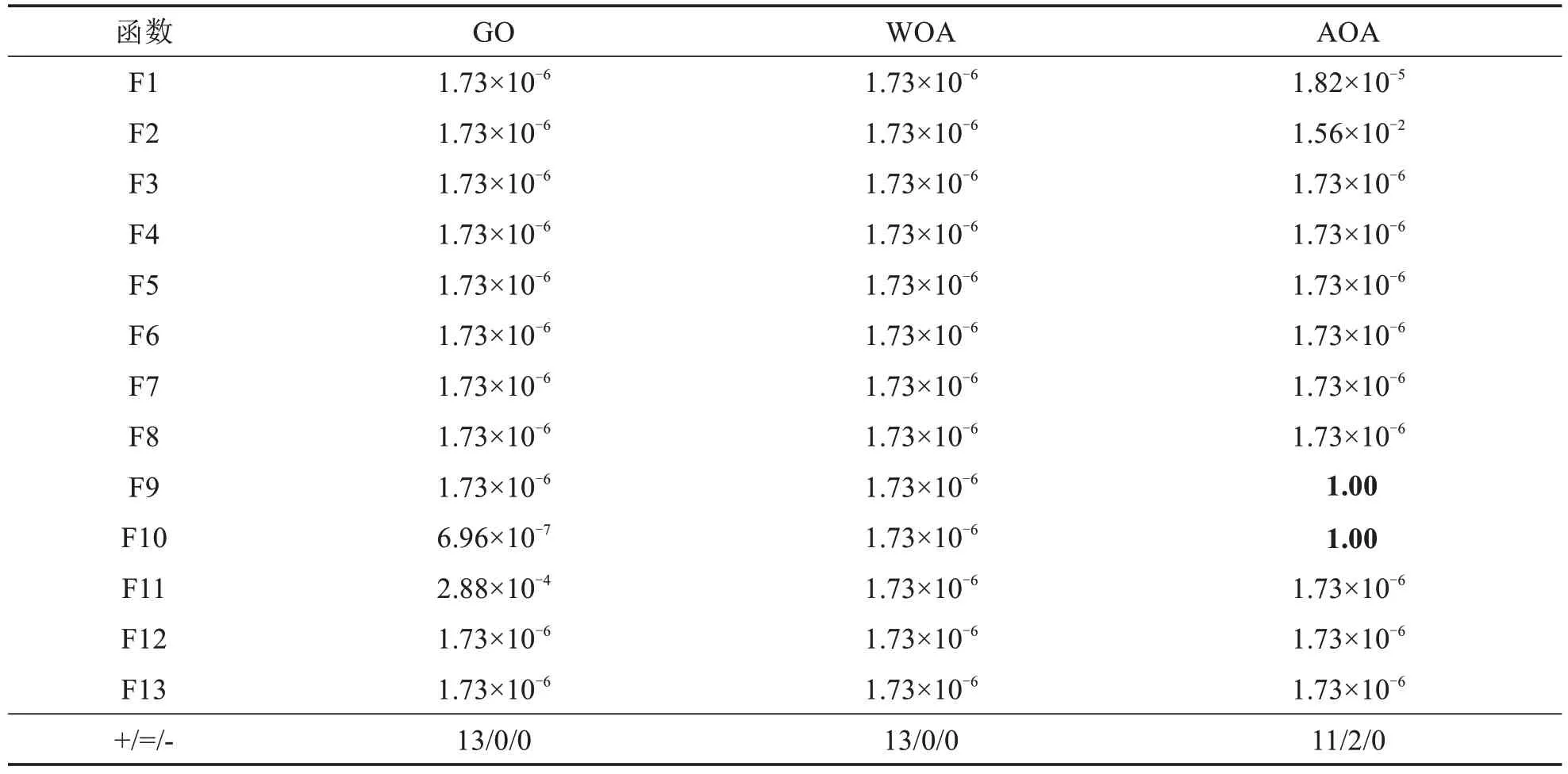
表4 Wilcoxon符号秩检验p值表Tab.4 Wilcoxon signed rank test p-value table
4 结论
提出一种融合知识共享和精英反向学习的成长算法,旨在通过将基于知识共享的优化算法与精英反向学习相结合,提升最优个体的局部搜索能力和其他个体的全局搜索能力,在探索和开发能力方面取得平衡.实验结果表明,改进后的GO 算法显著提高算法的随机性和全局搜索寻优性能,同时有效防止局部最优停滞现象.然而,目前该研究仅在13个基准测试函数上进行改进测试.未来的研究将尝试整合不同的改进策略,并根据实际工程需求努力发展更具适应性的智能优化算法,为实际工程问题提供更出色的解决方案.
