轻型多注意力融合网络实现图像超分辨率重建
2023-12-25陈新宇方金生
陈新宇, 方金生*
(1.闽南师范大学计算机学院,福建 漳州 363000;2.闽南师范大学数据科学与智能应用福建省高校重点实验室,福建 漳州 363000)
图像超分辨率(super-resolution, SR)重建技术是将低分辨率(low-resolution, LR)图像恢复为相应的高分辨率(high-resolution, HR)图像,因此SR重建是一个具有挑战性的不适定问题[1].近年来,随着硬件技术和卷积神经网络(convolutional neural network, CNN)的发展,基于CNN 的SR 重建算法已成为最流行的策略,并出现诸多性能优异的算法[2].
作为开创性的SR重建工作,SRCNN[3]仅用三个卷积层实现LR图像到HR图像的直接映射,其性能已经远超过传统的超分辨率图像重建方法.随后的研究表明,采用更深或更复杂的网络可实现更好的性能[4-5],但这些网络的参数和计算量大,难以部署于移动设备端.因此,设计轻量级的网络模型是当前的研究热点之一.为优化网络结构和减少参数量,CARN (cascading residual network)[6]引入级联残差网络的概念,通过级联多个残差块以增加网络的深度,更好地捕获图像细节和纹理.IMDN (information multi-distillation network)[7]通过信息蒸馏方法,有效地将不同尺度和级别的信息融合到一个轻量级的模型中,并获得较高网络性能.MCSN (multi-scale channel attention super-resolution network)[8]引入通道搅乱注意力模块,有效地促进通道之间信息的流动,提高网络在通道维度的特征选择能力.这些模型有效地降低模型的复杂度,但仍未取得令人满意的网络性能.为此,提出一种轻量级的多注意力融合网络模型(multi-attention fusion network,MAFN),有效地提高图像超分辨率重建结果.主要贡献如下
1)提出一种多注意力融合网络MAFN(multi-attention fusion network),有效地平衡网络性能和参数量与计算消耗的问题;在5个公共数据上的测试结果表明MAFN的性能优于其他的对比网络.
2)提出一种高效的多尺度卷积注意力模块MCAB(muti-scale convolution and attention block),该模块融合多尺度卷积模块、非线性自由激活模块(nonlinear activation free block, NFAB)、通道注意力(channel attention,CA)模块和增强空间注意力(enhanced spatial attention,ESA)模块,有效地提高网络对特征的学习能力,增强网络对高频细节特征的关注,从而提高图像SR的性能.
1 相关工作
1.1 轻量级图像超分辨率重建
为节省计算资源,轻量级超分辨率网络受到广泛关注.Hui等[7]提出的IMDN 使用多重蒸馏模块及对比感知通道注意力机制聚合各卷积层的蒸馏信息.Liu等[9]提出的RFDN在IMDN基础上进一步优化通道蒸馏操作,有效地提高网络性能,同时获得AIM 2020年的图像超分辨率比赛冠军.Lan等[10]提出的MADNet (multi-scale attention dense network)使用密集的轻量级网络来增强多尺度的特征表示和学习.Li等[11]进行卷积核可视化后,观察到很多卷积核呈现相似的特征分布,因而提出蓝图卷积模块减少特征的重复提取.Gendy等[12]提出BSPAN (balanced spatial feature distillation and pyramid attention network),可权衡不同通道和注意力机制提取特征的冲突,利用平衡的空间特征蒸馏块作主干,实现高性能的图像超分辨率重建.Sun等[13]提出的ShuffleMixer允许模块间的信息交流和特征混洗,以减少可学习特性的数量,能够在资源受限的环境下适应不同任务和数据集.Zhao 等[14]提出LIRDN (lightweight inverse separable residual information distillation network),该方法利用逆可分离复原浅残差单元逐步提取蒸馏信息,增加蒸馏层间的通道信息流动,在确保结构轻量化的同时获得更多样化的通道特征信息.
1.2 注意力机制
注意力机制可认为是一种模拟人眼视觉机制的方法,其通过图像特征信息动态调整权重系数,有效地帮助网络选择性地关注有用的信息,目前已经广泛应用于计算机视觉任务中.Woo 等[15]提出CBAM(convolutional block attention module),分别利用特征间的通道和空间关系来生成对应的通道和空间注意力映射,提高网络的特征表示能力.Liu等[9]提出一种增强的空间注意力模块,利用局部的空间信息计算注意力权重,使局部的重要信息得到更多的关注.Gao 等[16]引入多路注意力模块,用于提取不同维度的特征信息,以丰富特征的表征能力.为避免图像超分辨率网络不断的加深和拓宽,Feng等[17]通过在网络的首尾添加双注意力机制来区分深度网络中的后传递特征,获得更好的高频重建信息.Wang等[18]提出一种自适应注意力,通过浅层部分的大核卷积注意力取得更多的原始信息,保证深层网络的特征提取.因此,高效的注意力结构对提高超分重建网络的性能至关重要,致力于设计用于轻量级网络的注意力模块,以获得更优的重建结果.
2 方法
2.1 网络结构
提出的MAFN 网络结构如图1所示,主要由浅层特征提取模块(shallow feature extraction,SFE)、若干个多尺度卷积注意力模块(MCAB)和图像上采样重建模块(sub-pixel)三部分组成.与其他经典SR网络一样,MAFN的SFE采用3×3卷积层从LR图像中提取浅层特征I0,丰富输入的特征信息;然后通过一系列堆叠的MCAB 对I0进行深层特征提取,MCAB 利用支路残差多尺度卷积模块获得不同视野的图像特征,然后再通过NAFB、CA 和ESA 模块关注通道和空间中重要的特征,并分别采用卷积核大小为1×1 和3×3 融合深层特征;最后由上采样重建模块重建SR结果.

图1 MAFN的网络结构Fig.1 Network architecture of the MAFN
因此,对于输入的LR图像,经过SFE提取得到的浅层特征I0,可表示为
式(1)中:C3×3表示3×3 卷积操作;浅层特征F0经由k个MCAB 逐步提取特征,并将每个MCAB 的输出特征进行融合,再分别进行1×1卷积和3×3卷积操作,最后与原浅层特征I0相加,上述过程可表示为
式(2)中:C1×1表示1×1卷积操作;Ik,Fcat(·)分别为第k个MCAB的输出特征和融合函数.
在图像重建部分,常见的重建方法主要有双三次插值法、转置卷积法及亚像素卷积法(sub-pixel)[2].采用亚像素卷积法,sub-pixel模块通过一个3×3卷积和亚像素混洗层对输出特征进行上采样操作,得到网络最终输出的SR图像,该过程可表示为
式(3)中:Fup(·)表示sub-pixel函数.
为优化所提出的MAFN,采用LOSS函数,具体如下
2.2 多尺度卷积注意力模块(MCAB)
由图2 所示,MCAB 由一个支路残差多尺度卷积模块(BRMB)、一系列的非线性自由激活模块(nonlinear activation free block,NAFB)及级联式的通道注意力模块(CA)和增强空间注意力模块(ESA)组成.与Inception[19]不同,BRMB 简化Inception 模块,即采用1×1 卷积、单3×3 卷积和双3×3 卷积(两个3×3 卷积等价于一个5×5卷积)三个不同的通道,实现在不同尺度的视野下对特征进行提取,丰富图像的特征信息;同时,单3×3 卷积和双3×3 卷积通道分别增加残差连接,以增强原始特征信息更好地向后传递,同时可防止梯度因网络加深而消失的问题.输入特征经过BRMB后得到的特征IBRMB可以表示为
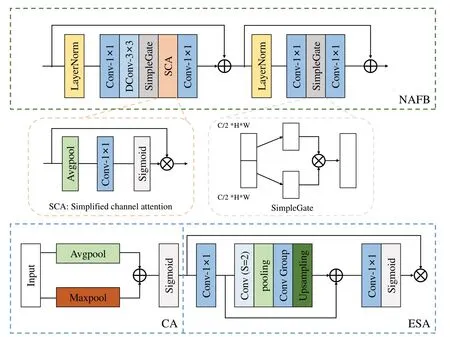
图2 非线性自由激活模块和级联式注意力模块的结构Fig.2 Structures of nonlinear activation free block and cascading attention block
式(5)中:Iin为BRMB输入特征;C1×1和C3×3分别表示1×1和3×3卷积操作.
非线性自由激活模块(NAFB)[20]如图2第一行所示,由层归一化层(layerNorm)、点卷积层和深度卷积层、SimpleGate模块和简单通道注意力(simplified channel attention,SCA)构成.SCA包含平均池化层、1×1卷积层和Sigmoid层组成,可通过简单的网络层有效地引导网络关注重要的特征信息;SimpleGate模块是将输入特征分成两等分的通道并点乘,相比于采用卷积操作降通道数,SimpleGate 可大大减少计算成本.NAFB的运算过程可以表示为
上式中:FLN(·)表示归一化函数;FD3×3(·)表示3×3 深度可分离卷积函数;FSimple(·),FSCA(·)分别为通道融合和简单通道注意力函数.
如图2 的第三行所示,由NAFB 获得的特征经过级联式通道注意力(CA)和增强空间注意力(ESA)进一步提取重要信息.CA 采用平均池化和最大池化提取图像通道特征,然后结合ESA 模块,ESA 更多关注局部空间信息,可以更好地提取高频信息.因此,MCAB的输出特征Iout表示为
式中:FCA(·)和FESA(·)分别表示CA和ESA函数.
3 实验结果与分析
3.1 数据准备
算法使用DIV2K[21]数据集作为训练集,该数据集包含800幅高质量训练图像和100幅验证图像;使用5 个基准数据集作为测试集,即Set5[22]、Set14[23]、BSD100[24]、Urban100[25]和Manga109[26].采用峰值信噪比(PSNR)和结构相似性(SSIM)作为度量来评价各算法的重建结果.
3.2 实验细节
网络的训练输入是由LR 图像随机裁剪为大小48×48 的图像块,批数据量设置为8;使用Adam 优化器,超参数为β1=0.9,β2=0.999;初始学习速率设置为5×10-4,每经过400 个训练轮次学习率减少为原来的一半,总共1 000个训练轮次;通道数为50.
3.3 消融实验
1)MCAB 数量对网络性能的影响.如表1 所示,随着MCAB 数量地增加,网络性能也随之提升,当数量从1 增加到5 时,PSNR 值显著增加且参数量也随之增长;当数量为6 时,PSNR 反而下降.由于MCAB数量为5 时,PSNR 值仅比数量为4 时增加0.03,而网络参数量增加165 K.因此,为权衡网络性能和参数量,采用4个MCAB的模型.

表1 在×4采样率下MCAB的不同数量在Set14数据集中的网络性能Tab.1 Network performance with different numbers of MCAB on Set14 ×4 dataset
2)BRMB对网络性能的影响.为验证的BRMB对网络的影响,本实验将BRMB与原始的Inception进行比较,结果如表2 所示,BRMB 在Urban100 测试集上得到优于原始Inception 模块的SR 性能,同时参数量减少40 K.由此可见,提出的BRMB简化模块结构,可有效地减少参数数量,且提高网络性能.

表2 在×2采样率下不同的BRMB模块数在Urban100数据集中的网络性能Tab.2 Network performance with different numbers of BRMB on Urban100 ×2 dataset
3)NFAB 对网络性能的影响.为更好地平衡MCAB 中各模块数量和网络性能,本实验验证MCAB 中NAFB数量对网络性能的影响,如表3所示.当采用2个NAFB时,PSNR值较没有采用NAFB时增加0.18,可见NAFB 可明显提升网络性能,随着NAFB 数量的进一步增加,PSNR 值也近似于线性提高,当NAFB数量大于4 时,增加量变缓,增量仅为0.03 dB.因此,为更好地平衡网络参数量和性能,本模型中的每个MCAB中采用4个NAFB模块.

表3 在×3采样率下NAFB的不同数量在Urban100数据集下的网络性能Tab.3 Network performance with different numbers of NAFB on Urban 100 ×3 dataset
4)注意力机制对图像超分辨率性能的影响.验证不同的注意力模块对网络性能的影响,结果如表4所示.以未添加任何注意力机制模块为基础网络(Base),然后在基础网络中分别采用1 个CA、1 个ESA、以及1 个级联的CA 和ESA 进行实验.从表4 可知,采用级联式的CA 和ESA,在B100 数据集中取得最优的PSNR值.由此证明级联式的CA和ESA可以有效地提升网络性能.

表4 3倍采样率下不同的注意力模块在BSD100数据集中的网络性能Tab.4 Network performance with different attention modules on BSD 100 ×3 dataset
3.4 与主流轻量型网络的性能比较
为验证MAFN 的性能,在5 个数据集上将MAFN 与IMDN[7]、RFDN[9]、MADNet[10]、GLADSR[27]、SMSR[28]、ShuffleMixer[13]、SR-LAM[17]和AAFFEN[18]等主流轻量级SR 重建方法进行比较,结果如表5 所示.在×2、×3和×4图像下采样的情况下,提出的MAFN在五个数据集下的指标均优于比较算法,其中,AAFFEN在Urban 100×2、Manga109×2 与BSD100×3 上的SSIM 值以及BSD100×3 与BSD100×4 的PSNR 值优于MAFN,但其参数量比MAFN高约260 K.与参数量和计算量小于MAFN的模型,如ShuffleMixer、SR-LAM等相比,MAFN可获得0.10~0.30 dB的提升.综上所述,提出的MAFN更好地权衡网络性能和网络模型.
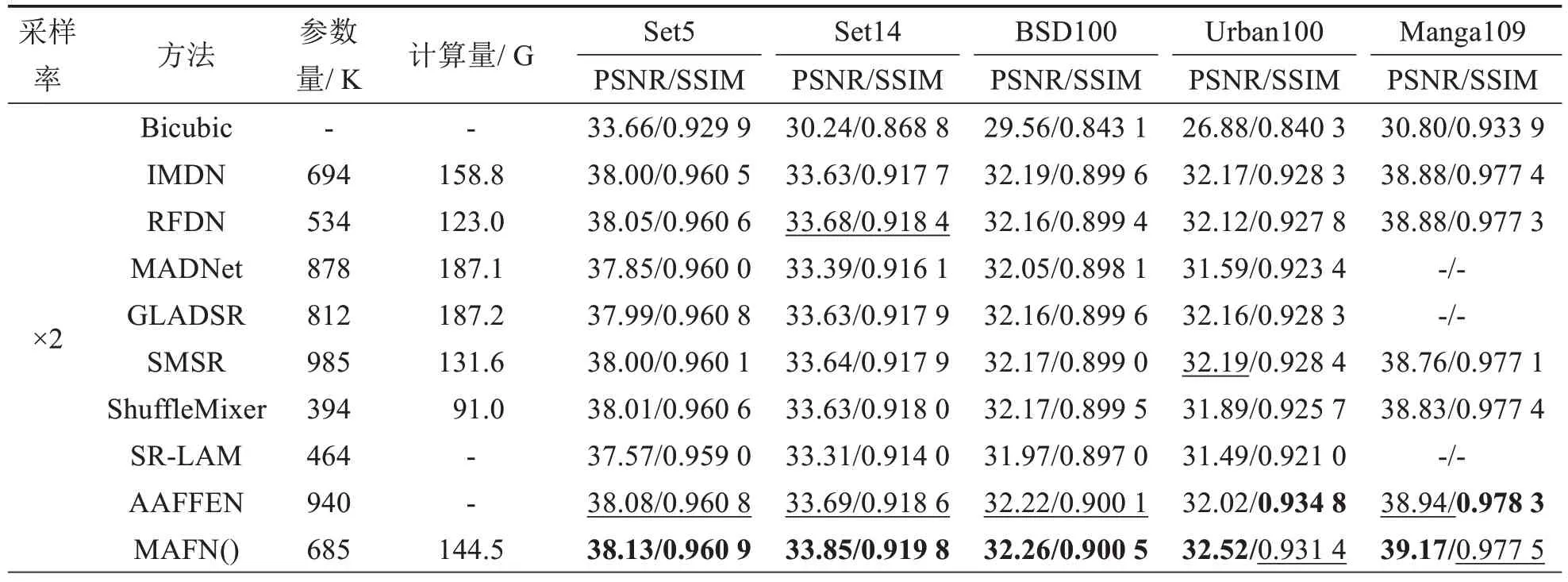
表5 在2、3、4倍采样率下比较5个数据集上不同轻量级模型的定量指标Tab.5 Quantitative comparison of different lightweight models on five datasets with ×2, ×3, ×4 scaling factors.
图3 展示MAFN 与其他主流网络在Urban100×4 数据集中的主观视觉效果比较.从放大图示可看出,由MAFN 网络重建的SR 图像中的线条和条纹边缘更为清晰,较其他网络更接近真实图像,由此说明MAFN 能够更好地得到边缘信息,以及较好地抑制伪影.尤其在image076 中,MAFN 可更为完整地重建边缘信息,进一步证明其在图像超分辨率重建中的有效性.

图3 不同算法对Urban100数据集中image067、image076、image093的4倍重建结果Fig.3 SR results of comparsion methods on image067, image076, image093 of Urban100 ×4 dataset
4 结语
提出一种用于图像超分辨率重建的轻量型多注意力融合网络模型(MAFN).本模型使用多个多尺度卷积注意力模块作为主干网络进行图像特征提取,通过支路残差多尺度卷积块获取不同的特征提取视野,利用非线性自由激活模块、通道注意力和空间注意力机制使模型能够更好地关注重要信息,提高模型的特征学习能力以获得更优的重建性能.实验结果表明,网络更好地平衡网络性能和模型规模,在5个测试数据集上,其综合性能优于其它的比较算法.
