不确定性环境下基于强化学习的自动驾驶运动规划研究
2023-12-20张苏男刘博程
胡 博,江 磊,宋 洁,袁 春,张苏男,刘博程
(重庆理工大学 车辆工程学院 汽车零部件先进制造技术教育部重点实验室, 重庆 400054)
0 引言
自动驾驶汽车技术的开发是一项重要工作,可以提高交通运输的安全性和机动性。目前,有许多商用的高级驾驶辅助系统,如自适应巡航、车道保持辅助等。现在研究者逐步转向开发更加高级别的自动驾驶车辆,这些车辆可以在更加复杂的环境中执行驾驶任务,如并线、十字路口、匝道合并和环岛等。此类场景都有一个典型的特征:强交互性,更具体来说,由于不同支路上的多个交通参与者带来了无数的交通状况和复杂的交互,使得在此类场景中的研究具有一定的挑战性。环岛是交互场景中一个很好的例子[1],因此,在此场景中的自动驾驶技术研究显得尤为重要。
目前,研究人员在自动驾驶汽车技术上的开发大体分为3个模块,包括感知、规划和控制模块[2]。本文中主要研究运动规划层,在运动规划领域,通常采用的方法大体上分为基于图[3-4](例如A*算法、Dijkstra算法和快速随机搜索树算法[5-9])、基于优化[10](例如模型预测控制、EM Planner)和基于学习算法[11](例如深度强化学习方法)。目前,许多研究者基于以上方法对运动规划进行了大量的研究,产生了许多投入产业化应用的案例,并且取得了良好的效果。运动规划模块主要负责为智能车辆生成局部运动轨迹,是自动驾驶技术中至关重要的一环。图搜索的算法通常是将自动驾驶车辆所处的环境通过离散化的方法转化为一个图,并通过一些启发式的算法生成一条满足条件的路径曲线[12]。Dijkstra算法就是一种非常经典的基于图搜索的算法。Dijkstra的主要特点是以起始点为中心向外层层扩散,直至扩散到目标点为止。它的优点是每次总能找到最优解,缺点是随着图的范围的扩大,计算效率发生显著地下降。A*算法则是一种启发式的算法,它改善了Dijkstra的缺点,提高了算法的搜索效率。Hybrid A*因其考虑了运动学的约束问题,可以直接生成可行驶的路径,在智能车辆中被广泛应用。其他的图搜索算法大多是以上算法的改进或者变种[13-14]。基于优化方法的核心问题在于构建目标函数和约束,函数的优化在每个运动状态都需要花费算力资源[15]。基于优化的方法需要在线优化,在考虑障碍物过多的情况下,使求解空间呈现高度的非凸性,在考虑成本的情况下,这可能会成为实时应用的巨大障碍[16]。近年来,基于学习的智能车辆运动规划方法(如深度强化学习)已被广泛采用[17]。与上述基于优化的方法相比,深度强化学习方法控制动作的输出只需少量的神经网络传播时间,显著地提高了计算效率[18]。一些研究试图通过经典强化学习来解决自动驾驶问题,目前,强化学习大多应用在从感知到控制或者规划到控制这样的端对端自动驾驶任务中。由于端对端的自动驾驶不需要人为指定规则,且智能体通过和环境进行交互学习驾驶策略与人类学习驾驶的方式十分相似,所以端对端的方法成为自动驾驶领域的一个重要研究方向。
在复杂环境中,车辆对动态障碍物行为意图的理解是十分重要的。在简单环境或模拟环境中,自动驾驶系统可以对其行为进行简单建模,对障碍物的未来轨迹进行预测,通过预测轨迹对运动规划系统生成的轨迹进行评估,防止其与之发生碰撞。但是在自动驾驶这样的复杂环境中,交通参与者行为意图的模型不能简单的进行建模,简单模型无法准确表达环境中的不确定性。因此,如何表达驾驶环境中的不确定性以及如何处理这些不确定性是目前自动驾驶运动规划研究中亟待解决的问题。百度Apollo公司提出的EM Planner规划方法采用了三维解耦的的运动规划思想证明了在存在动态障碍物的场景中进行横向的路径规划和纵向规划可以代替同时处理多个维度的轨迹规划。在这种思想下,纵向的速度规划成为了动态障碍物不确定性环境中需要解决的重要问题之一。例如使用深度强化学习在十字路口[19-20]、高速路口匝道合流[21-26]和环岛[27]等场景。目前,基于深度强化学习的运动规划方法由于其较高的计算效率已被广泛应用到自动驾驶行业。然而,当前的方法大多是基于仿真模型来学习其驾驶策略,基于神经网络的驾驶策略往往对未知场景的预测过于自信,这就导致了不安全等问题。为了避免这一问题,需要结合基于规则的方法对驾驶策略的规划结果进行进一步修正。许多研究人员设计了安全规则对运动规划系统的安全性进行冗余。Yang等[19-20]通过设置基于规则的过滤层对策略的不安全动作进行修正,最终在安全性指标上取得了不错的效果。Lubars等[28]通过结合模型预测控制和强化学习的方法显著地提高了运动规划系统的安全性。
综上所述,目前自动驾驶汽车的运动规划研究方法也面临着一些问题:1)在有限成本下,基于优化的方法在强交互场景中存在计算效率低的问题;2)在复杂环境中,如何表达驾驶环境中的不确定性以及如何处理这些不确定性以及基于深度强化学习方法基于不确定性模型训练而得的驾驶策略不能严格满足安全性的问题。本文中提出一种基于深度强化学习的运动规划方法,通过考虑周车的不确定性区域生成未来时域内的车辆可达到状态集,并通过设计基于规则的安全层,生成满足给定动力学约束、障碍物空间约束和强化学习优化输出约束下的修正轨迹,与传统基于优化的规划方法相比,轨迹生成策略可以进行离线训练和在线部署,解决了基线方法在线计算效率低的问题。同时,通过构建考虑不确定性的马尔科夫决策过程表征不确定环境模型,随后结合基于规则的方法作为考虑安全性的冗余操作,提高运动规划系统的安全性。最后,通过搭建仿真平台训练智能体,从安全性、通行效率、舒适性和计算效率等多个方面分析了方法的有效性。
1 不确定环境下运动过程的构建
马尔科夫决策过程(markov decision process,MDP)是1个典型的表示决策过程的模型[29],如图1所示。其决策过程可以表示为〈S,A,T,R〉,其中S和A分别为状态和动作的集合,T为状态转移模型,R为构建的奖励函数。整个决策过程就是t时刻状态为St的智能体执行动作At,进入下一时刻的状态,下一时刻的状态由当前状态以及当前采取的动作决定,是一个随机变量。
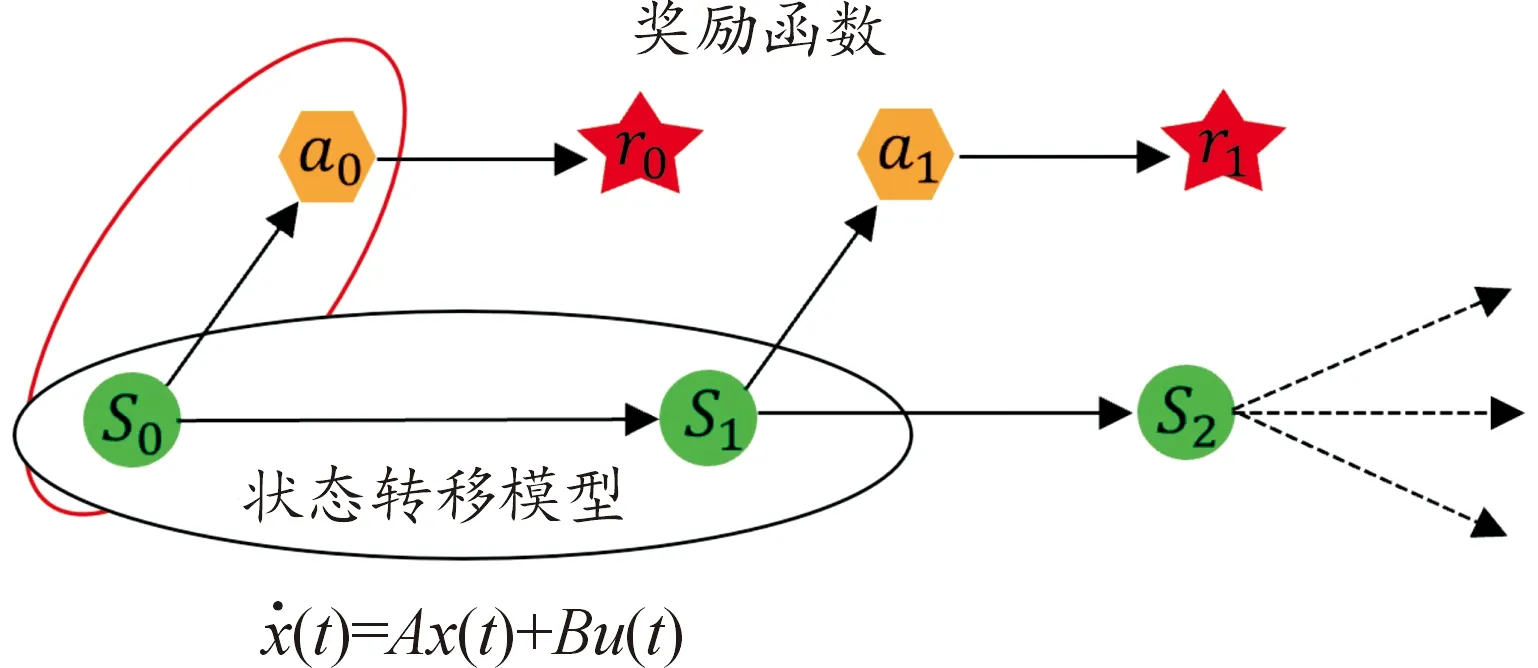
图1 马尔科夫决策过程MDP示意图
对于自动驾驶系统,MDP中的状态可以表示为智能车辆所处驾驶环境中每个时刻的表示,动作为车辆中可被赋予的1个属性,状态转移模型为环境中自我车辆与周围车辆的运动模型,回报为针对驾驶环境而构建的奖励函数。在自动驾驶环境中,由于环境和传感器误差的限制,系统无法准确知道周围环境的状态,因此无法构建一个精确的状态转移模型,此时构建的状态转移模型需要考虑传感器误差的不确定性带来的问题,在实际驾驶中,传感器的状态感知总是存在一定的误差的,这造成了获得的策略输出可能不是最优的,甚至是不安全的。为弥补这一差异,必须考虑这一不确定性。由于明确知道驾驶车辆的模型信息,因此自车的模型是1个确定性的模型。为了规划自车在预测时域内的轨迹,使用了如式(1)的确定性车辆纵向运动学模型,推出给定的强化学习策略的规划解。值得注意的是,与预测周车的交通行为不同,通过结合运动学模型以及基于深度强化学习的方案,可以得到一个合理且确定的规划结果。由于周围车辆的不确定性有着来自驾驶人员意图的不确定性和自车传感器误差带来的不确定性。因此,建立了考虑不确定性的交通流预测模型。智能驾驶员模型(IDM)被广泛应用于周车智能驾驶预测模型,并且能用统一的模型描述从自由流到完全拥堵流的不同状态。使用智能驾驶员模型(IDM)作为交通流车辆的状态转移模型。为使所建模型能够在微观水平上与IDM尽量保持一致,使用IDM模型的运动表达式:
(1)
式中:dt为采样周期;si、vi、ai和ji分别为在预测时域内第i点车辆的纵向位移、速度、加速度和加加速度。
(2)
(3)

为考虑传感器带来的数据误差,我们考虑了加速度噪声,不同车用测速雷达的测速误差会影响策略性能,如式(4)所示。
v′=v+σvel
(4)
式中:σvel为传感器的测速误差。
2 深度强化学习
2.1 强化学习
强化学习是一类机器学习方法,借鉴于行为主义心理学,强化学习算法要解决的问题是智能体在环境中如何执行动作以获得最大的累计奖励。
强化学习问题可以抽象成马尔科夫决策过程(Markov Decision Process),马尔科夫决策过程可以表示为
{S,A,P,R,γ}
(5)
式中:S和A分别为状态和动作的集合;R为奖励函数;γ为折扣因子。强化学习示意图如图2所示。假设t时刻状态为st,智能体执行动作at,进入下一时刻的状态st+1,下一时刻的状态由当前状态以及当前采取的动作决定,是一个随机变量,状态转移概率如下:
pa(s,s′)=p(st+1=s|st=s,at=a)
(6)
式中:pa为当前状态s下执行动作a,下一时刻进入状态s′的条件概率,强化学习问题的核心是执行动作a的策略,它可以抽象成一个函数π,定义了每种状态时选择的动作。这个函数定义了在状态s所选择的动作为:
π(a|s)=p(a|s)
(7)

图2 强化学习示意图
2.2 深度强化学习
深度强化学习方法是在强化学习的基础上结合深度学习而生成的一种更贴近人类思维方式的方法。DDPG (deep deterministic policy gradient)是应用最为广泛的深度强化学习算法之一。如图3所示,基于Actor-Critic(AC)框架的DDPG算法,通过神经网络逼近价值函数和策略函数,网络通过梯度下降的方式进行更新。θQ、θμ分别是策略网络和评估网络的权重。同时DDPG在DQN(deep Q-learning)的基础上进行了改进,结合了DQN以及DPG(deterministic polic gradient)的优点,包括双网络、构建经验回放池等。DDPG有2个网络,即演员网络和评论家网络,2个网络分别负责策略网络参数的迭代更新和价值网络参数的迭代更新[30]。由于自动驾驶车辆通常有一个连续的状态空间和动作空间,而DDPG算法在连续空间中拥有一个良好的表现。因此,本文中使用DDPG算法作为基础的强化学习模型。
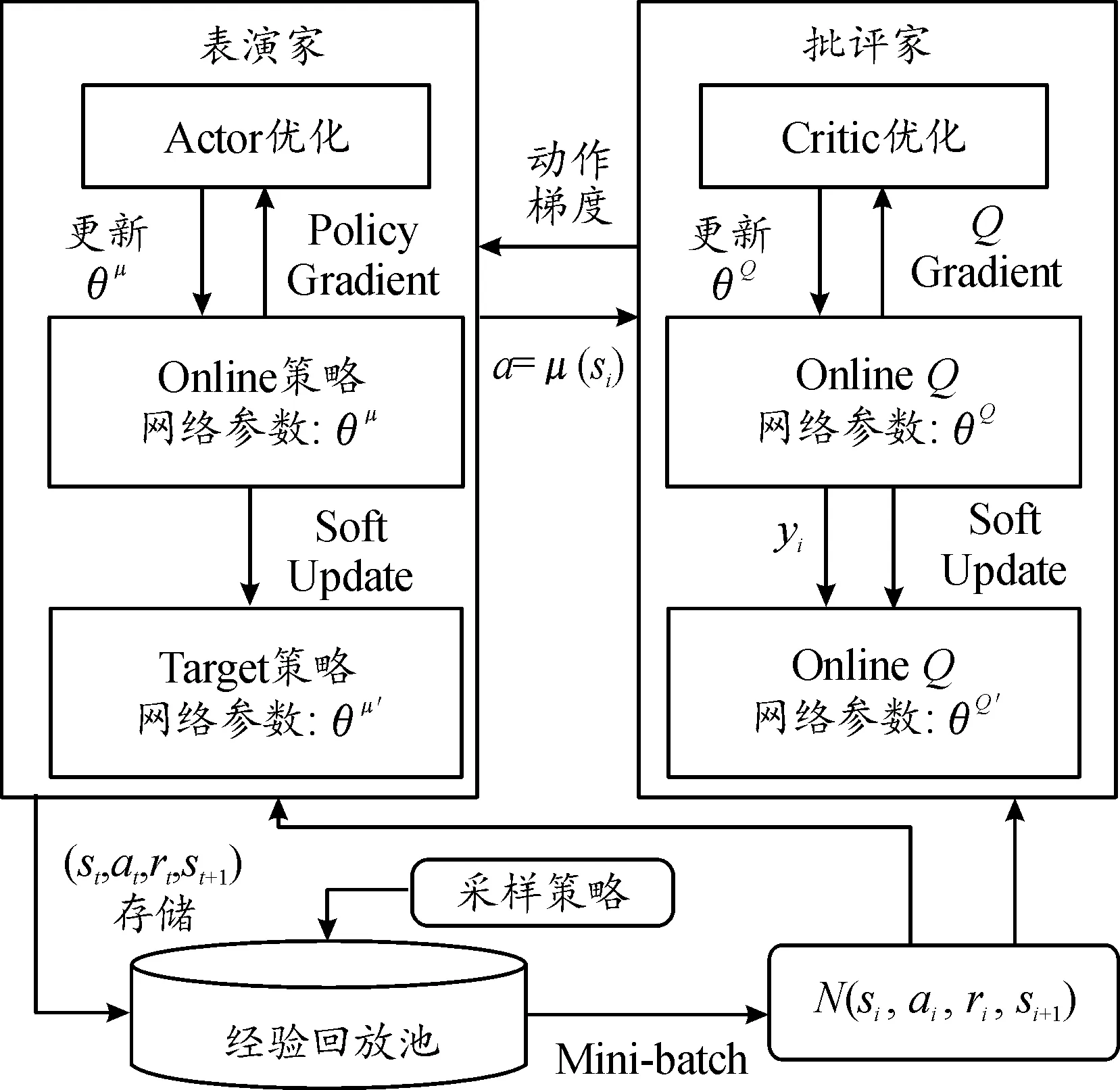
图3 DDPG算法框图
3 基于DDPG算法的运动规划策略框架
为解决基于深度强化学习的方法在复杂环境中如何表达驾驶环境中的不确定性以及如何处理这些不确定性问题,提出了一种基于DDPG的运动规划方法。
图4首先展示了这项工作的基础深度强化学习框架,并在图5所示的场景中完成驾驶策略的训练。通过结合本文中提出的车辆运动学模型推导轨迹规划结果,得出规划轨迹在未来一定时间段内的可视化结果。其次,考虑由于真实信息和传感器信息的差异,采用不确定性区间预测进行近似最优控制,在此基础上,设计了一个基于规则的安全层,该安全层旨在保证不确定区域内的交通信息的最坏情况下的安全性。安全层考虑了车辆的动力性、安全性和最优性约束。最后,通过搭建环岛场景中不同密度下的交通流模型来评估驾驶策略的各种性能指标。
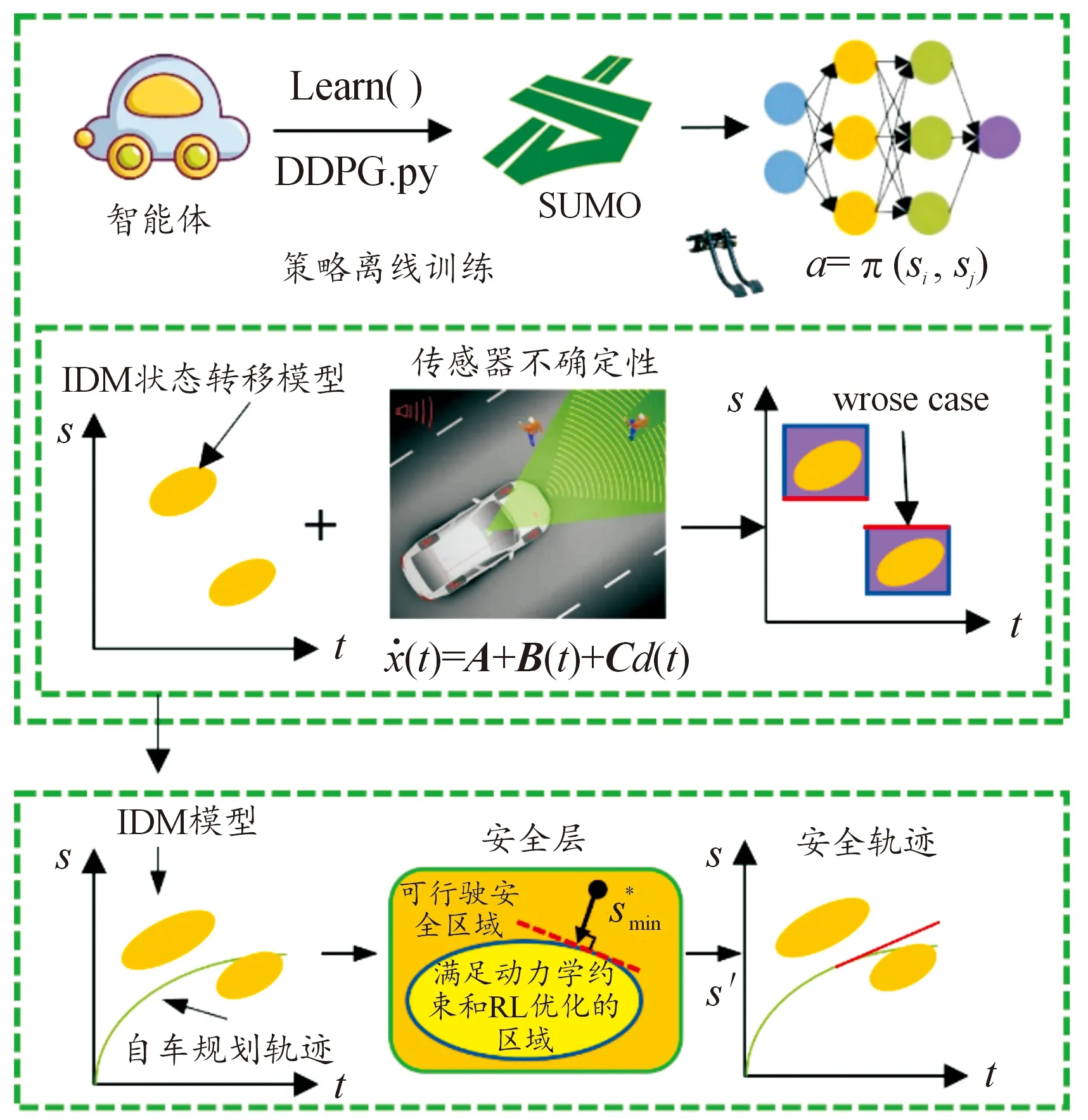
图4 单车道环岛场景示意图
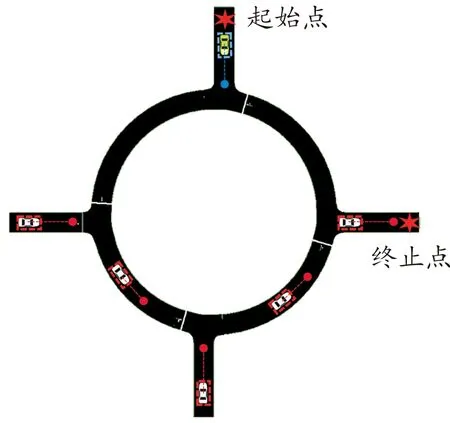
图5 基于强化学习的运动规划算法场景示意图
3.1 强化学习要素定义
状态:所构建的强化学习框架的环境状态包括2种车辆的状态:完成环岛任务的目标车辆(e)及其由完美传感器输出的2个前方(f1,f2)和2个后方(b1,b2)的车辆信息。目标车辆的状态信息包括位置、速度和加速度。前车和后车的状态包括位置(sf1,sf2,sb1,sb2)以及速度(vf1,vf2,vb1,vb2),所以,环境状态空间可以表示为
s=(se,ve,ae,sf1,sf2,sb1,sb2,
vf1,vf2,vb1,vb2)
动作:强化学习框架的动作是完成环岛任务车辆的加加速度值,加加速度值是加速度的导数,通常用来表示车辆的舒适性指标。目标车辆的加加速度值输出在[-3.0,3.0]m/s3,这与道路车辆正常加加速度范围值相同[27]。
奖励函数:在离线训练的过程中,训练神经网络是将驾驶经验从一种形式转移到另一种形式的过程,即把预期的行为转化为神经网络的权重和偏置,强化学习算法使智能体获得的累计回报最大化。因此,设计的奖励函数必须能很好地代表预期行为。此次奖励函数分为3个部分:碰撞、任务完成、任务进行中。对于环岛任务,智能体的第一目标就是能够无碰撞地到达目标点,此时给予智能体一个较大的奖励,保证奖励数值不会被其他部分所覆盖,同时给智能体在发生碰撞时一个较大的负奖励,防止智能体与其他动态障碍物发生碰撞,确保安全性。在智能体的运行过程中,设置舒适性奖励、时间花费奖励等,针对当前环岛场景所设计的奖励函数方程具体的实现方式可表示为
r(x,u)=ω1s(x,u)-ω2-ω3u2
(8)
式中:ω1、ω2、ω3为智能体在探索过程中回合成功/失败、通行效率和舒适性指标加加速度指数的可调权重,s(x,u)表示该回合的成功,回合成功时取值20,回合失败时取值-20。动作u是目标车辆在每一个仿真步长中加加速度值。在满足无碰撞到达目标点的前提下,通过给予智能体加加速度的奖励,尽可能满足车辆的舒适性指标。约束速度尽可能在期望速度之间,同时使加速度和加加速度的值尽可能地小。在测试过程中,发现智能体存在停止不动的情况,来获取更多的累计回报,为防止此类情况的发生,通过设置可调整的时间花费惩罚权重ω2来惩罚此类行为。
3.2 安全层修正框架
在学习过程中,我们期望能够学到最优策略,最优策略能够在当前状态下的动作空间输出最优动作,生成最优轨迹。不幸的是,在理论和实践过程中,我们发现很难获得这样的最优策略。因为驾驶场景的状态空间是连续的,自动驾驶问题转换为强化学习过程中,通过构建等效问题来求解策略,这就意味着无法考虑到无限的状态和约束;其次,模型的精确性也会直接影响规划结果,从而导致了无法在全局保证安全性。本文所提出的解耦端对端的方法,能够输出规划轨迹,为了确保规划结果的安全性能,我们设计了一种安全规则轨迹优化方法。
1) 优化规则:该优化方法的目标是在安全性行驶空间中找到与满足效率和舒适性的强化学习方法目标点最近的目标位置。
(9)
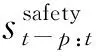
ssafety={s′f∣s∩sf}∩{s′a∣s∩sa}
(10)
式中:s′f为满足与他车保持安全距离的可行驶空间;s′a为满足车辆动力学约束下的可行驶空间。
2) 算法的在线部署:得到离线训练的策略后,结合车辆纵向运动学模型,生成车辆未来时域下的轨迹点,发现不安全的轨迹点后,使用上述优化规则对前面5个时间步长的轨迹点进行规则矫正,提高轨迹输出的安全性,如算法1所示。
算法1:在线部署-矫正不安全轨迹
输入:未来5 s的规划轨迹。
输出:未来5 s的安全规划轨迹。
fori=1,50 do
ui-1=π(xi-1,xj-1)
ui=π(xi,xj)
for eachsi∣t∉ssafety
end
4 实验结果和分析
4.1 DDPG算法训练结果分析
使用自动驾驶仿真模拟器SUMO模拟真实环岛工况,使用DDPG算法对驾驶行为进行训练,同时搭建如表1所示的不同密度下的交通流模型,并在不同模型中完成训练和测试(中等密度训练)。

表1 不同密度的交通流模型
通过离线训练的方式学习当前设置的奖励函数下的行驶策略,为验证离线训练算法的有效性,以本文搭建的仿真环境为实验平台对离线训练算法进行训练,选择智能体在一个训练周期内获得的平均奖励值作为评估指标。通过图6可以看出,整个训练过程中,当前任务的奖励累积都呈上升的趋势且在后面都趋于一个定值,证明了所提出的基于深度强化学习方法的有效性。此外收敛速度、不同随机种子之间的差异以及最终性能随交通工况的不同而不同,原因在于,在不同交通任务中与自车具有潜在冲突的动态障碍物是不同的,从而导致了训练难度之间的差异。本文所有仿真任务均在2.5 GHz 英特尔i7-8700处理器进行离线训练及在线部署仿真。DDPG算法的参数设置如表2所示。
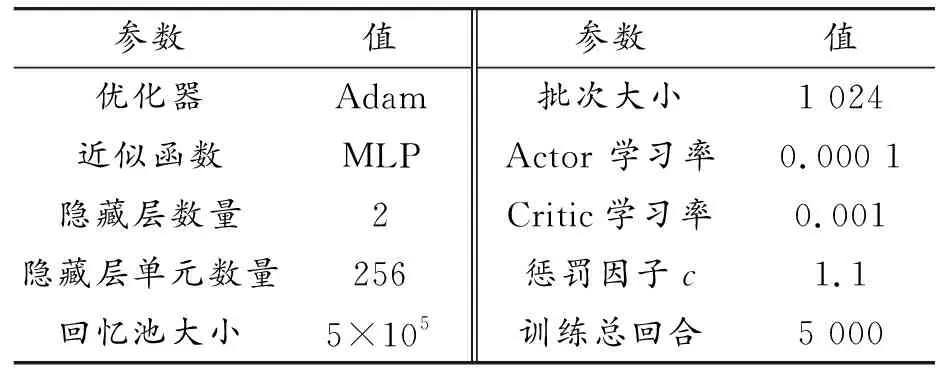
表2 DDPG算法的参数设置

图6 DDPG算法学习曲线
4.2 基于深度强化学习的运动规划结果
在中等密度场景中,完成基于DDPG算法的驾驶策略的训练,获得离线策略。通过将离线策略在线部署,生成高密度和中等密度下的运动规划轨迹。图7显示了使用增加传感器带来的速度噪声的不确定性感知模型的自车和交通流车辆在预测时域内的可视化轨迹,图中的阴影区域表示通过设置传感器测速误差带来的模型不确定性得到的车辆可能的行驶轨迹。本文中考虑了雷达所带来的测速误差,测速精度为±1.5 km/h,此精度为型号BGT24ATR12D的测速雷达,此型号的雷达广泛应用在自动驾驶解决方案中,不同传感器的测速精度有所不同,本文的解决方案是一种考虑误差下的通用解决方案。
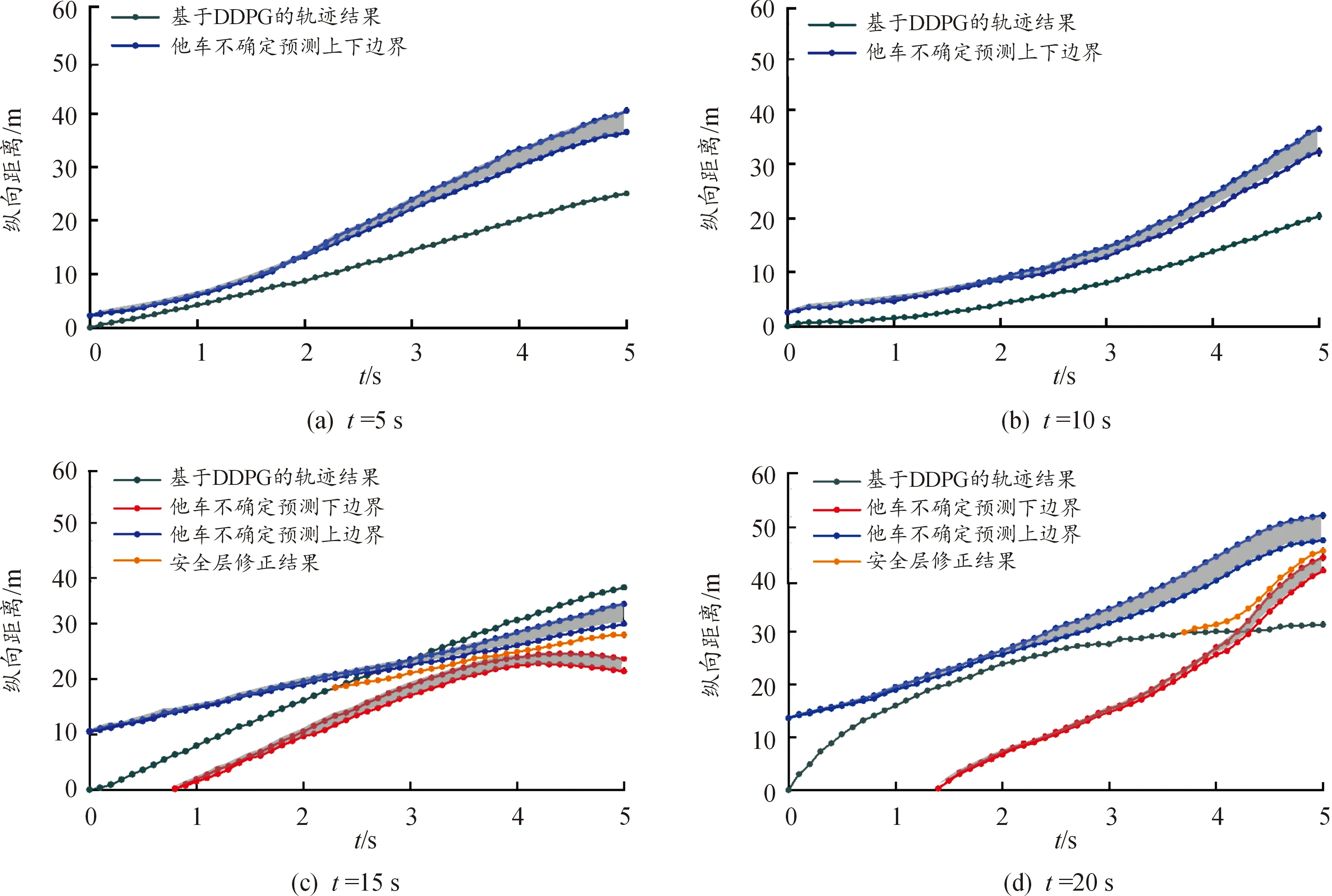
图7 目标车辆和周围交通流车辆的预测轨迹可视化曲线
在高等和低等密度下的交通流模型的训练测试中,图7(a)和(b)显示在一个任务回合过程中的5 s和10 s的规划轨迹可视化结果,所学习到的策略并没有表现出不安全的行为,这证明了DDPG算法所训练的驾驶策略的有效性,并表明了深度强化学习在一定程度上能够获得预期安全驾驶行为。图7(c)和(d)显示在一个任务回合过程中的15 s和20 s的规划轨迹可视化结果。可以看出,自车和交通参与者在预测时域内,可能发生不安全的驾驶行为。这不代表在实际中一定会发生碰撞,而是所训练的驾驶策略和车辆的运动学的规划结果,通过对未来结果的可视化,我们可以结合基于规则的安全层,对不安全的行为进行在线优化,来弥补传感器误差等带来的策略性能的下降。本文中的安全层主要考虑了3个方面的性能考虑,即车辆动力学限制、安全性和强化学习优化结果(尽可能贴近训练结果)。从图7(c)和(d)可以看出,通过考虑安全层的在线优化后,原有轨迹大部分保持不变,不安全的区域被修改。
4.3 不同方法结果对比分析
将本文所提出的方法与今经典基于优化(动态规划+二次规划)和端对端的强化学习方法(DDPG)进行比较,主要衡量以下4个指标:
1) 舒适性。通过计算所有评估回合合并车辆(控制车辆)的加速度的导数(加加速度)平均值来衡量舒适性, 加加速度通常用来衡量车辆舒适性,加加速度值越大,舒适性越差,加加速度值越小,舒适性越好。
2) 安全性。安全性通常由任务过程中的碰撞率来衡量,碰撞率越高则代表安全性越差。
3) 通行效率。通行效率是指合并车辆完成合并任务的平均通行时间。
4) 在线计算效率。在线计算效率是指算法1个周期所花费的计算时间。
表3显示了经典基于优化的动态规划加二次规划的方法(DP+QP)、基于强化学习的端对端方法(DDPG)和本文所提出的方法在低密度的交通流模型中进行测试的结果。可以看出,DDPG的方法的合并时间最短且加加速度值最小,这是由于DDPG方法设置的奖励函数考虑了车辆的通行效率和舒适性。但是其安全性却是3种方法中最低的。这是由于,通过设置考虑多种性能指标的奖励函数无法设置硬约束来满足安全性能,这是使用基于强化学习的方法应用在自动驾驶技术的开发上的一个普遍存在的问题,此类端对端的研究方法不能严格满足安全性。我们所提出的方法通过结合基于规则的方法着重考虑了安全性问题,由仿真结果可以得知,我们的方法在通行效率和舒适性指标上能够达到基于优化方法的表现,且也能够获得一个零碰撞率,从而严格保证安全性。
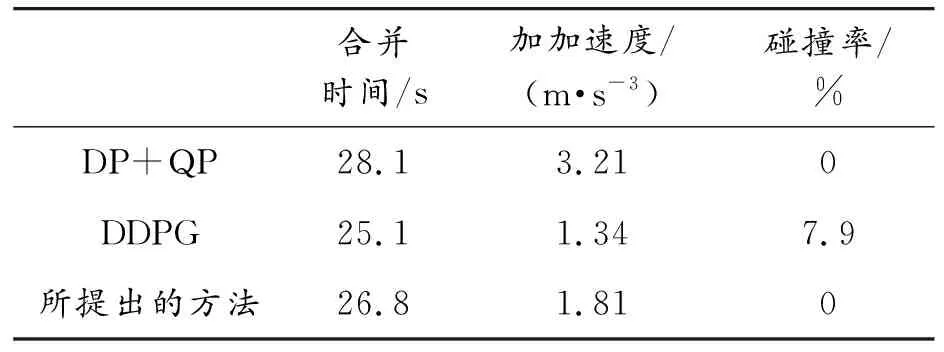
表3 3种方法在低密度下的性能参数
表4和表5显示了3种方法在中等和高等密度下的具体表现,总体趋势与表3相似,但是由于交通密度的增加,3种方法的性能均有所下降,这是一个正常的表现。我们的方法在不同交通密度下均能保持一个零碰撞率,这是我们提出基于规则的安全层修正的结果。所提出的方法能够在严格满足安全性的同时,在舒适性和通行效率上具有一个良好的表现。

表4 3种方法在中等密度下的性能参数
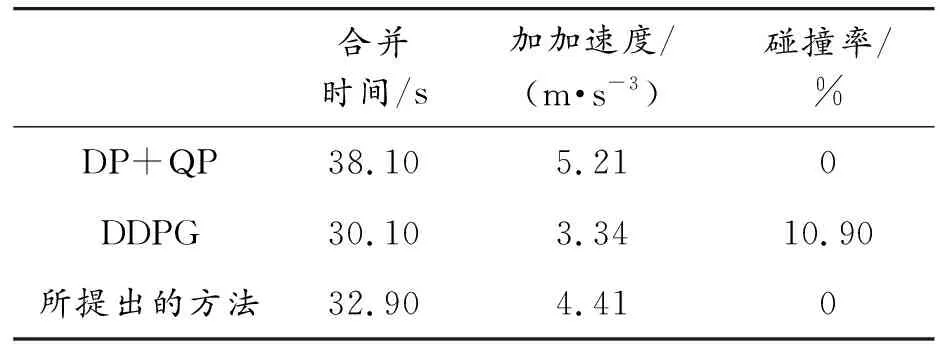
表5 3种方法在高密度下的性能参数
如图8所示,传统基于优化的动态规划和二次规划的方法1个规划周期的在线计算时间大概在100 ms,而本文所提出的方法在线计算时间能够在10 ms以内,降低了1个数量级。这是因为本文中所提出的方法将大部分在线计算的压力转移到了离线端。在工业应用中,当车端算力有限时,本文所提出的方法可能会成为一个比较理想的解决方法。
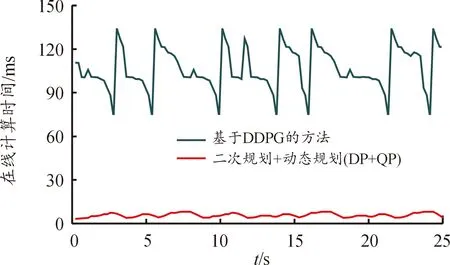
图8 2种方法的在线计算时间曲线
5 结论
1) 所提出的方法基于深度强化学习解决了含有大量约束的自动驾驶运动规划问题。所提出的方法与基于在线优化的传统算法相比,降低了车辆与环境大量交互而产生的对车端硬件设备的算力需求。
2) 该方法明确考虑了智能车辆传感器误差带来的不确定性,建立了基于学习方法的运动规划系统基本框架,并基于马尔科夫决策过程构建了一个模型来表征具有不确定性的驾驶环境。
3) 结合基于规则的方法设置安全层,对轨迹结果进行评估的同时能够进行在线动作修正。增加1层安全防护,使结果更加鲁棒可靠。
4) 通过构建仿真框架对所提出的方法在不同交通密度下进行了广泛的评估,验证该方法在安全性、舒适性和在线计算效率等方面的性能。
5) 本文提出的基于深度强化学习的运动规划方法在自动驾驶运动规划领域中具有应用价值。目前的研究仅集中在车辆的纵向规划中,后续研究可以考虑车辆的横纵向运动规划,考虑更加优秀的区间预测器,使不确定性预测区间不至于过度保守。
