“大数据+信贷工厂”普惠金融模式研究
2023-12-19吴敏刘姣林志峰
吴敏 刘姣 林志峰


摘 要:商业银行发展普惠金融业务普遍面临审核难度大、运营成本高、信用风险大、贷后管理难等问题,如何破解普惠金融发展难题显得尤为重要。本文结合理论研究及银行实践经验首次提出了“大数据+信贷工厂”这一发展普惠金融的创新模式,主要介绍了该模式的概念、特点与优势,并结合H银行的样本数据,分析论证了该模式下的核心风控模型能够有效区分“好客户”和“坏客户”,对于识别客户风险、加强风险管理有积极作用,同时,研究了由“大数据+信贷工厂”创新模式代替传统模式发展普惠金融的比较优势,实证分析证明该创新模式能够显著降低运营成本,提高风控水平,增加业务收入和毛利润,提升规模化增长水平,增强该普惠金融创新模式的可复制推广能力。最后提出应进一步加强顶层设计、构建成本可负担商业可持续的普惠金融长效机制、提升普惠金融业务的风险管理能力相关政策建议。
关键词:普惠金融;大数据;信贷工厂;效益评价模型;金融科技;风险评估
DOI:10.3969/j.issn.1003-9031.2023.11.007
中图分类号:F830 文献标识码:A 文章编号:1003-9031(2023)11-0071-17
一、引言
普惠金融(Financial Inclusion)的概念自2005年联合国进行广泛宣传后引入我国,随之受到国内社会大众的广泛关注和讨论。发展普惠金融契合服务实体经济、服务人民生活的理念,党中央和国务院一直高度重视普惠金融的发展。2015年国务院印发了《推进普惠金融发展规划(2016-2020年)》,对普惠金融工作进行了顶层设计,发展普惠金融正式确立为国家战略规划。发展普惠金融也面临诸多困难,中国人民银行发布的《中国普惠金融指标分析报告(2021)》,指出在全球经济增长放缓、内外部环境更趋复杂严峻的背景下,普惠金融服务的广度和深度仍然不足,居民家庭和个人的金融状况需要得到更多关注,普惠金融的风险防范化解需要不断加强。普惠金融的重点服务对象为小微客户和中低收入群体,这类客户通常具有资金需求额度小、资金占用周期短、需求頻率高、资金需求较急的特点,通常也难以提供有效抵押物和真实可信的财务数据,商业银行运用传统的业务模式发展普惠金融普遍面临审查难度大、运营成本高、信用风险大、贷后管理难等特点,难以同时实现可获得性、可负担性和风险可控的均衡,即难以同时解决“普”“惠”“险”的问题(郭正江等,2021),商业银行基于成本和风险的考量,对中低收入客户群体存在“惜贷”行为。因此,如何创新普惠金融业务模式、破解普惠金融发展难题显得尤为重要。
国内外专家学者对掣肘普惠金融发展的关键因素进行了研究,普遍认为信息不对称是关键因素之一,容易导致普惠金融的业务成本增加或者信用风险难以控制。随着大数据、云计算等为代表的信息技术飞速发展,商业银行可以充分借助大数据技术,对客户数据进行全面分析和挖掘,增强对客户的识别与了解(Manyika J,2011),减少信息不对称的问题,提高企业的决策效率和准确度,从而降低运营成本,提高生产效率,减少信用风险。“信贷工厂”是指银行参照工厂“流水线”的标准化模式对信贷业务的全流程环节进行标准化批量处理,借助“信贷工厂”模式对传统信贷模式进行变革与优化,能够提高审批效率,降低运营成本(林春山,2009)。
结合已有文献研究可知,目前学术界对大数据和信贷工厂的研究还存在部分局限:第一,目前学术界还没有将大数据技术和“信贷工厂”相结合的模式研究,二者对普惠金融的共同作用机理研究还未涉及,“大数据+信贷工厂”普惠金融模式有什么特点与优势?其核心业务模型是否能够精准识别客户、控制风险?这些还鲜有研究。第二,“大数据+信贷工厂”模式是否有助于提升银行普惠金融业务的经济效益?商业银行怎样有效地结合运用大数据技术与“信贷工厂”的优势创新普惠金融模式?上述问题的回答有助于破解长期困扰商业银行普惠金融发展的难题,为我国普惠金融的模式创新提供有益的参考借鉴,也是本文亟待研究的焦点问题。
二、文献综述
(一)发展普惠金融的难点及意义
普惠金融的概念,是指遵循机会平等和商业可持续原则,通过合理的可负担成本,为有金融服务需求的社会各阶层群体提供适当、简捷、有效的金融服务,普惠金融具有包容性、便捷性、可获得性和商业可持续性四大特征。发展普惠金融具有较大的经济意义和社会效益,学者对此已展开了丰富的研究。Karlan and Zinman(2010)、Dupas and Robinson(2011)认为发展普惠金融能够带动就业、刺激消费和投资,特别是中低收入群体获得的普惠金融服务越多,则更能刺激个体及家庭的消费,提高投资意愿和收入水平。Mandira and Jesim(2011)重点研究了普惠金融发展对宏观经济增长的影响,研究发现一个国家的金融普惠程度越高,则其经济社会发展程度、金融平等程度、城市化水平越高。因此研究促进普惠金融发展的有效模式非常有必要。
基于信息不对称理论,在市场经济活动中,由于掌握信息的数量、获得信息渠道的差异,各主体将承担不同的风险和收益。信息不对称是普惠金融发展难的重要原因之一,银行因为信息不对称原因容易产生“惜贷”或“拒贷”行为,要想解决普惠金融业务的难点问题,需要加强银行对客户信息全面的收集和分析,尽量减少信息不对称的程度。
交易成本高是普惠金融发展难的另一个重要原因。根据希克斯(J.K.Hicks)和尼汉斯(J.Niehans)提出的交易成本创新理论,在经济活动中交易成本处处存在,影响着企业的效率水平,降低交易成本是金融创新的支配因素和主要动机。小微客户或者中低收入等弱势群体因为信贷资金需求额度小,加之缺乏抵质押物及全面的财务报告,客户信息收集和业务审查相对更为复杂,单笔业务平均交易成本相对较高,银行出于经济效益和规模效应的考虑,会产生“惜贷”行为,故交易成本高的特点阻碍了普惠金融业务的发展。
(二)大数据技术对普惠金融的作用机理
大数据具有大規模、高速度和多样性三大特征(chen et al.,2012;McAfee and Brynjolfsson,2012),已经成为一种重要的商业资本和经济投入。大数据的收集、处理与运用可以统称为大数据技术,掌握这门技术这需要强大的决策力、洞察发现力和流程优化能力。
大数据技术向金融领域渗透融合,释放出巨大的创新活力和经济价值,基于客户特征的大数据采集、分析和挖掘,并结合人工智能算法和机器学习算法,成为金融机构进行客户风险识别、优化风险管理的重要方式,受到金融机构的青睐。大数据已发展成为一种新型的生产要素,将互联网、大数据、云计算等信息技术运用于普惠金融实践,能够显著提高对目标客户的识别度,从而弥补传统普惠金融的不足(宋玉茹,2022),商业银行可以充分借助大数据技术,对客户数据进行分析和挖掘,增强对客户的分析与风险识别,减少信息不对称程度,降低交易成本,有助于精准营销、客户分类和风险管理(ManyikaJ,2011;Strivastava and Gopalkrishnan,2015;óskarsdóttir M,2019),通过应用大数据和人工智能的技术能够简化信贷审批流程,强化风险管理,提升普惠金融程度(Che chang Chang,2019)。大数据技术的应用可以优化企业的业务流程和组织架构,使其信息传递更为高效,减少摩擦成本,实现更为高效的管理模式和业务模式,提升审查效率(Brynjolfsson et al.,2011)。
(三)“信贷工厂”模式对普惠金融的作用机理
“信贷工厂”模式最先由新加坡的“淡马锡”公司提出,国内由中国建设银行和中国银行率先引进试点,后在全国推广开来。“信贷工厂”模式是指银行参照工厂“流水线”的标准化模式对信贷业务的全流程环节进行标准化批量处理。“信贷工厂”模式的主要特点,即业务的标准化、批量化处理,该特点贯穿了信贷业务的全流程(Wilson,2010)。
“信贷工厂”模式是对传统信贷模式的一种变革与优化,与传统业务模式相比在产品营销、业务办理和经营模式等方面具有一定的比较优势(Fullerton,2009)。“信贷工厂”模式由于其标准化性质有利于减少业务信息在人员和流程之间传递的成本和摩擦,同时人员标准化分工又减少了对前台人员的经验和学历要求,能够优化组织架构管理、降低运营成本、提升业务办理效率,优化信贷服务体验,有助于银行扩大信贷业务规模实现规模效应,在强化风险管控的前提下能够提升银行的经济效益(林春山,2009;安丽娟和李昕,2010;杨晓璐,2011)。
三、“大数据+信贷工厂”普惠金融模式介绍
(一)概念及特点
“大数据+信贷工厂”普惠金融模式就是利用大数据、互联网等信息技术贯穿普惠金融业务全流程,参照制造业“工厂化”方式,对银行信贷审批的组织架构和业务流程进行切片化、标准化改造,从而使前台、中台、后台作业岗位聚焦切片职责,实现产品标准化、职责切片化、作业流程化、风险分散化、管理集约化、队伍专业化,最终达到大幅提高审批效率、大幅降低单笔作业成本、整体降低信贷风险、优化信贷审批流程、提升客户体验的效果。
大数据技术和信贷工厂是相辅相成、相互促进的,没有大数据技术全流程深度融合,业务流程在各个环节就做不到职责的切片化、标准化和高效化,在传统的普惠金融业务模式下,从前台信贷员到中台审批每个环节都要具有信贷知识和经验,有了技术支持后,数据和信贷工作经验由系统来把控和不断完善,不同岗位可以聚焦到自己相应负责的切片化工作上,标准化程度更高,从而业务更加高效。反过来,信贷工厂的作业方式,又能更好地促进大数据技术应用,专业化、标准化、数字化的数据、流程、经验和非标准化的作业方式相比,让大数据应用可以持续改进和提高,二者的结合能够产生质变的效果。
(二)运行流程及比较优势
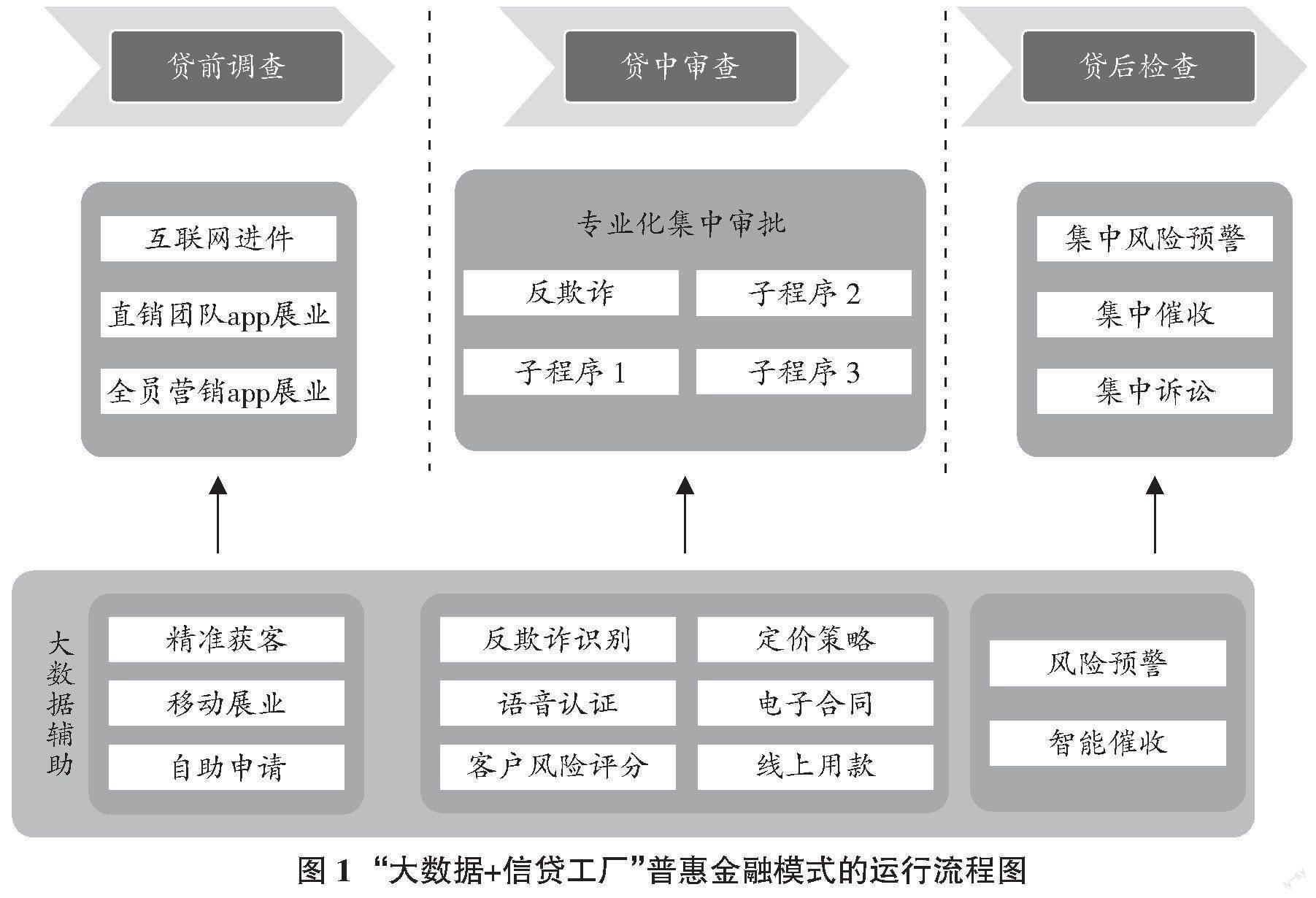
“大数据+信贷工厂”普惠金融模式的运行流程主要包括前台、中台和后台相关工作,充分利用大数据作为技术辅助支撑,把相关工作切片化,使得每一个岗位的工作更加标准化和专业化,该模式运行流程详见图1。
传统的普惠金融信贷模式主要基于相对少量的客户信息如征信和银行流水等,风险判断和信贷决策主要依靠人员经验,同时业务流程上大多未能形成标准化、切片化的职责分工,人员的专业化水平及主观性会较大影响业务实践效果,具有不稳定性,且容易产生“道德风险”。与传统模式相比,“大数据+信贷工厂”模式具有较大优势,能够解决普惠业务的难点问题,从各业务流程的视角而言,该模式的优势主要包括以下几个方面。
第一,实现标准化、易操作的前台移动展业。因为有了信息技术做支撑,能够降低对客户经理的经验要求,可进行批量化培训和上岗,且能实现标准化、易操作的移动展业。客户可以通过移动互联网渠道自主完成贷款申请,客户经理采用移动展业模式获客,借助大数据平台实现信息关联与共享,能够实现信息快速录入、自动核验,节省人力,提升客户体验。
第二,实现中台的专业化集中审批。中台工作采用工厂化的流程将待审批的贷款申请随机分配到专业的审批人员,进行批量化、集中专业审批。通过引入第三方公信力较高的数据源(人行征信、公安、司法、社保、学信网等),借助大数据平台、客户风险评分模型和授信额度模型等实现对客户信息的真实性核查,在提高审批效率的同时,有效的减少了材料造假风险及信息不对称风险,风险程度较高或较低的客户由系统自动完成拒绝或通过操作,对其他客户依据大数据分析给出参考额度及风险提示内容,提高审批效率。
第三,实现后台的集中风险管理。通过收集分析客户异常交易、收支情况、关联人情况、第三方征信等数据信息构建风险预警模型和智能监测系统,进行实时风险预警,同时安排专业团队进行统一的集中催收和集中诉讼,实现集中、动态、专业的风险管控。
图2以H银行信用卡业务践行“大数据+信贷工厂”模式为例,展示详细的模式流程圖,在该模式下信用卡业务全流程依托大数据技术开发了各类业务管理系统,实现了标准化和切片化的职能分工,实现了智能化、高效化的业务运营。
四、基于Logistic回归分析的风控模型研究
(一)模型的理论基础
“大数据+信贷工厂”普惠金融模式充分依靠大数据技术构建风控模型来进行风险管理,这与过去主要依赖人工经验识别风险并进行信贷决策的传统普惠金融模式有本质区别。业内使用的风控模型种类较多,考虑到基于Logistic回归分析的评分卡模型具备简单、稳定、技术成熟、易于监测和部署等优点,本文主要研究基于Logistic回归分析的评分卡风控模型,该模型基于大数据技术,利用客户大量的、多样化的、全面的数据刻画其指标表现,通过风险量化成分值的方式来预测客户违约可能性大小,然后通过划线策略区分好坏客户,从而达到客户风险分类的风险管理目的。
(二)模型的开发流程
基于Logistic回归分析的评分卡风控模型开发流程主要分为以下几个步骤。一是需求调研,通过对业务目标的分析,结合对客户数据的理解,深度研究分析确认项目目标。二是业务目标定义,根据业务需求目标定义好坏客户的划分标准,确定观测窗口和表现窗口的范围,针对汇总的可用数据确定样本的筛选规则。三是数据准备,为模型开发进行数据提取和数据预处理,在基础变量的基础上采用一定方法生成衍生变量,并形成宽表,结合业务经验,初步筛选模型变量。四是模型构建,综合采用变量聚类、IV、随机森林等方法对模型变量进行深入筛选构建模型,主要包括建模宽表、变量预处理、变量筛选及分项和模型拟合等过程。五是模型验证,通过KS值、PSI值等指标对模型的效果进行验证。六是上线监控,针对模型的拟合度及稳定性继续监控,如果模型拟合度和稳定性变差,需要调整模型。
(三)模型的评分计算公式
二分类Logistic回归模型满足如下的条件概率分布:
其中,x∈Rn是输入,Y∈{0,1}是输出,w∈Rn和b∈R是参数,w称为权值向量,b称之为偏置,w·x为w和x的内积。
某个事件发生的概率P和不发生的概率1-P之比,称之为几率Odds,其对数几率回归表达公式为:
基于Logistic评分卡的分值可以写成下列形式:
Score=A-B(β0+β1x1+…βpxp) (4)
其中,变量x1,x2…,xp为自变量对应的WOE(指标权重)值,因变量Score是信用风险的量化得分,得分越高违约概率越低。
(四)模型的评价指标
目标定义。目标定义影响评分卡解决问题的有效性,好、坏客户需要基于各阶段迁移情况及业务需求进行定义。本文拟定的目标定义为:好客户为表现期内未发生过逾期的客户;坏客户为表现期内发生过M3+逾期的客户;灰色客户为不满足表现期或表现期内发生逾期但没有达到过M3+的客户。
样本数据。本文样本数据来自国内H银行2016年11月到2017年2月的实际业务数据12801笔,为了使实验样本有足够的表现期且具有代表性,剔除掉命中H银行行内准入规则、反欺诈规则和高风险规则集后的966笔数据,剩余样本数据合计11835笔最终被确定使用,由上述数据生成开发样本及验证样本,将宽表数据分为两份数据集合,一份用来训练模型参数,另外一份用来测试模型的效果。
变量预处理及衍生变量生成。收集的数据主要包括申请表数据、人行征信数据、行内数据和第三方机构数据等变量。根据金融机构的实践经验、金融业务特点和可用数据特征三个主要标准对数据进行变量筛选,并结合众多项目经验总结汇总生成衍生变量,有效提取数据信息。
变量降维、分箱及筛选。变量的筛选一般使用IV值(Information Value)、Gini指数等判断变量的重要性,通过相关性分析排除变量间共线性,通过随机森林、GBDT(Gradient Boosting Decision Tree,梯度下降树)等方法挑选重要程度较高的变量最终达到降维的目的。变量集降维之后,需要将变量进行细分箱,然后在满足业务解释的情况下把同类或者相近的细分箱进行合并,即粗分箱。在粗分箱阶段,去掉未满足粗分箱三条原则的候选变量、单变量分析IV值低于0.02的变量和随机森林重要性排名100之后的变量,对候选变量进行业务分析,去掉不符合业务预期和不具备模型预测能力的变量,例如姓名、生日、身份证号等变量,筛选出30个初始变量。
模型逐步回归拟合。通过重复逐步回归和消除共线性步骤,尝试加入剔除变量看是否可以在稳定性保证的前提下提升KS效果。选取相对表现最好的变量,输出最终评分。最后结合业务专家经验,确定模型变量共19个,详见表1。
确定客户评分。根据最终确定的模型变量,通过逻辑回归方法进行拟合,结合评分卡计算公式,最终得出客户评分。
(五)实证分析结果
1.KS值分析
KS值用来判断模型区分风险的优劣程度,属于非常重要的判断指标,表2为KS值的评价标准,KS值在51%~75%之间说明模型效果显著,根据同行经验,训练集和测试集的KS值之差绝对值小于5%说明模型稳定性较好,在辨识好坏客户的效果上是显著的。为了检验本文评分卡模型的效果,本文运算得出训练集和测试集的KS值,同时为了对比运用大数据技术的模型与仅运用人行征信数据模型的效果差异,本文也选择了仅引用人行征信变量通过同样的模型构建流程来构建模型,并运算出测试集的KS值。基于大数据技术的评分卡模型的训练集和测试集的KS值分别为57.12%和56.65%,说明模型对客户风险的区分能力强,训练集和测试集的KS值差值为0.47%,差值小说明模型稳定性好。同时,基于大数据技术的评分卡模型的KS值比基于人行征信变量的评分卡模型的KS值高10.35%,说明前者对客户的风险区分能力更强,风险控制效果更好。
2.评分分布及稳定性评估
根据申请评分卡对模型开发样本人群进行评分,将评分由低到高进行排序,然后根据申请评分相同的分数段分进行分组,查看客户在不同分数区间内的分布情况。模型评分结果如图3所示,坏账户的分布呈左偏正态分布,随着分数的增加逾期率在逐步递减,表现出了评分的有效区分能力;客群的评分区间在300至1000之间,其中低分数段人群的坏账率较高,随着分数的增高,坏账率呈现逐渐降低的趋势,这说明评分卡存在排序功能,并能有效的对策略应用提供参考,更好的实现自动审批功能。通过分布图也可以看出训练集和验证集在各个分数段的人数占比基本趋势是一致的,这表明评分分布是稳定的。
3.PSI(Population Stability Index)指标分析
PSI指的是群体稳定性贡献指数,反映了验证样本在各个分数段的分布与建模样本分布的稳定性,图3显示本文模型运算PSI指标值为0.0035。结合表3关于PSI参考值的说明,在行业内一般认为模型PSI指标值小于0.1就说明模型具有较好的稳定性,因此可以判斷本文模型是稳定的。
4.假阳性率和假阴性率指标分析
根据通过率表和拒绝率表的交叉结果本文设定自动拒绝划线为500分,设定自动通过划线为600分,表4和表5分别为自动审批拒绝划线为500分时的混淆矩阵及自动审批通过划线为600分时的混淆矩阵,根据表达式计算出自动审批通过划线600分时的假阳性率为4.86%,假阴性率为39.87%,说明自动通过划线审批确保60.13%的好客户自动审批通过,排除95.14%的坏客户;根据表达式计算出自动拒绝划线500分时的假阳性率为49.19%,假阴性率为7.94%,说明自动拒绝划线审批能够把50.81%的坏客户排除在外,只把7.94%的好客户漏掉,自动审批不通过的客户中好客户占比39.87%,其中80.09%会通过人工方式审批。从假阳性率和假阴性率指标分析来看,本文模型能够有效的识别“好客户”与“坏客户”,智能审批的准确率较高。
综上所述,从以上模型评估的指标结果分析来看,基于大数据技术的评分卡风控模型具有较好的信用风险评估能力,通过该模型能够有效的识别“好客户”与“坏客户”,模型的风险预测能力较强、稳定性较好。
五、效益评价分析模型研究
(一)模型的理论基础
“大数据+信贷工厂”普惠金融模式的经济效益如何,需要结合业务数据进行实证分析,目前学术界可借鉴参考的针对金融机构具体的普惠金融效益评价方法较为缺乏,本文拟结合层次分析法和模糊数字方法,构建针对普惠金融信贷模式实施效果的效益评价分析模型。通过模糊数学方法的引入,对评价指标进行量化处理,使得不同评价对象的指标得分更加客观。层次分析法是Salty在1974年提出的综合评价方法,能够把一个复杂的评价问题层层拆解构建层次分明的指标体系结构,通过指标间进行重要性判断,求得归属于某个父节点指标下同层子节点指标的不同指标间的权重,最后根据加权计算出每个指标的权重值,结合专家评价法根据不同的指标的特征给指标一个分值,这样通过指标权重和指标分值,可以计算出最终评价对象的得分。王莲芬和许树柏(1989)在书中具体描述了层次分析法的具体理论及方法,本文学习并参考了其部分方法理论。
(二)模型的构建方法
明确指标集合。指标集合是层次分析法中的指标体系中的评价指标,每个指标的权重值为层次总排序的权重值。
构建模糊评价矩阵。根据模糊数学方法,对每个评价对象每一个指标的分值进行量化,形成模糊评价矩阵。对于n个评价对象,指标数量为m的模糊评价矩阵R,如下所示。
其中,rij是评价对象j在i个指标的量化得分值,量化得分值由隶属度函数计算得到。
(三)效益评价指标体系的确定
1.评价指标构成
本文根据普惠金融业务普遍的效益评价目标,结合专家调查评价的建议,采用层次分析法分析筛选评价指标,评价指标体系共2个层级9个指标,由上而下形成递阶结构。考虑到指标的可衡量和可操作性,最终经过多轮筛选,本文拟选择以下效益评价指标体系。
2.指标权重计算
本文邀请到30名精通业务的专家进行打分,对各指标的重要程度进行判断,假设各专家的重要性一致,则采用算术平均的方式得到准则层P及指标层L各元素之间相对重要性的比较值。
总排序权重向量为:
W(L2)=(0.2211,0.1089,0.1005,0.0495,0.1188,0.2412,0.04,0.04,0.08)(7)
3.模糊评价矩阵
根据模糊综合评价的方法,上述已经得出指标权重向量,还需要模糊评价矩阵数据,就可通过模糊综合计算式(6)计算出评价对象的综合评分,根据各评价对象的评分高低就可以区分判断出评价对象的优劣。为了得出模糊评价矩阵,需要对评价体系指标进行模糊评价。以人力成本率指标为例,人力成本率符合值越小越佳指标,适用其对应的公式,假设T1-T3年的值分别为XT1,XT2,XT3,则隶属度上限al为max(XT1,XT2,XT3)*1.1,隶属度下限al为max(XT1,XT2,XT3)*0.9,则T1年的隶属度值为:
同理可以计算出某年某业务条线的指标隶属度值。所有年份(n年)的所有指标隶属度值,利用所有指标的隶属度值可以构成一个9*n模糊评价矩阵。
4.模糊综合评价得分
综上所述,本文可应用各指标的权重值及隶属度值进行“大数据+信贷工厂”模式的效益评价,假设某t年的隶属度值为向量XT(Xc1,Xc2,...Xc9),则某t年的效益评价得分计算公式如下:
其中,Yt为某年某业务的效益评价得分;WTc为各评价指标的权重值,R为各指标的隶属度值。通过上述计算公式可以计算出某一年某项业务具体的效益评价得分,可以对同一业务不同年份的效益评价进行纵向的对比,也可以对同一年份不同业务的效益评价进行横向的对比,通过构建上述效益评价模型,可以对“大数据+信贷工厂”模式的实践效果进行客观量化的评价。
六、“大数据+信贷工厂”模式的实践效果
(一)基于H银行零售贷款样本数据的实证分析
1.样本选择
H银行自2016年开始逐步探索将“大数据+信贷工厂”模式运用于零售贷款条线,在前端报件营销、中端集中审批和贷后管理及服务方面充分运用了该创新模式。鉴于H银行的零售贷款条线主要从2016年开始逐步运用该创新模式,故主要选取了零售贷款条线2016年至2019年的零售贷款数据进行纵向对比分析,纳入统计样本中的借款人在行业分布和收入上具有分散性,能够代表各类普惠金融的客群,考虑到普惠金融金额小而分散的特点,主要选取500万元以下的零售贷款样本数据进行分析。
2.实证分析结果
从运营成本、风险控制水平、收入和利润水平以及规模化增长水平四个评价维度分别进行具体分析,根据第五部分普惠金融效益评价分析模型,可进行业务效益的整体综合评价,根据普惠金融效益评价分析模型的公式,将零售业务条线2016年至2019年末的贷款样本数据进行处理计算后,得出零售业务条线效益模糊属性值矩阵,如表7所示。
从运营成本、风险控制水平、收入和毛利润水平以及规模化增长水平四个评价维度共9个评价指标来看,表7中显示2016年至2019年期间9个评价指标均有所改善,具体表现为:运营成本显著下降,其中人力成本率和管理成本率降幅显著;风控水平得到有效提升,不良率和损失率降幅较大,维持在业内较低的水平;盈利能力显著提升,收入和毛利润逐年增幅较大;规模化增长水平较高,借助大数据技术对前台人员的学历和经验要求降低,人均产能水平提高,该创新模式更易复制推广。综上所述,从单个指标的纵向对比情况来看,H银行零售贷款业务实施“大数据+信贷工厂”模式相比传统业务模式效果更好。
下面进行综合效益的评价分析。根据零售业务条线效益模糊属性值矩阵,通过前述介绍的隶属度值计算方法,得出零售业务条线效益模糊量化得分值矩阵。把隶属度值矩阵的值带入式(9)计算零售业务条线的模糊量化得分值,其中2016年得0.1652分,2017年得0.3846分,2018年得0.6541分,2019年得0.8808分。换算成百分制对零售贷款业务条线进行效益评价计算综合得分,零售业务条线2016年至2019年综合效益评价得分分别为16.52分、38.46分、65.41分和88.08分,样本期间内综合效益评分显著提升,从计量模型的统计结果来看,H银行零售贷款业务自从“大数据+信贷工厂”模式实施后业务综合效益逐年提升,成效显著。
(二)基于H银行信用卡业务样本数据的实证分析
1.样本选择
H银行自2017年开始逐步探索将“大数据+信贷工厂”模式运用于信用卡业务,在前端报件营销、中端集中审批和贷后管理及服务方面充分运用了该创新模式。信用卡条线主要选取了2017年至2019年的零售贷款数据进行纵向对比分析,研究该模式在信用卡条线的实施效果。纳入统计样本中的借款人在行业分布和收入上具有分散性,业务额度小而分散,能够代表各类普惠金融的客群。
2.实证分析结果
从运营成本、风险控制水平、收入和利润水平以及规模化增长水平四个评价维度分别进行具体分析,根据第五部分普惠金融效益评价分析模型,可进行信用卡业务效益的综合评价,根据普惠金融效益评价分析模型的公式,将信用卡业务条线2016年至2019年的业务样本数据进行处理计算后,得出信用卡业务条线效益模糊属性值矩阵,如表8所示。
从运营成本、风险控制水平、收入和毛利润水平以及规模化增长水平四个评价维度共9个评价指标来看,2017年至2019年期间多个评价指标的模糊量化得分均逐年增长,具体表现在:运营成本显著下降,其中人力成本率和管理成本率降幅显著;风控水平表现尚可,从样本数据来看不良率和损失率指标仍维持在业内较低的均值水平;盈利能力显著提升,收入和毛利润逐年增幅较大;规模化增长水平较高,借助大数据技术对前台人员的学历和经验要求降低,人均产能水平提高,该创新模式更易复制推广。综上所述,从单个指标的纵向对比情况来看,H银行信用卡业务实施“大数据+信贷工厂”模式相比传统业务模式效果更好。
下面进行综合效益的评价分析。根据信用卡业务条线效益模糊属性值矩阵,通过前述介绍的隶属度值计算方法,得出信用卡业务条线效益模糊量化得分值矩阵。把隶属度值矩阵的值带入式(9)计算信用卡业务条线的模糊量化得分值,2017年至2019年模糊量化得分分别为0.2773分,0.5219分和0.7621分。换算成百分制对信用卡业务条线进行效益评价、计算综合得分,信用卡业务条线2017年至2019年综合得分分别为27.73分、52.19分和76.21分,样本期间内综合效益评分显著提升,从计量模型的统计结果来看,H银行信用卡业务自从“大数据+信贷工厂”模式实施后业务综合效益逐年提升,成效显著。
七、研究结论与政策建议
(一)研究结论
本文结合相關理论研究及银行实践经验详细阐述了“大数据+信贷工厂”普惠金融模式的概念、特点与优势,并选取了H银行2016—2019年的零售贷款条线及信用卡业务条线的样本数据对该模式的实践效果进行研究论证。
第一,基于Logistic回归分析的风控模型是H银行“大数据+信贷工厂”普惠金融模式的核心业务模型之一,通过KS值指标、评分分布及稳定性指标、PSI指标、假阳性率和假阴性率指标进行综合分析,论证该模型能够帮助银行精准区分“好客户”和“坏客户”,有效识别客户风险的高低,有助于提升银行普惠金融业务的风险管理水平及业务效率。
第二,基于效益评价分析模型的实证分析结果,银行运用“大数据+信贷工厂”普惠金融模式代替传统普惠金融模式,能够显著提升普惠金融业务的经济效益水平,具体包括可以显著降低运营成本,人力成本率和管理成本率降幅显著;可以有效提高风控水平,不良率和损失率稳定控制在业内较低水平,总体呈下降趋势;有利于提升盈利能力,增加业务收入和毛利润;同时还可以提升规模化增长水平,增强该普惠金融模式的可复制推广能力。
第三,“大數据+信贷工厂”普惠金融模式的核心在于数字技术的驱动以及“信贷工厂”的工作流程机制优化,通过融入数据技术、决策科学、场景元素,以金融数据模型的决策流程优化人工操作的工作流程,实现审批决策智能化、作业流程电子化、操作环节标准化,能够提升智能审批的比例并降低单笔业务成本,有效识别客户风险,从而实现普惠金融业务的规模化风控,提升普惠金融业务的整体质量和效率。
(二)政策建议
第一,加强顶层设计,推进普惠金融业务高质量发展。首先,要逐步扩大全国普惠金融业务试点范围,总结普惠金融的优秀案例及先进经验,在全国范围内进行有效的推广学习,切实发挥普惠金融的“示范作用”,构建普惠金融相关参与方良性互动、优势互补、合作共赢的良好局面,并为完善顶层设计提供更加可靠的现实依据。其次,要高度重视数字金融科技对发展普惠金融的关键性作用,推动建设普惠金融数字基础设施建设,持续推进金融基础数据库、金融科技共享平台、人行征信数据库、各地融资信用服务平台等的建设,丰富数据来源,强化数据支撑,为普惠金融发展提供技术、系统和数据支持,推动各类型金融机构提升数字金融技术水平,提升数据分析挖掘和建模能力,强化数字化获客和风控能力。最后,要进一步加强金融知识普及教育,提升普惠金融服务群体特别是偏远地区人群及弱势群体的的金融知识水平和金融素养,减少普惠金融业务中的“金融排斥”,将更多经济主体纳入金融服务体系,同时完善客户投诉和处理机制,切实保护消费者数据和资金安全。
第二,创新普惠金融发展模式,构建成本可负担、商业可持续的普惠金融长效机制。商业银行可以参考借鉴“大数据+信贷工厂”普惠金融模式的核心机制,结合自身的经营优势及本地市场特点,建立成本可负担、商业可持续的普惠金融长效机制模式。大型商业银行可有效运用自身在品牌、客户、人员、技术及资金等多方面的优势,建立普惠金融业务事业部体制,形成从总行到分支行的普惠业务专业化流程机制及专业化人才队伍,构建包括核算机制、风险管理机制、资源配置机制和考核评价机制在内的综合服务机制,加快推进数字化转型,构建数字化线上普惠金融产品体系,形成以“模型+算法”为驱动的数字普惠金融运营模式。中小型商业银行可以发挥自身“下沉市场、深耕当地、贴近客户”的运营优势,构建“总行选客+网点获客+线上合作引流”以及“线上自动决策+线下辅助决策”为特征的普惠金融运营模式,审批上做到“链条短、政策活、效率高”,提高普惠金融客户的服务满意度,与大型商业银行形成客群的分层经营,实现差异化竞争。
第三,树立风险底线思维,提升普惠金融业务的风险管理能力。普惠金融业务的稳健发展必须坚守风险底线,将业务风险控制在合理健康水平。首先,商业银行应充分运用大数据、人工智能、区块链等技术在客户风险识别、额度控制、贷后风险预警、风险处置等方面的优势,建立健全普惠金融业务风控体系,完善风险处置手段,建立风险分散机制,将普惠金融业务的不良率控制在合理健康水平。其次,逐步完善新时代普惠金融监管模式,监管层面应加强监督与指导,密切关注金融机构普惠金融业务的整体风险状况,细化区域、行业、机构等方面的微观监控,加强组合风险监测、 预警和预判,对苗头性、倾向性、个案性风险及时指导处置,切断风险传播源头,避免发生区域性的大面积风险暴露。最后,建议监管机构指导商业银行逐步建立常态化的普惠金融不良资产快速处置机制,由于普惠贷款一般具有“小而分散、少有抵质押物”的特点,一旦出现风险,处置的时间成本及人力成本较高,建议对该类型贷款的核销政策进行适度的差异化监管,指导商业银行逐步建立常态化的普惠贷款不良资产快速处置机制,降低银行的风险处置压力及不良率指标压力。
参考文献:
[1]安丽娟,李昕.“信贷工厂”模式的 SWOT 分析[J].经济研究导刊,2010(4):53.
[2]林春山.“信贷工厂”模式的运作机理研究[J].新金融,2009(10):51-53.
[3]郭正江,何九仲,黄杰,翟海涛.大数据技术破解普惠金融“不可能三角”的理论逻辑、实践基础与路径选择[J].浙江金融,2021(10):18-24.
[4]彭真善,宋德勇.交易成本理论的现实意义[J].财经理论与实践,2006(142):15-18.
[5]宋玉茹.数字普惠金融对经济高质量发展的影响研究[J].海南金融,2022(4):2022(4):58-59.
[6]王莲芬.许树柏.层次分析法引论[M].北京:中国人民大学出版社,1989.
[7]杨晓璐.“信贷工厂”模式的探索与应用[J].金融财税,2011(1):77-78.
[8]李万超,杨鹭,宋光宇,等.金融科技对银行业普惠金融的影响分析[J].金融经济,2022(5):51-62+76.
[9]]Chen H C,R H L Chiang,V C Storey.Business Intelligence and Analytics: From Big Data to Big Impact[J].MIS Quarterly,2012(4) :1165-1188.
[10]Che-Chang Chang,Fang-Tzu Chen.Applying Data Mining in order to Motivate Inclusive Finance[J].Proceedings of the 4th International Conference on Humanities Science,Management and Education Technology,2019:3-20.
[11]Dupas P,Robinson J.Why Dont the Poor Save More?Evidence from Health Savings Experiments[R].NBER Working Paper,2011.
[12]Fullerton.Temasek Fullerton SEM promotion and introduction of credit model replcation.[M].Singapore:Medo Press,2009:12-50.
[13]Karlan D,Zinman J.Expanding Credit Access:Using Randomized Supply Decisions to Estimate the Impacts[J].Review of Financial Studies,2010(1):433-464.
[14]McAfee A,E Brynjolfsson.Strategy & Competition Big Data:The Management Revolution[J].Harvard Business Review,2012(10):60-68.
[15]Manyika J,Chui M,Brown B,et al.Big data:the next frontier for innovation, competition,and productivity[J].Analytics,2011(7):52-78.
[16]Mandira S,Jesim P.Financial Inclusion and Development[J].Journal of International Development,2011(7):613-628.
[17]óskarsdóttir M,Bravo C,Sarraute C,et al.The value of big data for credit scoring: Enhancing financial inclusion using mobile phone data and social network analytics[J].Applied Soft Computing,2019(74):26-39.
[18]Stivastava U,Gopalkrishman S.Impact of Big Date Analytics on Banking Sector:Learning for Indian Banks[J].Procedia Computer Science,2015(50):634-652.
[19]Wilson N G.The evolution soverigh wealth funds:Singapors Temasek Holdings[J].Journal of Financial Regulation and compliance,2010,18(1)6-14.
