基于BP神经网络的粳稻种子拉曼光谱鉴别方法研究
2023-12-18祝子涵田芳明高嘉欣
祝子涵, 谭 峰, 田芳明,2, 高嘉欣, 白 楠
(黑龙江八一农垦大学信息与电气工程学院1,大庆 163319)
(农业部农产加工品质量监督检验测试中心2,大庆 163316)
水稻是人类最重要的粮食作物之一。因不同稻区的天气温度、天气湿度、降雨量、土壤成分、日照程度等自然生态环境因素有着明显差异,为使水稻种植地区的水稻产量最大化,将合适的水稻品种种植到对应的水稻种植区域显得尤为重要[1]。但因种子市场不规范操作,由种子品种选购错选问题产生的种子发芽率低、产量低等一系列纠纷时常发生。因此,针对不同水稻种植区域的水稻种子品种快速鉴定识别对现在的农业生产具有重要实际意义。
目前国内外水稻种子鉴别的方法主要包括形态学方法、田间种植法、化学鉴定法、电泳法、分子标记法、电子鼻法和理化检测法等[2,3],形态学方法效率低速度慢且较为主观。田间种植鉴定法鉴别精度不高、周期长且受环境影响过大,耗费大量人力物力。化学鉴定法虽然鉴别精度高,但耗时过多,对样品有损伤,需要专门的操作人员。电泳法中蛋白质电泳法较为常见,图谱对水稻品种的鉴别因基因的表达有时受发育阶段的环境因素的影响,某些品种因基因组相近无法找到特异性蛋白而影响判别正确率。分子标记法中常用SSR分子标记法,其方法虽然测量水稻品种较为可靠,但操作难度较高且对操作人员水平要求较高,无法大规模作业。电子鼻法主要通过辨别气味来实现品种鉴别,受环境因素影响过大,识别率不高,存在明显的弊端。而理化检测法中的光谱测定法依靠其无损、快速、便捷、客观、准确、高效、操作简单、不受环境影响等优势,迅速在品种鉴别方面得到广泛发展。因此,探究基于快速检测的种子品种鉴别方法对于深化该领域的研究具有重要的理论意义。
拉曼光谱分析技术是以光学质谱方法为基础,在待测样品的属性值和拉曼光谱数据之间建立分类或回归模型。由于拉曼光谱技术具有速度快、测量方便、成本低、无破坏等优点,已经被广泛应用于农业[4]、食品[5]、石化[6]、医药[7]等各个方面。
目前,基于拉曼光谱技术的水稻品种鉴别主要是以国内水稻的粗分类、少品种、小范围进行分类鉴别。沙敏等[8]对粳稻、籼稻和糯稻进行粗分类区分,虽然取得良好鉴别效果,但分类过于简单,需对具体水稻品种间的鉴别进行进一步研究。孙娟等[9]采用拉曼光谱技术结合化学计量法虽然能更精准实现对水稻品种间的鉴别,但是鉴别水稻品种较少仅为4种,需对多品种水稻种子鉴别进一步探究。朱培培等[10]采用拉曼光谱技术可以快速、准确、便捷、高效的针对粳稻种子多品种鉴别,但是鉴别地域仅为寒地水稻,地域较为狭小单一,需对地域分布更为广泛的粳稻种子鉴别进行进一步研究。因此,实验提出基于拉曼光谱技术针对多地区多品种粳稻种子的鉴别方法研究具有重要意义。
1 材料与方法
1.1 实验材料
粳稻的主要产地为长江以北地区,为使研究具有一定的地域代表性,按照东北(黑龙江)、华北(天津)、华中(河南)、华东(山东、江苏)地区来选择粳稻种子进行研究[11,12]。实验选用黑龙江、天津、山东、河南、江苏5个产地的20个不同品种粳稻种子作为样品,其中包含黑龙江6个品种,天津、山东各3个品种,河南、江苏各4个品种。样本信息如表1所示。
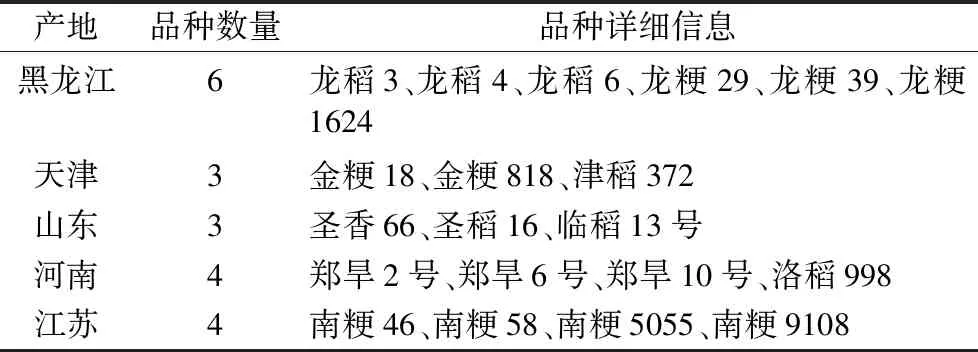
表1 水稻样本信息表
1.2 仪器与软件
光谱采集采取操作Advantage 532拉曼光谱仪,光谱测量波长范围为200~3 400 cm-1,激发波长为532 nm,激发功率为100 mW,积分时间为1~6 s,分辨率为1.4 cm-1,结合ProScope HR软件获取样品光谱信息。实验使用LJJM-2011精米机对水稻种子进行脱壳处理,脱壳率≥99%,工作电压为220 V,工作频率为50 Hz,电机功率为750 W,1次工作时间为50~80 s可调,1次实验用量为50~170 g。数据分析软件采用MatlabR2018a实现。
1.3 光谱的获取
对脱壳后的样本进行挑选,剔除有破损、垩白度高、干瘪畸形等问题的种子,将挑选后的粳稻种子样品按1~20编号存放在的密封袋中并标记对应地区和品种。为保证实验结果不受到外界因素的影响,测量前将全部粳稻种子样本与光谱仪放在同一室内环境下静置24 h, 确保样本的环境条件与仪器环境条件相同。每个品种的粳稻种子均随机选取15个作为该品种的实验样本集,20个不同品种共计300个种子样本集。在产地和品种分类鉴别中,选择每个品种样本集的4/5用作训练集,剩余1/5的样本集作为测试集,即训练集样本数为240个,测试集样本数为60个。
1.4 光谱的预处理
拉曼光谱检测由于样本因素、环境因素、仪器因素等因素影响,产生的无关信息和背景噪声对分析结果会产生很大影响。因此,为了得到准确的光谱信息,需要对数据进行预处理以减少影响。实验采得所有粳稻种子样品光谱信息范围为200~3 400 cm-1,但是光谱曲线在3 200~3 400 cm-1范围内没有特征峰值,且在200~400 cm-1范围内仅有1个特征峰值在269 cm-1,所有大米种子均有这一特征,可知这一特征光谱为C骨架振动归属为淀粉[13]。为提高模型运行速度减少运行时间,将这两个波段截除掉,只保留400~3 200 cm-1的光谱信息作为初始光谱信息。对比SG平滑、一阶导数(1-Der)、二阶导数(2-Der)、迭代自适应加权惩罚最小二乘法(AIRPLS)、多元散射校正(MSC)和标准正态变量变换(SNV)6种数据预处理方法对分类结果的影响。原始光谱数据及其6种预处理方法后的光谱数据如图1所示。选取对模型识别准确率提升最大的方法作为最终预处理方法。
图1 粳稻种子样本原始光谱数据与预处理后光谱数据
1.5 光谱的特征波段提取
由于预处理后的光谱数据量仍较大,为了减少建模数据量,提升模型运行速度,实验采用筛选强度较低的竞争性自适应重加权采样算法(CARS)和筛选强度较高的连续投影算法(SPA)对粳稻种子光谱数据进行特征波段筛选,以提高模型效率[14]。CARS和SPA 2种特征波段提取算法都是采取计算均方根误差(RMSE),并选择与均方根误差最小值相对应的波段变量子集,将所提取出来的波段变量子集作为拉曼光谱信息的特征波段。
1.5.1 CARS提取特征波段
实验使用CARS方法对预处理优化后的拉曼光谱数据进行特征筛选,筛选过程如图2所示。在实验过程中,将蒙特卡洛采样次数设置为50。从图2中的波段数曲线可以看出,运行次数增加的过程中,光谱特征波段数量迅速减少,随后曲线逐渐变得平缓,速度由快到慢表示选取过程由海选变为精选。运行次数增加的过程中,交互验证均方根误差RMSECV的值呈现先低速下降随后相对迅速上升的趋势,表明选取过程由无用信息被逐渐剔除到有用信息也被剔除。图2中回归系数路径曲线是波段提取过程中每次采样中每个波段变量的回归系数路径。当采样次数为18时RMSECV获得最小值,此时对应的特征波段数量用于检测粳稻种子模型分类的效果最好,相应的最佳特征波段数为248。因此,选取该248个特征波段对应的强度值作为后续建模数据。

图2 变量变化、五折交互验证及变量回归系数变化路径与运行次数关系曲线
1.5.2 SPA提取特征波段
采用SPA方法对预处理优化过后的拉曼光谱数据进行特征波段提取,基于最小均方根误差RMSEP值确定特征波段的最佳数目。由图3可见,最佳特征波段数对应均方根误差(RMSE)为0.703 88,特征波数为14。选取该14个特征波段对应的强度值作为后续建模数据。

图3 SPA提取特征波段
1.6 遗传算法优化BP神经网络
误差反向传播(Back Propagation, BP) 神经网络是当今使用最普遍的人工神经网络结构之一,是一种按照信号前向传播、误差逆向传播方式训练的多层前反馈神经网络,BP神经网络具有优秀的解决拟合回归问题能力和解决复杂度高的分类问题能力。传统BP神经网络包括3层结构,即输入层、隐藏层和输出层。原始光谱数据裁剪后有2 801个节点,水稻产地共有5个类别,隐含层设置为单层,根据经验公式[15]神经元个数初始设置为4。因此BP神经网络有2 801个节点在输入层, 设置4个节点在隐含层,输出层有5个节点。使用默认的S型函数在隐含层作为传递函数,输出层使用默认的线性函数,网络指定参数中学习率为0.001,目标误差为0.001,最大迭代次数设为1 000。最终得到一个初始结构为3层拓扑结构的BP神经网络模型。
BP神经网络虽然能够有效地适用于分类、拟合等任务,但在寻求最优解的时候,很有可能陷入局部最优、预测误差较大的情况[16];而遗传算法则是一种通过对自然进化过程的模拟来寻求最优解的方法。所以构建遗传算法(Genetic Algorithm, GA)优化的BP神经网络模型,对BP神经网络的初始权值、阈值进行优化,使被优化后的BP神经网络可以更好地实现对函数的输出。
采用GA算法优化BP模型,遗传算法优化后的个体适应度变化曲线如图4所示,其终止迭代次数为100。平均适应度与最佳适应度随着进化代数不断提升,说明GA算法能够对BP模型原算法进行优化。结果表明,当进化次数达到70时,个体达到最佳适应度。
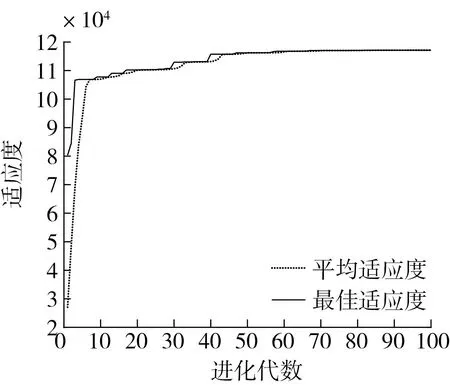
图4 个体适应度变化曲线
2 结果与分析
2.1 不同产地粳稻种子快速分类鉴别
水稻的质量和风味不仅受到父本母本遗传给自身的基因影响,还受到地理条件包括土壤质量、水源质量等和气候环境包括降雨量、日照时间、日照强度等的影响,因此不同产地的水稻品质相差明显。由于其相似的外观,肉眼很难将其分辨,所以利用拉曼光谱技术,针对黑龙江、天津、山东、河南、江苏5个地区20种不同品种粳稻种子,进行光谱采集,对采集的粳稻种子光谱数据进行预处理、特征波段提取操作,建立BP神经网络模型后,用遗传算法优化BP神经网络模型提升模型运行效率,达到快速区分不同产地粳稻种子目的。
2.1.1 预处理结果
预处理结果如表2所示。未进行预处理的光谱在BP神经网络模型中的识别准确率为85%,经过SG、1-Der、2-Der、Airpls、MSC和SNV预处理之后的光谱在BP分类模型中的识别准确率分别为90.00%、86.67%、80.00%、83.33%、83.33%和85.00%,其中SG平滑识别准确率最高,达到90.00%。因此在后续实验研究中,选择SG平滑的预处理方法进行深入建模分析。

表2 不同预处理方法建模鉴别结果
2.1.2 特征波段提取结果
在SG平滑处理原始光谱基础上,特征波段提取如表3所示。虽然2种方法均减少建模数据量,减少模型运行时间,但SPA方法对模型识别准确率较使用之前有所下降,CARS方法相比于使用之前对模型的运行速度和识别准确率均有提升,模型运行时间为40s,识别准确率为91.67%。因此在后续实验研究中,选择CARS的特征波段提取方法进行深入建模分析。
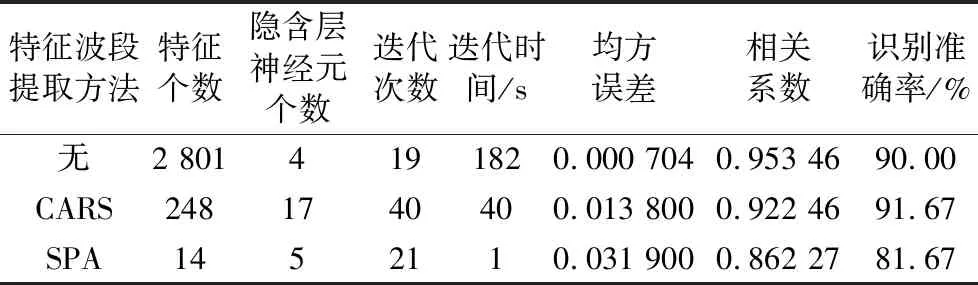
表3 不同特征波段提取方法建模鉴别结果
2.1.3 遗传算法优化结果
根据经验公式[17]优化隐含层神经元个数,不同隐含层神经元个数建模鉴别结果如表4所示。确定选取26为最佳隐含层神经元个数后,将BP神经网络模型的权值阈值用遗传算法优化,GA-BP模型对不同产地粳稻种子识别准确率由98.33%提升至100.00%,运行时间由74 s提升至26 s。说明建立的BP神经网络分析模型的预测精准度高、运行速度快,对不同产地粳稻种子能实现快速分类鉴别效果。

表4 不同隐含层神经元个数建模鉴别结果
2.2 相同产地不同品种粳稻种子快速分类鉴别
为进一步研究同为粳稻、相同产地,但不同品种的大米之间的分类效果,分别以黑龙江6个品种之间、天津3个品种之间、山东3个品种之间、河南4个品种之间、江苏4个品种之间为研究对象,进行光谱采集、数据预处理、数据特征波段提取、建立BP神经网络分析模型并用遗传算法优化,达到快速区分相同产地不同品种粳稻种子目的。
2.2.1 黑龙江地区
以黑龙江地区的龙稻3、龙稻4、龙稻6、龙粳29、龙粳39、龙粳1624共6个品种粳稻种子采用2.1.1优选SG平滑预处理方法、2.1.2优选CARS特征波段提取方法、选取最佳隐含层神经元个数后,用遗传算法优化BP神经网络模型的权值阈值,建立网络拓扑结构为136-19-6的最佳GA-BP神经网络模型。最终模型识别准确率为94.44%,运行时间为4s。说明建立的BP神经网络分析模型的预测精准度高、运行速度快,对黑龙江地区不同品种粳稻种子能实现快速分类鉴别效果。
2.2.2 天津地区
以天津地区的金粳18、金粳818、津稻372共3个品种粳稻种子采用2.1.1优选SG平滑预处理方法、2.1.2优选CARS特征波段提取方法、选取最佳隐含层神经元个数后,用遗传算法优化BP神经网络模型的权值阈值,建立网络拓扑结构为100-15-3的最佳GA-BP神经网络模型。最终模型识别准确率为100%,运行时间为1 s。说明建立的BP神经网络分析模型的预测精准度高、运行速度快,对天津地区不同品种粳稻种子能实现快速分类鉴别效果。
2.2.3 山东地区
以山东地区的圣香66、圣稻16、临稻13号共3个品种粳稻种子采用2.1.1优选SG平滑预处理方法、2.1.2优选CARS特征波段提取方法、选取最佳隐含层神经元个数后,用遗传算法优化BP神经网络模型的权值阈值,建立网络拓扑结构为86-10-3的最佳GA-BP神经网络模型。最终模型识别准确率为100%,运行时间为1 s。说明建立的BP神经网络分析模型的预测精准度高、运行速度快,对山东地区不同品种粳稻种子能实现快速分类鉴别效果。
2.2.4 河南地区
以河南地区的郑旱2号、郑旱6号、郑旱10号、洛稻998号共4个品种粳稻种子采用2.1.1优选SG平滑预处理方法、2.1.2优选CARS特征波段提取方法、选取最佳隐含层神经元个数后,用遗传算法优化BP神经网络模型的权值阈值,建立网络拓扑结构为86-14-4的最佳GA-BP神经网络模型。最终模型识别准确率为91.67%,运行时间为3 s。说明建立的BP神经网络分析模型的预测精准度高、运行速度快,对河南地区不同品种粳稻种子能实现快速分类鉴别效果。
2.2.5 江苏地区
以江苏地区的南粳46、南粳58、南粳5055、南粳9108共4个品种粳稻种子采用2.1.1优选SG平滑预处理方法、2.1.2优选CARS特征波段提取方法、选取最佳隐含层神经元个数后,用遗传算法优化BP神经网络模型的权值阈值,建立网络拓扑结构为86-12-4的最佳GA-BP神经网络模型。最终模型识别准确率为91.67%,运行时间为1 s。说明建立的BP神经网络分析模型的预测精准度高、运行速度快,对江苏地区不同品种粳稻种子能实现快速分类鉴别效果。
3 结论
选用黑龙江、天津、山东、河南、江苏5个不同地区20个不同品种的粳稻种子进行分类鉴别方法研究。在对比实验6种预处理方法对模型建模及判别影响中,SG平滑预处理方法在判别模型中识别准确率高于其他5种预处理方法。在探究光谱特征波段提取方法对模型建模及判别影响中,针对预测效果和运行速度综合考虑,CARS特征提取方法提取的光谱特征优于SPA特征提取方法。GA算法也加快了BP神经网络模型的运行速度,提高了模型识别准确率。
在SG平滑预处理、CARS特征波段提取拉曼光谱数据和GA算法优化BP神经网络模型后建立最佳GA-BP神经网络模型。其中,不同产地(黑龙江、天津、山东、河南、江苏)粳稻种子模型识别准确率达到100%,运行时间为26 s;相同产地不同品种粳稻种子模型识别准确率均在90%以上,平均识别准确率为95.56%,平均运行时间为2 s。说明拉曼光谱技术结合BP神经网络判别分析模型能够有效快速准确鉴别粳稻种子的产地和品种。
