基于三支决策的新型分类匿名模型
2023-12-17蒋浩英王滔滔洪承鑫
蒋浩英 ,钱 进,2* ,王滔滔 ,洪承鑫 ,余 鹰
(1.华东交通大学软件学院,南昌,330013;2.江苏科技大学计算机学院,镇江,212003)
信息时代,数据已经成为一种重要的战略资源,数据收集和共享被广泛应用于各个领域,创造了不菲的价值,然而,外包式的数据共享不可避免地增加了隐私泄露的风险,威胁用户信息安全.近年来,数据可用性和隐私性的对立引起了国内外学者的广泛关注,如何实现两者的最大平衡成为隐私保护领域的研究热点[1-3].
数据匿名是一种重要的隐私保护技术,和基于数据失真和基于数据加密的技术相比,数据匿名技术能更好地平衡数据的可用性和隐私的安全性.k-匿名是一种典型的数据匿名模型,2002 年由Sweeney[4]提出后受到了广泛关注.该模型通过在准标识属性上构建等价类,保证数据集中的任意一条记录都至少存在k-1 条不可区分的记录来降低敌手正确识别的概率,从而保护数据安全.随后,为了进一步提高数据匿名的效率,研究者们又相继提出一系列新的研究成果和改进技术,代表性的有Machanavajjhala et al[5]的l-多样性模型,Wong et al[6]的(α,k)-匿名模型,Li et al[7]的t-closeness 模型.近年来对数据匿名改进算法的研究仍在如火如荼地进行.Liang and Samavi[8]通过数学优化问题的k-匿名公式,提出基于优化的k-匿名算法.张强等[9]基于最优聚类结果,提出最优聚类的k-匿名隐私保护机制.翟冉等[10]利用随机森林和k-means 算法,提出一种更适合分类预测的PFK-算法.Kacha et al[11]在自然启发算法的基础上,提出一种新的基于黑洞算法的k-匿名方法.Mehta and Rao[12]使用MapReduce 作为编程框架,提出适应大数据隐私保护的改进的可扩展的l-多样性算法.不难发现,现有的k-匿名模型及其改进技术已经解决了大多数隐私泄露问题,逐渐趋于成熟.然而,无论是传统的k-匿名模型还是之后的改进技术,都存在同一个缺陷,即采取的都是二分类的匿名策略.现有的匿名模型无一不在匿名处理后将数据严格划分为两部分,满足匿名需求的数据被视为安全数据进行发布,不满足匿名需求的数据则进行隐匿和舍弃.但在实际决策中,这种“非此即彼”的处理方式往往过于绝对,大多数情况下,数据之间的联系并非严格的二分关系,例如,很多被舍弃的数据都十分接近匿名需求,它们只需要进行代价不大的再处理就能成为安全数据被人们利用.
三支决策[13-16]为分类匿名提供了新思路.三支决策是一种基于人类认知的决策方式,常用于分析和解决复杂问题[13],已被推广并应用于各个领域,在人脸识别[17]、数据挖掘[18]、聚类分析[19]、推荐[20]等领域都取得了瞩目的成就,三支分类[21-23]、三支聚类[19,24]、三支概念分析[25]等诸多主题也被越来越多的学者研究和应用.为了应对实际决策过程中可能出现的不确定性情况,和“非此即彼”的二支决策相比,三支决策增加了一个处理过程,即延迟决策.延迟决策的存在使得对问题的考虑更全面,可以避免很多不必要的损失.因此,为了提高数据的可用性,本文将三支决策的思想引入数据匿名,提出匿名上、下限的概念,并以k-匿名为例,提出基于三支决策的(Uk,Lk)-分类匿名模型.该模型充分考虑匿名过程中可能出现的模糊数据,通过对模糊数据的延迟决策处理,进一步完善匿名模型,提高匿名效率.
1 相关理论
1.1 k-匿名k-匿名是Sweeney[26]提出的一种用于抵御链接攻击的数据匿名模型,通常用泛化或抑制的手段对原始数据集进行匿名处理.该模型利用准标识属性将记录划分为不同的等价组,通过保证待发布数据集中的每条记录都至少拥有k-1 个等价类的方式来降低敌手的攻击准确度.为了更清晰地表达,下面给出几个基础定义.
定义1 准标识属性QI是待发布数据集中的一个属性集合,通常和敏感属性一起发布.通过结合背景信息,能以较高的概率推断出记录身份的最小属性集合.
定义2 敏感属性SA是待发布数据集中包含个人敏感信息的属性,也是攻击者最想确定和关联的属性.
表1 展示了一个原始数据集,其中{性别,年龄,学历}为准标识属性集,{疾病}为敏感属性集.
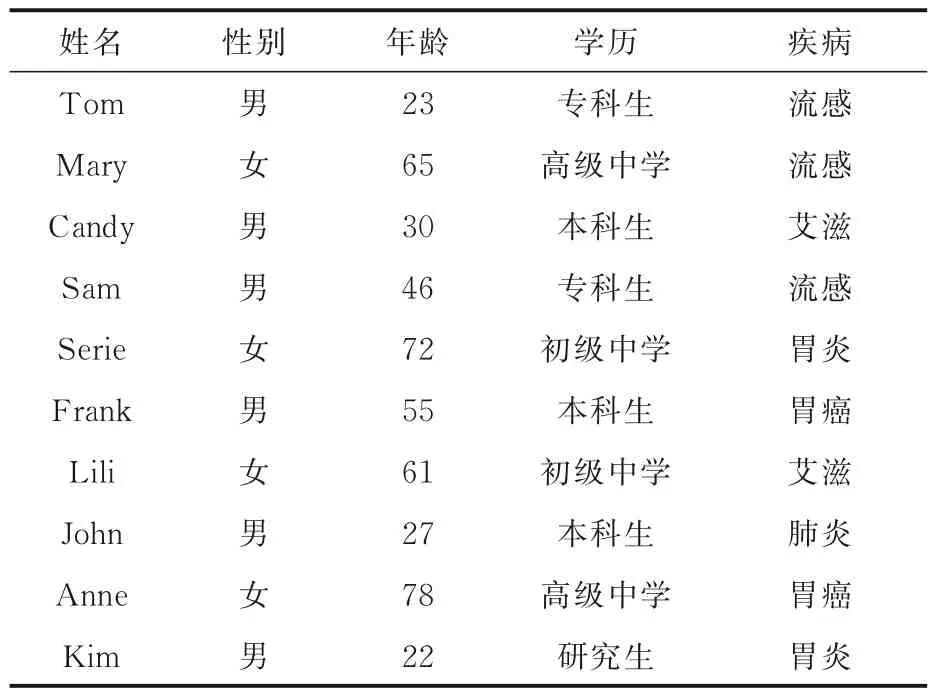
表1 原始数据集Table 1 Original dataset
定义3 等价组EG在待发布数据集中,准标识属性完全相同的记录集构成一个等价组,也称为一个QI-组.
定义4 k-匿名给定一个待发布数据集T={U,Ar=QI∪S∪O},其中,U是一个非空的记录集合,Ar是记录对应的属性集,包括准标识属性QI、敏感属性S以及其他属性O,当且仅当T[QI]中每一个有序的值在T[QI]中至少出现k次,待发布数据集T满足k-匿名.
表2 是表1 的一个5-匿名数据表,G1和G2是针对准标识属性集{性别,年龄,学历}的两个等价组,|G1|≥5,满足5-匿名;|G2|<5,不满足5-匿名.
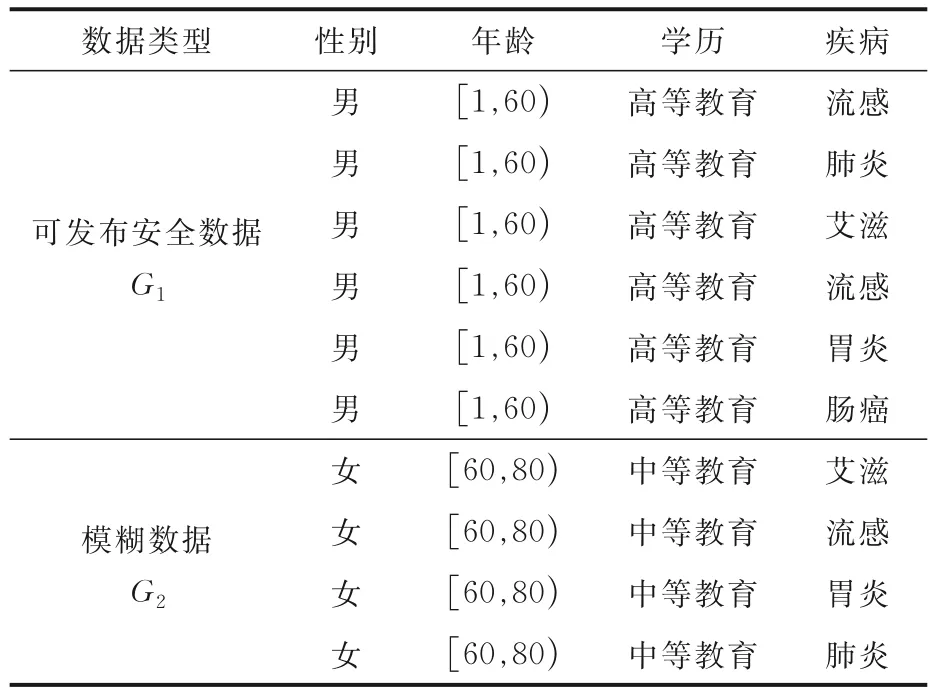
表2 表1 的一个5-匿名数据表Table 2 A 5-anonymity table of Table 1
定义5 匿名上、下限匿名需要满足的初始需求为匿名上限.不满足却十分接近匿名上限且在实际决策中允许少部分数据满足的匿名要求为匿名下限.
假设表2 的初始匿名要求为5-匿名,则其匿名上限为5;若实际决策中允许少部分数据满足的容错匿名要求为4-匿名,则4 为其匿名下限.
定义6 模糊数据T={U,At=QI∪S∪O}为待发布数据集,U/QI={G1,G2,…,Gn}是根据准标识属性QI划分的等价组,|Gi|代表等价组Gi的大小,f(x)代表对象x所在的等价组的大小(若x∈Gi,则f(x)=|Gi|).给定匿名阈值对(Uk,Lk),其中,Uk表示匿名上限,Lk表示匿名下限,当Lk<f(x)<Uk时,记录x为模糊数据.
假设表2 中Uk=5,Lk=3,根据定义6,|G1|≥5,为可发布的安全数据;3 <|G2|<5,为模糊数据.
1.2 三支决策和二支决策相比,三支决策[13-16]增加了一个额外的处理过程,即延迟决策.当对事物信息的掌握不充分、认知不彻底、无法作出全面的风险评估时,采取延迟的方式,将这部分信息暂存到边界域来暂缓决策,等收集了足够的信息或对风险了解到足够的程度后再接受或者拒绝.图1 对比了二支决策和三支决策的决策过程.
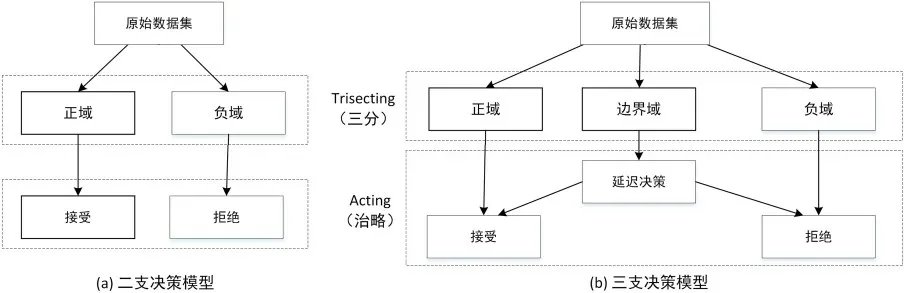
图1 二支决策(a)和三支决策(b)的决策过程对比Fig.1 Decision-making process of two-way (a) and three-way (b) decisions
三支分类是一种有效的数据处理方法,也是三支决策最常见的应用领域.Yao[13,21]从概率粗糙集的角度研究了三支分类问题,探讨了三支决策在概率粗糙集下的优势,并指出三支决策可以通过权衡不同类型的分类误差,实现最低的决策成本,降低分类风险.为了更好地模拟人的思考过程,定义7 从决策理论粗糙集的角度,引入评价函数和阈值来重新刻画三支决策模型.
定义7设S=(U,R)是一个信息系统,U=(x1,x2,…,xn)是一个非空有限对象集合,R是论域U上的二元关系,评价函数e(x)表示对象x的评价值.引入一对阈值α和β,论域U可被划分为三部分:
利用阈值来划分论域可以更好地模拟人的思考过程,阈值α和β一般由决策者容忍度或专家经验事先给定.
2 基于三支决策的(Uk,Lk)-分类匿名模型
为了充分考虑实际匿名过程中可能出现的模糊数据,解决二分类匿名的弊端,本文将三支决策的思想应用到数据匿名中,以k-匿名为例,提出一种基于三支决策的(Uk,Lk)-分类匿名模型,其中,Uk表示匿名上限,Lk表示匿名下限.
2.1 属性泛化抑制和泛化是k-匿名中的常用策略[26].为了能对数值型属性和分类型属性进行统一处理,首先利用属性之间的泛化关系来构建属性泛化树,将数据集中的准标识属性都处理为具有层次结构的属性;然后,通过提升记录在属性泛化树中的层级,用范围广的上级节点代替下级子节点,构建等价类,实现k-匿名.图2 展示了表1 中的准标识属性集{性别,年龄,学历}对应的属性泛化树.

图2 表1 中准标识属性对应的属性泛化树Fig.2 The attribute generalization trees corresponding to the quasi-Identifier attributes in Table 1
2.2 模型构建属性泛化完成后,将三支决策的思想引入数据匿名,利用三支决策对待发布数据集进行分类决策匿名.首先,定义6 中的f(x)作为评价函数,根据定义7 将待发布数据集划分为低敏感数据(LSR)、模糊敏感数据(FSR)和高敏感数据(HSR).具体划分方式如下:
其中,f(x)是记录x所在的等价组的大小;QI是原始数据集U中的准标识属性;(Uk,Lk)是根据实际应用场景设定的匿名上、下限,可以将数据集划分为三个成对不相交的区域.
接下来,根据三支决策的思想,对不同区域的记录采取不同的决策方式:对高于匿名上限的低敏感数据直接进行安全发布;抑制低于匿名下限的高敏感数据.为了提高数据的利用率,单独划分出接近匿名需求的模糊敏感数据,并对其进行进一步的处理(例如添加噪声数据,使其满足匿名需求等).图3 是所提模型的示意图.由图可见,通过分类决策匿名,三支分类匿名模型将数据处理成更符合人类思维模式的三分形式,用延迟决策的方式充分考虑实际决策中可能出现的不确定性因素,进一步提高匿名效率,优化传统的二分类匿名模型.

图3 一种基于三支决策的新型分类匿名模型Fig.3 A novel classified anonymity model based on three-way decisions
2.3 添加噪声为了验证所提模型的可用性,本文结合差分隐私,用少量添加噪声的方式来实现对模糊数据的延迟决策,并给出以下定理.
定理1若等价组G1和等价组G2满足相同的k-匿名需求,则G1∪G2也满足该匿名需求.
证明令等价组Ga={a1,a2,…,an}和等价组Gb={b1,b2,…,bm}都满足k-匿名,|Ga|=ka,|Gb|=kb,其中|Ga|和|Gb|分别为等价组Ga和Gb的大小.根据定义4,不难得到ka≥k且kb≥k.令Gs=Ga∪Gb,|Gs|为数据集Gs中最小等价组的大小,则有|Gs|=min{|Ga|,|Gb|}=min{ka,kb}≥k.因此,|Gs|≥k.根据定义4,Ga∪Gb满足k-匿名.
证毕.
定理2若待发布数据集中的每一个等价组都满足相同的k-匿名需求,则待发布数据集满足该匿名需求.
证明令待发布数据集S={G1,G2,…,Gn},其中G1,G2,…,Gn为该数据集中的等价组.当S中的所有等价组都满足k-匿名时,根据定义4 可以得到|G1|≥k,|G2|≥k,…,|Gn|≥k.假设|Gs|为该待发布数据集S中最小等价组的大小,则有|Gs|=min{|Ga|,|Gb|,…,|Gn|}≥k.因此,|Gs|≥k,待发布数据集S={G1,G2,…Gn}满足k-匿名.
证毕.
因此,根据定理1 和定理2,当原始数据集中存在模糊数据集时,只需通过特定方式对模糊数据进行再处理,使其满足匿名需求,即可实现对这部分模糊数据的安全数据发布,提高匿名效率.本文采用少量添加噪声的方式来处理模糊数据.具体地,当原始数据集中存在模糊数据时,在可以容忍少量噪声数据的情况下,通过复制模糊数据组中的等价类制造并添加新的噪声数据,使得模糊等价组中的等价类个数达到匿名上限,满足初始的Uk-匿名需求.
以表2 为例,G2为模糊数据集,在基于三支决策的(Uk,Lk)-分类匿名模型中复制G2中的记录,制造并添加噪声数据,使模糊数据集G2满足匿名上限(Uk=5)来满足匿名需求,提高数据的可用性.表3 是处理后的基于三支决策的(5,3)-分类匿名数据集.

表3 基于三支决策的(5,3)-分类匿名数据集Table 3 A (5,3)-classified anonymous dataset based on three-way decisions
显然,表3 的数据利用率高于表2.值得一提的是,所提模型是一个适应性较强的框架模型,对于具有不确定性的模糊数据,数据处理者可以根据实际情况进行不同的延迟决策处理,提高数据的可用性.例如,除了添加噪声的方式,在实际应用中也可以通过其他更适宜的方式对模糊数据进行再处理,使其满足匿名要求.
3 基于三支决策的(Uk,Lk)-分类匿名算法
3.1 算法实现基于上述分析,提出基于三支决策的(Uk,Lk)-分类匿名算法,具体的伪代码如下.

算法中,首先对原始数据集的准标识属性进行最小属性泛化,根据泛化后的准标识属性将原始数据集划分为n个等价组,将满足Uk-匿名的记录划分到正域,存入待发布安全数据集合Q中;将靠近Uk-匿名需求的模糊数据存入边界域,等待延迟决策;低于匿名下限的数据被视为完全不符合匿名需求的数据,划分到负域,直接进行抑制.需要注意的是,延迟决策在实际应用场景下是多样化的.例如,在可以容忍少量噪声数据的情况下,通过添加噪声使其达到Uk-匿名需求,从而提高数据的利用率.如果实际匿名要求十分严格,不允许添加噪声数据,或者需要添加的噪声过多,严重影响了数据的可用性,应将这部分数据并入负域,直接抑制.后者是极端特殊情况,相当于普通的二支匿名.
3.2 算法分析
3.2.1 有效性分析所提算法首先构建了属性泛化树,利用属性的泛化层次关系将属性处理为具有层次结构的属性集,再引入三支决策的思想对数据进行分类匿名决策.该算法采用泛化、隐匿以及少量添加噪声的方式对原始数据集进行模糊处理,降低了属性之间的关联度,每一步都使数据集向安全需求靠拢,最大程度地实现数据可用性和隐私性的平衡.算法的时间复杂度为O(n).因此,提出了下述定理.
定理3(Uk,Lk)-分类匿名算法满足数据安全发布需求.
证明该算法提出匿名上、下限的概念,并引入了三支分类的思想,将原始数据集划分为三个两两不相交的区域,对不同区域的数据分类处理.正域存储低敏感数据,通过属性泛化使其满足Uk-匿名.负域存储高敏感数据,但是该部分数据即使泛化到根节点也无法满足匿名要求,所以直接舍弃.边界域是划分出来的边缘模糊数据,进行泛化后这部分数据不满足但十分接近匿名上限Uk.为了尽可能提高数据的可用性,对这部分特殊数据采用添加适度噪声的方式进行二次处理.最终,处理后每一个区域都满足安全发布需求.
证毕.
3.2.2 安全性分析(Uk,Lk)-分类匿名算法首先利用属性泛化树进行最小属性泛化,使每个等价组都满足匿名上限Uk,即每条记录都存在至少Uk-1 个等价类,从而降低敌手的正确辨识率.此外,在能容忍少量噪声的情况下,该算法对高于匿名下限Lk的边缘模糊数据进行了再处理,通过添加噪声数据的方式使模糊数据集中的任意记录也都满足匿名上限.无论是泛化还是添加噪声,都能有效地切断准标识属性之间的关联性,抵御敌手的链接攻击,防止信息泄露,显然,最后发布的安全数据集Q满足Uk-匿名,保护了用户的隐私.
4 实验与结果分析
首先定义四个算法的效用评估函数,包括信息抑制率、泛化损失率、数据失真率以及隐私泄漏风险,然后通过实验来度量所提算法的性能,对比Uk-匿名模型、(Uk,Lk)-分类匿名模型以及降低匿名要求后的(Lk+1)-匿名模型的实验结果.实验使用的数据集是来自机器学习数据库的Adult 数据集,选取其中九个属性进行实验.
实验环境:Intel(R)Core(TM)i5-1135G7@ 2.40 GHz 2.42 GHz,16.0 GB(RAM)内存,Eclipse IDE 2022-03.
4.1 算法效用评估函数为了评估所提模型的实用性,定义几个算法效用的评估函数,从信息抑制、泛化损失、数据失真以及隐私泄露风险几个方面对所提算法进行综合评估.
4.1.1 信息抑制率给定原始数据集T,T'是进行k-匿名后得到的待发布的安全数据集.信息抑制率指匿名处理后记录的损耗率,定义如下:
其中,|T|是原始数据集中的记录条数,|T'|是待发布数据集中的记录条数.信息抑制率越低,越接近原始数据集,数据的可用性越高.
4.1.2 泛化损失率给定原始数据集T,待发布数据集T',T中准标识属性对应的属性泛化树共有l(l=1,2,…,m)层.泛化损失率定义如下:
其中,|Si|表示泛化到第i层的记录条数(i≤l),|T|是原始数据集中的记录条数,|T'|是待发布数据集中的记录条数.
当所有记录在底层就满足匿名条件时,记录无须泛化,泛化损失率为0;泛化到根节点时,数据几乎不可用.因此,当所有记录都泛化到最顶层或者都被抑制时,泛化损失率达到最大值1.
4.1.3 数据失真率噪声数据的添加不可避免地会导致数据失真.假设M是添加的噪声数据,信息失真率定义如下:
其中,|T|为原始信息中的记录(真实记录)条数,|M|为噪声记录条数.
4.1.4 隐私泄露风险假设原始数据集为T,对T采取数据匿名处理,使其满足k-匿名后得到待发布数据集T'.待发布数据集T'的隐私泄露风险为:
其中,R(x|T') 表示敌手从待发布数据集T'中准确识别出对象x真实身份的概率.
4.2 信息抑制率度量为了分析不同算法的数据利用率,在不同的匿名上限Uk下,比较三种算法的信息抑制率随匿名下限Lk的变化情况,实验结果按千分之一的形式取值.
实验结果如图4 所示.显然,与单一的Uk-匿名模型相比,所提(Uk,Lk)-分类匿名模型的信息抑制率明显降低,数据可用性得到了增强.这是因为采用了分类匿名的方式,模糊数据被单独划分出来进行再处理,提高了数据的利用率.其次,可以观察到(Lk+1)-匿名模型通过直接降低匿名要求也可以达到近似相同的效果,但这是以牺牲安全性为代价的.即使如此,所提算法在某些情况下的效果还是优于(Lk+1)-匿名模型,这也体现了分类匿名的优势.
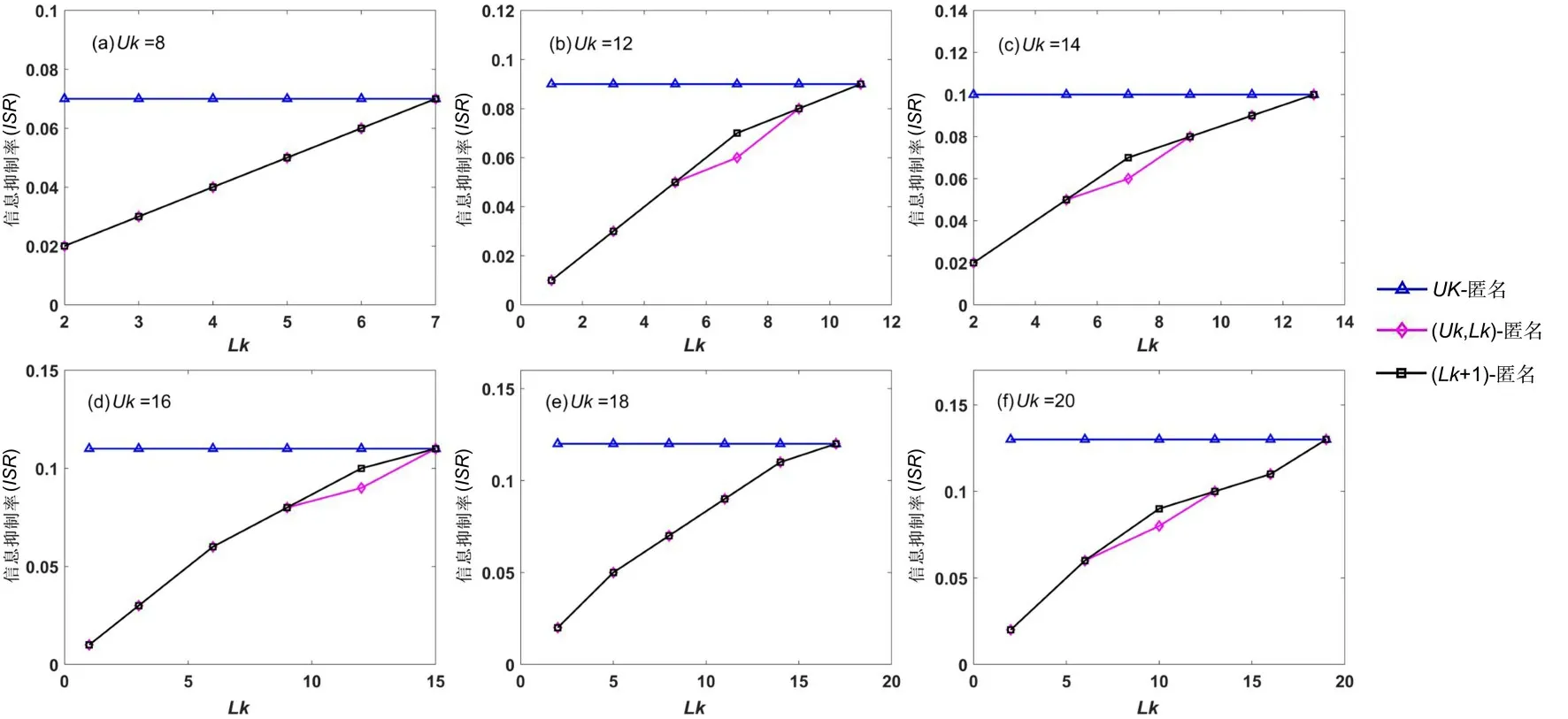
图4 匿名上限Uk 不同时信息抑制率随匿名下限Lk 的变化Fig.4 The variation of information suppression rate with Lk when Uk is different
由图4 还可以看出,在匿名上限Uk固定时,随着匿名下限Lk的下降,信息抑制率不断减少,这是模糊区间增大的影响,模糊区间越大,可二次处理的数据越多,信息利用率越高.值得注意的是,模糊区间不是越大越好,过大的模糊区间会导致添加的噪声过多,引发数据失真.最后,各组之间的实验也表明,在不同的匿名程度下三种算法的实验结果一致,避免了实验的偶然性.
4.3 泛化损失率度量属性泛化也会带来一定的信息损失,泛化损失率是本文提出的综合度量算法产生的信息损失的评价函数.图5 给出了相同情况下三种算法的泛化损失率.由图可见,在匿名上限Uk固定时,虽然(Uk,Lk)-分类匿名的损失率高于直接降低匿名要求的(Lk+1)-匿名模型,但低于初始的Uk-匿名模型,达到了在不改变匿名要求的同时实现更低的信息损失的目的,体现了所提算法的有效性.其次,随着匿名下限Lk的降低,损失率降低,这和4.2 中实验结果的原因一致,都源自模糊区间的扩大.
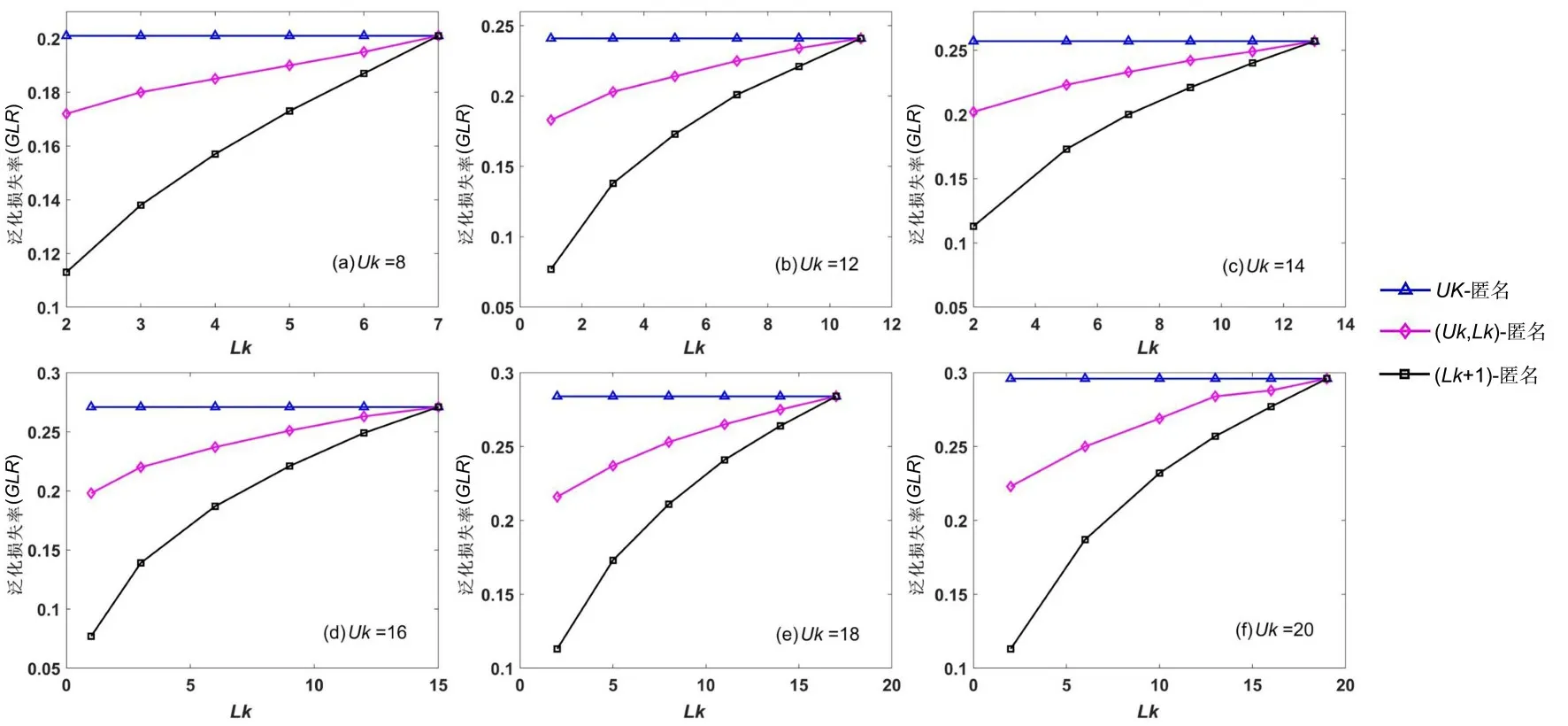
图5 匿名上限Uk 不同时泛化损失率随匿名下限Lk 的变化Fig.5 The variation of generalization loss rate with Lk when the Uk is different
4.4 算法的总体性能度量为了度量算法的总体性能,综合分析三种算法在数据失真、信息抑制、泛化损失以及算法安全性上的实验结果.在匿名上限Uk=12,匿名下限Lk=9,7,5,3,2,1六种情况下,对三种匿名算法的实验数据进行对比.实验结果如图6 所示.由图可见,(Uk,Lk)-分类匿名模型的信息抑制率和泛化损失率低于初始的Uk-匿名,数据可用性得到了明显的提高;其次,与以降低安全性为代价的(Lk+1)-匿名算法相比,(Uk,Lk)-分类匿名模型不会增加隐私泄露风险,更能保障信息安全.总体上,所提算法可以在不改变隐私保护度的同时最大程度地提高数据的可用性,优于初始的Uk-匿名以及以降低安全性为代价的(Lk+1)-匿名.
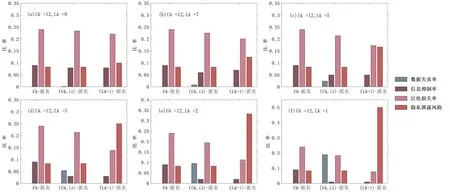
图6 匿名上限Uk 固定时,数据失真率、信息抑制率、泛化损失率以及隐私泄露风险随匿名下限Lk 的变化Fig.6 Data distortion rate,information suppression rate,generalization loss rate and risk of privacy leakage with Lk when Uk is fixed
但从图6 也不难发现,随着匿名下限Lk的降低,模糊区间增加,(Uk,Lk)-分类匿名模型产生的数据失真率大幅增加,过多的噪声添加可能严重影响了信息的真实性.因此,设置合适的匿名下限很有必要.在实际应用中,可以通过设置阈值来决定是否采用(Uk,Lk)-分类匿名算法,数据失真率超过一定的阈值则不推荐使用该算法.
4.5 算法显著度分析为了进一步检验提出的方法与其他选择算法的性能差异,以泛化损失率为例进行统计显著性分析.由于三种算法之间具有相关关系,因此使用了Friedman 检验[27].假设三种算法性能相同,计算每种算法在图6 的六种评估环境下的平均秩.构建统计变量如下:
其中,N和k分别是评价环境总数和算法个数,ri为第i种方法在N种评估环境下的分类精度的平均秩.
构造一个随机变量如下:
其中,随机变量τF服从自由度为k-1 和(k-1)(N-1)的F分布.
选择Uk-匿名、(Uk,Lk)-分类匿名以及(Lk+1)-匿名三种匿名算法,评价环境为匿名上限Uk=12,匿名下限Lk=9,7,5,3,2,1.图7 是Friedman 双向按秩方差的分析结果,在显著性水平α=0.05 时,=12,自由度为2,渐进显著性为0.002.查阅相关资料,大于对应的Friedman临界值,说明可以拒绝检验的原假设,即所提算法和对比的两种算法性能是有差别的.
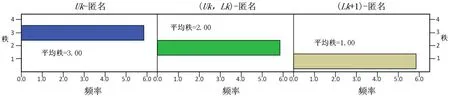
图7 Friedman 双向按秩方差分析Fig.7 Friedman two-way analysis of variance by rank
为了进一步比较算法的优劣,采用Nemenyi测试作为后续检验,Nemenyi 检验的临界值定义如下[27]:
当k=3 时,q0.05=2.344,根据式(9)计算得CD=1.353.因此,所提的三种算法中(Uk,Lk)-匿名算法和其他两种算法的平均秩之差都小于临界阈值CD,说明(Uk,Lk)-匿名算法和其他两种算法的性能没有显著差别。
根据不同算法的结果排序,进一步给出了Friedman 检验图,如图8 所示,其中A1,A2,A3 分别代表Uk-匿名、(Uk,Lk)-分类匿名以及(Lk+1)-匿名三种匿名算法.
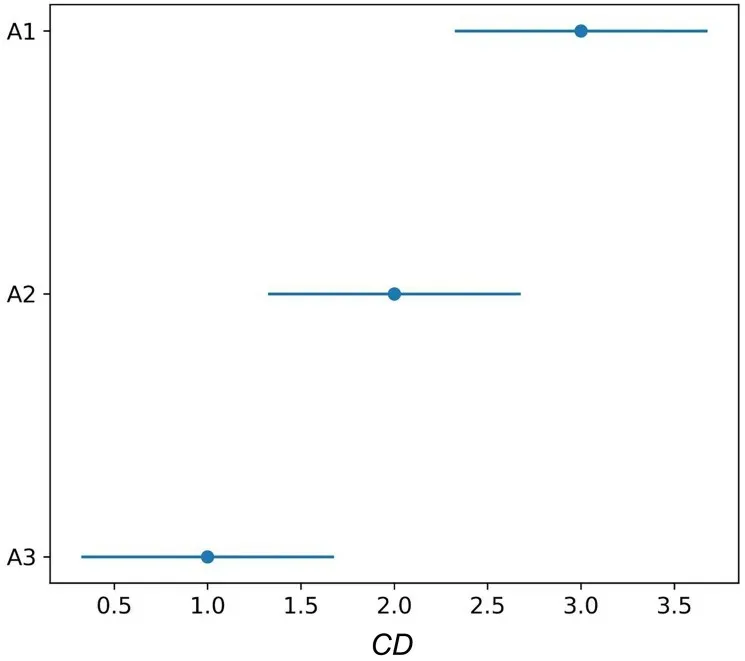
图8 Friedman 检验图Fig.8 Friedman test graph
由图8 可见,所提算法(A2)和对比的两种算法都有交叠,说明它和两种对比算法没有显著差别,但其平均性能优于传统的Uk-匿名算法(A1),原因是所提算法处理了模糊数据,提高了数据利用率,证明所提算法是对传统的Uk-匿名算法的改进.(Lk+1)-匿名算法(A3)的平均性能虽然最好,但通过实验分析可知,这是以降低安全性为代价的.综上,所提算法可以在不改变隐私保护度的同时提高算法性能,优于Uk-匿名和以降低安全性为代价的(Lk+1)-匿名算法.
5 结论
数据匿名是一种重要的隐私保护方案,现有的匿名算法大多采用二支决策的方式,对数据进行严格的二分类后再进行匿名处理.为了考虑实际决策中可能出现的模糊数据,将三支决策的思想引入匿名过程,以经典的k-匿名为例,提出一种新型的三支分类匿名模型,即(Uk,Lk)-分类匿名模型.其通过分类匿名的方式筛选出模糊数据,然后对这部分数据进行再处理,使其满足原来的安全需求,从而提高匿名效率.本文采用添加噪声的方式来处理模糊数据,实验结果表明所提模型优于传统的二分类k-匿名模型,可以在保证隐私性的同时,最大限度地提高数据可用性,在实际应用场景中更灵活.其次,为了应对模糊数据的定义和在不同的应用场景下不同的处理需求,提出的新型匿名框架可以根据实际应用环境灵活调整算法,这也体现了所提模型的可扩展性.未来将继续探索这一点,以实现更好的隐私保护方案.
