基于BoBGSAL-Net 的文档级实体关系抽取方法
2023-12-17冯超文吴瑞刚温绍杰刘英莉
冯超文 ,吴瑞刚 ,温绍杰 ,刘英莉*
(1.昆明理工大学信息工程与自动化学院,昆明,650500;2.云南省计算机技术应用重点实验室,昆明理工大学,昆明,650500)
近年来,随着深度学习算法快速发展,基于神经网络的文档级实体关系抽取[1]方法已经成为研究热点.文档级实体关系抽取是指从整个文档中抽取出实体之间的关系,相较于句子级实体关系抽取[2],文档级实体关系抽取需要处理更大量、更复杂的实体关系信息.因此,需要将多个句子中的实体关系整合起来,以更准确地识别实体之间的关系.目前实体关系抽取的方法主要分为基于传统机器学习和深度学习的方法.基于传统机器学习的文档级实体关系抽取依赖于特征工程,无法处理复杂关系,并且模型的泛化能力有限.相比之下,基于深度学习的实体关系抽取方法可以很好地解决这些问题,对长文本处理更加高效,也具有更强的鲁棒性.
1 相关工作
基于深度学习的文档级实体关系抽取的方法主要包括基于序列[3]、基于图和基于预训练语言模型[4].Geng et al[5]提出一种基于双向树结构长短期记忆的端到端方法,提取基于句子依赖树的结构特征.Luo et al[6]提出一种基于神经网络的方法,即带有条件随机场层的注意力双向长短时记忆方法,用于文档级别的化学命名实体识别.Tang et al[7]提出一种分层推理网络,充分利用来自实体级、句子级和文档级的丰富信息,将平移约束和双线性变换应用于多个子空间中的目标实体对,以获得实体级的推理信息.Najibi et al[8]提出一种基于卷积神经网络[9-12]的目标检测技术,可以从多尺度网格的固定边界框开始,训练一个回归器,迭代地将网格元素移动和缩放到紧密围绕物体的框中.Huang et al[13]提出一种针对不断变化的大型图而设计的动态图划分算法,该算法与分区算法紧密集成,进一步减少了分区算法切割的边数.尽管以上研究方法已在文档级实体关系抽取任务中取得了一些较好的成果,但仍然存在一定的局限性,具体表现在识别一些不需要一致性的实体类型时可能存在缺点.例如,在文章中有时会使用相同的缩写来指代不同的实体,而且在处理需要捕获更复杂的长距离依赖信息的文章时,这些方法表现不佳.
针对文档级实体关系抽取的研究,主要难点有:(1)文档中不同实体之间的复杂信息交互问题,需要对文档中多个句子进行推理,对于深度学习模型的训练和推理会带来更高的计算复杂度;(2)文档中实体关系中存在的关系重叠问题,一个实体可能有多种不同的含义及解释,一个实体对应多种关系的复杂性.为了解决上述问题,本文提出一种基于双图结构的聚合逻辑网络(Based on Bipartite Graph Structure Aggregate Logic Network,BoBGSAL-Net)的文档级实体关系抽取方法,该方法首先构建一个混合提及级图(Mixed Mention-Level Graph,MMLG)来模拟整个文档中不同提及节点之间的信息交互,然后构建了实体关系图(Entity Relation Graph),针对文档的句内实体进行关系提取.基于MMLG 和ERG,本文融合聚合逻辑推理路径来推断实体之间的关系并进行分类预测.最后,在公开的数据集DocRED 以及作者实验室构建的数据集AlSia-RED[14]上进行实验,结果证明BoBGSAL-Net 在文档级实体关系抽取任务中性能有一定提升.
2 本文方法
BoBGSAL-Net 是一种基于双图特征的图聚合和推理网络[15-17],利用异构提及级图来建模文档中不同提及级节点之间的交互,并捕获文档感知功能,从而更好地处理文档级的实体关系提取任务.BoBGSAL-Net 采用实体级图,并融合路径推理机制来更明确地推断关系.该模型由四个部件组成,包括文本编码嵌入机制、混合提及级图策略、实体关系图模块和分类预测模块.其中,文本编码嵌入机制采用了BiLSTM[6],GloVe[18]和BERT[19]三种文本编码嵌入方式.BiLSTM 在捕捉局部上下文信息方面效果较好;GloVe 生成的词向量利用了全局语料库中的共现信息,对于单个词的语义表示有一定优势;BERT 通过双向文本建模捕捉丰富的上下文信息,对于理解复杂实体关系至关重要.BERT 的预训练模型能有效编码整个文档上下文,包括长文本中的实体语义关系.相较于BiLSTM 和GloVe,采用BERT 作为词嵌入模型具有显著优势.混合提及级图策略主要用于不同提及级节点之间的信息交互模拟计算,实体关系图模块对整个文档中的实体关系进行交叉计算.最后,通过实体关系分类预测模块,该模型可以从文档中抽取实体和关系.BoBGSAL-Net 的完整结构如图1 所示.

图1 BoBGSAL-Net 结构图Fig.1 The structure of BoBGSAL-Net
2.1 文本编码嵌入机制在文本编码嵌入机制中,定义一个文档,其中n为文档中包含的词数量,将D映射为一个向量序列对于D中每个词wi,首先将词嵌入、实体类型嵌入与核心关系嵌入进行拼接,作为一个文本编码向量嵌入,表示方法如式(1)所示:
其中,Ew(·),Et(·)和Ec(·)分别代表词嵌入矩阵、实体类型嵌入矩阵和核心关系嵌入矩阵,ti表示命名实体类型,ci表示实体id.无论是DocRED 数据集还是文档级实体关系抽取数据集中都有大量词不属于任何实体,因此本文定义一个None 实体类型和id 作为这些实体的实体类型嵌入与核心关系嵌入.
接着将向量化的单词表征嵌入编码器来获得每个词的上下文敏感表征,嵌入公式如下所示:
2.2 混合提及级图策略本文提出混合提及级图策略对文档级的提及级节点和实体之间的相互作用进行建模.该策略包含两种不同类型的节点,即提及级节点和文档级节点.每个提及级节点表示一个实体的提及表征,文档级节点则用于建模整个文档,类似于一个支点与不同的提及级节点进行交互,以解决长距离节点交互的问题.提及级节点之间的交互采用有向无环图的形式,该表示方式同时代表了节点在文档中的上下文关系.
MMLG 模块共包含三种类型的边,包括共指边、实体间边和文档级边.其中,共指边指同一实体类型形成的边,例如实验名——实验名.通过共指边,可以实现文档中同一实体在不同提及方式之间的信息交互和建模.实体间边指两个不同的实体在一个句子中共同出现形成的边,例如合金——元素.通过实体间边,可以对实体之间的信息交互进行建模.共指边和实体间边都属于提及级边,而所有提及级内容都通过文档级边连接到文档节点.
通过以上连接结构,文档级节点可以关注到所有提及级节点,并实现文档和提及之间的互动.同时,使用文档级节点作为支点,两个提及级节点之间的距离最多为两条边,通过这种结构可以很好地避免文档长文本的长距离依赖问题.
接着,在MMLG 模块上使用GCN 来聚合邻接特征.给定第l层的节点u,图卷积操作的定义如下式所示:
其中,k代表不同类型的边,都是可训练参数,Nk(u)表示连接在第k类边上的节点u的邻接,δ表示激活函数.
GCN 的不同层表达了不同抽象层次的特征,为了涵盖所有层次的特征,将各隐藏层状态串联起来,形成节点u的最终表示,如式(4)所示:
对于文档级节点,则被初始化为编码模块输出的文档表征.
2.3 实体关系图模块边连接的实体合并到实体节点,得到ERG 中的节点,该模块对文档级节点透明,被提及N次的第i个实体节点利用平均数来表示,如式(6)所示:
将所有连接两个相同实体提法的实体间边合并,得到ERG 中的边.从实体i到实体j的有向边的表示方法如式(7)所示:
其中,Wq和bq为可训练的参数,δ为激活函数.基于向量化的边表示,头实体eh和尾实体et之间经过实体eo的第i条路径采用如式(8)所示:
以上只考虑两次跳转情况的路径,上述公式很容易扩展到多次跳转路径的情况.同时,引入注意力机制[20],使用实体对(eh,et)作为query 来融合eh和et之间的不同路径信息.融合公式的表述如式(9)~(11)所示:
其中,αi表示第i条路径的归一化注意力权重,这样会使模型更关注有用的路径.然后,在ERG 模块上融合GCN 来获取实体关系信息,最大程度上提高模型对实体关系的预测准确率.
通过ERG 模块将实体的提及信息进行融合,通常这些信息分布在多个句子中,通过实体之间的不同路径来模拟潜在的推理线索.然后采用自注意力机制结合这些信息,能够更好地利用潜在的逻辑推理链来预测实体之间的关系.
2.4 分类预测模块BoBGSAL-Net 的分类预测模块是该模型的最后一层,用于对文档级实体关系进行分类预测.该模块通过将每个实体对连接起来实现此目的,连接方式如下.
(1)对每个ERG 模块中得到的头实体和尾实体表征eh和et,通过对比操作来加强特征,将两个实体表征的绝对值相减,即|eh-et|.然后逐元素相乘,即eh⊙et.
(2)将每个MMLG 模块中的文档级节点表示为mdoc,利用该节点来聚合跨句间的信息,并提供文档级节点与提及级节点的交互表征信息.
(3)综合以上两步推理路径信息Ph,t,具体表述如下所示:
最后,将文档级实体关系抽取任务定位为多标签分类任务,并对实体之间的关系进行预测,公式如下:
其中,Wa,Wb,ba,bb为训练参数,δ为激活函数.使用二进制交叉熵作为分类损失来训练该端到端网络,表征连接过程如式(14)所示:
其中,S代表整个语料库,Ⅱ(·)表示指示函数.
3 实验设置
3.1 实验环境实验在一台搭载Ubuntu 20.04操作系统的服务器上进行,服务器的相关配置如表1 所示.由于BoBGSAL-Net 模型是深度学习模型,需要GPU 进行模型运算,GPU 可以极大地提高模型的运算速度.实验使用的核心依赖工具包如表2 所示.

表1 服务器的详细配置Table 1 Detailed server configuration
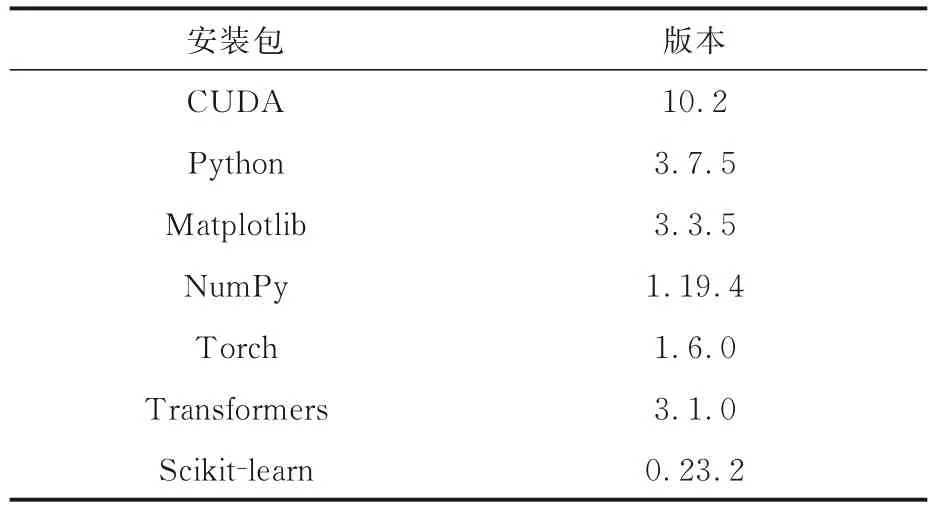
表2 核心依赖工具包Table 2 Core dependency toolkit
使用NumPy 和Matplotlib 对数据进行探索性分析,并使用Scikit-learn 和Torch 构建训练机器学习和深度学习模型.在处理文本数据时,使用Transformers 库中预训练的模型来提取特征,然后使用Scikit-learn 或Torch 进行分类和回归任务.此外,使用CUDA 在GPU 上加速模型的训练和推断过程,提高计算速度.
3.2 数据集DocRED 是一个大规模数据集,从维基百科和维基数据构建而来.它提供了全面的人工标注,包括实体提及、实体类型、关系事实以及相应的支持证据.共有97 个目标关系,每个文档中平均大约有26 个实体.数据规模为3053 个训练文档,1000 个开发集文档和1000 个测试文档.此外,DocRED 还收集了用于其他研究的远程监督数据.
作者自建数据集AlSiaRED[14]是在铝硅合金研究领域的专家指导下,构建的用于铝硅合金关系抽取的一个数据集,其构建过程包括选择材料科学文献、确定标注内容以及进一步确定数据集的实体类型和关系类型.AlSiaRED 数据集共涵盖8226 个句子,标注了9362 个实体以及6876 种关系,可以同时进行实体识别和关系抽取任务.
3.3 实验配置本文提出的BoBGSAL-Net 是一个基于Pytorch 和DGL(Deep Graph Library)框架的模型,其中包含两层GCN 网络结构,dropout 的比率设置为0.6,学习率初始化为0.001.模型优化器采用AdamW,权重衰减为0.0001.
在词嵌入层层面,采用了三种不同的模型,包括BiLSTM,GloVe 和BERT.其中,BiLSTM(256 d)和GloVe(100 d)用于词嵌入编码.基于BERT 的词嵌入采用官方提供的BERT base 和BERT large 预训练模型,并将学习率初始化为1e-5.
3.4 评估指标使用F1 作为评估指标之一.F1是精确率和召回率的加权几何平均值,是平衡准确率和召回率的综合指标.精确率、召回率和F1如式(15)~(17)所示:
其中,T为一类实体被正确分类的实际个数,C表示被识别为这一类实体的样本总数,A为样本中的实体实例总数.
基于混淆矩阵衍生出另一个评估指标AUC(Area under Curve),即受试者工作特征曲线下的面积来评估分类模型的性能.评估指标的计算涉及混淆矩阵,主要通过对True Positive(TP),False Positive(FP),True Negative(TN)和False Negative(FN)四个参数进行计算.TP表示模型将样本预测为正例,并且实际标签也为正例,即模型预测正确的标签;FP表示模型将样本预测为正例,但是实际标签为负例,即模型预测错误的标签;TN表示模型将样本预测为负例,并且实际标签也为负例,即模型预测正确的标签;FN表示模型将样本预测为负例,但实际标签为正例,即模型预测错误的标签.
本文采用的评估指标包括F1,AUC,IgnF1以及IgnAUC.
3.5 基准模型实验使用的基准模型主要完成实体识别和关系抽取两个任务.对于实体识别任务,选用多种经典模型进行对比,包括LSTM[5],BiLSTM[6],HIN-GloVe[7],CNN[12],Context-Aware[21],CFER-GloVe[27],SSAN-BERT-base[28]和GAIN+SIEF[29].这些模型在文本分类和实体关系抽取任务中表现出色,已被广泛应用于自然语言处理领域.对于关系抽取任务,选择HINBERT-base[7],GCNN[8],LSR-GloVe[22],GAT[23],EOG[24],AGGCN[25],GAIN-GloVe[26],LSR+BERT-base[30]和CGM2IR-RoBERTa[31]作为基准模型.其中,LSR+BERT-base 模型在文档级实体关系抽取任务中具有较高的影响力,已成为该领域的重要研究方向.
总体上,本文实验选用多种经典和代表性模型,对后续研究具有重要的参考价值.
4 实验结果与分析
针对命名实体识别和关系抽取两个任务进行实验,并通过对BoBGSAL-Net 模型在DocRED和AlSiaRED 数据集上的多方面评估来进行模型性能的分析.
实验1:BoBGSAL-Net 在DocRED 数据集上的命名实体识别对比实验.
为了评估本文提出的BoBGSAL-Net 模型在公开数据集上的命名实体识别性能,在公开数据集DocRED 上与基准模型进行对比实验,实验结果如表3 所示,表中黑体字表示结果最优.由表可知,BoBGSAL-Net 模型在DocRED 数据集上的命名实体识别各项指标均优于基准模型,这可能是因为MMLG 策略能够捕捉文档中不同实体间的复杂信息交互,同时ERG 模块融合了路径推理机制,能够自动学习实体之间的多个关系路径,导致BoBGSAL-Net 模型在DocRED 数据集上表现有所提升.
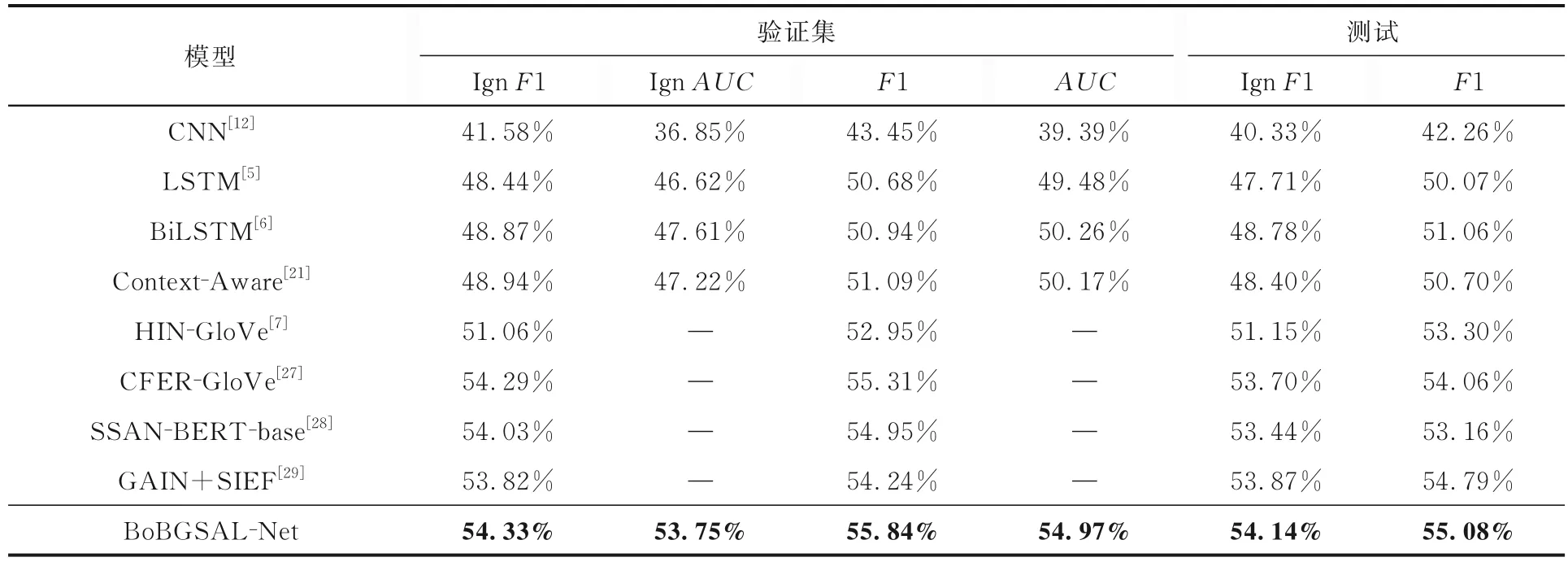
表3 BoBGSAL-Net 模型和其他模型在DocRED 数据集上的命名实体识别实验结果的对比Table 3 Experimental results of named entity recognition by BoBGSAL-Net and other models on the DocRED dataset
实验2:BoBGSAL-Net 模型在AlSiaRED 数据集上的命名实体识别对比实验.
对BoBGSAL-Net 模型在铝硅合金材料实体识别任务上的性能进行了验证,并在AlSiaRED数据集上进行了命名实体识别实验.实验结果如表4 所示,表中黑体字表示结果最优.
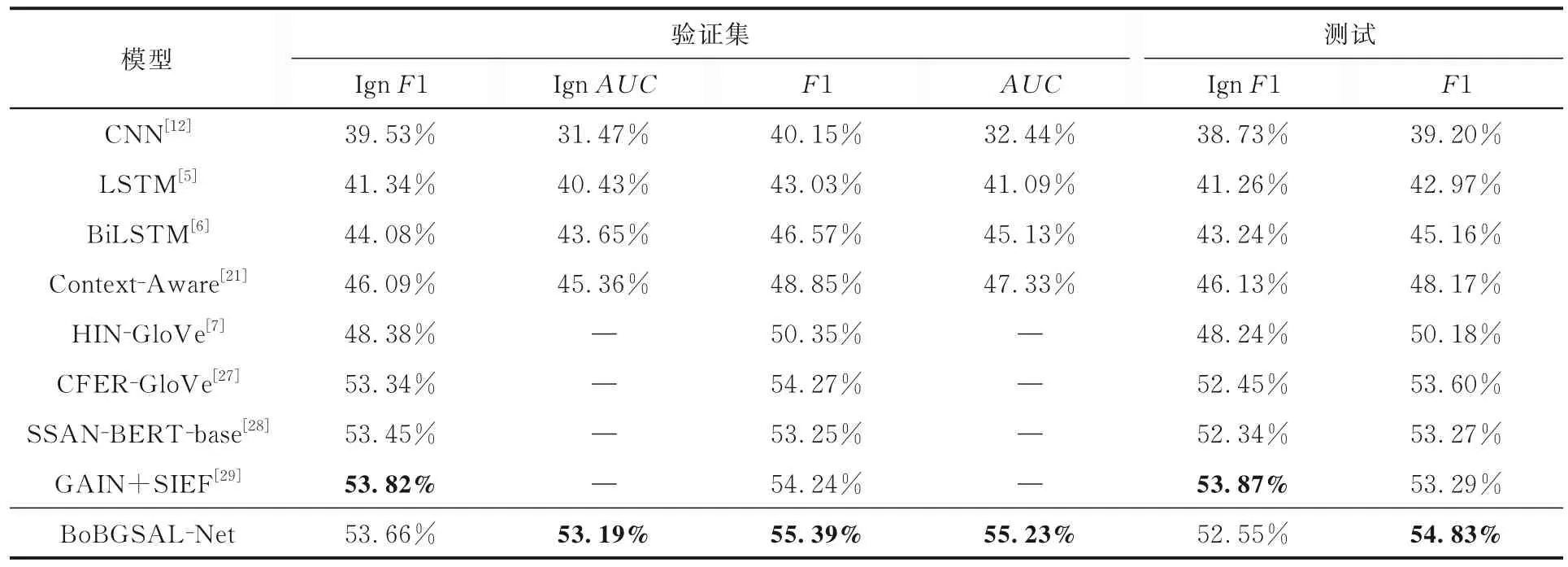
表4 BoBGSAL-Net 模型和其他模型在AlSiaRED 数据集上的命名实体识别实验结果的对比Table 4 Experimental results of named entity recognition by BoBGSAL-Net and other models on the AlSiaRED dataset
由表可知,BoBGSAL-Net 模型在AlSiaRED数据集上的表现优于基准模型,但和其在Doc-RED 数据集上的表现相比,性能有所下降.这可能是因为作者实验室构建的数据集包含更多的实体类型且文本长度较长,BoBGSAL-Net 模型训练和推理的时间开销较大,导致性能指标的下降.
实验3:BoBGSAL-Net 模型在DocRED 数据集上的关系抽取对比实验.
为了评估BoBGSAL-Net 模型在DocRED 数据集上的关系抽取任务性能,进行了相应的对比实验,结果如表5 所示,表中黑体字表示结果最优.由表可知,BoBGSAL-Net 模型在DocRED 数据集上的关系抽取任务中,性能比基准模型更好,主要原因是该模型中的MMLG 模块和ERG 模块都具有针对实体之间关系信息的感知结构.与GAT 和GCNN 相比,BoBGSAL-Net 具有更好的全局上下文建模能力,能够更好地理解多个句子之间的实体关系.BoBGSAL-Net 结合了图结构、实体关系路径推理和注意力机制,能够自动学习实体之间的多个关系路径.与EOG 和AGGCN相比,BoBGSAL-Net 在捕捉实体之间的多层语义关系时表现更为突出.由表可知,BoBGSALNet 模型在DocRED 数据集上的性能不如LSR+BERT-base 和CGM2IR-RoBERTa,这可能是因为BoBGSAL-Net 具有更复杂的模型结构,导致在训练过程中需要更多的计算资源和参数调优,而不当的调优会影响性能.

表5 BoBGSAL-Net 模型和其他模型在DocRED 数据集上的关系抽取实验结果的对比Table 5 Experimental results of relation extraction by BoBGSAL-Net and other models on the DocRED dataset
此外,在引入词嵌入模型后,性能与BoBGSALNet相比,有显著提升,尤其在BoBGSAL-Net 与BERT 相结合的BoBGSAL-Net+BERT 模型中,性能表现最为出色.可能因为BoBGSAL-Net+BERT 模型将图结构与BERT 的预训练语义表示相结合,从而更加充分地整合不同层次的信息.通过ERG 模块的路径推理机制,该模型能够更准确地学习实体关系的多个关系路径,增强对复杂关系的抽取能力,使得该模型在关系抽取任务中表现出色.
实验4:BoBGSAL-Net 模型在AlSiaRED 数据集上的关系抽取对比实验.
为了评估BoBGSAL-Net 模型在作者实验室构建的数据集上的关系抽取性能,设置该实验对模型性能进行测试,实验结果如表6 所示,表中黑体字表示结果最优.由表可知,在AlSiaRED 数据集上的关系抽取任务中,BoBGSAL-Net 模型的性能和其他模型相比,提升更显著.此外,BoBGSAL-Net 模型结合了MMLG 策略和BERT 的全局上下文建模,能够更准确地捕捉整个文档的实体关系,在语义和语法更复杂以及长句子更多的AlSiaRED 数据集中表现更好.
实验5:BoBGSAL-Net 模型在DocRED 数据集上的实体抽取对比实验.
为了评估文档级实体抽取相对文档-句子-语言三级实体抽取在DocRED 数据集上的实体抽取性能,本文设置该实验对模型性能进行测试,实验结果如表7 所示,表中黑体字表示结果最优.由表可知,BoBGSAL-Net+BERT 模型在DocRED数据集上的实体抽取任务性能优于其他模型.相较于文档-句子-语言三级实体抽取模型,BoBGSAL-Net+BERT 模型不仅是将不同模块简单地串联起来,而且将图结构与语义表示紧密结合,使模型更深入地理解实体关系.在文档级实体抽取中,BoBGSAL-Net 综合考虑整个文档的语境,更好地理解实体的上下文关系,由于直接在文档级别进行抽取,相对于独立处理文档、句子和语言级别的模型,其整体处理速度可能更快.这种整合性使得BoBGSAL-Net+BERT 能够更好地理解文本中的复杂关系,提升了抽取质量.

表7 BoBGSAL-Net 模型和其他模型在DocRED 数据集上的实体抽取实验结果的对比Table 7 Experimental results of entity extraction by BoBGSAL-Net and other model on the DocRED dataset
5 结论
本文提出一种文档级实体关系抽取方法,即基于双图结构的聚合逻辑网络BoBGSAL-Net.该方法首先构建一个MMLG 模块,模拟整个文档中不同提及之间的复杂信息交互,提高模型对文档级实体关系的感知能力.其次,构建了ERG模块,该模块融合路径推理机制,主要针对实体间的多个关系路径进行推理学习,更准确地识别提及级节点实体及关系.
本文基于MMLG 和ERG 提出聚合逻辑推理路径以推断实体之间的关系,并进行分类预测.在公开数据集DocRED 以及作者实验室构建的数据集AlSiaRED 上进行对比实验,结果表明BoBGSAL-Net+BERT 在文档级实体关系抽取任务中,性能优于其他所有模型,与CGM2IRRoBERTa 模型相比,F1 指标提升2.66%,在文档级关系抽取任务中性能得到提升.
未来将探索并优化本文模型,进一步提高实体关系抽取性能.针对多语言文档的场景,通过跨语言模型迁移等技术实现对不同语言的文档级实体关系抽取,提高模型的通用性和可扩展性.
