草莓感官评价模型方法比较
2023-12-15马婉婷尚伟谷晏赵峙尧孙颖
马婉婷,尚伟,谷晏,赵峙尧,孙颖
(1.北京工商大学化学与材料工程学院,人工智能学院,北京 100048)(2.北京市西城区市场监督管理局,北京 100048)
草莓为蔷薇科的多年生草本植物,其果实鲜美红嫩、果肉柔嫩多汁、有着浓郁的特殊香气,具有较高的营养价值,有着“浆果皇后”的美称,在国内外许多地区均有种植[1,2]。近年来,中国草莓生产规模稳定增长,产量和种植规模均居于全球首位,在全世界的经济作物中占有重要的地位[3]。然而针对草莓的品质优劣的评价流程仍存在欠缺从而使得草莓的综合利用率相对较低[4]。目前有关草莓的感官评价研究大多聚集在草莓果汁、果酒和草莓酱等领域[5],针对草莓新鲜果实的感官评价方法较少,有基于电子鼻技术[6]、近红外光谱检测[7]等,但仍以专家组人工品尝评定的方法为主[8]。人工评定与评价者本人的评价经验、年龄及健康状况有关,结果具有主观性,不同专家评定结果会有偏差,导致不同批次的产品无法横向比较。钟成等[8]提出一种基于神经网络对啤酒风味建立的客观评价模型,但由于草莓的货架期短,导致理化指标样本数据少,故而鲜果草莓感官评价的估计模型相对较少。
支持向量机(Support Vector Machine,SVM)是一种具有构建流程相对简洁且耗时较低,可以较好的解决样本数量少、数据维度高等问题的机器学习算法[10],被广泛应用于分类和回归问题中。支持向量机模型不仅可以表征样本数据中输入数据多个特性和目标输出之间的非线性关系而且结果精度高、稳定性好。游清顺等[11]通过SVM对抽检数据进行食品质量合格分类。王娜[12]采用了最小二乘支持向量机预测模型对北京市肉类供应量做出了预估。影响支持向量机模型精度、稳定性及泛化性的主要因素就是支持向量机的核心参数:惩罚因子c和松弛因子g。故而参数的优化对于如何建立起一个支持向量机模型必不可少。因此,本文提出了一种基于支持向量回归的草莓感官评价估计方法,并利用灰狼算法(Grey Wolf Optimizer,GWO)对模型参数进行优化。
1 材料与方法
1.1 材料与试剂
本研究中的草莓果实品种为“章姬”,来自北京天翼生物工程有限公司的昌平奶油草莓生产基地。超氧化物歧化酶(Superoxide Dismutase,SOD)、过氧化氢酶(Catalase,CAT)、抗坏血酸过氧化物酶(Ascorbate Peroxidase,APX)、过氧化物酶(Peroxidase,POD)、多酚氧化酶(Polyphenol Oxidase,PPO)、过氧化氢(H2O2)测定试剂盒,南京建成生物工程研究所有限公司;生理盐水,石家庄四药有限公司。
1.2 仪器与设备
Bio-tek酶标仪,SYNERGY公司;分光光度计,安捷伦科技有限公司;3K15高速冷冻离心机,SIGMA公司;T-403数字电子天平,北京赛多利斯仪器系统有限公司;恒温集热式加热磁力搅拌器DF-101S,巩义市予华仪器有限公司;F-80C型制冰机,北京博威兴业科技发展有限公司。
1.3 方法
1.3.1 草莓样品设计
选择果实体积、色泽、成熟度相同(草莓品种为章姬,八成熟,色泽红润鲜艳色深,单果质量(15±1) g),无病虫害和机械伤的草莓鲜果在常温下进行试验。
1.3.2 理化指标测定
按照SOD、CAT、APX、POD、PPO、H2O2测定试剂盒提供的方法进行测定。按照m(草莓):m(生理盐水)=1:9,在冰水浴条件下配制比例为10%组织均匀浆液,获取3500 r/min离心10 min后的上清液。遵循试剂盒步骤,先准备好实验管、对照管,再添加相应试剂1到试剂4。均匀后,获取3500 r/min离心10 min后的上清液,在相应波长处,利用酶标仪进行测定,平行重复各3次,计算酶活力[13]。
黄酮的测定方法[14]:称取芦丁10 mg,加入10 mL无水乙醇,配成0.1 mg/mL的标准品溶液。称取草莓样品5 g,置于50 mL棕色容量瓶中,加入无水乙醇35 mL,超声60 min,以无水乙醇定容至刻度,摇匀后取25 mL于50 mL离心管中,于6000 r/min离心10 min,上清液备用。吸取0.00、1.00、2.00、3.00、4.00、5.00 mL芦丁标准品溶液,分别置于25 mL的比色管中,补水至10 mL,加1.0 mL亚硝酸钠(50 g/L),放置6 min,加1.0 mL硝酸铝溶液(100 g/L),放置6 min,加入4.0 mL氢氧化钠溶液(40 g/L),加水至刻度,放置15 min。用1 cm比色皿,以试剂空白调节零点,在波长510 nm处测定吸光度。以吸光度为纵坐标,芦丁质量为横坐标,绘制标准曲线。精密吸取2.0 mL供试品溶液,置25 mL比色管中,补水至10 mL。在波长510 nm处测定吸光度。
总多酚的测定方法[15]:称取没食子酸约10 mg,置于100 mL棕色容量瓶中,加水配成的0.1 mg/mL标准品溶液。称取草莓样品10 g,置100 mL棕色容量瓶中,加入水适量,超声60 min,冷却至室温,以水定容至刻度,摇匀后取30~35 mL于50 mL离心管中,于6000 r/min离心15 min,上清液备用。吸取标准品溶液0.20、0.40、0.60、0.80 mL分别置于10 mL的容量瓶中,各加入3~4 mL的水。加入0.5 mL福林酚试液;在1~8 min内,各加入1.5 mL Na2CO3溶液(20.0 g/100 mL的水溶液)。用水定容至刻度,分别得到没食子酸浓度约为0.002、0.004、0.006、0.008 mg/mL的标准品溶液,将各容量瓶置于30 ℃水浴中保持2 h。同时配制空白溶液,以空白溶液调零,于760 nm(10 min内)处测定吸光度,以吸光度为纵坐标,浓度为横坐标,绘制回归曲线。精密吸取0.2 mL供试品溶液,置10 mL容量瓶中,各加入3~4 mL水,以空白溶液调零,于760 nm(10 min内)处测定吸光度。
pH值的测定:草莓可食部分打浆,取一定量的草莓酱加等量的屈臣氏水混匀,用pH计测量5次。
可溶性固形物(Soluble Solids Content,SSC)的测定[16]:草莓可食部分打浆,用四层纱布挤出均浆汁液,用Abbemat 500全自动折光仪测量3次。
1.3.3 感官评价
感官评价小组由5名女性和5名男性(年龄从25岁到55岁)组成。他们能够区分基本口味(苦、甜、酸、咸和鲜味),并在果蔬感官评级及风味分析方面有一定经验。小组成员接受了培训,每周(3周)三次,每次20 min,对5种不同浓度的基本口味溶液进行区分和重新排序。在培训期间,为受试者提供了五种草莓,为每种属性提供了广泛的感官可变性,并进一步刺激描述符的形成。感官评估的最终评估标准由小组讨论确定。
描述性术语及其评价标准定义如下:(1)酸度:0.05 g柠檬酸/100 mL水=酸10,0.1 g柠檬酸/100 mL水=酸性20;(2)甜度:2 g蔗糖/100 mL水=甜度10,4 g蔗糖/100 mL水=甜值20;(3)苦味:0.00075 g奎宁/100 mL水=苦味10,0.0015 g奎宁/100 mL水=苦20;(4)外观:草莓果实饱满完整,没有机械损伤=外观20;(5)坚硬度:硬度高,无腐烂=硬度20;(6)色泽:红润,均匀=色泽20;(7)香气:草莓香气浓郁,无异味,无涩味=香气20;(8)滋味:不同口味的组合。根据确定的感官评估标准,小组成员在2周内接受了6次培训。最后,所有小组成员都能够识别这些描述词并一致使用它们。
感官评价在(23±2)℃、湿度55%的感官面板室中进行。小组成员被要求以外观、坚硬度、色泽、香气、滋味为评价指标。每个指标满分20分,总计100分。表1为试验中的感官评价回答表。为了避免疲劳和携带影响,小组成员被要求在两个不同样本的测试间隔期间用50~60 mL的饮用水漱口。感官评估前一小时不允许进食、饮酒或吸烟。在每节课结束时收集所有记分卡,并计算所有10名小组成员在三次重复实验中给出的所有描述符的平均值,以进行多元统计分析。

表1 感官评价得分表Table 1 Sensory evaluation score table
1.3.4 数据处理
理化指标及感官指标均每0.5 d测定一次,共测量6 d,每次平行测定3组,共测得36条实验样本数据。
2 模型的建立
2.1 支持向量机模型
支持向量机可以对样本进行有监督的分类和回归,2014年由Vladimie等[17]提出,本文使用的是支持向量机的回归(Support Vector Regression,SVR),图1为其原理图,目的是通过训练寻找到一个使得所有样本点距其距离最小的超平面。

图1 支持向量机原理示意图Fig.1 Schematic diagram of Support vector machine
超平面可用式(1)表示:
式中:
ωT——权向量转置,
b——偏置。
寻找最优超平面的问题可以转化为所对应的凸二次规划问题:
式中惩罚因子c的取值反映了公式(2)中2个变量的权重;iξ和ξ*i为松弛变量,旨在使得寻找最优超平面的标准降低。落入到ε定义的不敏感带内的样本数据忽略其损失,即只有落在不敏感地带外的样本才会对支持向量模型产生影响,最后确定的优化模型具有总损失最小和间隔最大的特点。
SVR的核函数有多种选择[18],应用广泛的径向基函数作为本文选用的核函数。寻找最优超平面转化为的凸二次规划的对偶问题由拉格朗日乘数法解决,并给出决策函数:
式中:
ai和aj——拉格朗日乘数;
用K(xi,xj)=φ(xi)Tφ(xj)来计算多维特征空间向量的数量积。
参数的正确取值也对SVR模型有着很大的影响[19],合理的参数选择会使得所建立模型学习能力更强,精度更高。惩罚因子c和径向基核函数的参数g是建立支持向量回归模型需要确定的两个关键参数。c决定了模型的复杂程度和误差大小,拟合效果会随着c数值的增大而变好,然而取值超过一定范围也会导致过拟合现象。核函数参数g则是用于定义了单一训练样本能起到多大的影响,如果g的取值不恰当会导致支持向量机模型的泛化能力差。为获取精度最高的SVR模型,采用GWO算法进行参数c、g的寻优[20]。
2.2 灰狼优化算法
灰狼优化算法在2014年作为一种群体的随机搜索算法由高校研究者Mirjalili等[21]提出。该优化算法模仿灰狼种群的等级制度及捕猎生活,存在能够自适应调整的收敛因子,需要设定的参数少易通过编程实现等优点因而被广泛选用。
灰狼是一种处于食物链顶端的群居犬科哺乳动物[22]。灰狼种群严格按照社会权力等级制度进行生活。GWO将灰狼群体划分为α、β、γ和ω4种等级。按适应度的大小排序金字塔如图2所示。
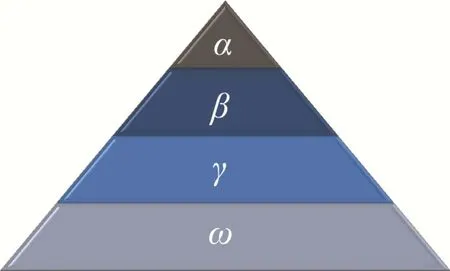
图2 灰狼的社会等级制度Fig.2 The social hierarchy of the gray wolf
狼群中的头狼记为α,它是在狼群中对捕猎、生长、作息时间等行为进行决定的支配狼。狼群中所有其他的狼都要听从它的吩咐。另外,虽然它不一定是整个狼群中最强大的狼但是它是整个狼群中最具有管理技能。
β狼是α狼的最优递补狼,它可以管理除了α狼之外的其他等级的狼群,并帮助α狼做出选择,在α狼死亡或衰弱后,β狼将有望顶替α狼。
γ狼,它服从α、β狼,并同时调配底层狼。
ω狼,需要服从社会层级上的其他狼,主要作用是保持狼群内秩序的稳定,防止出现自相残杀等问题。
灰狼捕食猎物有如下三个步骤:搜寻、跟踪和围捕[23],GWO优化过程就是灰狼种群生活中社会阶级划分、搜索、包围和攻击猎物的过程,GWO算法首先自由产生部分狼群,确定猎物的大致位置,ω狼在α、β、γ狼的带领和指导下进行跟踪猎物和围攻,最优参数通过计算适应度值得出,直至满足终止条件时,目标函数的最优解即为猎物的最终位置。
灰狼在发觉猎物后渐渐靠近并围困猎物的过程可用如下数学模型进行描述:
搜寻过程大多依赖α、β、γ狼的合作进行。算法通过假设狼群具有分辨猎物方向和位置的潜能[23,24]来模拟灰狼狩猎的过程从而获得最优解,这样在每次迭代过程中,保留社会等级中前三层级的狼群位置并根据其位置数据来更新计算出其余灰狼的定位[25],用下列数学模型描述上述过程:

图3 灰狼位置更新示意图Fig.3 Schematic of gray wolf location update
2.3 基于GWO-SVM的草莓感官评价软测量模型
2.3.1 数据分析
实验每隔0.5 d测量一次与草莓感官评价相关的十项理化风味指标并记录,同时记录专家组评定的草莓感官评价得分数据,每次平行测定三组,直至6 d后草莓腐败失去感官价值,共获得3组36条草莓理化风味指标及对应的专家组感官评价得分数据,并计算三组平行实验数据的均值。对所有数据进行归一化处理,将实验所得的三组平行数据作为训练集,用三组平行数据的均值作为测试集对模型的估计结果进行验证。利用十项理化风味指标作为输入数据,草莓感官评价得分作为输出数据的软测量模型结构图如图4。
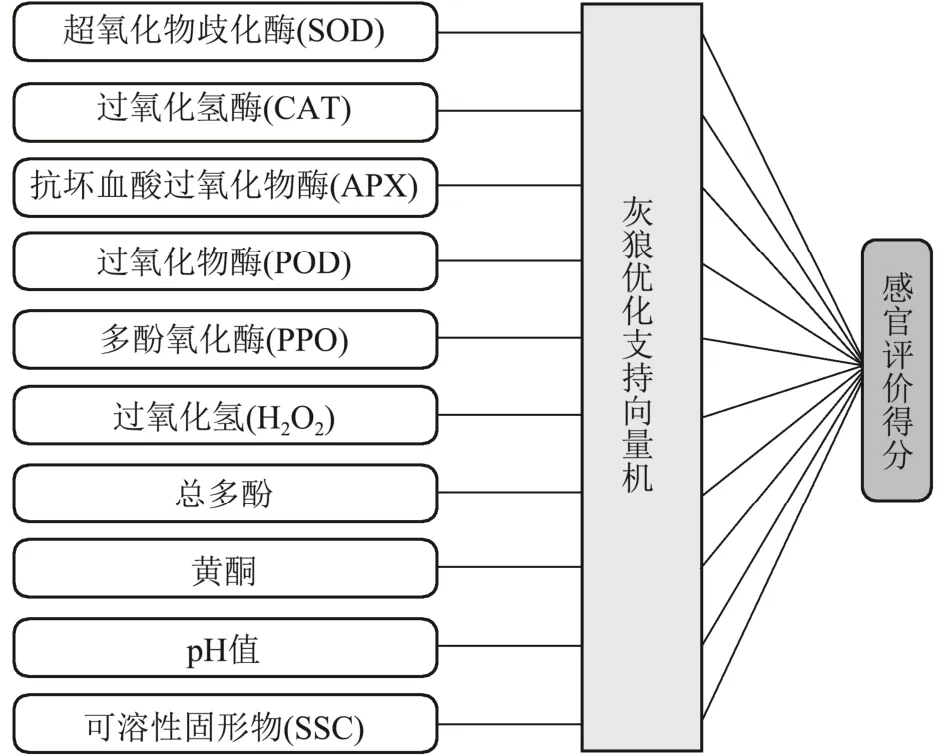
图4 草莓感官评价模型结构图Fig.4 Structural diagram of strawberry sensory evaluation model
2.3.2 草莓感官评价模型的建立
整个流程在MATLAB2019b中进行编译与实现,使用LIBSVM工具箱来进行支持向量机的应用,核函数采用径向基函数。影响SVR模型精度参数的惩罚因子c和核函数参数g由灰狼优化算法通过不断迭代直至达到终止状态获得,模型的精度由测试集数据进行评定,上述过程即为草莓感官评价得分的软测量模型的建立,如图5所示。

图5 基于灰狼优化支持向量回归的草莓感官评价模型的建立Fig.5 Establishment of strawberry sensory evaluation based on grey wolf optimized support vector regression
3 结果与分析
本文按照3:1的比例划分为训练集和测试集。草莓感官评价模型基于灰狼优化支持向量机算法实现,其中灰狼算法初始参数设置为:狼群数量20,迭代终止次数50。将寻优算法寻优后获得的最佳参数c和参数g代入构建的支持向量回归模型中对样本进行训练和预测。
本实验选用均方根误差(Root Mean Squared Error,RMSE)、平均绝对误差[27](Mean Absolute Error,MAE)和R2(R Squared)这三个指标来评价基于GWO-SVM的草莓感官评价模型的性能。
其中,以均方根误差计算出估计值与真值之间偏差的平方和与训练次数n比值的平方根,用于反映估计值同真值之间的误差[28];平均绝对误差用于衡量估计值与真值之间的距离,可以准确表达实际估计偏差的严重程度;R2是一个相对度量指标,它的主要作用是对其结果进行了归一化,更易于看出模型间的差距[29],故而可以使用它来与在相同数据上训练的其他模型进行比较。
三项指标的计算公式如下:
式中:
n——样本数;
ˆy——草莓感官评价真实值;
ˆy——草莓感官评价真实值的平均值;
y——预测结果;
y——预测结果的平均值。
设置粒子群优化支持向量机(Particle Swarm Optimization-Support Vector Machine,PSO-SVM)、卷积神经网络(Convolutional Neural Network,CNN)、长短时记忆网络(Long Short Term Memory Networks,LSTM)进行对比,每种算法的迭代次数均与实验所用方法迭代次数一致。其中粒子群优化算法与灰狼优化算法的目的相同,均为找到支持向量机模型中最优的的惩罚因子c和松弛因子g[30,31],旨在比较不同优化算法在此实验问题中的参数寻优性能。LSTM和CNN[32]有监督学习的深度神经网络对草莓感官评价数据进行回归预测,比较了机器学习和深度学习在本实验中小样本数据回归问题上的精度。为了充分验证所提出模型的有效性,将每种方法独立重复20次,均计算均方根误差、平均绝对误差、R2三个评价指标与所提出模型的误差效果进行对比,以确保结果的客观性。统计结果如图6~8所示。

图6 各个模型的RMSE箱线图Fig.6 RMSE boxplot of each model

图7 各个模型的MAE箱线图Fig.7 MAE boxplot of each model
由图6、7可以看出,经GWO优化后的SVM模型的误差箱体小于其他模型的误差箱体,重复实验20次后,RMSE均值为0.28,误差浮动范围为0.04,MAE均值为0.24,误差浮动范围为0.05。其次依次为经PSO优化的支持向量机模型RMSE均值0.46,MAE均值0.38,误差浮动范围分别为0.06、0.06;CNN模型RMSE均值0.88,MAE均值为0.75,误差浮动范围0.9、0.44;LSTM模型RMSE均值1.24,MAE均值0.99,误差浮动范围0.85、0.66。证明所提出模型的RMSE和MAE的分布最集中,模型误差最小,相比其他模型,保持了较高的精度和稳定性。由图8可以看出,GWO-SVM模型的R2最高,证明在草莓感官评价估计问题中,所提出模型的拟合度最高。文中所需设定寻优参数较少,灰狼优化算法可以可以在简单寻优问题中在局部寻优与全局搜索之间实现平衡,证明GWO在简单寻优问题中全局寻优能力强,效果优于侧重于局部寻优的PSO算法。SVM模型作为机器学习模型的一种,在小样本回归问题中准确率和稳定性均高于深度神经网络模型。由图9可以看出,GWO-SVM与真值重合度最高,其余依次为PSO-SVM、CNN、LSTM。
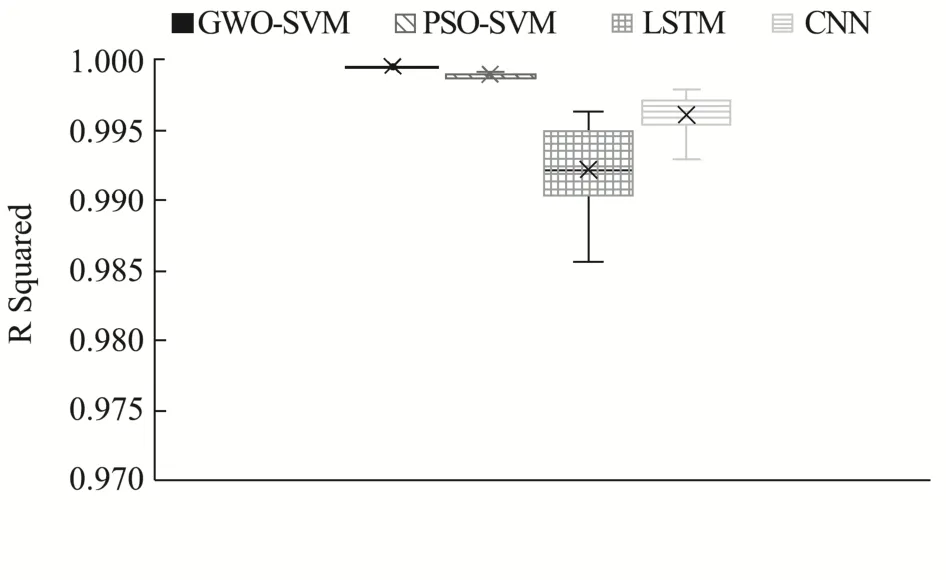
图8 各个模型的R2箱线图Fig.8 R2 boxplot of each model

图9 各个模型的感官评价得分估计曲线及分值Fig.9 Sensory evaluation score estimation curve and score of each model
4 结论
本试验建立了一种可以将草莓的理化指标与感官评价得分对应起来的综合模型,并设置了对照实验验证了所提出模型的优越性。试验结果表明,同等条件下,在小样本高纬度问题中,SVM模型的结果优于神经网络模型,而灰狼优化算法在简单寻优问题中可以在局部寻优与全局搜索之间实现平衡且具有较强的收敛性能,基于GWO-SVM综合模型的草莓感官评价软测量结果优于基于PSO-SVM模型软测量结果。以上结论已在其他批次的草莓上进行过验证,结果表明方法可行,可以为支持向量机方法在其他食品领域感官评价得分的估计研究提供一定的参考,在未来的研究中,将尝试使用该模型对不同种类食品的理化指标数据进行测试,并对模型结构进一步优化和改进。
