双目视觉的智能汽车目标检测算法研究
2023-12-12申彩英朱思瑶黄兴驰
申彩英,朱思瑶,黄兴驰
(辽宁工业大学 汽车与交通工程学院, 辽宁 锦州 121001)
0 引言
环境感知是智能驾驶汽车得以实现的基础,所有路径规划与运动控制都要基于环境感知系统[1]。目标检测是环境感知系统的重要功能之一,如何准确、快速地检测车辆周围目标,对于汽车智能化至关重要。
深度学习在目标检测方面有着非常优异的表现[2],传统目标检测方法只适用于目标单一、背景相对简单的情境,而深度学习方法可对复杂的多目标情境进行处理。基于深度学习的目标检测方法,主要分为两类。一类是近年出现的,将基于自然语言处理领域中的Transformer模型迁移到计算机视觉任务中的Transformer框架算法,其代表性算法有 DETR[3]、ViT-FRCNN[4]等。这类算法通常能够更好地处理遮挡问题,但训练周期长、计算量大。另一类是基于卷积神经网络(CNN)的目标检测算法,发展比较成熟,已经广泛应用在各类图像处理任务中。这一类目标检测算法按网络结构可分为两大类,即One-stage和Two-stage。One-stage算法将目标分类功能和目标定位功能融合在一起,只需将图像送入网络一次,即可同时得到分类结果和定位结果,此类算法运算速度快,但精确度相对Two-stage算法略低,典型代表有SSD、YOLOv3[5]、YOLOv4[6]、CornerNet[7]等。Two-stage算法先产生候选区域,再对候选区域进行分类和定位回归,此类算法精确度较高,但运行速度较慢,典型代表有R-CNN、Faster R-CNN等。
对智能驾驶汽车而言,检测算法对周围目标的检测速度越快、精度越高越好。YOLO系列算法作为一阶段目标检测方法的代表,由于其在速度和检测质量上取得了很好的平衡,在实际工业场景得到了广泛的应用。同时为了确保智能驾驶汽车的安全,即意味着汽车在行驶过程中不会撞到任何人或物,所以在汽车行驶过程中需要知道其周边物体和车辆本身之间的距离。有了这些相应的目标距离,作为后续的规划控制模块的上层输入信息,才能设计出高效安全的智能驾驶汽车。
在用深度 CNN 模型识别图像时,一般是通过卷积核去提取图像的局部信息。然而,每个局部信息对图像能否被正确识别的影响力是不同的[8](如背景部分和物体)。通过注意力机制可以建立不同区域的特征之间的交互关系,获得全局特征,同时能得到图像中不同局部信息的重要性程度。从而让网络模型能专注于图像中有效的特征信息,忽视一些无效信息,提高检测精度。
综合上述现实需求,本文中在YOLO算法的基础上,提出一种目标检测+距离测算方法:dual-YOLO。使用双目视觉相机作为数据采集传感器,从数据通道维度划分主干网络注意力,提升神经网络检测精度,并且利用SGBM算法对双目相机视差进行立体匹配,从而测算目标距离,最终形成一套可用度高且成本较低的环境感知系统。
1 检测网络框架
1.1 总体框架
dual-YOLO算法结构如图1所示,其由4个部分组成:① 双目相机预处理模块,对相机数据进行畸变矫正、坐标对齐等处理;② 目标检测网络,对目标进行分类和位置回归;③ 注意力模块,赋予数据不同学习权重,提高检测效率与准确度;④ 距离检测模块,测算目标与传感器的距离。
1.2 双目相机数据预处理
1.2.1畸变矫正
可见光相机具有非常复杂的光学设计,光线要经过多组镜片才能到达其传感器。由于实际工作环境复杂,成像过程往往不能达到理想效果导致畸变产生,如图2所示。在使用可见光相机数据之前,利用Matlab软件得到畸变参数矩阵,对图像畸变进行矫正,以避免影响后续检测及控制精度[9]。
1.2.2立体校正
在三维空间中,以不同视角观察同一点,其生成的图像平面不共面。需要用立体校正对双目相机两摄像头进行平面投影变换,使两平面共面。本文中使用文献[10]的方法对双目相机进行立体校正。
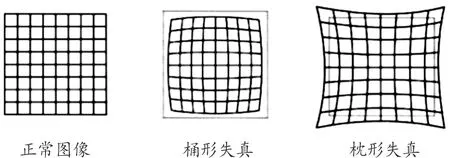
图2 径向畸变示意图
1.3 检测网络
以卷积神经网络为基础,参考文献[11],构建One-stage结构的检测网络,对目标进行检测。该网络由主干网络、颈部网络、检测头3部分构成,如图3所示。
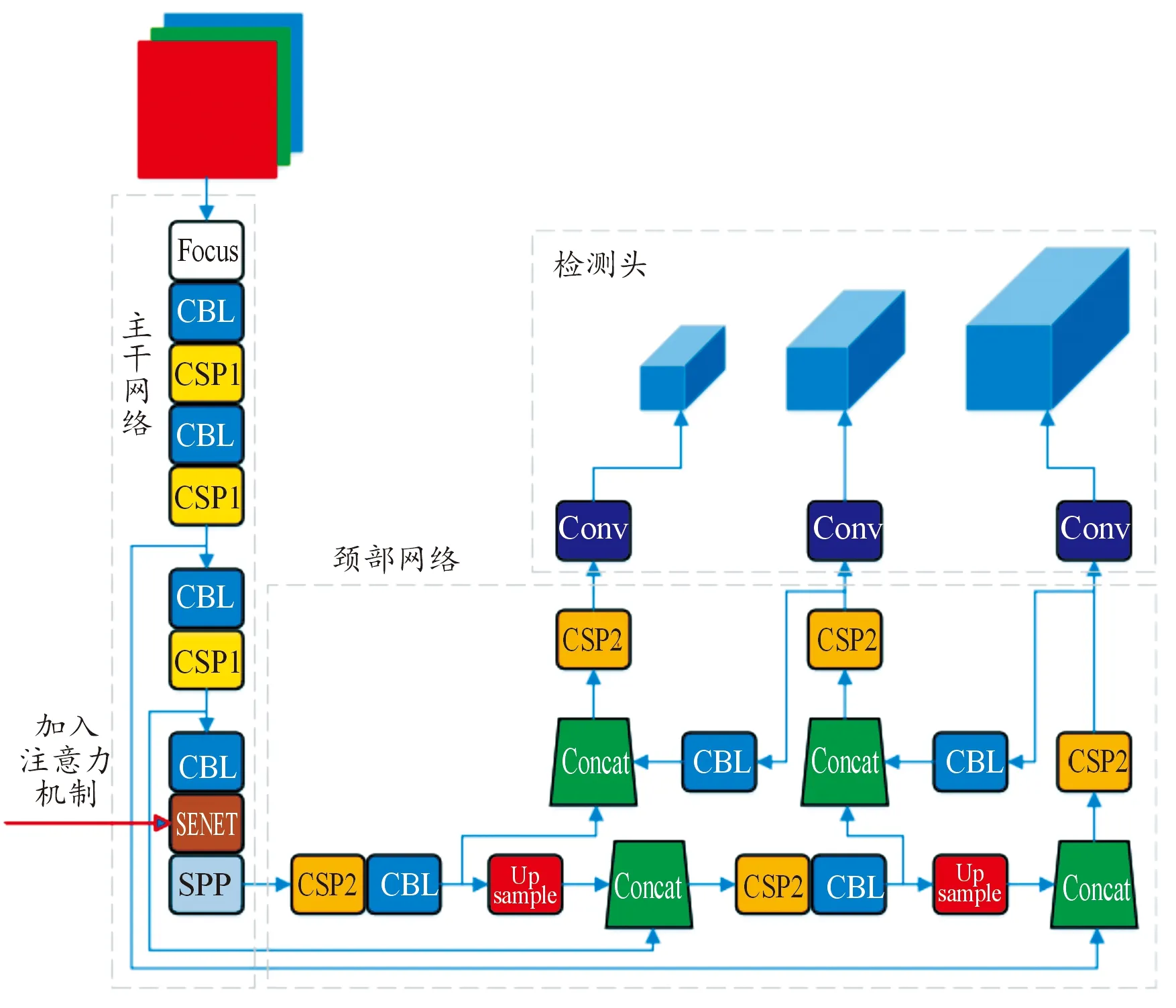
图3 检测网络结构示意图
1.3.1主干网络
主干网络由Focus、CBL、CSP1、SPP和注意力模块SENET构成。SENET模块赋予数据通道注意力,能提高网络对有效特征的学习权重。作为输入608*608*3的张量经主干网络后,变为20*20*512。
Focus将640*640分辨率的输入图像分为4份再进行切片,张量拼接后接卷积操作和LeakyReLU激活函数,特征图变为320*320*32。
CBL模块是此网络的核心模块,其将卷积、批归一化、LeakyReLU激活函数合三为一,其他模块中也存有CBL,经CBL后,特征图再次缩小但深度加深,为160*160*64。CSP1模块由CBL和多个残差单元构成,其有2个分支,分别学习特征信息,再进行张量拼接,使得输入和输出大小一致。
SPP模块对特征图分别进行3次最大池化再张量拼接,在不改变特征图大小的情况下增加检测网络对特征信息的学习范围。
1.3.2颈部网络
颈部网络是FPN+PAN结构,FPN自上向下采样,PAN自下向上采样。浅层网络更关注位置特征,深层网络更关注语义特征,FPN由上向下传达语义特征,PAN由下向上传达位置特征,颈部网络将二者串接起来,能显著提高检测网络的特征学习能力。
其颈部网络由CBL、CSP2、Concat和Upsample构成。CSP2模块相比CSP1,将残差单元替换为 CBL。Concat即张量拼接,将多个特征图拼接为一个,并加大特征图深度。Upsample即上采样,放大特征图以便下一步处理。
1.3.3检测头
检测头设计了3个head和9种anchor,输入数据最终被分别下采样8、16、32倍,变为80*80、40*40、20*20。3个head由感受野从小到大各分配3个anchor,更好地提升了对不同尺度大小的目标的检测精度。
检测ground truth宽、高与anchor宽、高的缩放系数,若小于anchor_t(预设为4.0),则判定为正样本,否则判定为负样本。正样本损失函数包括objectness loss、classification loss、localization loss 3种。其中位置损失函数采用CIOU_loss,解决了IOU_loss无法衡量ground truth和anchor不相交时的情况。
置信度损失函数采用二元交叉熵损失:
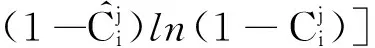
(1)
类别损失函数同样采用二元交叉熵损失:
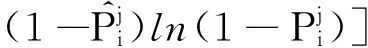
(2)

αν-DIOU
(3)
式中:IOU为两矩形框交并比;ρ为两矩形框中心点距离;c为两矩形框包围矩形的对角线长;ν为两矩形框相似度;α为ν的影响因子。
负样本损失函数为:
(4)
式中:λnoobj为权重系数,预设为0.5。
总损失函数为:
Loss=Lobj+Lnoobj+Lcla+Lloc
(5)
1.4 注意力机制
人类观察外界事物时,不会平均地观察眼睛所获取的画面,会将注意力聚焦在能获取重要信息部位,学习处理若干局部重要信息后,形成整体认知。注意力机制模仿人类观察事物的方式,将注意力更多地投入到更重要的任务中。如今注意力机制[12-15]被广泛使用在自然语言处理、图像识别、语音识别等各种不同的深度学习任务中。
注意力机制与卷积神经网络相结合的基本思想是让网络专注于图像中有效的特征信息,忽视无效信息来达到提高检测精度的目的。其作用机理是通过改变网络中的神经元权重达到的。通过注意力机制处理后的数据,其具有更好的非线性,使神经网络能够更好地学习数据特征。
可见光摄像头传感器采集到的数据是RGB形式的张量,通道数为3。卷积神经网络对其进行处理时,随着网络深度加大,数据通道数也会增加至数百层。参考文献[12],针对数据的不同通道维度,使神经网络学习每个通道的重要程度,提升重要特征并抑制非重要特征,注意力机制处理模块如图4所示。

图4 注意力机制处理模块示意图
1.4.1数据处理
输入数据X=「X1,X2,…,XC′⎤,X∈RH′×W′×C′。先对X做Ftr运算得到U=「u1,u2,…,uc⎤,U∈RH×W×C,uc∈RH×W:
(6)
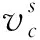
1.4.2压缩操作
对张量U做Fsq运算,可以压缩通道维度特征,把uc蕴含的二维特征变为一个实数,这个实数具有一定的全局感受野。方法是对U进行全局平均池化处理:
(7)
式中:压缩uc的空间尺寸H×W得到zc,其构成1×1×C的特征张量,具有全局感受野。
1.4.3激活操作
为了捕获各通道相关性,生成每个通道的权重,对数据做Fex运算:
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(8)
式中:W1z、W2为2个全连接层;δ为ReLU激活函数;σ为sigmoid激活函数。
1.4.4重构操作
对数据做Fscale运算,用通道间乘法将权重s加权到uc上:
(9)

1.5 双目测距
可见光摄像头作为传感器,具有信息密度高、可识别纹理、成本低廉等优点。但摄像头无法直接获取目标物体深度信息,难以满足智能驾驶汽车对环境感知的需求。双目视觉研究有力地解决了这一问题。双目相机测距的基本原理是三角测量,利用2个摄像头之间的视觉差来判断物体远近。双目测距,首先对相机进行标定和校正,再进行立体匹配得到视差,最后计算出深度信息。
1.5.1立体匹配
立体匹配的作用是使双目相机左右摄像头的像素点具有相互对应关系。半全局块匹配(semi-global block matching,SGBM)算法具有视差效果好、速度快的特点,是一种同时兼顾匹配精度和处理速度的算法[16]。使用SGBM法对双目相机进行立体匹配,流程如图5所示。
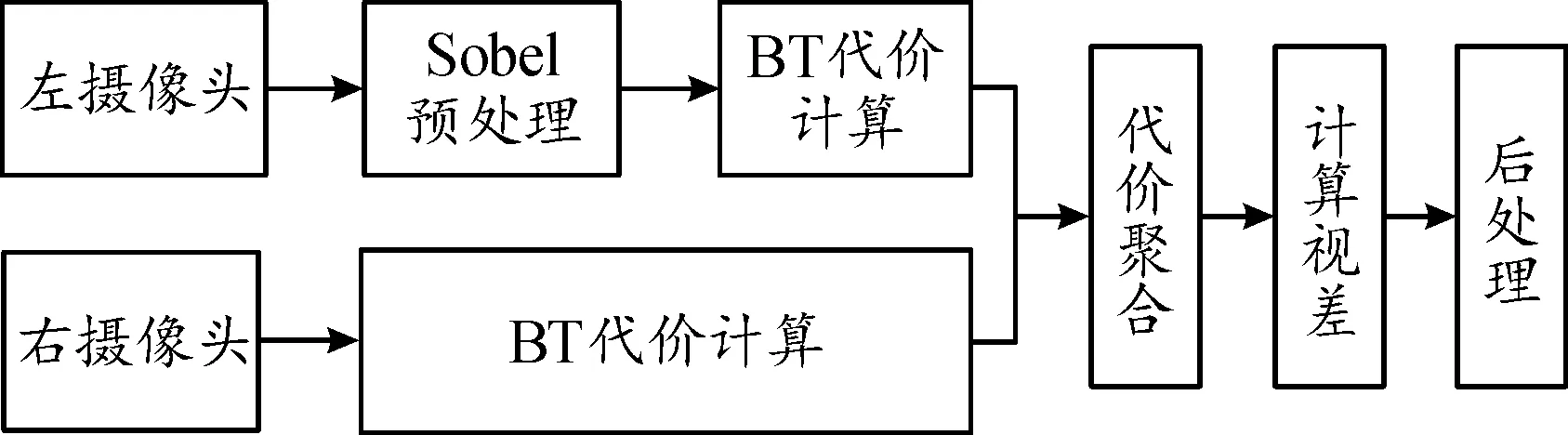
图5 SGBM检测流程框图
使用Sobel算子对图像进行预处理,提取物体边缘轮廓信息,之后进行BT代价计算。BT算法可以使像素变化更具连续性,更好地保留图像边缘细节信息。
经代价计算后,再进行代价聚合,先融合两摄像头数据:
Costcombine=BTsobel+α·BTgray
(10)
式中:α为权重系数,默认为0.25。
式中:p为像素点;r为某一路径;d为视差;Lr为当前路径的累积代价函数;第一项为匹配代价,此算法中等价为BT代价;第二项为平滑惩罚项,取4种情况下的最小代价;P1、P2为惩罚力度;第三项限定Lr的上限。式(12)是某一路径下的代价聚合,总路径代价聚合公式即为
(12)
式中:r值可设为4、8、16等。然后,即可计算视差,采取WTA赢者通吃策略,取视差最小值:
d=minS(p,d)
(13)
1.5.2距离测算
经过1.5.1处理后,对检测目标进行深度计算:
(14)
式中:depth为深度;f为焦距;b为基线长度;cxl为左摄像头主点横坐标;cxr为右摄像头主点横坐标。使用式(10)即可计算摄像头传感器到检测目标之间的距离。
2 平台搭建与试验
2.1 双目摄像头标定
双目摄像头传感器负责数据采集,作为算法的输入端。传感器规格如表1所示。
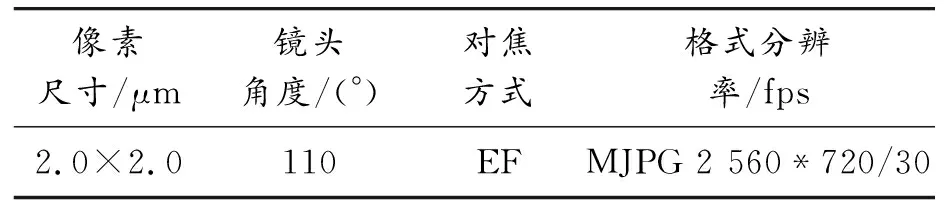
表1 传感器规格
在A3纸上打印9×7的棋盘格,利用Python脚本拍摄多张双目照片,在Matlab中对摄像头进行标定。舍弃Mean Error高于0.2的照片,再由Matlab计算相机参数并输出。
相机左右内参为:
trinsicMatrixLeft=

(15)
IntrinsicMatrixRight=

(16)
左右径向畸变为:
RadialDistortionLeft=
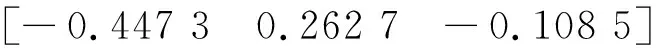
(17)
RadialDistortionRight=

(18)
左右切向畸变为:
旋转矩阵为:
RotationMatrix=

(21)
平移矩阵为:
TranslationMatrix=

(22)
2.2 云服务器搭建与软件版本
构建Linux发行版为Ubuntu 18.04的服务器环境,服务器硬件配置为CPU Intel Xeon Platinum 8255C、RAM 39 GB、GPU Nvidia GeForce RTX 2080Ti。
PyTorch版本1.10.1,CUDA版本11.1,Python版本3.8。
2.3 训练步骤
利用KITTI数据集训练。KITTI Object Detection Evaluation 2012数据集包含7 481张道路交通采集图像,将数据集划分为训练集70%、测试集30%。初始学习率为0.01,优化器使用SDG优化器,模型dual-YOLO在数据集进行30轮训练。最后得到dual-YOLO模型参数为7 101 704个,模型大小为27.09M。
3 结果分析
3.1 定性分析
对KITTI测试集进行试验,结果如图6所示,目标检测网络模型能够有效识别道路上的汽车、行人和骑行者,检测框可以包围目标位置,检测标签左侧为目标类别,右侧为置信度,即当前检测物体类别的可信程度,其值越大越好。在宽广马路、林荫路、步行街多种场景下,目标检测网络均可以正确识别到汽车、行人、骑行者,由图6右下角还可见,目标检测网络没有将停靠在路边的自行车误识别为骑行者。图7为未引入注意力机制的检测模型,同场景下,置信度较低,图中右侧一位骑行者被漏检。目标检测网络模型对双目摄像头采集的数据进行距离测算,当道路环境较好时,能够对自车道前方和临车道附近车辆测距,距离测算结果显示在左侧摄像头中(如图8所示)。
3.2 定量分析
由表2[17-19]可以看出,未引入注意力机制的模型命名为dual-YOLO-without模型,其虽然速率与dual-YOLO模型相当,但精度显著低于后者,其消融实验见表3。dual-YOLO算法:汽车和骑行者识别AP可达90%以上,行人识别AP可达80%以上。在骑行者和行人检测方面明显优于其他算法,检测速度能达到60 fps, dual-YOLO算法能更好地满足实时检测要求,同时保证不低的识别率。

图6 在KITTI测试集上的目标检测结果

图8 双目测距试验结果

表2 各算法在KITTI测试数据集AP的性能结果 %

表3 消融实验结果 %
4 结论
提出了一种基于卷积神经网络的目标检测算法,引入注意力机制,可对各类物体进行深度学习后检测。使用该算法对道路交通主要参与者(汽车、骑行者、行人)进行检测。结果表明:1) 汽车和骑行者识别AP可达90%以上,行人识别AP可达80%以上。2) 模型检测速率在60 fps左右,具有良好的实时性,配合双目摄像头,还可对目标进行距离测算,实用价值较高。3) 在复杂道路环境和较差光线环境下,检测正确率有小幅下降,距离测算准确性降幅较大,鲁棒性有待进一步提高。
