面向分布式卷积神经训练网络的FPGA加速器设计
2023-12-11张小军王俊英王晓静王正荣张德学
张小军, 王俊英, 王晓静, 韩 钦, 王正荣, 张德学
(1.山东科技大学电子信息工程学院,山东青岛 266590;2.高效能服务器和存储技术国家重点实验室,济南 250101)
0 引 言
近年来,卷积神经网络(Convolutional Neural Networks,CNN)已成功应用于目标检测、图像识别和自然语言处理等人工智能领域[1-2]。在神经网络开发的硬件平台中,FPGA相对于GPU和CPU具有更高的能效,与ASIC 相比可扩展性更好、开发周期更短[3]。故基于FPGA的加速平台成为一种极具潜力的计算方案[4]。尽管得益于近年集成电路工艺特征尺寸的减小,FPGA单片资源数增加明显,但仍旧难以满足搭建大规模CNN的需求。因此,采用多个FPGA可提高大规模神经网络模型的训练效率[5]。
与单FPGA 的硬件加速系统只考虑算法映射相比,多FPGA 的CNN 硬件加速由于包含算法拆分、算法映射与多FPGA 通信等机制,其实现复杂性大幅提高[6-7]。分布式加速分为数据并行和模型并行。其中数据并行在不同CNN 层中应用的配置不同,FPGA 需要在层间重新配置,以实现每一层的优化设计。为降低多FPGA加速器的实现复杂度,提高CNN的执行效率,众多国内外学者对其展开了研究。Zhang 等[8]提出一种深度流水线多FPGA设计,使总吞吐量最大化。Sharma等[9]基于Caffe 框架中的CNN规范,提出一种为多FPGA平台生成可合成加速器的技术。为减少片外访问,Alwani 等[10]改变计算模式,为计算多个卷积层提供了更好的缓存空间。Lian 等[11]利用软件控制执行并将计算密集型操作加载到硬件加速器,提出一种基于多FPGA数据并行方案,批量处理数据集,实现了深度神经网络(Deep Neural Networks,DNN)推理加速。以上工作主要探索了CNN 在多FPGA 平台上的推理加速,在多FPGA的存储和计算方面进行了研究。但基于多FPGA 的训练网络的相关工作较少。基于FPGA采用反向传播(Back Propagation,BP)算法训练CNN的过程中存在计算强度不平衡,导致整体性能降低。肖望勇[12]提出一种软件训练、硬件加速方案,通过改进手写数字识别架构算法,采用Python 训练CNN参数并通过高层综合语言设计基于FPGA的手写数字识别系统。Geng 等[13]优化可扩展框架,有效将CNN训练逻辑映射到多个FPGA。Jiang 等[14]提出一种新硬件和软件协同探索框架,用于高效神经架构搜索,缩短训练时间。神经网络的训练过程主要通过误差BP算法完成,反向训练运算处理单元与前向重合度较高,数据间存在高度的依赖性,针对CNN 架构,优化整体架构,调整计算时序,实现多FPGA分布式神经网络训练加速实验。主要工作如下:
(1)根据BP算法,完成CNN 训练。采用数据并行分布式模型,拆分图片训练集,进行并行训练,实现多FPGA分布式CNN的训练加速。
(2)根据各层数据的依赖性,改变矩阵内部卷积顺序,实现层内和层间的细粒度流水线设计,降低计算延迟。
(3)根据各层卷积核特点,提出一种数据拼接方案,根据需求选择不同的数据拼接方案,解决卷积运算造成的存储资源消耗过大。根据不同层数据分布特征,各层之间选用不同定点量化方案,进一步降低存储资源消耗。
(4)搭建多FPGA测试平台,采用QSFP光纤接口进行通信,优化Ring-Allreduce 数据传输方案,测试表明,多FPGA测试可得到近似线性加速比。
1 卷积神经网络算法
1.1 前向传播算法
为提取图片特征,卷积层中卷积核与输入矩阵做卷积运算,提取数据特征值。输入特征和权重经卷积得到输出特征。设卷积层输入尺寸为M×M,卷积核的尺寸为N×N,卷积步长为S,填充为P,可得多通道输出二维矩阵
池化层用于减少图片中特征数量,降低计算量,主要分为最大池化和平均池化,平均池化由于减少估计值方差,增大误差,更大限度地保留了图像的背景信息。平均池化后的图像信息。
式中:datai为池化层的输入矩阵元素;l×l为池化层的窗口元素尺寸。
全连接层对数据特征进行拼接计算,分类输出。输入矩阵由三维转化成二维矩阵,与多组单通道权重运算,得到多个神经元输出。CNN 中的激活函数改变架构内部线性运算特性,对输出进行判断,采用Sigmoid作为激活函数。
1.2 反向传播(BP)算法
BP算法称为误差反向传播,结合梯度下降完成对权重和偏置的更新,每层更新对应参数并通过误差损失函数传递到前层,达到训练效果。BP算法的本质为链式求导过程,前向推理运算完成后,进行BP 更新参数。CNN逐层传递,经过链式求导
通过损失函数的传递更新参数。最终通过链式法则实现整个架构反向流动。BP 由误差传递以及参数更新两部分组成。
2 硬件架构设计
采用细粒度流水线提高训练速度,实现高吞吐率。提出一种数据拼接读写方案减少存储资源消耗,优化激活函数及池化层硬件实现方案,减少计算资源的消耗,提高内部运算效率。分布式CNN 训练过程中多FPGA之间采用光模块互联,减少板间通信延迟。
2.1 整体架构
神经网络整体训练架构由片外存储CNN数据集,FPGA内部增加缓冲区,解决读取数据滞后,节省数据读取时间。缓冲区预存并加载数据集,初始化参数存储到内部存储器。如图1 所示,FPGA 内部CNN 架构由卷积层、池化层和全连接层构成,BP 更新权重和偏置,完成一轮训练。权重和偏置更新后进行新一轮迭代。多FPGA之间通过光纤通信完成板间传输,实现数据同步。训练完成后,输入测试集测试训练性能。

图1 多FPGA分布式结构
2.2 层内加速
卷积运算通过RAM 存储不同地址,实现矩阵像素位置的移动,经过乘加模块得到卷积结果。已知卷积核为N×N,输入为M×M,步长为S,池化层的核为l×l,步长为t,得到输出矩阵:
根据式(4)可得卷积计算预估时钟个数。后经过激活函数,写入RAM数据存储器。式(5)为卷积后的第1 个像素点所需clock个数,第1 个像素点进行卷积运算所需clock数可用式(6)表示,式(7)为其余像素点所需clock 个数,其余像素点进行卷积运算所需clock数可用式(8)表示。式(9)为池化之后第1 个像素点所需clock个数,式(10)为其余像素点所需clock数量,所有像素点卷积与池化后所需clock 个数可用式(11)表示。O1和O2分别为卷积和池化后像素点的大小。若未采用流水线设计,O1和O2的大小为卷积和池化后本层输出矩阵大小,细粒度流水线设计是从存储器中提前读取数据,改变像素点计算顺序,减小O1和O2,从而减小Xc。当O1和O2大小满足下一层卷积核大小时,进行下一层运算。如图2、3 所示,由后层卷积核大小决定L层卷积结果的运算顺序,在L层卷积未完成的情况下,满足L+1 层的像素点窗口条件后提前进行L+1 层运算。采用细粒度流水线方案,可缩短47.8%的运算时长。

图2 流水线加速

图3 卷积运算示意图
当前数据写入RAM,状态机判断读写地址关系,发送读使能信号,无须满足全部数据存入后的延时,即可进行下一步计算。根据以上2 种方式做细粒度流水完成各层运算。在保证频率相对较高的基础上,缩短了图片训练时长。
2.3 资源优化
存储器主要存储权重、偏置和每层输出数据做前向传播运算以及BP运算。设卷积核为N×N,卷积层硬件实现是将输入的数据和权重同时存储到N个RAM存储器,从N个RAM 中同时读取不同地址的N个数据进行卷积运算,分批次处理部分数据的乘加,经过N个时钟运算,得到输出矩阵的一个元素。通过设置存储基地址偏移量,实现卷积核在输入矩阵中的小窗口移位卷积计算,地址横向移动,依次处理每个卷积核运算。在数据读取过程中,满足不同地址数据的同时读写,并行输出N个数据做乘加运算,这种方案存储资源消耗过大,增加了(N-1)倍的片内资源。提出一种既节省存储资源又可在消耗较少的时钟下完成对整个矩阵的卷积计算方法。图4 是数据进行卷积的硬件结构。假设N=5,将5 个数据进行并行拼接且存储到RAM的一个地址中,此时RAM内部存储位宽是原来的5 倍,深度变成原来的1/5。RAM 采用双端口设计,根据卷积计算特点进行数据选择,每个时钟可以读出两组由5 个输入数据并行拼接的数据。令步长为1,可组合成(N+1)个数据卷积运算,每个clock 完成(N+1)个像素点的1/N部分计算,N个时钟就可完成(N+1)个像素点计算。以本文反向卷积运算、核为24 ×24 为例,输入矩阵尺寸为28 ×28,内部元素采用24 个数值拼接,存储到1 个地址中,RAM 采用双口读写,解决每个clock同时读取24 个数据以及所需卷积元素跨2 个地址卷积运算。

图4 卷积硬件结构
为节省硬件内部计算资源,平均池化采用移位运算实现。激活函数采用分段非线性拟合法[15]实现,增加移位运算以减少乘法器数量,降低由乘法运算带来的资源消耗。
2.4 Ring-Allreduce传输模式
基于多FPGA分布式CNN数据传输方案:
式(12)为板间数据传输所消耗的时间,由数据计算时间Tt1和数据输出串、并转换时间Tsp以及板间传输时间Ttran组成。式(13)~(15)为数据经过FPGA传输的数据累加。数据传输方式如图5(a)所示,经过完整的3 轮循环数据传输,根据式(13)~(15),数据从3 个FPGA内部传输,完成3 组数据累加,耗时6Ttran后,将一组数据传输到每个FPGA 内部,这种数据传输方式重复性高,耗时长。因此采用图5(b)方案传输数据。在FPGA3接收来自FPGA1和FPGA2的数据之后,结合FPGA3内部数据完成计算,分别传输到FPGA1和FPGA2,耗时3Ttran,循环一周完成数据累加,减少数据传输时间T,也减少了数据的传输量。

图5 Ring-Allreduce数据传输
3 性能测试
3.1 量化分析
为节省硬件资源消耗,减少逻辑运算,选用定点量化进行神经网络训练。量化方案
式中:QS为符号位;QI为整数位;QF为小数位。
在不同量化方案,对Mnist数据集训练性能统计,见表1。当选用QS为1、QI为1、QF为6,即Q(1,1,6)方案时,错误率高达91.08%。选用Q(1,5,10)方案,错误率为12.97%,与Q(1,10,21)方案2.75%的错误率相比仍差距过大,因此针对各梯度数据分布统计,设计一种位宽可变精度方案。统计表明,卷积层输出数据在0.1 ~1 之间,池化层数据分布主要集中在0.01 ~1 之间,卷积层4 的梯度数据分布主要集中在10-1~10-4之间,卷积层2 的梯度数据分布主要集中在10-2~10-5之间。预留乘加运算溢出位宽,量化方案为BP全连接层选用Q(1,5,10),卷积层分别选用Q(1,2,13)和Q(1,0,15)的数据精度,得到错误率为4.93%,与32 位宽相比,仅相差2%,因此选用16 位可变精度量化方案进行图片训练。

表1 训练识别效果
3.2 Ring-Allreduce数据传输
如图6 所示,分布式CNN 数据传输由3 个FPGA互联,并行训练多张图片。FPGA 之间依次传输每一层更新后的参数,根据图5(b)中的Ring-Allreduce 传输模式进行板间传输。采用QSFP 光纤接口传输数据,以减小数据传输延迟对训练速度的影响,板间添加异步FIFO解决数据不同步问题,最终实现板间高速通信。采用数据并行分布式训练,完成图片的训练,工作频率为154.54 MHz。由于多FPGA之间存在数据传输耗时,相较于单FPGA,2FPGA 和3FPGA 的加速比为1.99 和2.98。则:
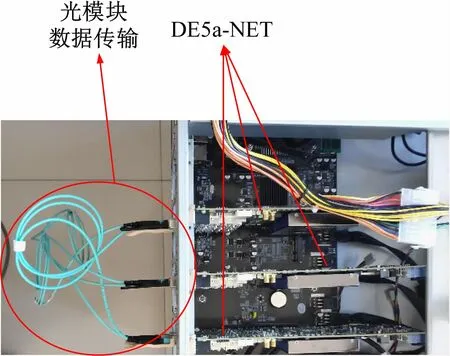
图6 多FPGA互联实验装置
式(17)为某一层乘法器的个数,式(18)为某一层加法器的个数,其中:O为对应层输出大小;Cin为输入通道;Cout为输出通道。计算整体架构包括BP 中的乘法器和加法器的总和近似得到整个训练架构的计算性能,并根据时钟频率得到整体性能。根据表2 的性能比对,单FPGA 选用16 位定点训练得到的吞吐量是CPU的4.3 倍,是在Altera Stratix V 平台下选用4 位定点数的3.25 倍,比在Xilinx KCU1500 平台下,借助自适应精度随机梯度下降(Stochastic Gradient Descent,SGD),采用软、硬件结合选用8 位定点位宽训练性能低,其影响因素包括除采用性能较好的开发平台外,选用了比16 位少一倍的位宽,但8 位定点位宽的吞吐量比3FPGA分布式并行训练选用16 位定点位宽得到的吞吐量低,整体性能也相对较好,且16 位定点位宽训练得到的正确率也会相对较高。
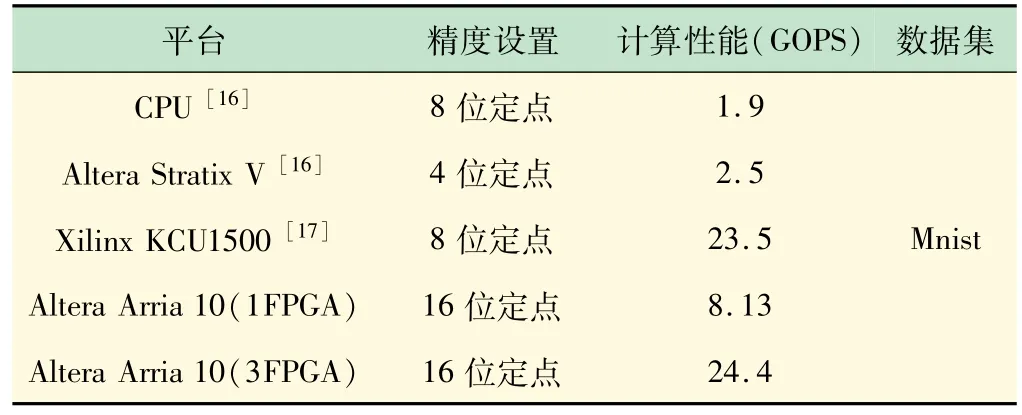
表2 性能对比
3.3 资源消耗
表3 为每个FPGA内部整体未优化和优化过后的资源占用对比情况。优化过后,以牺牲少量的ALM和DSP资源,减少了大量block memory存储资源。
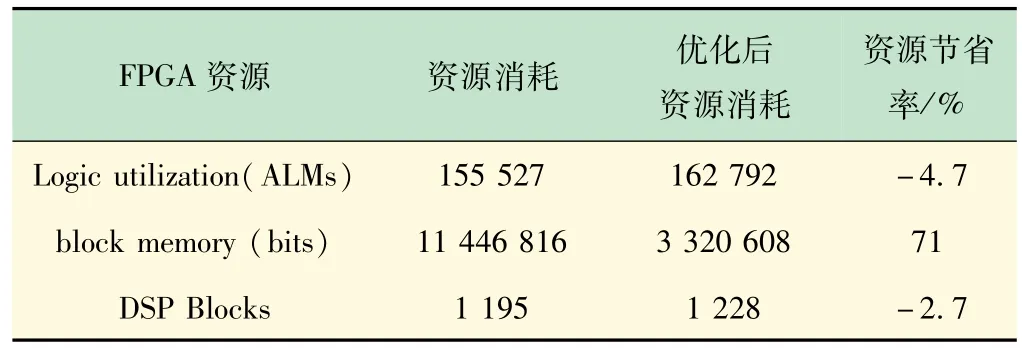
表3 资源消耗
4 结 语
本文设计了一种基于FPGA分布式神经网络训练加速器,实现了基于多FPGA 训练加速,完成资源优化,提高整体性能。采用数据并行训练,优化实现多通道并行计算,内部架构采用层内和层间细粒度流水线设计,缩短了训练时长,提高了整体效率。反向训练过程优化量化位数,在降低资源消耗的基础上,提升整体训练精度。优化Ring-Allreduce数据传输方案,提高了数据传输速率,实现了2FPGA为1.99,3FPGA为2.98的加速比。
