基于改进随机森林集成模型的疾病风险预测
2023-12-11吴佩珊李春玲杜宝林
李 丹, 卢 琰, 吴佩珊, 李春玲, 杜宝林,3
(1.广东省科技基础条件平台中心,广州 510006;2.广东省农业科学院动物卫生研究所,广州 510640;3.广东省计算技术应用研究所,广州 510033)
0 引 言
随着国民生活水平的提高,国内畜禽养殖业得到了快速发展,其总产值目前占农林牧渔业的30%以上[1],并朝着规模化、集约化以及智能化模式加速推进。在这种形势下,畜禽疫病防控问题愈加凸显,存在爆发风险大、人畜共患病危险高等,对产业的生产效益、产品出口以及公共卫生安全构成严重威胁[2-3]。
提高畜禽重大疫病诊断、防控与高效安全养殖综合技术水平对畜禽养殖业健康发展尤为重要。目前畜禽疾病的检测主要依靠兽医以及行业专家的巡视与诊断,存在诊断滞后、交叉感染等不足,无法开展高质量的群体化和个性化疾病防控管理工作[4]。
与此同时,随着计算机与人工智能技术的发展,畜禽疾病检测技术不断升级,研究人员通过运用关联、聚类以及分类等数据挖掘策略建立了各种有效的畜禽疾病风险预测模型,例如BP神经网络[5-6]、决策树[7]、支持向量机[8]、随机森林[9]以及深度学习[10]等。叶婵等[11]针对传统专家系统推理能力弱以及自学习能力差等,提出一种基于BP 神经网络算法的虾病害诊断以及防治专家系统。李尚汝等[12]利用机器学习算法建立奶牛疾病预测模型,并评估了人工神经网络(Artificial neural network,ANN)、决策树、逻辑回归等算法的性能,由实验结果可知,基于机器学习的预测模型在畜禽疾病风险预测应用中展现了极大的潜力。ANN虽然在BP神经网络的基础上有较大改进,并表现出较好的非线性映射能力以及自学习能力。但在实际工程应用中通常存在着训练数据缺失等情况,ANN模型中存在较多的隐节点,在函数逼近的过程中该模型容易出现过拟合等。随机森林算法对训练样本缺失数据的敏感度较低,并且能较好地处理非均衡数据,目前已被广泛应用于疾病预测研究[13]。Meng 等[14]设计了基于随机森林与XGBoost 算法的疾病预测模型,并对手足口病的发病率及其影响因素进行了分析和预测,取得了较好的预测性能。然而,当输入训练样本数据集过大时,基于随机森林算法的疾病预测模型容易出现过拟合现象,对疾病风险预测的性能产生较大影响。针对于此,Mohan等[15]提出一种混合随机森林与线性算法的预测模型,提高了疾病预测水平,准确率达到88.7%。针对XGBoost模型收敛速度慢等缺陷,张春富等[16]利用遗传算法(Genetic Algorithm,GA)优异的全局优化性能,设计了一种基于GA-XGBoost 算法的疾病预测模型,确保所设计算法在每一轮中的进化效果最优。因此,学习模型的集合方法比交叉验证测试确定的“单一最佳”模型能够获得更为准确的性能。
机器学习技术为畜禽疾病风险预警预测提供了有效的解决方案,由于畜禽疾病数据集的相关数据记录较少,增加了学习的复杂度[17-18];畜禽疾病数据集在类别中往往存在严重的分布不平衡,即绝大多数类别为正常案例,少数类别是患病案例,容易导致预测过拟合以及误导等情况。为此,研究人员引入随机过采样[19]、重采样[20]、动态采样[21]以及合成少数样本过采样[22]等方法。Chen等[23]针对不平衡数据的复杂特性,提出一种新的过采样技术,并获得较好的效果。陈旭等[24]针对不均衡医学数据疾病预测,设计了一种基于欠采样技术的集成分类模型,提高了疾病预测性能。如果样本是随机选取的,潜在的有用数据可能会被丢弃,Wang等[25]提出一种自步调学习的非平衡抽样方法,可有效地选择高质量样本,提高预测鲁棒性。
本文根据猪口蹄疫实验检测的临床指标,结合随机森林的特征选择优势和ANN的预测能力,设计了基于合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMTOE)算法的混合随机森林(Random forest,RF)与ANN 的集成预测模型(SMOTE-Hybrid Random Forest-Artificial Neural Network,SMOTE-HRF-ANN);采用合成少数样本过采样技术算法SMTOE对非均衡训练数据集的少数样本进行线性插值以生成新的训练样本,实现对数据集的均衡化处理;通过使用随机森林算法对人工神经网络的输入属性进行优化,对相关特征进行优化选择,能有效避免特征过多导致过拟合现象,提高畜禽疾病预测模型的预测精准度。
1 基于集成模型的疾病风险预测
1.1 SMOTE算法
在畜禽养殖领域由于疾病的发病率存在差异,容易导致畜禽疾病样本数据样本量小、不均衡等,样本(即非患者病例样本)往往在数据集中占比较高,不利于畜禽疾病预测模型的训练。本研究采用SMOTE 算法对训练数据集进行插值处理[23]:
式中:rand(0,1)为区间(0,1)内的随机数;Dmin为少数类数据;Πi为距离样本Dmin的v个最近邻样本中的第i个数据。
1.2 随机森林算法
随机森林模型是一类由多决策树组成的自举聚类(Bagging)方法,通过节点随机分裂以及随机重采样构建多棵决策树,采用投票的方式获得模型的预测结果[14]。
本研究采用随机森林通过分类回归树生成的决策树的策略进行学习。随机森林在训练集总样本中随机又放回地抽取n个子样本;将每一个单独抽取的子样本对单棵决策树进行循环处理,构建由n个决策树所组成的决策“森林”,具体步骤如下:
步骤1 预设初始参数。设置n棵决策树以及决策树节点的阈值。
步骤2 获取数据子集。在预设参数的基础上,以随机森林理论思想,根据自主抽样法从疾病原始数据集D中有放回地随机抽取n个独立的训练子集D={D1,D2,…,Dn},在此抽样过程中,独立抽样n次,每个子样本没有被抽取的概率
步骤3 随机选取节点特征指标。根据所获取的数据子集建立个体决策树,计算每个节点特征指标的纯度以获得Gini 指数[14](采用Gini 值作为纯度标准来分割节点)
式中,pn为从当前的样本空间中各取值的概率。
步骤4 确定分裂节点。在获得Gini 值的基础上,对Gini指数最大的节点进行分裂,同时重新计算Gini指数;通过循环步骤使得对应指数小于初始设置的阈值,生成目标的决策“森林”。
步骤5 递归分类。基于上述步骤,对生成的决策树分类结果进行反馈,根据票数最多的原则选择指标变量的最佳线性分解的方法,实现对疾病风险指标特征的排序。其中,RF模型生成流程如图1 所示。
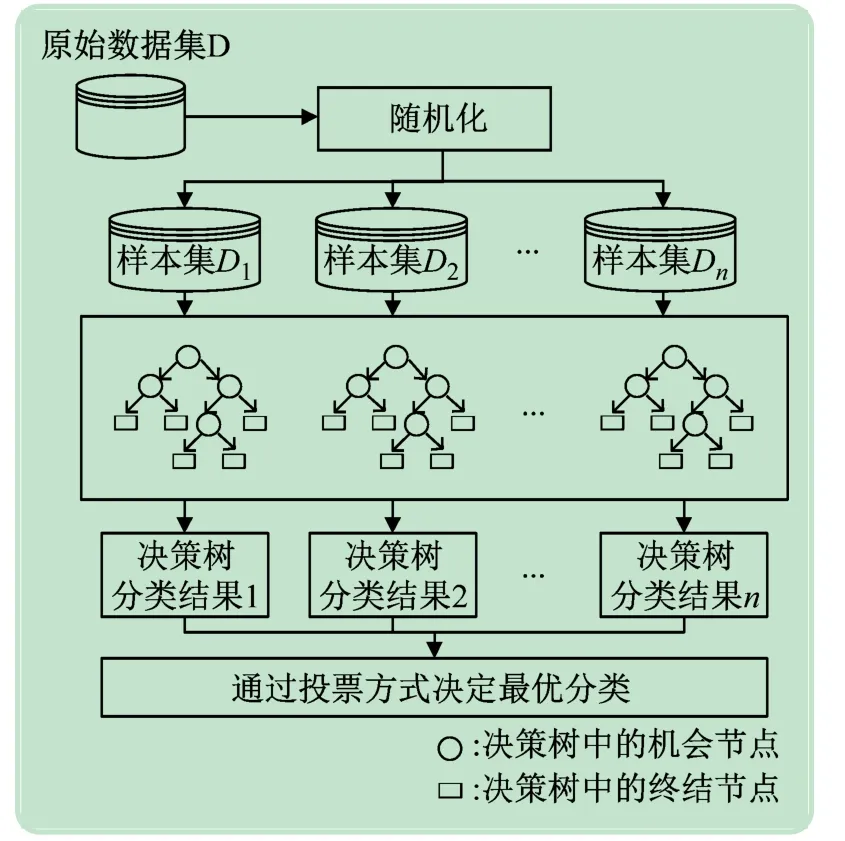
图1 RF模型生成流程
综上,随机森林模型能通过构建多个决策树的方法获得准确的预测结果,并对样本缺失数据的敏感度较小;当输入的训练样本数据集过大时,训练模型容易出现过拟合现象,对疾病风险预测的性能产生较大影响。
1.3 人工神经网络算法
ANN主要由输入层、隐藏层以及输出层组成。网络中的隐藏层包含若干神经元,且各神经元间通过带可变权重的有向弧进行连接;该模型能通过对已知样本信息进行学习训练,达到处理大量信息的目的[12]。ANN结构如图2 所示。

图2 人工神经网络结构图
1.4 集成预测模型
在畜禽疾病预警预测领域,动物疾病样本存在数据集中以及数据不均衡等,这对疾病风险预测模型的训练产生巨大的挑战,容易出现模型过拟合,降低模型预测的可靠性。
考虑到ANN具备优异的非线性匹配以及泛化能力。本研究结合随机森林在特征选择中的优势以及ANN在预测中的能力,提出一种基于SMTOE 算法的混合随机森林与ANN 集成预测模型SMOTE-HRFANN。将经SMOTE算法处理过的数据输入随机森林模型进行训练;通过计算其特征属性的Gini 指数,排除Gini指数最高的特征;对随机森林模型进行新一轮的训练以得到新的Gini指数排名;通过重复上一步骤直到每一个特征的Gini 指数都保持在预设的阈值范围内。将随机森林模型优选后的特征输入ANN 进行预测处理,以获得精确度较高的疾病风险预测值。其算法流程如图3 所示。

图3 SMOTE-HRF-ANN算法流程
SMOTE-HRF-ANN算法步骤如下:
步骤1 输入目标疾病样本数据集D。
步骤2 预设数据集非均衡尺度Ω0=1,其中多数类样本数据设为Dmax,少数类样本数据设为Dmin。
步骤3 判断Dmax与Dmin数据集的大小。如果Dmax>Dmin,则进行步骤4,否则进行步骤5。
步骤4 对少数类数据集Dmin使用SMOTE 算法处理,以增加其样本数量,得到数据集Domin。
步骤5 合并数据集Dmax与Domin得到数据集D0。
步骤6 计算非均衡尺度Ω =Dmax/Domin,判断Ω与Ω0是否相等,如果Ω≠Ω0则返回步骤3,否则进行步骤7。
步骤7 输入数据集D0。将获得均衡的数据集D0使用所提出的算法对疾病风险进行预测研究,得到疾病诊断结果。
2 实验分析
2.1 数据准备
为研究面向非平衡数据集的疾病风险预测模型的性能,分别对2 种特征不同的疾病数据集进行对比,实验数据集分别来自于:
(1)Kaggle平台提供的UCI 心脏病数据集,有效患者数据为303 例,其中,非患者样本164 例、患者样本139 例。常见的13 个心脏病主要属性见表1。其中,Num属性表示患者诊断结果,用以分类样本。

表1 UCI心脏病数据集特征信息表
(2)猪口蹄疫疾病数据集来源于某省农业科学院动物卫生研究所的实验室送样样本的检测数据,总计检测数据244 条;该数据集特征信息包含年龄、猪类型、血清试验结果、养殖环境温度、养殖环境湿度、是否出现水泡和蹄壳是否脱落等特征数据。
2.2 模型评价
为验证疾病预测模型在非平衡数据集中的性能,采用ROC 曲线(Receiver Operating Characteristic,ROC)对预测模型的性能进行评价与对比,具体指标选择了精确率、F1-Score 值和召回率。其中,定义TP、FP分别为实例为正类的正确预测数与错误预测数,TN、FN分别为实例为负类的正确预测数与错误预测数。则精确率(Precision)
召回率(Recall)
2.3 实验与分析
为验证SOMTE-HRF-ANN 算法面向非均衡训练数据集的疾病预测性能,将算法与RF[14]、XGBoot[16]、SOMTE-RF以及SOMTE-XGBoot 等算法进行对比,实验结果见表2、3,不同算法在UCI数据集中的ROC 变化如图4 所示,不同算法在猪口蹄疫数据集中的ROC变化如图5 所示,图中,area为曲线下面积。

表3 在UCI数据集中各模型对比评价指标结果(患病病例)

图4 在UCI数据集中不同算法的ROC变化
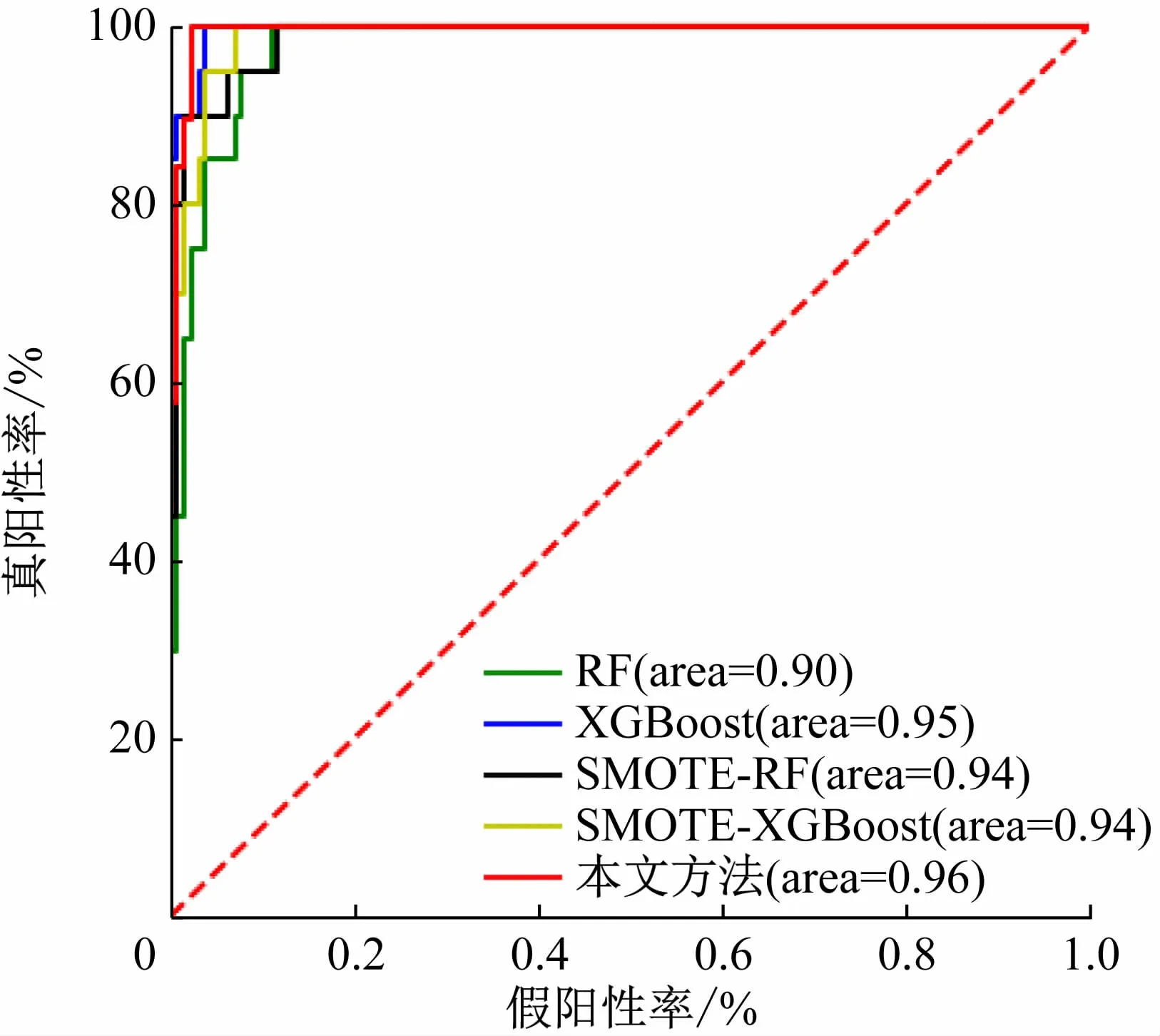
图5 在猪口蹄疫数据集中不同算法的ROC变化
由图4 可知,使用合成少数样本过采样技术SMOTE对数据集进行处理后的模型分类性能有了一定程度的提升。随机森林模型与XGBoot模型的Area值分别提高了1%和4%;在同等的情况下,SOMTEHRF-ANN预测模型的Area 值要高于其他的模型,最大提升了9%,验证了所提方法的有效性以及优越性。
由图5 可知,在猪口蹄疫数据集中,所设计模型的ROC曲线的Area 值达到了96%,获得了较好的预测性能。与此同时,由表2、3 可知,在UCI 数据集中,所设计的SMOTE-HRF-ANN 算法在少数类样本中的精确率和F1-score值分别达到96%和85%,该算法在两个指标下都取得了较高值。由此表明,所设计方法相较于其他预测模型能有效地提高对非平衡样本数据的疾病风险预测性能,为实现畜禽疾病风险预警预测的业务化运行进行了积极的尝试。
综上所述,通过SMOTE 算法对训练样本数据进行处理,能有效增强预测模型在面对非均衡训练样本数据时对少数类样本的识别能力。
3 结 语
在畜禽养殖领域中由于疾病的发病率存在差异,导致畜禽疾病样本数据样本量小、不均衡,为避免畜禽疫病风险预测模型过拟合,利用SMOTE 算法对训练数据集进行均衡处理,并结合随机森林和ANN 的特点,通过集成方法构建混合集成预测模型SMOTEHRF-ANN。实验结果表明:SMOTE-HRF-ANN 畜禽疾病风险预警预测模型相较于随机森林、XGBoost 等算法优势如下:
(1)利用少数样本合成过采样技术SMOTE 构建平衡训练数据集,避免预测模型过拟合。
(2)使用ANN 对经过随机森林算法优选后的特征进行学习训练,避免特征冗余导致的预测精确度下降。
(3)SMOTE-HRF-ANN预测技术在实验过程中多指标的平均水平上表现更优,为实现畜禽疾病风险预测业务化运行进行了积极的尝试。下一步研究将重点考虑多标签预测场景和小样本预测研究,更加智能地实现疾病诊断。
