引入跨批存储机制度量学习的人脸活体检测
2023-12-11蔡体健刘文鑫尘福春罗词勇
蔡体健,刘文鑫,尘福春,陈 均,罗词勇
华东交通大学 信息工程学院,南昌 330013
人脸识别系统在金融、门禁、移动设备等生活场景中得到了广泛的应用。然而,却存在伪造人脸攻击的风险,例如非法用户可能通过打印照片[1]、数字图像视频[2](即重放攻击)和3D 面具[3]等手段欺骗人脸识别系统。为了提高人脸识别系统的安全性,需要开展人脸反欺诈(face anti-spoofing,FAS)技术的研究。
人脸反欺诈技术就是检测输入样本是活体人脸还是欺诈人脸,在计算机视觉领域中它是一个二分类或多分类问题,而解决这个问题的方式又分为基于传统机器学习的方法和基于深度学习的方法。
传统机器学习方法常在提取人脸图像中的纹理特征或者色调、饱和度和明度颜色空间(hue,saturation,value,HSV)等手工设计特征后,再利用支持向量机等分类器进行分类。手工制作的特征是专门为某种特定类型的欺诈而设计的,很容易受到环境条件,如相机设备、照明条件和演示攻击仪器(presentation attack instruments,PAIs)的影响,这使得传统方法人脸活体检测效果往往不是很好。
随着深度学习技术的发展,以及大规模数据集的发布,研究人员提出了多种基于二分类的深度FAS网络结构来判别人脸真假。如Yang等人[4]提出了第一种使用8层浅CNN 进行特征表示的深度FAS 方法。Chen等人[5]对预训练的VGG16进行微调用于FAS。文献[6]使用光流和卷积神经网络提取具有判别性的图像特征。Yu等人[7]提出了一种中心差分卷积网络(central difference convolution network,CDCN),能够通过聚集强度和梯度信息来捕获人脸图像的固有细节信息。然而由于欺诈样本的多样性影响了有效的决策边界建模,这些方法虽然在数据集内测试中表现良好,但容易过拟合,泛化性差,不能很好地推广到新的攻击类型。为了减轻欺诈多样性对决策边界建模的影响,很多研究者又开始从异常检测的角度研究人脸反欺诈问题。异常检测是从一组正常数据中识别异常样本的任务,假设正常样本属于封闭集,不同类型欺诈样本都属于封闭集的离群点,属于开放集。基于这种假设,多数异常检测的方法通过深度度量学习的方式训练一个分类器来准确聚类。然后,将正常样本簇边缘以外的任何样本(如未知攻击)都被检测为异常样本。如Schroff 等人[8]提出用一种基于深度度量学习的超球损失(hypersphere loss)来监督深度FAS 模型,以保持活样本的类内紧凑性,同时保持活体样本和欺骗样本之间的类间分离。最后在学习到的特征空间上直接检测未知攻击,不需要额外的分类器。Pérez-Cabo等人[9]从异常检测的角度对FAS问题进行了改造,提出了一种三重聚焦损失(triplet focal loss)的深度度量学习模型,它将三元组损失和焦点损失结合起来,利用度量学习使样本特征在类内紧凑,类间分散。Feng 等人[10]设计了一种只对正样本进行显示监督的回归损失模型,来生成欺诈线索,并且依据欺诈线索分数对样本进行分类,在跨数据集上取得了很好的结果。
异常检测的FAS方式,被证明了能够提高模型的泛化能力,这些方式多是基于度量学习来实现的,而基于度量学习方法的性能很大程度上依赖于它们挖掘困难样本[11]的能力,即提取特征信息的能力。尽管开发了各种复杂的抽样方案,如batch-all[11]、batch-hard[12],但难样本挖掘能力本质上还是受到了batchsize的限制,使得提取出困难样本受到限制,网络学习不到好的特征进行分类,从而导致精确度和泛化能力变差。
针对上述问题,本文提出了一种结合度量学习与跨批存储机制的人脸活体检测算法,改进基于异常检测的FAS 模型,使得网络能获得更多的困难样本对,提取出更具区分性的微特征,提高FAS的精度和泛化能力。
1 本文方法
整体网络结构如图1所示,由欺诈线索生成器和一个辅助分类器组成。欺诈线索生成器采用U-Net 架构来生成欺诈线索映射图,并通过异常检测的方式最小化活体样本的欺诈特征来学习欺诈线索。辅助分类器可以放大欺诈特征,来学习更具有分辨性的欺诈线索。同时本文在欺诈线索生成器中引入多尺度度量学习技术,并结合跨批存储机制来改进样本挖掘策略,以提取更多的困难样本对,增加类内相似度并加大类间的距离,以学习出更清晰的分类边界。
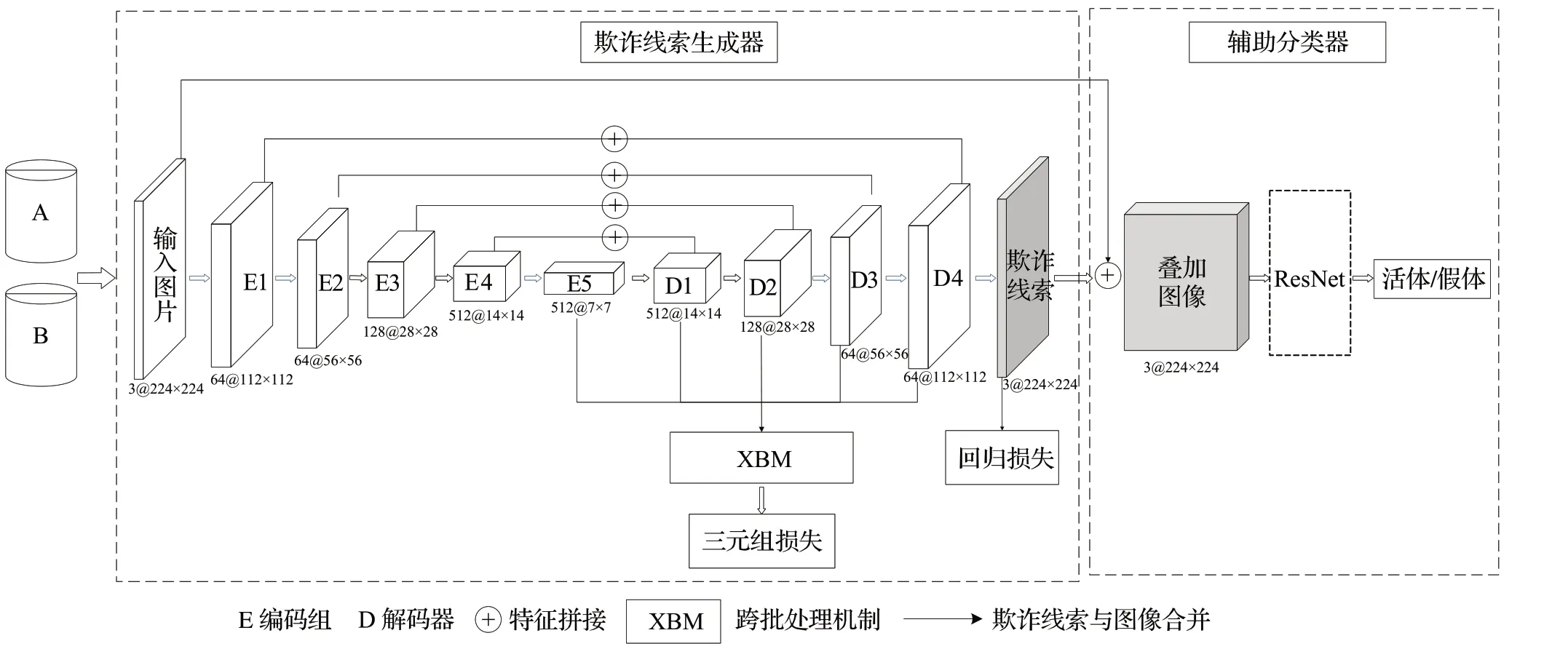
图1 本文网络结构Fig.1 Network structure
1.1 欺诈线索生成器
该模块采用U-Net架构,在多个尺度上建立从编码器到解码器的跳跃连接,以生成欺诈特征。具体做法是:使用在ImageNet[13]上预训练的ResNet18[14]作为编码器E,其中包含5个编码器残块;而解码器D由4个解码器残块组成,在E 后面对信息进行解码,生成欺诈特征。在每个解码器残块中,前一层的特征图通过最近邻插值进行上采样,然后通过连接操作,将编码器中对称位置到解码器的特征映射集合起来,然后输入到解码器残块中。在解码器最后的一个残块连着一个Tanh激活层来产生欺诈特征。
由于活体样本不具有任何欺诈材质构成,所以活体样本的欺诈特征应为0,而不同材质的欺诈样本应具有不同的欺诈特征,称之为欺诈线索。因此本文采用异常检测的方式:只对活体样本进行监督来学习欺诈线索,而对欺诈样本的欺诈线索不施加约束,这样可以学习到更多样的欺诈类型,能将模型推广应用到未知的欺诈攻击检测。
具体算法如下:假设给定RGB输入图像I,欺诈线索生成器输出相同大小的欺诈线索映射图C。活体样本的欺诈线索映射C是全0的特征图;而欺诈样本的C是未知的。欺诈线索生成器的目标函数是像素级的L1回归损失,其表达式为:
式中,Nl是活体样本的数量,此目标函数只约束活体样本的训练,促使活体样本的欺诈线索最小化,但并没有约束欺诈样本,这样可保证欺诈形式的多样性。
1.2 辅助分类器
本文使用辅助分类器作为欺诈线索的放大器,有助于学习更具有分辨性的欺诈线索。欺诈线索生成后,将生成的欺诈线索映射C添加到输入图像I中,形成叠加图像S。以S作为辅助分类器的输入,使用ResNet18网络提取图像特征,并利用二元交叉熵损失对网络进行优化,其表达式为:
式中,N为样本个数,zi为活体或者欺诈样本的标签,qi为网络输出的分类概率。
1.3 结合跨批存储机制的度量学习
1.3.1 多尺度三元组损失
为了获得更清晰的分类边界,本文在欺诈线索生成器中引入多尺度度量学习技术。首先提取E5 层至D4层共5 层的多尺度特征,使用全局平均池化(global average pooling,GAP)将他们向量化,得到一组特征向量{V},然后计算多尺度特征向量的三元组损失,其目标是促使锚样本和正样本之间的距离尽量小,而锚样本与负样本之间的距离尽量大。三元组损失函数的表达式如下:
式中,T是样本对个数,ai代表锚样本,pi代表正样本,ni代表负样本,m是预定义的边界常数,d(i,j)表示两个归一化特征向量之间的欧几里德距离,其表达式如下
度量学习技术在很大程度上依赖于样本挖掘策略。目前常用的在线三元组挖掘(online triplet mining)[11]是在一小批样本(batch-size)中,选择有效的三元组样本,即满足d(ra,rn)<m+d(ra,rp)要求的难样本或半难样本对(以下统称为困难样本对),去除了简单样本,也就是那些远离锚样本的负样本,以及与锚样本过近的正样本,它们对模型的训练并不会有什么贡献。在线三元组挖掘又有两种处理策略:batch-all[11]和batch-hard[12]。batch-all 是选择所有有效的三元组,然后计算目标函数的平均损失;batch-hard是对于每个锚样本,选择最难的正样本和负样本构成三元组,使用此策略可以得到与batch-size 相同数量的三元组对。不管是batch-all 还是batch-hard 策略,都只是在一小批样本(batch)中选择难样本,难样本挖掘受到了batch-size的限制,所生成的样本只是在一小批样本中的难样本,而不是整个数据集的难样本。一个简单的处理方法是增大batch 的大小[11],在更大的范围寻找难样本,但batch的增大,意味着计算量的增加。那么如何在不增加计算量的基础上,扩大难样本的寻找范围?为此,本文在多尺度度量学习中引入了跨批存储机制(cross-batch memory(XBM))[15]的样本挖掘策略。
1.3.2 跨批存储器(XBM)机制
跨批存储器(XBM)机制可用来存储前期迭代的特征向量,允许模型在多个批数据中甚至整个数据集上收集足够的难样本对,来提高度量学习的性能。XBM 算法并不是在模型训练初期即使用的,而是要在特征向量出现“慢偏移”现象时,才可以引入XBM机制。
(1)“慢偏移”现象
在度量学习中,前期的小批量特征向量通常被认为是过时的,因为模型参数在整个训练过程中不断优化[16-18],这些过时的特征总是被丢弃。但实际上特征向量的更新有时存在“慢偏移”现象,也就是同一实例在不同的训练迭代中所生成的特征差异较小。为了量化“慢偏移”现象,本文将步长Δt迭代时,输入样本x的特征偏移量定义为:
式中,f(x;θt)是样本x在t时刻提取的特征,θ是模型参数。
为了描述“慢偏移”现象,下面本文将网络训练过程中的特征向量,按照公式(5)计算出随着迭代次数的增加时的偏移量,结果如图2 所示,其中图2(a)是随着迭代次数增加的特征向量;而图2(b)是随着迭代次数增加的偏移量。由图可知,在迭代前期,特征向量的变化还是比较大的;但大约在2 500次迭代后,特征向量变得相对稳定,特征偏移量变小,出现了“慢偏移”现象。当特征向量出现“慢偏移”现象时,意味着前期训练的特征向量与当前的特征向量之间只存在微小的差异,这时可以将前期训练的特征暂时存储并利用起来,用于辅助当前的网络训练,这样可以扩大难样本的挖掘范围,同时不需要任何额外的计算,只是需要增加少量额外的存储空间。

图2 随着网络训练迭代次数变化的特征偏移量Fig.2 Characteristic offset varies with number of network training iterations
(2)跨批存储机制算法
当特征向量出现“慢偏移”现象(本模型是在迭代次数达到2 500)时,可以将XBM 嵌入度量学习中。为了使用XBM机制,首先需要在内存中建一些队列Mi,其中i∈{E5,D1,D2,D3,D4},被初始化为第j个样本的第i个解码器输出的特征向量,表示第j个样本的标签,q为队列长度,通常为batch-size 的倍数,并且把存储比定义为Rn=q/n,队列长度q与训练集样本总数n之比。图3展示了XBM机制的工作流程,其主要工作是维护和更新内存中的队列:在每次迭代中,首先将当前批的特征向量v和标签y进入队列M,并将最早的批特征向量和标签退出队列,始终保持队列的长度为q。

图3 跨批存储机制Fig.3 Cross-batch storage mechanism
添加了XBM机制的度量学习过程如算法1所示:
算法1XBM跨批存储机制
在算法中,整个模型训练分成两个阶段:前期迭代训练和后期迭代训练。前期迭代训练采用一般三元组的batch-all[12]样本挖掘策略,前期迭代训练k次,特征向量出现“慢偏移”现象后,进入后期迭代训练,此时采用XBM的难样本挖掘策略。
后期迭代训练过程中,首先对内存中的队列M进行初始化,然后计算当前批的特征向量,并进行队列更新,即将当前批进入队列,最早批移出队列,接着在整个队列M中挖掘三元组困难样本对,计算样本之间的相似度,最后利用三元组损失对网络进行优化。
由于队列长度一般是远大于batch-size,因此XBM策略比batch-all策略扩展了难样本的挖掘范围,可以得到更好的性能;此外,由于是直接将当前批特征向量放入内存模块,因此没有任何额外的计算。并且因为存储特征向量特征所需的内存非常有限,所以整个训练集都可以缓存到该内存模块中,可以保证模型能够搜集到足够的有效样本对。在前期迭代中,模型采用公式(3)作为目标函数来训练网络;进入后期迭代,使用XBM难样本挖掘策略时,则采用以下目标函数来训练网络:
式中,pxbm和nxbm是在整个内存存储队列中挖掘出的有效正样本和负样本。
1.4 总体损失和测试策略
该模型的损失函数分为三个部分:活体样本欺诈线索的像素级回归损失Lr,所有训练样本上的三元组损失Lt或Lt_xbm和辅助二值分类损失La。将这些损失综合起来,得出在训练期间的总损失L:
式中,k表示应用三元组损失惩罚的层,a1、a2、a3是平衡不同损失分量影响的权重。
在测试阶段,本文使用生成的欺诈线索映射C而不是分类器的输出来进行欺诈检测。理想情况下,活体样本具有全0的欺诈线索映射,而不同类型的欺诈样本具有不同的欺诈线索映射。本文可将欺诈得分定义为样本欺诈映射图C的均值,则测试样本的欺诈得分为:
2 实验与分析
2.1 数据集
为了验证提出方法的有效性,本文分别在OULUNPU[19]、CASIA-FASD[20]、Replay-Attack[21]数据集上进行了测试。
OULU-NPU 可以较好地模拟真实场景,它由4 950个真实和攻击视频组成。视频是在不同的背景以及光照情况下收集,并采用6个不同的手机进行录制。攻击类型划分为4种,分别为两种打印攻击和两种视频重放攻击。在上面的基础上,数据集划分了4 种协议,用来测试算法针对不同场景的有效性。协议1 是为了评估模型在不同背景和光照下的泛化能力,协议2是为了评估模型对于不同的攻击媒介的泛化能力,协议3是为了评估模型对于不同的拍摄设备的泛化能力,协议4则是对上面3 种场景的汇总,即评估模型在不同环境,攻击媒介,拍摄设备下的泛化能力。
CASIAMFSD 包含50 个不同主题的600 个视频片段。这些视频被分为150个活体访问视频和450个欺骗攻击视频。欺骗人脸由真实人脸的高质量记录制成,扭曲照片攻击、剪切照片攻击和视频重放攻击是数据集中的3种欺骗攻击。
Replay Attack 包含了来自50 个受试者的1 300 个视频。这些视频是在不同环境条件下收集的,分为训练集、开发集和测试集,分别有15个、15个和20个主题
2.2 实验设置
在实验中,首先将所有RGB 人脸图像裁剪为224×224×3,然后随机选择训练数据,以保持正负样本比率为1∶1。Batch size 设置为32,存储比Rn设置为0.2,初始学习率为1E-3,选择Adam[22]作为优化器。在欺诈线索生成器中,使用Tanh作为激活函数,将三元组损失中边界常量m设为0.5,同时在训练的迭代次数达到2 500次时,引入跨批存储机制来进行难样本挖掘,以保证提取更有效的样本对。
在损失函数权重值方面,将a1,a2,a3设为5,1 和5,公式(8)中的评分阈值是通过开发集实验设置的。实验的硬件环境为NVDIA GeForce RTX 2080Ti 显卡,编程语言为Python3.7,框架采用Pytorch。
性能评价指标方面,在数据集内部实验中使用了平均分类错误率(average classification error rate,ACER),它是假体人脸分类错误率(attack presentation classifi cation error rate,APCER)和活体人脸分类错误率(bona fide presentation classification error rate,BPCER)的均值。在跨数据集实验中,本文使用了半总错误率(half total error rate,HTER),它是错误拒绝率(false rejection rate,FRR)和错误接受率(false acceptance rate,FAR)的平均值。
2.3 实验结果与分析
2.3.1 数据集内部测试
本文在OULU-NPU数据集上进行了数据集内部测试。表1 是在OULU-NPU 数据集4 种协议上的实验结果,是本文算法与其他的算法包括STASN[23]、CILF[24]、BCN[25]、CDCN-PS[26]、DC-CDN[7]、Spoof Trace[27]和LGSC[10]的实验比较。由表可知,在协议1 下,本文算法可以获得最好的APCER、BPCER、ACER 指标,而在其他3 个协议下,本文算法也可以获得综合最好的指标,例如表中DC-CDN 算法虽然采用中央差分卷积来提高特征信息丰富度,但最后只使二元交叉熵损失对网络进行优化,而本文算法用三元组损失结合二元交叉熵进行辅助监督能比DC-CDN 获得更好的分类边界。同时相比较于LGSC 算法使用单一的三元组损失,即只用一般的batch-all策略在一个小批内获得有效的样本对用于网络学习,而本文结合三元组损失以及跨批存储机制在多个批次内获得更多的有效的三元组样本对,来提取信息更丰富的特征进行网络学习,从而获得更优的结果。

表1 在OULU-NPU数据集上进行测试Table 1 Testing on OULU-NPU dataset 单位:%
2.3.2 跨数据集测试
为了验证模型的泛化能力,本文进行了跨数据集测试实验,即在一个数据集上训练,然后在另一个数据集上测试。不同数据集之间由于背景、光照、攻击类型等因素影响,数据分布差异很大,这使得跨数据集的模型评估具有挑战性。本文在CASIA-MFSD 和Replay-Attack 数据集进行了交叉测试,以评估模型的泛化能力。表2 是跨数据集上测试得到的HTER 指标,是本文算法与其他的FAS算法包括CNN[4]、Patch CNN[28]、Color Texture[29]、STASN[21]、DENet[30]、Disentangled[31]和LGSC[10]的实验比较。由表可知,与当前的算法比较,本文算法可以取得较好的HTER结果,具有较明显的优势。如相较于表中算法Patch CNN 也使用了基于度量学习的三元组损失进行辅助监督,但最后还是利用二元交叉熵进行分类,即将所有不同欺诈类型的样本归为一类,这样会模糊各种欺诈人脸的欺诈特征。而本文除了结合三元组损失与跨批存储机制作为辅助监督外,还利用只对活体样本进行像素级回归损失作为监督,这样可以加深真假样本之间,以及不同欺诈样本之间的特征差异。并最后利用欺诈线索的均值进行分类,提高泛化能力。

表2 跨数据集上测试得到的HTER指标Table 2 HTER indicators from tests across datasets单位:%
2.3.3 消融实验及分类比较
(1)消融实验
本文在OULU协议1数据集上进行了消融实验,来验证在本模型中各个组件对整个模型的影响。本文将相应的模块定义为“TripletLoss”“XBM”“AC”分别表示三元组损失、跨批存储机制、辅助监督,“√”表示在模型中使用该技术模块。消融实验如表3所示。由表可知,去掉跨批存储机制集成的三元组损失模块,导致ACER分别上升3.4个百分点;只去掉跨批存储机制后,ACER上升了1.1个百分点,去掉辅助分类器后,ACER上升了1.2 个百分点。相比于其他模块,跨批存储机制集成的三元组损失对结果的影响更大。
(2)分类比较
本文分别在跨数据集上使用样本欺诈线索的值进行分类,以及使用辅助分类器的二元交叉熵进行分类,来说明哪种分类效果更好。如表4所示,相比较于辅助分类器,使用欺诈线索的值在Repay-Attacks 数据集上进行分类HTER 下降了0.6 个百分点,同样在CASIAMFSD 上HTER 下降了2.8 个百分点,这说明了直接使用欺诈线索进行分类,能提高模型的泛化能力。
2.4 特征可视化
2.4.1 欺诈线索可视化
为了更直观地理解欺诈线索,本文对欺诈线索的空间分布进行了可视化展示。具体做法是:首先从OULU测试数据集挑选样本生成欺诈线索,然后将欺诈线索特征图的三个通道分别求平均值,作为样本在轴上的坐标,并用○表示活体样本,△表示打印攻击样本,s表示视频重放攻击样本,三类样本的欺诈线索分布如图4所示。从图4 可以观察到活体样本(正常样本)属于封闭集,而欺诈样本(异常样本)属于封闭集的离群点。图5是OULU 数据集中各类样本及对应生成的欺诈线索映射图。由图5可以看到,活体样本的欺诈线索映射图像素值几乎为0,与欺诈样本的欺诈线索映射图具有明显的差异,这些差异的产生可能和欺诈样本的颜色失真、云纹图案或材质有关。

图4 欺诈线索在特征空间中的分布Fig.4 Distribution of SpoofCues in feature space

图5 不同类型样本及对应生成的欺诈线索映射图Fig.5 Different types of samples and corresponding generated spoof cue maps
2.4.2 跨批存储机制的比较
(1)可视化比较
本文对去除或添加跨批存储模块的两种情况下,所获得的嵌入D4 层的特征进行可视化比较,来进一步展示跨批存储机制对FAS 性能的影响。具体做法是首先获取OULU 测试集在D4 层的特征,然后使用T-SNE 技术[32]将数据降维,最后在二维平面上展示,效果如图6所示。图中每个红色○点代表一个活体样本,每个黑色□点代表一个欺诈样本。图6(a)是去掉了跨批存储机制的特征分布;而图6(b)则是增加了跨批存储机制的特征分布。明显地图6(b)比图6(a)具有较清晰的分类边界,这证明了跨批存储机制可以通过提取更多有效的样本对来提高模型的性能。

图6 D4层特征的T-SNE可视化Fig.6 T-SNE visualization of D4 layer features
(2)与其他样本挖掘算法比较
在本文网络结构中,分别将样本挖掘策略设置为跨批存储机制(XBM),以及其他通用的在线三元组挖掘策略:batch-all、batch-hard,来对比不同样本挖掘策略对网络性能的影响。表5 展示了是由不同的样本挖掘策略组成的网络结构在OULU数据集上进行测试的结果,以及在训练过程中一个迭代次数内所能挖掘出的最大样本对数,其中n表示一个batch 的大小,q表示XBM队列的长度,一般为n的整数倍。如表所示,使用跨批存储机制的网络结构与使用batch-all 在OULU 数据集上的APCER 值相比,该方法的APCER值减少了1.1个百分点;与使用batch-hard 的APCER 值相比,减少了31.7个百分点。同时XBM机制在一个迭代次数内获得的样本对数远大于batch-all、batch-hard 的大小,即所获得的困难样本数也远大于这些策略。这说明跨批存储机制能通过挖掘出更多的困难样本对来获得比其他样本挖掘策略更好的性能。

表5 样本挖掘策略比较Table 5 Comparison of sample mining strategies单位:%
3 结束语
本文提出了一种结合跨批存储机制与度量学习的人脸活体检测算法。在度量学习中利用跨批存储机制使得网络可以在多个批数据中挖掘困难样本对,提取更加丰富的特征信息,从而避免网络在进行特征提取时,样本挖掘被限制在一个批数据中,导致所提取的特征信息量不够,模型精度下降。另外为了提高模型泛化能力,本文采用异常检测的方式,只对活体样本进行像素级回归损失的监督,来生成欺诈线索,并用欺诈线索来对样本进行分类,结果表明相较于二元交叉熵损失,使用欺诈线索进行分类能得到更好的结果。最后本文对欺诈线索进行了可视化,证明了真实样本和不同欺诈类型的欺诈线索是具有明显的差异。虽然本文猜测这些差异的产生可能和欺诈样本的颜色失真、云纹图案或材质有关,但真实情况仍不确定。未来本文会针对这种情况进行更进一步的探索。
