情感分析中的多传感器数据融合研究综述
2023-12-11金叶磊古兰拜尔吐尔洪买日旦吾守尔
金叶磊,古兰拜尔·吐尔洪,买日旦·吾守尔
新疆大学 信息科学与工程学院,乌鲁木齐 830046
多传感器数据融合技术[1]是一种综合处理和利用来自多个传感器的不确定数据和信息的理论和方法。该技术并非新概念,自然界中的人类和其他生物系统通过利用多个感官来获取客观对象不同质的数据和信息,以提高生存能力。人类视觉、听觉、触觉、嗅觉和味觉等都是从眼、耳、手、鼻和口等多源“传感器”获取到的信息[2],或通过同类“传感器”(如双目)获取同样的信息。人体大脑作为融合中心,协同不同的“传感器”获取客观对象的各个侧面信息,并通过经验和知识等进行相关分析,从而综合更多的数据和信息,获得对周围环境做出更精确的判断和估计[3]。多传感器数据融合技术用于估计或预测实体状态,是融合多源信息的综合处理技术,以此获得对同一事物或目标的更客观、更本质认识的信息。该技术汇集了数字信号处理、统计估计、控制论、计算机通信以及人工智能等多个传统学科中的技术[4]。
情感分析是指利用计算机和自然语言处理技术来识别人类语言中所表达的情感状态[5],它在许多领域中都具有广泛的应用,例如营销、广告、客户服务和医疗保健等。现实生活中,情感表达不仅仅依赖于文本,还包括音频、视频和生理信息等多种形式,所以仅仅依靠单一类型或形式的数据将无法更全面、更客观地表达出人类的情感信息,如何利用多种类型的情感数据进行多综合性分析,是当前情感分析领域的一个研究热点。
随着深度学习的发展,多传感器数据融合技术已经逐渐开始应用于情感分析领域[6]。作为多传感器数据融合的一种,多模态融合技术可以用于从多个来源(如音频、视频、文本等)中获取更全面和准确的情感信息,从而提高情感分析和分析的质量。
目前可应用于情感分析的数据源主要为音频、视频、文本、生理信息等,所以目前可以应用于检测人体情绪的传感器主要有电极、图像传感器(如摄像头、红外传感器)、音频传感器(如麦克风)、视线追踪传感器等。通过在人体皮肤表面放置电极,可以检测到生理信号,如脑电图(EEG)[7]、心率变异性(HRV)[8]、心率、皮肤电阻[9]和肌肉收缩[10]等,从而推断情绪状态。例如,EEG 可以用来检测情绪波动[11],HRV 可以用来检测情绪调节能力[12]。使用摄像头或红外线传感器等设备捕捉人脸表情信息,并通过算法识别出不同的情绪状态,如微笑、愤怒、悲伤等。通过分析从音频传感器收集到的语音信息中的声音特征,从而推断出不同的情绪状态。通过视线追踪传感器监测眼球的运动轨迹,可以推断出人的视觉注意力和情绪状态[13]。例如,当人们感到紧张或焦虑时,他们的视线会更倾向于固定在某个特定的区域。
随着多模态融合情感分析技术的深入以及传感器领域的发展,传感器将会更加频繁地组合使用,以获得更准确和全面的情绪状态信息,由此情感分析的应用领域会更广泛。此外,随着科技的不断发展,新型传感器不断涌现,例如生物传感器、环境传感器等,也有望被应用于情绪检测领域。
1 多传感器融合
1.1 融合分类
针对不同的数据类型、目的和应用场景,可以采用多种不同的数据融合分类方法。
(1)按照融合结构
多传感器数据融合技术可以分为集中式融合结构和分布式融合结构。
集中式数据融合结构指的是将不同来源的数据集中到一个中央位置,并将其进行融合和整合,形成一个统一的数据存储和处理平台。这种结构通常采用集中式数据库或数据仓库来存储数据,并利用ETL(抽取、转换、加载)工具来将不同来源的数据进行转换和整合。
分布式数据融合[14]是指每个传感器都作为一个专家系统,先对原始观测数据进行处理,做出本地判决结论,并与分布在网络中其他位置上的传感器交换结论,从而更新判决结论。
集中式数据融合[15]的优点是数据全面、最终判决结论置信度高,但数据量大、对传输网络要求苛刻、数据处理的时间较长、影响系统响应能力。分布式数据融合中所需传送的数据量要相对较少,且数据融合中心所需的处理时间较短,响应速度较快。
(2)按照融合层次
按照数据融合层次来划分,多传感器数据融合技术主要可以分为三类,原始数据级融合、特征级数据融合和决策级数据融合。
原始数据级融合是指直接融合同构的传感器数据,典型的数据层融合技术包括经典估计方法,例如卡尔曼滤波。
特征级融合首先从传感器数据中提取出特征向量,并将特征向量输入到模式识别过程中,最后利用神经网络方法、聚类算法或模板方法等模式识别方法进行识别。特征级融合的功能主要是融合分类。
决策级融合是在每一个传感器都已经初步确定了一个实体的状态之后,再将这些信息进行融合决策。决策层融合的主要方法有加权决策法(表决法)、经典推理法、贝叶斯推理法和D-S(dempster-shafer)证据理论。
(3)按照传感器组合方式
按照传感器的组合方式可以分为同构传感器和异类传感器数据融合[16-17]。
同类传感器组合只处理来自同一类传感器的数据,其数据格式、信息内容等都基本相同,因而处理方法比较简单。例如处理在不同网络位置上同一种入侵检测系统所产生的报警事件。
异类传感器组合同时处理来自不同类型传感器采集的数据。优点是信息内容广泛,来自不同传感器的数据具有互补性,因而可以获得更准确、更全面、更可靠的结果,但是处理难度相对较为复杂。
1.2 融合方法
1.2.1 加权平均法
加权平均法[18]是一种常用的数据层融合方法,它将多个数据源的值进行加权平均,其中每个数据源的权重是由融合目标和数据源之间的关系来确定的。加权平均法的基本思想是,对于不同的数据源,根据其贡献大小赋予不同的权重,将它们加权平均得到最终结果。在加权平均法中,数据源的权重可以是固定的,也可以根据实际情况动态调整。
在上式中,R表示加权平均数,n表示为数据源的个数,f1,f2,…,fn表示权重。
1.2.2 多贝叶斯估计法
多贝叶斯估计法[19]是一种统计学习方法,用于处理多传感器数据的融合问题。它基于贝叶斯定理,将多个模态的概率分布函数进行融合,从而得到整个系统的概率分布函数。多贝叶斯估计方法框架如图1所示,它可以处理模态之间的相关性和非线性关系,从而提高数据融合的精度和鲁棒性。
具体来说,多贝叶斯估计法将不同模态的数据表示为一个多元随机变量向量,然后基于训练数据集,通过最大后验概率推断得到各个模态的条件概率分布。然后,根据贝叶斯定理,将各个模态的概率分布函数进行融合,得到整个系统的后验概率分布。在测试阶段,将测试数据代入后验概率分布函数中,根据贝叶斯准则,可以得到数据的分类结果。
1.2.3 D-S证据推理法
D-S 证据理论,是一种处理不确定信息的推理理论,通过对相关命题的主观概率进行转化,将命题的不确定问题转化为集合的不确定问题。该理论的基本思想是从相关命题的主观概率获取目标命题的信任度,并通过对互相独立的证据项的信任度采取Dempster 融合规则结合起来。D-S证据理论能够区分“不确定”和“不知道”的差异,可以处理由于随机性和模糊性带来的不确定性,特别适用于决策级数据融合[20]。
在D-S证据理论中,信任函数用于描述证据与命题之间的关系,反映了命题成立的程度。似然度函数则用于描述证据的可靠性和权重。通过将似然度函数和信任函数相乘,可以得到证据的证据权重。根据Dempster融合规则,可以将多个证据的证据权重进行合并,得到目标命题的证据权重。在多传感器数据融合中,可以使用D-S证据理论对不同传感器的数据进行决策合并,提高决策的准确性和鲁棒性[21]。在模式识别中,可以使用D-S证据理论对多个分类器的结果进行融合,提高分类的准确性。在机器学习中,可以使用D-S证据理论处理缺失数据和噪声数据,提高模型的鲁棒性和泛化能力。
设n为目标类型数,m为传感器数量,Ci(Oi)为传感器i对识别目标Oi的关联系数,该系数需要根据具体情况而定,λi是传感器i的环境加权系数,则可以定义:
则传感器i对目标Oi的基本概率赋值为:
传感器i的不确定性为:
1.2.4 模糊聚类法
模糊聚类(fuzzy clustering)[22]是一种聚类算法,与传统的硬聚类(hard clustering)算法不同,它允许数据点属于多个聚类中心的概率(或权重)分配。模糊聚类的主要思想是将数据点分配给每个聚类中心的概率(或权重)相对于其与该聚类中心的距离而言。这样,在模糊聚类中,数据点可以同时属于多个聚类中心,且每个聚类中心对于每个数据点的重要性不同。
1.2.5 神经网络方法
数据融合中的神经网络方法[23]指的是使用人工神经网络(artificial neural network,ANN)来融合多个数据源的技术。这种方法是一种基于模型的数据融合技术,旨在将来自不同源的数据进行集成,以获得更精确、更全面的信息。
具体来说,该方法将来自不同源的数据输入到ANN 中进行训练,以获得融合后的结果。ANN 通常包含多个层次,每个层次包含多个节点。如图2为一个简单的二层ANN 结构,在训练期间,ANN 将根据给定的输入和输出数据对其内部参数进行调整,以最小化标准预测误差。在训练完成后,ANN 将可以用于预测新的数据输入。
1.2.6 深度学习方法
深度学习(deep learning)是由多层人工神经网络堆叠而成,所以基于深度学习的数据融合本质就是基于人工神经网络的数据融合方法的一种,但两者也有一些区别:基于人工神经网络的数据融合通常使用简单的前馈神经网络,而基于深度学习的数据融合则可以使用更复杂的卷积神经网络、循环神经网络等。基于人工神经网络的数据融合通常使用传统的反向传播算法进行训练,而基于深度学习的数据融合则可以使用更高级的优化算法,如Adam、Adagrad 等。基于深度学习的数据融合相对于基于人工神经网络的数据融合,具有更强的自动化和抽象能力,可以更好地处理大规模和高维度的数据,并且可以学习更复杂的特征和模式。但同时,也需要更多的数据和计算资源来进行训练和调优。
现有的基于深度学习的数据融合方法分为基于深度学习特征提取的数据融合方法、基于深度学习融合的数据融合方法以及基于深度学习全过程的数据融合方法三种[24]。
(1)基于深度学习特征提取的数据融合方法
在基于深度学习特征提取的数据融合方法中,使用深度学习模型对原始数据进行特征提取,不应用到融合阶段,如图3 所示。所以,数据的融合操作既可以在深度学习模型之前(数据级融合),也可以在深度学习模型之后(特征级融合、决策级融合)。

图3 数据的深度特征融合流程图Fig.3 Flow chart of deep feature fusion of data
文献[25]提出一种基于非下采样轮廓波变换(nonsubsampled contourlet transform,NSCT)和卷积神经网络(convolutional neural network,CNN)的X 射线图像骨龄评估多尺度数据融合框架,并在该框架下提出基于特征级融合的回归模型和基于决策级融合的分类模型。该方法通过执行NSCT 来预先提取输入图像的丰富特征集,从而获得其多尺度和多方向表示,并将在每个尺度上获得的NSCT系数图单独输入到卷积网络中,然后合并来自不同尺度的信息以实现最终预测。该方法包括两个CNN 模型:具有特征级融合的回归模型和具有决策级融合的分类模型。该方法在公共BAA数据集数字手部图谱上进行了实验,并显示出了较高的预测准确率和优于其他最先进的BAA方法的表现。
(2)基于深度学习融合的数据融合方法
在基于深度学习融合的数据融合方法,深度学习模型针对数据或特征进行融合处理,如图4所示。该方法中,深度学习模型的输入可能是原始数据集,也可能是经过处理后的数据特征。

图4 基于深度学习融合的流程图Fig.4 Flow chart based on deep learning fusion
文献[26]提出一种基于深度长短时记忆神经网络(deep long short time memory,DLSTM)数据融合预测模型,该模型以长短时记忆网络(long short-term memory,LSTM)神经单元为基础,多个LSTM神经单元构成LSTM 层,DLSTM 模型通过多层LSTM 层进行叠加构成,通过实验验证,DLSTM 数据融合预测模型的预测准确率有明显提高,并且模型的鲁棒性也有很大提高,DLSTM 模型可以很好地挖掘多传感器数据之间的长期依赖关系。
文献[27]提出的基于卷积神经网络的自适应数据融合方法主要解决了多源数据融合困难的问题。该方法的主要特点是采用自适应卷积核设计自适应数据融合层,然后利用基于空洞卷积的一维卷积神经网络对融合数据特征进行提取。经过实验验证,基于卷积神经网络的自适应数据融合方法具有较高的实用价值,在多源数据融合故障诊断等领域具有广泛的应用前景。
(3)基于深度学习全过程的数据融合方法
在该方法中,数据特征的提取和数据的融合两个阶段均会用到深度学习模型。两个阶段可以使用相同类型的深度学习模型,也可以使用不同类型的深度学习模型。
(4)总结
深度神经网络既可以自适应地挖掘原始数据的深层次特征,也可以在数据的融合过程中充分考虑数据之间的关联性和互补性,从而提高融合数据的有效信息密度。随着传感器技术的发展,原始数据量不断增加,深度学习常会通过增加网络深度和复杂度来提高模型的表达能力,但这样也会导致模型的参数数量和训练难度增加,同时需要更多的计算资源来进行模型训练和推理。
1.3 研究现状
多传感器融合技术在军事领域得到了广泛的应用,特别是在航空目标探测、识别和跟踪方面,以及战场监视、战术态势估计和威胁估计等方面。随着时间的推移,数据融合技术的应用领域已经扩展到其他领域,如地质科学、机器人技术、医疗诊断和复杂工业过程控制等[28-30]。
近年来,多源图像融合作为多传感器信息融合技术的重要应用方向,得到了广泛关注。多源图像融合技术是从多个传感器中获取的图像数据中提取有用信息,将它们融合成一个单一的图像,以提高图像的质量和可用性。该技术广泛应用于许多领域,如无人机和卫星图像、医学图像和军事情报等[30]。多源图像融合可以提高图像的清晰度和分辨率,增加图像的信息量,降低噪声水平,使图像更加适合于后续处理和决策[31]。
随着人工智能领域的发展,多传感器融合技术开始逐渐应用在更多的人机交互技术中,如智能机器人、自动驾驶、智能家居、健康监测、情感分析等。多传感器融合技术已经成为未来机器学习的重要途径,其可以针对数据实现更加智能化、高效化的处理和决策。
2 情感分析
情感主要通过多种方式表征出来,因此情感分析的研究也涉及多种数据信息的应用。除了语音、图像和语言数据外,还包括生理信号,如心率、皮肤电导、脑电波等。这些数据可以通过传感器或设备采集,并经过处理和分析以获得有关情感的信息。所以本章对语音情感分析、图像情感分析以及生理信号情感分析进行总结。
2.1 语音情感分析
语音情感分析是指通过分析人类语音信号中所蕴含的情感信息,自动地确定说话人的情感状态,比如愤怒、高兴、悲伤、惊讶等。如麦克风等语音传感器,将收集到的语音信号转换为电信号,然后通过放大和数字转换等过程转换为计算机可处理的数字信号。语音情感分析的主要挑战是如何从语音信号中提取情感信息。
可以通过对传感器所收集的语音信号进行处理和分析,将语音信号分割为定长的帧,然后从这些帧中提取情感特征,如基音频率、声音强度、语调、语速等[32]情感特征。常用的音频特征提取工具有librosa[33]、opensmile[34]等。深度学习算法在语音情感特征提取中的应用,包括卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)等。当给定一种将音频信号映射到二维表示的方法时,CNN 可以学习深度音频特征,而RNN和LSTM可以对音频信号进行序列建模,并对序列中的情感信息进行建模和预测。最近,无监督的表示学习技术和结构也在迅速发展,如SincNet 网络和wav2vec 模型等,它们能够从初始波形中学习音频表示,提高语音情感分析的性能和鲁棒性。需要注意的是,深度学习算法在语音情感分析中需要大量的数据和计算资源进行训练和调优,但是它们通常能够提供比传统机器学习算法更好的性能和鲁棒性。
目前,常用的语音情感分析技术包括基于高斯混合模型(GMM)、支持向量机(support vector machine,SVM)、决策树(DT)以及深度学习等的方法。文献[35]提出了一种通过学习三个频道的对数Mel频谱图的高层特征表示来设计用于语音信号的情感差距的深度卷积神经网络(deep convolutional neural network,DCNN)模型,其学习的分段级特征通过判别时间金字塔匹配(DTPM)策略进行聚合,该方法在语音情感分析方面取得了良好的性能。文献[36]通过STFT算法将所选序列转换为频谱图,并使用CNN 模型从语音频谱图中提取区分性和显著性特征,然后通过对CNN 提取的特征进行标准化处理,再将其输入深度双向长短时记忆(BiLSTM)模型中学习时间信息以识别最终情感状态。
近年来,注意力机制(attention mechanism)在深度学习领域得到了广泛的应用。Mirsamadi等人[37]提出了基于注意力机制的循环神经网络(recurrent neural network,RNN),有效地提升了语音情感分析的性能。传统的深度学习方法不能够对不同的语音段进行不同程度的关注,因而无法有效地处理一段语音中与情感体现无关的部分。注意力机制可以使深度学习模型更关注与情感体现相关的部分,忽视与情感体现无关的部分,进而有效地提高深度学习模型的性能。Sarma等人[38]将Attention分别用于LSTM和TDNN-LSTM模型,性能均得到了显著的提升。针对语音在情感特征表示上的不足,文献[39]对比了直接利用语音提取特征和利用梅尔频率滤波器组(Mel-frequency filter banks,FBank)特征进行深度学习语音情感分析的效果,研究表明,利用FBank特征进行语音情感分析可以取得更好的效果。
2.2 视觉情感分析
2.2.1 图像情感分析
图像情感分析是一种通过分析和处理从传感器获取的静态图像,从中提取出低层次的特征(例如颜色、纹理、形状等)和高层次的语义特征(例如人脸、动作、场景等),并通过建模和推理,从而获得关于图像所表达的情感信息的方法。图像情感特征的研究大多是捕捉人脸面部表情。面部表情特征提取会产生更小、更丰富的属性集,这些属性集包含脸部边缘、对角线等特征,以及嘴唇和眼睛之间的距离、两只眼睛之间的距离等信息。表情特征提取的方法包括基于几何的特征提取和基于外观的特征提取。
近年来,研究人员提出了一系列深度卷积神经网络(DCNN)方法用于视频序列中面部表情识别任务的高级特征学习。DCNN能够有效提取图像的多种特征,包括低级别特征(如颜色、纹理、形状等)和高级别语义特征(如物体、场景、情感等)。所以在DCNN中,卷积层通过使用多个卷积核对输入的人脸图像进行卷积操作,从而提取出人脸图像中的局部特征,如边缘、对角线等低级别特征。池化层则用于对卷积层输出的特征图进行降维处理,从而减少模型的参数数量和计算量。全连接层则将池化层输出的特征向量进行分类任务,对特征所蕴含的表情情感信息进行分类。目前,基于深度学习的图像情感分析发展迅速,VGG[40]、ResNet[41]、Inception[42]等基于深度卷积神经网络的模型广泛应用在图像情感特征提取。
文献[43]提出了一种基于残差网络的深度卷积神经网络,可以用于图像分类、目标检测等任务,该方法通过跨层连接(skip connection)来解决深度网络中的梯度消失问题,从而提高了网络的准确率和收敛速度。文献[44]提出了一种基于面部关键点的情感分析方法,其利用面部关键点识别不同的情感表达,简单、高效地对图像中的表情信息进行提取和分析。文献[45]采用VGG-16 深度卷积神经网络模型对FER-2013 人类数据集进行情感分类,准确率达到了69.40%,模型如图5 所示。文献[46]提出了一种使用深度残差网络ResNet-50的特征提取方法,结合用于面部情感分析的卷积神经网络,该模型获得了较好的性能。

图5 VGG-16网络提取图像信息Fig.5 Extracting image information of VGG-16 network
2.2.2 视频情感分析
视频数据相比于图像数据,其不仅包含了空间信息,还包含了时间属性信息[47]。视频的空间属性是指视频中每一帧图像所包含的信息,包括图像的颜色、形状、纹理等,可以通过CNN 等方法来提取。CNN 模型通常包括多个卷积层和池化层,能够有效地捕捉图像的空间信息。而视频的时间属性是指视频中相邻的图像帧之间的相互作用信息,包括运动、动作等。这些信息可以通过卷积神经网络或LSTM 等方法来提取。卷积神经网络可以通过卷积操作来捕捉图像帧之中的空间信息,LSTM则可以捕捉更长时间跨度的运动信息,可以更好地建模视频序列中的时间信息。
文献[48]引入了一种基于树的增强朴素贝叶斯(tree augmented naive Bayes,TAN)分类器,学习面部特征之间的依赖关系,还提供了一种用于寻找最佳TAN结构的算法,使用此TAN 结构比使用简单的朴素贝叶斯分类器提供了显著更好的结果。文献[49]提出了一种采用混合深度学习模型的视频序列情感分析方法,首先利用两个独立的CNN,包括一个处理静态面部图像的空间CNN 和一个处理光流图像的时间CNN,分别在划分的视频段上学习高级空间和时间特征,然后将特征整合到一个由深度置信网络(deep confidence network,DBN)模型构建的深度融合网络中,在视频序列中对学习的DBN 段级特征进行平均池化,产生一个固定长度的全局视频特征表示,并使用SVM进行分类,该方法在RML 数据集上的准确率可以达到73.73%。文献[50]提出了一种基于表情片段的视频流形建模方法,用于解决动态表情识别中的时间对齐和语义感知动态表示问题,实验结果显示该方法在CK+、MMI、Oulu-CASIA 和AFEW 数据集上均获得较好的效果。文献[51]提出了包括一种基于短片段感知情感丰富特征学习网络(CEFLNet)的方法,该网络一个基于短片段的特征编码器(CFE)和一个情感强度激活网络(EIAN),结果表示该方法在3DFE、MMI、AFEW和DFEW四种数据集上均取得不错的效果。
2.3 文本情感分析
文本情感分析是一种自然语言处理技术,旨在对带有情感色彩的主观性文本进行分析和挖掘,以识别和分析文本中表达的情感倾向和态度。文本情感分析的要过程为数据预处理、特征提取、模型训练和情感分类。
在文本情感特征提取之前首先需要对原始文本数据进行清理和预处理,例如去除停用词、标点符号、数字和特殊字符,并进行分词、词性标注和词干提取等操作。将经过预处理的文本数据转换成有意义的数值特征向量。文本情感特征常用的传统提取方法有过滤法、映射法、词袋模型[52]、tf-idf(term frequency-inverse document frequency(词频-逆文档频率))[53]和词嵌入[54]。与传统方法相比,深度学习可以从训练数据中快速获得新的有效情感特征,如CNN和RNN。在涉及顺序输入的任务中,RNN通常更适用于文本处理。此外,GloVe和BERT模型等无监督架构也被设计用来学习单词的向量空间表示,可以用于多模态情感分析的文本模态。这些模型通过大量数据的预训练,具有很强的特征表示学习能力,能够捕捉词义和上下文。为了方便与基线模型进行比较,大多数多模态情感分析模型都采用了GloVe嵌入。
模型训练和情感分类是使用已标注的文本情感数据集,训练一个分类器模型,以自动将文本分类为正面、负面或中性。常见的分类器模型包括朴素贝叶斯、SVM、决策树和深度学习模型等。文献[55]提出了一种使用CNN 进行短文本情感分类的方法,取得了较好的分类效果。文献[56]提出了一种基于双向转换器编码器(BERT)的预训练语言模型,可用于各种自然语言处理任务,包括情感分析。BERT 在多个任务上取得了目前最好的效果。文献[57]提出了一种基于Transformer模型的文本生成框架,并探究了在情感分类任务中如何使用预训练模型进行迁移学习。在多个情感分类任务上进行实验,该方法取得了优秀的性能。文献[58]提出了一种层次注意力网络模型,用于对整篇文档的情感进行分类。
2.4 生理信息情感分析
生理信息情感分析是指利用人体的生理信号(如心率、脑电波、皮肤电反应等)来推断人的情感状态。这种方法通常涉及到生理信号传感器设备的使用,例如心电图机、脑电图机、皮肤电导测量仪等。通过传感器收集这些信号,并从信号的变化可以了解人的情感状态和心理反应。生理信号情感分析的主要优点是可以实现非侵入式的情感分析,因为这些信号的采集不需要对被试进行任何身体干预。同时,这种方法也不会受到语言和文化差异的影响,因为生理信号是人类本身具有的生理反应。常用的生理信号有脑电、皮肤电、心电以及肌电等。
蕴含情感信息的特征包括时域特征、频域特征、小波变换特征及时频特征等。时域特征是指在时间维度上对信号的统计特征进行提取,如均值、方差、标准差、斜度和峰度等。这些特征可以反映信号的振幅、波形和分布等信息,从而对情感状态进行刻画。频域特征是指在频率维度上对信号的频域特性进行提取,如功率谱密度、频带能量比和频率峰值等。这些特征可以反映信号的频率分布和能量分布情况。小波变换可以将信号在时域和频域上进行分解,从而提取信号的局部时频特征。常用的小波变换特征包括小波包能量、小波包熵和小波包标准差等。时频特征是指在时域和频域上同时对信号的特征进行提取,如短时傅里叶变换(STFT)、连续小波变换(CWT)和离散小波变换(DWT)等。
所提取的生理信息特征可以使用机器学习算法进行情感分类。常用的机器学习算法包括支持向量机(SVM)、随机森林(RF)和神经网络等。文献[60]分别利用心电图、肌电信息和皮电信息进行情感分析。先是对心电信息进行预处理和特征提取,再使用随机森林和神经网络进行分类,实验结果表明心电信息对情感分类最有效。
2.5 总结
情感分析任务已经取得了一定的研究进展,并且在实际应用中具有很高的实用价值。但是情感分析的研究也正面临了一些挑战,其主要的问题之一则是单一数据的局限性。
使用一种数据进行情感分析的局限主要包括数据的不平衡性、数据质量问题和数据获取成本三方面。数据的不平衡性是由于不同类型的数据信息所涵盖的情感维度不同,例如语音数据可以涵盖声音的情感维度,但无法涵盖面部表情的情感维度,又如不同的生理信号对情感的响应可能存在差异。数据质量问题则是因为不同类型的数据采集方法和设备会对数据的质量产生不同程度的影响,如图像数据可能会受到光线、姿态等因素的影响,且生理信号的采集和处理需要专业的设备和技术。数据获取成本即不同类型的数据获取成本不同,例如语音数据可以通过麦克风进行采集,而生理信号需要特殊的传感器进行采集。
因此,为了更全面准确地表征情感,研究人员通常会采用多种类型的数据进行情感分析,利用从多种类型的传感器或多个传感器收集的数据进行融合,以提高情感分析算法的准确度和鲁棒性。
3 多模态情感分析
作为多传感器数据融合技术的一种,多模态融合近几年开始成为人工智能领域的研究热点。因为用单模态进行情感分析存在着识别率低、稳定性差等限制,情感分析研究者综合利用多种模态的数据进行情感分析来提高其准确性和稳定性。在多模态情感分析中,模态融合的效果直接影响结果的准确性,因此需要根据所用模态的不同和模态中信息的不同选择适当的模态融合方法。
3.1 多模态情感分析方法
3.1.1 特征级融合
特征级融合是一种多模态情感分析方法,其融合框架如图6所示。它能够利用多模态特征之间的相关性,从而提高情感分析的准确性和可靠性。但是,它也存在一些缺点,例如融合后特征的维度通常较高,这种高维度会增加模型的计算复杂度和训练难度,导致过拟合和性能下降的风险增加。因此,需要对融合后的特征进行降维或者对情感分析具有显著影响的特征进行重要性排序和选择,以减少特征维度并提高模型性能。

图6 特征级融合框架Fig.6 Feature-level fusion framework
多种模态特征的融合方法有加权融合、串联融合、堆叠融合和交互式融合等。加权融合是对于每种模态,赋予其一个权重,然后将不同模态的特征按照权重加权求和。串联融合是将不同模态的特征拼接在一起,然后再输入到分类器中进行分类或者回归等任务。堆叠融合将不同模态的特征分别输入到不同的神经网络中进行特征提取,然后将提取的特征进行堆叠,最后再输入到分类器中进行分类或者回归等任务。交互式融合通过将不同模态的特征进行交互,从而学习到它们之间的关联性。这种方式常见的方法包括神经注意力机制和循环神经网络等。
文献[59]提出了一种基于自注意力机制的新的特征级融合方法,在文本和语音模态上进行分析,实验结果经过与传统的融合方法(如串联、交叠等)进行了对比,在视频中进行话语级情感分析的情况下,提出的融合方法优于其他方法。文献[60]提出了一种新的基于特征融合表示的阿拉伯语推特表征方法以捕捉多义性、语义/句法信息和传达的情感知识,且提出了一种基于双向门控循环单元(BiGRU)、双向长短期记忆(BiLSTM)和卷积神经网络的注意力深度学习模型,有效地学习局部和全局特征,并提供多标签情感分类,实验结果表明该方法取得了良好的效果。文献[61]利用对权重进行低秩矩阵分解,将TFN先张量外积再全连接的过程变为每个模态先单独线性变换之后再多维度点积,可以看作是多个低秩向量的结果的和,从而减少了模型中的参数数量。文献[62]所有模态使用全连接层进行特征提取,即encoder,再用decode 还原特征,最后计算特征之间的损失。文献[63]同时捕捉时序上和模态间的交互,以得到更好的多视图融合。文献[64]使用aspect-guided attention 机制来指导模型生成文本和图像的attention向量。
3.1.2 决策级融合
决策级融合的优点在于,它能够将不同模态的情感分析结果进行简单的整合,产生最终的情感决策结果。图7为决策级融合框架。相比于特征级融合,决策级融合更加直接,模型也更加简单。此外,决策级融合能够有效地处理各模态间的差异,提高了模型的稳定性和鲁棒性。同时,当某个模态数据不可用或者丢失时,决策级融合也可以通过其他模态的数据来做出情感决策,提高了模型的可靠性。然而,决策级融合也存在一些局限性。例如,各模态之间的相关性可能会被忽略,导致决策级融合的结果不够全面。此外,决策级融合需要对不同模态的情感分析结果进行整合,这需要针对不同模态的分析结果进行加权处理,这种加权处理可能会存在一定的主观性。因此,在实际应用中,决策级融合需要综合考虑各种因素,确定最适合的融合方法。

图7 决策级融合框架Fig.7 Decision-level fusion framework
文献[65]提出了一种可靠的决策级多模态融合方法,该方法设置了一个决策规则,在决策层级上融合了音频和视觉信息以识别情感,以此可以实现从人类语音和面部表情中以良好的性能自动识别情感状态。文献[66]提出了一种对从眼动仪收集的脑电图(EEG)信号和瞳孔反应两种数据进行决策级融合方法,该方法证明结合两种生理信号进行决策级融合也能够有效提高情感分析模型的性能。文献[67]构建了一种基于生理信号、均值阈值和决策级融合算法来识别人类情绪状态。首先从脑电图和外围生理信号中选择关键特征,并使用平均值方法获得每个参与者的分类阈值,以区分个体差异。然后采用高斯朴素贝叶斯(GNB)、线性回归(LR)、SVM 等分类方法进行情绪识别,实验结果表明该算法对情感的分类效果优于其他融合方法。文献[68]提出了一个多模态情感分类框架,利用多通道生理信号,并引入了两种关键技术:混合特征提取和自适应决策融合,凸显了开发自适应决策融合策略进行情感分类的重要性。
3.1.3 混合融合
混合融合方法是特征级融合和决策级融合的结合,它通过组合多个模型的特征和决策来获得更好的性能,其流程如图8所示,其特殊之处在于既包含特征融合也包含决策融合。相比于单一融合方法,混合融合方法可以更好地利用各个模型的优势,从而提高模型的准确性和鲁棒性。由于混合融合方法需要考虑不同模型的特征和决策的融合方式,因此它的实现难度和模型复杂度都相对较高。同时,混合融合方法也需要更多的计算资源和时间,因此在实际应用中需要根据具体情况进行选择和权衡。

图8 混合融合框架Fig.8 Hybrid fusion framework
文献[69]通过特征级融合和决策级融合这两种多模态融合策略,实现了包含视频和音频信号的多模态情感分析系统,展现了多模态情感分析系统性能的优越性。文献[70]提出了特征级-决策级融合的方法融合声学特征和语义特征进行情感分析,首先将声学特征与语义特征进行特征级融合,然后在结果之上进行决策级融合。文献[71]提出了一种基于注意力机制神经网络的认知脑边缘系统(HALCB)的层次化Attention-BiLSTM(bidirectional long-short term memory)模型,该模型可以在不同的分析阶段使用不同的模态融合方法。
3.1.4 模型级融合
模型级融合[72]是一种不同于特征级融合和决策级融合的多模态融合方法。该方法通过建立适当的模型,联合学习不同模态之间的相关信息,而不需要探究各模态的重要程度。模型级融合可以将不同模态特征分别输入到不同模型结构再进行进一步特征提取,从而达到融合不同模态信息的目的。相比于特征级融合和决策级融合,模型级融合最大的优势在于可以灵活地选择融合的位置。基于深度学习的数据融合便是模型级融合之一。
一些研究表明,基于深度神经网络的模型级融合方法能够显著提高多模态数据的性能。例如,文献[73]通过将堆叠的受限玻尔兹曼机展开成深度置信网络,将手工提取出来的脑电和眼动特征分别作为两个玻尔兹曼机的输入并从神经网络中学习两种模式的共享表示。实验结果表明,该方法能够提高多模态数据的分类准确率。文献[74]提出了分别针对音频和视频数据进行特征提取的新颖特征提取网络,并通过在模型级别上融合音频和视频特征来创建最优多模态情感分析模型,该模型在RAVDESS 和SAVEE 两种数据集上实现了高达99%和86%的预测准确率。
3.2 模态对齐
不同模态数据之间存在时间上的不一致性,导致难以对多模态数据进行有效地整合和利用。例如,在视频中,一个人的语音和图像信息是同步的,但是由于处理和传输的延迟,这两种信息到达计算机的时间可能不同。为了利用多模态数据,就需要将它们对齐到同一时间轴上[75],以便进行有效地整合和利用。
多模态对齐可以采用多种方法,包括基于时间对齐、基于特征对齐、基于模型对齐等方法。其中,基于时间对齐是最简单和常见的方法,即将不同模态的数据对齐到同一时间轴上;基于特征对齐是指将不同模态的特征对齐到同一时间轴上;基于模型对齐是指通过学习模型来对多模态数据进行对齐。
3.3 多模态情感数据集
随着多模态情感分析的研究不断深入,越来越多的研究人员开始关注多模态数据集的构建和应用。多模态情感数据集多是来源于社交媒体发布的视频、音频以及评论等内容,或是研究人员在实验室所采集并开放的数据集。目前已经有很多模态情感数据集被构建出来,涵盖了各种应用场景和语言文化。表1 列举了当前经常用于多模态情感研究与应用领域的数据集。
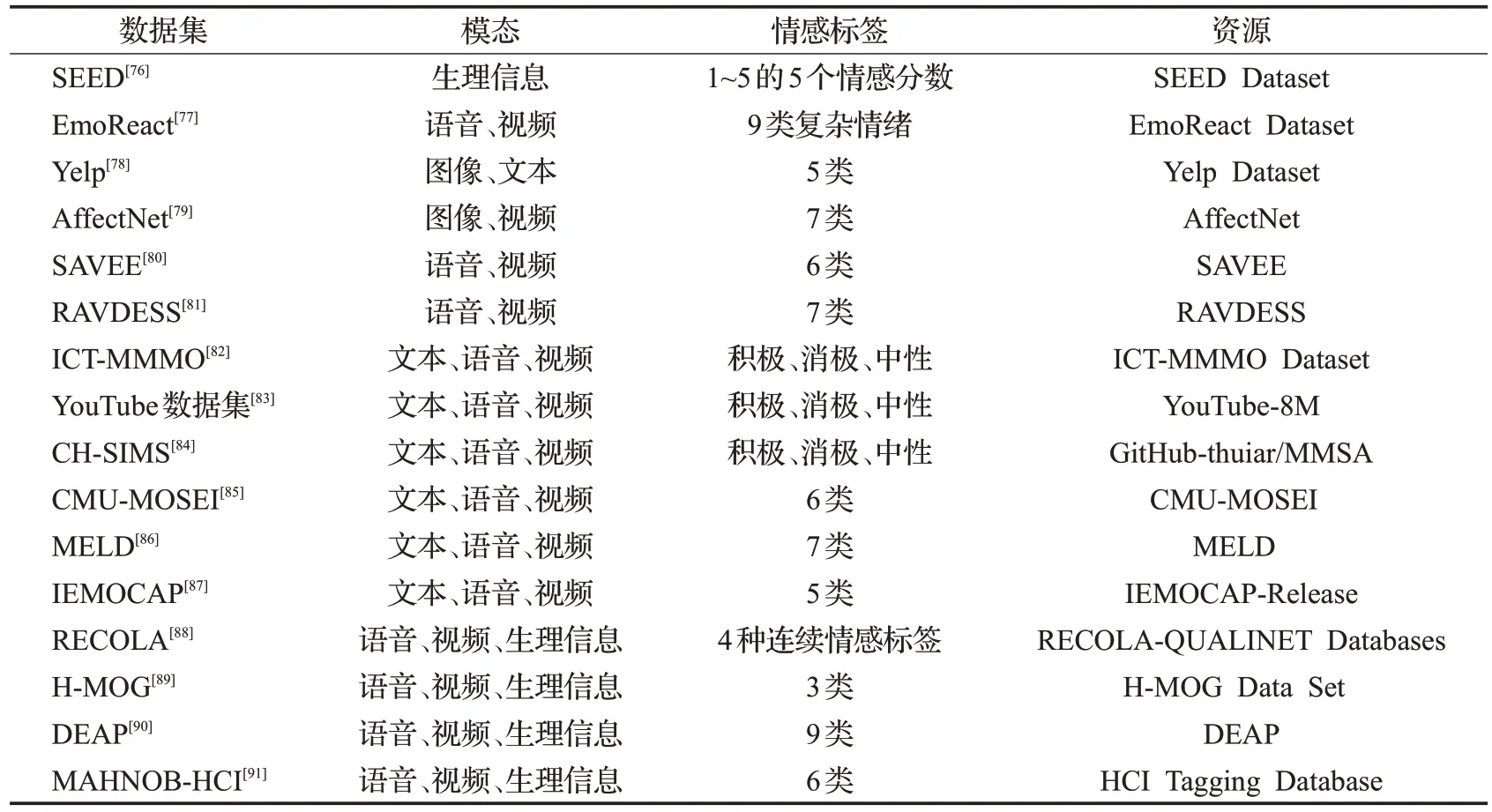
表1 多模态情感数据集Table 1 Multimodal emotional datasets
4 实验
为了比较单模态和多模态情感分析方法的性能,设计了一组对比实验。实验中,使用了A(音频)、V(视频)和T(文本)这3 种不同的模态数据,并比较了它们在单模态和多模态情感分类任务上的表现。此实验使用的是特征级融合。
4.1 模型建立
对于文本数据,使用了一个嵌入层将文本序列转换为向量表示,并通过两个包含512、256 个隐藏单元的LSTM 层对序列进行建模,以捕捉文本之间的时序关系。然后,通过全连接层进行特征提取和情感分类。
对于语音数据,首先使用两个LSTM层,两个LSTM层分别有512、256 个隐藏单元,以对输入序列进行建模,然后添加了Flatten层将卷积层输出的特征图展平成一维向量,以及包含512个神经元的全连接层并应用了ReLU 激活函数,最后添加了一个具有4 个神经元的输出层,用于多类别分类任务。
对于视觉单模态数据的处理,设计了5组Block,每组Block 都由一个卷积层、一个Dropout 层以及一个激活函数层Activation 组成,增加了网络的深度和非线性能力。最后一组Block 还添加了Flatten 层将卷积层输出的特征图展平成一维向量,以及256个神经元的全连接层,最后添加了一个具有4 个神经元的输出层,用于多类别分类任务。
特征融合则是将上述模型中全连接层的输入特征进行concat(串联),然后再使用全连接层对特征进行映射和转换。
4.2 实验结果
实验所使用的是IEMOCAP数据集和RAVDESS数据集。分别将IEMOCAP数据集中的音频、文本和表情数据作为输入利用上面建立的模型进行特征提取和情感分类,得到的识别准确率如表2所示。

表2 IEMOCAP数据集的单模态和多模态情感分析结果Table 2 Single modal and multimodal sentiment analysis results of IEMOCAP dataset
IEMOCAP 和RAVDESS 数据集的情感分类实验指标Accuracy和Recall对比如图9所示。通过对比实验的结果,可以观察到单模态和多模态情感分析的差异。在IEMOCAP和RAVDESS数据集的实验中,3种模态数据的单模态情感分析指标不论是准确率还是召回率都要低于多模态融合情感分析,而且3种模态融合的分类结果要比两种模态融合更准确。

图9 情感分类实验结果Fig.9 Experimental results of sentiment classification
从实验也能看出单模态数据中文本数据更能准确表达出情感信息,音频数据次之,而且音频和视频两种模态数据的融合相较于其他两种模态数据融合更能准确反映出情感信息。不难看出多模态方法相对于单模态方法表现出更好的性能。图10 展示了在IEMOCAP数据集上的3 种模态融合情感分类训练中训练和测试准确率的变化曲线图。图11 展示了在RAVDESS 数据集上的两种模态融合情感分类训练中训练和测试准确率的变化曲线图。
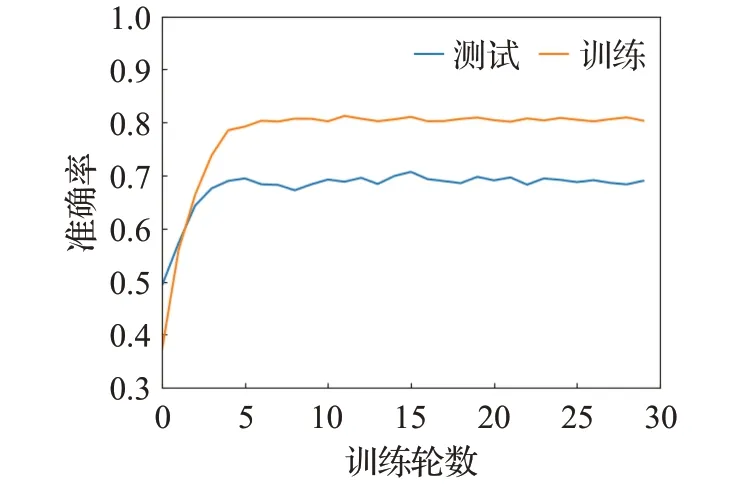
图10 IEMOCAP三模态融合情感分类准确率曲线Fig.10 Emotion classification accuracy curve for IEMOCAP dataset with fusion of three modalities
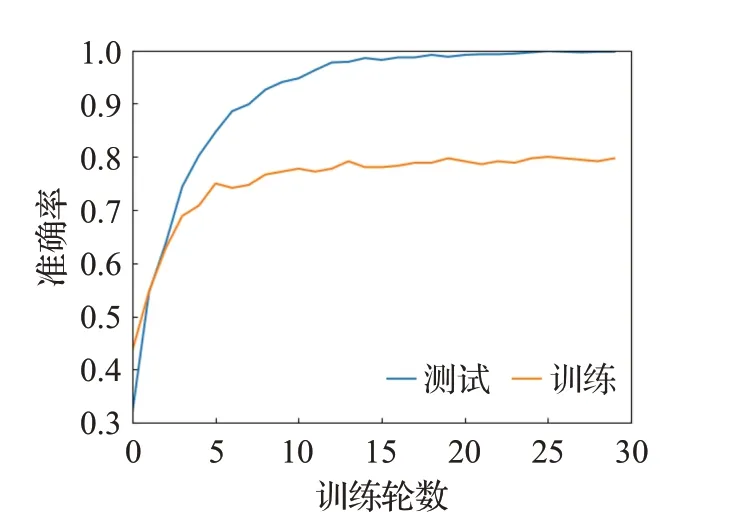
图11 RAVDESS双模态融合情感分类准确率曲线Fig.11 Emotion classification accuracy curve for RAVDESS dataset with fusion of two modalities
结果表明,多模态方法能够利用不同模态之间的互补性,提供更全面和丰富的信息,从而改善情感分类的准确性。模态的融合可以帮助消除某个单一模态中的噪声或缺失信息,并增强不同情感类别之间的对比度。此外,多模态方法还可以更好地处理数据缺失的情况,通过利用其他可用的模态信息填补缺失模态的信息。
5 结语
目前,生理信号的采集和分析技术仍存在一定的局限性,而随着传感器技术的不断更新和发展,采集生理信号的传感器的尺寸和重量将会不断减小,在日常生活中的应用会更加广泛,生理信号如脑电、皮肤电等的采集和分析精度和效率将会不断提高,基于生理信号的情感分析技术将会迎来较快的发展,从而为多传感器融合技术的发展提供更好的基础。
更多的传感器数据会作为情感数据源进行情感分析。目前情感分析领域多数聚焦于语音、表情、文本以及生理信号的单模态数据或多模态融合的研究,较少研究会考虑身体姿态数据作为情感分析数据源。主要是因为身体姿态识别传感器设备还不具有普适性和实时性,随着身体姿态识别技术的发展和人体传感器技术的进步,更广泛的场景和设备应用,例如智能手机、可穿戴设备、虚拟现实设备等皆可作为人体姿态数据的采集设备,数据的实时性越来越高,身体姿态识别技术将得到更广泛的应用,身体姿态作为一种重要的情感分析信息源,将在多模态情感领域发挥越来越重要的作用。液体传感器也将会作为新的情感数据源对情感分析技术的发展起到一定作用。液体传感器可以检测人的汗液中的化学物质,例如皮质醇和多巴胺,这些物质与人的情绪状态有关。通过检测这些物质的浓度变化,可以判断一个人的情绪状态,例如焦虑、兴奋或紧张。液体传感器可以用于提供情感反馈,例如水的颜色和味道可以影响人的情绪状态。液体传感器可以监测液体的化学和物理特性的变化,并调整水的味道和颜色以提供情感反馈。所以液体传感器在情感分析中具有广泛的应用前景,液体的传感器数据也会作为模态之一丰富情感分析的研究领域。
多模态情感分析技术能够在多语言情感分析领域发挥其重要作用。例如,通过使用多个传感器同时捕捉语音和面部表情数据,可以更准确地识别多种语言中的情感状态。此外,对于一些流行的语言(如英语、汉语、法语等),已经存在大量的情感分析研究和数据集,这些数据可以用于如小语种、方言等多种语言的情感分析的研究和开发。
对于多模态情感分析技术,还有许多问题可以深入研究:(1)为了更好地评估模型的泛化能力,未来的多模态情感分析模型可以采用跨数据集的评估方式进行训练,以便更好地适应不同的应用场景。(2)为了提高模型的泛化能力,未来的多模态情感分析模型可以利用无监督或有监督领域适应方法的能力,从而更好地适应不同的数据集和应用场景。(3)为了更好地处理非对齐的多模态数据,未来的多模态情感分析模型应该具有对非对齐数据进行推断的能力,从而更好地理解和识别情感。(4)为了更好地处理有噪声或缺失模态的情况,未来的多模态情感分析模型应该具有对有噪声或缺失模态进行推断的能力,从而更好地识别情感。例如,可以利用多任务学习的方法,同时识别多个模态的情感信息,从而提高模型的鲁棒性。
