电子档案实时推荐系统模型优化应用研究
2023-12-08陈静胡祥科彭煦彭登辉
陈静 胡祥科 彭煦 彭登辉
摘要:论文结合实时推荐技术的特性,针对现有电子档案管理系统中的检索推荐方法,进一步提出实时推荐的优化方式,即通过应用基于内容的召回推荐策略和基于用户的协同过滤推荐策略进行电子档案的实时推荐。此种方式将打破传统依赖关键词的正向检索局限,提升电子档案的利用效率,为电子档案管理提供一定的参考与借鉴。
关键词:电子档案 实时推荐 计算机应用
随着电子档案呈海量增长的趋势加强,如何高效、精准地满足电子档案利用者的需求,提升检索效能,充分发挥电子档案的价值,成为亟待解决的问题。本文提出了应用基于内容的召回推荐策略和基于用户的协同过滤推荐策略,打破了传统依赖关键词检索推荐的局限,有效缩短了档案查询时间,提升了电子档案的检索效率。
一、电子档案推荐系统现状及存在的问题
电子档案具有类型复杂多样、数量大等特点。现有推荐系统大多是通过获取所检索的关键词,与后台数据库存储的电子档案进行匹配,筛选符合条件的电子档案,最终反馈匹配成功的检索结果。由于此种方式要将关键词与存储的电子档案逐一匹配,若存储的电子档案数量不大,需要比对的数据量相对较少,尚可满足利用需求。但针对海量电子文档的检索,由于数据量过大,此种查询方式会带来查询延时,在一定程度上无法满足实时反馈检索结果的需求。
另外,在查询用户无法提供关键词或者提供的关键词相关性不大的应用场景下,系统无法精准获取用户需求,进而无法提供给用户真正所需的电子档案,从而减弱电子档案的利用效率,影响用户体验。而且当前大部分推荐系统缺乏用户喜好的相关数据,无法建立用户和用户之间的关联度分析,进而尚未实现相似用户感兴趣的电子档案的互相推荐。
二、电子档案实时推荐系统优化策略
针对上述问题,本文提出电子档案实时推荐系统的优化模型,以解决推荐效率低下等问题。该优化模型是在不同阶段分别应用基于内容的召回推荐策略和基于用户的协同过滤推荐策略,通过用户画像生成和倒排索引构建、混合推荐和推荐结果的实时反馈等步骤,最终达到电子档案实时推荐的目标。具体实施步骤如下所述。
(一)基础数据生成与构建
1.用户画像生成。不同于传统基于关键词的检索方式,该推荐系统主要基于用户的喜好和意图进行自动化的推荐。为了获取用户的喜好,推荐系统需要获取用户对不同电子档案的行为数据,包括点击、阅读等操作,然后基于此生成用户画像。同时,该系统逐一对电子档案生成电子档案画像,主要涉及文章分类、主题词提取等。
2.电子档案标签编码。为了高效完成自动推荐,该系统还需要逐一对电子档案和用户进行标签编码。为便于理解,这里假设每一份电子档案使用64位整数作为标签进行编码,将64位整数分为两部分,高12位用来表示电子档案的相关类型参数,低52位用来表示该类型参数对应的编码标识。例如,某电子档案的标签是{“所属领域:新能源”,“发布单位:集团某科研院所”,“文档类型:制度”,“主题词:海上风电”},这里的标签和对应的值可根据业務需要动态进行调整。
3.用户标签编码。与上述电子档案的标签编码类似,这里也采用64位整数来标识用户,将64位整数分为两部分,高12位用来表示用户的相关类型参数,低52位用来表示该类型参数对应的编码标识。例如,某用户的标签是“{关注领域:新能源”,“所在单位:集团某科研院所”,“喜好文档类型:制度”,“喜好主题:海上风电”},这里的标签和对应的值可根据业务需要动态调整。
4.倒排索引构建。传统正向索引技术主要是建立电子档案与关键词的映射关系,将档案ID或者标题作为文档唯一标识。例如“档案A”“档案B”“档案C”中包含“新能源”这个关键词,其对应的正向索引为:{“档案A”:“新能源”、“档案B”:“新能源”、“档案C”:“新能源”},通过此种方式建立的映射关系,在对“新能源”这个关键词进行检索查询时,需逐一从每份档案中进行全文检索,在一定程度上影响了检索效率。而倒排索引是记录每个关键词和对应的电子档案信息的列表,采用倒排索引建立的映射关系为:{“新能源”:“档案A”,“档案B”,“档案C”}。后期通过“新能源”关键词检索时,只需要查询一次就可以得到所有包含该关键词的档案信息,可有效提升检索效率。
这里将电子档案和用户的标签作为关键词来构建倒排索引,在倒排索引列表中记录对应的电子档案的存放列表。以上述电子档案和用户标签编码为例,构建的电子档案倒排索引列表为:{“所属领域”:“海上风电,新能源,水电”},{“文档类型”:“制度,通知,纪要”};用户倒排索引列表为:{“关注领域-新能源”:“用户A,用户B,用户C”},{“感兴趣类型-制度”:“用户B,用户C,用户D”}。
(二)基于内容的召回推荐策略
基于内容的召回是指根据电子档案的内容,来判断该档案是否符合用户喜好。其主要应用在推荐系统的冷启动环节(即系统上线运行的初期),处于这个时期的推荐系统由于缺乏用户的浏览、点击等行为数据,无法通过用户的喜好进行推荐。基于内容的召回推荐策略可以通过分析电子档案的内容,从而提炼出电子档案标签,推荐给能匹配该标签的用户。
具体来说,如果用户画像和电子档案画像中的标签或关键词相同,说明该电子档案的内容符合用户喜好,可推送该电子档案。从计算的角度来说,即将用户标签和电子档案标签进行逻辑“与”运算(标签里存放的都是0或者1这样的64位正整数),若运算结果完全一致,可将电子档案倒排索引列表中的电子档案依次取出并推送给该用户,也可通过设定结果相似度的阈值来判断是否需要推送。
(三)基于用户的协同过滤推荐策略
在系统运行上述基于内容的召回推荐算法一段时间后,此时后台系统已存储大量的用户行为数据。在此背景下可使用基于用户的协同过滤推荐策略,该策略与基于内容的召回推荐策略的不同之处在于,其不依赖电子档案的内容进行推荐,而基于用户与电子档案的互动关系来进行推荐。从本质上说,就是将和某用户相似的用户找出来,然后将相似用户所浏览过的电子档案推荐给该用户。
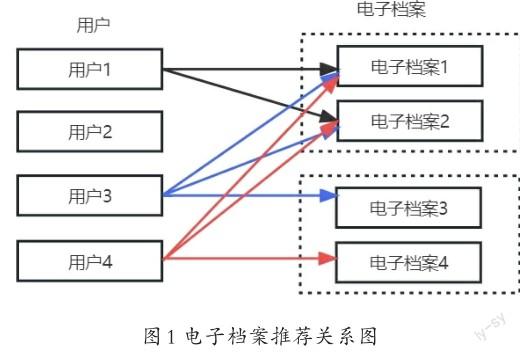
具体操作分为两步:第一步,找到与该用户最相似的一批用户;第二步,将相似用户浏览过但该用户没有浏览的电子档案进行推荐。例如,用户1浏览过档案1和档案2,而用户3和用户4也浏览过档案1和档案2,那么用户1和用户3、用户4就是相似用户。如果用户3和用户4还分别浏览过档案3和档案4,就可以将档案3和档案4都推荐给用户1。具体如图1所示。
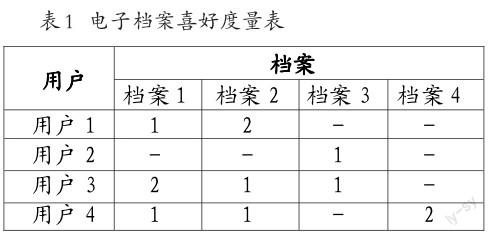
这里以一个实际例子来进一步说明,假定有四个用户、四篇电子档案,用户对四篇电子档案的兴趣程度(可通过用户的点击次数、收藏和转发等行为计算)如表1所示。
为了便于理解,表格里的每个电子档案列下的数字表示每个用户对该电子档案的喜好度(可通过用户的点击次数、收藏和转发等行为计算),表中“-”表示用户和档案尚未建立相关的喜好度。
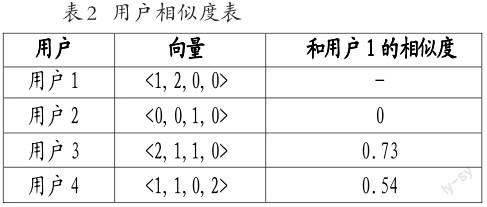
基于表1,若要找出和用户1相似的用户,可以将用户对电子档案的喜好度看作一个n维空间,每个用户都可以表示为n维空间中的一个向量,同时将n维空间中各个向量维度中的值设置为用户对电子档案的喜好度。据此,找到与用户1最相似的用户的问题,就变成在n维向量空间中,找到和用户1这个点最接近的点的问题。而在n维向量空间中找到与某点最接近的点可以通过计算余弦距离来对比获得。这里采用余弦距离所得的结果如表2所示。
根据表2,用户2、用户3、用户4和用户1的相似度排序为用户3>用户4>用户2,根据相似度的排序可取出若干相似用户,然后将相似用户感兴趣的电子档案取出进行推荐。从排序得出,用户3和用户4为用户1的相似用户,然后将用户4和用户3感兴趣的电子档案3和电子档案4进行排序推荐。针对优先推荐档案3还是档案4的问题,可对电子档案的喜好进行加权打分(用户喜好度×与待推荐用户的相似度)累加,优先推荐分数最高的电子档案。
基于上述数据,分别计算电子档案3和电子档案4的推荐得分,档案3的推荐得分是:1×0.73=0.73(用户3的喜好度×用户3和用户1的相似度),档案4的推荐得分是:2×0.54 = 1.08(用户4的喜好度×用户4和用户1的相似度)。因此,根据计算得到的结果,系统会优先推荐档案4,再推荐档案3。
(四)推荐结果的实时反馈
最后根据上述算法选取符合条件的且排序最靠前的若干个电子档案返回,得到最终推荐结果,也就是说从全部符合条件的电子档案中选择排名前K个结果即可。为提高排序选择效率,可采用常规排序的Top-K排序(又叫堆排序)算法来获取。该算法是在特定的数据区域中找出排名前K个符合条件的数据的检索方法。采用该方法将大幅减少排序的时间,有效提升检索性能,同时避免不必要的系统资源消耗,减少计算资源,提升系统运行效率。
三、结语
本文围绕电子档案实时推荐的应用方式,通过引入基于内容的召回推荐策略和基于用户的协同过滤推荐策略,将两种类型的推荐模式进行互补融合。在用户行为数据较少、相似用户不具规模的情况下,采用基于内容的召回推荐策略进行电子档案推荐,解决系统冷启动问题。当系统运行一段时间,用户和电子档案积累到一定数量时,采用基于用户的协同过滤推荐策略,可以进一步提高电子档案推荐的科学性和准确率。下一阶段,对电子档案检索的研究还可关注基于AI的实时推荐模型,即通过AI自动化与推荐搜索算法进一步融合,以达到更好的实时推荐效果。
*本文系2020年国家档案局科技项目“基于重大工程项目施工现场的电子文件‘单套制归档和电子档案管理研究”(项目批准号:2020-X-22)的阶段性研究成果。
参考文献:
[1]刘青文.基于协同过滤的推荐算法研究[D].合肥:中国科学技术大学,2013.
[2]王哲.新时期建设工程电子档案的移交与接收工作探析[J].北京档案,2023(1):30-32.
[3]杨茜雅.中国联通电子档案数据挖掘與智能利用的研究[J].档案学研究,2018(6):105-109.
[4]杨俊杰.数字化转型背景下的档案信息安全问题研究[D].郑州:郑州航空工业管理学院,2022.
[5]柯贤斌.基于用户的协同过滤算法在图书推荐系统中的应用研究[D].荆州:长江大学,2019.
[6]张新,王玮.探索电子文件归档和电子档案管理新模式[J].中国档案,2018(5):70-71.
[7]秦杨.我国智慧档案馆建设的现状分析与对策研究[D].保定:河北大学,2020.
作者单位:1.中国长江三峡集团有限公司科学技术研究院
2.中国长江三峡集团有限公司档案中心
