基于深度学习模型的伺服压机压装结果预测研究
2023-12-04王清亮陈岩霞
王 亮 王清亮 陈岩霞
(北京天玛智控科技股份有限公司,北京 100013)
在机械加工制造领域,随着设备自动化、数字化、网络化的发展,各种智能感知设备产生海量的工艺设备、生产过程和运行管理数据,这些蕴含丰富信息的数据共同构成了制造大数据或工业大数据。面对大数据,以深度学习为代表的人工智能技术从基于逻辑推理和概率统计的传统范式向大数据驱动的新范式转变,通过解析多源异构动态数据中隐含的复杂结构特征来处理异常运行状况的不确定性和模糊性,为研究工业大数据条件下异常工况诊断与自优化系统奠定了基础[1]。
电磁先导阀是电液控制系统的核心元件。为了完成阀体上某些深孔的加工,需要对工艺孔进行疏通或者联络,但是工艺孔在实际使用中需要完全堵死,利用涨开式堵头(以下简称涨堵)进行密封。矿用液压阀块装配专机采用伺服压机将涨堵压入工艺孔内。装配过程中,由于涨堵与工艺孔的配合精度和装配环境等问题,依据伺服压机的压力位移曲线特征判断产品是否合格存在较大的误判率,导致生产上的浪费。基于此,首先采集液压阀块码值、压制过程实时压力和行程数据、产品检测结果数据,建立液压阀块数据库。其次,读取数据库数据,采用深度学习的方法,训练并建立压制过程数学模型。最后,将生产时伺服压机的实时压力和行程数据代入模型,通过计算判断产品是否合格。本控制算法投入使用后,对于判断加工产品是否合格的正确率由原来的87%提高到94%。后期随着数据的累积和训练模型的成熟,能够继续提高判断的正确率,减少生产浪费。
1 系统架构
矿用液压阀块装配专机工作流程,如图1 所示。

图1 产品加工流程图
六轴机器人从工位1 夹取液压阀块送至工位2,工位2 读码器读取液压阀块码值后,再由六轴机器人将液压阀块放置到工位3。工位3 的四轴机器人抓取涨堵,放入液压阀块工艺孔内。六轴机器人将液压阀块放置在工位4,工位4 伺服压机将涨堵压入液压阀块工艺孔内,完成液压阀块加工。最后,六轴机器人将合格品放入工位5,不合格品放入工位6。
系统控制系统架构如图2 所示,控制层包括数据采集与监视控制(Supervisory Control And Data Acquisition,SCADA)、可编程逻辑控制器(Programmable Logic Controller,PLC)和搭载深度学习模型的工控机。PLC 负责设备动作时序控制和数据采集,与工控机和SCADA 系统通信。SCADA 系统存储液压阀块码值、压装过程实时压力和行程数据、液压阀块检测结果数据,生成并输出液压阀块合格品表格和不合格品表格。工控机读取SCADA 系统液压阀块信息,使用合格品与不合格品数据表格训练并建立伺服压机压装过程深度学习模型。设备生产时,工控机接收PLC 传送的伺服压机实时压力和行程数据,将数据代入深度学习模型运算后,输出产品是否合格的判断结果,并传送给PLC。

图2 控制系统架构
2 数据采集
2.1 压装过程建模数据采集
压装过程建模数据采集包括以下4 个步骤。第一,液压阀块码值。六轴机器人先从工位1 夹取液压阀块放置在工位2,再由PLC 触发工位2 读码器,读取液压阀块码值并存入内部存储器,液压阀块与码值一一对应。第二,压装过程数据采集。液压阀块在工位3 放堵完成后,六轴机器人将其移至工位4,PLC启动伺服压机。伺服压机反馈实时压力、行程数据给PLC,PLC 根据实时数据判断伺服压机是否接触到涨堵。当判断伺服压机接触到涨堵时,PLC 启动循环中断程序,周期记录压力、行程数据,并存储于内部寄存器。第三,检测结果数据采集。在检测工位,由人工或液压检测台对液压阀块进行检测[2]。人工检测先扫码液压阀块编码,再测量涨堵深度,观察判断涨堵是否涨开,最后手动将检测结果输入SCADA 系统。自动检测到液压阀块经后续工位装入先导阀后,对先导阀进行上压测试。在检测工位,PLC 读取液压阀块码值和检测结果数据,传输给SCADA 系统储存。第四,SCADA 系统数据采集。SCADA 系统依据液压阀块码值、伺服压机实时压力和行程数据以及检测结果数据,输出合格品数据表和不合格品数据表。深度学习个人计算机(Personal Computer,PC)与SCADA 系统通信,读取表格数。
2.2 设备生产时压力和行程数据采集
设备生产时,工控机与PLC 通信。压装完成后,PLC 将采集到的压装过程实时压力和行程数据打包传输给工控机,工控机调用训练好的深度学习数学模型,代入实时压力行程数据,得出液压阀块压装的预测结果并反馈给PLC。
3 压装过程建模
3.1 数据处理
SCADA 系统以液压阀块码值为索引建立产品记录,包括液压阀块码值、实时压力和行程(6 组采样点)、是否合格判断结果[3],多条记录组成产品数据库。在工控机上,人工启动深度学习训练模型时,工控机向SCADA 系统发送数据请求指令。SCADA 系统输出合格品表和不合格品表给工控机,工控机先对收到数据进行数据处理,流程如图3 所示。

图3 数据处理过程
由于不合格件记录数量较少,为增加深度学习模型的广泛适用性,在观察合格件的压力及行程数据后发现,两者数据大体呈现正比关系,于是将几组数据顺序打乱,作为不合格数据的组成部分之一,增加不合格件的样本数量[4]。打乱方法为使用Python 内置Shuffle 随机打乱功能,将压力及行程的数据随机匹配作为不合格数据。对于液压阀孔深度不一致、倒角不一致以及有毛刺的情况进行测试并采集数据,归为不合格数据样本。本次训练模型采用数据记录包括合格数据145 组,不合格数据31 组,组成三维矩阵[176,6,2]。其中,“176”为总的采集数据组数量,“6”为每组记录采样数,“2”为压力及行程数据。输入结果数据矩阵为[176,1],其中“1”为检测结果。
为保证深度学习模型训练过拟合,同时避免训练集特有的特征情况出现,在训练前将所有合格数据和不合格数据组及其结果次序打乱,并按照140 组为训练集、36 组为验证集进行区分。在训练完成后,有额外65 组未参加训练的数据作为测试集,验证深度学习训练模型的结果。
3.2 深度学习模型搭建与训练
由于合格品数据的关系特征呈相对正比关系,选择全连接层(Dense 层)作为模型的主题结构。增加拉平层(Flatten 层),拉平二维数据简化模型训练过程,并根据数据的数量及矩阵的尺寸调整层数内参数数量,进而确定深度学习模型。根据训练数据得出最终的深度学习模型,如图4 所示。

图4 深度学习模型架构
此模型总计302 209 个参数,训练完成后总计训练参数为302 209 个,未训练参数为0 个。由于输出结果为1 或者0,选用二元交叉熵函数作为损失函数。由于过程数据较为分散,优化算法选用Adam。一次训练所选取的样本数为32,总计训练次数为5 000 次。完成5 000 次训练后的模型训练集成功率为97.43%,验证集成功率为97.22%。深度模型训练集和验证集的准确性及损失过程图,如图5 ~图8 所示。
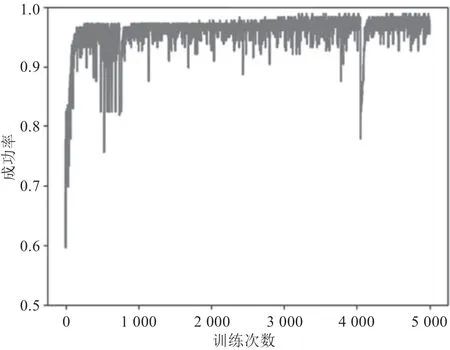
图5 训练集准确性过程图
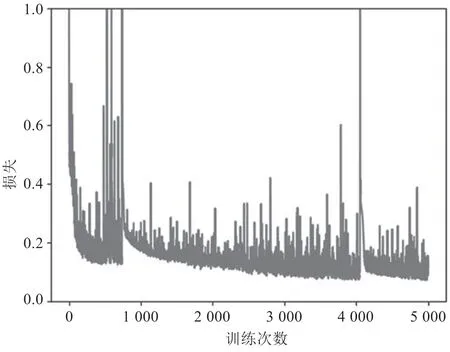
图6 训练集损失过程图

图7 验证集准确性过程图
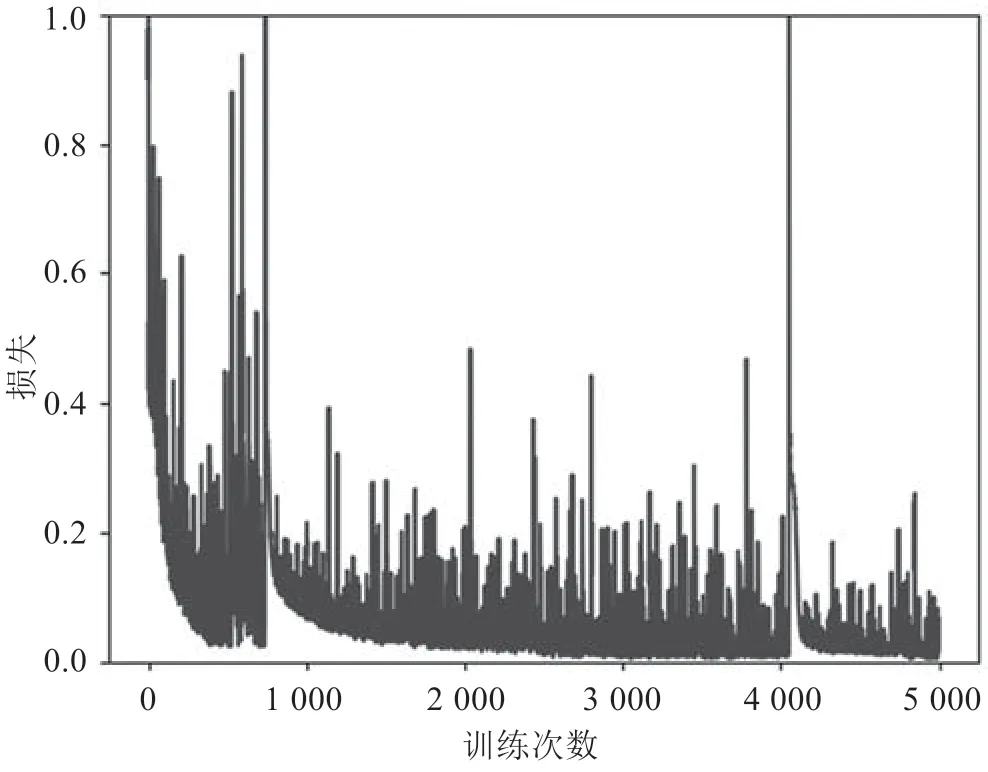
图8 验证集损失过程图
在深度学习模型训练完成后,使用65 组数据作为测试集数据对模型进行测试。测试集中合格品数量为40 组,不合格品数量为25 组,模型预测成功率为93.85%,合格品误检率为2.50%,不合格误检率为16.00%。由测试集可以看出,不合格品误检率远高于合格品误检率,其原因在于不合格品的样本数量少。此外,从模型可以看出,在3 500 次训练后,其准确率及损失函数逐渐趋于稳定。但是由于采集数据的数量限制,测试集的数据仅为36 组,准确率变化较大。而且数据中合格数据和不合格数据比例为145 ∶31,不合格数据占比较低,导致模型在判定不合格情况的成功率上具有不确定性。
3.3 深度学习模型应用与改进
为解决模型健壮性差、应用面窄的问题,同时提高模型预判的准确率,增加自适应性控制系统架构[5]。模型自适应系统,如图9 所示。
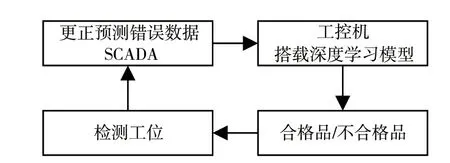
图9 模型自适应系统
矿用液压阀块加工专机连续生产时,完成加工的产品经深度学习模型判断,理论上分为合格品和不合格品。这两类产品再次进入检测工位,经检测后得出实际的合格品与不合格品,并将检测结果数据传送给SCADA 系统,SCADA 系统更正预测错误数据,建立新的训练数据组。当新数据组达到500 组,且合格品与不合格品的比例为3 ∶2 时,将新旧数据库进行整合。SCADA 调用工控机中的深度学习模型训练程序重新训练模型,如果训练集和验证集的成功率高于产线合格率(99%)的要求,则使用新训练模型代替原模型完成模型自适应更新。
4 结语
将深度学习理论应用于处理矿用液压阀块加工专机大数据,经过对伺服压机压制过程的数据采样、建模、模型自适应等环节,建立基于深度学习的压制过程数学模型,用于判读产品压装结果是否合格。在实际应用过程中,随着训练模型样本的增加,模型输出正确率在94%以上。深度学习原理可应用于处理单机设备数据,也可用于其他无明显线性及逻辑回归关系的预测性问题的建模预测。在工业大数据时代背景下,深度学习原理将被应用于智能产线,助力产线由自动化向智能化转型。
